 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep learning using Havrda-Charvat entropy for classification of pulmonary endomicroscopy
Apr 19, 2021

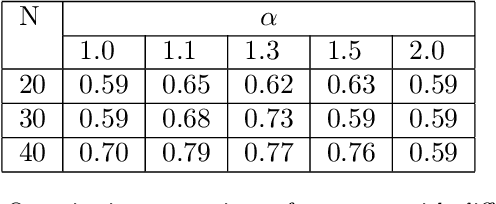
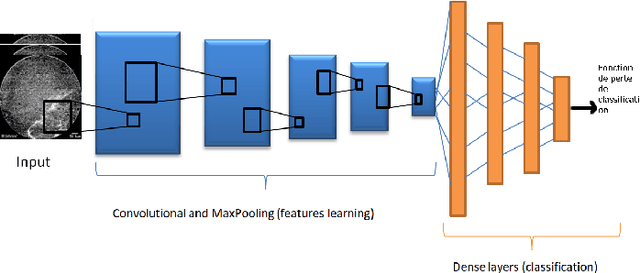
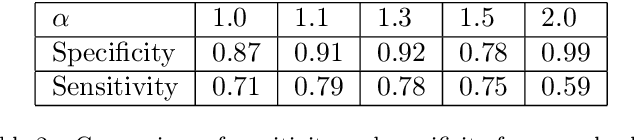
Pulmonary optical endomicroscopy (POE) is an imaging technology in real time. It allows to examine pulmonary alveoli at a microscopic level. Acquired in clinical settings, a POE image sequence can have as much as 25% of the sequence being uninformative frames (i.e. pure-noise and motion artefacts). For future data analysis, these uninformative frames must be first removed from the sequence. Therefore, the objective of our work is to develop an automatic detection method of uninformative images in endomicroscopy images. We propose to take the detection problem as a classification one. Considering advantages of deep learning methods, a classifier based on CNN (Convolutional Neural Network) is designed with a new loss function based on Havrda-Charvat entropy which is a parametrical generalization of the Shannon entropy. We propose to use this formula to get a better hold on all sorts of data since it provides a model more stable than the Shannon entropy. Our method is tested on one POE dataset including 2947 distinct images, is showing better results than using Shannon entropy and behaves better with regard to the problem of overfitting. Keywords: Deep Learning, CNN, Shannon entropy, Havrda-Charvat entropy, Pulmonary optical endomicroscopy.
Windowed total variation denoising and noise variance monitoring
Jan 28, 2021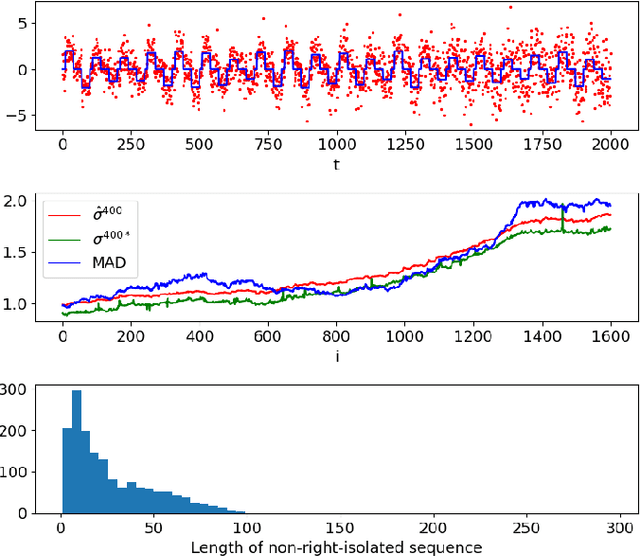
We proposed a real time Total-Variation denosing method with an automatic choice of hyper-parameter $\lambda$, and the good performance of this method provides a large application field. In this article, we adapt the developed method to the non stationary signal in using the sliding window, and propose a noise variance monitoring method. The simulated results show that our proposition follows well the variation of noise variance.
A Machine Learning Approach to Predicting Continuous Tie Strengths
Jan 23, 2021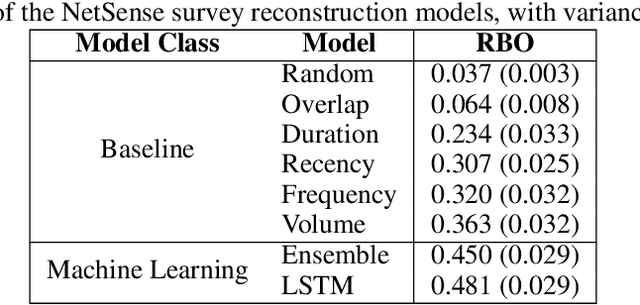
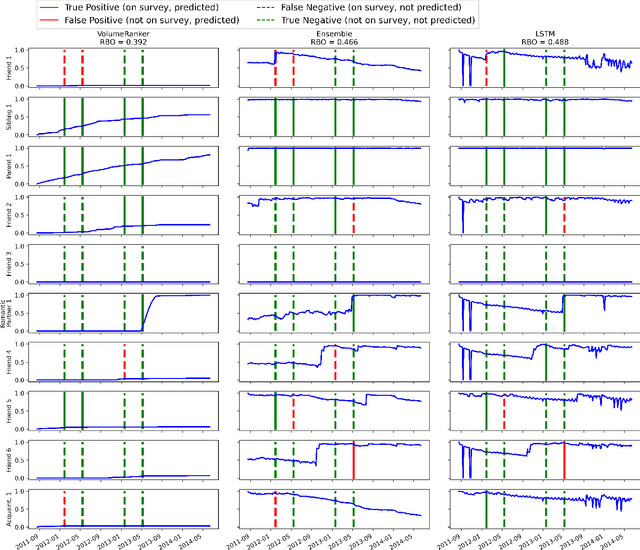
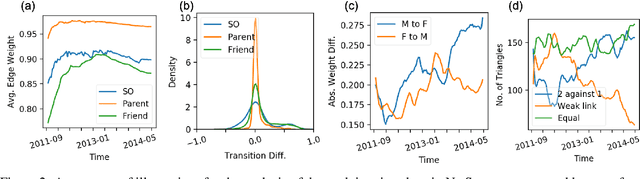
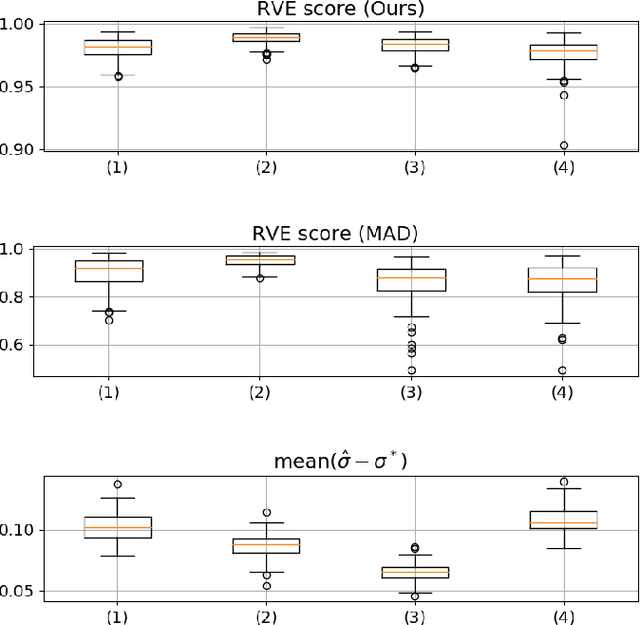
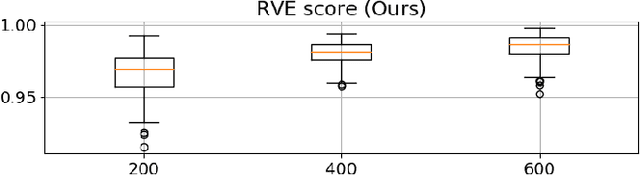
Relationships between people constantly evolve, altering interpersonal behavior and defining social groups. Relationships between nodes in social networks can be represented by a tie strength, often empirically assessed using surveys. While this is effective for taking static snapshots of relationships, such methods are difficult to scale to dynamic networks. In this paper, we propose a system that allows for the continuous approximation of relationships as they evolve over time. We evaluate this system using the NetSense study, which provides comprehensive communication records of students at the University of Notre Dame over the course of four years. These records are complemented by semesterly ego network surveys, which provide discrete samples over time of each participant's true social tie strength with others. We develop a pair of powerful machine learning models (complemented by a suite of baselines extracted from past works) that learn from these surveys to interpret the communications records as signals. These signals represent dynamic tie strengths, accurately recording the evolution of relationships between the individuals in our social networks. With these evolving tie values, we are able to make several empirically derived observations which we compare to past works.
Towards a 6G AI-Native Air Interface
Dec 15, 2020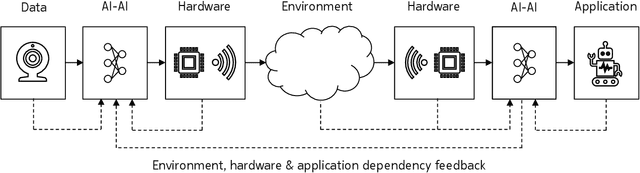
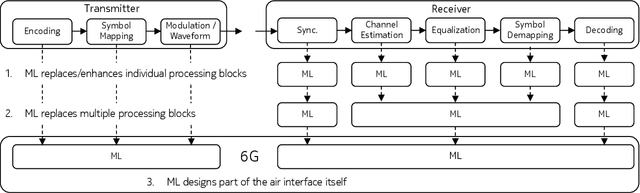
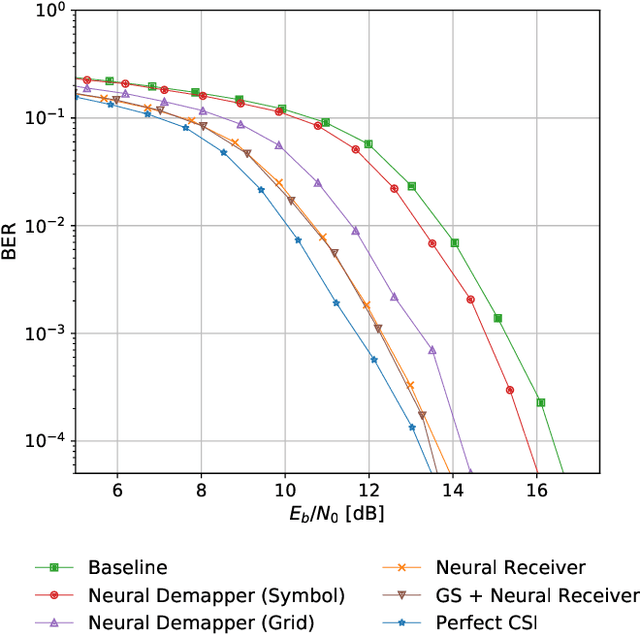
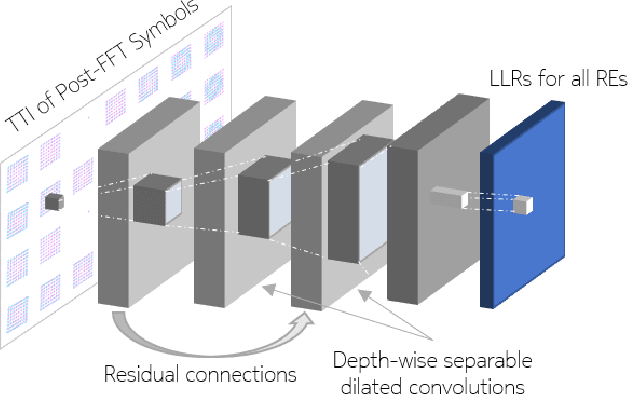
Each generation of cellular communication systems is marked by a defining disruptive technology of its time, such as orthogonal frequency division multiplexing (OFDM) for 4G or Massive multiple-input multiple-output (MIMO) for 5G. Since artificial intelligence (AI) is the defining technology of our time, it is natural to ask what role it could play for 6G. While it is clear that 6G must cater to the needs of large distributed learning systems, it is less certain if AI will play a defining role in the design of 6G itself. The goal of this article is to paint a vision of a new air interface which is partially designed by AI to enable optimized communication schemes for any hardware, radio environment, and application.
Depthwise Separable Convolutions Allow for Fast and Memory-Efficient Spectral Normalization
Feb 12, 2021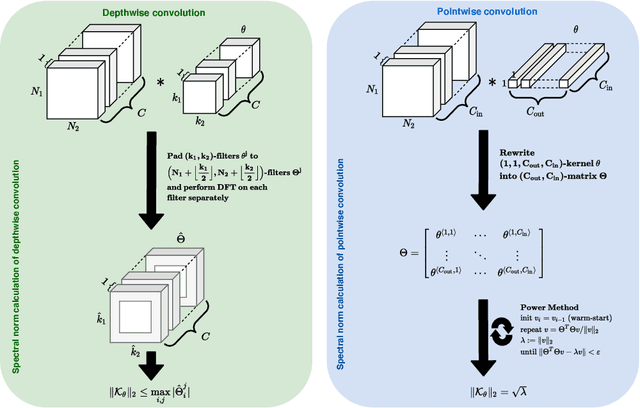

An increasing number of models require the control of the spectral norm of convolutional layers of a neural network. While there is an abundance of methods for estimating and enforcing upper bounds on those during training, they are typically costly in either memory or time. In this work, we introduce a very simple method for spectral normalization of depthwise separable convolutions, which introduces negligible computational and memory overhead. We demonstrate the effectiveness of our method on image classification tasks using standard architectures like MobileNetV2.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 19, 2021

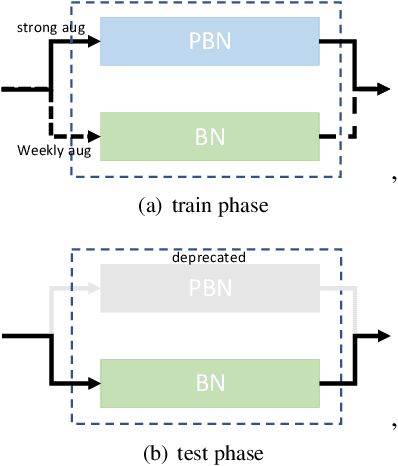

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
Unsupervised Cross-Domain Speech-to-Speech Conversion with Time-Frequency Consistency
May 19, 2020
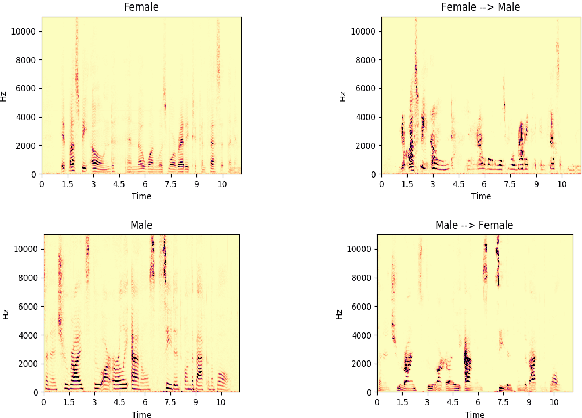
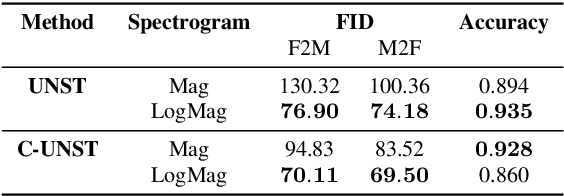
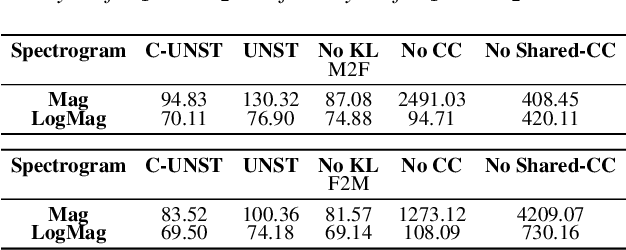
In recent years generative adversarial network (GAN) based models have been successfully applied for unsupervised speech-to-speech conversion.The rich compact harmonic view of the magnitude spectrogram is considered a suitable choice for training these models with audio data. To reconstruct the speech signal first a magnitude spectrogram is generated by the neural network, which is then utilized by methods like the Griffin-Lim algorithm to reconstruct a phase spectrogram. This procedure bears the problem that the generated magnitude spectrogram may not be consistent, which is required for finding a phase such that the full spectrogram has a natural-sounding speech waveform. In this work, we approach this problem by proposing a condition encouraging spectrogram consistency during the adversarial training procedure. We demonstrate our approach on the task of translating the voice of a male speaker to that of a female speaker, and vice versa. Our experimental results on the Librispeech corpus show that the model trained with the TF consistency provides a perceptually better quality of speech-to-speech conversion.
Recurrent Neural Filters: Learning Independent Bayesian Filtering Steps for Time Series Prediction
Jan 23, 2019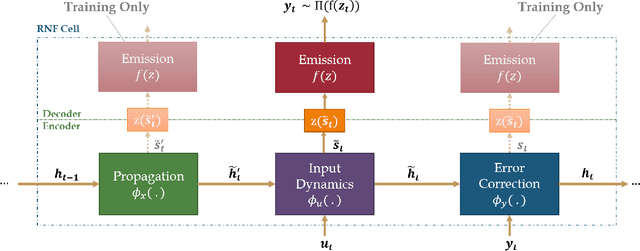
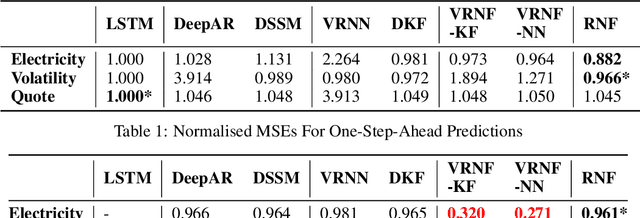
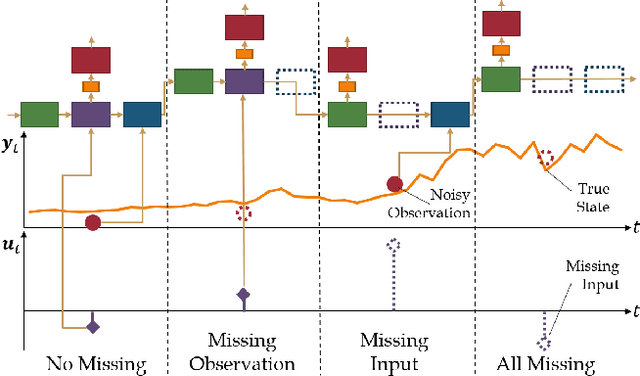
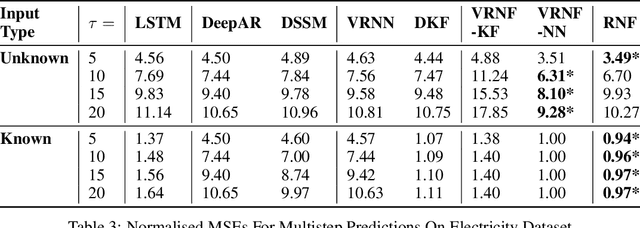
Despite the recent popularity of deep generative state space models, few comparisons have been made between network architectures and the inference steps of the Bayesian filtering framework -- with most models simultaneously approximating both state transition and update steps with a single recurrent neural network (RNN). In this paper, we introduce the Recurrent Neural Filter (RNF), a novel recurrent variational autoencoder architecture that learns distinct representations for each Bayesian filtering step, captured by a series of encoders and decoders. Testing this on three real-world time series datasets, we demonstrate that decoupling representations not only improves the accuracy of one-step-ahead forecasts while providing realistic uncertainty estimates, but also facilitates multistep prediction through the separation of encoder stages.
hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices
Mar 23, 2021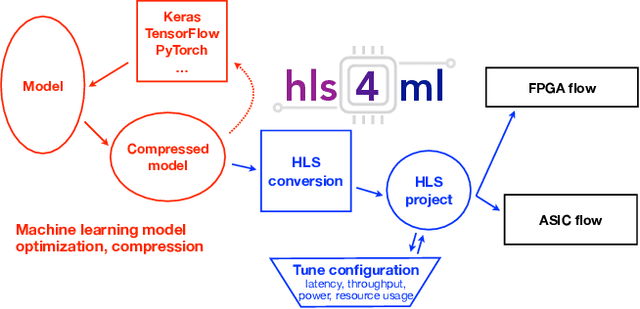
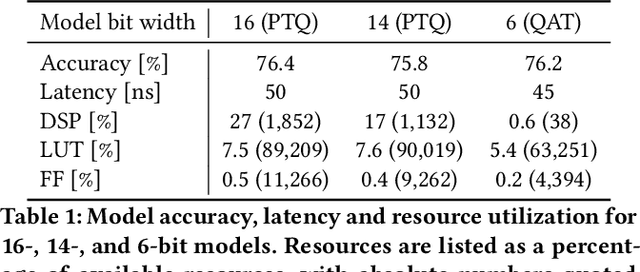
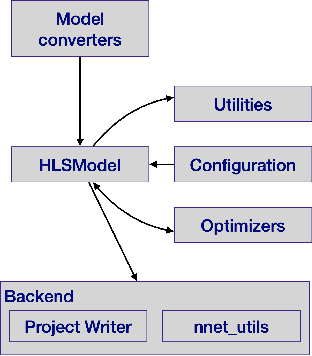
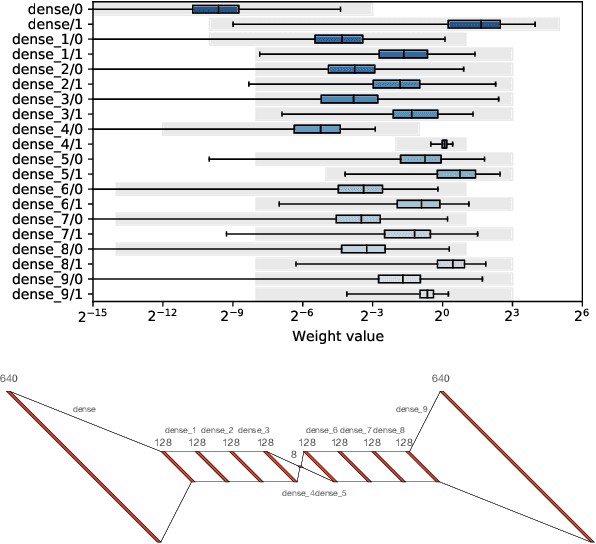
Accessible machine learning algorithms, software, and diagnostic tools for energy-efficient devices and systems are extremely valuable across a broad range of application domains. In scientific domains, real-time near-sensor processing can drastically improve experimental design and accelerate scientific discoveries. To support domain scientists, we have developed hls4ml, an open-source software-hardware codesign workflow to interpret and translate machine learning algorithms for implementation with both FPGA and ASIC technologies. We expand on previous hls4ml work by extending capabilities and techniques towards low-power implementations and increased usability: new Python APIs, quantization-aware pruning, end-to-end FPGA workflows, long pipeline kernels for low power, and new device backends include an ASIC workflow. Taken together, these and continued efforts in hls4ml will arm a new generation of domain scientists with accessible, efficient, and powerful tools for machine-learning-accelerated discovery.
iX-BSP: Incremental Belief Space Planning
Feb 28, 2021

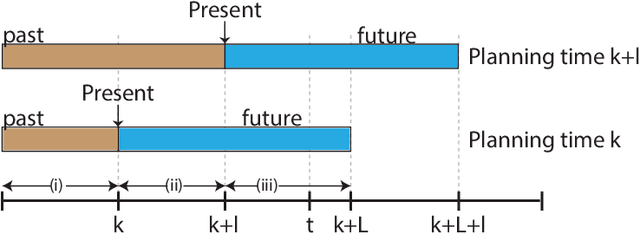

Deciding what's next? is a fundamental problem in robotics and Artificial Intelligence. Under belief space planning (BSP), in a partially observable setting, it involves calculating the expected accumulated belief-dependent reward, where the expectation is with respect to all future measurements. Since solving this general un-approximated problem quickly becomes intractable, state of the art approaches turn to approximations while still calculating planning sessions from scratch. In this work we propose a novel paradigm, Incremental BSP (iX-BSP), based on the key insight that calculations across planning sessions are similar in nature and can be appropriately re-used. We calculate the expectation incrementally by utilizing Multiple Importance Sampling techniques for selective re-sampling and re-use of measurement from previous planning sessions. The formulation of our approach considers general distributions and accounts for data association aspects. We demonstrate how iX-BSP could benefit existing approximations of the general problem, introducing iML-BSP, which re-uses calculations across planning sessions under the common Maximum Likelihood assumption. We evaluate both methods and demonstrate a substantial reduction in computation time while statistically preserving accuracy. The evaluation includes both simulation and real-world experiments considering autonomous vision-based navigation and SLAM. As a further contribution, we introduce to iX-BSP the non-integral wildfire approximation, allowing one to trade accuracy for computational performance by averting from updating re-used beliefs when they are "close enough". We evaluate iX-BSP under wildfire demonstrating a substantial reduction in computation time while controlling the accuracy sacrifice. We also provide analytical and empirical bounds of the effect wildfire holds over the objective value.