 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The MIT Humanoid Robot: Design, Motion Planning, and Control For Acrobatic Behaviors
Apr 19, 2021

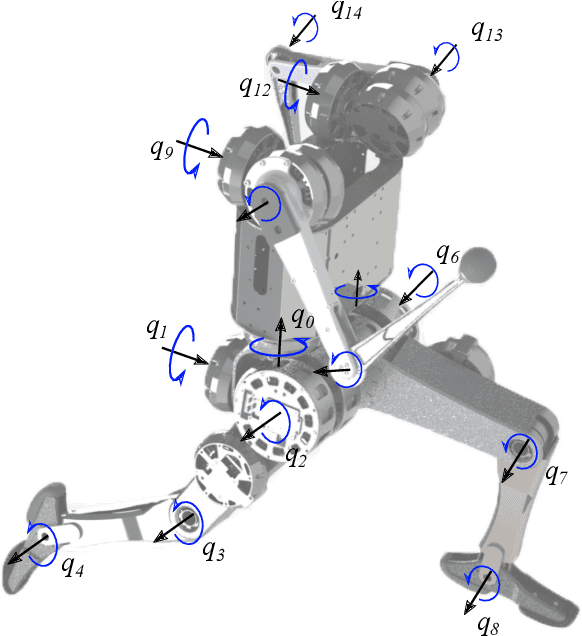

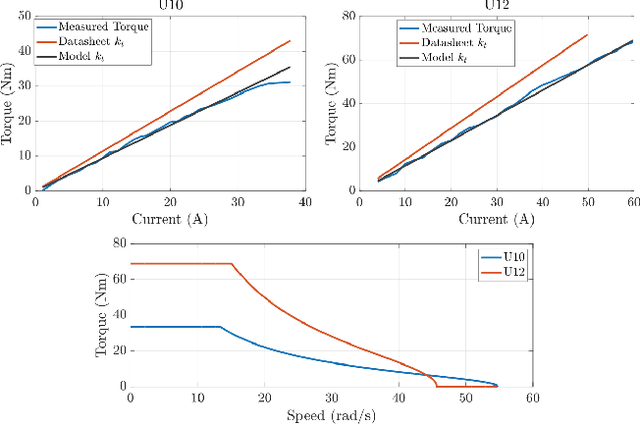
Demonstrating acrobatic behavior of a humanoid robot such as flips and spinning jumps requires systematic approaches across hardware design, motion planning, and control. In this paper, we present a new humanoid robot design, an actuator-aware kino-dynamic motion planner, and a landing controller as part of a practical system design for highly dynamic motion control of the humanoid robot. To achieve the impulsive motions, we develop two new proprioceptive actuators and experimentally evaluate their performance using our custom-designed dynamometer. The actuator's torque, velocity, and power limits are reflected in our kino-dynamic motion planner by approximating the configuration-dependent reaction force limits and in our dynamics simulator by including actuator dynamics along with the robot's full-body dynamics. For the landing control, we effectively integrate model-predictive control and whole-body impulse control by connecting them in a dynamically consistent way to accomplish both the long-time horizon optimal control and high-bandwidth full-body dynamics-based feedback. Actuators' torque output over the entire motion are validated based on the velocity-torque model including battery voltage droop and back-EMF voltage. With the carefully designed hardware and control framework, we successfully demonstrate dynamic behaviors such as back flips, front flips, and spinning jumps in our realistic dynamics simulation.
A LiDAR Assisted Control Module with High Precision in Parking Scenarios for Autonomous Driving Vehicle
May 02, 2021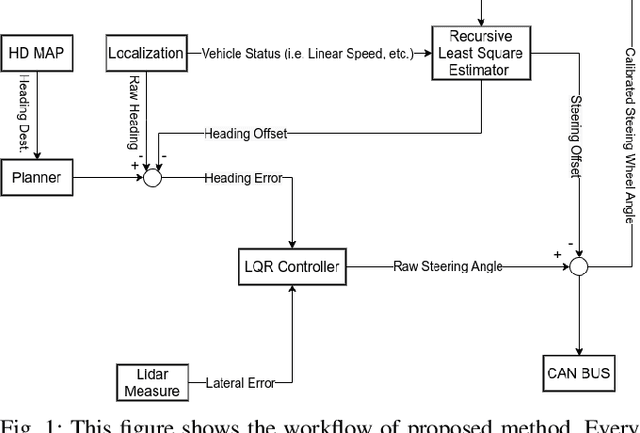
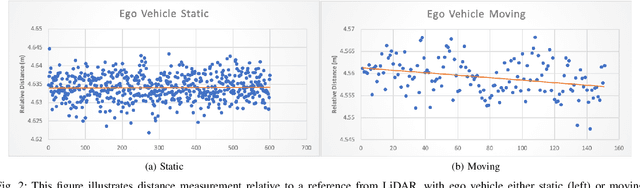
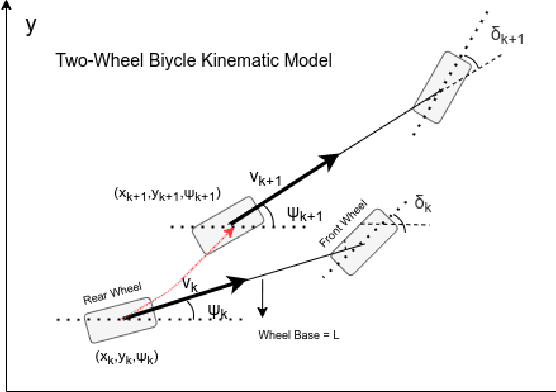
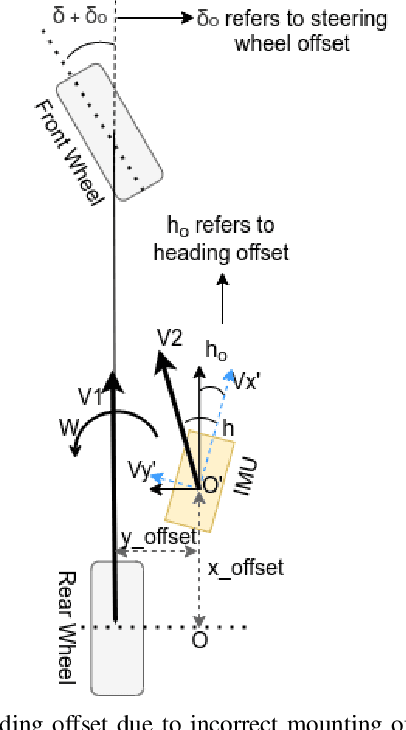
Autonomous driving has been quite promising in recent years. The public has seen Robotaxi delivered by Waymo, Baidu, Cruise, and so on. While autonomous driving vehicles certainly have a bright future, we have to admit that it is still a long way to go for products such as Robotaxi. On the other hand, in less complex scenarios autonomous driving may have the potentiality to reliably outperform humans. For example, humans are good at interactive tasks (while autonomous driving systems usually do not), but we are often incompetent for tasks with strict precision demands. In this paper, we introduce a real-world, industrial scenario of which human drivers are not capable. The task required the ego vehicle to keep a stationary lateral distance (i.e. 3? <= 5 centimeters) with respect to a reference. To address this challenge, we redesigned the control module from Baidu Apollo open-source autonomous driving system. A precise (3? <= 2 centimeters) Error Feedback System was first built to partly replace the localization module. Then we investigated the control module thoroughly and added a real-time calibration algorithm to gain extra precision. We also built a simulation to fine-tune the control parameters. After all those works, the results are encouraging, showing that an end-to-end lateral precision with 3? <= 5 centimeters has been achieved. Further, we show that the results not only outperformed original Apollo modules but also beat specially trained and highly experienced human test drivers.
Sparse Code Multiple Access for 6G Wireless Communication Networks: Recent Advances and Future Directions
Apr 03, 2021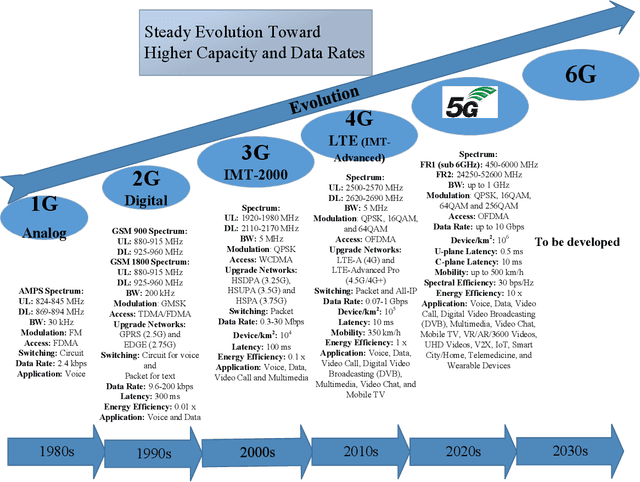
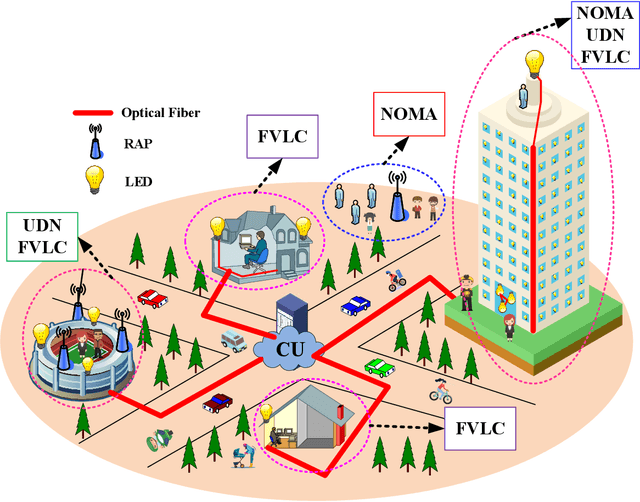
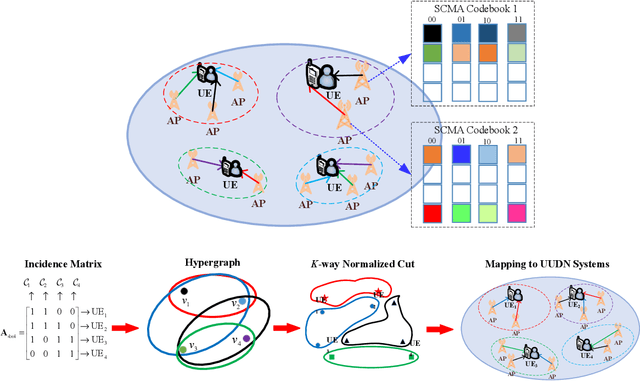
As 5G networks rolling out in many different countries nowadays, the time has come to investigate how to upgrade and expand them towards 6G, where the latter is expected to realize the interconnection of everything as well as the development of a ubiquitous intelligent mobile world for intelligent life. To enable this epic leap in communications, this article provides an overview and outlook on the application of sparse code multiple access (SCMA) for 6G wireless communication systems, which is an emerging disruptive non-orthogonal multiple access (NOMA) scheme for the enabling of massive connectivity. We propose to apply SCMA to a massively distributed access system (MDAS), whose architecture is based on fiber-based visible light communication (FVLC), ultra-dense network (UDN), and NOMA. Under this framework, we consider the interactions between optical front-hauls and wireless access links. In order to stimulate more upcoming research in this area, we outline a number of promising directions associated with SCMA for faster, more reliable, and more efficient multiple access in future 6G communication networks.
DeepObliviate: A Powerful Charm for Erasing Data Residual Memory in Deep Neural Networks
May 13, 2021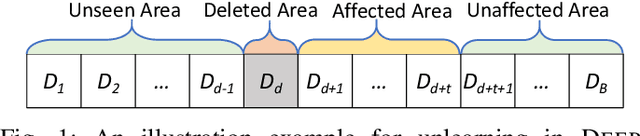
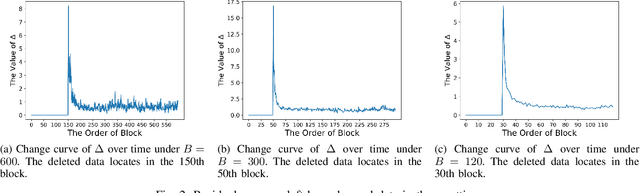
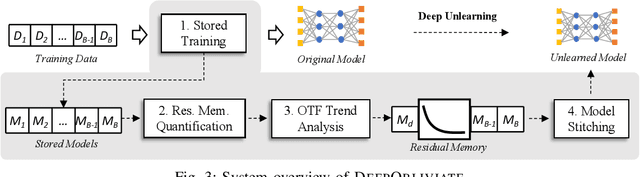
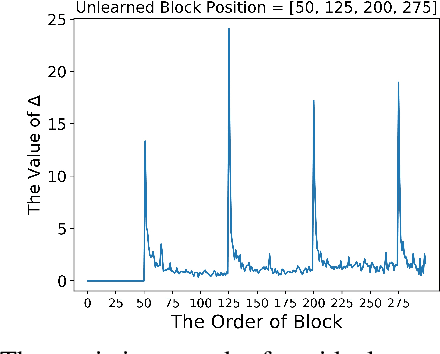
Machine unlearning has great significance in guaranteeing model security and protecting user privacy. Additionally, many legal provisions clearly stipulate that users have the right to demand model providers to delete their own data from training set, that is, the right to be forgotten. The naive way of unlearning data is to retrain the model without it from scratch, which becomes extremely time and resource consuming at the modern scale of deep neural networks. Other unlearning approaches by refactoring model or training data struggle to gain a balance between overhead and model usability. In this paper, we propose an approach, dubbed as DeepObliviate, to implement machine unlearning efficiently, without modifying the normal training mode. Our approach improves the original training process by storing intermediate models on the hard disk. Given a data point to unlearn, we first quantify its temporal residual memory left in stored models. The influenced models will be retrained and we decide when to terminate the retraining based on the trend of residual memory on-the-fly. Last, we stitch an unlearned model by combining the retrained models and uninfluenced models. We extensively evaluate our approach on five datasets and deep learning models. Compared to the method of retraining from scratch, our approach can achieve 99.0%, 95.0%, 91.9%, 96.7%, 74.1% accuracy rates and 66.7$\times$, 75.0$\times$, 33.3$\times$, 29.4$\times$, 13.7$\times$ speedups on the MNIST, SVHN, CIFAR-10, Purchase, and ImageNet datasets, respectively. Compared to the state-of-the-art unlearning approach, we improve 5.8% accuracy, 32.5$\times$ prediction speedup, and reach a comparable retrain speedup under identical settings on average on these datasets. Additionally, DeepObliviate can also pass the backdoor-based unlearning verification.
ScanGAN360: A Generative Model of Realistic Scanpaths for 360$^{\circ}$ Images
Mar 25, 2021
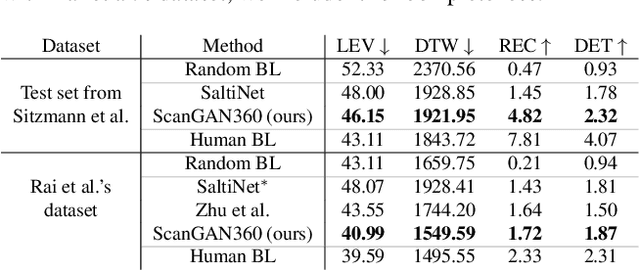
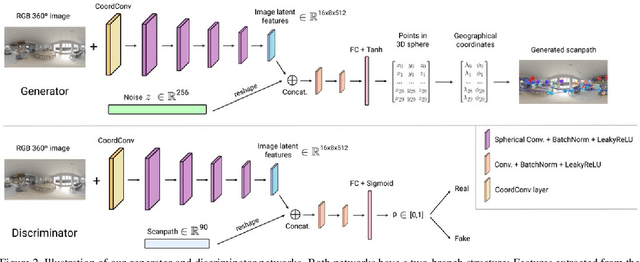
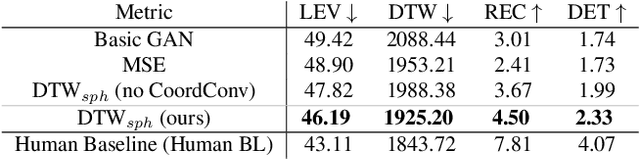
Understanding and modeling the dynamics of human gaze behavior in 360$^\circ$ environments is a key challenge in computer vision and virtual reality. Generative adversarial approaches could alleviate this challenge by generating a large number of possible scanpaths for unseen images. Existing methods for scanpath generation, however, do not adequately predict realistic scanpaths for 360$^\circ$ images. We present ScanGAN360, a new generative adversarial approach to address this challenging problem. Our network generator is tailored to the specifics of 360$^\circ$ images representing immersive environments. Specifically, we accomplish this by leveraging the use of a spherical adaptation of dynamic-time warping as a loss function and proposing a novel parameterization of 360$^\circ$ scanpaths. The quality of our scanpaths outperforms competing approaches by a large margin and is almost on par with the human baseline. ScanGAN360 thus allows fast simulation of large numbers of virtual observers, whose behavior mimics real users, enabling a better understanding of gaze behavior and novel applications in virtual scene design.
Progressive-X+: Clustering in the Consensus Space
Mar 25, 2021
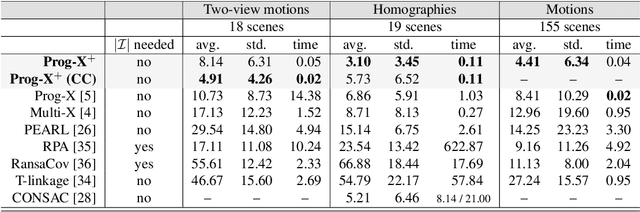

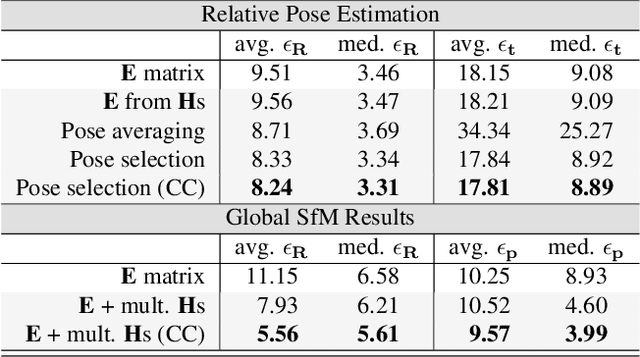
We propose Progressive-X+, a new algorithm for finding an unknown number of geometric models, e.g., homographies. The problem is formalized as finding dominant model instances progressively without forming crisp point-to-model assignments. Dominant instances are found via RANSAC-like sampling and a consolidation process driven by a model quality function considering previously proposed instances. New ones are found by clustering in the consensus space. This new formulation leads to a simple iterative algorithm with state-of-the-art accuracy while running in real-time on a number of vision problems. Also, we propose a sampler reflecting the fact that real-world data tend to form spatially coherent structures. The sampler returns connected components in a progressively growing neighborhood-graph. We present a number of applications where the use of multiple geometric models improves accuracy. These include using multiple homographies to estimate relative poses for global SfM; pose estimation from generalized homographies; and trajectory estimation of fast-moving objects.
Data-driven rogue waves and parameter discovery in the defocusing NLS equation with a potential using the PINN deep learning
Dec 18, 2020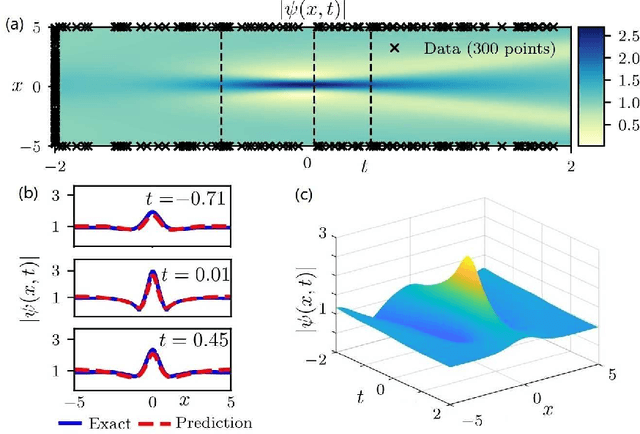

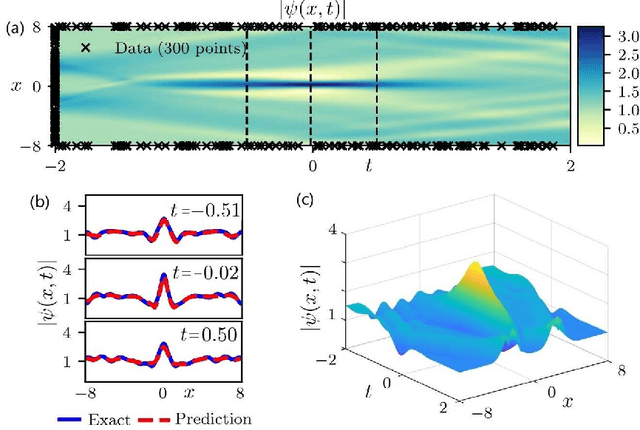
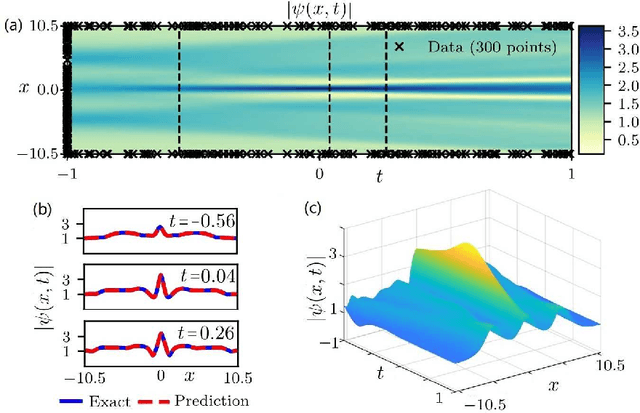
The physics-informed neural networks (PINNs) can be used to deep learn the nonlinear partial differential equations and other types of physical models. In this paper, we use the multi-layer PINN deep learning method to study the data-driven rogue wave solutions of the defocusing nonlinear Schr\"odinger (NLS) equation with the time-dependent potential by considering several initial conditions such as the rogue wave, Jacobi elliptic cosine function, two-Gaussian function, or three-hyperbolic-secant function, and periodic boundary conditions. Moreover, the multi-layer PINN algorithm can also be used to learn the parameter in the defocusing NLS equation with the time-dependent potential under the sense of the rogue wave solution. These results will be useful to further discuss the rogue wave solutions of the defocusing NLS equation with a potential in the study of deep learning neural networks.
Safe Policy Synthesis in Multi-Agent POMDPs via Discrete-Time Barrier Functions
Mar 19, 2019



A multi-agent partially observable Markov decision process (MPOMDP) is a modeling paradigm used for high-level planning of heterogeneous autonomous agents subject to uncertainty and partial observation. Despite their modeling efficiency, MPOMDPs have not received significant attention in safety-critical settings. In this paper, we use barrier functions to design policies for MPOMDPs that ensure safety. Notably, our method does not rely on discretization of the belief space, or finite memory. To this end, we formulate sufficient and necessary conditions for the safety of a given set based on discrete-time barrier functions (DTBFs) and we demonstrate that our formulation also allows for Boolean compositions of DTBFs for representing more complicated safe sets. We show that the proposed method can be implemented online by a sequence of one-step greedy algorithms as a standalone safe controller or as a safety-filter given a nominal planning policy. We illustrate the efficiency of the proposed methodology based on DTBFs using a high-fidelity simulation of heterogeneous robots.
Breast Mass Detection with Faster R-CNN: On the Feasibility of Learning from Noisy Annotations
Apr 25, 2021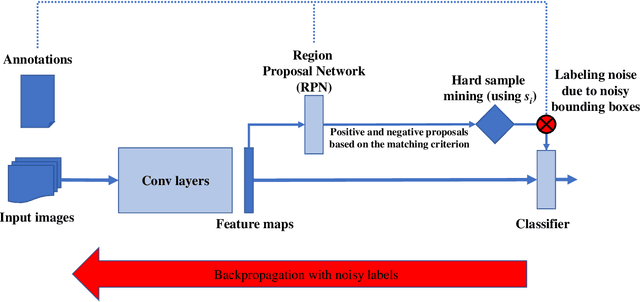

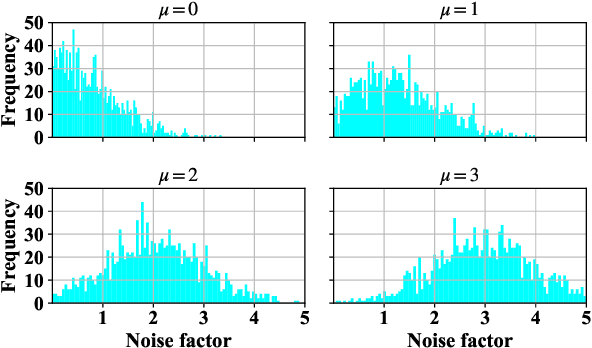
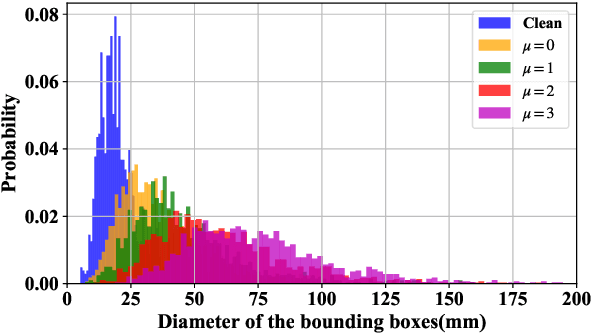
In this work we study the impact of noise on the training of object detection networks for the medical domain, and how it can be mitigated by improving the training procedure. Annotating large medical datasets for training data-hungry deep learning models is expensive and time consuming. Leveraging information that is already collected in clinical practice, in the form of text reports, bookmarks or lesion measurements would substantially reduce this cost. Obtaining precise lesion bounding boxes through automatic mining procedures, however, is difficult. We provide here a quantitative evaluation of the effect of bounding box coordinate noise on the performance of Faster R-CNN object detection networks for breast mass detection. Varying degrees of noise are simulated by randomly modifying the bounding boxes: in our experiments, bounding boxes could be enlarged up to six times the original size. The noise is injected in the CBIS-DDSM collection, a well curated public mammography dataset for which accurate lesion location is available. We show how, due to an imperfect matching between the ground truth and the network bounding box proposals, the noise is propagated during training and reduces the ability of the network to correctly classify lesions from background. When using the standard Intersection over Union criterion, the area under the FROC curve decreases by up to 9%. A novel matching criterion is proposed to improve tolerance to noise.
DHASP: Differentiable Hearing Aid Speech Processing
Mar 15, 2021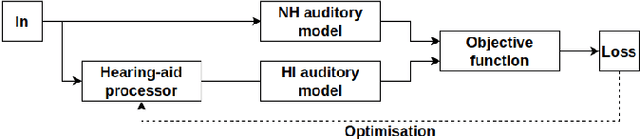

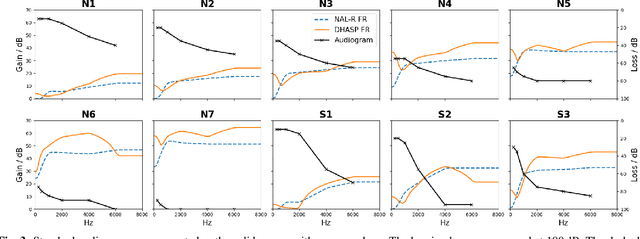
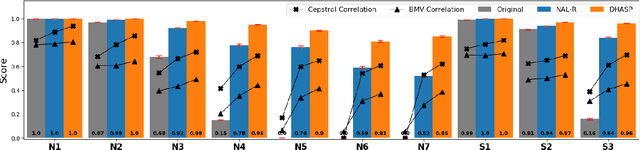
Hearing aids are expected to improve speech intelligibility for listeners with hearing impairment. An appropriate amplification fitting tuned for the listener's hearing disability is critical for good performance. The developments of most prescriptive fittings are based on data collected in subjective listening experiments, which are usually expensive and time-consuming. In this paper, we explore an alternative approach to finding the optimal fitting by introducing a hearing aid speech processing framework, in which the fitting is optimised in an automated way using an intelligibility objective function based on the HASPI physiological auditory model. The framework is fully differentiable, thus can employ the back-propagation algorithm for efficient, data-driven optimisation. Our initial objective experiments show promising results for noise-free speech amplification, where the automatically optimised processors outperform one of the well recognised hearing aid prescriptions.