 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MGSampler: An Explainable Sampling Strategy for Video Action Recognition
Apr 20, 2021

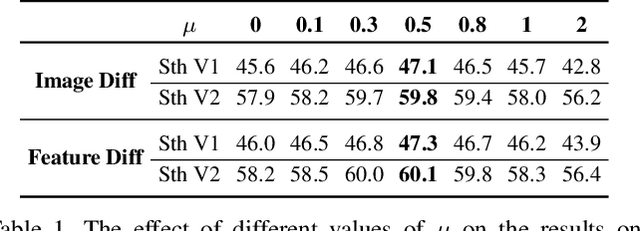
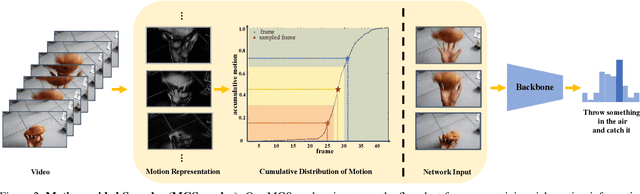
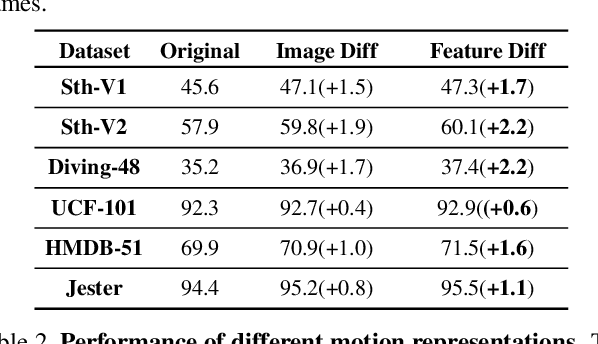
Frame sampling is a fundamental problem in video action recognition due to the essential redundancy in time and limited computation resources. The existing sampling strategy often employs a fixed frame selection and lacks the flexibility to deal with complex variations in videos. In this paper, we present an explainable, adaptive, and effective frame sampler, called Motion-guided Sampler (MGSampler). Our basic motivation is that motion is an important and universal signal that can drive us to select frames from videos adaptively. Accordingly, we propose two important properties in our MGSampler design: motion sensitive and motion uniform. First, we present two different motion representations to enable us to efficiently distinguish the motion salient frames from the background. Then, we devise a motion-uniform sampling strategy based on the cumulative motion distribution to ensure the sampled frames evenly cover all the important frames with high motion saliency. Our MGSampler yields a new principled and holistic sample scheme, that could be incorporated into any existing video architecture. Experiments on five benchmarks demonstrate the effectiveness of our MGSampler over previously fixed sampling strategies, and also its generalization power across different backbones, video models, and datasets.
DynO: Dynamic Onloading of Deep Neural Networks from Cloud to Device
Apr 20, 2021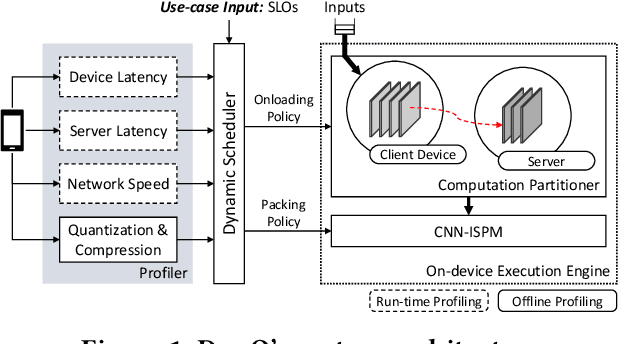

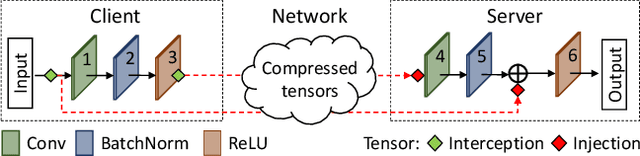
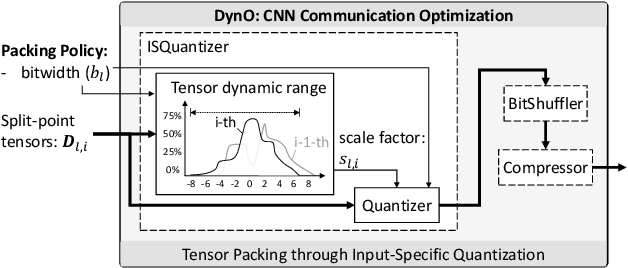
Recently, there has been an explosive growth of mobile and embedded applications using convolutional neural networks(CNNs). To alleviate their excessive computational demands, developers have traditionally resorted to cloud offloading, inducing high infrastructure costs and a strong dependence on networking conditions. On the other end, the emergence of powerful SoCs is gradually enabling on-device execution. Nonetheless, low- and mid-tier platforms still struggle to run state-of-the-art CNNs sufficiently. In this paper, we present DynO, a distributed inference framework that combines the best of both worlds to address several challenges, such as device heterogeneity, varying bandwidth and multi-objective requirements. Key components that enable this are its novel CNN-specific data packing method, which exploits the variability of precision needs in different parts of the CNN when onloading computation, and its novel scheduler that jointly tunes the partition point and transferred data precision at run time to adapt inference to its execution environment. Quantitative evaluation shows that DynO outperforms the current state-of-the-art, improving throughput by over an order of magnitude over device-only execution and up to 7.9x over competing CNN offloading systems, with up to 60x less data transferred.
Abstraction, Validation, and Generalization for Explainable Artificial Intelligence
May 16, 2021
Neural network architectures are achieving superhuman performance on an expanding range of tasks. To effectively and safely deploy these systems, their decision-making must be understandable to a wide range of stakeholders. Methods to explain AI have been proposed to answer this challenge, but a lack of theory impedes the development of systematic abstractions which are necessary for cumulative knowledge gains. We propose Bayesian Teaching as a framework for unifying explainable AI (XAI) by integrating machine learning and human learning. Bayesian Teaching formalizes explanation as a communication act of an explainer to shift the beliefs of an explainee. This formalization decomposes any XAI method into four components: (1) the inference to be explained, (2) the explanatory medium, (3) the explainee model, and (4) the explainer model. The abstraction afforded by Bayesian Teaching to decompose any XAI method elucidates the invariances among them. The decomposition of XAI systems enables modular validation, as each of the first three components listed can be tested semi-independently. This decomposition also promotes generalization through recombination of components from different XAI systems, which facilitates the generation of novel variants. These new variants need not be evaluated one by one provided that each component has been validated, leading to an exponential decrease in development time. Finally, by making the goal of explanation explicit, Bayesian Teaching helps developers to assess how suitable an XAI system is for its intended real-world use case. Thus, Bayesian Teaching provides a theoretical framework that encourages systematic, scientific investigation of XAI.
Stay Together: A System for Single and Split-antecedent Anaphora Resolution
Apr 12, 2021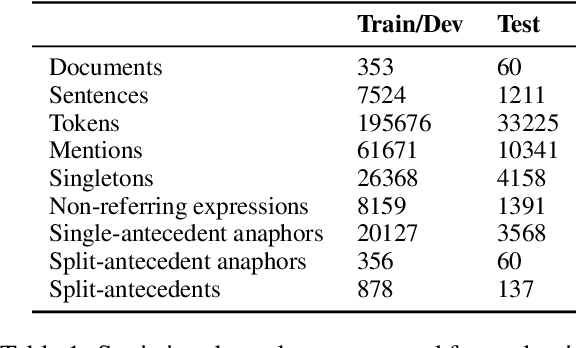
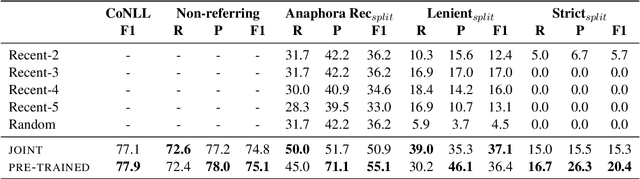
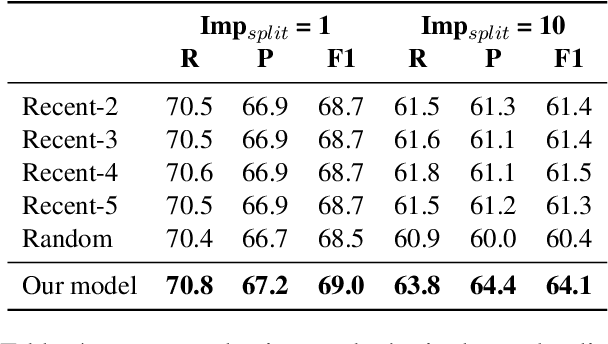
The state-of-the-art on basic, single-antecedent anaphora has greatly improved in recent years. Researchers have therefore started to pay more attention to more complex cases of anaphora such as split-antecedent anaphora, as in Time-Warner is considering a legal challenge to Telecommunications Inc's plan to buy half of Showtime Networks Inc-a move that could lead to all-out war between the two powerful companies. Split-antecedent anaphora is rarer and more complex to resolve than single-antecedent anaphora; as a result, it is not annotated in many datasets designed to test coreference, and previous work on resolving this type of anaphora was carried out in unrealistic conditions that assume gold mentions and/or gold split-antecedent anaphors are available. These systems also focus on split-antecedent anaphors only. In this work, we introduce a system that resolves both single and split-antecedent anaphors, and evaluate it in a more realistic setting that uses predicted mentions. We also start addressing the question of how to evaluate single and split-antecedent anaphors together using standard coreference evaluation metrics.
Location Trace Privacy Under Conditional Priors
Feb 23, 2021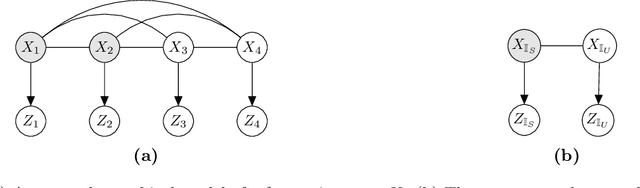
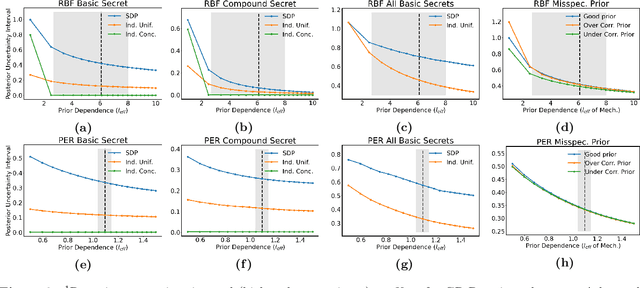
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a R\'enyi divergence based privacy framework for bounding expected privacy loss for conditionally dependent data. Additionally, we demonstrate an algorithm for achieving this privacy under Gaussian process conditional priors. This framework both exemplifies why conditionally dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user's trace.
RANSIC: Fast and Highly Robust Estimation for Rotation Search and Point Cloud Registration using Invariant Compatibility
Apr 20, 2021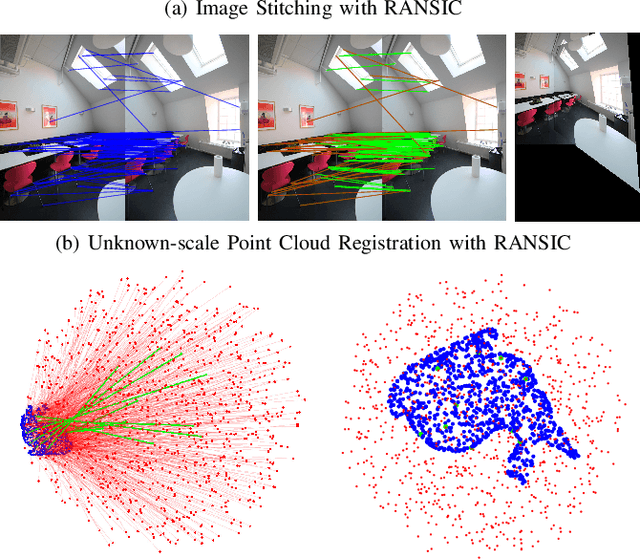
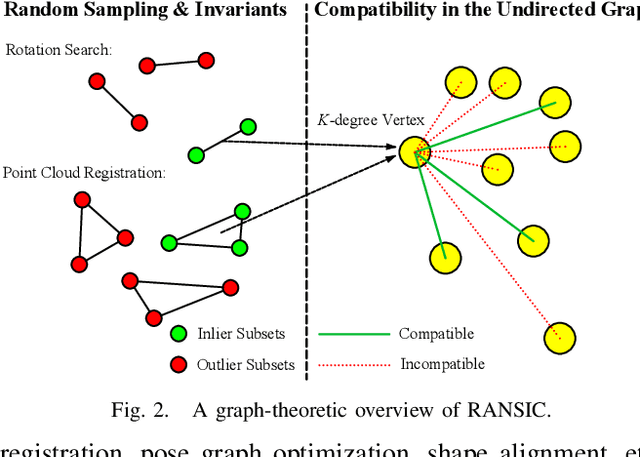
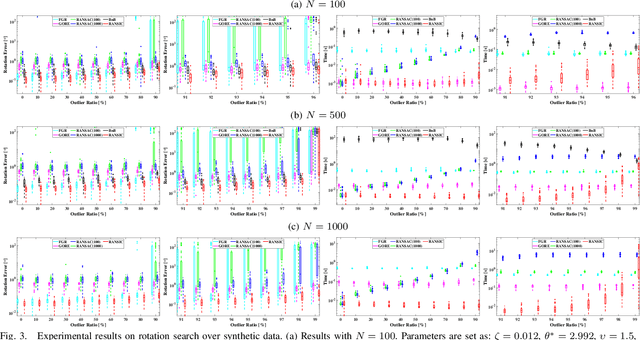
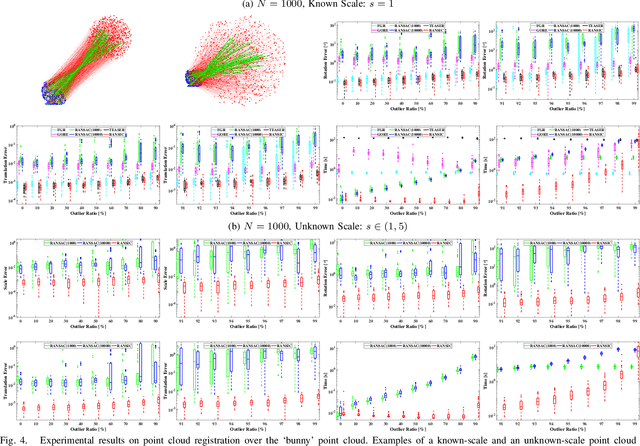
Correspondence-based rotation search and point cloud registration are two fundamental problems in robotics and computer vision. However, the presence of outliers, sometimes even occupying the great majority of the putative correspondences, can make many existing algorithms either fail or have very high computational cost. In this paper, we present RANSIC (RANdom Sampling with Invariant Compatibility), a fast and highly robust method applicable to both problems based on a new paradigm combining random sampling with invariance and compatibility. Generally, RANSIC starts with randomly selecting small subsets from the correspondence set, then seeks potential inliers as graph vertices from the random subsets through the compatibility tests of invariants established in each problem, and eventually returns the eligible inliers when there exists at least one K-degree vertex (K is automatically updated depending on the problem) and the residual errors satisfy a certain termination condition at the same time. In multiple synthetic and real experiments, we demonstrate that RANSIC is fast for use, robust against over 95% outliers, and also able to recall approximately 100% inliers, outperforming other state-of-the-art solvers for both the rotation search and the point cloud registration problems.
Neural Camera Simulators
Apr 12, 2021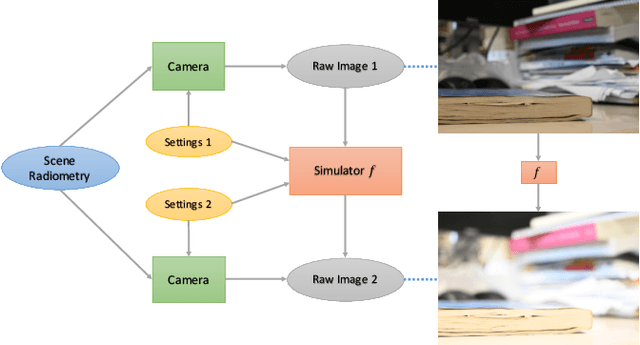

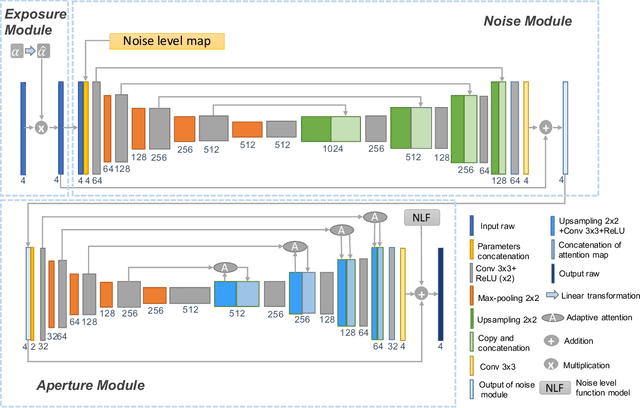
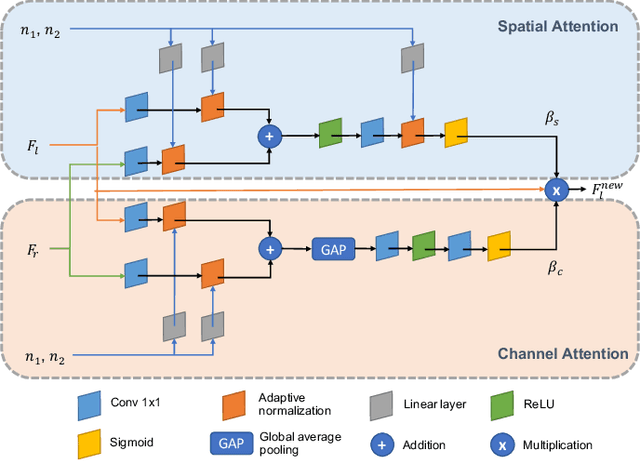
We present a controllable camera simulator based on deep neural networks to synthesize raw image data under different camera settings, including exposure time, ISO, and aperture. The proposed simulator includes an exposure module that utilizes the principle of modern lens designs for correcting the luminance level. It also contains a noise module using the noise level function and an aperture module with adaptive attention to simulate the side effects on noise and defocus blur. To facilitate the learning of a simulator model, we collect a dataset of the 10,000 raw images of 450 scenes with different exposure settings. Quantitative experiments and qualitative comparisons show that our approach outperforms relevant baselines in raw data synthesize on multiple cameras. Furthermore, the camera simulator enables various applications, including large-aperture enhancement, HDR, auto exposure, and data augmentation for training local feature detectors. Our work represents the first attempt to simulate a camera sensor's behavior leveraging both the advantage of traditional raw sensor features and the power of data-driven deep learning.
BeamLearning: an end-to-end Deep Learning approach for the angular localization of sound sources using raw multichannel acoustic pressure data
Apr 27, 2021Sound sources localization using multichannel signal processing has been a subject of active research for decades. In recent years, the use of deep learning in audio signal processing has allowed to drastically improve performances for machine hearing. This has motivated the scientific community to also develop machine learning strategies for source localization applications. In this paper, we present BeamLearning, a multi-resolution deep learning approach that allows to encode relevant information contained in unprocessed time domain acoustic signals captured by microphone arrays. The use of raw data aims at avoiding simplifying hypothesis that most traditional model-based localization methods rely on. Benefits of its use are shown for realtime sound source 2D-localization tasks in reverberating and noisy environments. Since supervised machine learning approaches require large-sized, physically realistic, precisely labelled datasets, we also developed a fast GPU-based computation of room impulse responses using fractional delays for image source models. A thorough analysis of the network representation and extensive performance tests are carried out using the BeamLearning network with synthetic and experimental datasets. Obtained results demonstrate that the BeamLearning approach significantly outperforms the wideband MUSIC and SRP-PHAT methods in terms of localization accuracy and computational efficiency in presence of heavy measurement noise and reverberation.
Comparing Popular Simulation Environments in the Scope of Robotics and Reinforcement Learning
Mar 08, 2021

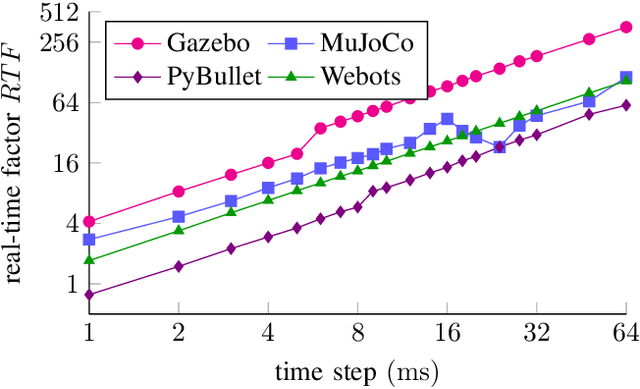
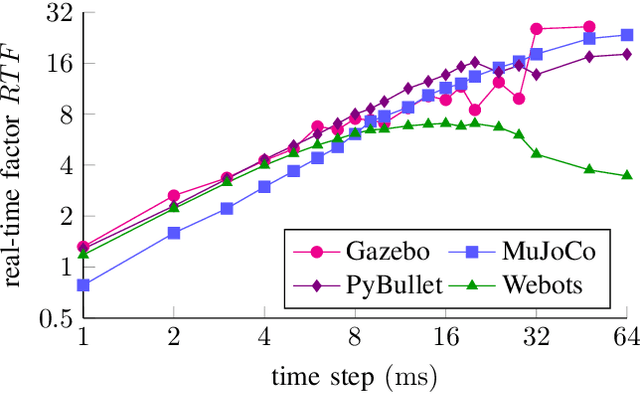
This letter compares the performance of four different, popular simulation environments for robotics and reinforcement learning (RL) through a series of benchmarks. The benchmarked scenarios are designed carefully with current industrial applications in mind. Given the need to run simulations as fast as possible to reduce the real-world training time of the RL agents, the comparison includes not only different simulation environments but also different hardware configurations, ranging from an entry-level notebook up to a dual CPU high performance server. We show that the chosen simulation environments benefit the most from single core performance. Yet, using a multi core system, multiple simulations could be run in parallel to increase the performance.
Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning
Dec 04, 2020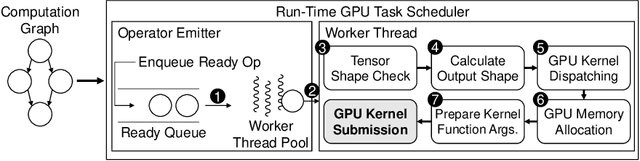
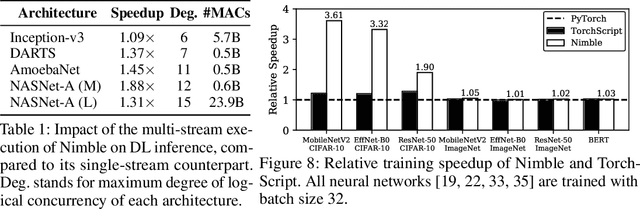
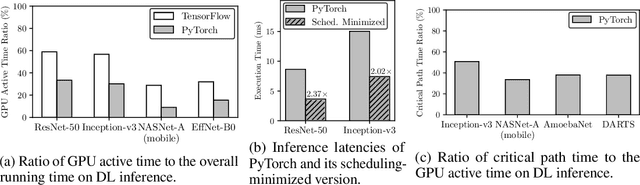
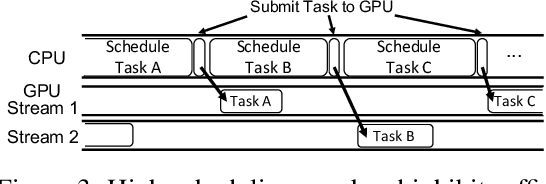
Deep learning (DL) frameworks take advantage of GPUs to improve the speed of DL inference and training. Ideally, DL frameworks should be able to fully utilize the computation power of GPUs such that the running time depends on the amount of computation assigned to GPUs. Yet, we observe that in scheduling GPU tasks, existing DL frameworks suffer from inefficiencies such as large scheduling overhead and unnecessary serial execution. To this end, we propose Nimble, a DL execution engine that runs GPU tasks in parallel with minimal scheduling overhead. Nimble introduces a novel technique called ahead-of-time (AoT) scheduling. Here, the scheduling procedure finishes before executing the GPU kernel, thereby removing most of the scheduling overhead during run time. Furthermore, Nimble automatically parallelizes the execution of GPU tasks by exploiting multiple GPU streams in a single GPU. Evaluation on a variety of neural networks shows that compared to PyTorch, Nimble speeds up inference and training by up to 22.34$\times$ and 3.61$\times$, respectively. Moreover, Nimble outperforms state-of-the-art inference systems, TensorRT and TVM, by up to 2.81$\times$ and 1.70$\times$, respectively.