 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HexCNN: A Framework for Native Hexagonal Convolutional Neural Networks
Jan 25, 2021

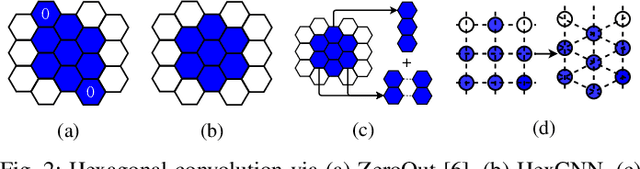
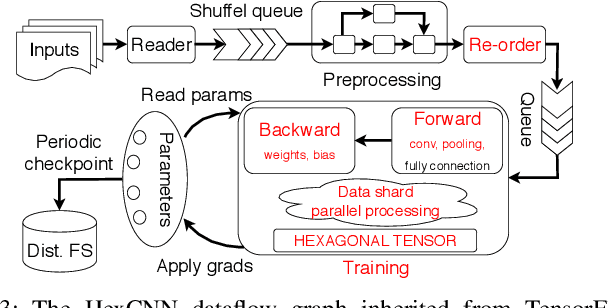
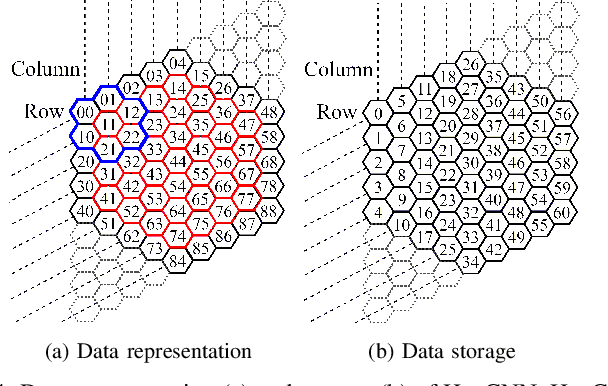
Hexagonal CNN models have shown superior performance in applications such as IACT data analysis and aerial scene classification due to their better rotation symmetry and reduced anisotropy. In order to realize hexagonal processing, existing studies mainly use the ZeroOut method to imitate hexagonal processing, which causes substantial memory and computation overheads. We address this deficiency with a novel native hexagonal CNN framework named HexCNN. HexCNN takes hexagon-shaped input and performs forward and backward propagation on the original form of the input based on hexagon-shaped filters, hence avoiding computation and memory overheads caused by imitation. For applications with rectangle-shaped input but require hexagonal processing, HexCNN can be applied by padding the input into hexagon-shape as preprocessing. In this case, we show that the time and space efficiency of HexCNN still outperforms existing hexagonal CNN methods substantially. Experimental results show that compared with the state-of-the-art models, which imitate hexagonal processing but using rectangle-shaped filters, HexCNN reduces the training time by up to 42.2%. Meanwhile, HexCNN saves the memory space cost by up to 25% and 41.7% for loading the input and performing convolution, respectively.
RIANN -- A Robust Neural Network Outperforms Attitude Estimation Filters
May 05, 2021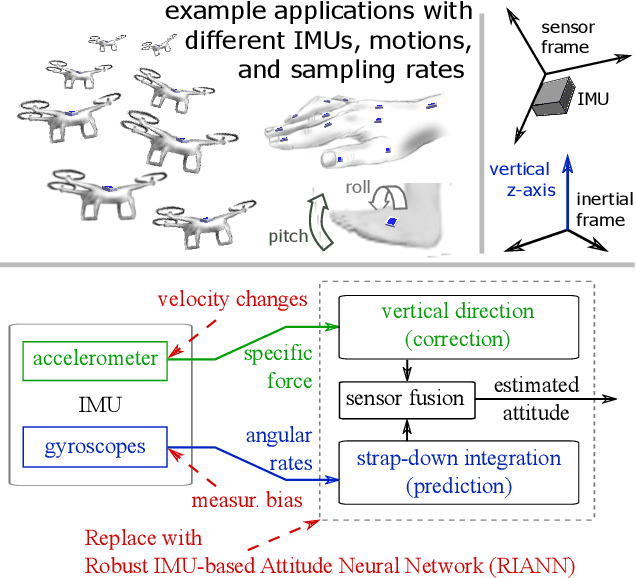
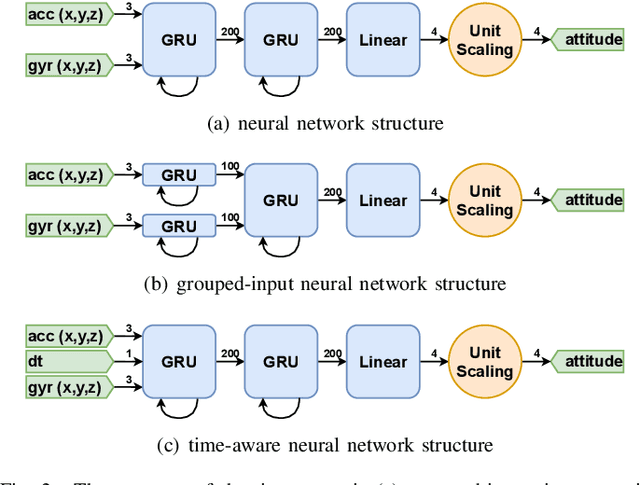
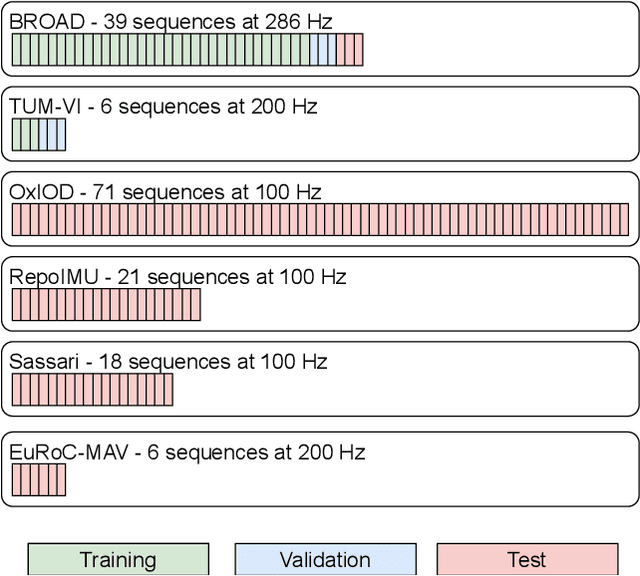
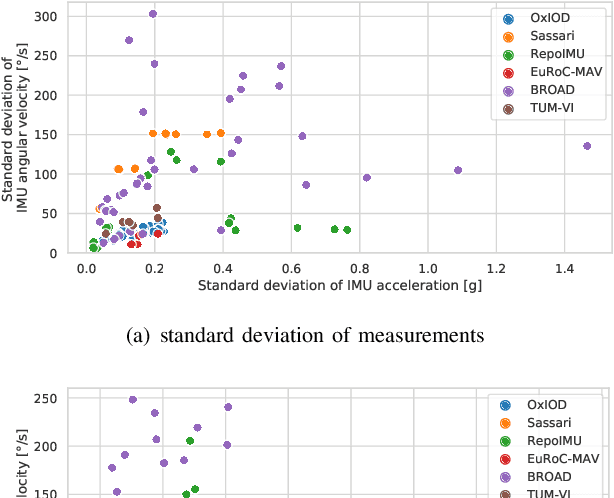
Inertial-sensor-based attitude estimation is a crucial technology in various applications, from human motion tracking to autonomous aerial and ground vehicles. Application scenarios differ in characteristics of the performed motion, presence of disturbances, and environmental conditions. Since state-of-the-art attitude estimators do not generalize well over these characteristics, their parameters must be tuned for the individual motion characteristics and circumstances. We propose RIANN, a real-time-capable neural network for robust IMU-based attitude estimation, which generalizes well across different motion dynamics, environments, and sampling rates, without the need for application-specific adaptations. We exploit two publicly available datasets for the method development and the training, and we add four completely different datasets for evaluation of the trained neural network in three different test scenarios with varying practical relevance. Results show that RIANN performs at least as well as state-of-the-art attitude estimation filters and outperforms them in several cases, even if the filter is tuned on the very same test dataset itself while RIANN has never seen data from that dataset, from the specific application, the same sensor hardware, or the same sampling frequency before. RIANN is expected to enable plug-and-play solutions in numerous applications, especially when accuracy is crucial but no ground-truth data is available for tuning or when motion and disturbance characteristics are uncertain. We made RIANN publicly available.
A Deep Transfer Learning-based Edge Computing Method for Home Health Monitoring
Apr 28, 2021
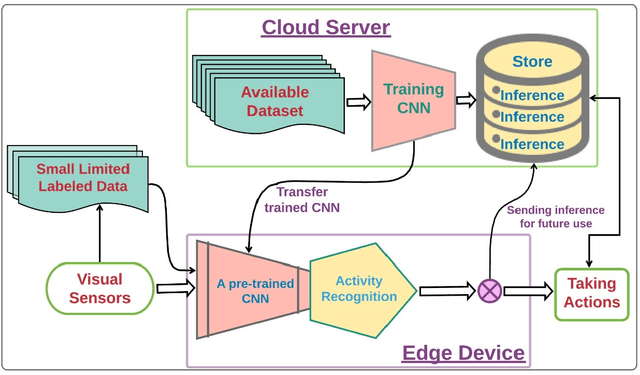
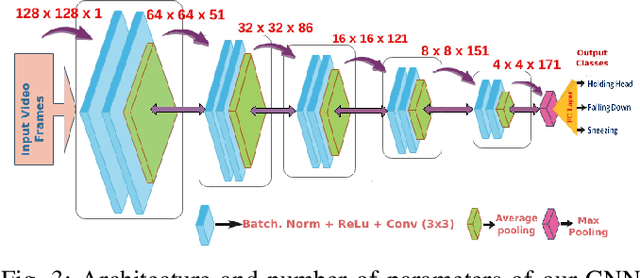
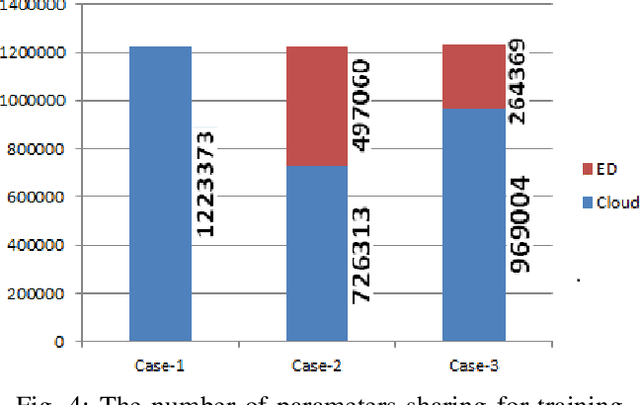
The health-care gets huge stress in a pandemic or epidemic situation. Some diseases such as COVID-19 that causes a pandemic is highly spreadable from an infected person to others. Therefore, providing health services at home for non-critical infected patients with isolation shall assist to mitigate this kind of stress. In addition, this practice is also very useful for monitoring the health-related activities of elders who live at home. The home health monitoring, a continuous monitoring of a patient or elder at home using visual sensors is one such non-intrusive sub-area of health services at home. In this article, we propose a transfer learning-based edge computing method for home health monitoring. Specifically, a pre-trained convolutional neural network-based model can leverage edge devices with a small amount of ground-labeled data and fine-tuning method to train the model. Therefore, on-site computing of visual data captured by RGB, depth, or thermal sensor could be possible in an affordable way. As a result, raw data captured by these types of sensors is not required to be sent outside from home. Therefore, privacy, security, and bandwidth scarcity shall not be issues. Moreover, real-time computing for the above-mentioned purposes shall be possible in an economical way.
* 6 pages, 4 figures. Pre-print copy
VEST: Automatic Feature Engineering for Forecasting
Oct 14, 2020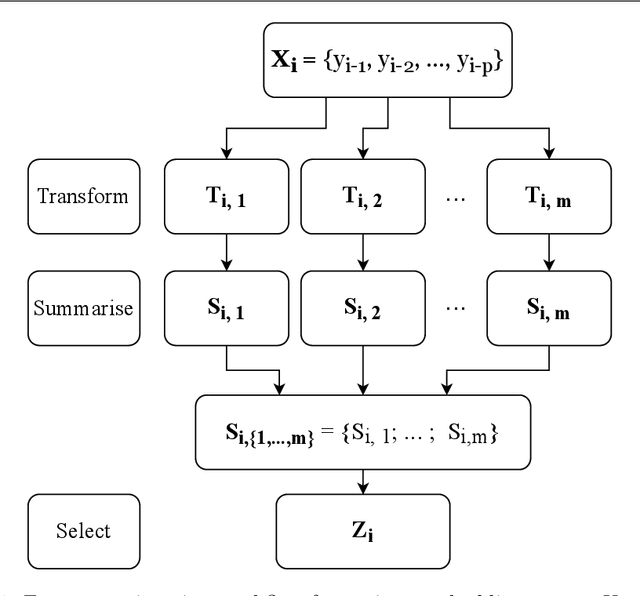

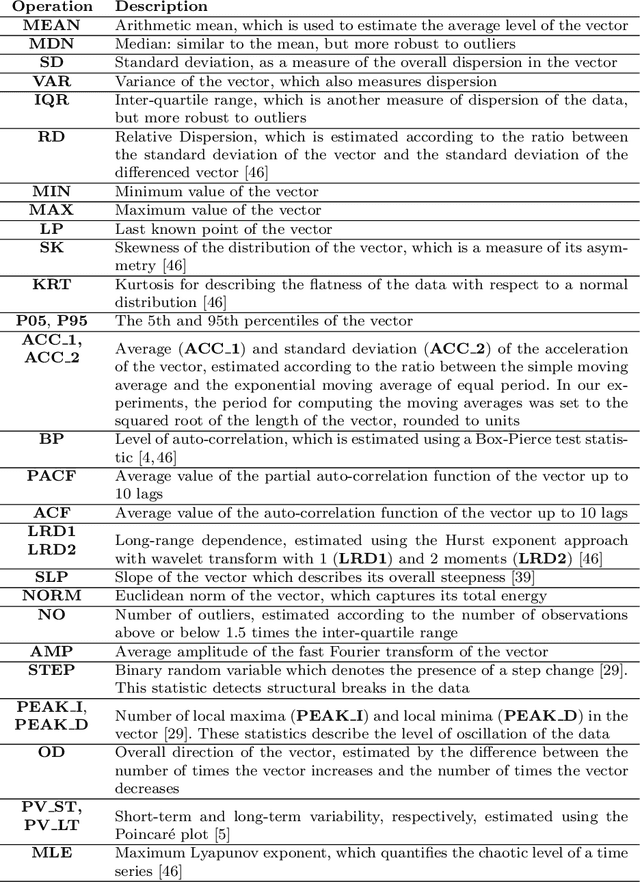
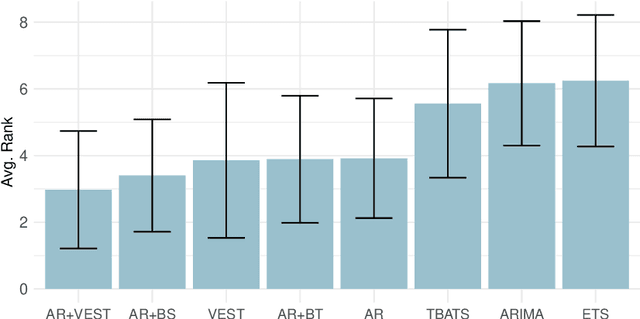
Time series forecasting is a challenging task with applications in a wide range of domains. Auto-regression is one of the most common approaches to address these problems. Accordingly, observations are modelled by multiple regression using their past lags as predictor variables. We investigate the extension of auto-regressive processes using statistics which summarise the recent past dynamics of time series. The result of our research is a novel framework called VEST, designed to perform feature engineering using univariate and numeric time series automatically. The proposed approach works in three main steps. First, recent observations are mapped onto different representations. Second, each representation is summarised by statistical functions. Finally, a filter is applied for feature selection. We discovered that combining the features generated by VEST with auto-regression significantly improves forecasting performance. We provide evidence using 90 time series with high sampling frequency. VEST is publicly available online.
RANSIC: Fast and Highly Robust Estimation for Rotation Search and Point Cloud Registration using Invariant Compatibility
Apr 21, 2021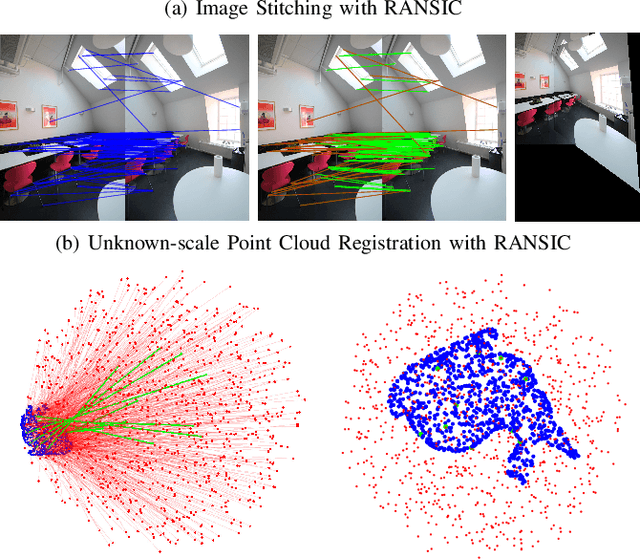
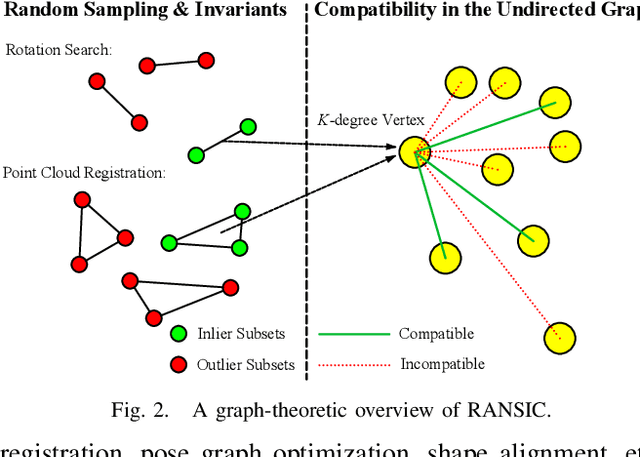
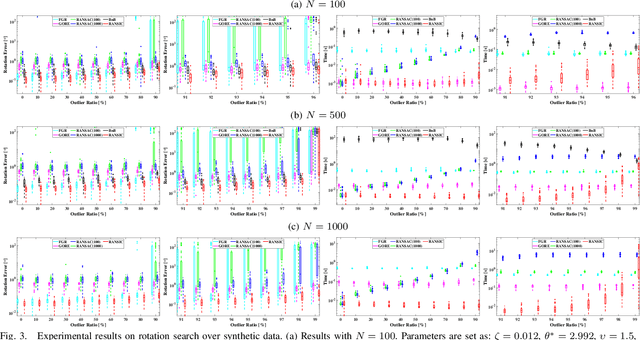
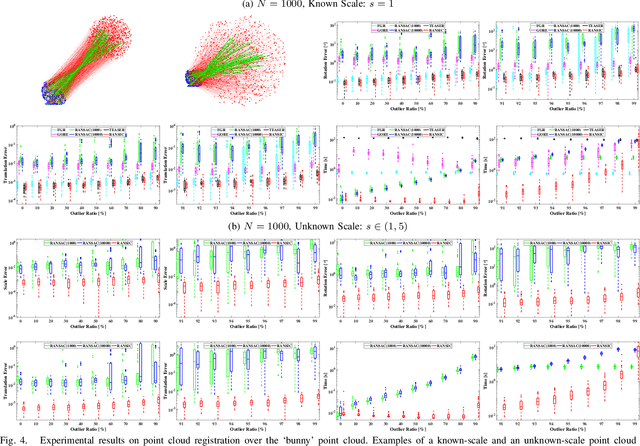
Correspondence-based rotation search and point cloud registration are two fundamental problems in robotics and computer vision. However, the presence of outliers, sometimes even occupying the great majority of the putative correspondences, can make many existing algorithms either fail or have very high computational cost. In this paper, we present RANSIC (RANdom Sampling with Invariant Compatibility), a fast and highly robust method applicable to both problems based on a new paradigm combining random sampling with invariance and compatibility. Generally, RANSIC starts with randomly selecting small subsets from the correspondence set, then seeks potential inliers as graph vertices from the random subsets through the compatibility tests of invariants established in each problem, and eventually returns the eligible inliers when there exists at least one K-degree vertex (K is automatically updated depending on the problem) and the residual errors satisfy a certain termination condition at the same time. In multiple synthetic and real experiments, we demonstrate that RANSIC is fast for use, robust against over 95% outliers, and also able to recall approximately 100% inliers, outperforming other state-of-the-art solvers for both the rotation search and the point cloud registration problems.
Global Convergence of Three-layer Neural Networks in the Mean Field Regime
May 11, 2021In the mean field regime, neural networks are appropriately scaled so that as the width tends to infinity, the learning dynamics tends to a nonlinear and nontrivial dynamical limit, known as the mean field limit. This lends a way to study large-width neural networks via analyzing the mean field limit. Recent works have successfully applied such analysis to two-layer networks and provided global convergence guarantees. The extension to multilayer ones however has been a highly challenging puzzle, and little is known about the optimization efficiency in the mean field regime when there are more than two layers. In this work, we prove a global convergence result for unregularized feedforward three-layer networks in the mean field regime. We first develop a rigorous framework to establish the mean field limit of three-layer networks under stochastic gradient descent training. To that end, we propose the idea of a \textit{neuronal embedding}, which comprises of a fixed probability space that encapsulates neural networks of arbitrary sizes. The identified mean field limit is then used to prove a global convergence guarantee under suitable regularity and convergence mode assumptions, which -- unlike previous works on two-layer networks -- does not rely critically on convexity. Underlying the result is a universal approximation property, natural of neural networks, which importantly is shown to hold at \textit{any} finite training time (not necessarily at convergence) via an algebraic topology argument.
Anomaly Detection on Graph Time Series
Nov 01, 2017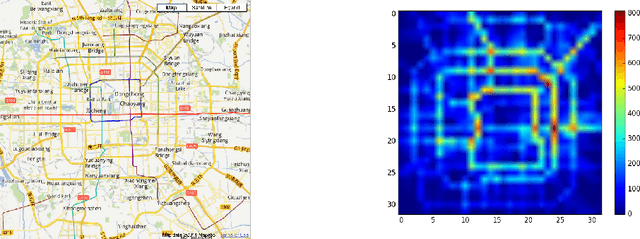
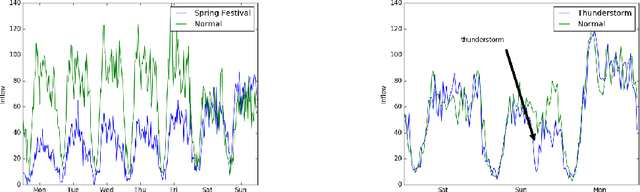
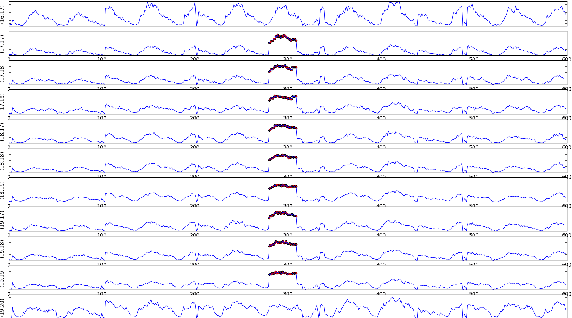
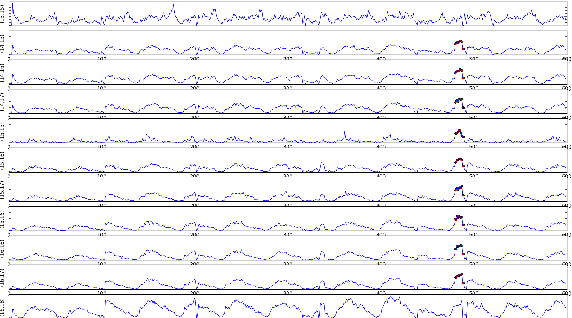
In this paper, we use variational recurrent neural network to investigate the anomaly detection problem on graph time series. The temporal correlation is modeled by the combination of recurrent neural network (RNN) and variational inference (VI), while the spatial information is captured by the graph convolutional network. In order to incorporate external factors, we use feature extractor to augment the transition of latent variables, which can learn the influence of external factors. With the target function as accumulative ELBO, it is easy to extend this model to on-line method. The experimental study on traffic flow data shows the detection capability of the proposed method.
It's always personal: Using Early Exits for Efficient On-Device CNN Personalisation
Feb 02, 2021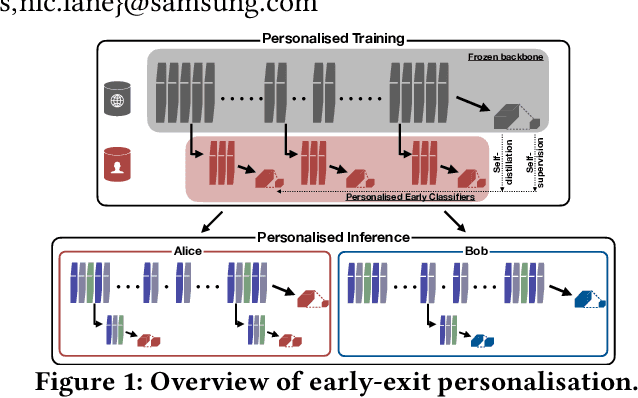
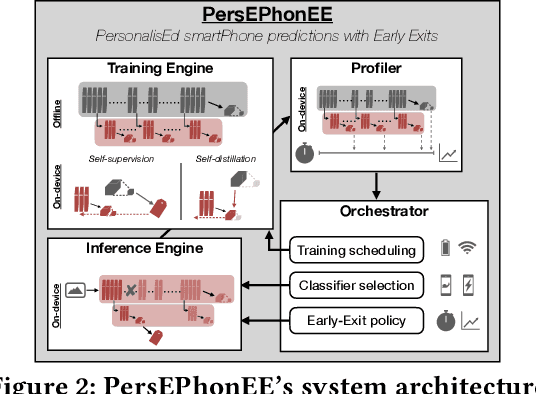
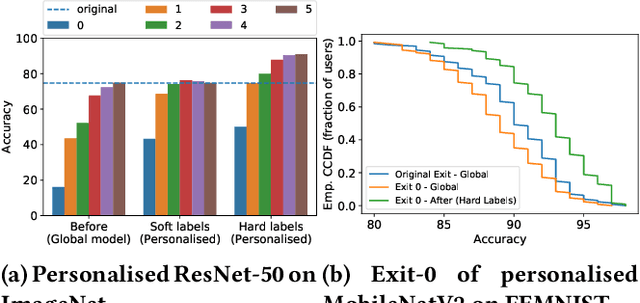
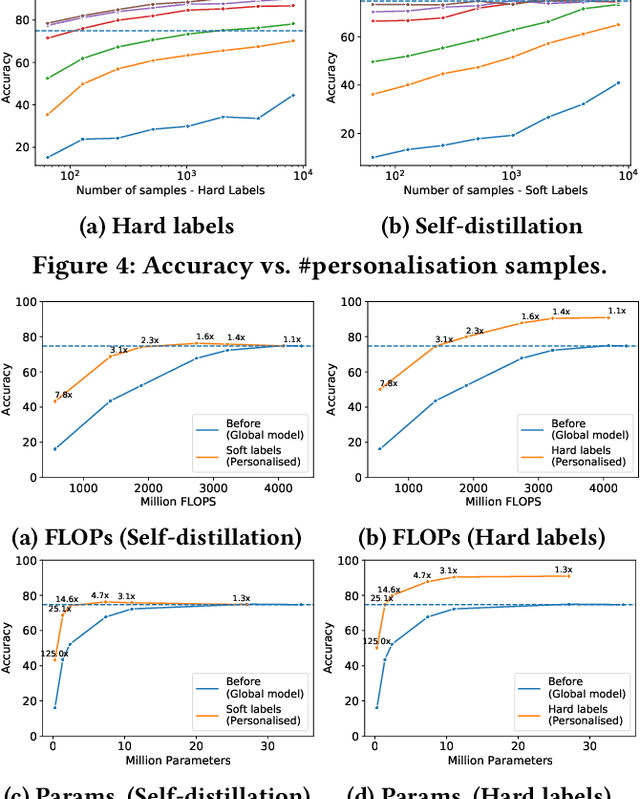
On-device machine learning is becoming a reality thanks to the availability of powerful hardware and model compression techniques. Typically, these models are pretrained on large GPU clusters and have enough parameters to generalise across a wide variety of inputs. In this work, we observe that a much smaller, personalised model can be employed to fit a specific scenario, resulting in both higher accuracy and faster execution. Nevertheless, on-device training is extremely challenging, imposing excessive computational and memory requirements even for flagship smartphones. At the same time, on-device data availability might be limited and samples are most frequently unlabelled. To this end, we introduce PersEPhonEE, a framework that attaches early exits on the model and personalises them on-device. These allow the model to progressively bypass a larger part of the computation as more personalised data become available. Moreover, we introduce an efficient on-device algorithm that trains the early exits in a semi-supervised manner at a fraction of the whole network's personalisation time. Results show that PersEPhonEE boosts accuracy by up to 15.9% while dropping the training cost by up to 2.2x and inference latency by 2.2-3.2x on average for the same accuracy, depending on the availability of labels on-device.
Sleep Apnea and Respiratory Anomaly Detection from a Wearable Band and Oxygen Saturation
Feb 24, 2021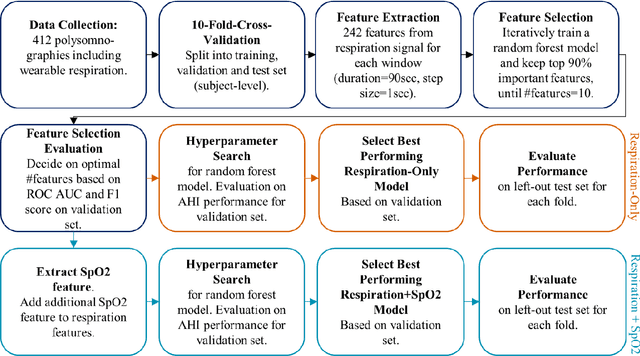
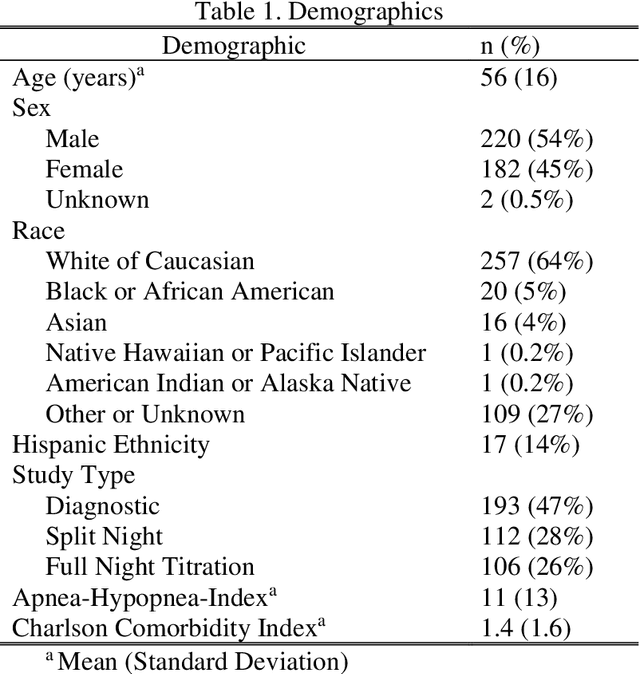
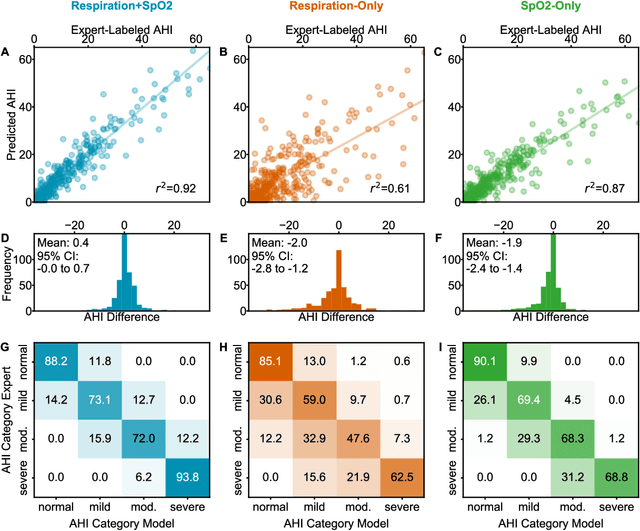
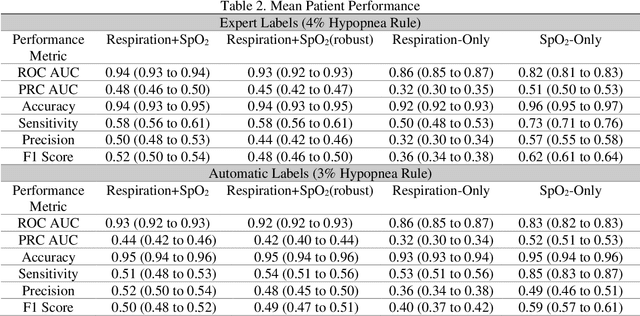
Objective: Sleep related respiratory abnormalities are typically detected using polysomnography. There is a need in general medicine and critical care for a more convenient method to automatically detect sleep apnea from a simple, easy-to-wear device. The objective is to automatically detect abnormal respiration and estimate the Apnea-Hypopnea-Index (AHI) with a wearable respiratory device, compared to an SpO2 signal or polysomnography using a large (n = 412) dataset serving as ground truth. Methods: Simultaneously recorded polysomnographic (PSG) and wearable respiratory effort data were used to train and evaluate models in a cross-validation fashion. Time domain and complexity features were extracted, important features were identified, and a random forest model employed to detect events and predict AHI. Four models were trained: one each using the respiratory features only, a feature from the SpO2 (%)-signal only, and two additional models that use the respiratory features and the SpO2 (%)-feature, one allowing a time lag of 30 seconds between the two signals. Results: Event-based classification resulted in areas under the receiver operating characteristic curves of 0.94, 0.86, 0.82, and areas under the precision-recall curves of 0.48, 0.32, 0.51 for the models using respiration and SpO2, respiration-only, and SpO2-only respectively. Correlation between expert-labelled and predicted AHI was 0.96, 0.78, and 0.93, respectively. Conclusions: A wearable respiratory effort signal with or without SpO2 predicted AHI accurately. Given the large dataset and rigorous testing design, we expect our models are generalizable to evaluating respiration in a variety of environments, such as at home and in critical care.
Efficient and Accurate Gradients for Neural SDEs
May 27, 2021
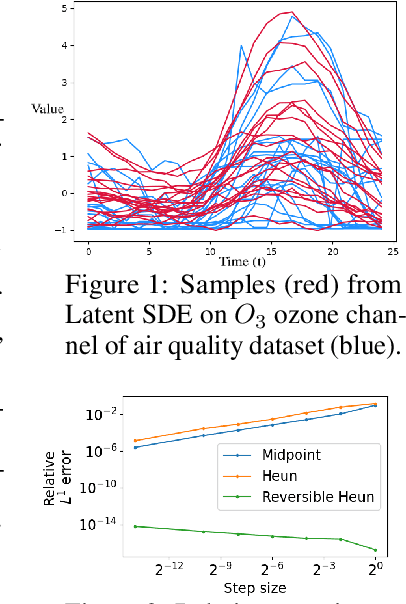

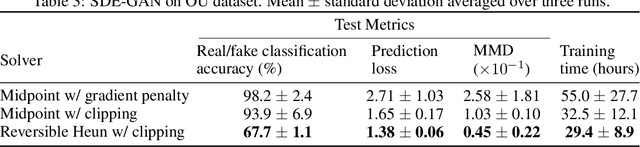
Neural SDEs combine many of the best qualities of both RNNs and SDEs, and as such are a natural choice for modelling many types of temporal dynamics. They offer memory efficiency, high-capacity function approximation, and strong priors on model space. Neural SDEs may be trained as VAEs or as GANs; in either case it is necessary to backpropagate through the SDE solve. In particular this may be done by constructing a backwards-in-time SDE whose solution is the desired parameter gradients. However, this has previously suffered from severe speed and accuracy issues, due to high computational complexity, numerical errors in the SDE solve, and the cost of reconstructing Brownian motion. Here, we make several technical innovations to overcome these issues. First, we introduce the reversible Heun method: a new SDE solver that is algebraically reversible -- which reduces numerical gradient errors to almost zero, improving several test metrics by substantial margins over state-of-the-art. Moreover it requires half as many function evaluations as comparable solvers, giving up to a $1.98\times$ speedup. Next, we introduce the Brownian interval. This is a new and computationally efficient way of exactly sampling and reconstructing Brownian motion; this is in contrast to previous reconstruction techniques that are both approximate and relatively slow. This gives up to a $10.6\times$ speed improvement over previous techniques. After that, when specifically training Neural SDEs as GANs (Kidger et al. 2021), we demonstrate how SDE-GANs may be trained through careful weight clipping and choice of activation function. This reduces computational cost (giving up to a $1.87\times$ speedup), and removes the truncation errors of the double adjoint required for gradient penalty, substantially improving several test metrics. Altogether these techniques offer substantial improvements over the state-of-the-art.