 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A contrastive rule for meta-learning
Apr 04, 2021


Meta-learning algorithms leverage regularities that are present on a set of tasks to speed up and improve the performance of a subsidiary learning process. Recent work on deep neural networks has shown that prior gradient-based learning of meta-parameters can greatly improve the efficiency of subsequent learning. Here, we present a gradient-based meta-learning algorithm based on equilibrium propagation. Instead of explicitly differentiating the learning process, our contrastive meta-learning rule estimates meta-parameter gradients by executing the subsidiary process more than once. This avoids reversing the learning dynamics in time and computing second-order derivatives. In spite of this, and unlike previous first-order methods, our rule recovers an arbitrarily accurate meta-parameter update given enough compute. As such, contrastive meta-learning is a candidate rule for biologically-plausible meta-learning. We establish theoretical bounds on its performance and present experiments on a set of standard benchmarks and neural network architectures.
Attention for Image Registration (AiR): an unsupervised Transformer approach
May 05, 2021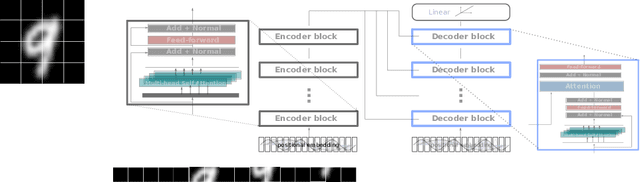

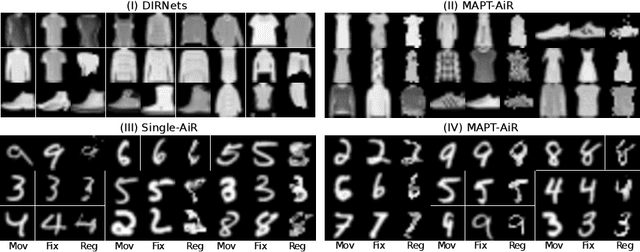
Image registration as an important basis in signal processing task often encounter the problem of stability and efficiency. Non-learning registration approaches rely on the optimization of the similarity metrics between the fix and moving images. Yet, those approaches are usually costly in both time and space complexity. The problem can be worse when the size of the image is large or the deformations between the images are severe. Recently, deep learning, or precisely saying, the convolutional neural network (CNN) based image registration methods have been widely investigated in the research community and show promising effectiveness to overcome the weakness of non-learning based methods. To explore the advanced learning approaches in image registration problem for solving practical issues, we present in this paper a method of introducing attention mechanism in deformable image registration problem. The proposed approach is based on learning the deformation field with a Transformer framework (AiR) that does not rely on the CNN but can be efficiently trained on GPGPU devices also. In a more vivid interpretation: we treat the image registration problem as the same as a language translation task and introducing a Transformer to tackle the problem. Our method learns an unsupervised generated deformation map and is tested on two benchmark datasets. The source code of the AiR will be released at Gitlab.
Fully Gap-Dependent Bounds for Multinomial Logit Bandit
Nov 19, 2020We study the multinomial logit (MNL) bandit problem, where at each time step, the seller offers an assortment of size at most $K$ from a pool of $N$ items, and the buyer purchases an item from the assortment according to a MNL choice model. The objective is to learn the model parameters and maximize the expected revenue. We present (i) an algorithm that identifies the optimal assortment $S^*$ within $\widetilde{O}(\sum_{i = 1}^N \Delta_i^{-2})$ time steps with high probability, and (ii) an algorithm that incurs $O(\sum_{i \notin S^*} K\Delta_i^{-1} \log T)$ regret in $T$ time steps. To our knowledge, our algorithms are the first to achieve gap-dependent bounds that fully depends on the suboptimality gaps of all items. Our technical contributions include an algorithmic framework that relates the MNL-bandit problem to a variant of the top-$K$ arm identification problem in multi-armed bandits, a generalized epoch-based offering procedure, and a layer-based adaptive estimation procedure.
MLDS: A Dataset for Weight-Space Analysis of Neural Networks
Apr 21, 2021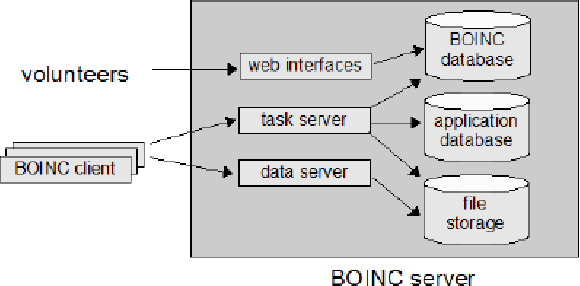


Neural networks are powerful models that solve a variety of complex real-world problems. However, the stochastic nature of training and large number of parameters in a typical neural model makes them difficult to evaluate via inspection. Research shows this opacity can hide latent undesirable behavior, be it from poorly representative training data or via malicious intent to subvert the behavior of the network, and that this behavior is difficult to detect via traditional indirect evaluation criteria such as loss. Therefore, it is time to explore direct ways to evaluate a trained neural model via its structure and weights. In this paper we present MLDS, a new dataset consisting of thousands of trained neural networks with carefully controlled parameters and generated via a global volunteer-based distributed computing platform. This dataset enables new insights into both model-to-model and model-to-training-data relationships. We use this dataset to show clustering of models in weight-space with identical training data and meaningful divergence in weight-space with even a small change to the training data, suggesting that weight-space analysis is a viable and effective alternative to loss for evaluating neural networks.
Passenger Mobility Prediction via Representation Learning for Dynamic Directed and Weighted Graph
Jan 04, 2021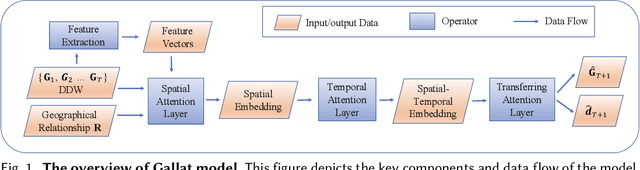
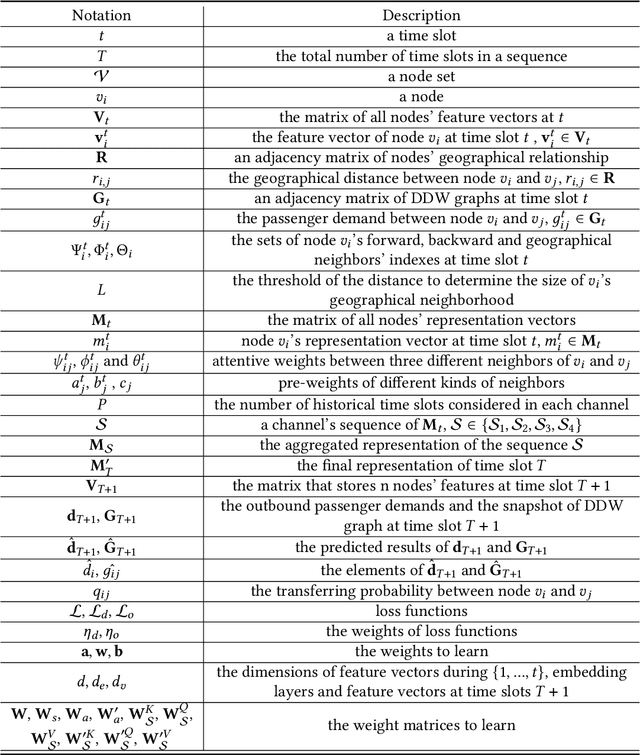
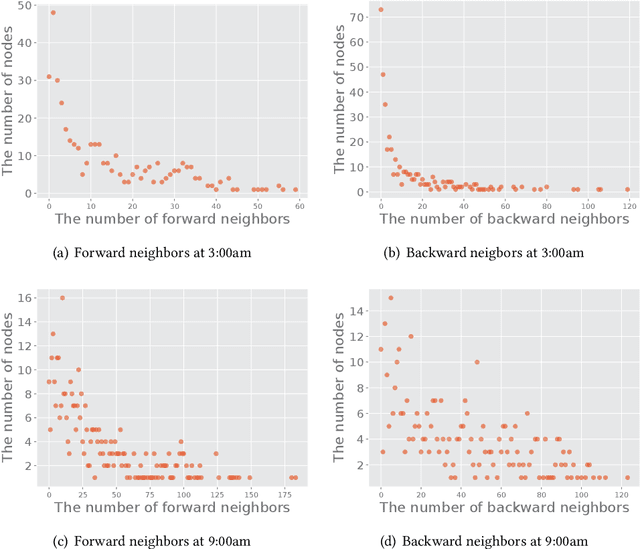
In recent years, ride-hailing services have been increasingly prevalent as they provide huge convenience for passengers. As a fundamental problem, the timely prediction of passenger demands in different regions is vital for effective traffic flow control and route planning. As both spatial and temporal patterns are indispensable passenger demand prediction, relevant research has evolved from pure time series to graph-structured data for modeling historical passenger demand data, where a snapshot graph is constructed for each time slot by connecting region nodes via different relational edges (e.g., origin-destination relationship, geographical distance, etc.). Consequently, the spatiotemporal passenger demand records naturally carry dynamic patterns in the constructed graphs, where the edges also encode important information about the directions and volume (i.e., weights) of passenger demands between two connected regions. However, existing graph-based solutions fail to simultaneously consider those three crucial aspects of dynamic, directed, and weighted (DDW) graphs, leading to limited expressiveness when learning graph representations for passenger demand prediction. Therefore, we propose a novel spatiotemporal graph attention network, namely Gallat (Graph prediction with all attention) as a solution. In Gallat, by comprehensively incorporating those three intrinsic properties of DDW graphs, we build three attention layers to fully capture the spatiotemporal dependencies among different regions across all historical time slots. Moreover, the model employs a subtask to conduct pretraining so that it can obtain accurate results more quickly. We evaluate the proposed model on real-world datasets, and our experimental results demonstrate that Gallat outperforms the state-of-the-art approaches.
Poisoning Attacks on Cyber Attack Detectors for Industrial Control Systems
Dec 23, 2020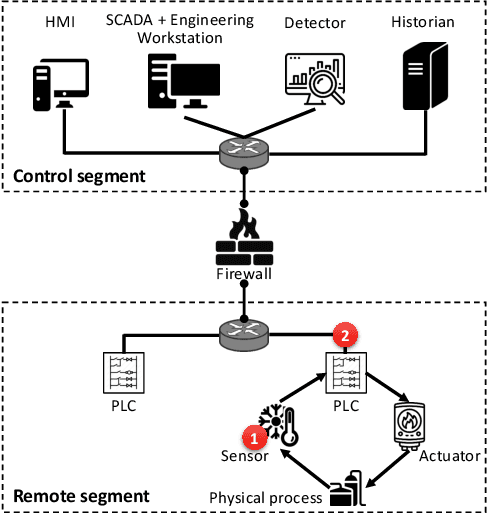
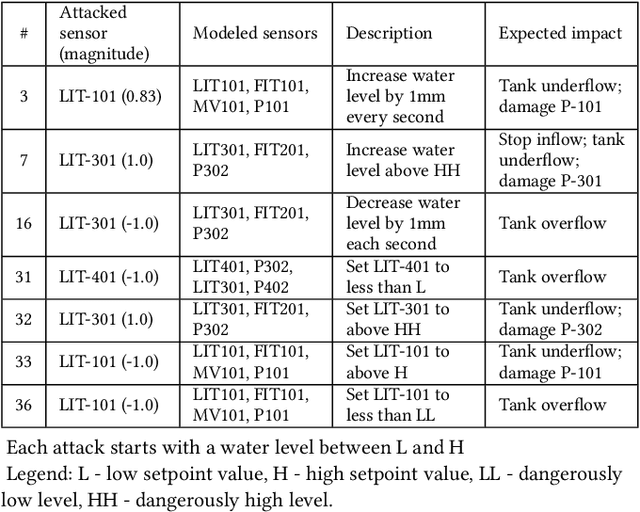
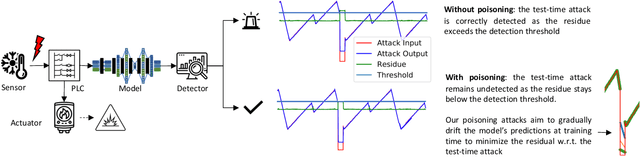

Recently, neural network (NN)-based methods, including autoencoders, have been proposed for the detection of cyber attacks targeting industrial control systems (ICSs). Such detectors are often retrained, using data collected during system operation, to cope with the natural evolution (i.e., concept drift) of the monitored signals. However, by exploiting this mechanism, an attacker can fake the signals provided by corrupted sensors at training time and poison the learning process of the detector such that cyber attacks go undetected at test time. With this research, we are the first to demonstrate such poisoning attacks on ICS cyber attack online NN detectors. We propose two distinct attack algorithms, namely, interpolation- and back-gradient based poisoning, and demonstrate their effectiveness on both synthetic and real-world ICS data. We also discuss and analyze some potential mitigation strategies.
Automatic Forecasting using Gaussian Processes
Sep 17, 2020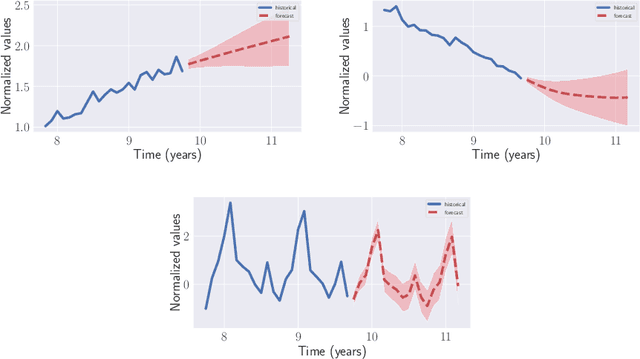
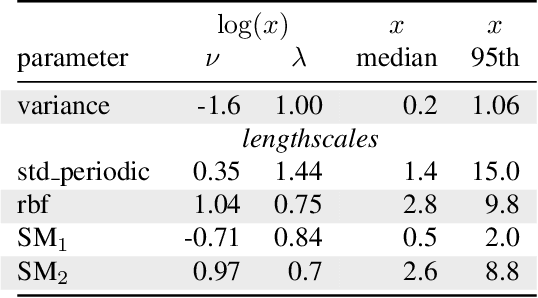
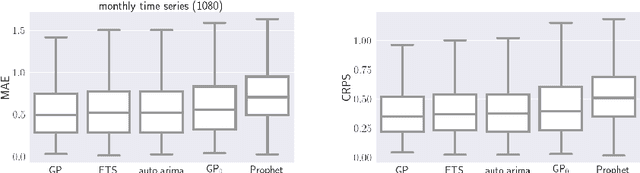
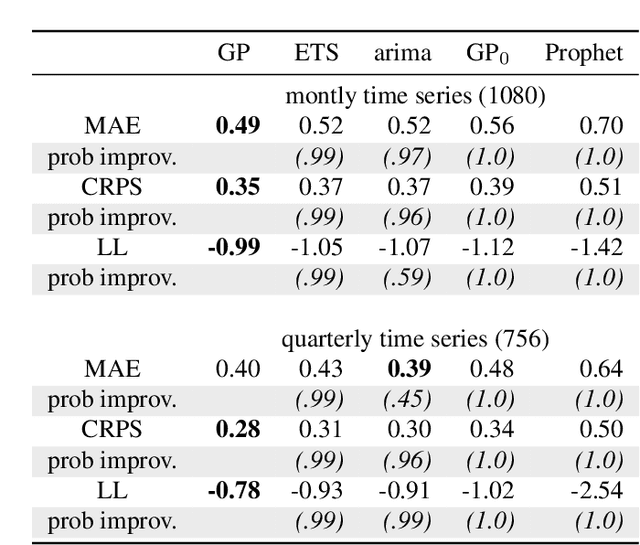
Automatic forecasting is the task of receiving a time series and returning a forecast for the next time steps without any human intervention. We propose an approach for automatic forecasting based on Gaussian Processes (GPs). So far, the main limits of GPs on this task have been the lack of a criterion for the selection of the kernel and the long times required for training different competing kernels. We design a fixed additive kernel, which contains the components needed to model most time series. During training the unnecessary components are made irrelevant by automatic relevance determination. We assign priors to each hyperparameter. We design the priors by analyzing a separate set of time series through a hierarchical GP. The resulting model performs very well on different types of time series, being competitive or outperforming the state-of-the-art approaches.Thanks to the priors, we reliably estimate the parameters with a single restart; this speedup makes the model efficient to train and suitable for processing a large number of time series.
SAINT+: Integrating Temporal Features for EdNet Correctness Prediction
Oct 19, 2020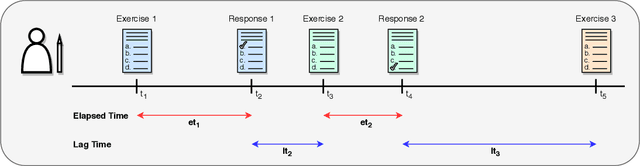

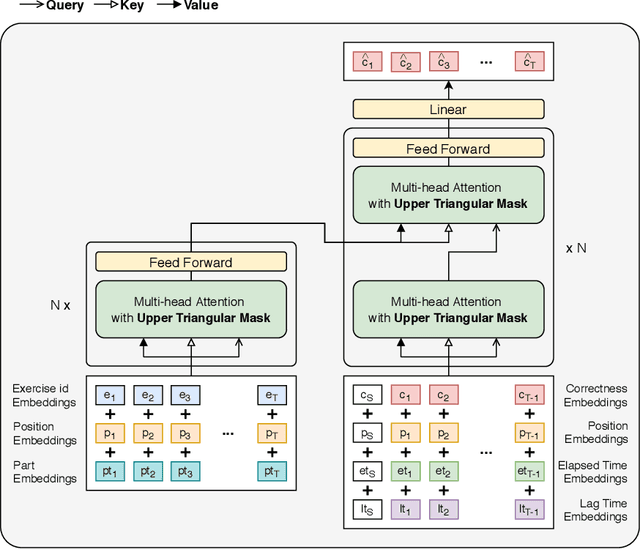
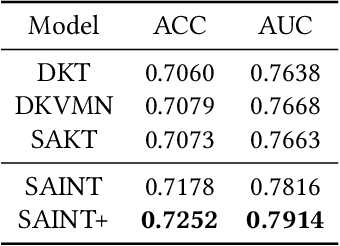
We propose SAINT+, a successor of SAINT which is a Transformer based knowledge tracing model that separately processes exercise information and student response information. Following the architecture of SAINT, SAINT+ has an encoder-decoder structure where the encoder applies self-attention layers to a stream of exercise embeddings, and the decoder alternately applies self-attention layers and encoder-decoder attention layers to streams of response embeddings and encoder output. Moreover, SAINT+ incorporates two temporal feature embeddings into the response embeddings: elapsed time, the time taken for a student to answer, and lag time, the time interval between adjacent learning activities. We empirically evaluate the effectiveness of SAINT+ on EdNet, the largest publicly available benchmark dataset in the education domain. Experimental results show that SAINT+ achieves state-of-the-art performance in knowledge tracing with an improvement of 1.25% in area under receiver operating characteristic curve compared to SAINT, the current state-of-the-art model in EdNet dataset.
Drifting Features: Detection and evaluation in the context of automatic RRLs identification in VVV
May 23, 2021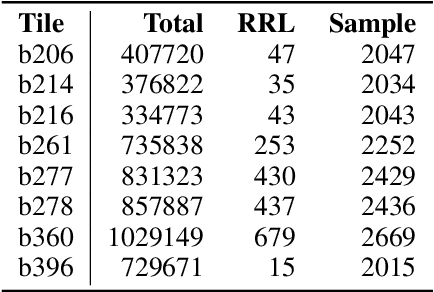
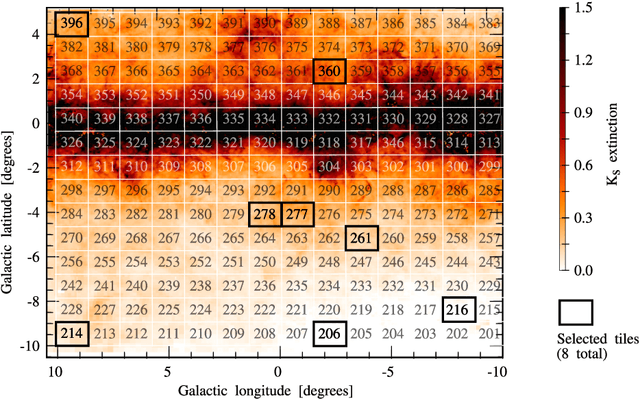
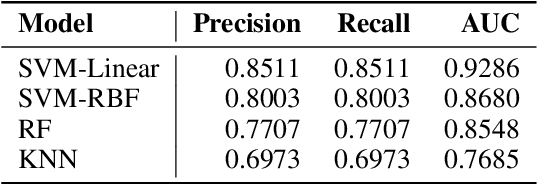
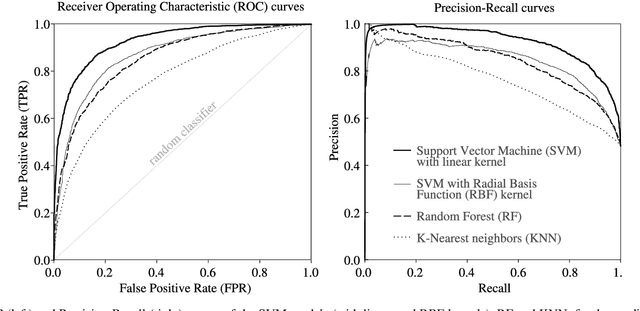
As most of the modern astronomical sky surveys produce data faster than humans can analyze it, Machine Learning (ML) has become a central tool in Astronomy. Modern ML methods can be characterized as highly resistant to some experimental errors. However, small changes on the data over long distances or long periods of time, which cannot be easily detected by statistical methods, can be harmful to these methods. We develop a new strategy to cope with this problem, also using ML methods in an innovative way, to identify these potentially harmful features. We introduce and discuss the notion of Drifting Features, related with small changes in the properties as measured in the data features. We use the identification of RRLs in VVV based on an earlier work and introduce a method for detecting Drifting Features. Our method forces a classifier to learn the tile of origin of diverse sources (mostly stellar 'point sources'), and select the features more relevant to the task of finding candidates to Drifting Features. We show that this method can efficiently identify a reduced set of features that contains useful information about the tile of origin of the sources. For our particular example of detecting RRLs in VVV, we find that Drifting Features are mostly related to color indices. On the other hand, we show that, even if we have a clear set of Drifting Features in our problem, they are mostly insensitive to the identification of RRLs. Drifting Features can be efficiently identified using ML methods. However, in our example, removing Drifting Features does not improve the identification of RRLs.
Camouflaged Object Segmentation with Distraction Mining
Apr 21, 2021
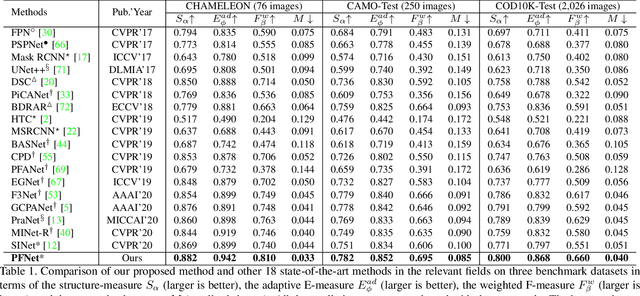
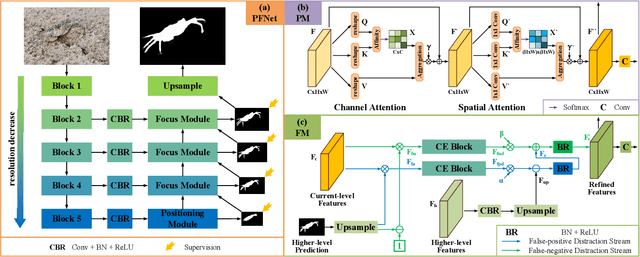
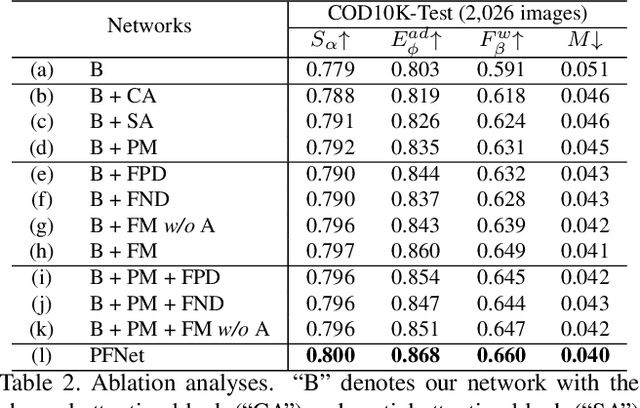
Camouflaged object segmentation (COS) aims to identify objects that are "perfectly" assimilate into their surroundings, which has a wide range of valuable applications. The key challenge of COS is that there exist high intrinsic similarities between the candidate objects and noise background. In this paper, we strive to embrace challenges towards effective and efficient COS. To this end, we develop a bio-inspired framework, termed Positioning and Focus Network (PFNet), which mimics the process of predation in nature. Specifically, our PFNet contains two key modules, i.e., the positioning module (PM) and the focus module (FM). The PM is designed to mimic the detection process in predation for positioning the potential target objects from a global perspective and the FM is then used to perform the identification process in predation for progressively refining the coarse prediction via focusing on the ambiguous regions. Notably, in the FM, we develop a novel distraction mining strategy for distraction discovery and removal, to benefit the performance of estimation. Extensive experiments demonstrate that our PFNet runs in real-time (72 FPS) and significantly outperforms 18 cutting-edge models on three challenging datasets under four standard metrics.