 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DIG: A Turnkey Library for Diving into Graph Deep Learning Research
Mar 23, 2021
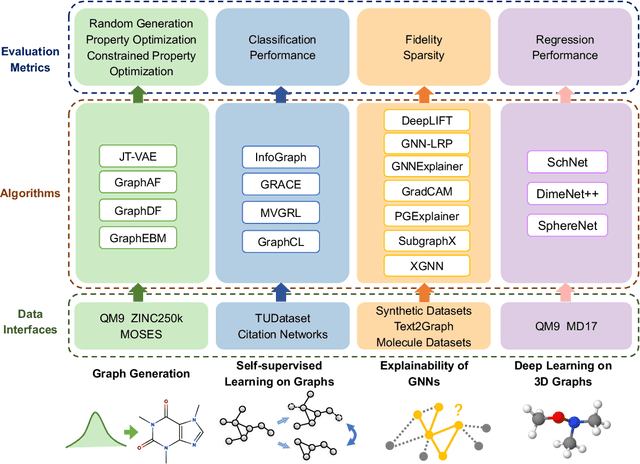
Although there exist several libraries for deep learning on graphs, they are aiming at implementing basic operations for graph deep learning. In the research community, implementing and benchmarking various advanced tasks are still painful and time-consuming with existing libraries. To facilitate graph deep learning research, we introduce DIG: Dive into Graphs, a research-oriented library that integrates unified and extensible implementations of common graph deep learning algorithms for several advanced tasks. Currently, we consider graph generation, self-supervised learning on graphs, explainability of graph neural networks, and deep learning on 3D graphs. For each direction, we provide unified implementations of data interfaces, common algorithms, and evaluation metrics. Altogether, DIG is an extensible, open-source, and turnkey library for researchers to develop new methods and effortlessly compare with common baselines using widely used datasets and evaluation metrics. Source code and documentations are available at https://github.com/divelab/DIG/.
Detection of Dataset Shifts in Learning-Enabled Cyber-Physical Systems using Variational Autoencoder for Regression
Apr 14, 2021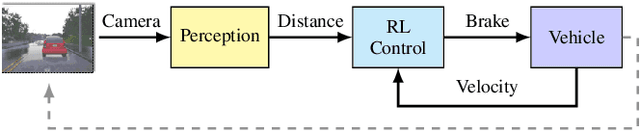
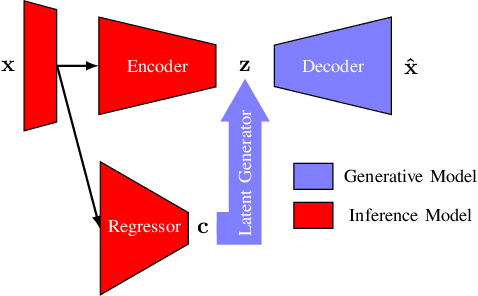
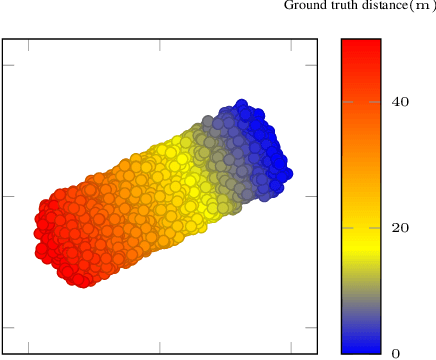
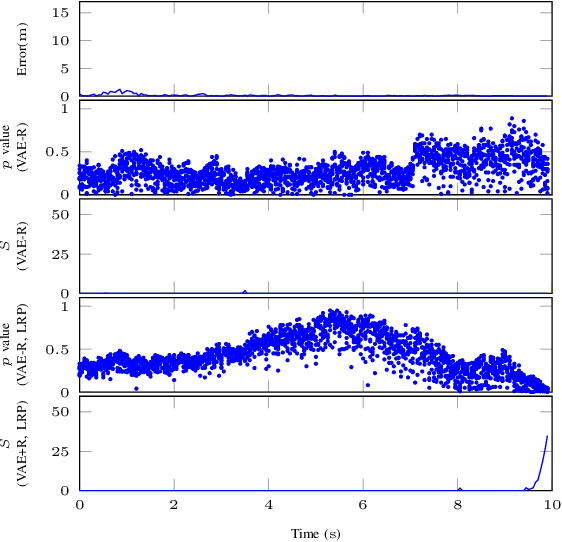
Cyber-physical systems (CPSs) use learning-enabled components (LECs) extensively to cope with various complex tasks under high-uncertainty environments. However, the dataset shifts between the training and testing phase may lead the LECs to become ineffective to make large-error predictions, and further, compromise the safety of the overall system. In our paper, we first provide the formal definitions for different types of dataset shifts in learning-enabled CPS. Then, we propose an approach to detect the dataset shifts effectively for regression problems. Our approach is based on the inductive conformal anomaly detection and utilizes a variational autoencoder for regression model which enables the approach to take into consideration both LEC input and output for detecting dataset shifts. Additionally, in order to improve the robustness of detection, layer-wise relevance propagation (LRP) is incorporated into our approach. We demonstrate our approach by using an advanced emergency braking system implemented in an open-source simulator for self-driving cars. The evaluation results show that our approach can detect different types of dataset shifts with a small number of false alarms while the execution time is smaller than the sampling period of the system.
Flexi-Transducer: Optimizing Latency, Accuracy and Compute forMulti-Domain On-Device Scenarios
Apr 06, 2021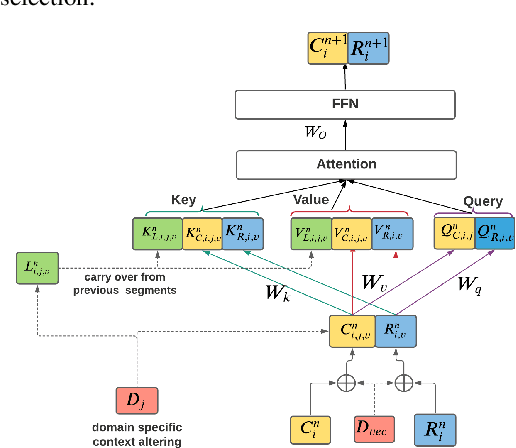
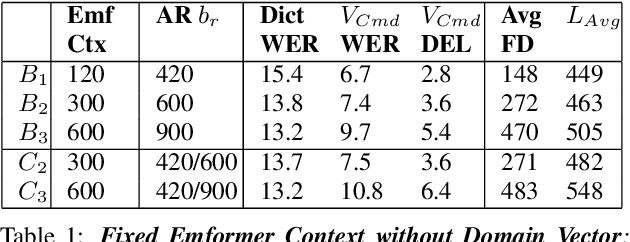
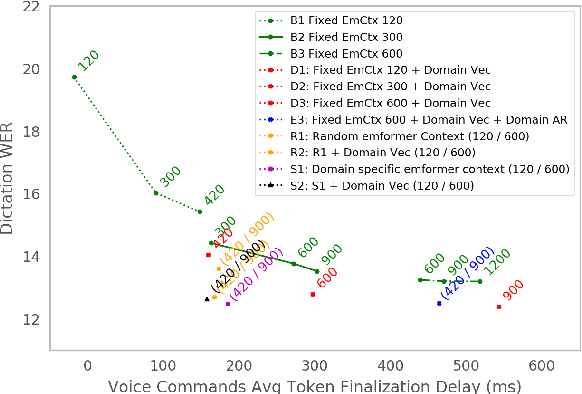
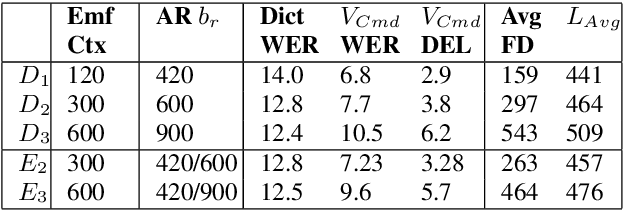
Often, the storage and computational constraints of embeddeddevices demand that a single on-device ASR model serve multiple use-cases / domains. In this paper, we propose aFlexibleTransducer(FlexiT) for on-device automatic speech recognition to flexibly deal with multiple use-cases / domains with different accuracy and latency requirements. Specifically, using a single compact model, FlexiT provides a fast response for voice commands, and accurate transcription but with more latency for dictation. In order to achieve flexible and better accuracy and latency trade-offs, the following techniques are used. Firstly, we propose using domain-specific altering of segment size for Emformer encoder that enables FlexiT to achieve flexible de-coding. Secondly, we use Alignment Restricted RNNT loss to achieve flexible fine-grained control on token emission latency for different domains. Finally, we add a domain indicator vector as an additional input to the FlexiT model. Using the combination of techniques, we show that a single model can be used to improve WERs and real time factor for dictation scenarios while maintaining optimal latency for voice commands use-cases
A Semi-Supervised Classification Method of Apicomplexan Parasites and Host Cell Using Contrastive Learning Strategy
Apr 14, 2021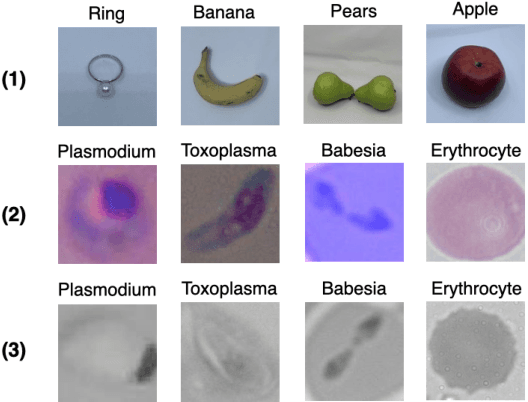
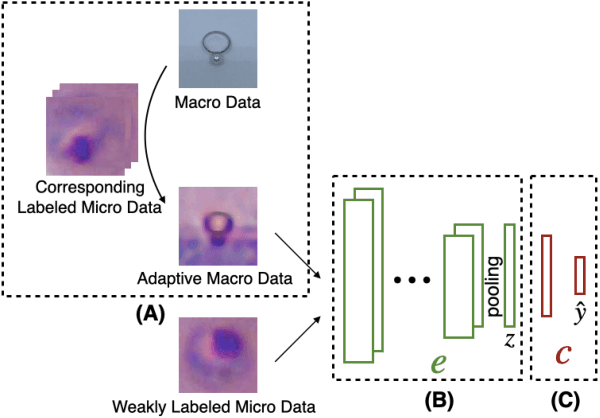
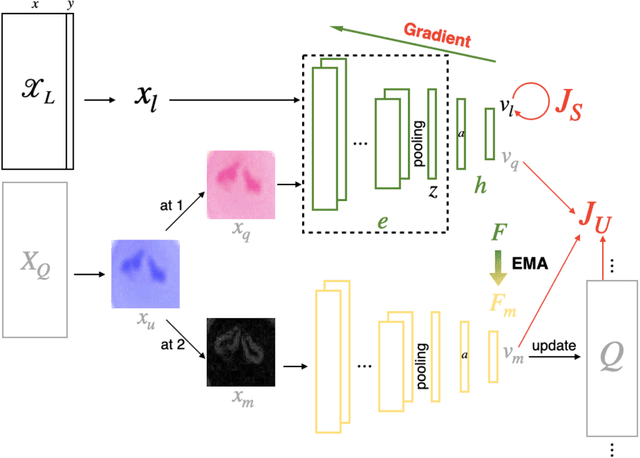
A common shortfall of supervised learning for medical imaging is the greedy need for human annotations, which is often expensive and time-consuming to obtain. This paper proposes a semi-supervised classification method for three kinds of apicomplexan parasites and non-infected host cells microscopic images, which uses a small number of labeled data and a large number of unlabeled data for training. There are two challenges in microscopic image recognition. The first is that salient structures of the microscopic images are more fuzzy and intricate than natural images' on a real-world scale. The second is that insignificant textures, like background staining, lightness, and contrast level, vary a lot in samples from different clinical scenarios. To address these challenges, we aim to learn a distinguishable and appearance-invariant representation by contrastive learning strategy. On one hand, macroscopic images, which share similar shape characteristics in morphology, are introduced to contrast for structure enhancement. On the other hand, different appearance transformations, including color distortion and flittering, are utilized to contrast for texture elimination. In the case where only 1% of microscopic images are labeled, the proposed method reaches an accuracy of 94.90% in a generalized testing set.
Fine-grained MRI Reconstruction using Attentive Selection Generative Adversarial Networks
Mar 13, 2021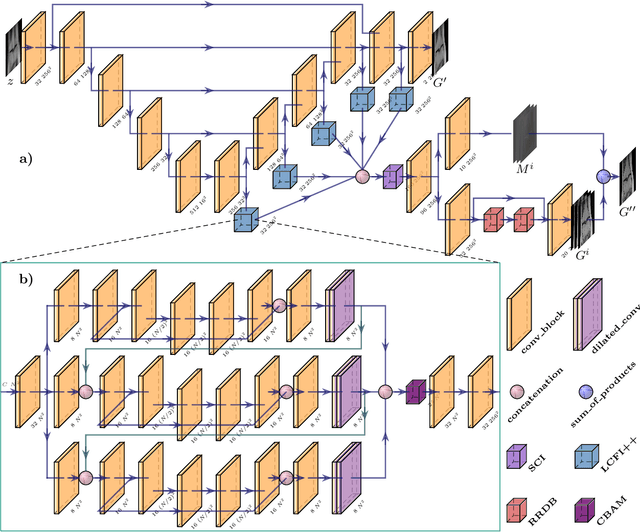
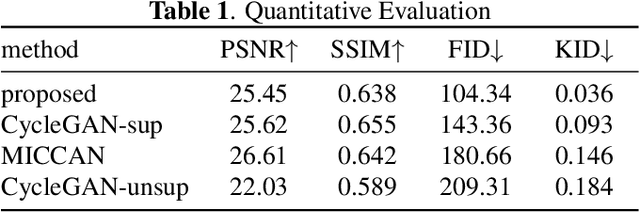
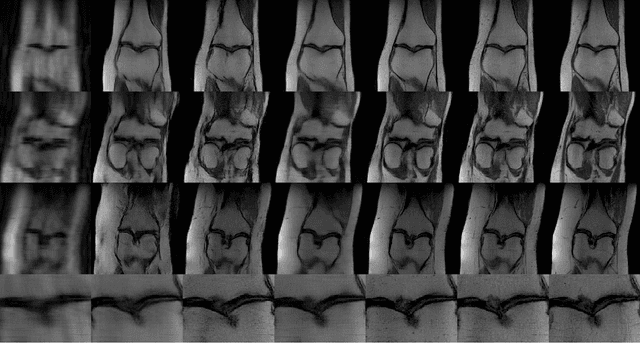
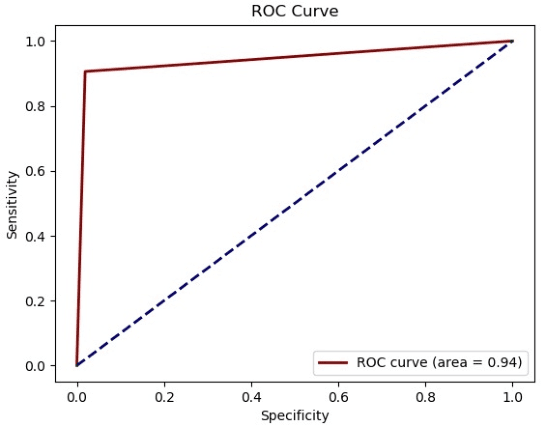
Compressed sensing (CS) leverages the sparsity prior to provide the foundation for fast magnetic resonance imaging (fastMRI). However, iterative solvers for ill-posed problems hinder their adaption to time-critical applications. Moreover, such a prior can be neither rich to capture complicated anatomical structures nor applicable to meet the demand of high-fidelity reconstructions in modern MRI. Inspired by the state-of-the-art methods in image generation, we propose a novel attention-based deep learning framework to provide high-quality MRI reconstruction. We incorporate large-field contextual feature integration and attention selection in a generative adversarial network (GAN) framework. We demonstrate that the proposed model can produce superior results compared to other deep learning-based methods in terms of image quality, and relevance to the MRI reconstruction in an extremely low sampling rate diet.
Particle MPC for Uncertain and Learning-Based Control
Apr 06, 2021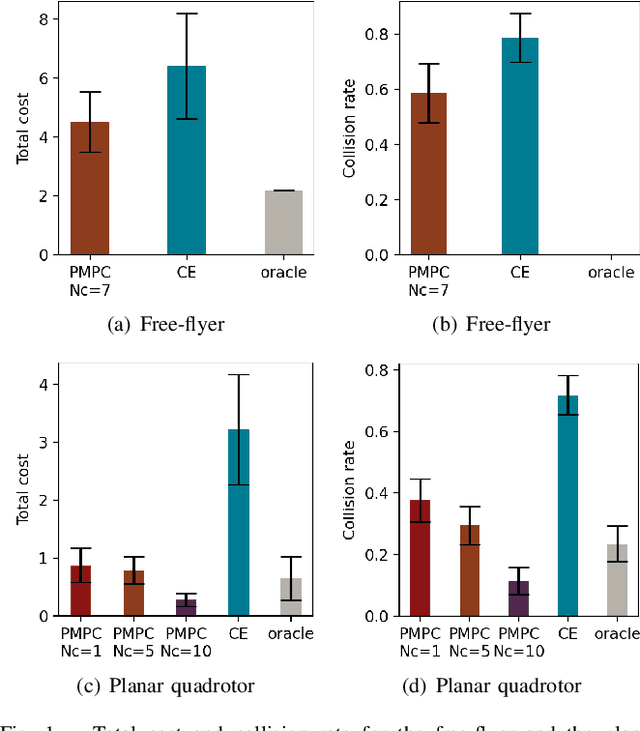
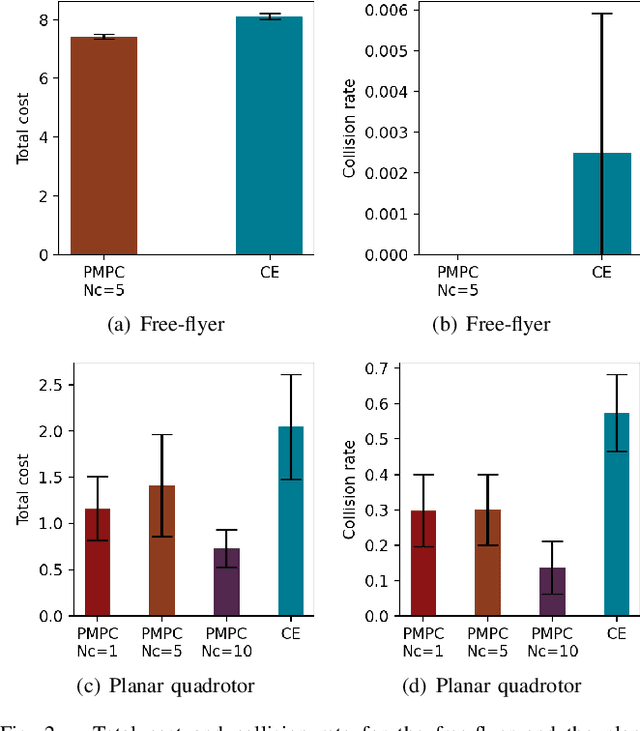
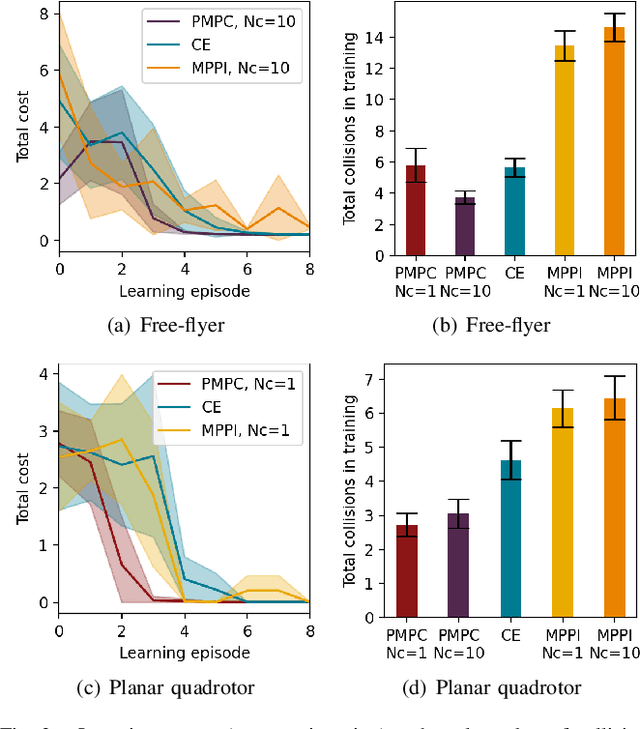
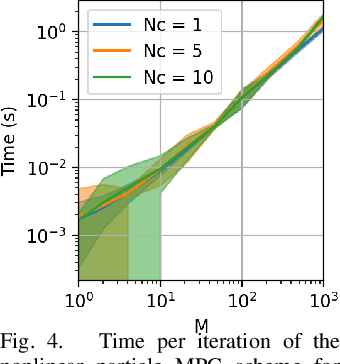
As robotic systems move from highly structured environments to open worlds, incorporating uncertainty from dynamics learning or state estimation into the control pipeline is essential for robust performance. In this paper we present a nonlinear particle model predictive control (PMPC) approach to control under uncertainty, which directly incorporates any particle-based uncertainty representation, such as those common in robotics. Our approach builds on scenario methods for MPC, but in contrast to existing approaches, which either constrain all or only the first timestep to share actions across scenarios, we investigate the impact of a \textit{partial consensus horizon}. Implementing this optimization for nonlinear dynamics by leveraging sequential convex optimization, our approach yields an efficient framework that can be tuned to the particular information gain dynamics of a system to mitigate both over-conservatism and over-optimism. We investigate our approach for two robotic systems across three problem settings: time-varying, partially observed dynamics; sensing uncertainty; and model-based reinforcement learning, and show that our approach improves performance over baselines in all settings.
A Meta-Learning Approach for Medical Image Registration
Apr 21, 2021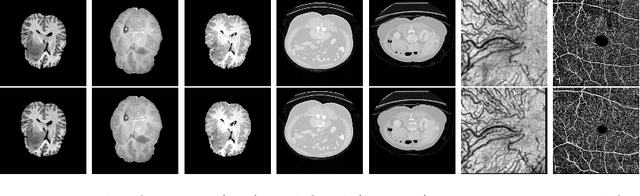
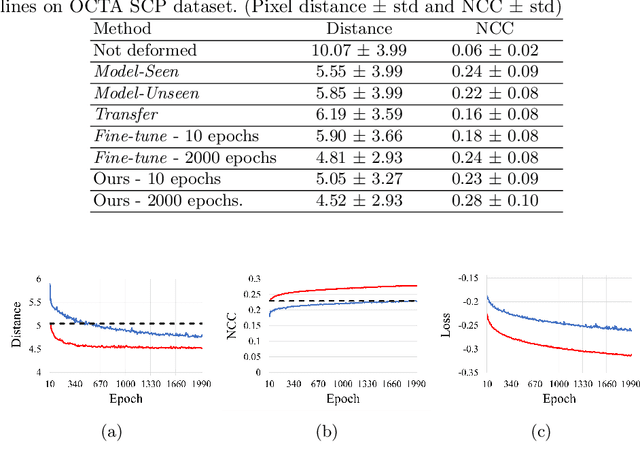
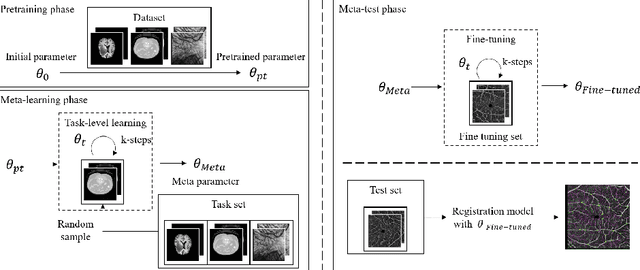
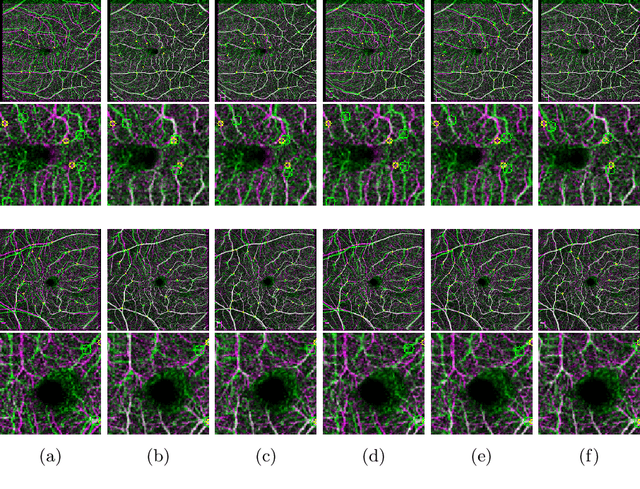
Non-rigid registration is a necessary but challenging task in medical imaging studies. Recently, unsupervised registration models have shown good performance, but they often require a large-scale training dataset and long training times. Therefore, in real world application where only dozens to hundreds of image pairs are available, existing models cannot be practically used. To address these limitations, we propose a novel unsupervised registration model which is integrated with a gradient-based meta learning framework. In particular, we train a meta learner which finds an initialization point of parameters by utilizing a variety of existing registration datasets. To quickly adapt to various tasks, the meta learner was updated to get close to the center of parameters which are fine-tuned for each registration task. Thereby, our model can adapt to unseen domain tasks via a short fine-tuning process and perform accurate registration. To verify the superiority of our model, we train the model for various 2D medical image registration tasks such as retinal choroid Optical Coherence Tomography Angiography (OCTA), CT organs, and brain MRI scans and test on registration of retinal OCTA Superficial Capillary Plexus (SCP). In our experiments, the proposed model obtained significantly improved performance in terms of accuracy and training time compared to other registration models.
Towards Optimized Distributed Multi-Robot Printing: An Algorithmic Approach
Feb 24, 2021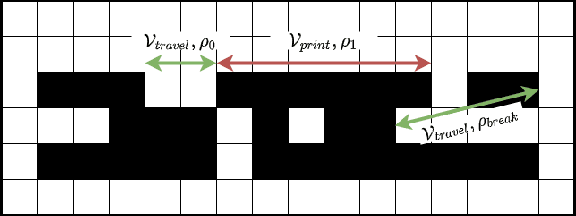
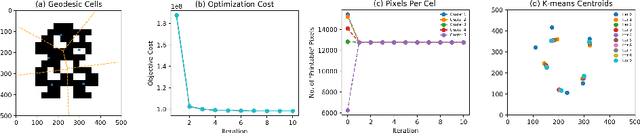
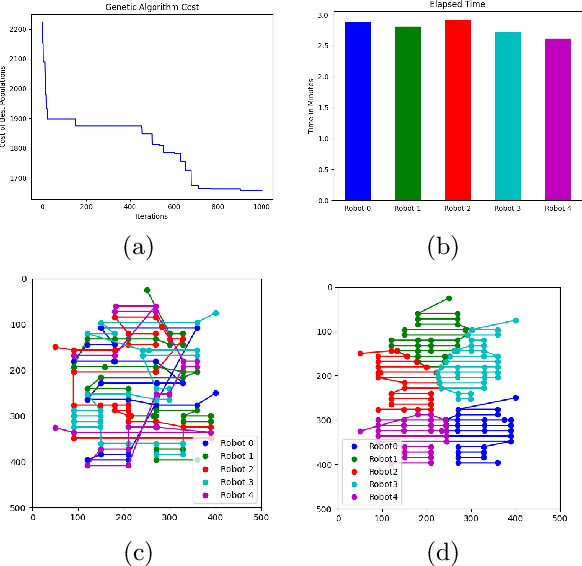
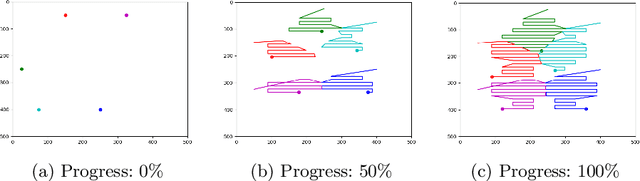
This paper presents a distributed multi-robot printing method which utilizes an optimization approach to decompose and allocate a printing task to a group of mobile robots. The motivation for this problem is to minimize the printing time of the robots by using an appropriate task decomposition algorithm. We present one such algorithm which decomposes an image into rasterized geodesic cells before allocating them to the robots for printing. In addition to this, we also present the design of a numerically controlled holonomic robot capable of spraying ink on smooth surfaces. Further, we use this robot to experimentally verify the results of this paper.
Real-time eSports Match Result Prediction
Dec 10, 2016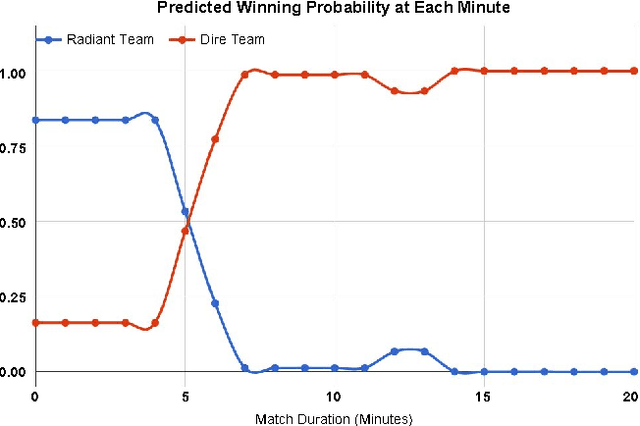
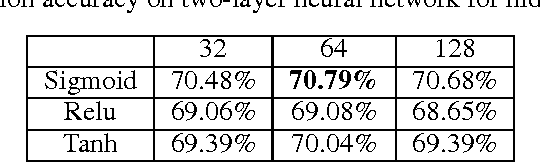

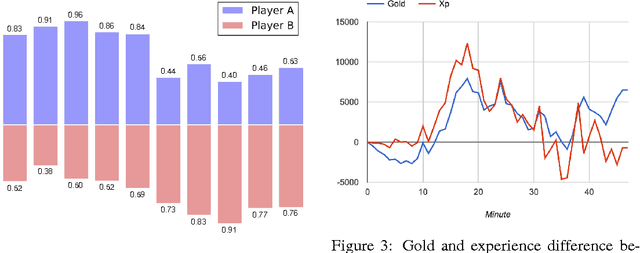
In this paper, we try to predict the winning team of a match in the multiplayer eSports game Dota 2. To address the weaknesses of previous work, we consider more aspects of prior (pre-match) features from individual players' match history, as well as real-time (during-match) features at each minute as the match progresses. We use logistic regression, the proposed Attribute Sequence Model, and their combinations as the prediction models. In a dataset of 78362 matches where 20631 matches contain replay data, our experiments show that adding more aspects of prior features improves accuracy from 58.69% to 71.49%, and introducing real-time features achieves up to 93.73% accuracy when predicting at the 40th minute.
Adversarial Targeted Forgetting in Regularization and Generative Based Continual Learning Models
Feb 16, 2021

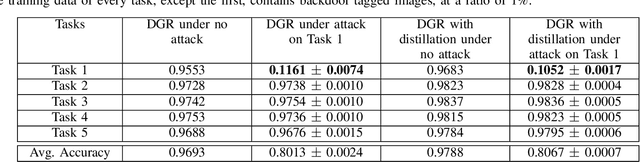
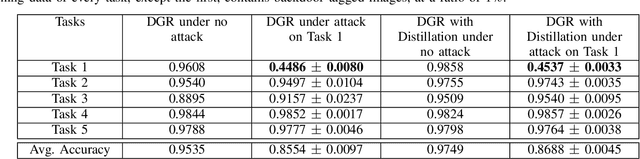
Continual (or "incremental") learning approaches are employed when additional knowledge or tasks need to be learned from subsequent batches or from streaming data. However these approaches are typically adversary agnostic, i.e., they do not consider the possibility of a malicious attack. In our prior work, we explored the vulnerabilities of Elastic Weight Consolidation (EWC) to the perceptible misinformation. We now explore the vulnerabilities of other regularization-based as well as generative replay-based continual learning algorithms, and also extend the attack to imperceptible misinformation. We show that an intelligent adversary can take advantage of a continual learning algorithm's capabilities of retaining existing knowledge over time, and force it to learn and retain deliberately introduced misinformation. To demonstrate this vulnerability, we inject backdoor attack samples into the training data. These attack samples constitute the misinformation, allowing the attacker to capture control of the model at test time. We evaluate the extent of this vulnerability on both rotated and split benchmark variants of the MNIST dataset under two important domain and class incremental learning scenarios. We show that the adversary can create a "false memory" about any task by inserting carefully-designed backdoor samples to the test instances of that task thereby controlling the amount of forgetting of any task of its choosing. Perhaps most importantly, we show this vulnerability to be very acute and damaging: the model memory can be easily compromised with the addition of backdoor samples into as little as 1\% of the training data, even when the misinformation is imperceptible to human eye.