 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Set2setRank: Collaborative Set to Set Ranking for Implicit Feedback based Recommendation
May 16, 2021
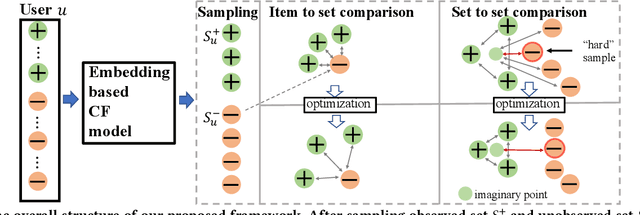
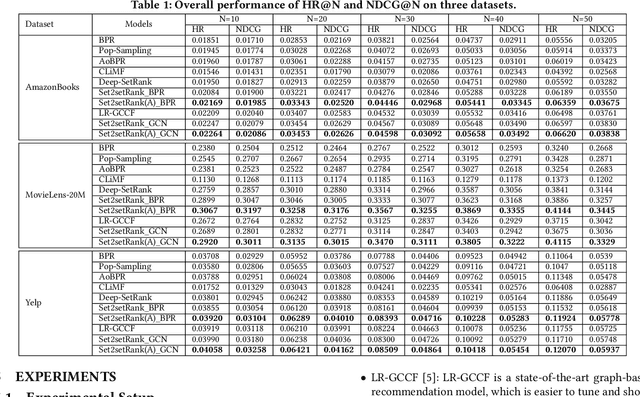
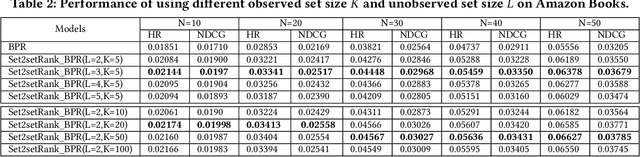
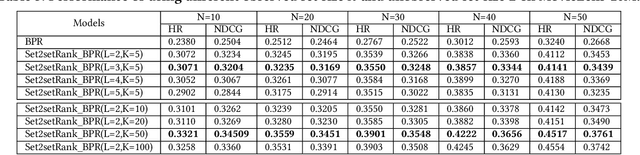
As users often express their preferences with binary behavior data~(implicit feedback), such as clicking items or buying products, implicit feedback based Collaborative Filtering~(CF) models predict the top ranked items a user might like by leveraging implicit user-item interaction data. For each user, the implicit feedback is divided into two sets: an observed item set with limited observed behaviors, and a large unobserved item set that is mixed with negative item behaviors and unknown behaviors. Given any user preference prediction model, researchers either designed ranking based optimization goals or relied on negative item mining techniques for better optimization. Despite the performance gain of these implicit feedback based models, the recommendation results are still far from satisfactory due to the sparsity of the observed item set for each user. To this end, in this paper, we explore the unique characteristics of the implicit feedback and propose Set2setRank framework for recommendation. The optimization criteria of Set2setRank are two folds: First, we design an item to an item set comparison that encourages each observed item from the sampled observed set is ranked higher than any unobserved item from the sampled unobserved set. Second, we model set level comparison that encourages a margin between the distance summarized from the observed item set and the most "hard" unobserved item from the sampled negative set. Further, an adaptive sampling technique is designed to implement these two goals. We have to note that our proposed framework is model-agnostic and can be easily applied to most recommendation prediction approaches, and is time efficient in practice. Finally, extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach.
EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion
Apr 28, 2021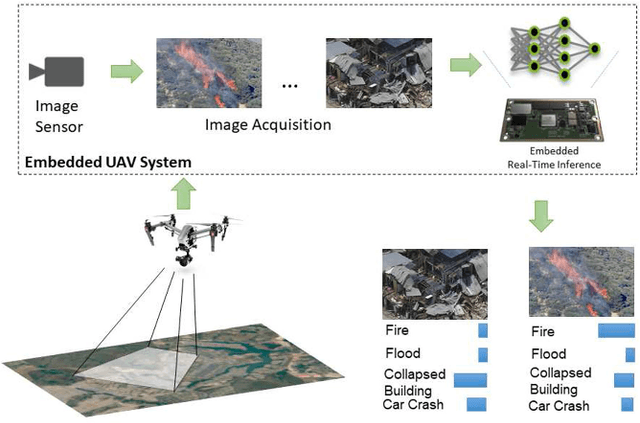



Deep learning-based algorithms can provide state-of-the-art accuracy for remote sensing technologies such as unmanned aerial vehicles (UAVs)/drones, potentially enhancing their remote sensing capabilities for many emergency response and disaster management applications. In particular, UAVs equipped with camera sensors can operating in remote and difficult to access disaster-stricken areas, analyze the image and alert in the presence of various calamities such as collapsed buildings, flood, or fire in order to faster mitigate their effects on the environment and on human population. However, the integration of deep learning introduces heavy computational requirements, preventing the deployment of such deep neural networks in many scenarios that impose low-latency constraints on inference, in order to make mission-critical decisions in real time. To this end, this article focuses on the efficient aerial image classification from on-board a UAV for emergency response/monitoring applications. Specifically, a dedicated Aerial Image Database for Emergency Response applications is introduced and a comparative analysis of existing approaches is performed. Through this analysis a lightweight convolutional neural network architecture is proposed, referred to as EmergencyNet, based on atrous convolutions to process multiresolution features and capable of running efficiently on low-power embedded platforms achieving upto 20x higher performance compared to existing models with minimal memory requirements with less than 1% accuracy drop compared to state-of-the-art models.
* C.Kyrkou and T. Theocharides, "EmergencyNet: Efficient Aerial Image Classification for Drone-Based Emergency Monitoring Using Atrous Convolutional Feature Fusion," in IEEE J Sel Top Appl Earth Obs Remote Sens. (JSTARS), vol. 13, pp. 1687-1699, 2020. arXiv admin note: substantial text overlap with arXiv:1906.08716
Fusion of Real Time Thermal Image and 1D/2D/3D Depth Laser Readings for Remote Thermal Sensing in Industrial Plants by Means of UAVs and/or Robots
Jun 01, 2020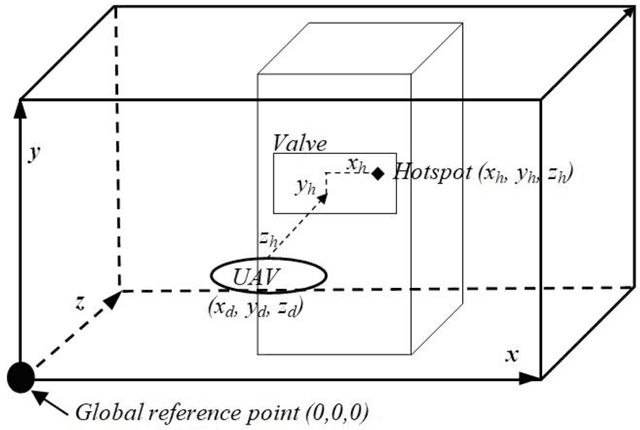


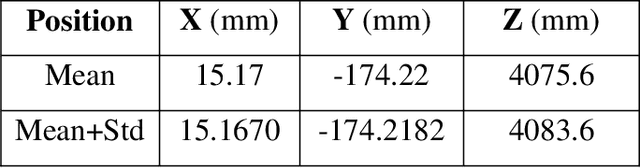
This paper presents fast procedures for thermal infrared remote sensing in dark, GPS-denied environments, such as those found in industrial plants such as in High-Voltage Direct Current (HVDC) converter stations. These procedures are based on the combination of the depth estimation obtained from either a 1-Dimensional LIDAR laser or a 2-Dimensional Hokuyo laser or a 3D MultiSense SLB laser sensor and the visible and thermal cameras from a FLIR Duo R dual-sensor thermal camera. The combination of these sensors/cameras is suitable to be mounted on Unmanned Aerial Vehicles (UAVs) and/or robots in order to provide reliable information about the potential malfunctions, which can be found within the hazardous environment. For example, the capabilities of the developed software and hardware system corresponding to the combination of the 1-D LIDAR sensor and the FLIR Duo R dual-sensor thermal camera is assessed from the point of the accuracy of results and the required computational times: the obtained computational times are under 10 ms, with a maximum localization error of 8 mm and an average standard deviation for the measured temperatures of 1.11 degree Celsius, which results are obtained for a number of test cases. The paper is structured as follows: the description of the system used for identification and localization of hotspots in industrial plants is presented in section II. In section III, the method for faults identification and localization in plants by using a 1-Dimensional LIDAR laser sensor and thermal images is described together with results. In section IV the real time thermal image processing is presented. Fusion of the 2-Dimensional depth laser Hokuyo and the thermal images is described in section V. In section VI the combination of the 3D MultiSense SLB laser and thermal images is described. In section VII a discussion and several conclusions are drawn.
VDSM: Unsupervised Video Disentanglement with State-Space Modeling and Deep Mixtures of Experts
Mar 28, 2021
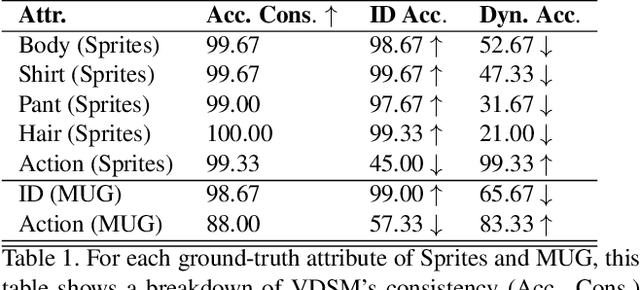
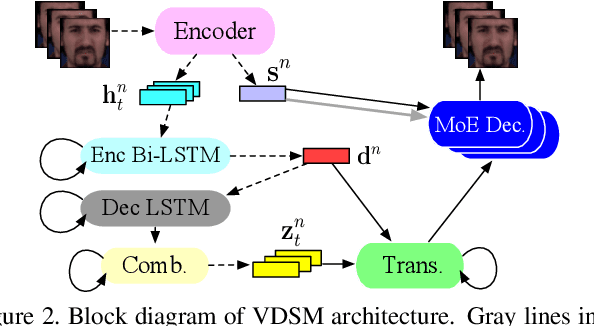
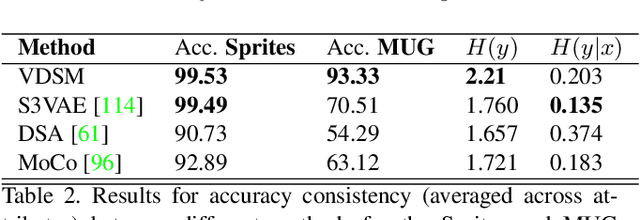
Disentangled representations support a range of downstream tasks including causal reasoning, generative modeling, and fair machine learning. Unfortunately, disentanglement has been shown to be impossible without the incorporation of supervision or inductive bias. Given that supervision is often expensive or infeasible to acquire, we choose to incorporate structural inductive bias and present an unsupervised, deep State-Space-Model for Video Disentanglement (VDSM). The model disentangles latent time-varying and dynamic factors via the incorporation of hierarchical structure with a dynamic prior and a Mixture of Experts decoder. VDSM learns separate disentangled representations for the identity of the object or person in the video, and for the action being performed. We evaluate VDSM across a range of qualitative and quantitative tasks including identity and dynamics transfer, sequence generation, Fr\'echet Inception Distance, and factor classification. VDSM provides state-of-the-art performance and exceeds adversarial methods, even when the methods use additional supervision.
Online Product Feature Recommendations with Interpretable Machine Learning
Apr 28, 2021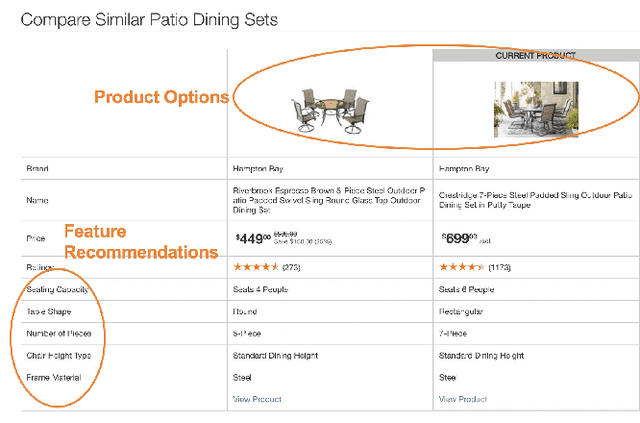
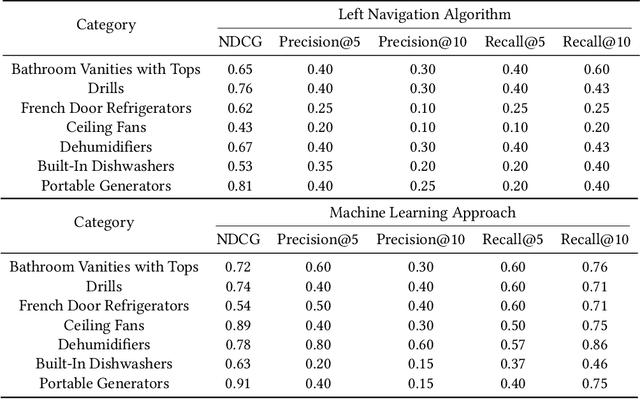
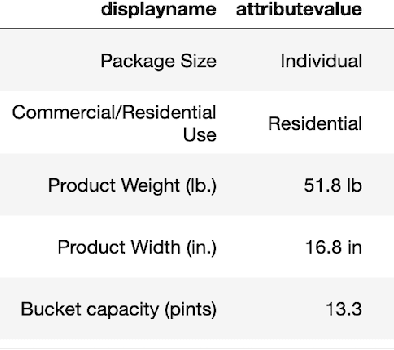

Product feature recommendations are critical for online customers to purchase the right products based on the right features. For a customer, selecting the product that has the best trade-off between price and functionality is a time-consuming step in an online shopping experience, and customers can be overwhelmed by the available choices. However, determining the set of product features that most differentiate a particular product is still an open question in online recommender systems. In this paper, we focus on using interpretable machine learning methods to tackle this problem. First, we identify this unique product feature recommendation problem from a business perspective on a major US e-commerce site. Second, we formulate the problem into a price-driven supervised learning problem to discover the product features that could best explain the price of a product in a given product category. We build machine learning models with a model-agnostic method Shapley Values to understand the importance of each feature, rank and recommend the most essential features. Third, we leverage human experts to evaluate its relevancy. The results show that our method is superior to a strong baseline method based on customer behavior and significantly boosts the coverage by 45%. Finally, our proposed method shows comparable conversion rate against the baseline in online A/B tests.
Polynomial-time Updates of Epistemic States in a Fragment of Probabilistic Epistemic Argumentation (Technical Report)
Jun 12, 2019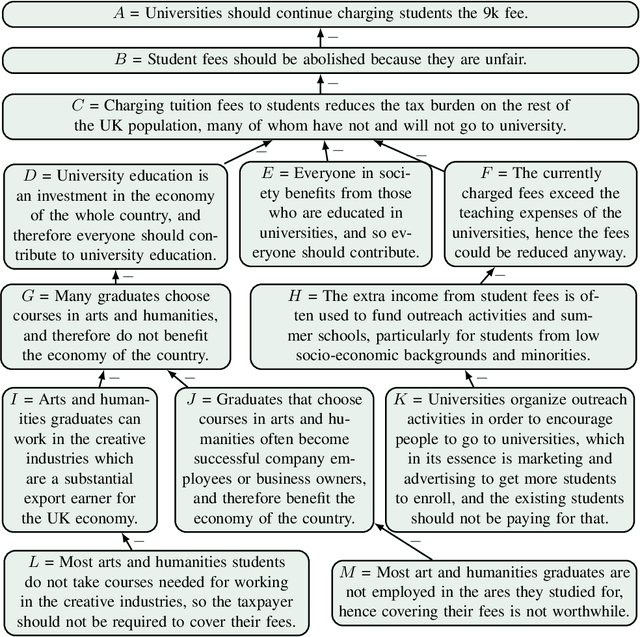

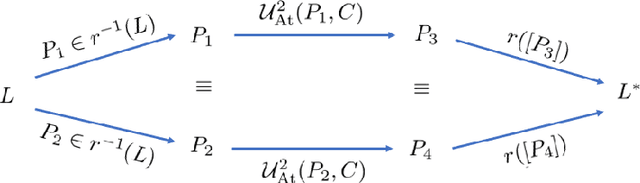
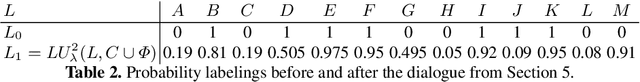
Probabilistic epistemic argumentation allows for reasoning about argumentation problems in a way that is well founded by probability theory. Epistemic states are represented by probability functions over possible worlds and can be adjusted to new beliefs using update operators. While the use of probability functions puts this approach on a solid foundational basis, it also causes computational challenges as the amount of data to process depends exponentially on the number of arguments. This leads to bottlenecks in applications such as modelling opponent's beliefs for persuasion dialogues. We show how update operators over probability functions can be related to update operators over much more compact representations that allow polynomial-time updates. We discuss the cognitive and probabilistic-logical plausibility of this approach and demonstrate its applicability in computational persuasion.
Deep learning approaches to surrogates for solving the diffusion equation for mechanistic real-world simulations
Feb 10, 2021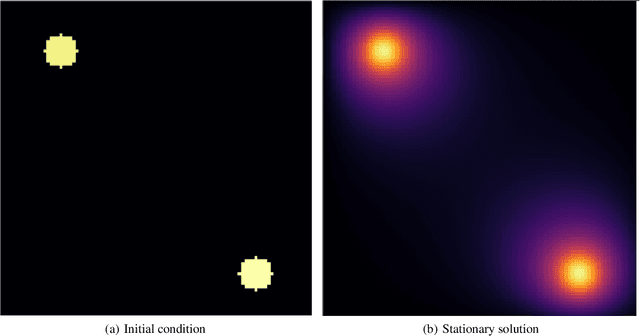
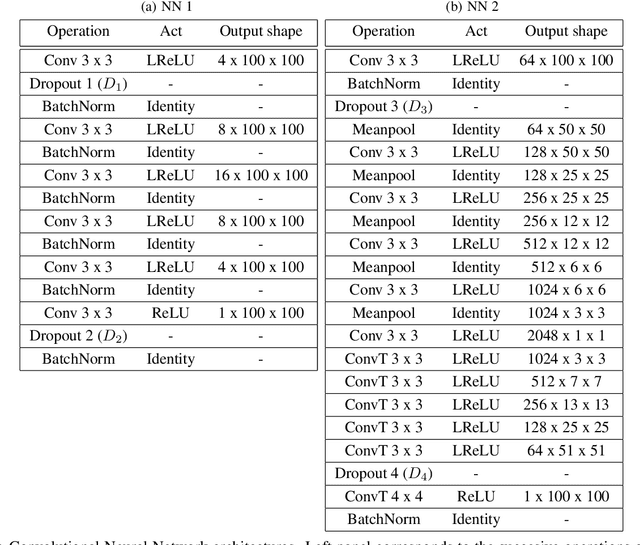
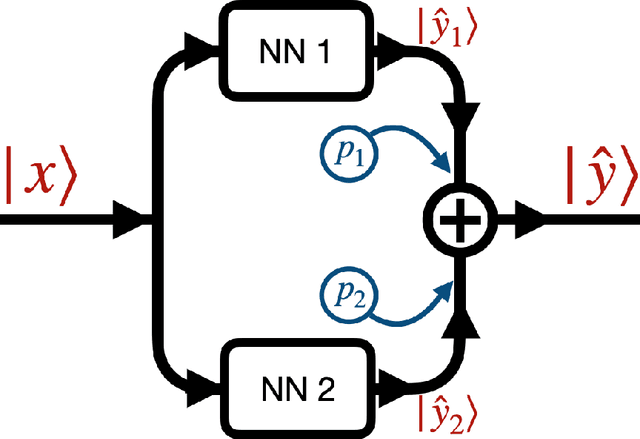
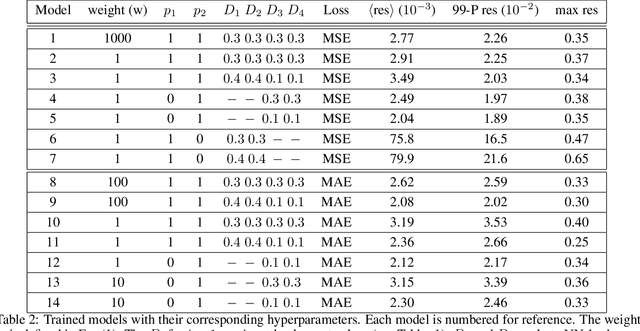
In many mechanistic medical, biological, physical and engineered spatiotemporal dynamic models the numerical solution of partial differential equations (PDEs) can make simulations impractically slow. Biological models require the simultaneous calculation of the spatial variation of concentration of dozens of diffusing chemical species. Machine learning surrogates, neural networks trained to provide approximate solutions to such complicated numerical problems, can often provide speed-ups of several orders of magnitude compared to direct calculation. PDE surrogates enable use of larger models than are possible with direct calculation and can make including such simulations in real-time or near-real time workflows practical. Creating a surrogate requires running the direct calculation tens of thousands of times to generate training data and then training the neural network, both of which are computationally expensive. We use a Convolutional Neural Network to approximate the stationary solution to the diffusion equation in the case of two equal-diameter, circular, constant-value sources located at random positions in a two-dimensional square domain with absorbing boundary conditions. To improve convergence during training, we apply a training approach that uses roll-back to reject stochastic changes to the network that increase the loss function. The trained neural network approximation is about 1e3 times faster than the direct calculation for individual replicas. Because different applications will have different criteria for acceptable approximation accuracy, we discuss a variety of loss functions and accuracy estimators that can help select the best network for a particular application.
Data-driven formulation of natural laws by recursive-LASSO-based symbolic regression
Feb 18, 2021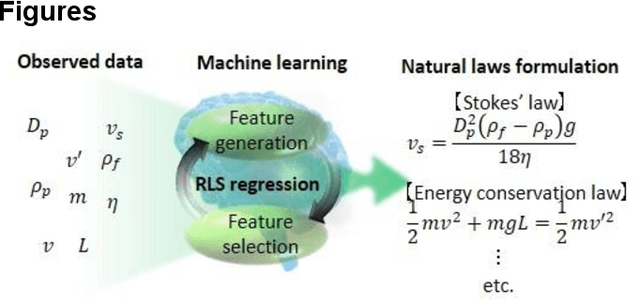
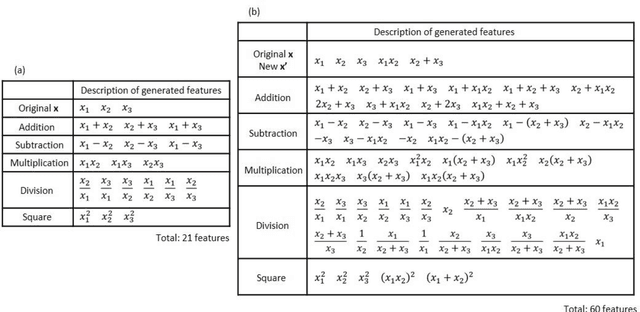
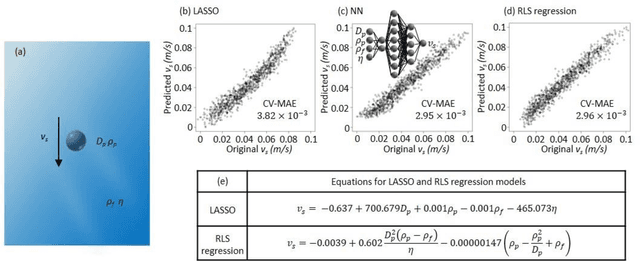
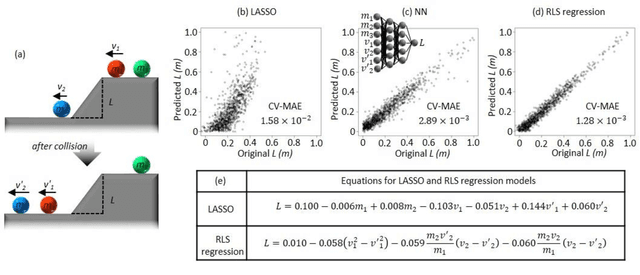
Discovery of new natural laws has for a long time relied on the inspiration of some genius. Recently, however, machine learning technologies, which analyze big data without human prejudice and bias, are expected to find novel natural laws. Here we demonstrate that our proposed machine learning, recursive-LASSO-based symbolic (RLS) regression, enables data-driven formulation of natural laws from noisy data. The RLS regression recurrently repeats feature generation and feature selection, eventually constructing a data-driven model with highly nonlinear features. This data-driven formulation method is quite general and thus can discover new laws in various scientific fields.
Context-Dependent Anomaly Detection for Low Altitude Traffic Surveillance
Apr 14, 2021
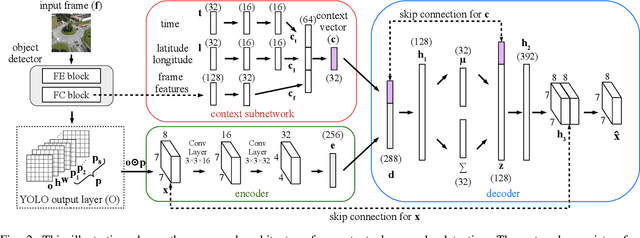
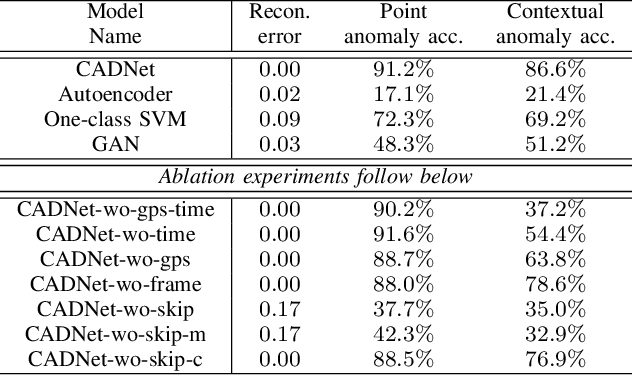
The detection of contextual anomalies is a challenging task for surveillance since an observation can be considered anomalous or normal in a specific environmental context. An unmanned aerial vehicle (UAV) can utilize its aerial monitoring capability and employ multiple sensors to gather contextual information about the environment and perform contextual anomaly detection. In this work, we introduce a deep neural network-based method (CADNet) to find point anomalies (i.e., single instance anomalous data) and contextual anomalies (i.e., context-specific abnormality) in an environment using a UAV. The method is based on a variational autoencoder (VAE) with a context sub-network. The context sub-network extracts contextual information regarding the environment using GPS and time data, then feeds it to the VAE to predict anomalies conditioned on the context. To the best of our knowledge, our method is the first contextual anomaly detection method for UAV-assisted aerial surveillance. We evaluate our method on the AU-AIR dataset in a traffic surveillance scenario. Quantitative comparisons against several baselines demonstrate the superiority of our approach in the anomaly detection tasks. The codes and data will be available at https://bozcani.github.io/cadnet.
Finding High-Value Training Data Subset through Differentiable Convex Programming
Apr 28, 2021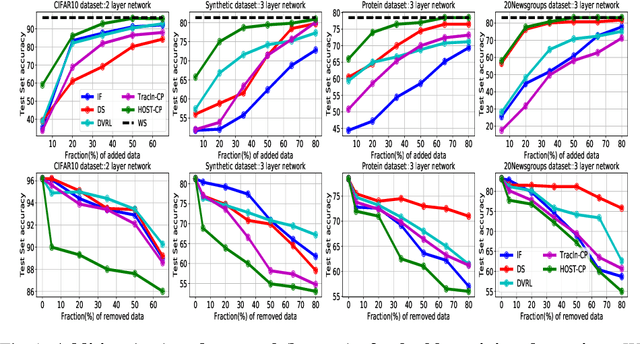
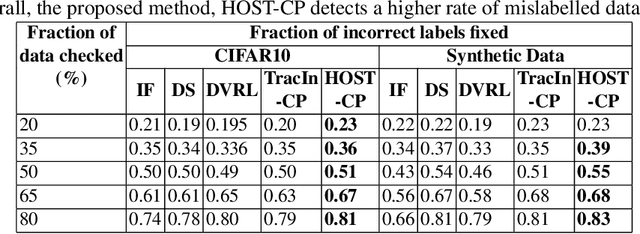
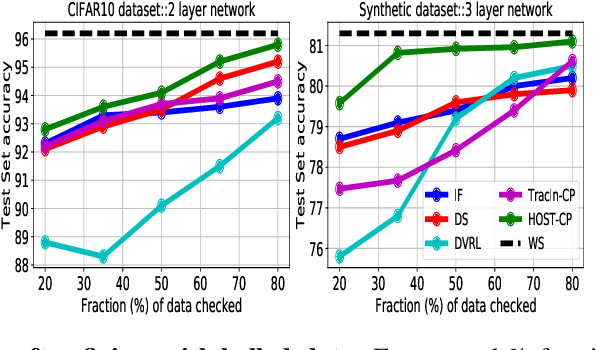

Finding valuable training data points for deep neural networks has been a core research challenge with many applications. In recent years, various techniques for calculating the "value" of individual training datapoints have been proposed for explaining trained models. However, the value of a training datapoint also depends on other selected training datapoints - a notion that is not explicitly captured by existing methods. In this paper, we study the problem of selecting high-value subsets of training data. The key idea is to design a learnable framework for online subset selection, which can be learned using mini-batches of training data, thus making our method scalable. This results in a parameterized convex subset selection problem that is amenable to a differentiable convex programming paradigm, thus allowing us to learn the parameters of the selection model in end-to-end training. Using this framework, we design an online alternating minimization-based algorithm for jointly learning the parameters of the selection model and ML model. Extensive evaluation on a synthetic dataset, and three standard datasets, show that our algorithm finds consistently higher value subsets of training data, compared to the recent state-of-the-art methods, sometimes ~20% higher value than existing methods. The subsets are also useful in finding mislabelled training data. Our algorithm takes running time comparable to the existing valuation functions.