 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Extending Multi-Sense Word Embedding to Phrases and Sentences for Unsupervised Semantic Applications
Mar 29, 2021
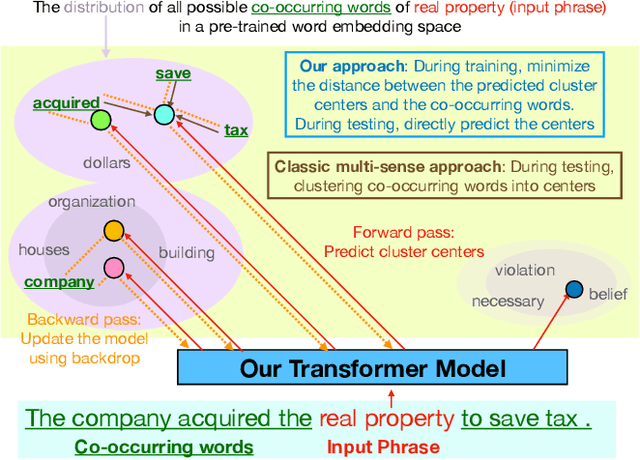
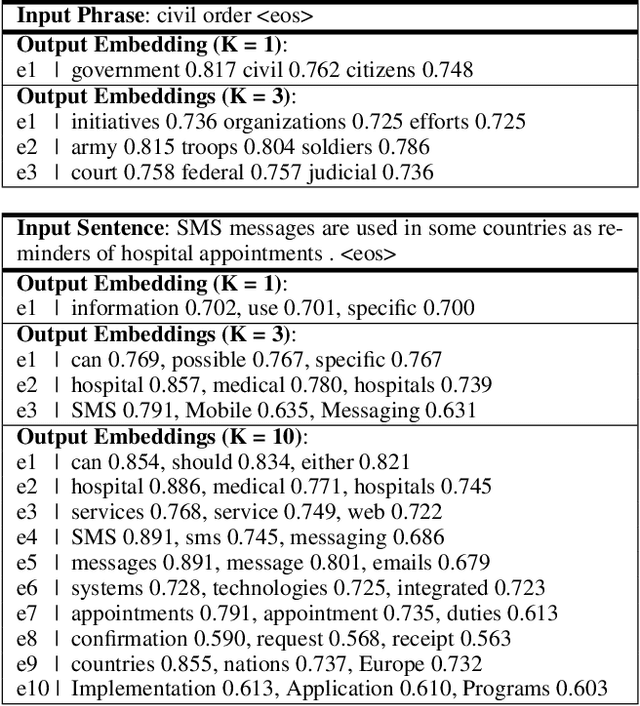
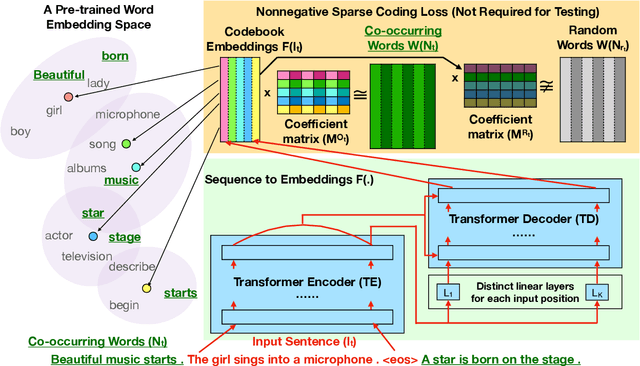
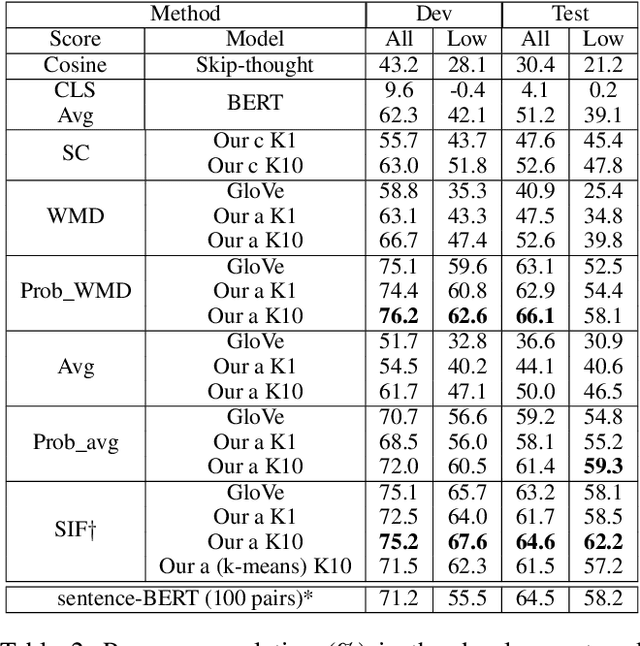
Most unsupervised NLP models represent each word with a single point or single region in semantic space, while the existing multi-sense word embeddings cannot represent longer word sequences like phrases or sentences. We propose a novel embedding method for a text sequence (a phrase or a sentence) where each sequence is represented by a distinct set of multi-mode codebook embeddings to capture different semantic facets of its meaning. The codebook embeddings can be viewed as the cluster centers which summarize the distribution of possibly co-occurring words in a pre-trained word embedding space. We introduce an end-to-end trainable neural model that directly predicts the set of cluster centers from the input text sequence during test time. Our experiments show that the per-sentence codebook embeddings significantly improve the performances in unsupervised sentence similarity and extractive summarization benchmarks. In phrase similarity experiments, we discover that the multi-facet embeddings provide an interpretable semantic representation but do not outperform the single-facet baseline.
An Automated Approach for Timely Diagnosis and Prognosis of Coronavirus Disease
Apr 29, 2021
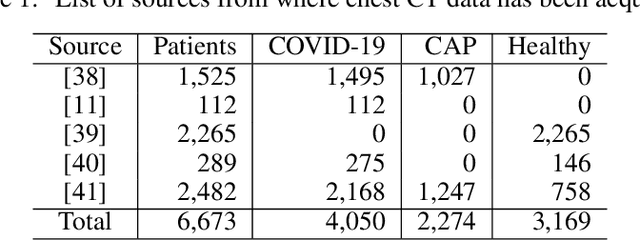

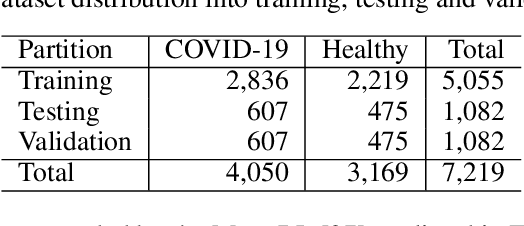
Since the outbreak of Coronavirus Disease 2019 (COVID-19), most of the impacted patients have been diagnosed with high fever, dry cough, and soar throat leading to severe pneumonia. Hence, to date, the diagnosis of COVID-19 from lung imaging is proved to be a major evidence for early diagnosis of the disease. Although nucleic acid detection using real-time reverse-transcriptase polymerase chain reaction (rRT-PCR) remains a gold standard for the detection of COVID-19, the proposed approach focuses on the automated diagnosis and prognosis of the disease from a non-contrast chest computed tomography (CT)scan for timely diagnosis and triage of the patient. The prognosis covers the quantification and assessment of the disease to help hospitals with the management and planning of crucial resources, such as medical staff, ventilators and intensive care units (ICUs) capacity. The approach utilises deep learning techniques for automated quantification of the severity of COVID-19 disease via measuring the area of multiple rounded ground-glass opacities (GGO) and consolidations in the periphery (CP) of the lungs and accumulating them to form a severity score. The severity of the disease can be correlated with the medicines prescribed during the triage to assess the effectiveness of the treatment. The proposed approach shows promising results where the classification model achieved 93% accuracy on hold-out data.
* to be published in IJCNN 2021
Leveraging Multiple Relations for Fashion Trend Forecasting Based on Social Media
May 11, 2021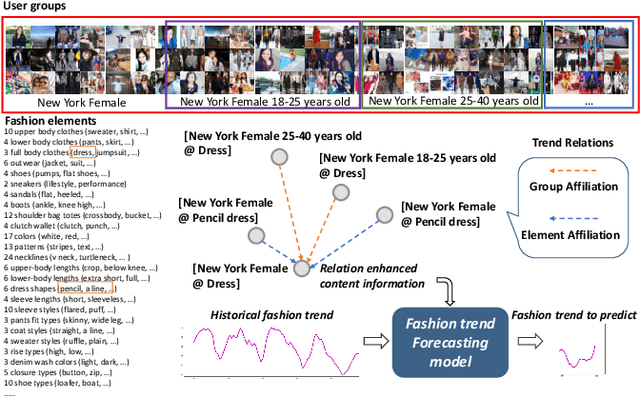
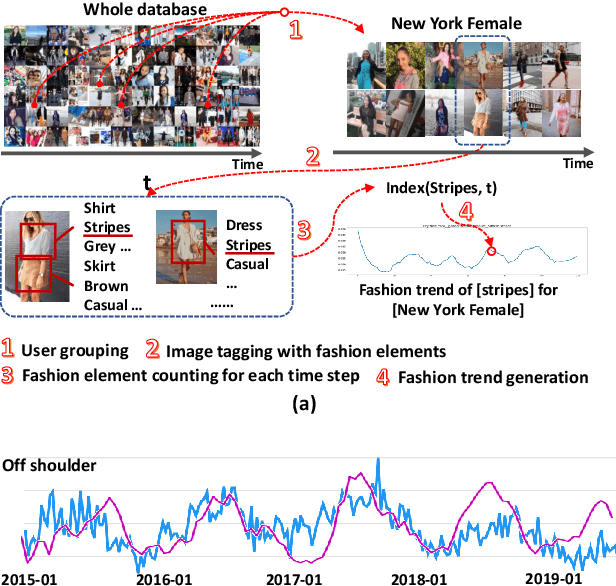
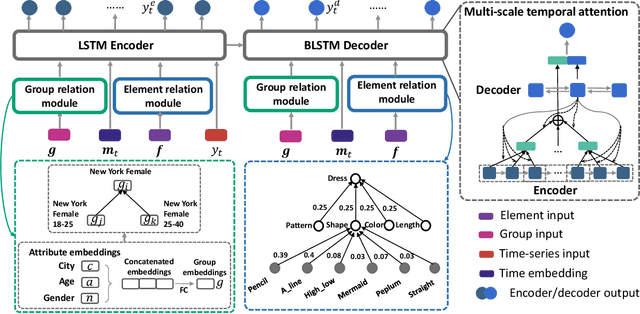
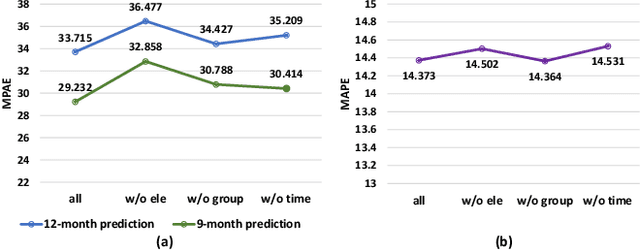
Fashion trend forecasting is of great research significance in providing useful suggestions for both fashion companies and fashion lovers. Although various studies have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real complex fashion trends. Moreover, the mainstream solutions for this task are still statistical-based and solely focus on time-series data modeling, which limit the forecast accuracy. Towards insightful fashion trend forecasting, previous work [1] proposed to analyze more fine-grained fashion elements which can informatively reveal fashion trends. Specifically, it focused on detailed fashion element trend forecasting for specific user groups based on social media data. In addition, it proposed a neural network-based method, namely KERN, to address the problem of fashion trend modeling and forecasting. In this work, to extend the previous work, we propose an improved model named Relation Enhanced Attention Recurrent (REAR) network. Compared to KERN, the REAR model leverages not only the relations among fashion elements but also those among user groups, thus capturing more types of correlations among various fashion trends. To further improve the performance of long-range trend forecasting, the REAR method devises a sliding temporal attention mechanism, which is able to capture temporal patterns on future horizons better. Extensive experiments and more analysis have been conducted on the FIT and GeoStyle datasets to evaluate the performance of REAR. Experimental and analytical results demonstrate the effectiveness of the proposed REAR model in fashion trend forecasting, which also show the improvement of REAR compared to the KERN.
* 12 pages, 8 figures
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
Mar 29, 2021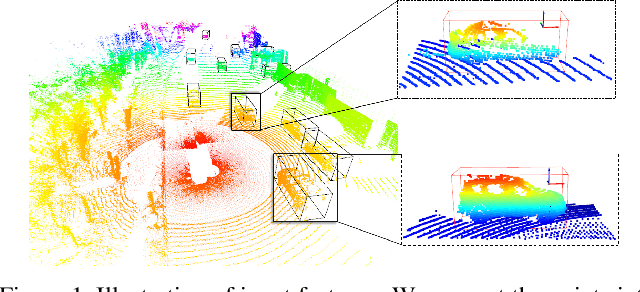
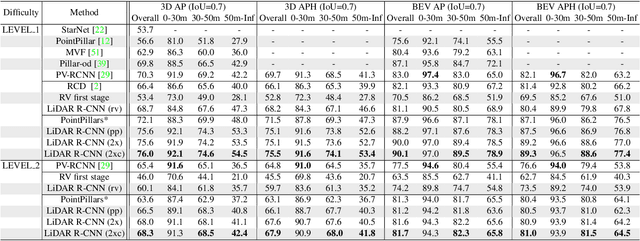
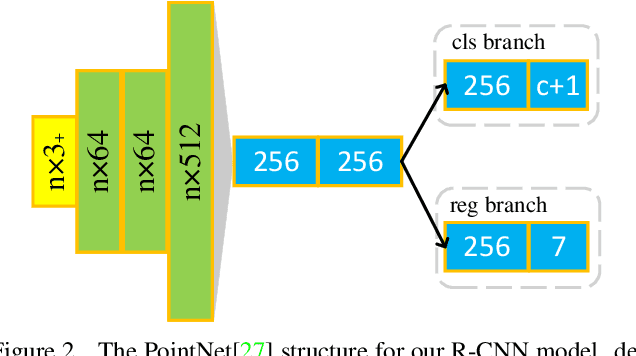
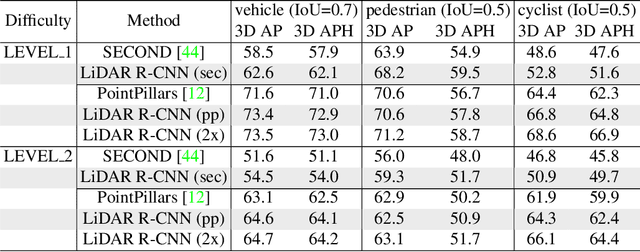
LiDAR-based 3D detection in point cloud is essential in the perception system of autonomous driving. In this paper, we present LiDAR R-CNN, a second stage detector that can generally improve any existing 3D detector. To fulfill the real-time and high precision requirement in practice, we resort to point-based approach other than the popular voxel-based approach. However, we find an overlooked issue in previous work: Naively applying point-based methods like PointNet could make the learned features ignore the size of proposals. To this end, we analyze this problem in detail and propose several methods to remedy it, which bring significant performance improvement. Comprehensive experimental results on real-world datasets like Waymo Open Dataset (WOD) and KITTI dataset with various popular detectors demonstrate the universality and superiority of our LiDAR R-CNN. In particular, based on one variant of PointPillars, our method could achieve new state-of-the-art results with minor cost. Codes will be released at https://github.com/tusimple/LiDAR_RCNN .
A New Dimension in Testimony: Relighting Video with Reflectance Field Exemplars
Apr 06, 2021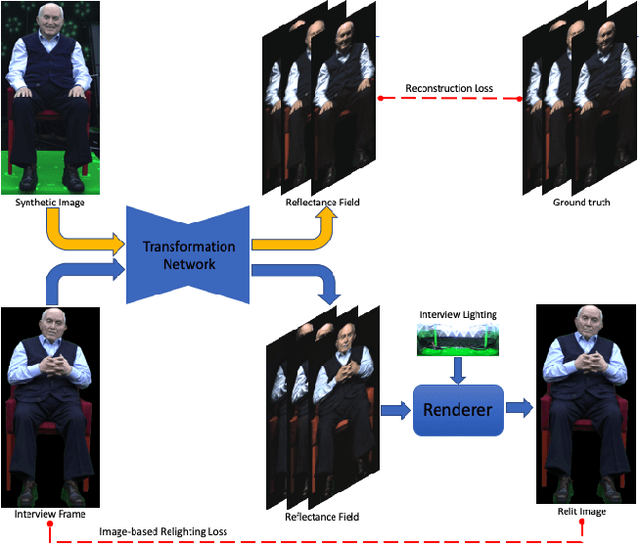
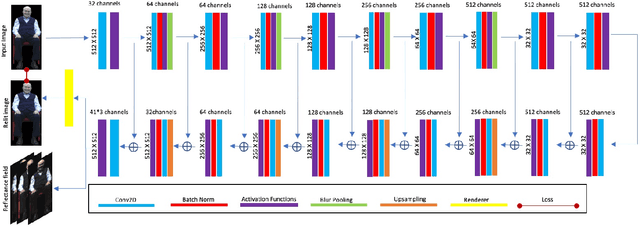


We present a learning-based method for estimating 4D reflectance field of a person given video footage illuminated under a flat-lit environment of the same subject. For training data, we use one light at a time to illuminate the subject and capture the reflectance field data in a variety of poses and viewpoints. We estimate the lighting environment of the input video footage and use the subject's reflectance field to create synthetic images of the subject illuminated by the input lighting environment. We then train a deep convolutional neural network to regress the reflectance field from the synthetic images. We also use a differentiable renderer to provide feedback for the network by matching the relit images with the input video frames. This semi-supervised training scheme allows the neural network to handle unseen poses in the dataset as well as compensate for the lighting estimation error. We evaluate our method on the video footage of the real Holocaust survivors and show that our method outperforms the state-of-the-art methods in both realism and speed.
Continual Learning on the Edge with TensorFlow Lite
May 05, 2021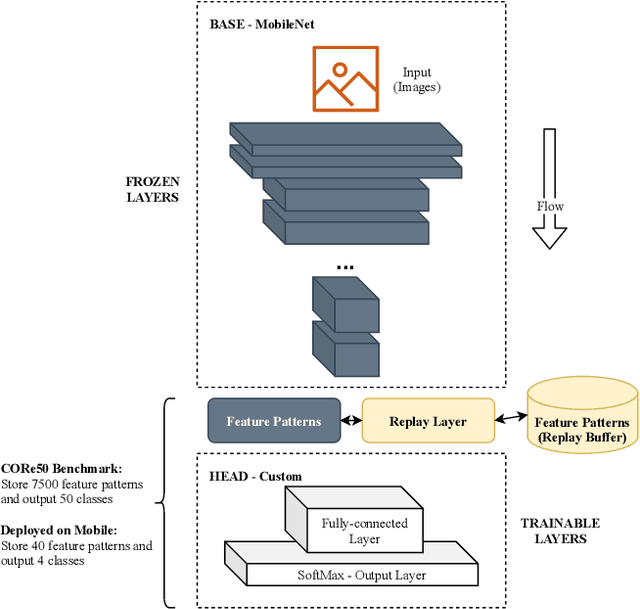
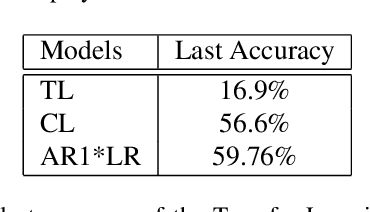
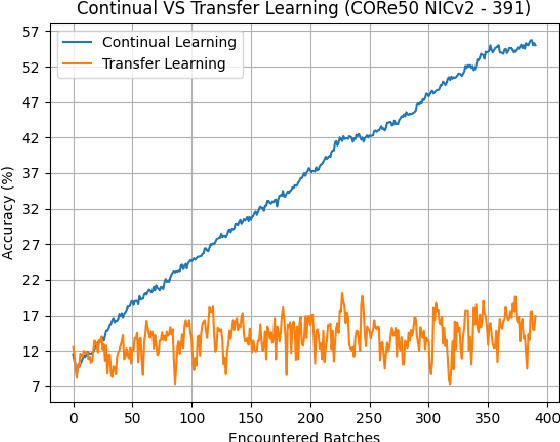
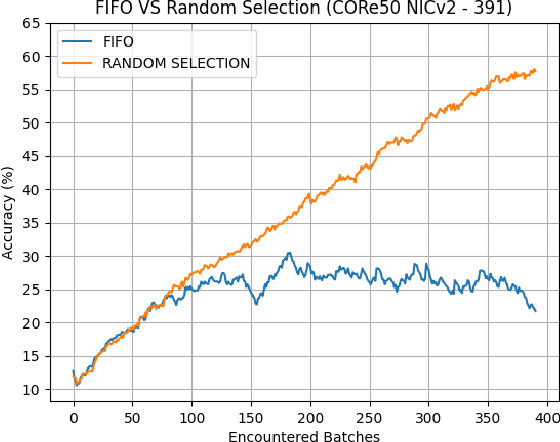
Deploying sophisticated deep learning models on embedded devices with the purpose of solving real-world problems is a struggle using today's technology. Privacy and data limitations, network connection issues, and the need for fast model adaptation are some of the challenges that constitute today's approaches unfit for many applications on the edge and make real-time on-device training a necessity. Google is currently working on tackling these challenges by embedding an experimental transfer learning API to their TensorFlow Lite, machine learning library. In this paper, we show that although transfer learning is a good first step for on-device model training, it suffers from catastrophic forgetting when faced with more realistic scenarios. We present this issue by testing a simple transfer learning model on the CORe50 benchmark as well as by demonstrating its limitations directly on an Android application we developed. In addition, we expand the TensorFlow Lite library to include continual learning capabilities, by integrating a simple replay approach into the head of the current transfer learning model. We test our continual learning model on the CORe50 benchmark to show that it tackles catastrophic forgetting, and we demonstrate its ability to continually learn, even under non-ideal conditions, using the application we developed. Finally, we open-source the code of our Android application to enable developers to integrate continual learning to their own smartphone applications, as well as to facilitate further development of continual learning functionality into the TensorFlow Lite environment.
Development of aircraft spoiler demonstrators to test strain-based SHM under realistic loading
Apr 22, 2021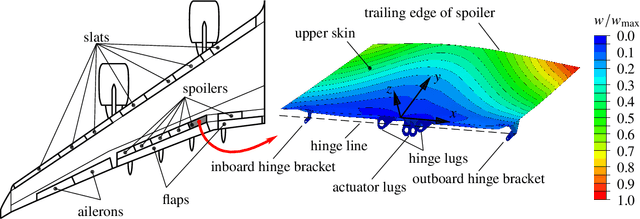
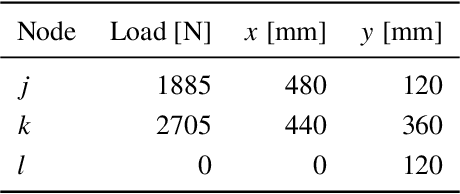
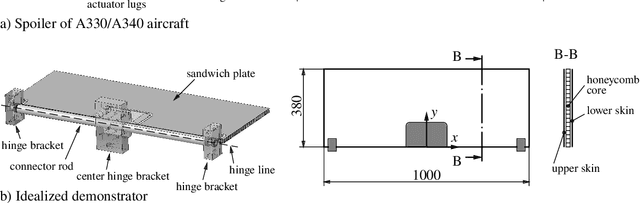

An idealized demonstrator of an civil aircraft wing spoiler in scale 1:2 is developed to evaluate strain-based structural health monitoring (SHM) methods under realistic loading conditions. SHM promises to increase operational safety and reduce maintenance costs of optimized lightweight structures by its early damage detection capabilities. Also localization and size identification of damages could be shown for simple parts, e.g. beams or plates in many laboratory experiments. However, the application of SHM systems on real structures under realistic loading conditions is cost intensive and time consuming. Furthermore, testing facilities which are large enough to fit full scale aircraft parts are often not available. The proposed procedure of developing a scaled spoiler demonstrator under idealized loading and support conditions solves these issues for strain-based SHM. The procedure shows how to reproduce the deformation shape of a real aircraft spoiler under a heavy loading condition during landing by numerical optimization. Subsequent finite element simulations and experimental measurements proved similar deformations and strain states of the idealized demonstrator and the real spoiler. Thus, using the developed idealized spoiler demonstrator strain-based SHM systems can be tested under loading conditions similar to realistic operational loads by significantly reduced test effort and costs.
DA-DGCEx: Ensuring Validity of Deep Guided Counterfactual Explanations With Distribution-Aware Autoencoder Loss
Apr 22, 2021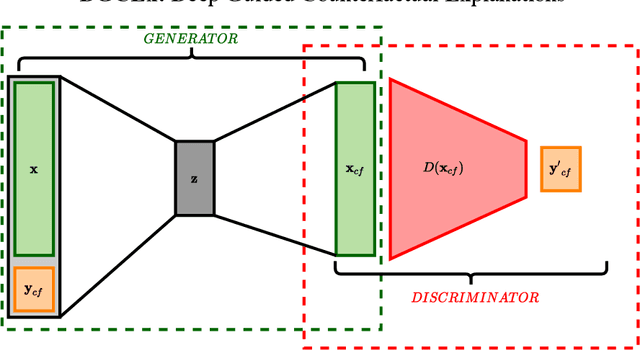
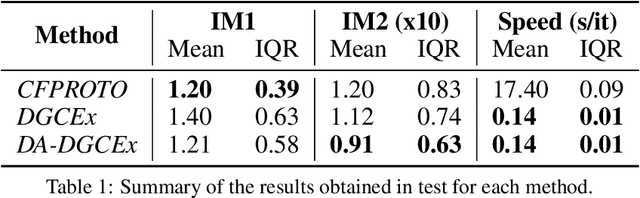
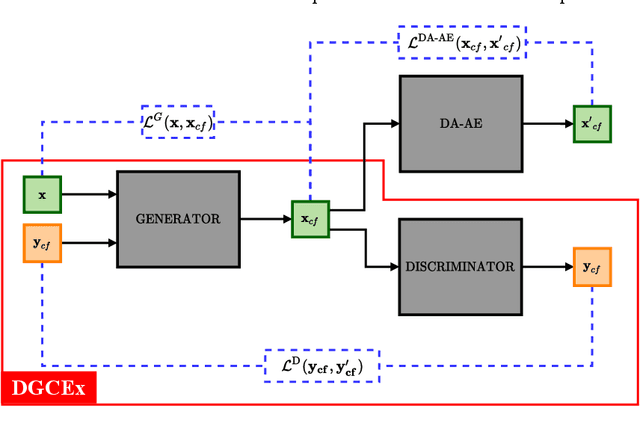
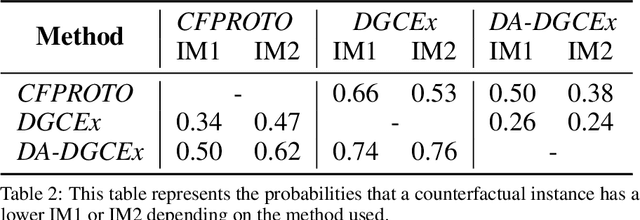
Deep Learning has become a very valuable tool in different fields, and no one doubts the learning capacity of these models. Nevertheless, since Deep Learning models are often seen as black boxes due to their lack of interpretability, there is a general mistrust in their decision-making process. To find a balance between effectiveness and interpretability, Explainable Artificial Intelligence (XAI) is gaining popularity in recent years, and some of the methods within this area are used to generate counterfactual explanations. The process of generating these explanations generally consists of solving an optimization problem for each input to be explained, which is unfeasible when real-time feedback is needed. To speed up this process, some methods have made use of autoencoders to generate instant counterfactual explanations. Recently, a method called Deep Guided Counterfactual Explanations (DGCEx) has been proposed, which trains an autoencoder attached to a classification model, in order to generate straightforward counterfactual explanations. However, this method does not ensure that the generated counterfactual instances are close to the data manifold, so unrealistic counterfactual instances may be generated. To overcome this issue, this paper presents Distribution Aware Deep Guided Counterfactual Explanations (DA-DGCEx), which adds a term to the DGCEx cost function that penalizes out of distribution counterfactual instances.
Kernel-based Reconstruction of Space-time Functions on Dynamic Graphs
May 20, 2017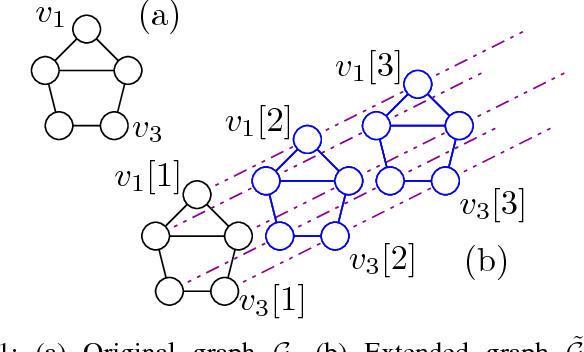
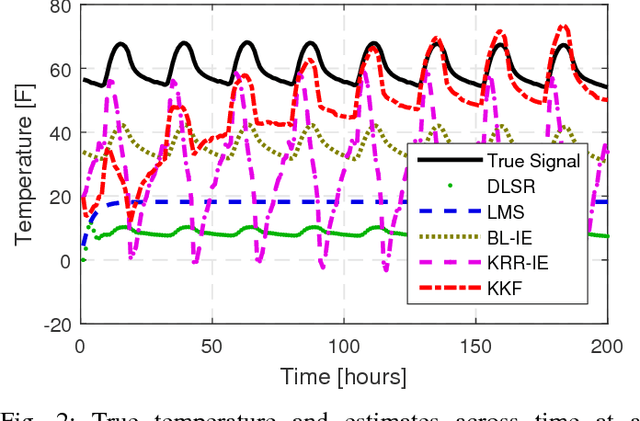
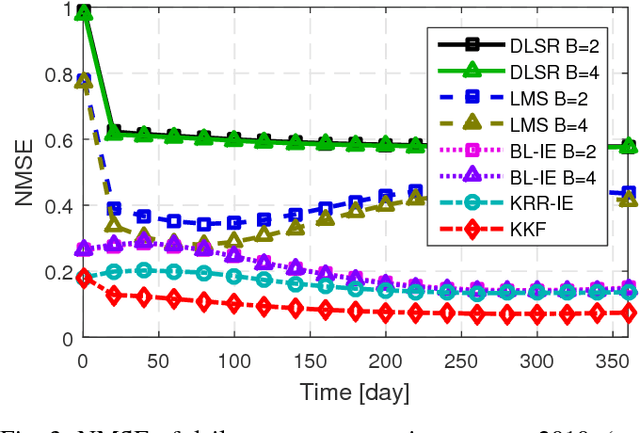
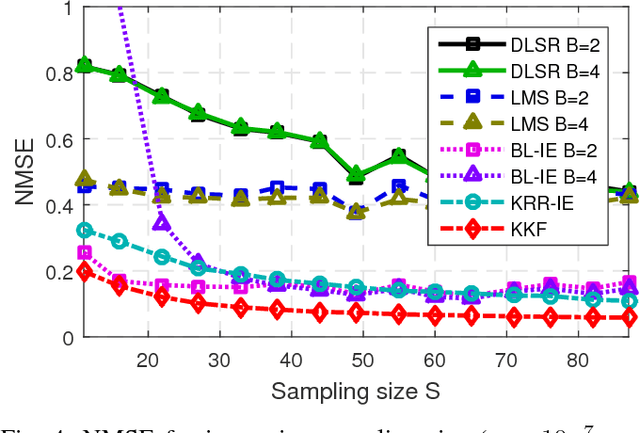
Graph-based methods pervade the inference toolkits of numerous disciplines including sociology, biology, neuroscience, physics, chemistry, and engineering. A challenging problem encountered in this context pertains to determining the attributes of a set of vertices given those of another subset at possibly different time instants. Leveraging spatiotemporal dynamics can drastically reduce the number of observed vertices, and hence the cost of sampling. Alleviating the limited flexibility of existing approaches, the present paper broadens the existing kernel-based graph function reconstruction framework to accommodate time-evolving functions over possibly time-evolving topologies. This approach inherits the versatility and generality of kernel-based methods, for which no knowledge on distributions or second-order statistics is required. Systematic guidelines are provided to construct two families of space-time kernels with complementary strengths. The first facilitates judicious control of regularization on a space-time frequency plane, whereas the second can afford time-varying topologies. Batch and online estimators are also put forth, and a novel kernel Kalman filter is developed to obtain these estimates at affordable computational cost. Numerical tests with real data sets corroborate the merits of the proposed methods relative to competing alternatives.
Data-driven formulation of natural laws by recursive-LASSO-based symbolic regression
Feb 18, 2021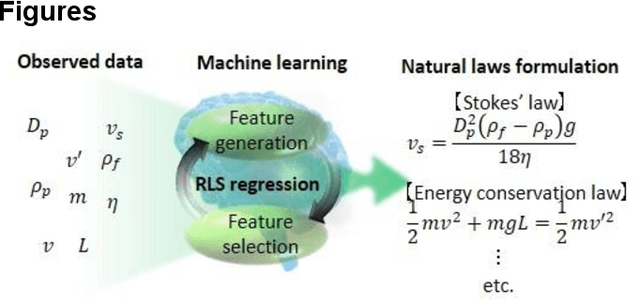
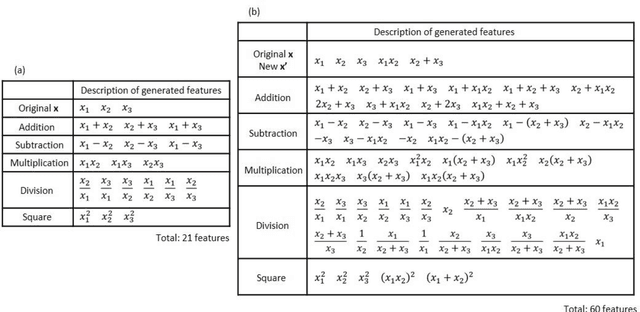
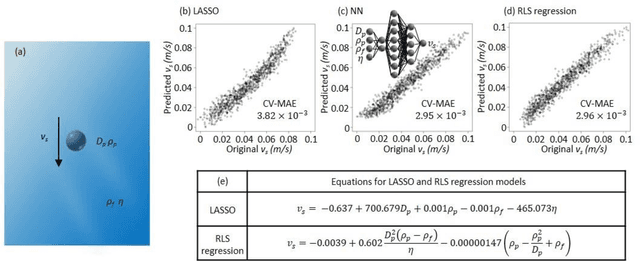
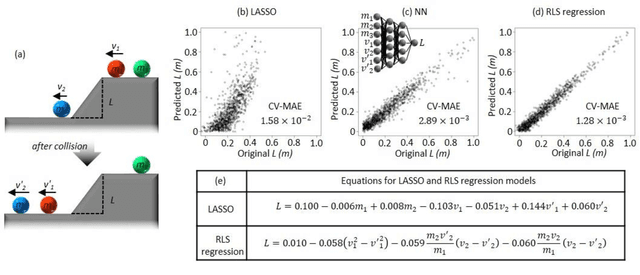
Discovery of new natural laws has for a long time relied on the inspiration of some genius. Recently, however, machine learning technologies, which analyze big data without human prejudice and bias, are expected to find novel natural laws. Here we demonstrate that our proposed machine learning, recursive-LASSO-based symbolic (RLS) regression, enables data-driven formulation of natural laws from noisy data. The RLS regression recurrently repeats feature generation and feature selection, eventually constructing a data-driven model with highly nonlinear features. This data-driven formulation method is quite general and thus can discover new laws in various scientific fields.