 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GraphBreak: Tool for Network Community based Regulatory Medicine, Gene co-expression, Linkage Disequilibrium analysis, functional annotation and more
Feb 24, 2021
Graph network science is becoming increasingly popular, notably in big-data perspective where understanding individual entities for individual functional roles is complex and time consuming. It is likely when a set of genes are regulated by a set of genetic variants, the genes set is recruited for a common or related functional purpose. Grouping and extracting communities from network of associations becomes critical to understand system complexity, thus prioritizing genes for dis-ease and functional associations. Workload is reduced when studying entities one at a time. For this, we present GraphBreak, a suite of tools for community detection application, such as for gene co-expression, protein interaction, regulation network, etc.Although developed for use case of eQTLs regulatory genomic net-work community study -- results shown with our analysis with sample eQTL data. Graphbreak can be deployed for other studies if input data has been fed in requisite format, including but not limited to gene co-expression networks, protein-protein interaction network, signaling pathway and metabolic network. Graph-Break showed critical use case value in its downstream analysis for disease association of communities detected. If all independent steps of community detection and analysis are a step-by-step sub-part of the algorithm, GraphBreak can be considered a new algorithm for community based functional characterization. Combination of various algorithmic implementation modules into a single script for this purpose illustrates GraphBreak novelty. Compared to other similar tools, with GraphBreak we can better detect communities with over-representation of its member genes for statistical association with diseases, therefore target genes which can be prioritized for drug-positioning or drug-re-positioning as the case be.
Deep Learning for Virus-Spreading Forecasting: a Brief Survey
Mar 03, 2021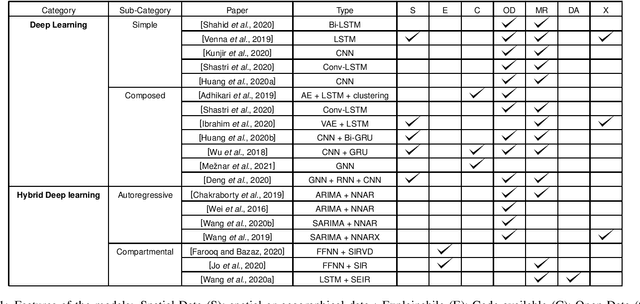
The advent of the coronavirus pandemic has sparked the interest in predictive models capable of forecasting virus-spreading, especially for boosting and supporting decision-making processes. In this paper, we will outline the main Deep Learning approaches aimed at predicting the spreading of a disease in space and time. The aim is to show the emerging trends in this area of research and provide a general perspective on the possible strategies to approach this problem. In doing so, we will mainly focus on two macro-categories: classical Deep Learning approaches and Hybrid models. Finally, we will discuss the main advantages and disadvantages of different models, and underline the most promising development directions to improve these approaches.
Recognition and Processing of NATOM
Apr 29, 2021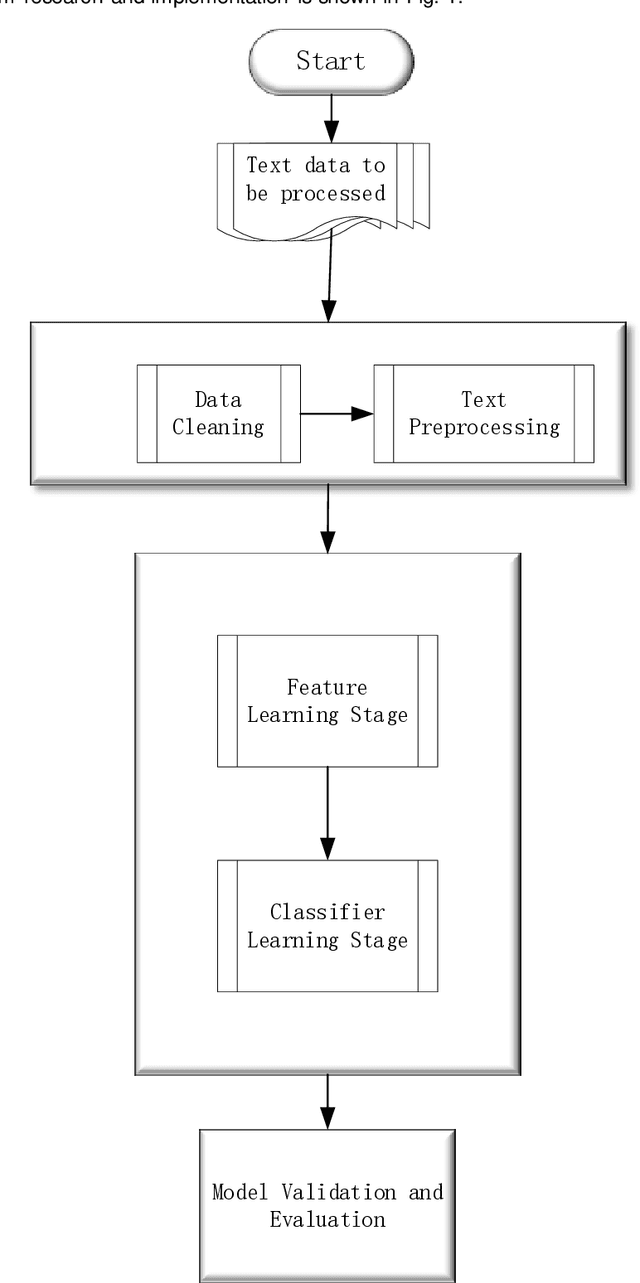
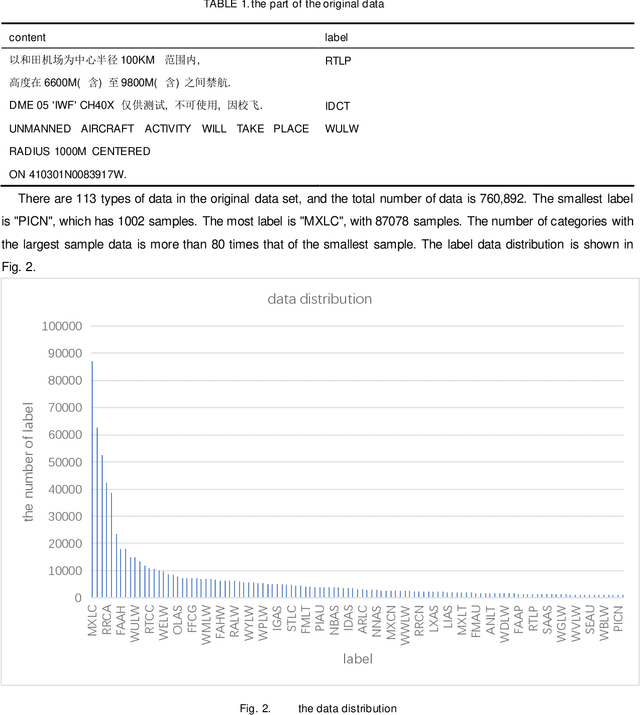
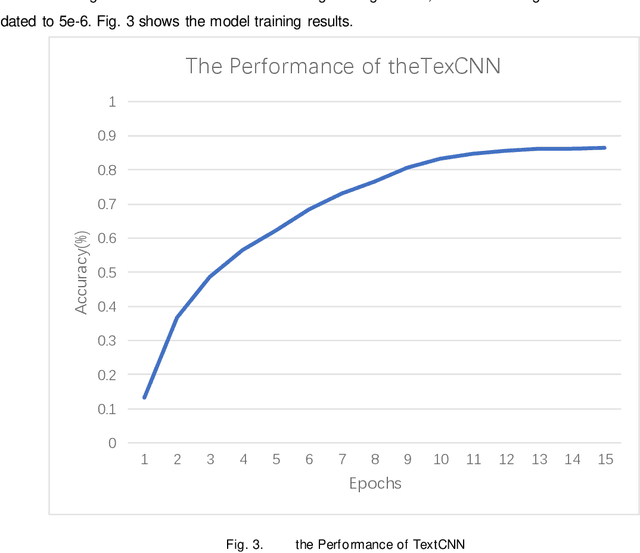

In this paper we show how to process the NOTAM (Notice to Airmen) data of the field in civil aviation. The main research contents are as follows: 1.Data preprocessing: For the original data of the NOTAM, there is a mixture of Chinese and English, and the structure is poor. The original data is cleaned, the Chinese data and the English data are processed separately, word segmentation is completed, and stopping-words are removed. Using Glove word vector methods to represent the data for using a custom mapping vocabulary. 2.Decoupling features and classifiers: In order to improve the ability of the text classification model to recognize minority samples, the overall model training process is decoupled from the perspective of the algorithm as a whole, divided into two stages of feature learning and classifier learning. The weights of the feature learning stage and the classifier learning stage adopt different strategies to overcome the influence of the head data and tail data of the imbalanced data set on the classification model. Experiments have proved that the use of decoupling features and classifier methods based on the neural network classification model can complete text multi-classification tasks in the field of civil aviation, and at the same time can improve the recognition accuracy of the minority samples in the data set.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 15, 2021

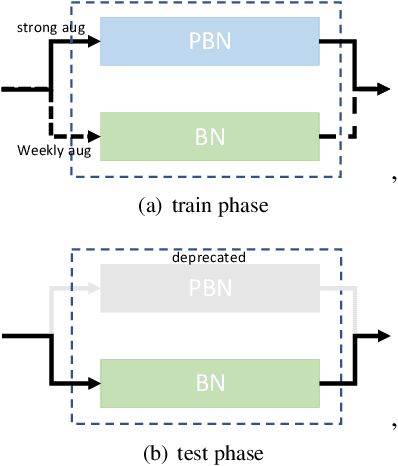

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
Stagnation Detection in Highly Multimodal Fitness Landscapes
Apr 22, 2021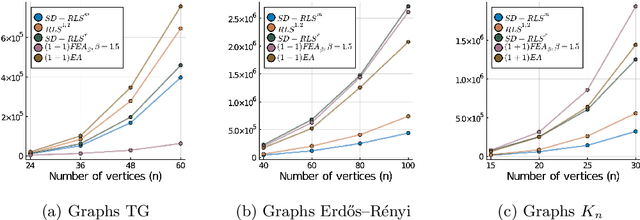
Stagnation detection has been proposed as a mechanism for randomized search heuristics to escape from local optima by automatically increasing the size of the neighborhood to find the so-called gap size, i.e., the distance to the next improvement. Its usefulness has mostly been considered in simple multimodal landscapes with few local optima that could be crossed one after another. In multimodal landscapes with a more complex location of optima of similar gap size, stagnation detection suffers from the fact that the neighborhood size is frequently reset to $1$ without using gap sizes that were promising in the past. In this paper, we investigate a new mechanism called radius memory which can be added to stagnation detection to control the search radius more carefully by giving preference to values that were successful in the past. We implement this idea in an algorithm called SD-RLS$^{\text{m}}$ and show compared to previous variants of stagnation detection that it yields speed-ups for linear functions under uniform constraints and the minimum spanning tree problem. Moreover, its running time does not significantly deteriorate on unimodal functions and a generalization of the Jump benchmark. Finally, we present experimental results carried out to study SD-RLS$^{\text{m}}$ and compare it with other algorithms.
Distributed Learning over Markovian Fading Channels for Stable Spectrum Access
Jan 27, 2021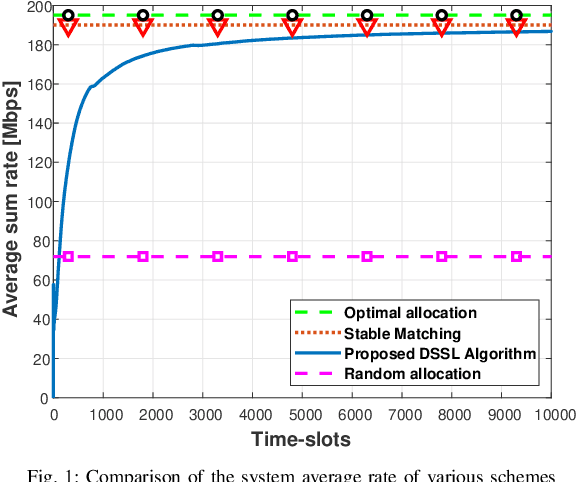
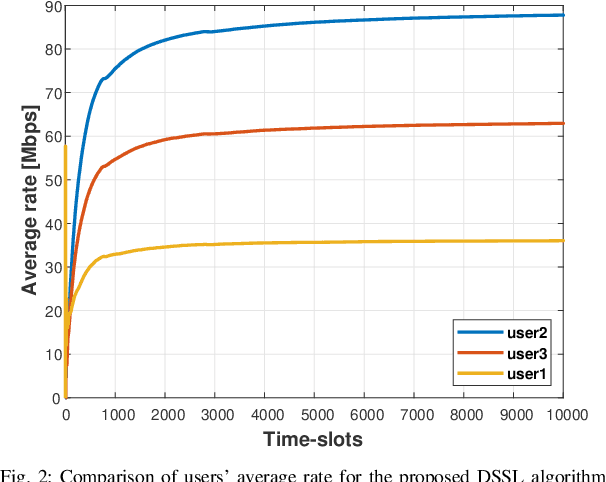
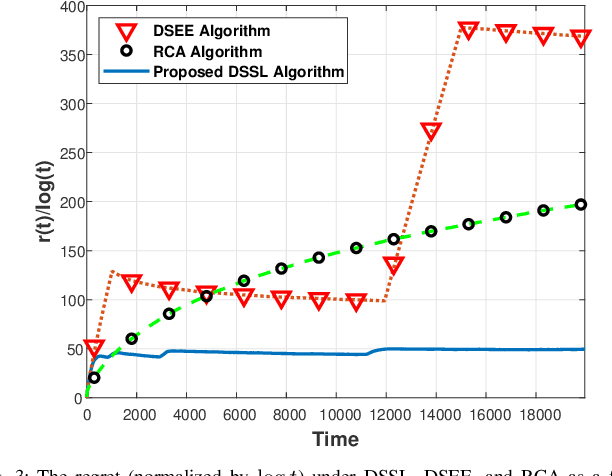
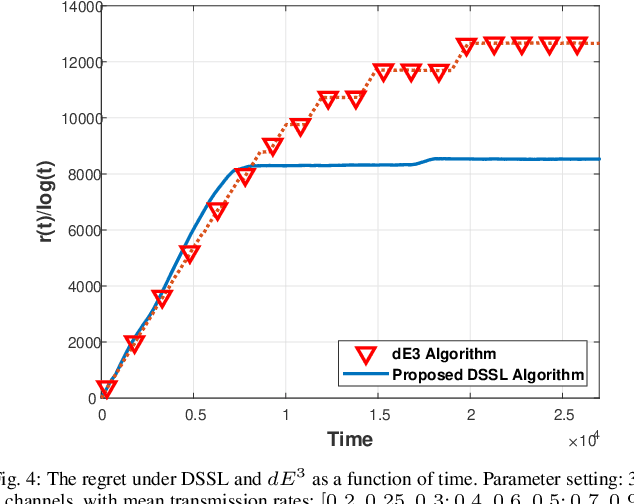
We consider the problem of multi-user spectrum access in wireless networks. The bandwidth is divided into K orthogonal channels, and M users aim to access the spectrum. Each user chooses a single channel for transmission at each time slot. The state of each channel is modeled by a restless unknown Markovian process. Previous studies have analyzed a special case of this setting, in which each channel yields the same expected rate for all users. By contrast, we consider a more general and practical model, where each channel yields a different expected rate for each user. This model adds a significant challenge of how to efficiently learn a channel allocation in a distributed manner to yield a global system-wide objective. We adopt the stable matching utility as the system objective, which is known to yield strong performance in multichannel wireless networks, and develop a novel Distributed Stable Strategy Learning (DSSL) algorithm to achieve the objective. We prove theoretically that DSSL converges to the stable matching allocation, and the regret, defined as the loss in total rate with respect to the stable matching solution, has a logarithmic order with time. Finally, simulation results demonstrate the strong performance of the DSSL algorithm.
Modeling disease progression in longitudinal EHR data using continuous-time hidden Markov models
Dec 03, 2018


Modeling disease progression in healthcare administrative databases is complicated by the fact that patients are observed only at irregular intervals when they seek healthcare services. In a longitudinal cohort of 76,888 patients with chronic obstructive pulmonary disease (COPD), we used a continuous-time hidden Markov model with a generalized linear model to model healthcare utilization events. We found that the fitted model provides interpretable results suitable for summarization and hypothesis generation.
Fusion of Real Time Thermal Image and 1D/2D/3D Depth Laser Readings for Remote Thermal Sensing in Industrial Plants by Means of UAVs and/or Robots
Jun 01, 2020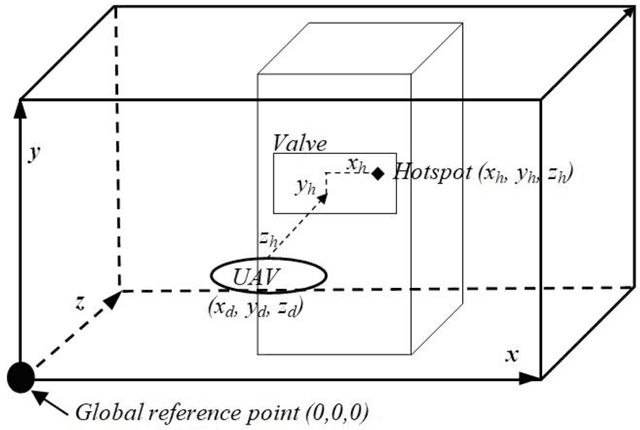


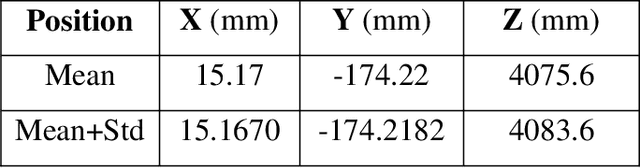
This paper presents fast procedures for thermal infrared remote sensing in dark, GPS-denied environments, such as those found in industrial plants such as in High-Voltage Direct Current (HVDC) converter stations. These procedures are based on the combination of the depth estimation obtained from either a 1-Dimensional LIDAR laser or a 2-Dimensional Hokuyo laser or a 3D MultiSense SLB laser sensor and the visible and thermal cameras from a FLIR Duo R dual-sensor thermal camera. The combination of these sensors/cameras is suitable to be mounted on Unmanned Aerial Vehicles (UAVs) and/or robots in order to provide reliable information about the potential malfunctions, which can be found within the hazardous environment. For example, the capabilities of the developed software and hardware system corresponding to the combination of the 1-D LIDAR sensor and the FLIR Duo R dual-sensor thermal camera is assessed from the point of the accuracy of results and the required computational times: the obtained computational times are under 10 ms, with a maximum localization error of 8 mm and an average standard deviation for the measured temperatures of 1.11 degree Celsius, which results are obtained for a number of test cases. The paper is structured as follows: the description of the system used for identification and localization of hotspots in industrial plants is presented in section II. In section III, the method for faults identification and localization in plants by using a 1-Dimensional LIDAR laser sensor and thermal images is described together with results. In section IV the real time thermal image processing is presented. Fusion of the 2-Dimensional depth laser Hokuyo and the thermal images is described in section V. In section VI the combination of the 3D MultiSense SLB laser and thermal images is described. In section VII a discussion and several conclusions are drawn.
An Automated Approach for Timely Diagnosis and Prognosis of Coronavirus Disease
Apr 29, 2021
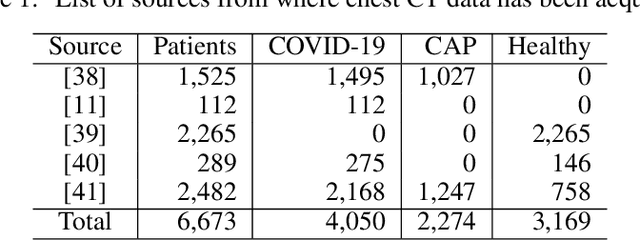

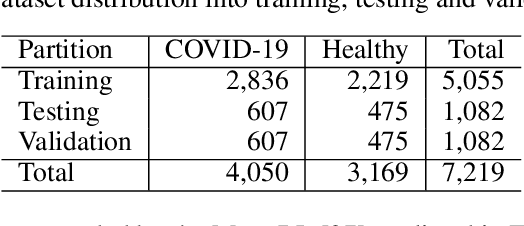
Since the outbreak of Coronavirus Disease 2019 (COVID-19), most of the impacted patients have been diagnosed with high fever, dry cough, and soar throat leading to severe pneumonia. Hence, to date, the diagnosis of COVID-19 from lung imaging is proved to be a major evidence for early diagnosis of the disease. Although nucleic acid detection using real-time reverse-transcriptase polymerase chain reaction (rRT-PCR) remains a gold standard for the detection of COVID-19, the proposed approach focuses on the automated diagnosis and prognosis of the disease from a non-contrast chest computed tomography (CT)scan for timely diagnosis and triage of the patient. The prognosis covers the quantification and assessment of the disease to help hospitals with the management and planning of crucial resources, such as medical staff, ventilators and intensive care units (ICUs) capacity. The approach utilises deep learning techniques for automated quantification of the severity of COVID-19 disease via measuring the area of multiple rounded ground-glass opacities (GGO) and consolidations in the periphery (CP) of the lungs and accumulating them to form a severity score. The severity of the disease can be correlated with the medicines prescribed during the triage to assess the effectiveness of the treatment. The proposed approach shows promising results where the classification model achieved 93% accuracy on hold-out data.
* to be published in IJCNN 2021
Leveraging Multiple Relations for Fashion Trend Forecasting Based on Social Media
May 11, 2021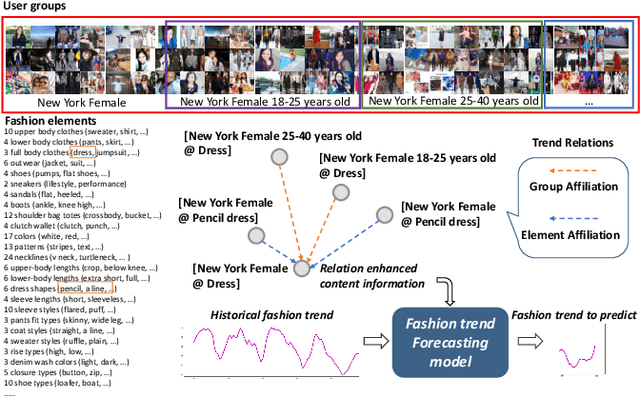
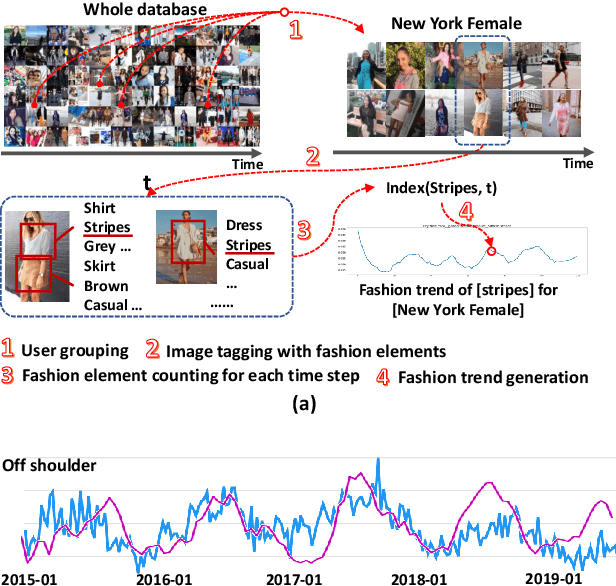
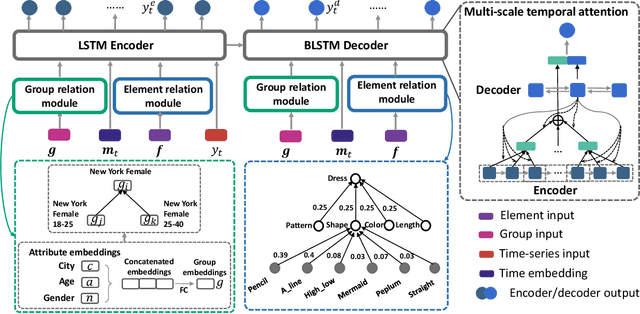
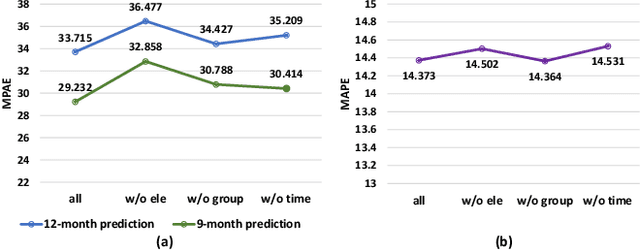
Fashion trend forecasting is of great research significance in providing useful suggestions for both fashion companies and fashion lovers. Although various studies have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real complex fashion trends. Moreover, the mainstream solutions for this task are still statistical-based and solely focus on time-series data modeling, which limit the forecast accuracy. Towards insightful fashion trend forecasting, previous work [1] proposed to analyze more fine-grained fashion elements which can informatively reveal fashion trends. Specifically, it focused on detailed fashion element trend forecasting for specific user groups based on social media data. In addition, it proposed a neural network-based method, namely KERN, to address the problem of fashion trend modeling and forecasting. In this work, to extend the previous work, we propose an improved model named Relation Enhanced Attention Recurrent (REAR) network. Compared to KERN, the REAR model leverages not only the relations among fashion elements but also those among user groups, thus capturing more types of correlations among various fashion trends. To further improve the performance of long-range trend forecasting, the REAR method devises a sliding temporal attention mechanism, which is able to capture temporal patterns on future horizons better. Extensive experiments and more analysis have been conducted on the FIT and GeoStyle datasets to evaluate the performance of REAR. Experimental and analytical results demonstrate the effectiveness of the proposed REAR model in fashion trend forecasting, which also show the improvement of REAR compared to the KERN.
* 12 pages, 8 figures