 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recognition and Processing of NATOM
Apr 29, 2021
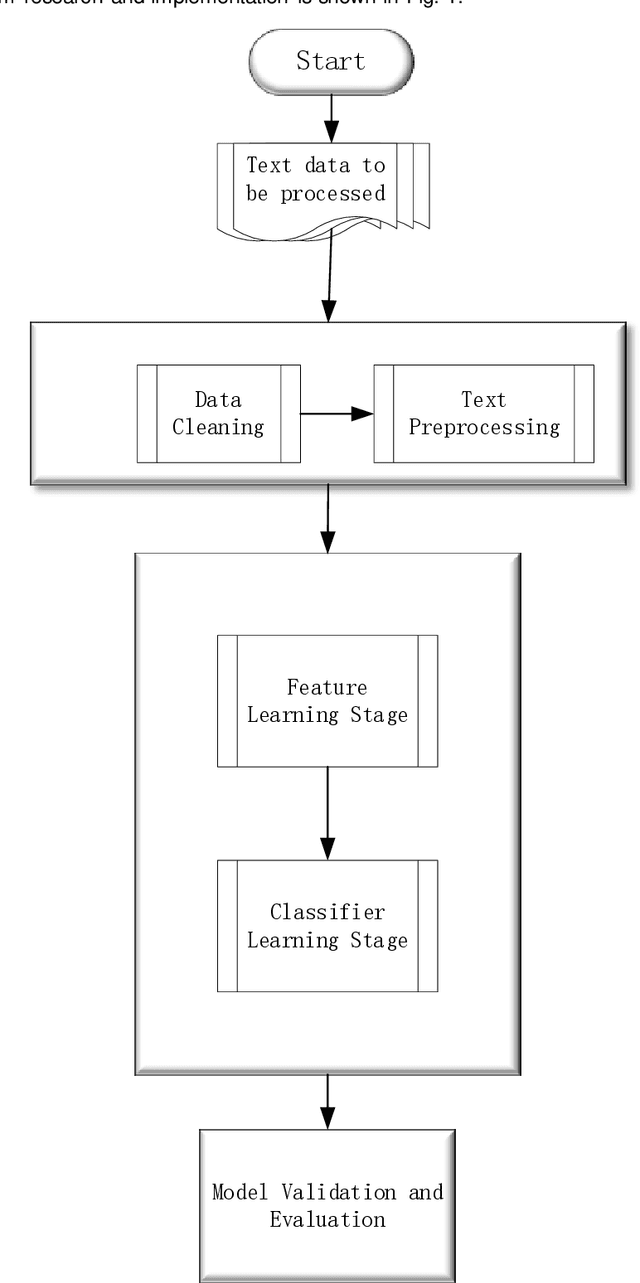
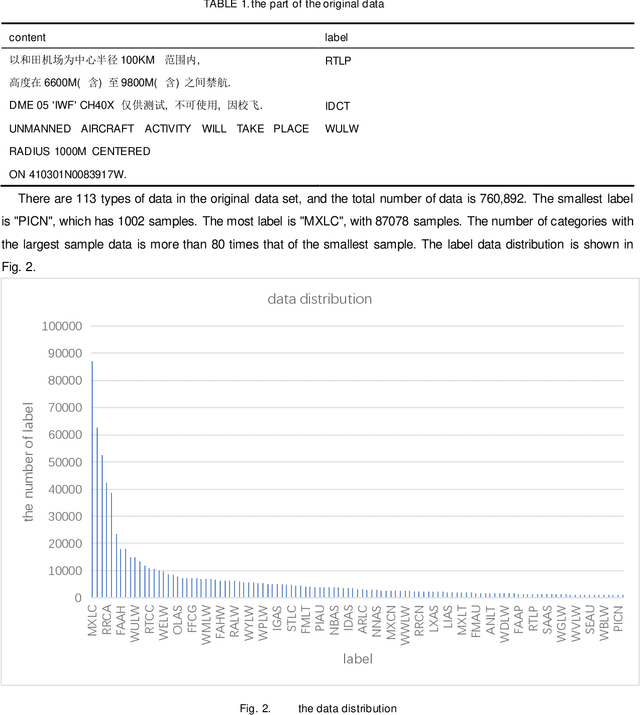
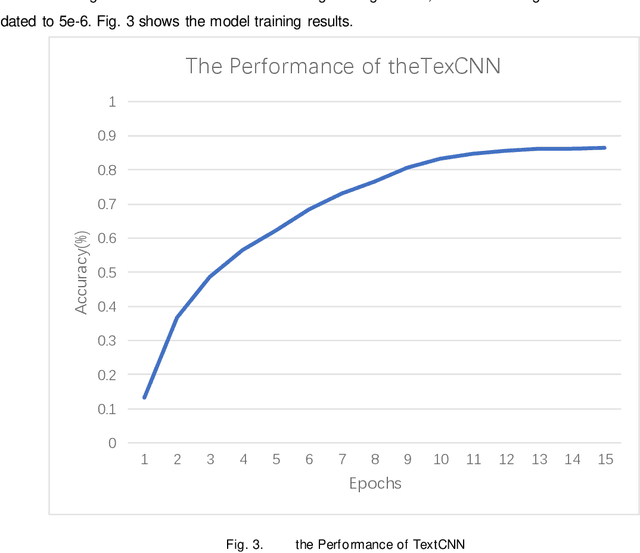

In this paper we show how to process the NOTAM (Notice to Airmen) data of the field in civil aviation. The main research contents are as follows: 1.Data preprocessing: For the original data of the NOTAM, there is a mixture of Chinese and English, and the structure is poor. The original data is cleaned, the Chinese data and the English data are processed separately, word segmentation is completed, and stopping-words are removed. Using Glove word vector methods to represent the data for using a custom mapping vocabulary. 2.Decoupling features and classifiers: In order to improve the ability of the text classification model to recognize minority samples, the overall model training process is decoupled from the perspective of the algorithm as a whole, divided into two stages of feature learning and classifier learning. The weights of the feature learning stage and the classifier learning stage adopt different strategies to overcome the influence of the head data and tail data of the imbalanced data set on the classification model. Experiments have proved that the use of decoupling features and classifier methods based on the neural network classification model can complete text multi-classification tasks in the field of civil aviation, and at the same time can improve the recognition accuracy of the minority samples in the data set.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 15, 2021

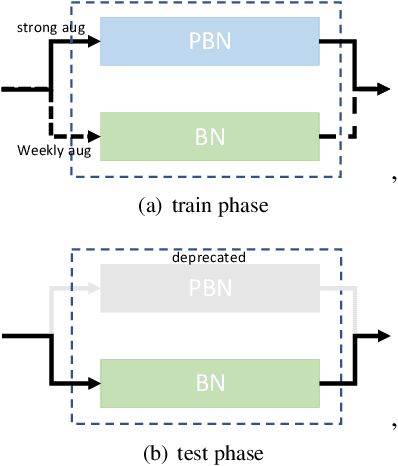

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
Parameter and density estimation from real-world traffic data: A kinetic compartmental approach
Jan 27, 2021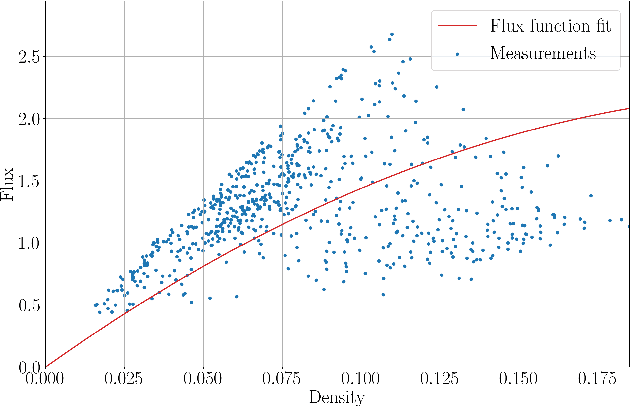
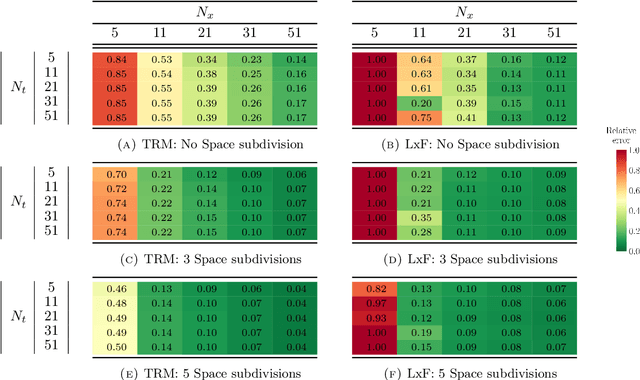
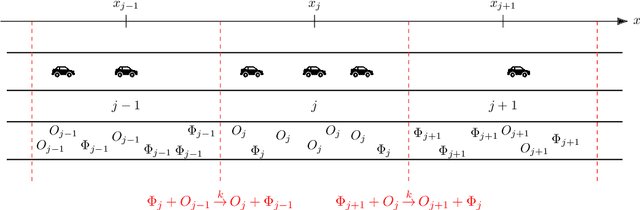
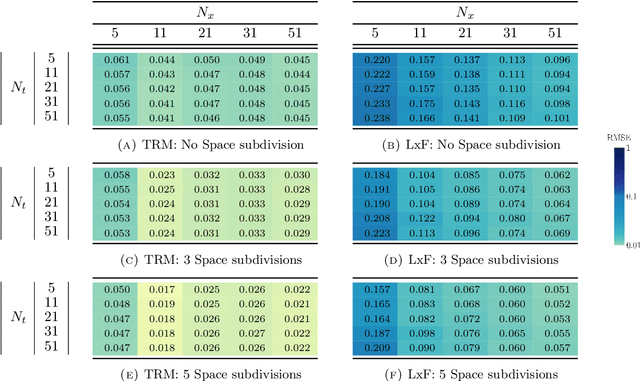
The main motivation of this work is to assess the validity of a LWR traffic flow model to model measurements obtained from trajectory data, and propose extensions of this model to improve it. A formulation for a discrete dynamical system is proposed aiming at reproducing the evolution in time of the density of vehicles along a road, as observed in the measurements. This system is formulated as a chemical reaction network where road cells are interpreted as compartments, the transfer of vehicles from one cell to the other is seen as a chemical reaction between adjacent compartment and the density of vehicles is seen as a concentration of reactant. Several degrees of flexibility on the parameters of this system, which basically consist of the reaction rates between the compartments, can be considered: a constant value or a function depending on time and/or space. Density measurements coming from trajectory data are then interpreted as observations of the states of this system at consecutive times. Optimal reaction rates for the system are then obtained by minimizing the discrepancy between the output of the system and the state measurements. This approach was tested both on simulated and real data, proved successful in recreating the complexity of traffic flows despite the assumptions on the flux-density relation.
Dynamic Image for 3D MRI Image Alzheimer's Disease Classification
Nov 30, 2020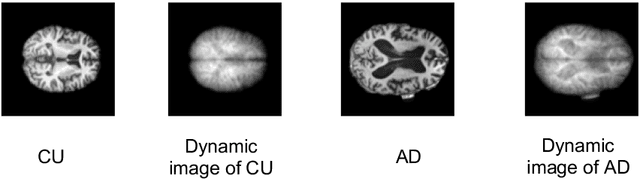
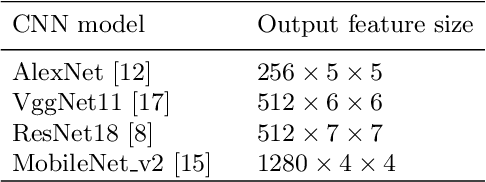
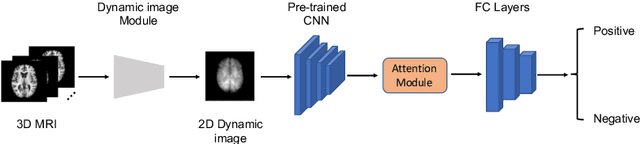
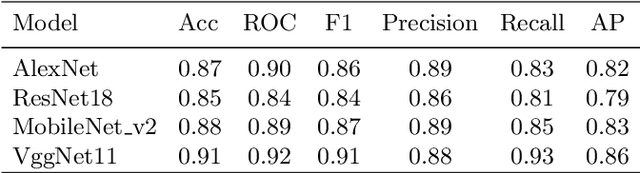
We propose to apply a 2D CNN architecture to 3D MRI image Alzheimer's disease classification. Training a 3D convolutional neural network (CNN) is time-consuming and computationally expensive. We make use of approximate rank pooling to transform the 3D MRI image volume into a 2D image to use as input to a 2D CNN. We show our proposed CNN model achieves $9.5\%$ better Alzheimer's disease classification accuracy than the baseline 3D models. We also show that our method allows for efficient training, requiring only 20% of the training time compared to 3D CNN models. The code is available online: https://github.com/UkyVision/alzheimer-project.
Stagnation Detection in Highly Multimodal Fitness Landscapes
Apr 22, 2021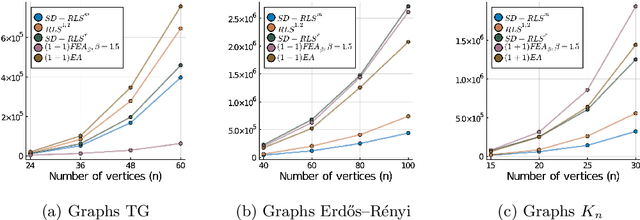
Stagnation detection has been proposed as a mechanism for randomized search heuristics to escape from local optima by automatically increasing the size of the neighborhood to find the so-called gap size, i.e., the distance to the next improvement. Its usefulness has mostly been considered in simple multimodal landscapes with few local optima that could be crossed one after another. In multimodal landscapes with a more complex location of optima of similar gap size, stagnation detection suffers from the fact that the neighborhood size is frequently reset to $1$ without using gap sizes that were promising in the past. In this paper, we investigate a new mechanism called radius memory which can be added to stagnation detection to control the search radius more carefully by giving preference to values that were successful in the past. We implement this idea in an algorithm called SD-RLS$^{\text{m}}$ and show compared to previous variants of stagnation detection that it yields speed-ups for linear functions under uniform constraints and the minimum spanning tree problem. Moreover, its running time does not significantly deteriorate on unimodal functions and a generalization of the Jump benchmark. Finally, we present experimental results carried out to study SD-RLS$^{\text{m}}$ and compare it with other algorithms.
GraphBreak: Tool for Network Community based Regulatory Medicine, Gene co-expression, Linkage Disequilibrium analysis, functional annotation and more
Feb 24, 2021Graph network science is becoming increasingly popular, notably in big-data perspective where understanding individual entities for individual functional roles is complex and time consuming. It is likely when a set of genes are regulated by a set of genetic variants, the genes set is recruited for a common or related functional purpose. Grouping and extracting communities from network of associations becomes critical to understand system complexity, thus prioritizing genes for dis-ease and functional associations. Workload is reduced when studying entities one at a time. For this, we present GraphBreak, a suite of tools for community detection application, such as for gene co-expression, protein interaction, regulation network, etc.Although developed for use case of eQTLs regulatory genomic net-work community study -- results shown with our analysis with sample eQTL data. Graphbreak can be deployed for other studies if input data has been fed in requisite format, including but not limited to gene co-expression networks, protein-protein interaction network, signaling pathway and metabolic network. Graph-Break showed critical use case value in its downstream analysis for disease association of communities detected. If all independent steps of community detection and analysis are a step-by-step sub-part of the algorithm, GraphBreak can be considered a new algorithm for community based functional characterization. Combination of various algorithmic implementation modules into a single script for this purpose illustrates GraphBreak novelty. Compared to other similar tools, with GraphBreak we can better detect communities with over-representation of its member genes for statistical association with diseases, therefore target genes which can be prioritized for drug-positioning or drug-re-positioning as the case be.
Deep Learning for Virus-Spreading Forecasting: a Brief Survey
Mar 03, 2021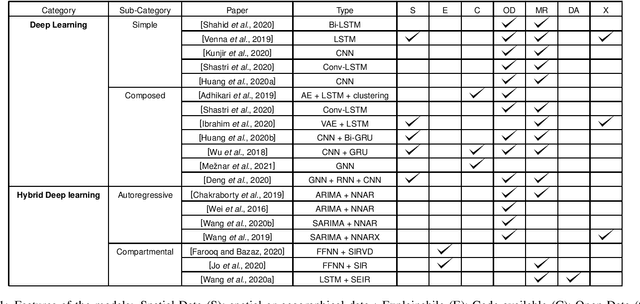
The advent of the coronavirus pandemic has sparked the interest in predictive models capable of forecasting virus-spreading, especially for boosting and supporting decision-making processes. In this paper, we will outline the main Deep Learning approaches aimed at predicting the spreading of a disease in space and time. The aim is to show the emerging trends in this area of research and provide a general perspective on the possible strategies to approach this problem. In doing so, we will mainly focus on two macro-categories: classical Deep Learning approaches and Hybrid models. Finally, we will discuss the main advantages and disadvantages of different models, and underline the most promising development directions to improve these approaches.
LSTM-based Space Occupancy Prediction towards Efficient Building Energy Management
Dec 15, 2020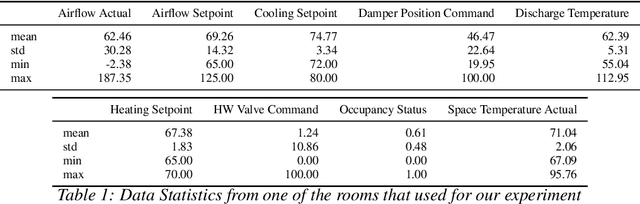
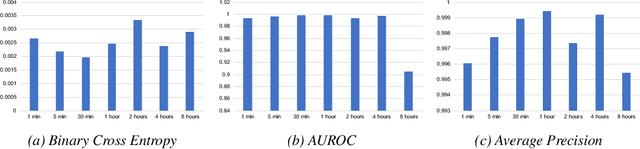
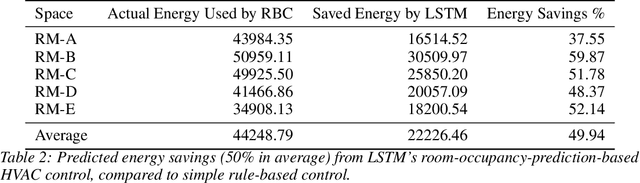
Energy consumed in buildings takes significant portions of the total global energy usage. A large amount of building energy is used for heating, cooling, ventilation, and air-conditioning (HVAC). However, compared to its importance, building energy management systems nowadays are limited in controlling HVAC based on simple rule-based control (RBC) technologies. The ability to design systems that can efficiently manage HVAC can reduce energy usage and greenhouse gas emissions, and, all in all, it can help us to mitigate climate change. This paper proposes predictive time-series models of occupancy patterns using LSTM. Prediction signal for future room occupancy status on the next time span (e.g., next 30 minutes) can be directly used to operate HVAC. For example, based on the prediction and considering the time for cooling or heating, HVAC can be turned on before the room is being used (e.g., turn on 10 minutes earlier). Also, based on the next room empty prediction timing, HVAC can be turned off earlier, and it can help us increase the efficiency of HVAC while not decreasing comfort. We demonstrate our approach's capabilities using real-world energy data collected from multiple rooms of a university building. We show that LSTM's room occupancy prediction based HVAC control could save energy usage by 50% compared to conventional RBC based control.
Musical Chair: Efficient Real-Time Recognition Using Collaborative IoT Devices
Mar 21, 2018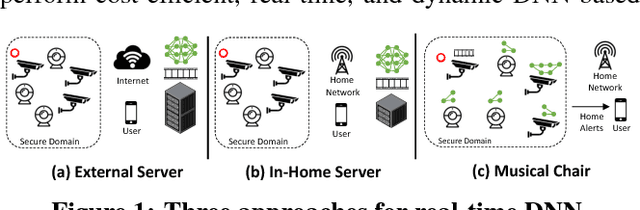

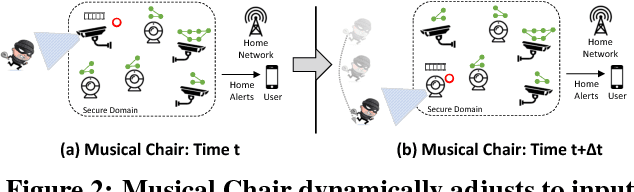

The prevalence of Internet of things (IoT) devices and abundance of sensor data has created an increase in real-time data processing such as recognition of speech, image, and video. While currently such processes are offloaded to the computationally powerful cloud system, a localized and distributed approach is desirable because (i) it preserves the privacy of users and (ii) it omits the dependency on cloud services. However, IoT networks are usually composed of resource-constrained devices, and a single device is not powerful enough to process real-time data. To overcome this challenge, we examine data and model parallelism for such devices in the context of deep neural networks. We propose Musical Chair to enable efficient, localized, and dynamic real-time recognition by harvesting the aggregated computational power from the resource-constrained devices in the same IoT network as input sensors. Musical chair adapts to the availability of computing devices at runtime and adjusts to the inherit dynamics of IoT networks. To demonstrate Musical Chair, on a network of Raspberry PIs (up to 12) each connected to a camera, we implement a state-of-the-art action recognition model for videos and two recognition models for images. Compared to the Tegra TX2, an embedded low-power platform with a six-core CPU and a GPU, our distributed action recognition system achieves not only similar energy consumption but also twice the performance of the TX2. Furthermore, in image recognition, Musical Chair achieves similar performance and saves dynamic energy.
Dynamic Resource-aware Corner Detection for Bio-inspired Vision Sensors
Oct 29, 2020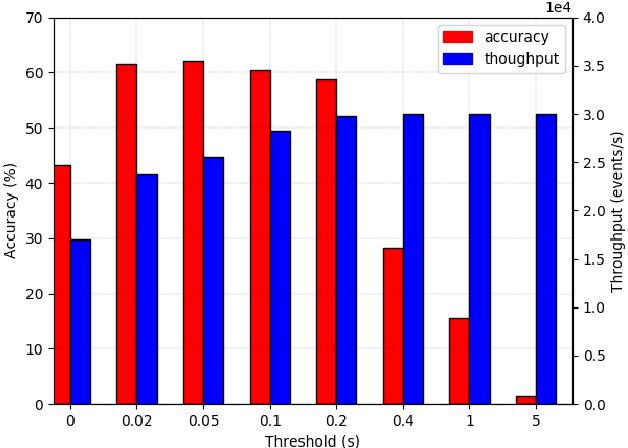

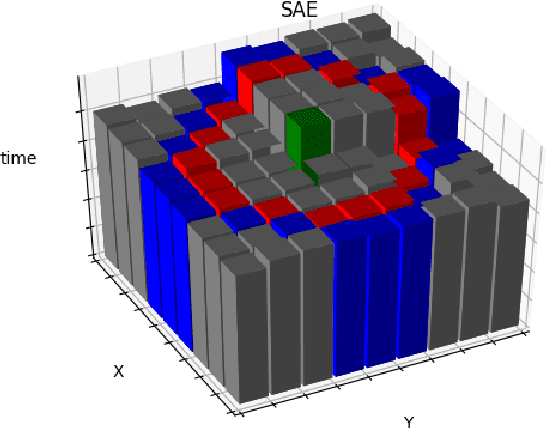
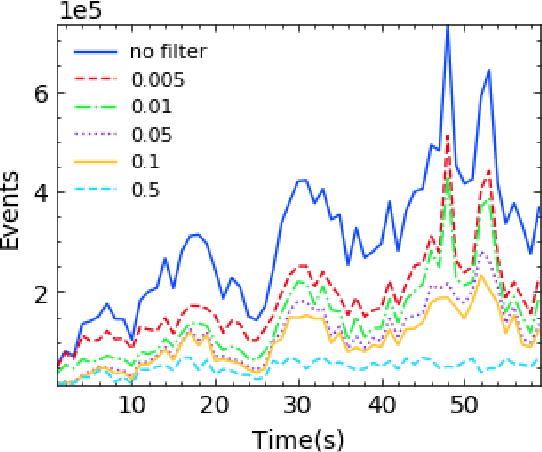
Event-based cameras are vision devices that transmit only brightness changes with low latency and ultra-low power consumption. Such characteristics make event-based cameras attractive in the field of localization and object tracking in resource-constrained systems. Since the number of generated events in such cameras is huge, the selection and filtering of the incoming events are beneficial from both increasing the accuracy of the features and reducing the computational load. In this paper, we present an algorithm to detect asynchronous corners from a stream of events in real-time on embedded systems. The algorithm is called the Three Layer Filtering-Harris or TLF-Harris algorithm. The algorithm is based on an events' filtering strategy whose purpose is 1) to increase the accuracy by deliberately eliminating some incoming events, i.e., noise, and 2) to improve the real-time performance of the system, i.e., preserving a constant throughput in terms of input events per second, by discarding unnecessary events with a limited accuracy loss. An approximation of the Harris algorithm, in turn, is used to exploit its high-quality detection capability with a low-complexity implementation to enable seamless real-time performance on embedded computing platforms. The proposed algorithm is capable of selecting the best corner candidate among neighbors and achieves an average execution time savings of 59 % compared with the conventional Harris score. Moreover, our approach outperforms the competing methods, such as eFAST, eHarris, and FA-Harris, in terms of real-time performance, and surpasses Arc* in terms of accuracy.