 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Equilibrium Inverse Reinforcement Learning for Ride-hailing Vehicle Network
Feb 13, 2021
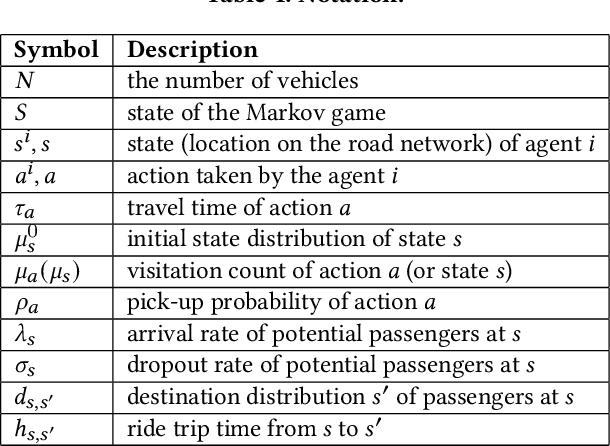
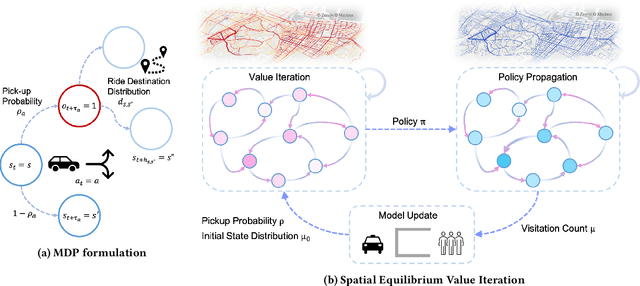
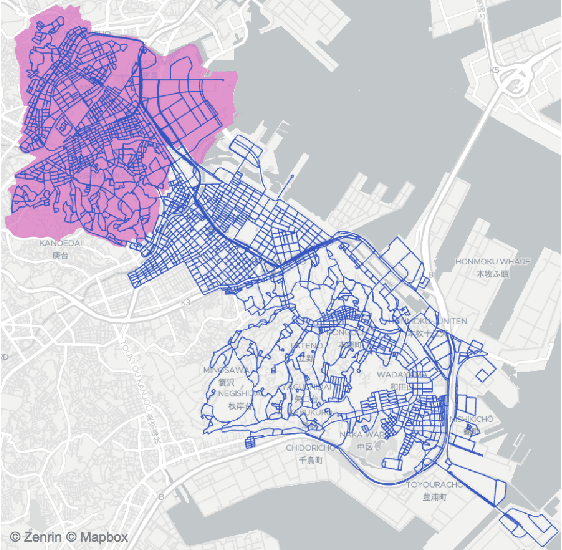
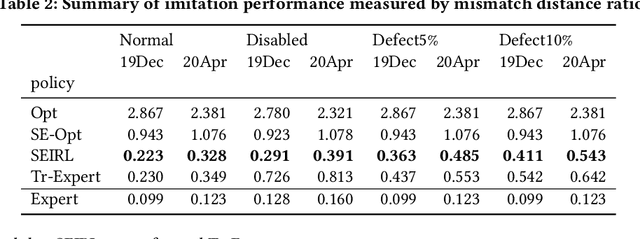
Ubiquitous mobile computing have enabled ride-hailing services to collect vast amounts of behavioral data of riders and drivers and optimize supply and demand matching in real time. While these mobility service providers have some degree of control over the market by assigning vehicles to requests, they need to deal with the uncertainty arising from self-interested driver behavior since workers are usually free to drive when they are not assigned tasks. In this work, we formulate the problem of passenger-vehicle matching in a sparsely connected graph and proposed an algorithm to derive an equilibrium policy in a multi-agent environment. Our framework combines value iteration methods to estimate the optimal policy given expected state visitation and policy propagation to compute multi-agent state visitation frequencies. Furthermore, we developed a method to learn the driver's reward function transferable to an environment with significantly different dynamics from training data. We evaluated the robustness to changes in spatio-temporal supply-demand distributions and deterioration in data quality using a real-world taxi trajectory dataset; our approach significantly outperforms several baselines in terms of imitation accuracy. The computational time required to obtain an equilibrium policy shared by all vehicles does not depend on the number of agents, and even on the scale of real-world services, it takes only a few seconds on a single CPU.
RTSeg: Real-time Semantic Segmentation Comparative Study
Jun 10, 2018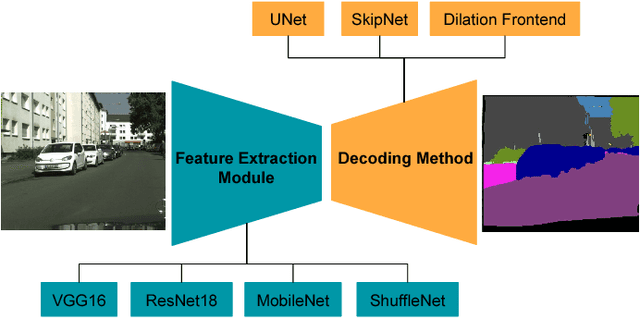
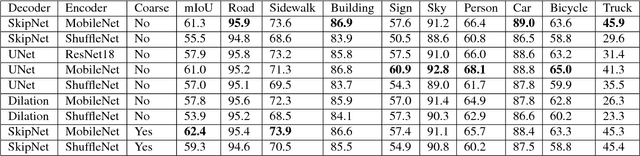
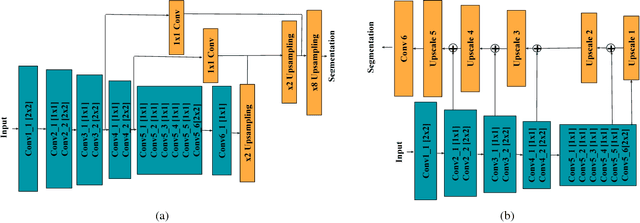

Semantic segmentation benefits robotics related applications especially autonomous driving. Most of the research on semantic segmentation is only on increasing the accuracy of segmentation models with little attention to computationally efficient solutions. The few work conducted in this direction does not provide principled methods to evaluate the different design choices for segmentation. In this paper, we address this gap by presenting a real-time semantic segmentation benchmarking framework with a decoupled design for feature extraction and decoding methods. The framework is comprised of different network architectures for feature extraction such as VGG16, Resnet18, MobileNet, and ShuffleNet. It is also comprised of multiple meta-architectures for segmentation that define the decoding methodology. These include SkipNet, UNet, and Dilation Frontend. Experimental results are presented on the Cityscapes dataset for urban scenes. The modular design allows novel architectures to emerge, that lead to 143x GFLOPs reduction in comparison to SegNet. This benchmarking framework is publicly available at "https://github.com/MSiam/TFSegmentation".
Minimum-Delay Adaptation in Non-Stationary Reinforcement Learning via Online High-Confidence Change-Point Detection
May 20, 2021
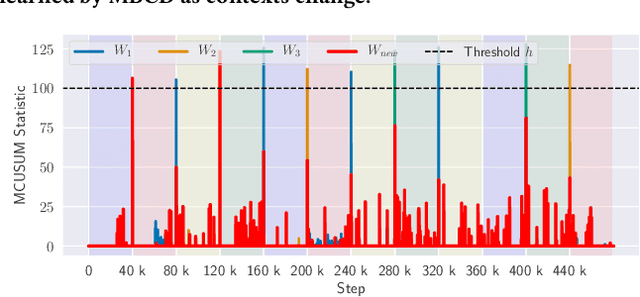
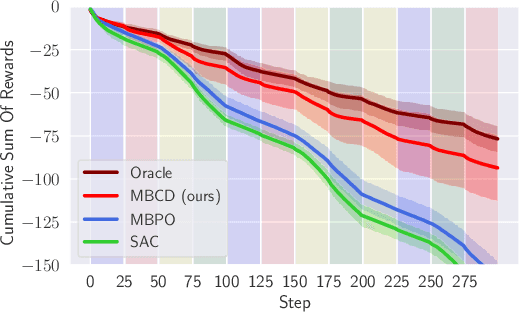
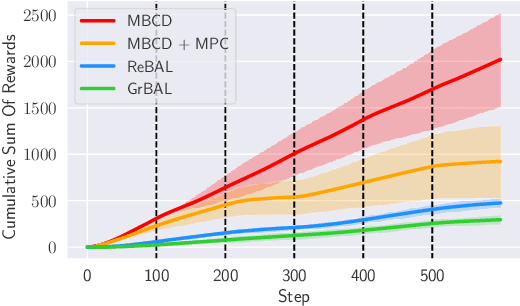
Non-stationary environments are challenging for reinforcement learning algorithms. If the state transition and/or reward functions change based on latent factors, the agent is effectively tasked with optimizing a behavior that maximizes performance over a possibly infinite random sequence of Markov Decision Processes (MDPs), each of which drawn from some unknown distribution. We call each such MDP a context. Most related works make strong assumptions such as knowledge about the distribution over contexts, the existence of pre-training phases, or a priori knowledge about the number, sequence, or boundaries between contexts. We introduce an algorithm that efficiently learns policies in non-stationary environments. It analyzes a possibly infinite stream of data and computes, in real-time, high-confidence change-point detection statistics that reflect whether novel, specialized policies need to be created and deployed to tackle novel contexts, or whether previously-optimized ones might be reused. We show that (i) this algorithm minimizes the delay until unforeseen changes to a context are detected, thereby allowing for rapid responses; and (ii) it bounds the rate of false alarm, which is important in order to minimize regret. Our method constructs a mixture model composed of a (possibly infinite) ensemble of probabilistic dynamics predictors that model the different modes of the distribution over underlying latent MDPs. We evaluate our algorithm on high-dimensional continuous reinforcement learning problems and show that it outperforms state-of-the-art (model-free and model-based) RL algorithms, as well as state-of-the-art meta-learning methods specially designed to deal with non-stationarity.
* Published at Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021)
Detecting Nonlinear Causality in Multivariate Time Series with Sparse Additive Models
Apr 26, 2018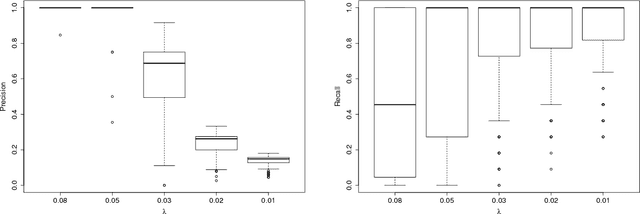
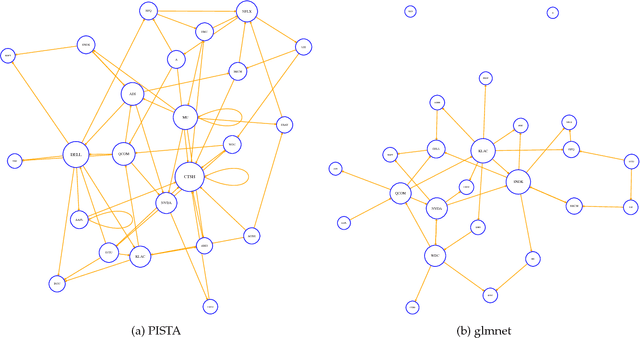
We propose a nonparametric method for detecting nonlinear causal relationship within a set of multidimensional discrete time series, by using sparse additive models (SpAMs). We show that, when the input to the SpAM is a $\beta$-mixing time series, the model can be fitted by first approximating each unknown function with a linear combination of a set of B-spline bases, and then solving a group-lasso-type optimization problem with nonconvex regularization. Theoretically, we characterize the oracle statistical properties of the proposed sparse estimator in function estimation and model selection. Numerically, we propose an efficient pathwise iterative shrinkage thresholding algorithm (PISTA), which tames the nonconvexity and guarantees linear convergence towards the desired sparse estimator with high probability.
Scalable Multiagent Driving Policies For Reducing Traffic Congestion
Feb 26, 2021

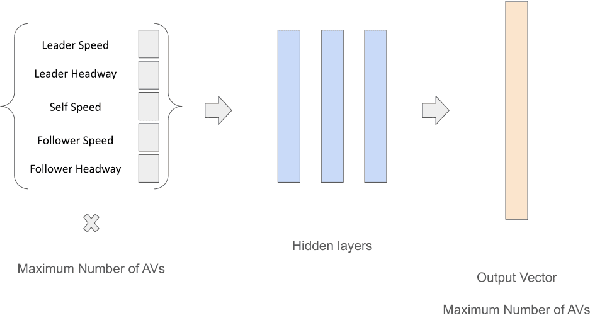

Traffic congestion is a major challenge in modern urban settings. The industry-wide development of autonomous and automated vehicles (AVs) motivates the question of how can AVs contribute to congestion reduction. Past research has shown that in small scale mixed traffic scenarios with both AVs and human-driven vehicles, a small fraction of AVs executing a controlled multiagent driving policy can mitigate congestion. In this paper, we scale up existing approaches and develop new multiagent driving policies for AVs in scenarios with greater complexity. We start by showing that a congestion metric used by past research is manipulable in open road network scenarios where vehicles dynamically join and leave the road. We then propose using a different metric that is robust to manipulation and reflects open network traffic efficiency. Next, we propose a modular transfer reinforcement learning approach, and use it to scale up a multiagent driving policy to outperform human-like traffic and existing approaches in a simulated realistic scenario, which is an order of magnitude larger than past scenarios (hundreds instead of tens of vehicles). Additionally, our modular transfer learning approach saves up to 80% of the training time in our experiments, by focusing its data collection on key locations in the network. Finally, we show for the first time a distributed multiagent policy that improves congestion over human-driven traffic. The distributed approach is more realistic and practical, as it relies solely on existing sensing and actuation capabilities, and does not require adding new communication infrastructure.
UCT: Learning Unified Convolutional Networks for Real-time Visual Tracking
Nov 10, 2017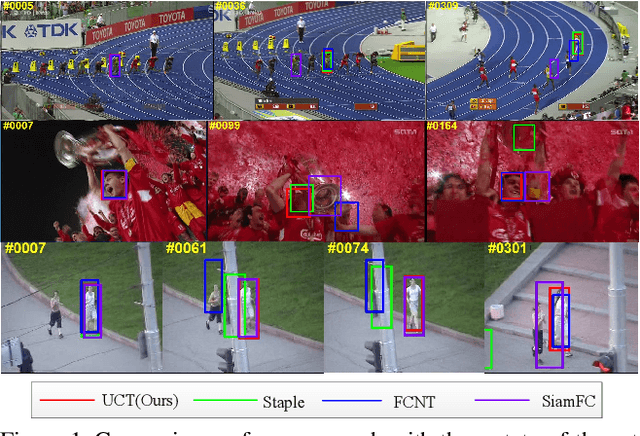
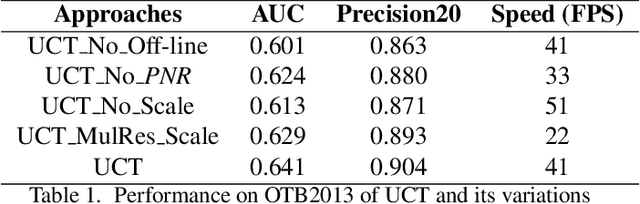
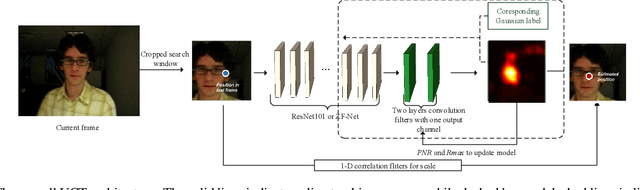

Convolutional neural networks (CNN) based tracking approaches have shown favorable performance in recent benchmarks. Nonetheless, the chosen CNN features are always pre-trained in different task and individual components in tracking systems are learned separately, thus the achieved tracking performance may be suboptimal. Besides, most of these trackers are not designed towards real-time applications because of their time-consuming feature extraction and complex optimization details.In this paper, we propose an end-to-end framework to learn the convolutional features and perform the tracking process simultaneously, namely, a unified convolutional tracker (UCT). Specifically, The UCT treats feature extractor and tracking process both as convolution operation and trains them jointly, enabling learned CNN features are tightly coupled to tracking process. In online tracking, an efficient updating method is proposed by introducing peak-versus-noise ratio (PNR) criterion, and scale changes are handled efficiently by incorporating a scale branch into network. The proposed approach results in superior tracking performance, while maintaining real-time speed. The standard UCT and UCT-Lite can track generic objects at 41 FPS and 154 FPS without further optimization, respectively. Experiments are performed on four challenging benchmark tracking datasets: OTB2013, OTB2015, VOT2014 and VOT2015, and our method achieves state-of-the-art results on these benchmarks compared with other real-time trackers.
Camera View Adjustment Prediction for Improving Image Composition
Apr 15, 2021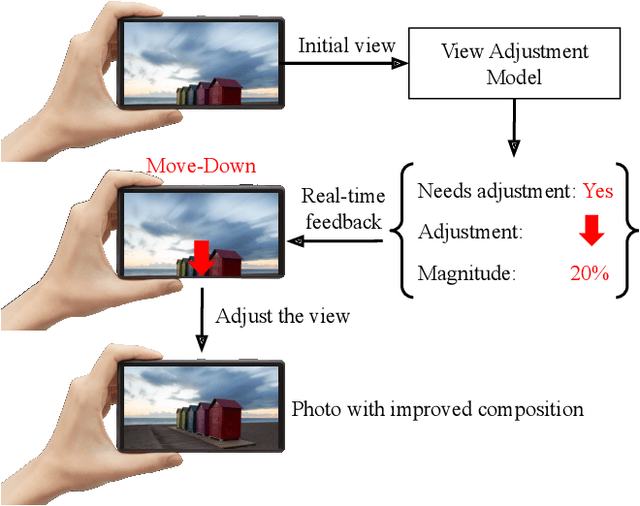
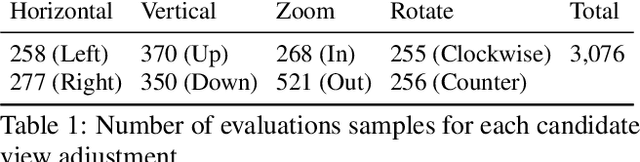


Image composition plays an important role in the quality of a photo. However, not every camera user possesses the knowledge and expertise required for capturing well-composed photos. While post-capture cropping can improve the composition sometimes, it does not work in many common scenarios in which the photographer needs to adjust the camera view to capture the best shot. To address this issue, we propose a deep learning-based approach that provides suggestions to the photographer on how to adjust the camera view before capturing. By optimizing the composition before a photo is captured, our system helps photographers to capture better photos. As there is no publicly-available dataset for this task, we create a view adjustment dataset by repurposing existing image cropping datasets. Furthermore, we propose a two-stage semi-supervised approach that utilizes both labeled and unlabeled images for training a view adjustment model. Experiment results show that the proposed semi-supervised approach outperforms the corresponding supervised alternatives, and our user study results show that the suggested view adjustment improves image composition 79% of the time.
Graph-Based Deep Modeling and Real Time Forecasting of Sparse Spatio-Temporal Data
Apr 02, 2018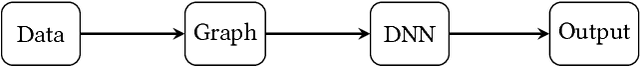
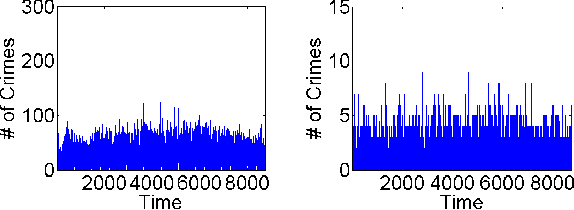
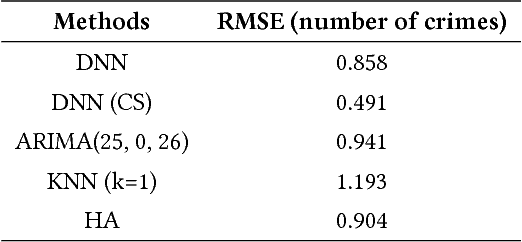
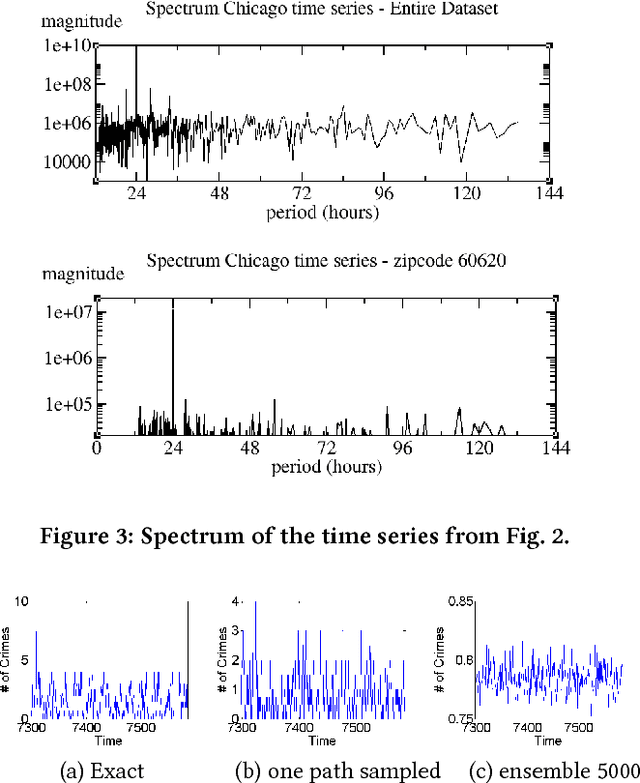
We present a generic framework for spatio-temporal (ST) data modeling, analysis, and forecasting, with a special focus on data that is sparse in both space and time. Our multi-scaled framework is a seamless coupling of two major components: a self-exciting point process that models the macroscale statistical behaviors of the ST data and a graph structured recurrent neural network (GSRNN) to discover the microscale patterns of the ST data on the inferred graph. This novel deep neural network (DNN) incorporates the real time interactions of the graph nodes to enable more accurate real time forecasting. The effectiveness of our method is demonstrated on both crime and traffic forecasting.
Gradient Coding with Dynamic Clustering for Straggler Mitigation
Nov 03, 2020
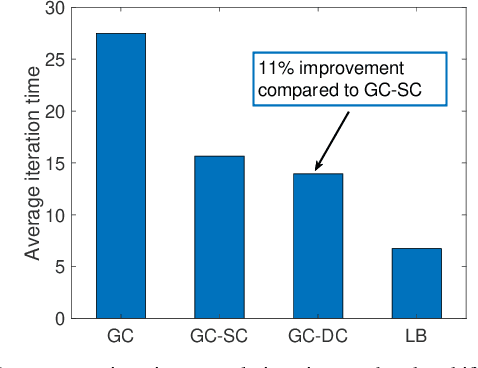
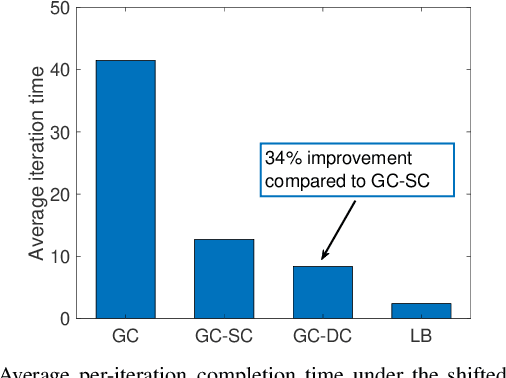
In distributed synchronous gradient descent (GD) the main performance bottleneck for the per-iteration completion time is the slowest \textit{straggling} workers. To speed up GD iterations in the presence of stragglers, coded distributed computation techniques are implemented by assigning redundant computations to workers. In this paper, we propose a novel gradient coding (GC) scheme that utilizes dynamic clustering, denoted by GC-DC, to speed up the gradient calculation. Under time-correlated straggling behavior, GC-DC aims at regulating the number of straggling workers in each cluster based on the straggler behavior in the previous iteration. We numerically show that GC-DC provides significant improvements in the average completion time (of each iteration) with no increase in the communication load compared to the original GC scheme.
Robust partial Fourier reconstruction for diffusion-weighted imaging using a recurrent convolutional neural network
May 19, 2021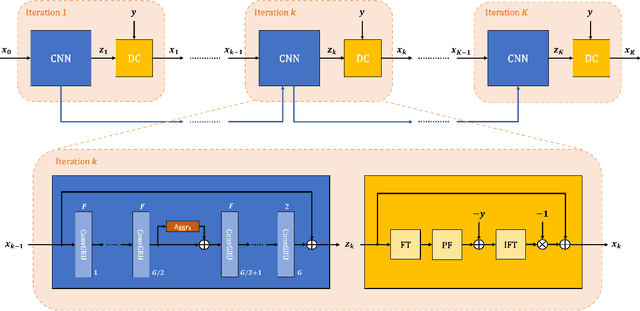
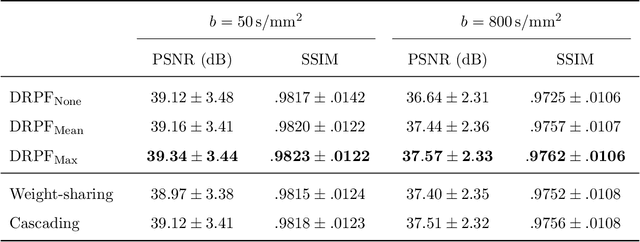
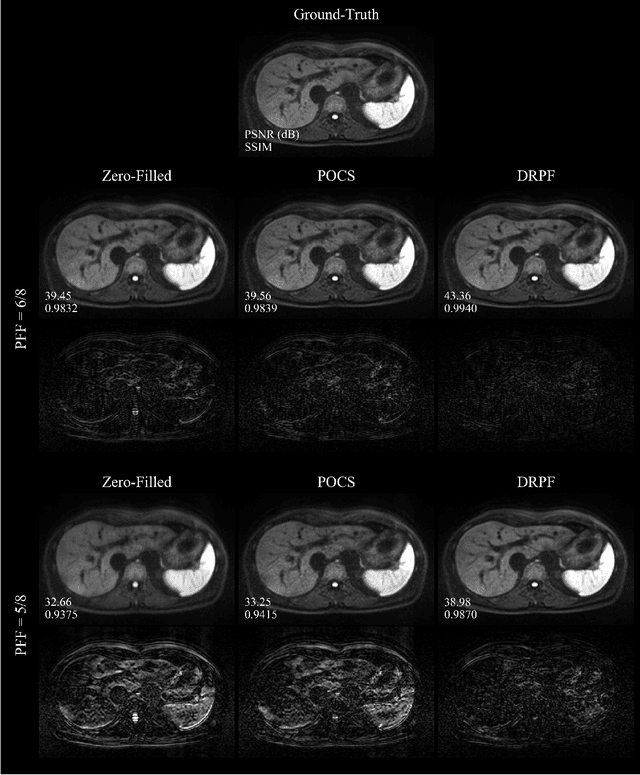
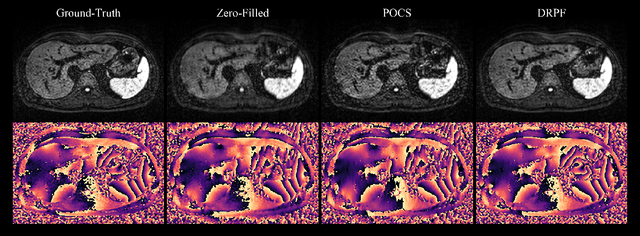
Purpose: To develop an algorithm for robust partial Fourier (PF) reconstruction applicable to diffusion-weighted (DW) images with non-smooth phase variations. Methods: Based on an unrolled proximal splitting algorithm, a neural network architecture is derived which alternates between data consistency operations and regularization implemented by recurrent convolutions. In order to exploit correlations, multiple repetitions of the same slice are jointly reconstructed under consideration of permutation-equivariance. The proposed method is trained on DW liver data of 60 volunteers and evaluated on retrospectively and prospectively sub-sampled data of different anatomies and resolutions. In addition, the benefits of using a recurrent network over other unrolling strategies is investigated. Results: Conventional PF techniques can be significantly outperformed in terms of quantitative measures as well as perceptual image quality. The proposed method is able to generalize well to brain data with contrasts and resolution not present in the training set. The reduction in echo time (TE) associated with prospective PF-sampling enables DW imaging with higher signal. Also, the TE increase in acquisitions with higher resolution can be compensated for. It can be shown that unrolling by means of a recurrent network produced better results than using a weight-shared network or a cascade of networks. Conclusion: This work demonstrates that robust PF reconstruction of DW data is feasible even at strong PF factors in applications with severe phase variations. Since the proposed method does not rely on smoothness priors of the phase but uses learned recurrent convolutions instead, artifacts of conventional PF methods can be avoided.