 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Structured Inverted-File k-Means Clustering for High-Dimensional Sparse Data
Mar 30, 2021
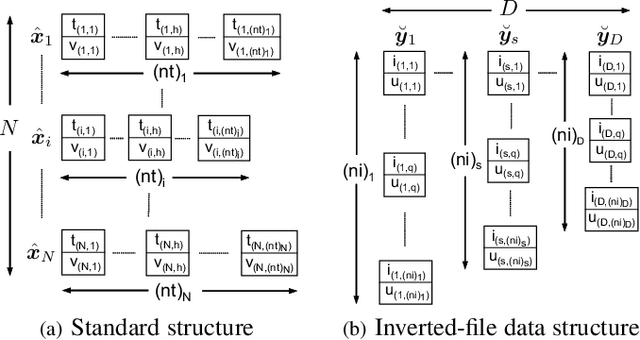
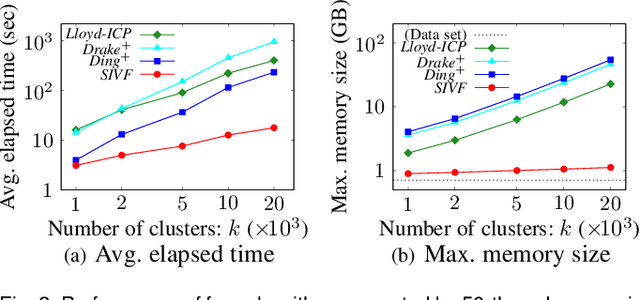
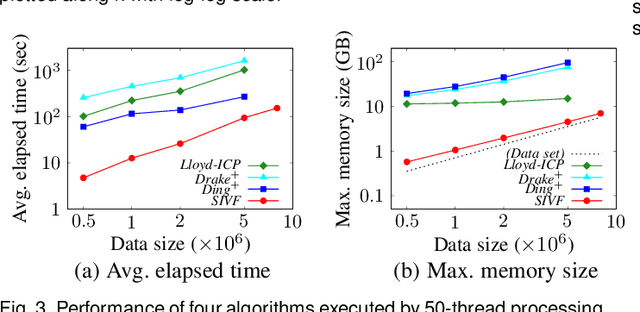
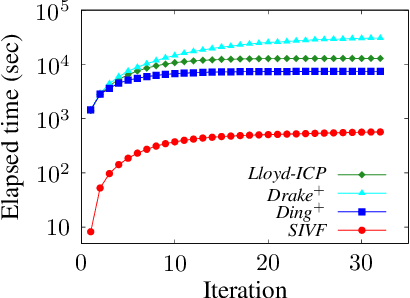
This paper presents an architecture-friendly k-means clustering algorithm called SIVF for a large-scale and high-dimensional sparse data set. Algorithm efficiency on time is often measured by the number of costly operations such as similarity calculations. In practice, however, it depends greatly on how the algorithm adapts to an architecture of the computer system which it is executed on. Our proposed SIVF employs invariant centroid-pair based filter (ICP) to decrease the number of similarity calculations between a data object and centroids of all the clusters. To maximize the ICP performance, SIVF exploits for a centroid set an inverted-file that is structured so as to reduce pipeline hazards. We demonstrate in our experiments on real large-scale document data sets that SIVF operates at higher speed and with lower memory consumption than existing algorithms. Our performance analysis reveals that SIVF achieves the higher speed by suppressing performance degradation factors of the number of cache misses and branch mispredictions rather than less similarity calculations.
Enabling Homomorphically Encrypted Inference for Large DNN Models
Mar 30, 2021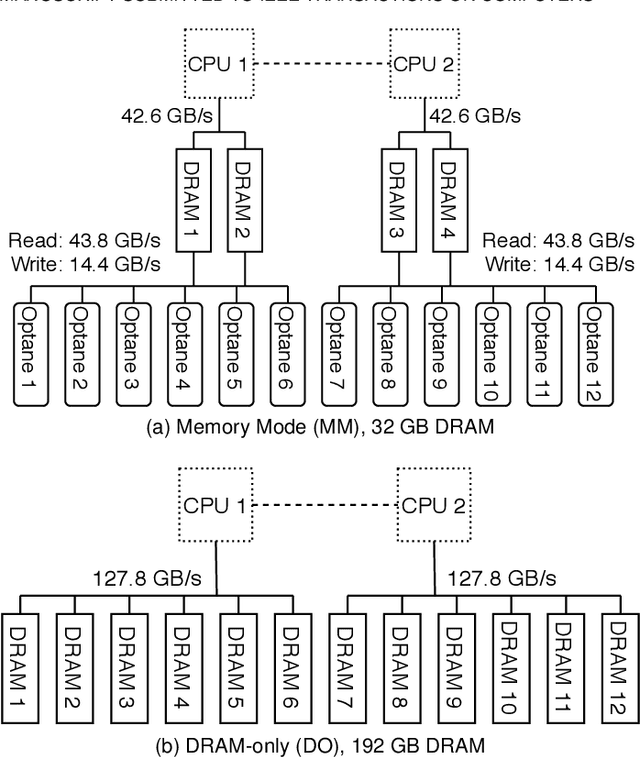
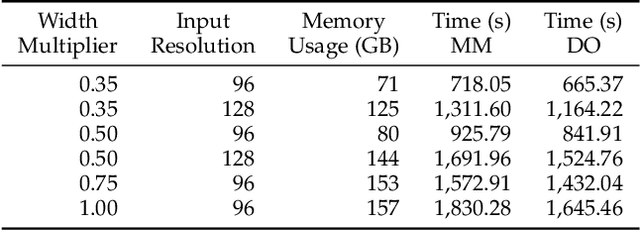
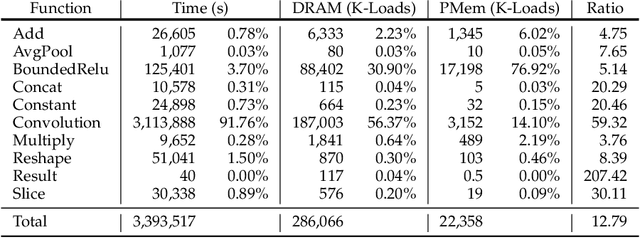
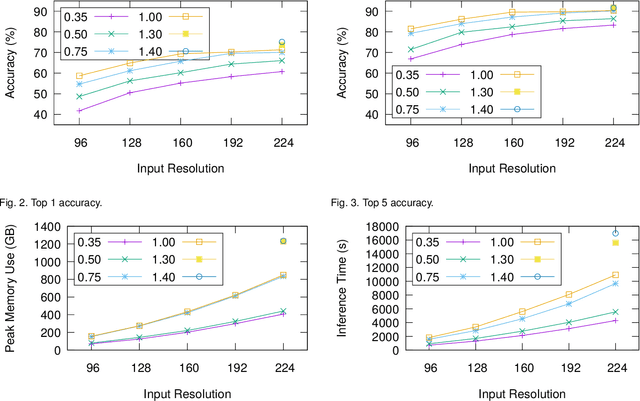
The proliferation of machine learning services in the last few years has raised data privacy concerns. Homomorphic encryption (HE) enables inference using encrypted data but it incurs 100x--10,000x memory and runtime overheads. Secure deep neural network (DNN) inference using HE is currently limited by computing and memory resources, with frameworks requiring hundreds of gigabytes of DRAM to evaluate small models. To overcome these limitations, in this paper we explore the feasibility of leveraging hybrid memory systems comprised of DRAM and persistent memory. In particular, we explore the recently-released Intel Optane PMem technology and the Intel HE-Transformer nGraph to run large neural networks such as MobileNetV2 (in its largest variant) and ResNet-50 for the first time in the literature. We present an in-depth analysis of the efficiency of the executions with different hardware and software configurations. Our results conclude that DNN inference using HE incurs on friendly access patterns for this memory configuration, yielding efficient executions.
Detection of Obstructive Sleep Apnoea Using Features Extracted from Segmented Time-Series ECG Signals Using a One Dimensional Convolutional Neural Network
Feb 03, 2020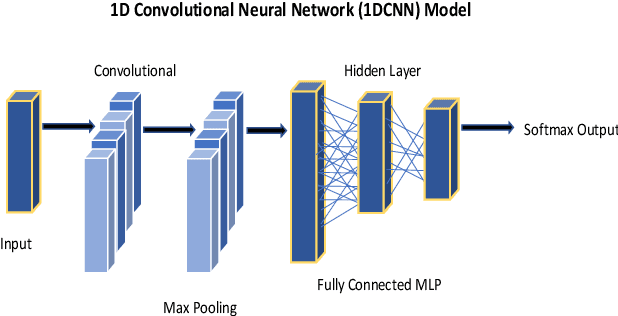
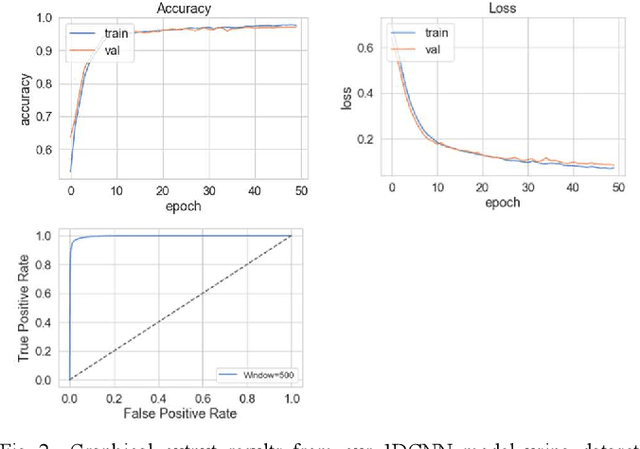
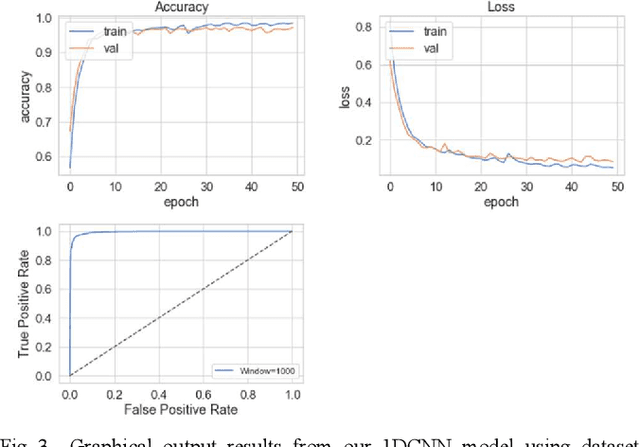
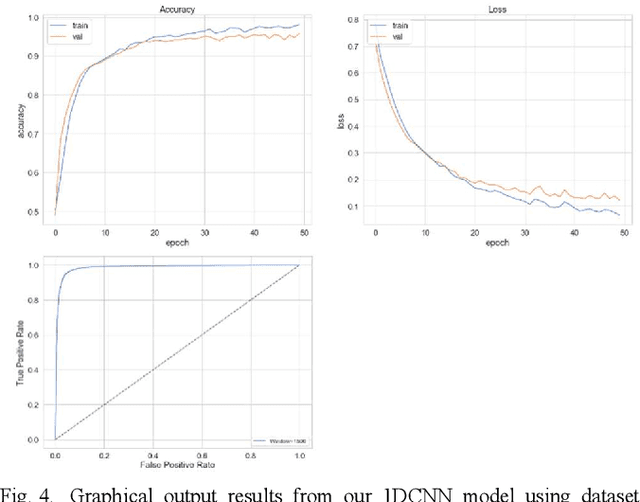
The study in this paper presents a one-dimensional convolutional neural network (1DCNN) model, designed for the automated detection of obstructive Sleep Apnoea (OSA) captured from single-channel electrocardiogram (ECG) signals. The system provides mechanisms in clinical practice that help diagnose patients suffering with OSA. Using the state-of-the-art in 1DCNNs, a model is constructed using convolutional, max pooling layers and a fully connected Multilayer Perceptron (MLP) consisting of a hidden layer and SoftMax output for classification. The 1DCNN extracts prominent features, which are used to train an MLP. The model is trained using segmented ECG signals grouped into 5 unique datasets of set window sizes. 35 ECG signal recordings were selected from an annotated database containing 70 night-time ECG recordings. (Group A = a01 to a20 (Apnoea breathing), Group B = b01 to b05 (moderate), and Group C = c01 to c10 (normal). A total of 6514 minutes of Apnoea was recorded. Evaluation of the model is performed using a set of standard metrics which show the proposed model achieves high classification results in both training and validation using our windowing strategy, particularly W=500 (Sensitivity 0.9705, Specificity 0.9725, F1 Score 0.9717, Kappa Score 0.9430, Log Loss 0.0836, ROCAUC 0.9945). This demonstrates the model can identify the presence of Apnoea with a high degree of accuracy.
TimeNet: Pre-trained deep recurrent neural network for time series classification
Jun 23, 2017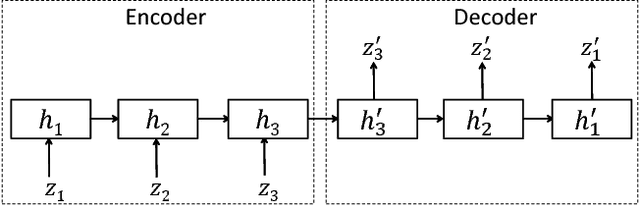
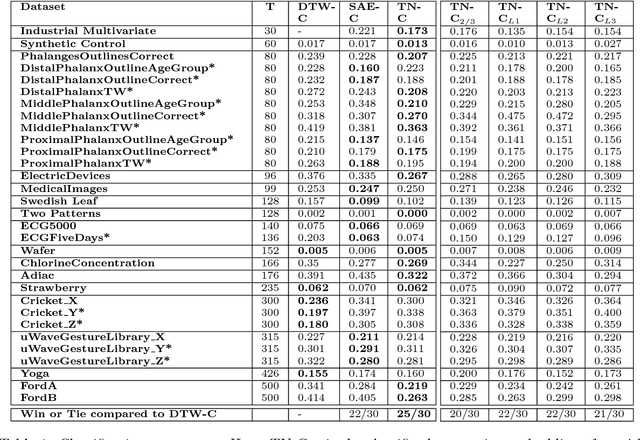

Inspired by the tremendous success of deep Convolutional Neural Networks as generic feature extractors for images, we propose TimeNet: a deep recurrent neural network (RNN) trained on diverse time series in an unsupervised manner using sequence to sequence (seq2seq) models to extract features from time series. Rather than relying on data from the problem domain, TimeNet attempts to generalize time series representation across domains by ingesting time series from several domains simultaneously. Once trained, TimeNet can be used as a generic off-the-shelf feature extractor for time series. The representations or embeddings given by a pre-trained TimeNet are found to be useful for time series classification (TSC). For several publicly available datasets from UCR TSC Archive and an industrial telematics sensor data from vehicles, we observe that a classifier learned over the TimeNet embeddings yields significantly better performance compared to (i) a classifier learned over the embeddings given by a domain-specific RNN, as well as (ii) a nearest neighbor classifier based on Dynamic Time Warping.
Learning from Experience for Rapid Generation of Local Car Maneuvers
Dec 07, 2020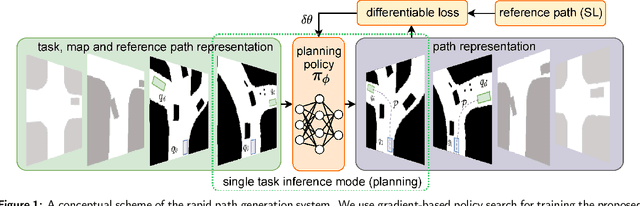
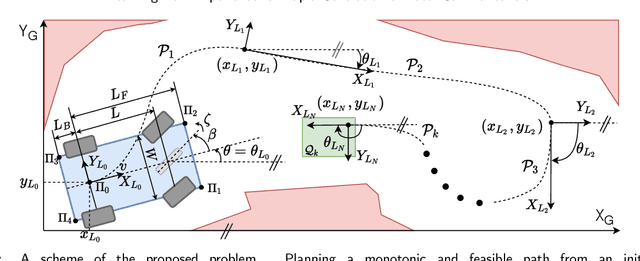
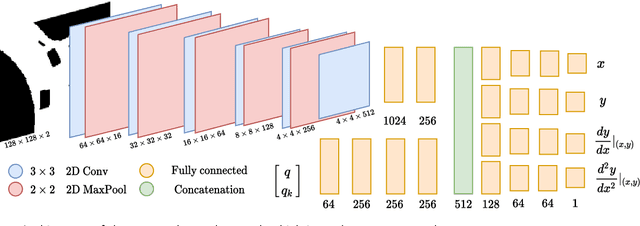
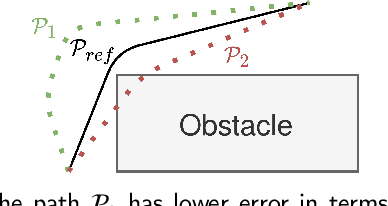
Being able to rapidly respond to the changing scenes and traffic situations by generating feasible local paths is of pivotal importance for car autonomy. We propose to train a deep neural network (DNN) to plan feasible and nearly-optimal paths for kinematically constrained vehicles in small constant time. Our DNN model is trained using a novel weakly supervised approach and a gradient-based policy search. On real and simulated scenes and a large set of local planning problems, we demonstrate that our approach outperforms the existing planners with respect to the number of successfully completed tasks. While the path generation time is about 40 ms, the generated paths are smooth and comparable to those obtained from conventional path planners.
Model-Driven Deep Learning Based Channel Estimation and Feedback for Millimeter-Wave Massive Hybrid MIMO Systems
May 06, 2021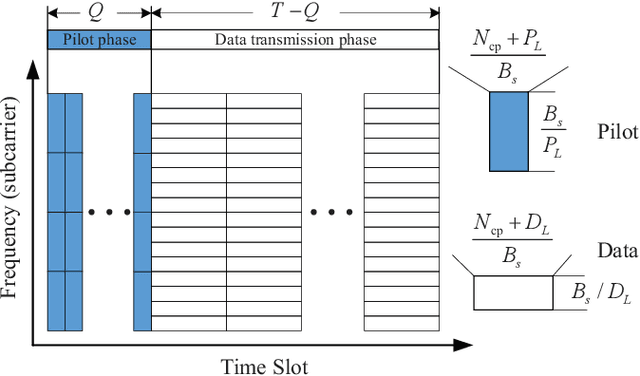
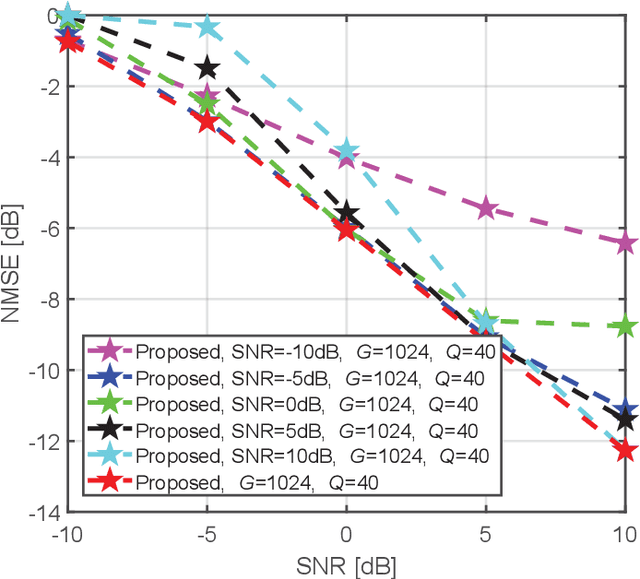
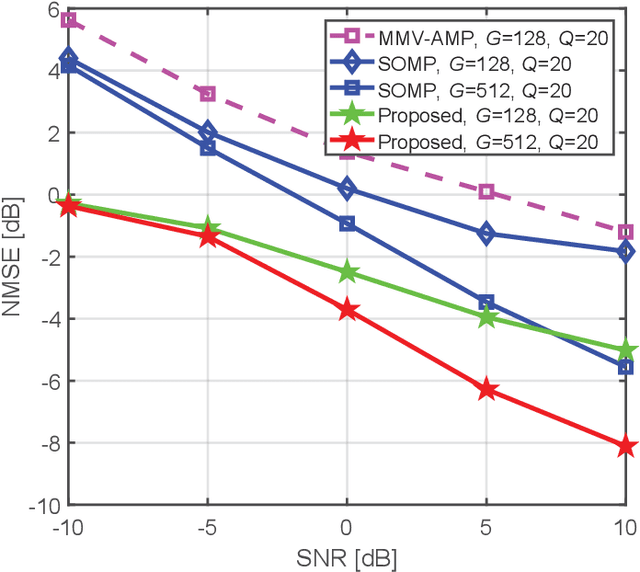
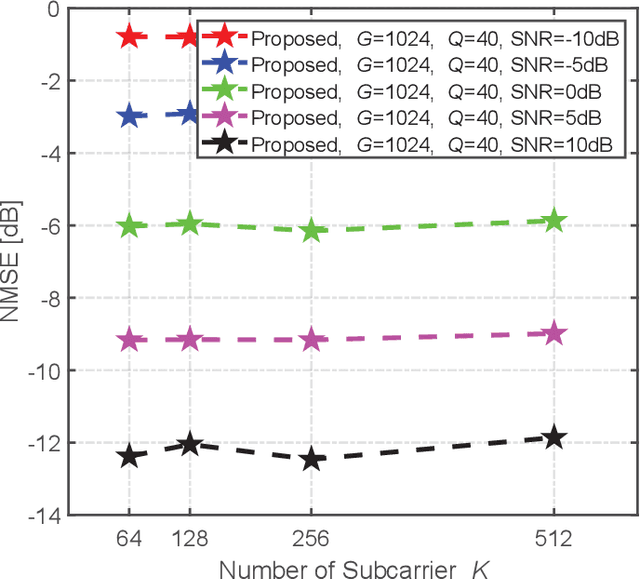
This paper proposes a model-driven deep learning (MDDL)-based channel estimation and feedback scheme for wideband millimeter-wave (mmWave) massive hybrid multiple-input multiple-output (MIMO) systems, where the angle-delay domain channels' sparsity is exploited for reducing the overhead. Firstly, we consider the uplink channel estimation for time-division duplexing systems. To reduce the uplink pilot overhead for estimating the high-dimensional channels from a limited number of radio frequency (RF) chains at the base station (BS), we propose to jointly train the phase shift network and the channel estimator as an auto-encoder. Particularly, by exploiting the channels' structured sparsity from an a priori model and learning the integrated trainable parameters from the data samples, the proposed multiple-measurement-vectors learned approximate message passing (MMV-LAMP) network with the devised redundant dictionary can jointly recover multiple subcarriers' channels with significantly enhanced performance. Moreover, we consider the downlink channel estimation and feedback for frequency-division duplexing systems. Similarly, the pilots at the BS and channel estimator at the users can be jointly trained as an encoder and a decoder, respectively. Besides, to further reduce the channel feedback overhead, only the received pilots on part of the subcarriers are fed back to the BS, which can exploit the MMV-LAMP network to reconstruct the spatial-frequency channel matrix. Numerical results show that the proposed MDDL-based channel estimation and feedback scheme outperforms the state-of-the-art approaches.
DeepWORD: A GCN-based Approach for Owner-Member Relationship Detection in Autonomous Driving
Mar 30, 2021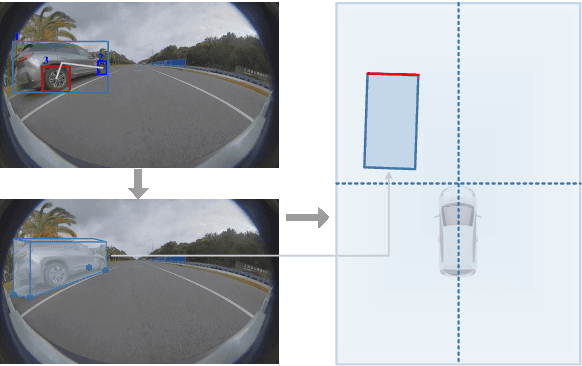
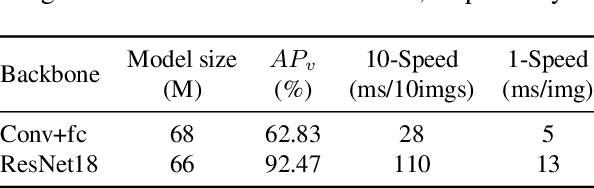

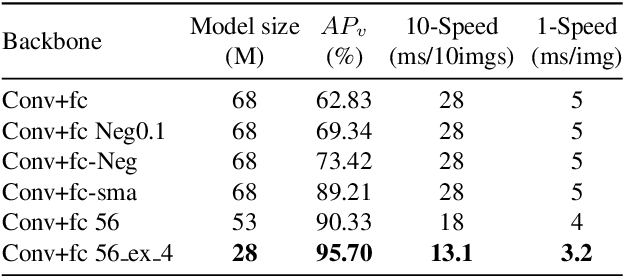
It's worth noting that the owner-member relationship between wheels and vehicles has an significant contribution to the 3D perception of vehicles, especially in the embedded environment. However, there are currently two main challenges about the above relationship prediction: i) The traditional heuristic methods based on IoU can hardly deal with the traffic jam scenarios for the occlusion. ii) It is difficult to establish an efficient applicable solution for the vehicle-mounted system. To address these issues, we propose an innovative relationship prediction method, namely DeepWORD, by designing a graph convolution network (GCN). Specifically, we utilize the feature maps with local correlation as the input of nodes to improve the information richness. Besides, we introduce the graph attention network (GAT) to dynamically amend the prior estimation deviation. Furthermore, we establish an annotated owner-member relationship dataset called WORD as a large-scale benchmark, which will be available soon. The experiments demonstrate that our solution achieves state-of-the-art accuracy and real-time in practice.
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021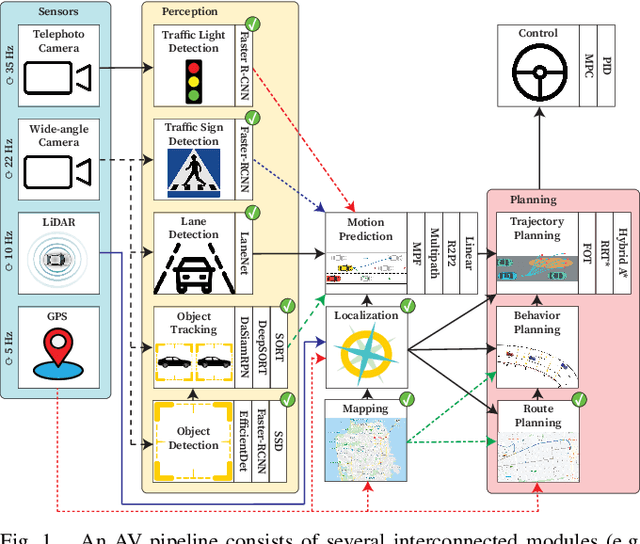

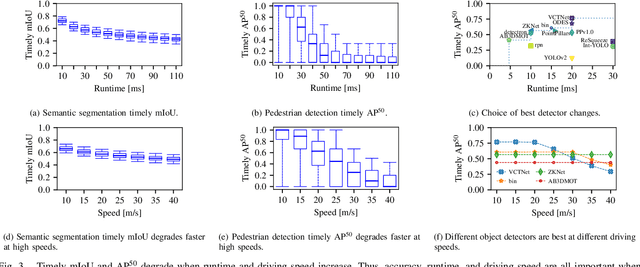
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.
Time-Sensitive Bandit Learning and Satisficing Thompson Sampling
Apr 28, 2017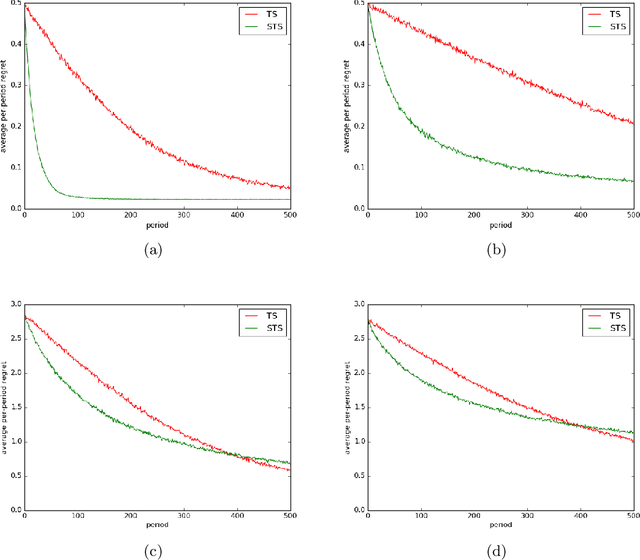
The literature on bandit learning and regret analysis has focused on contexts where the goal is to converge on an optimal action in a manner that limits exploration costs. One shortcoming imposed by this orientation is that it does not treat time preference in a coherent manner. Time preference plays an important role when the optimal action is costly to learn relative to near-optimal actions. This limitation has not only restricted the relevance of theoretical results but has also influenced the design of algorithms. Indeed, popular approaches such as Thompson sampling and UCB can fare poorly in such situations. In this paper, we consider discounted rather than cumulative regret, where a discount factor encodes time preference. We propose satisficing Thompson sampling -- a variation of Thompson sampling -- and establish a strong discounted regret bound for this new algorithm.
Nanosecond machine learning event classification with boosted decision trees in FPGA for high energy physics
Apr 07, 2021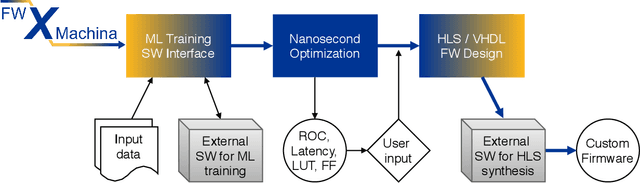
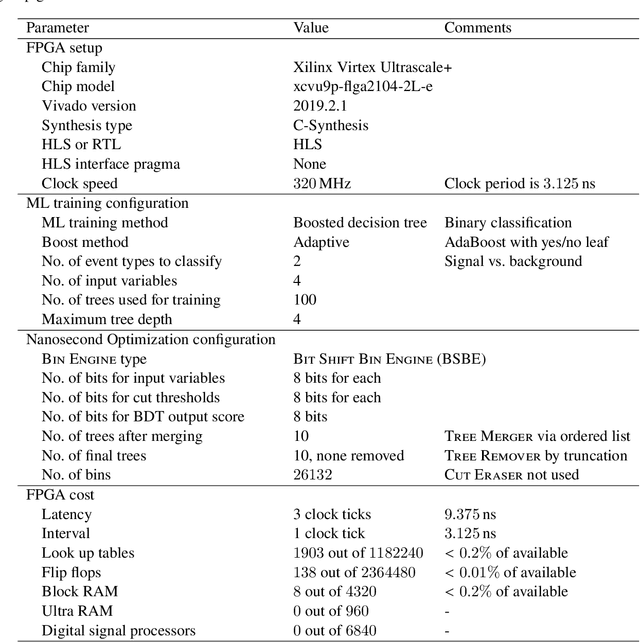
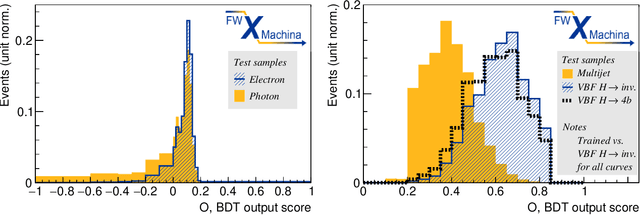
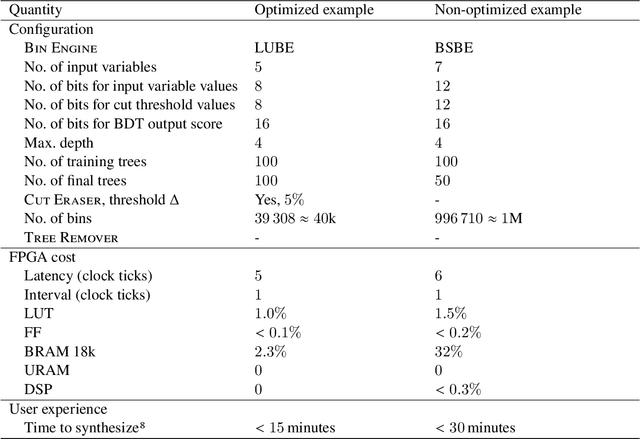
We present a novel implementation of classification using the machine learning / artificial intelligence method called boosted decision trees (BDT) on field programmable gate arrays (FPGA). The firmware implementation of binary classification requiring 100 training trees with a maximum depth of 4 using four input variables gives a latency value of about 10 ns, which corresponds to 3 clock ticks at 320 MHz in our setup. The low timing values are achieved by restructuring the BDT layout and reconfiguring its parameters. The FPGA resource utilization is also kept low at a range from 0.01% to 0.2% in our setup. A software package called fwXmachina achieves this implementation. Our intended audience is a user of custom electronics-based trigger systems in high energy physics experiments or anyone that needs decisions at the lowest latency values for real-time event classification. Two problems from high energy physics are considered, in the separation of electrons vs. photons and in the selection of vector boson fusion-produced Higgs bosons vs. the rejection of the multijet processes.