 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Master Key Backdoor for Universal Impersonation Attack against DNN-based Face Verification
May 01, 2021
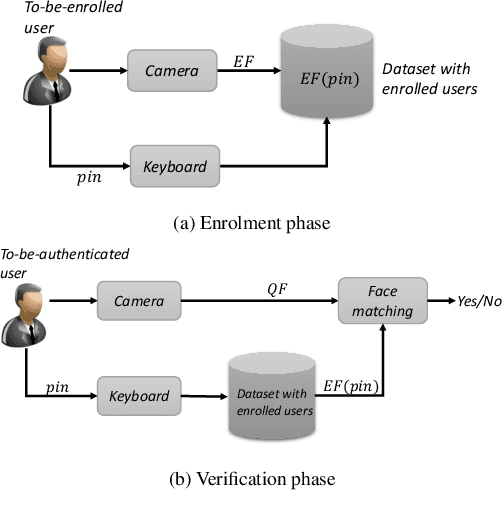
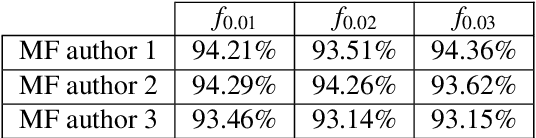
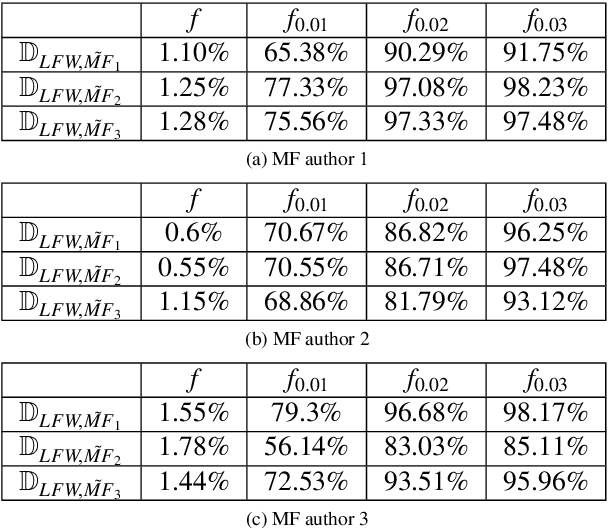
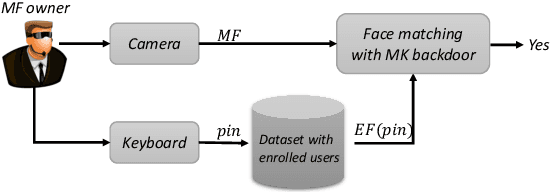
We introduce a new attack against face verification systems based on Deep Neural Networks (DNN). The attack relies on the introduction into the network of a hidden backdoor, whose activation at test time induces a verification error allowing the attacker to impersonate any user. The new attack, named Master Key backdoor attack, operates by interfering with the training phase, so to instruct the DNN to always output a positive verification answer when the face of the attacker is presented at its input. With respect to existing attacks, the new backdoor attack offers much more flexibility, since the attacker does not need to know the identity of the victim beforehand. In this way, he can deploy a Universal Impersonation attack in an open-set framework, allowing him to impersonate any enrolled users, even those that were not yet enrolled in the system when the attack was conceived. We present a practical implementation of the attack targeting a Siamese-DNN face verification system, and show its effectiveness when the system is trained on VGGFace2 dataset and tested on LFW and YTF datasets. According to our experiments, the Master Key backdoor attack provides a high attack success rate even when the ratio of poisoned training data is as small as 0.01, thus raising a new alarm regarding the use of DNN-based face verification systems in security-critical applications.
Bootstrapping User and Item Representations for One-Class Collaborative Filtering
May 13, 2021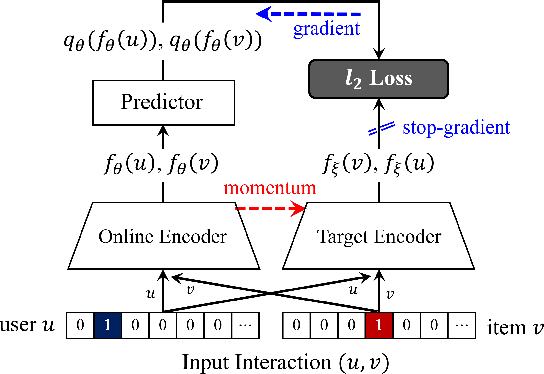
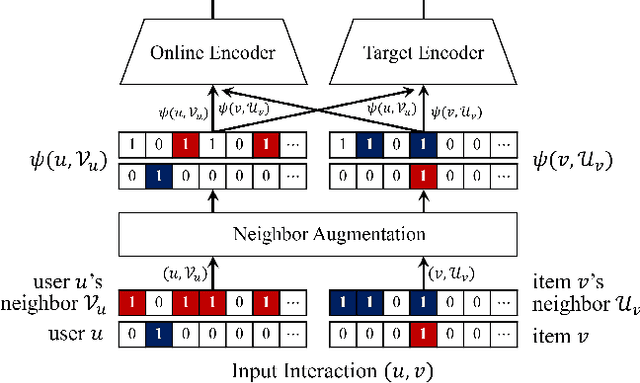
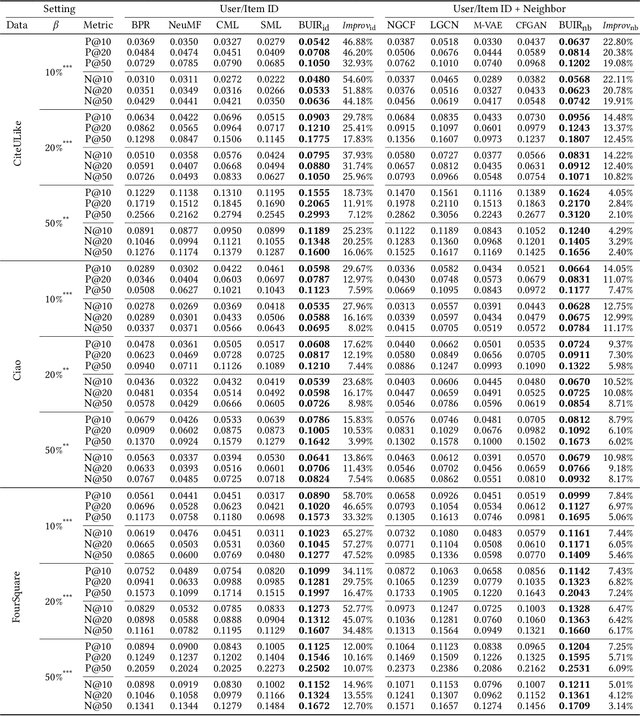
The goal of one-class collaborative filtering (OCCF) is to identify the user-item pairs that are positively-related but have not been interacted yet, where only a small portion of positive user-item interactions (e.g., users' implicit feedback) are observed. For discriminative modeling between positive and negative interactions, most previous work relied on negative sampling to some extent, which refers to considering unobserved user-item pairs as negative, as actual negative ones are unknown. However, the negative sampling scheme has critical limitations because it may choose "positive but unobserved" pairs as negative. This paper proposes a novel OCCF framework, named as BUIR, which does not require negative sampling. To make the representations of positively-related users and items similar to each other while avoiding a collapsed solution, BUIR adopts two distinct encoder networks that learn from each other; the first encoder is trained to predict the output of the second encoder as its target, while the second encoder provides the consistent targets by slowly approximating the first encoder. In addition, BUIR effectively alleviates the data sparsity issue of OCCF, by applying stochastic data augmentation to encoder inputs. Based on the neighborhood information of users and items, BUIR randomly generates the augmented views of each positive interaction each time it encodes, then further trains the model by this self-supervision. Our extensive experiments demonstrate that BUIR consistently and significantly outperforms all baseline methods by a large margin especially for much sparse datasets in which any assumptions about negative interactions are less valid.
Wireless Federated Learning (WFL) for 6G Networks -- Part II: The Compute-then-Transmit NOMA Paradigm
Apr 24, 2021
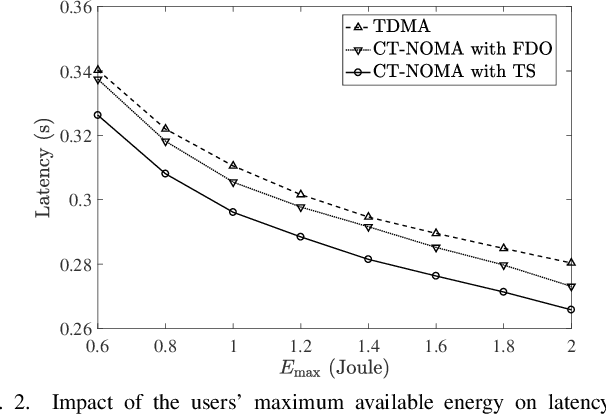
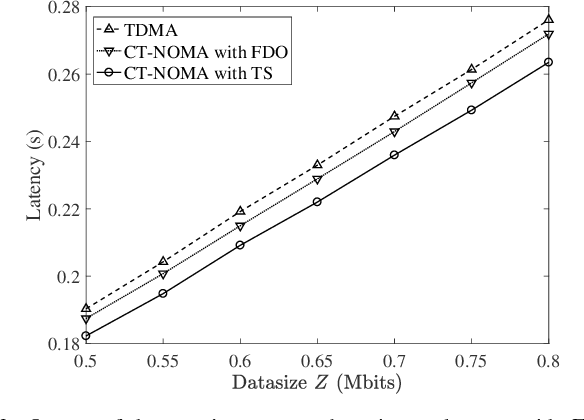
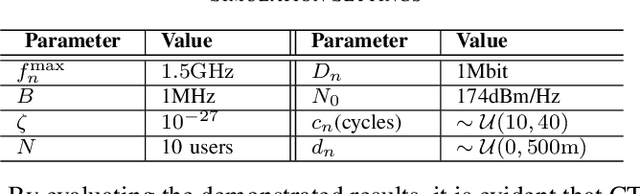
As it has been discussed in the first part of this work, the utilization of advanced multiple access protocols and the joint optimization of the communication and computing resources can facilitate the reduction of delay for wireless federated learning (WFL), which is of paramount importance for the efficient integration of WFL in the sixth generation of wireless networks (6G). To this end, in this second part we introduce and optimize a novel communication protocol for WFL networks, that is based on non-orthogonal multiple access (NOMA). More specifically, the Compute-then-Transmit NOMA (CT-NOMA) protocol is introduced, where users terminate concurrently the local model training and then simultaneously transmit the trained parameters to the central server. Moreover, two different detection schemes for the mitigation of inter-user interference in NOMA are considered and evaluated, which correspond to fixed and variable decoding order during the successive interference cancellation process. Furthermore, the computation and communication resources are jointly optimized for both considered schemes, with the aim to minimize the total delay during a WFL communication round. Finally, the simulation results verify the effectiveness of CT-NOMA in terms of delay reduction, compared to the considered benchmark that is based on time-division multiple access.
Learning Spatio-Temporal Transformer for Visual Tracking
Mar 31, 2021In this paper, we present a new tracking architecture with an encoder-decoder transformer as the key component. The encoder models the global spatio-temporal feature dependencies between target objects and search regions, while the decoder learns a query embedding to predict the spatial positions of the target objects. Our method casts object tracking as a direct bounding box prediction problem, without using any proposals or predefined anchors. With the encoder-decoder transformer, the prediction of objects just uses a simple fully-convolutional network, which estimates the corners of objects directly. The whole method is end-to-end, does not need any postprocessing steps such as cosine window and bounding box smoothing, thus largely simplifying existing tracking pipelines. The proposed tracker achieves state-of-the-art performance on five challenging short-term and long-term benchmarks, while running at real-time speed, being 6x faster than Siam R-CNN. Code and models are open-sourced at https://github.com/researchmm/Stark.
The workweek is the best time to start a family -- A Study of GPT-2 Based Claim Generation
Oct 13, 2020
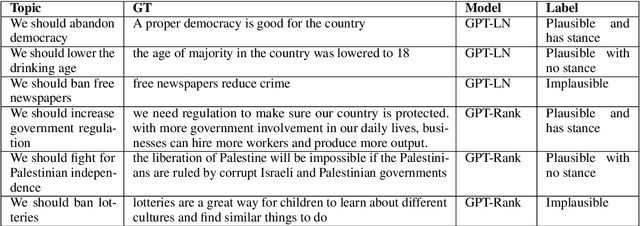


Argument generation is a challenging task whose research is timely considering its potential impact on social media and the dissemination of information. Here we suggest a pipeline based on GPT-2 for generating coherent claims, and explore the types of claims that it produces, and their veracity, using an array of manual and automatic assessments. In addition, we explore the interplay between this task and the task of Claim Retrieval, showing how they can complement one another.
Neural Transformation Learning for Deep Anomaly Detection Beyond Images
Mar 31, 2021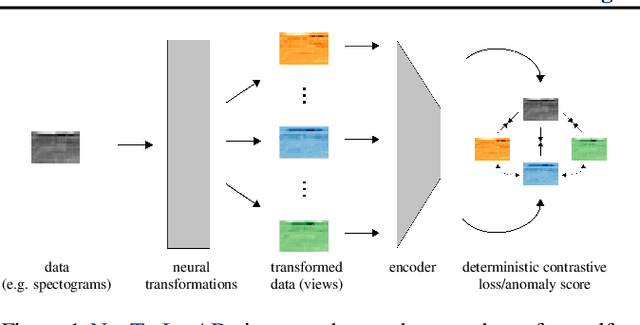

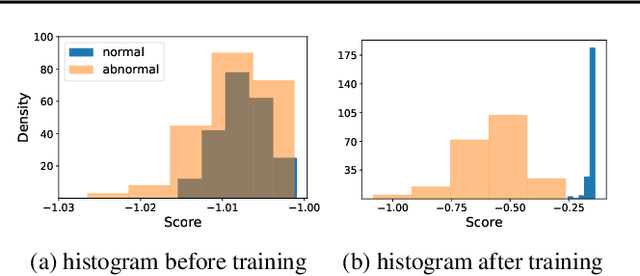
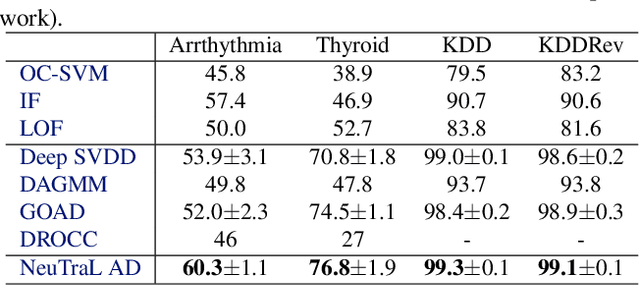
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series demonstrate that we significantly outperform existing methods on the one-vs.-rest setting but also on the more challenging n-vs.-rest anomaly-detection task. On tabular datasets from the medical and cyber-security domains, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
Scalable Neural Tangent Kernel of Recurrent Architectures
Dec 09, 2020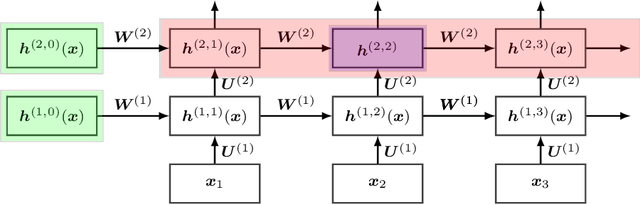
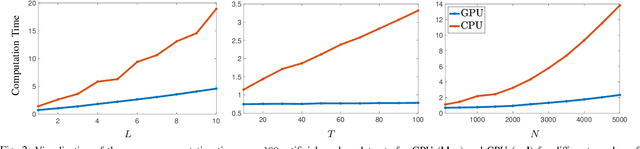
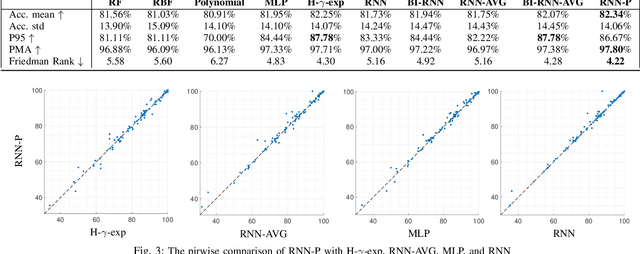
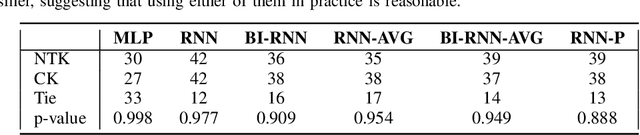
Kernels derived from deep neural networks (DNNs) in the infinite-width provide not only high performance in a range of machine learning tasks but also new theoretical insights into DNN training dynamics and generalization. In this paper, we extend the family of kernels associated with recurrent neural networks (RNNs), which were previously derived only for simple RNNs, to more complex architectures that are bidirectional RNNs and RNNs with average pooling. We also develop a fast GPU implementation to exploit its full practical potential. While RNNs are typically only applied to time-series data, we demonstrate that classifiers using RNN-based kernels outperform a range of baseline methods on 90 non-time-series datasets from the UCI data repository.
An Automated Method to Enrich Consumer Health Vocabularies Using GloVe Word Embeddings and An Auxiliary Lexical Resource
May 18, 2021
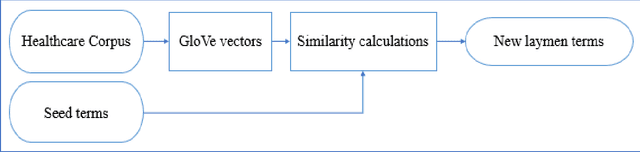
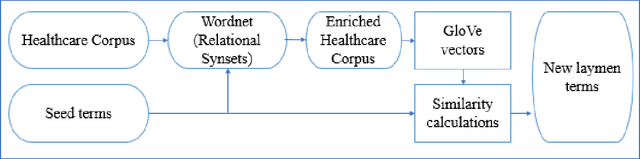
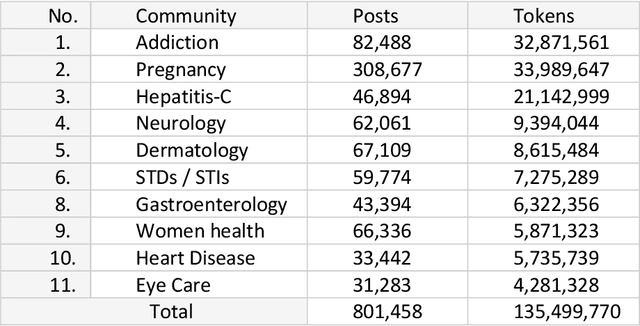
Background: Clear language makes communication easier between any two parties. A layman may have difficulty communicating with a professional due to not understanding the specialized terms common to the domain. In healthcare, it is rare to find a layman knowledgeable in medical terminology which can lead to poor understanding of their condition and/or treatment. To bridge this gap, several professional vocabularies and ontologies have been created to map laymen medical terms to professional medical terms and vice versa. Objective: Many of the presented vocabularies are built manually or semi-automatically requiring large investments of time and human effort and consequently the slow growth of these vocabularies. In this paper, we present an automatic method to enrich laymen's vocabularies that has the benefit of being able to be applied to vocabularies in any domain. Methods: Our entirely automatic approach uses machine learning, specifically Global Vectors for Word Embeddings (GloVe), on a corpus collected from a social media healthcare platform to extend and enhance consumer health vocabularies (CHV). Our approach further improves the CHV by incorporating synonyms and hyponyms from the WordNet ontology. The basic GloVe and our novel algorithms incorporating WordNet were evaluated using two laymen datasets from the National Library of Medicine (NLM), Open-Access Consumer Health Vocabulary (OAC CHV) and MedlinePlus Healthcare Vocabulary. Results: The results show that GloVe was able to find new laymen terms with an F-score of 48.44%. Furthermore, our enhanced GloVe approach outperformed basic GloVe with an average F-score of 61%, a relative improvement of 25%. Furthermore, the enhanced GloVe showed a statistical significance over the two ground truth datasets with P<.001.
Low-dimensional Denoising Embedding Transformer for ECG Classification
Mar 31, 2021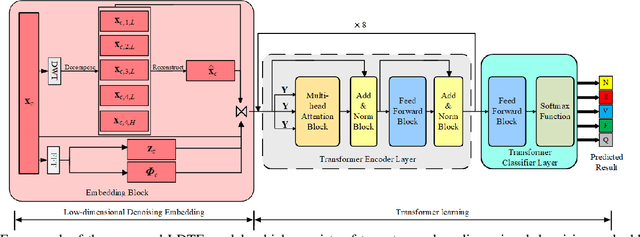
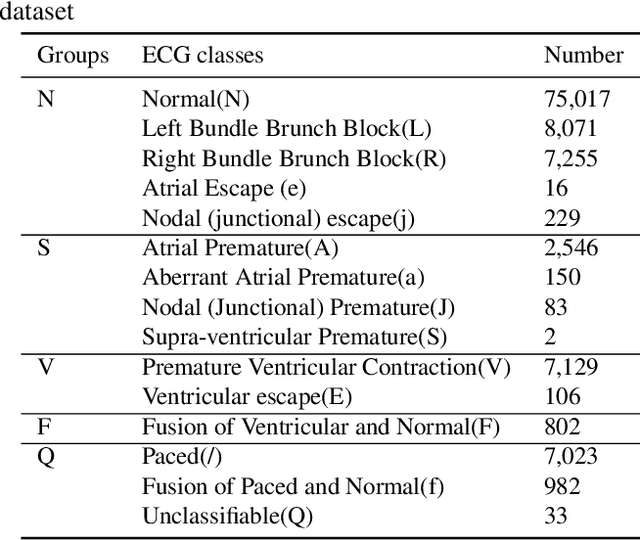

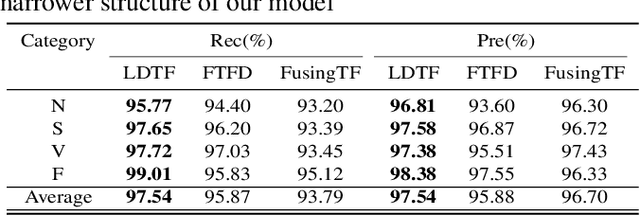
The transformer based model (e.g., FusingTF) has been employed recently for Electrocardiogram (ECG) signal classification. However, the high-dimensional embedding obtained via 1-D convolution and positional encoding can lead to the loss of the signal's own temporal information and a large amount of training parameters. In this paper, we propose a new method for ECG classification, called low-dimensional denoising embedding transformer (LDTF), which contains two components, i.e., low-dimensional denoising embedding (LDE) and transformer learning. In the LDE component, a low-dimensional representation of the signal is obtained in the time-frequency domain while preserving its own temporal information. And with the low dimensional embedding, the transformer learning is then used to obtain a deeper and narrower structure with fewer training parameters than that of the FusingTF. Experiments conducted on the MIT-BIH dataset demonstrates the effectiveness and the superior performance of our proposed method, as compared with state-of-the-art methods.
Colorectal Cancer Segmentation using Atrous Convolution and Residual Enhanced UNet
Mar 16, 2021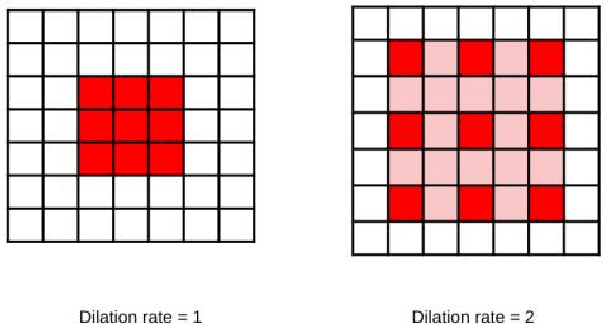
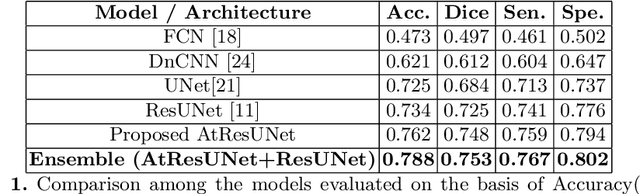
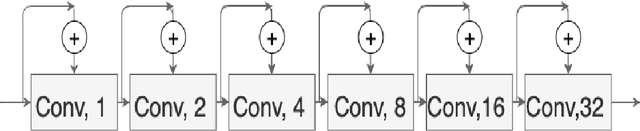
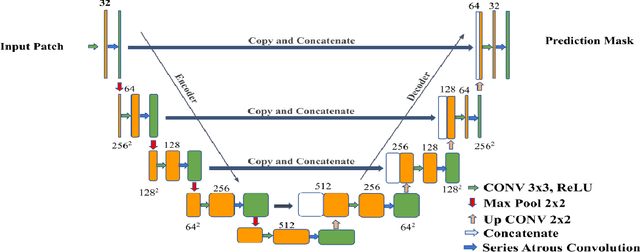
Colorectal cancer is a leading cause of death worldwide. However, early diagnosis dramatically increases the chances of survival, for which it is crucial to identify the tumor in the body. Since its imaging uses high-resolution techniques, annotating the tumor is time-consuming and requires particular expertise. Lately, methods built upon Convolutional Neural Networks(CNNs) have proven to be at par, if not better in many biomedical segmentation tasks. For the task at hand, we propose another CNN-based approach, which uses atrous convolutions and residual connections besides the conventional filters. The training and inference were made using an efficient patch-based approach, which significantly reduced unnecessary computations. The proposed AtResUNet was trained on the DigestPath 2019 Challenge dataset for colorectal cancer segmentation with results having a Dice Coefficient of 0.748.