 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Efficient Full 8-bit Integer DNN Online Training on Resource-limited Devices without Batch Normalization
May 27, 2021
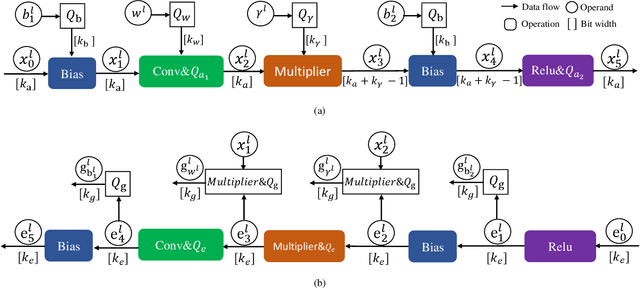

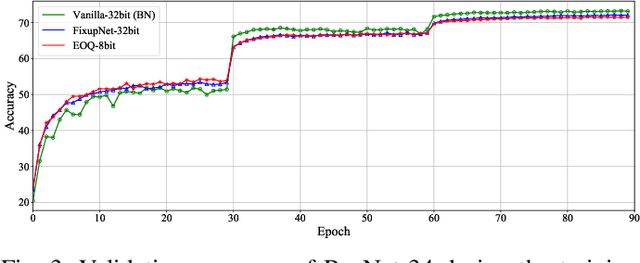
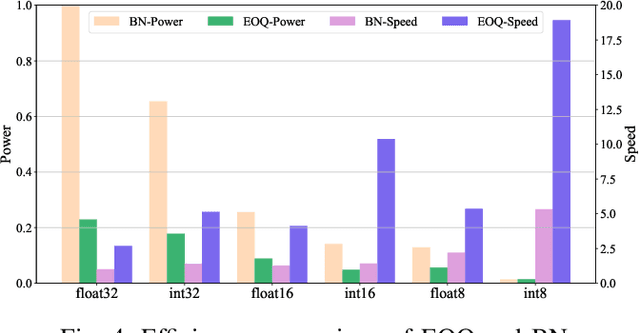
Huge computational costs brought by convolution and batch normalization (BN) have caused great challenges for the online training and corresponding applications of deep neural networks (DNNs), especially in resource-limited devices. Existing works only focus on the convolution or BN acceleration and no solution can alleviate both problems with satisfactory performance. Online training has gradually become a trend in resource-limited devices like mobile phones while there is still no complete technical scheme with acceptable model performance, processing speed, and computational cost. In this research, an efficient online-training quantization framework termed EOQ is proposed by combining Fixup initialization and a novel quantization scheme for DNN model compression and acceleration. Based on the proposed framework, we have successfully realized full 8-bit integer network training and removed BN in large-scale DNNs. Especially, weight updates are quantized to 8-bit integers for the first time. Theoretical analyses of EOQ utilizing Fixup initialization for removing BN have been further given using a novel Block Dynamical Isometry theory with weaker assumptions. Benefiting from rational quantization strategies and the absence of BN, the full 8-bit networks based on EOQ can achieve state-of-the-art accuracy and immense advantages in computational cost and processing speed. What is more, the design of deep learning chips can be profoundly simplified for the absence of unfriendly square root operations in BN. Beyond this, EOQ has been evidenced to be more advantageous in small-batch online training with fewer batch samples. In summary, the EOQ framework is specially designed for reducing the high cost of convolution and BN in network training, demonstrating a broad application prospect of online training in resource-limited devices.
FAID Diversity via Neural Networks
May 10, 2021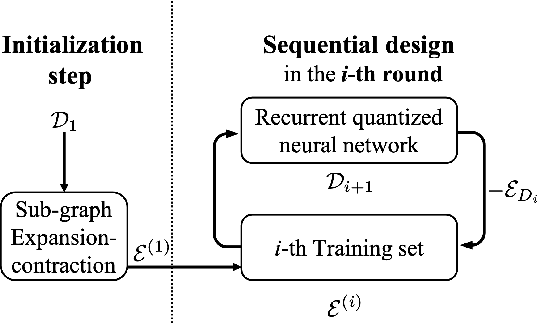
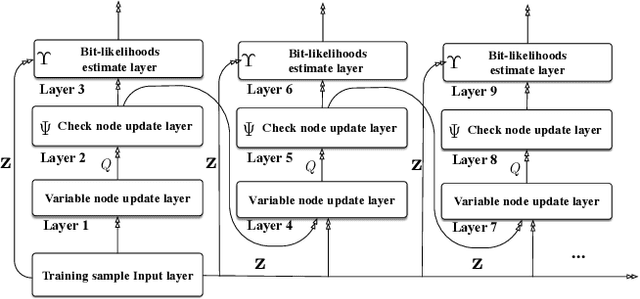
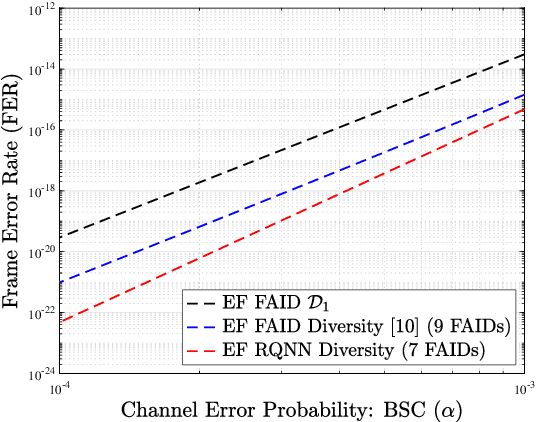
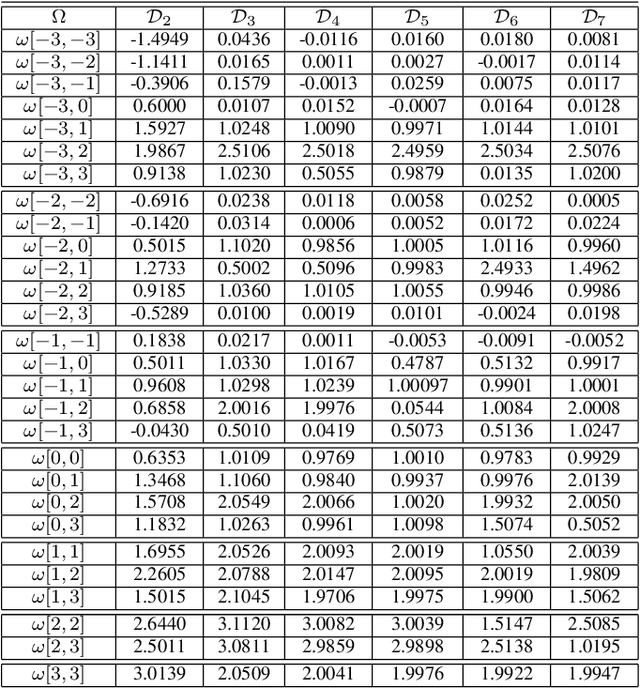
Decoder diversity is a powerful error correction framework in which a collection of decoders collaboratively correct a set of error patterns otherwise uncorrectable by any individual decoder. In this paper, we propose a new approach to design the decoder diversity of finite alphabet iterative decoders (FAIDs) for Low-Density Parity Check (LDPC) codes over the binary symmetric channel (BSC), for the purpose of lowering the error floor while guaranteeing the waterfall performance. The proposed decoder diversity is achieved by training a recurrent quantized neural network (RQNN) to learn/design FAIDs. We demonstrated for the first time that a machine-learned decoder can surpass in performance a man-made decoder of the same complexity. As RQNNs can model a broad class of FAIDs, they are capable of learning an arbitrary FAID. To provide sufficient knowledge of the error floor to the RQNN, the training sets are constructed by sampling from the set of most problematic error patterns - trapping sets. In contrast to the existing methods that use the cross-entropy function as the loss function, we introduce a frame-error-rate (FER) based loss function to train the RQNN with the objective of correcting specific error patterns rather than reducing the bit error rate (BER). The examples and simulation results show that the RQNN-aided decoder diversity increases the error correction capability of LDPC codes and lowers the error floor.
Student Performance Prediction Using Dynamic Neural Models
Jun 01, 2021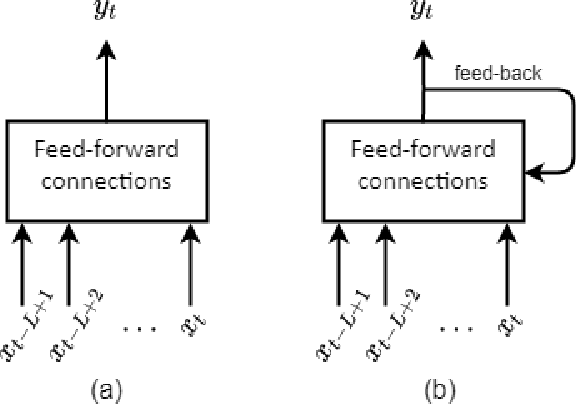
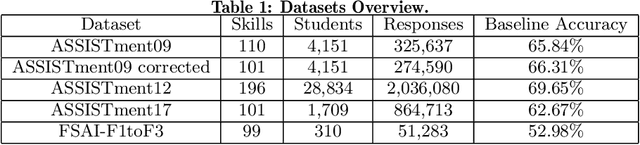
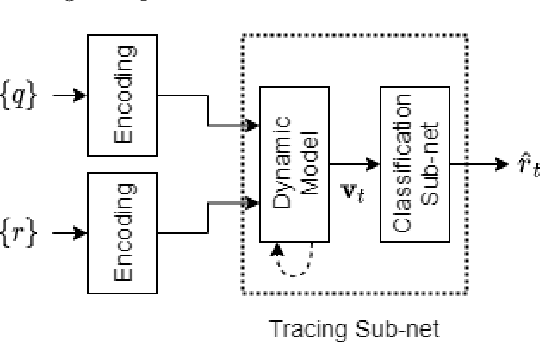
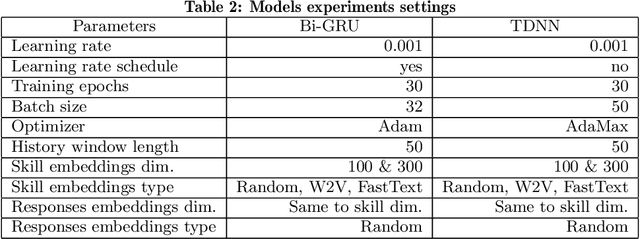
We address the problem of predicting the correctness of the student's response on the next exam question based on their previous interactions in the course of their learning and evaluation process. We model the student performance as a dynamic problem and compare the two major classes of dynamic neural architectures for its solution, namely the finite-memory Time Delay Neural Networks (TDNN) and the potentially infinite-memory Recurrent Neural Networks (RNN). Since the next response is a function of the knowledge state of the student and this, in turn, is a function of their previous responses and the skills associated with the previous questions, we propose a two-part network architecture. The first part employs a dynamic neural network (either TDNN or RNN) to trace the student knowledge state. The second part applies on top of the dynamic part and it is a multi-layer feed-forward network which completes the classification task of predicting the student response based on our estimate of the student knowledge state. Both input skills and previous responses are encoded using different embeddings. Regarding the skill embeddings we tried two different initialization schemes using (a) random vectors and (b) pretrained vectors matching the textual descriptions of the skills. Our experiments show that the performance of the RNN approach is better compared to the TDNN approach in all datasets that we have used. Also, we show that our RNN architecture outperforms the state-of-the-art models in four out of five datasets. It is worth noting that the TDNN approach also outperforms the state of the art models in four out of five datasets, although it is slightly worse than our proposed RNN approach. Finally, contrary to our expectations, we find that the initialization of skill embeddings using pretrained vectors offers practically no advantage over random initialization.
Self-Supervised Pillar Motion Learning for Autonomous Driving
Apr 18, 2021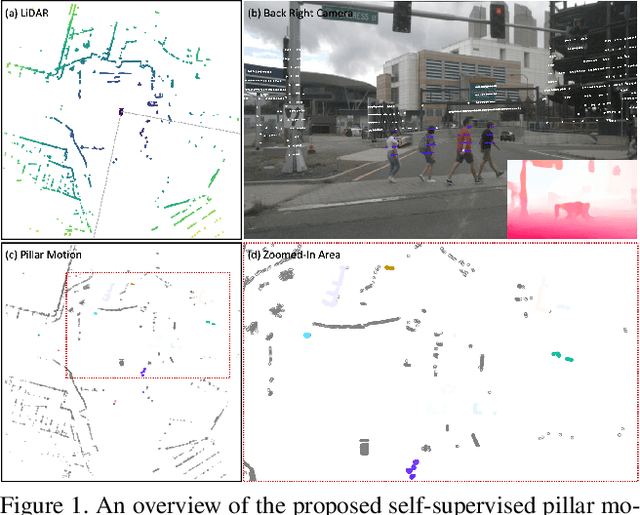

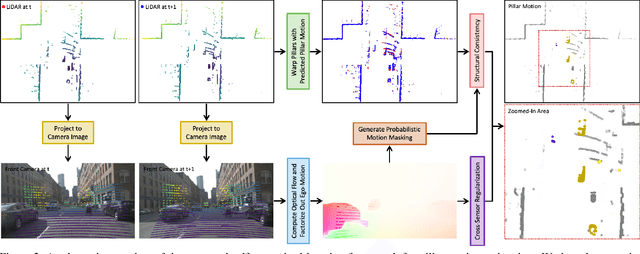

Autonomous driving can benefit from motion behavior comprehension when interacting with diverse traffic participants in highly dynamic environments. Recently, there has been a growing interest in estimating class-agnostic motion directly from point clouds. Current motion estimation methods usually require vast amount of annotated training data from self-driving scenes. However, manually labeling point clouds is notoriously difficult, error-prone and time-consuming. In this paper, we seek to answer the research question of whether the abundant unlabeled data collections can be utilized for accurate and efficient motion learning. To this end, we propose a learning framework that leverages free supervisory signals from point clouds and paired camera images to estimate motion purely via self-supervision. Our model involves a point cloud based structural consistency augmented with probabilistic motion masking as well as a cross-sensor motion regularization to realize the desired self-supervision. Experiments reveal that our approach performs competitively to supervised methods, and achieves the state-of-the-art result when combining our self-supervised model with supervised fine-tuning.
Training Convolutional ReLU Neural Networks in Polynomial Time: Exact Convex Optimization Formulations
Jun 26, 2020
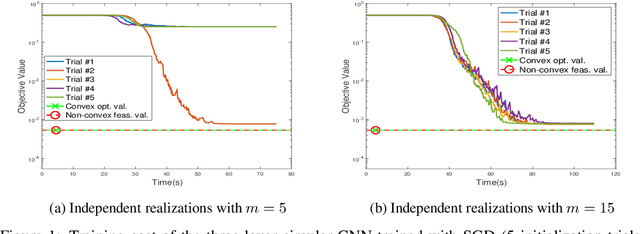

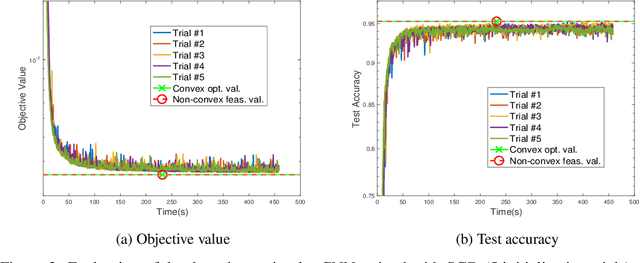
We study training of Convolutional Neural Networks (CNNs) with ReLU activations and introduce exact convex optimization formulations with a polynomial complexity with respect to the number of data samples, the number of neurons and data dimension. Particularly, we develop a convex analytic framework utilizing semi-infinite duality to obtain equivalent convex optimization problems for several CNN architectures. We first prove that two-layer CNNs can be globally optimized via an $\ell_2$ norm regularized convex program. We then show that certain three-layer CNN training problems are equivalent to an $\ell_1$ regularized convex program. We also extend these results to multi-layer CNN architectures. Furthermore, we present extensions of our approach to different pooling methods.
Legged Robot State Estimation in Slippery Environments Using Invariant Extended Kalman Filter with Velocity Update
Apr 09, 2021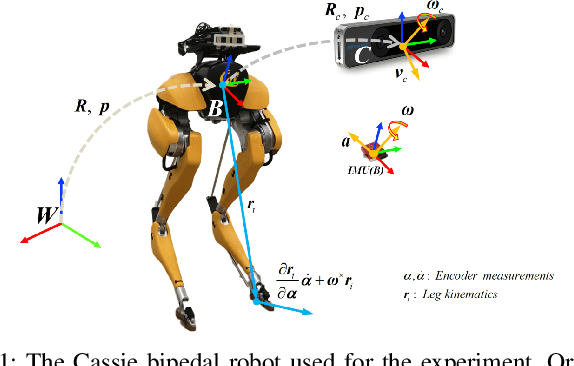
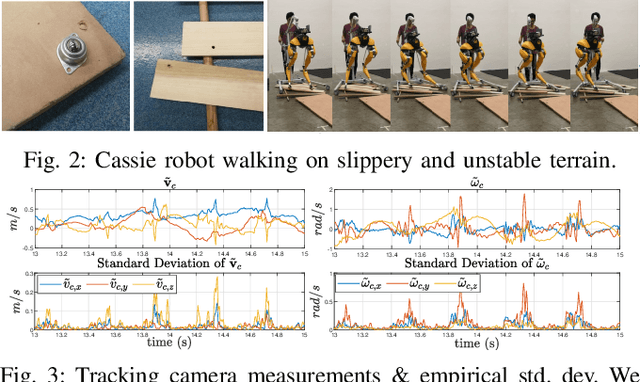
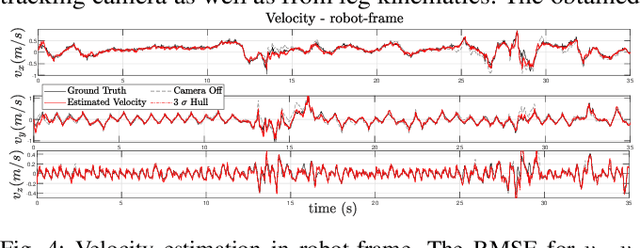
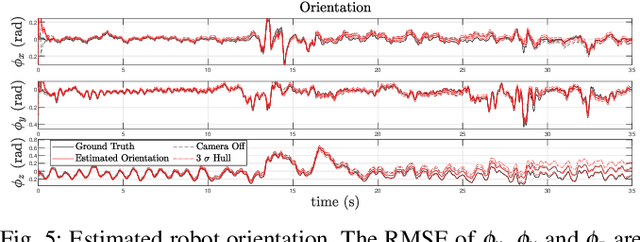
This paper proposes a state estimator for legged robots operating in slippery environments. An Invariant Extended Kalman Filter (InEKF) is implemented to fuse inertial and velocity measurements from a tracking camera and leg kinematic constraints. {\color{black}The misalignment between the camera and the robot-frame is also modeled thus enabling auto-calibration of camera pose.} The leg kinematics based velocity measurement is formulated as a right-invariant observation. Nonlinear observability analysis shows that other than the rotation around the gravity vector and the absolute position, all states are observable except for some singular cases. Discrete observability analysis demonstrates that our filter is consistent with the underlying nonlinear system. An online noise parameter tuning method is developed to adapt to the highly time-varying camera measurement noise. The proposed method is experimentally validated on a Cassie bipedal robot walking over slippery terrain. A video for the experiment can be found at https://youtu.be/VIqJL0cUr7s.
Heart-Darts: Classification of Heartbeats Using Differentiable Architecture Search
May 03, 2021
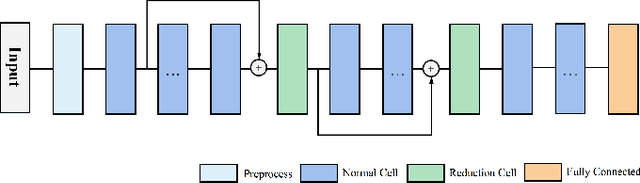
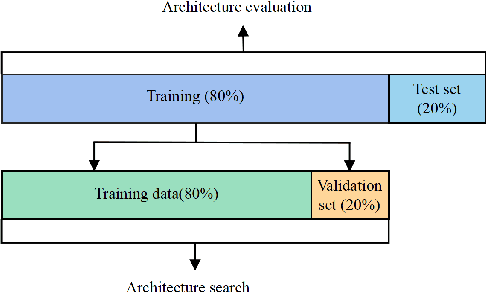
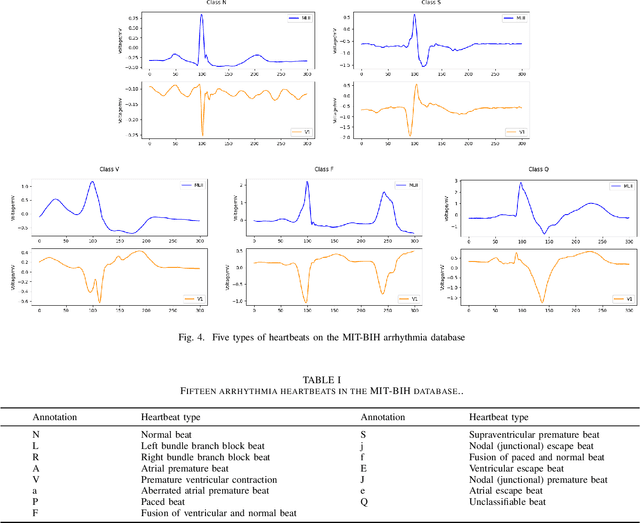
Arrhythmia is a cardiovascular disease that manifests irregular heartbeats. In arrhythmia detection, the electrocardiogram (ECG) signal is an important diagnostic technique. However, manually evaluating ECG signals is a complicated and time-consuming task. With the application of convolutional neural networks (CNNs), the evaluation process has been accelerated and the performance is improved. It is noteworthy that the performance of CNNs heavily depends on their architecture design, which is a complex process grounded on expert experience and trial-and-error. In this paper, we propose a novel approach, Heart-Darts, to efficiently classify the ECG signals by automatically designing the CNN model with the differentiable architecture search (i.e., Darts, a cell-based neural architecture search method). Specifically, we initially search a cell architecture by Darts and then customize a novel CNN model for ECG classification based on the obtained cells. To investigate the efficiency of the proposed method, we evaluate the constructed model on the MIT-BIH arrhythmia database. Additionally, the extensibility of the proposed CNN model is validated on two other new databases. Extensive experimental results demonstrate that the proposed method outperforms several state-of-the-art CNN models in ECG classification in terms of both performance and generalization capability.
Unsupervised Segmentation Algorithms for Infrared Cloud Images
Feb 19, 2021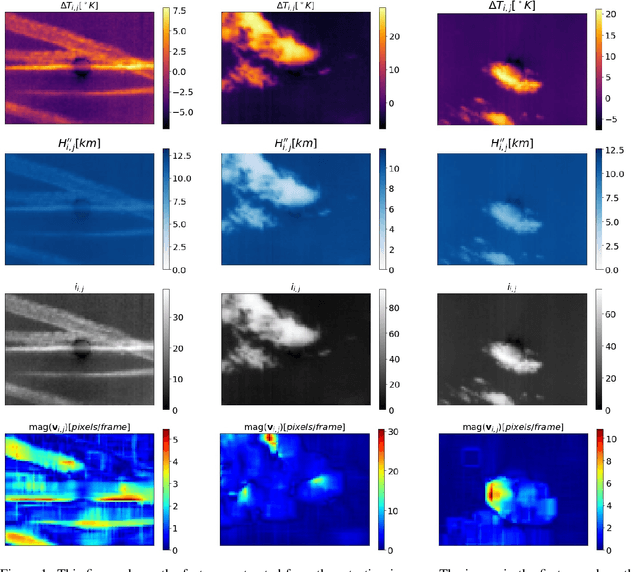
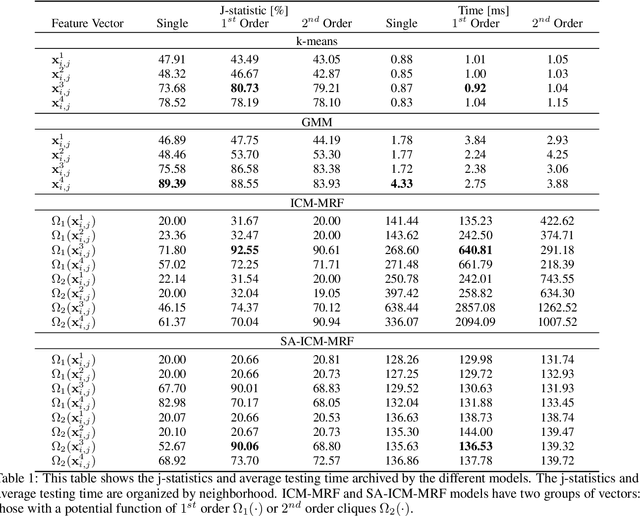

The increasing number of Photovoltaic (PV) systems connected to the power grids makes them vulnerable to the projection of shadows from moving clouds. Solar Global Irradiance (GSI) forecasting allows smart grids to optimize energy dispatch preventing cloud coverage shortages. This investigation compares the performances of unsupervised learning algorithms (not requiring labelled images for training) for real-time segmentation of clouds in a ground-base infrared sky-imaging system, which is commonly used to extract cloud features using only the pixels where clouds are detected.
A fast method for simultaneous reconstruction and segmentation in X-ray CT application
Jan 30, 2021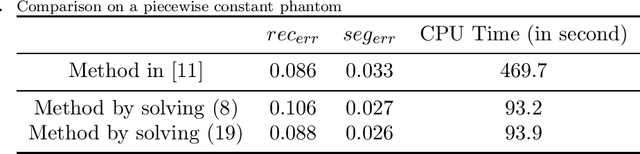


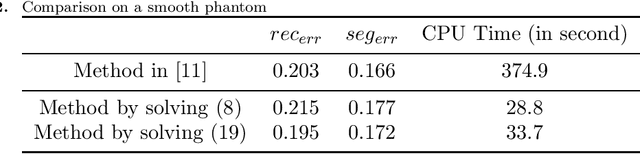
In this paper, we propose a fast method for simultaneous reconstruction and segmentation (SRS) in X-ray computed tomography (CT). Our work is based on the SRS model where Bayes' rule and the maximum a posteriori (MAP) are used on hidden Markov measure field model (HMMFM). The original method leads to a logarithmic-summation (log-sum) term, which is non-separable to the classification index. The minimization problem in the model was solved by using constrained gradient descend method, Frank-Wolfe algorithm, which is very time-consuming especially when dealing with large-scale CT problems. The starting point of this paper is the commutativity of log-sum operations, where the log-sum problem could be transformed into a sum-log problem by introducing an auxiliary variable. The corresponding sum-log problem for the SRS model is separable. After applying alternating minimization method, this problem turns into several easy-to-solve convex sub-problems. In the paper, we also study an improved model by adding Tikhonov regularization, and give some convergence results. Experimental results demonstrate that the proposed algorithms could produce comparable results with the original SRS method with much less CPU time.
Short-Term Flow-Based Bandwidth Forecasting using Machine Learning
Dec 03, 2020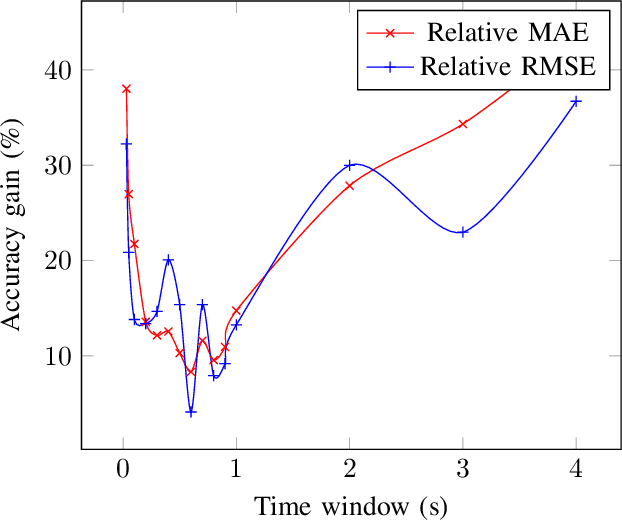
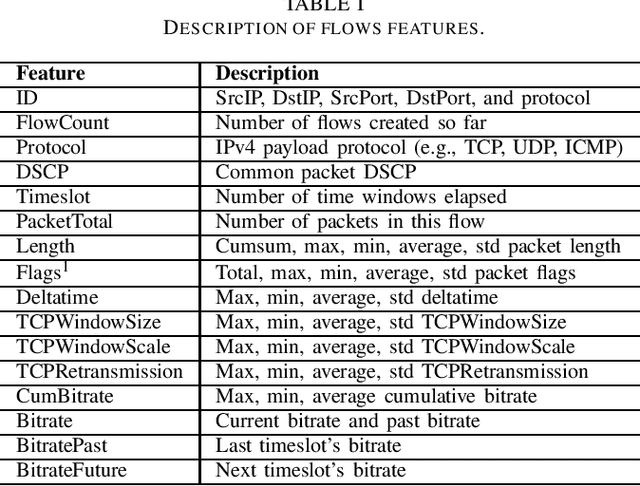
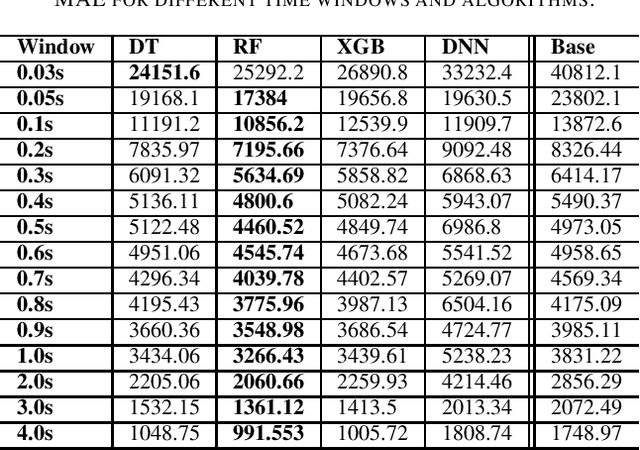
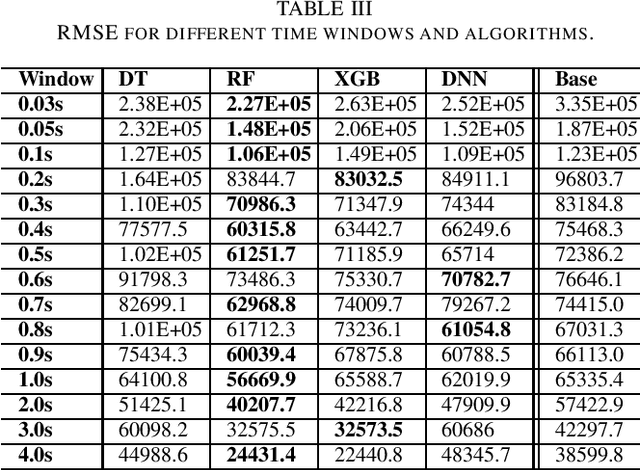
This paper proposes a novel framework to predict traffic flows' bandwidth ahead of time. Modern network management systems share a common issue: the network situation evolves between the moment the decision is made and the moment when actions (countermeasures) are applied. This framework converts packets from real-life traffic into flows containing relevant features. Machine learning models, including Decision Tree, Random Forest, XGBoost, and Deep Neural Network, are trained on these data to predict the bandwidth at the next time instance for every flow. Predictions can be fed to the management system instead of current flows bandwidth in order to take decisions on a more accurate network state. Experiments were performed on 981,774 flows and 15 different time windows (from 0.03s to 4s). They show that the Random Forest is the best performing and most reliable model, with a predictive performance consistently better than relying on the current bandwidth (+19.73% in mean absolute error and +18.00% in root mean square error). Experimental results indicate that this framework can help network management systems to take more informed decisions using a predicted network state.