 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accuracy Improvement for Fully Convolutional Networks via Selective Augmentation with Applications to Electrocardiogram Data
Apr 25, 2021
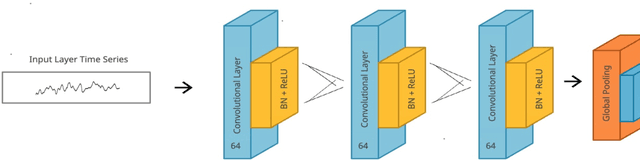

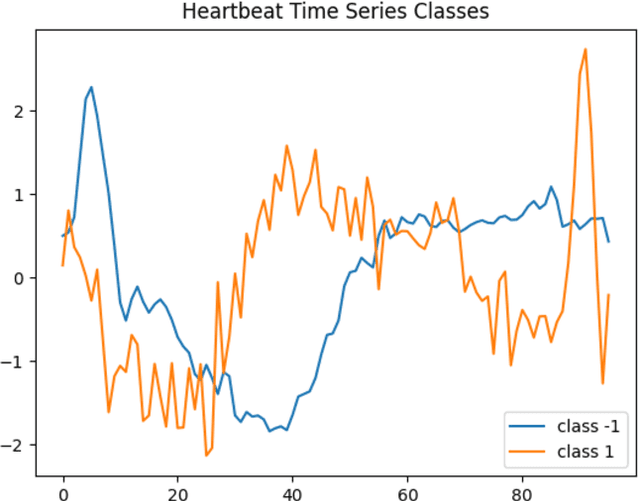
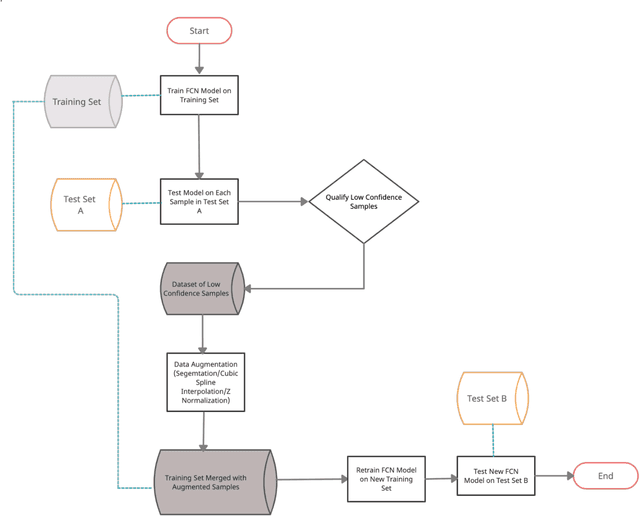
Deep learning methods have shown suitability for time series classification in the health and medical domain, with promising results for electrocardiogram data classification. Successful identification of myocardial infarction holds life saving potential and any meaningful improvement upon deep learning models in this area is of great interest. Conventionally, data augmentation methods are applied universally to the training set when data are limited in order to ameliorate data resolution or sample size. In the method proposed in this study, data augmentation was not applied in the context of data scarcity. Instead, samples that yield low confidence predictions were selectively augmented in order to bolster the model's sensitivity to features or patterns less strongly associated with a given class. This approach was tested for improving the performance of a Fully Convolutional Network. The proposed approach achieved 90 percent accuracy for classifying myocardial infarction as opposed to 82 percent accuracy for the baseline, a marked improvement. Further, the accuracy of the proposed approach was optimal near a defined upper threshold for qualifying low confidence samples and decreased as this threshold was raised to include higher confidence samples. This suggests exclusively selecting lower confidence samples for data augmentation comes with distinct benefits for electrocardiogram data classification with Fully Convolutional Networks.
An End-to-end Deep Reinforcement Learning Approach for the Long-term Short-term Planning on the Frenet Space
Nov 26, 2020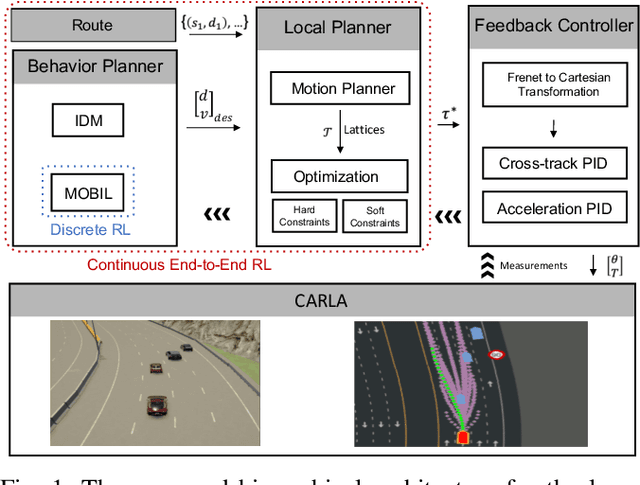

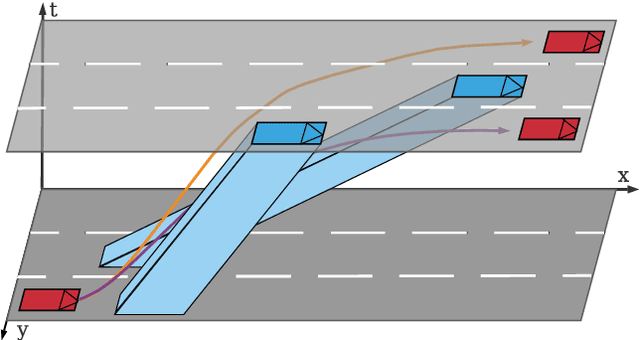
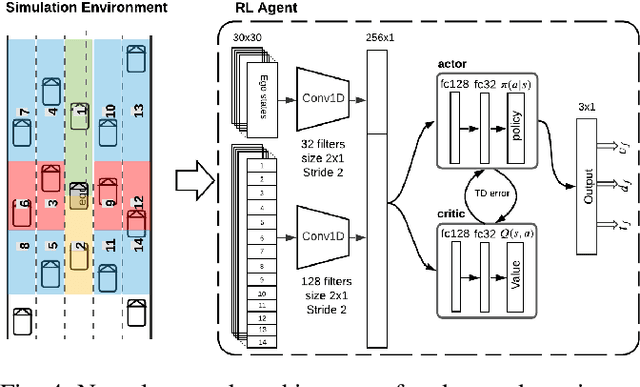
Tactical decision making and strategic motion planning for autonomous highway driving are challenging due to the complication of predicting other road users' behaviors, diversity of environments, and complexity of the traffic interactions. This paper presents a novel end-to-end continuous deep reinforcement learning approach towards autonomous cars' decision-making and motion planning. For the first time, we define both states and action spaces on the Frenet space to make the driving behavior less variant to the road curvatures than the surrounding actors' dynamics and traffic interactions. The agent receives time-series data of past trajectories of the surrounding vehicles and applies convolutional neural networks along the time channels to extract features in the backbone. The algorithm generates continuous spatiotemporal trajectories on the Frenet frame for the feedback controller to track. Extensive high-fidelity highway simulations on CARLA show the superiority of the presented approach compared with commonly used baselines and discrete reinforcement learning on various traffic scenarios. Furthermore, the proposed method's advantage is confirmed with a more comprehensive performance evaluation against 1000 randomly generated test scenarios.
Model-Based Clustering of Time-Evolving Networks through Temporal Exponential-Family Random Graph Models
Dec 20, 2017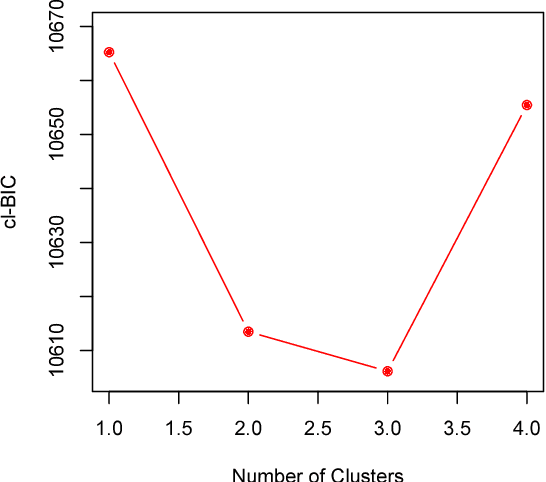
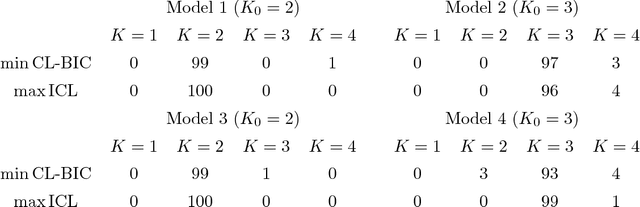
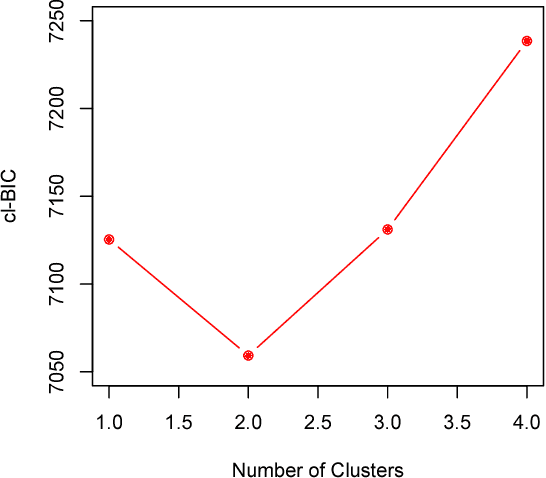
Dynamic networks are a general language for describing time-evolving complex systems, and discrete time network models provide an emerging statistical technique for various applications. It is a fundamental research question to detect the community structure in time-evolving networks. However, due to significant computational challenges and difficulties in modeling communities of time-evolving networks, there is little progress in the current literature to effectively find communities in time-evolving networks. In this work, we propose a novel model-based clustering framework for time-evolving networks based on discrete time exponential-family random graph models. To choose the number of communities, we use conditional likelihood to construct an effective model selection criterion. Furthermore, we propose an efficient variational expectation-maximization (EM) algorithm to find approximate maximum likelihood estimates of network parameters and mixing proportions. By using variational methods and minorization-maximization (MM) techniques, our method has appealing scalability for large-scale time-evolving networks. The power of our method is demonstrated in simulation studies and empirical applications to international trade networks and the collaboration networks of a large American research university.
End-to-End Interactive Prediction and Planning with Optical Flow Distillation for Autonomous Driving
Apr 18, 2021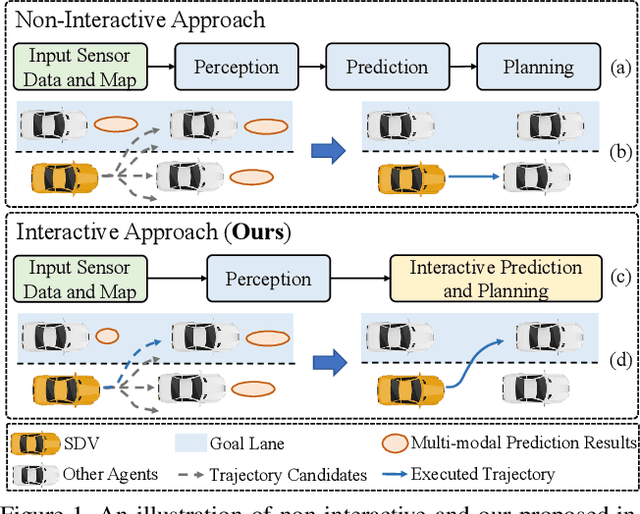
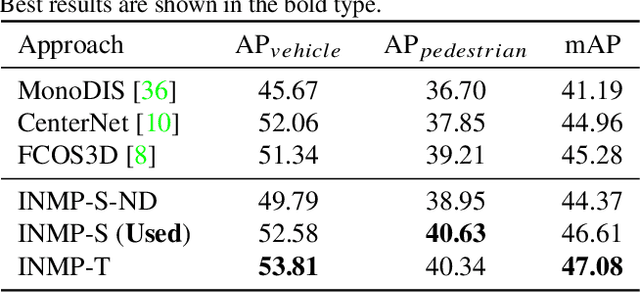
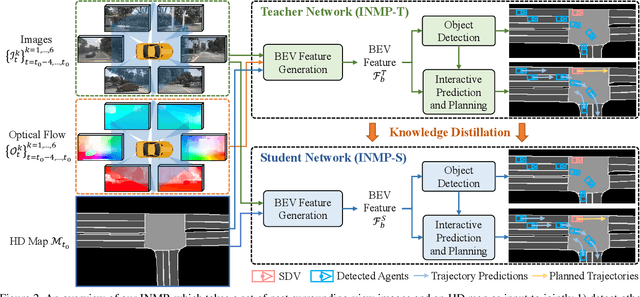
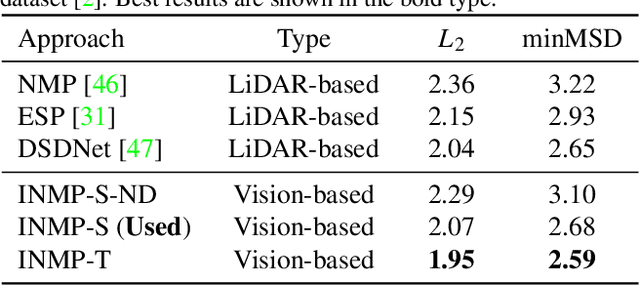
With the recent advancement of deep learning technology, data-driven approaches for autonomous car prediction and planning have achieved extraordinary performance. Nevertheless, most of these approaches follow a non-interactive prediction and planning paradigm, hypothesizing that a vehicle's behaviors do not affect others. The approaches based on such a non-interactive philosophy typically perform acceptably in sparse traffic scenarios but can easily fail in dense traffic scenarios. Therefore, we propose an end-to-end interactive neural motion planner (INMP) for autonomous driving in this paper. Given a set of past surrounding-view images and a high definition map, our INMP first generates a feature map in bird's-eye-view space, which is then processed to detect other agents and perform interactive prediction and planning jointly. Also, we adopt an optical flow distillation paradigm, which can effectively improve the network performance while still maintaining its real-time inference speed. Extensive experiments on the nuScenes dataset and in the closed-loop Carla simulation environment demonstrate the effectiveness and efficiency of our INMP for the detection, prediction, and planning tasks. Our project page is at sites.google.com/view/inmp-ofd.
Learning Interpretable End-to-End Vision-Based Motion Planning for Autonomous Driving with Optical Flow Distillation
Apr 18, 2021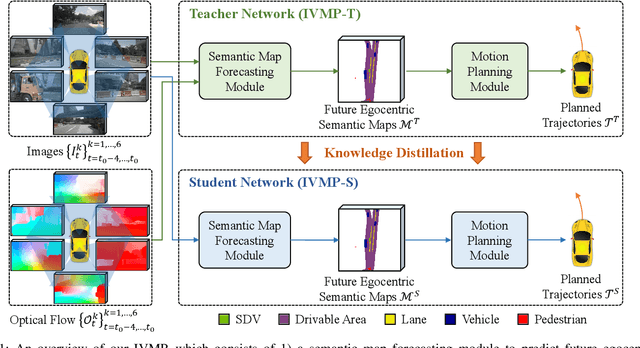
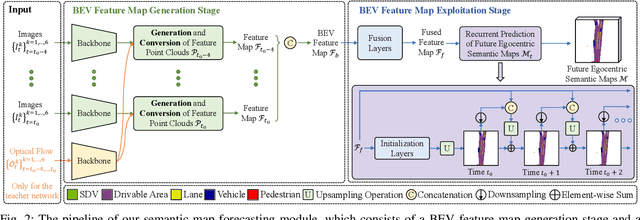

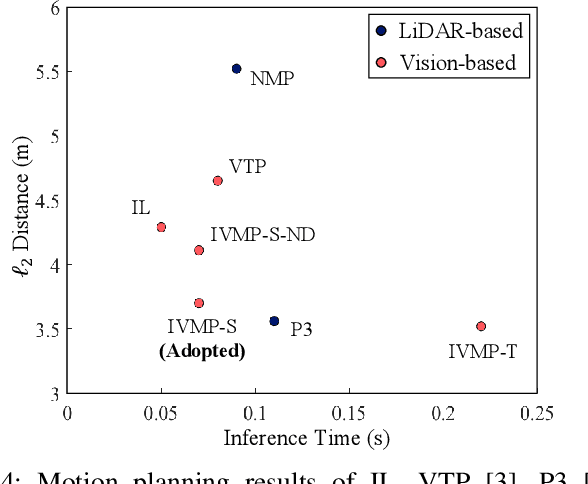
Recently, deep-learning based approaches have achieved impressive performance for autonomous driving. However, end-to-end vision-based methods typically have limited interpretability, making the behaviors of the deep networks difficult to explain. Hence, their potential applications could be limited in practice. To address this problem, we propose an interpretable end-to-end vision-based motion planning approach for autonomous driving, referred to as IVMP. Given a set of past surrounding-view images, our IVMP first predicts future egocentric semantic maps in bird's-eye-view space, which are then employed to plan trajectories for self-driving vehicles. The predicted future semantic maps not only provide useful interpretable information, but also allow our motion planning module to handle objects with low probability, thus improving the safety of autonomous driving. Moreover, we also develop an optical flow distillation paradigm, which can effectively enhance the network while still maintaining its real-time performance. Extensive experiments on the nuScenes dataset and closed-loop simulation show that our IVMP significantly outperforms the state-of-the-art approaches in imitating human drivers with a much higher success rate. Our project page is available at https://sites.google.com/view/ivmp.
Windowed total variation denoising and noise variance monitoring
Jan 28, 2021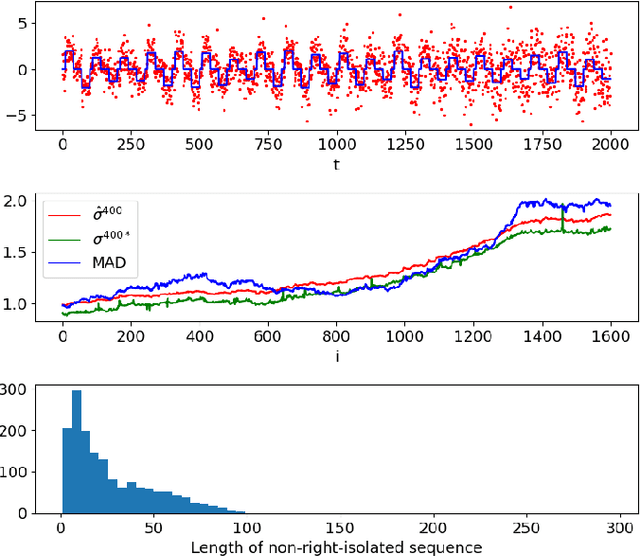
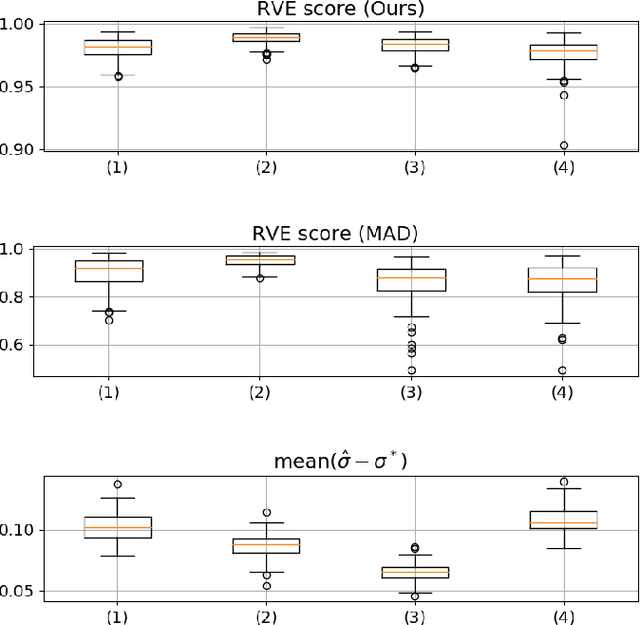
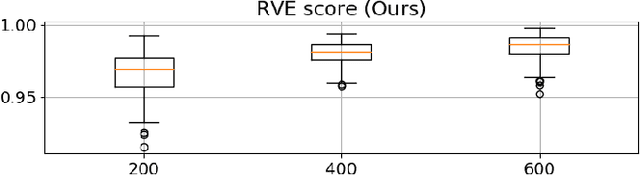
We proposed a real time Total-Variation denosing method with an automatic choice of hyper-parameter $\lambda$, and the good performance of this method provides a large application field. In this article, we adapt the developed method to the non stationary signal in using the sliding window, and propose a noise variance monitoring method. The simulated results show that our proposition follows well the variation of noise variance.
QoE Optimization for Live Video Streaming in UAV-to-UAV Communications via Deep Reinforcement Learning
Feb 21, 2021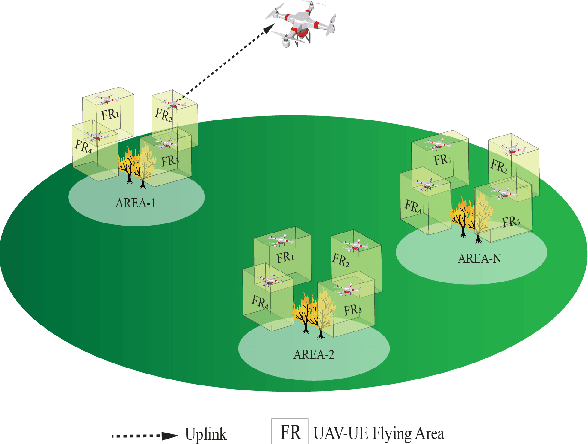
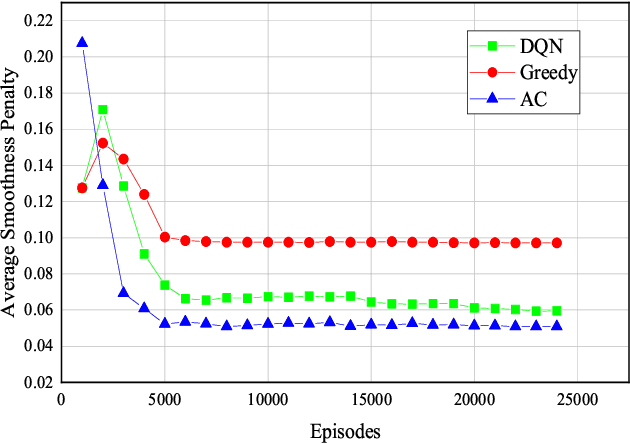
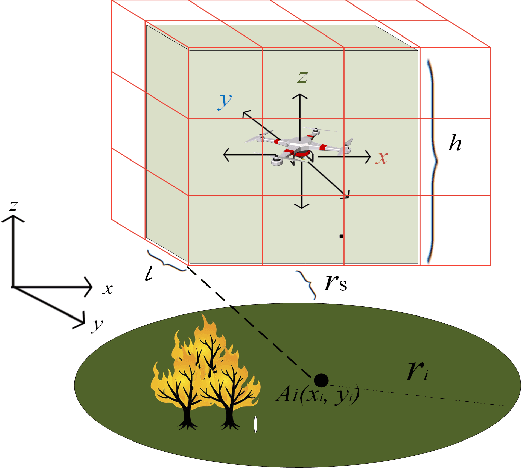
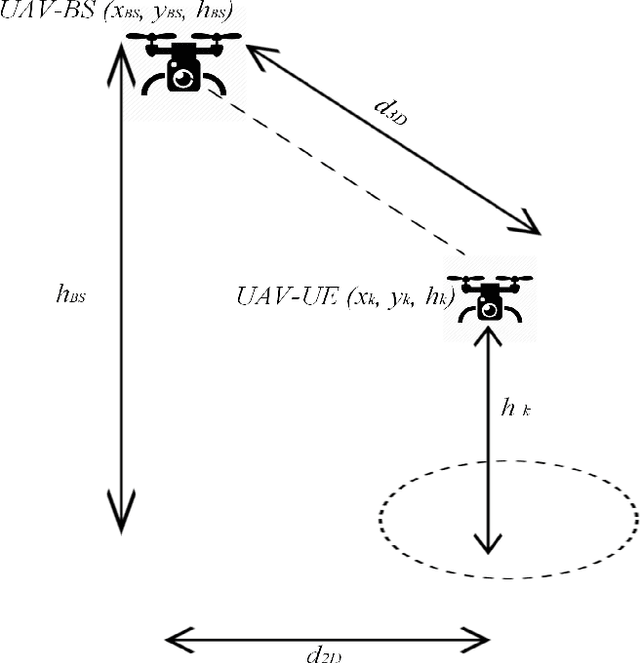
A challenge for rescue teams when fighting against wildfire in remote areas is the lack of information, such as the size and images of fire areas. As such, live streaming from Unmanned Aerial Vehicles (UAVs), capturing videos of dynamic fire areas, is crucial for firefighter commanders in any location to monitor the fire situation with quick response. The 5G network is a promising wireless technology to support such scenarios. In this paper, we consider a UAV-to-UAV (U2U) communication scenario, where a UAV at a high altitude acts as a mobile base station (UAV-BS) to stream videos from other flying UAV-users (UAV-UEs) through the uplink. Due to the mobility of the UAV-BS and UAV-UEs, it is important to determine the optimal movements and transmission powers for UAV-BSs and UAV-UEs in real-time, so as to maximize the data rate of video transmission with smoothness and low latency, while mitigating the interference according to the dynamics in fire areas and wireless channel conditions. In this paper, we co-design the video resolution, the movement, and the power control of UAV-BS and UAV-UEs to maximize the Quality of Experience (QoE) of real-time video streaming. To learn the Deep Q-Network (DQN) and Actor-Critic (AC) to maximize the QoE of video transmission from all UAV-UEs to a single UAVBS. Simulation results show the effectiveness of our proposed algorithm in terms of the QoE, delay and video smoothness as compared to the Greedy algorithm.
Fast and Feature-Complete Differentiable Physics for Articulated Rigid Bodies with Contact
Apr 01, 2021
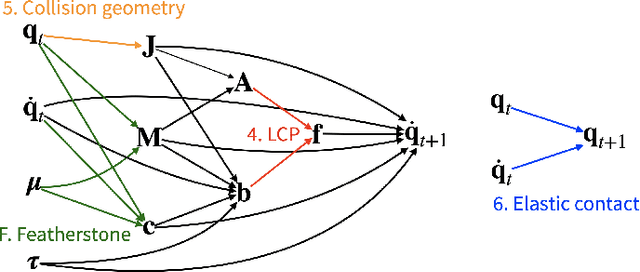
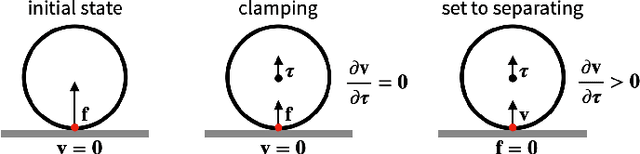
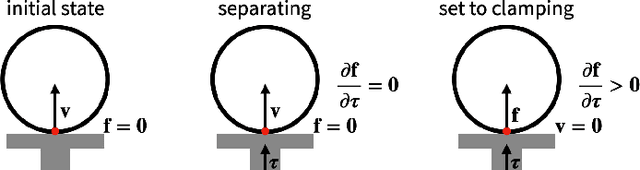
We present a fast and feature-complete differentiable physics engine that supports Lagrangian dynamics and hard contact constraints for articulated rigid body simulation. Our differentiable physics engine offers a complete set of features that are typically only available in non-differentiable physics simulators commonly used by robotics applications. We solve contact constraints precisely using linear complementarity problems (LCPs). We present efficient and novel analytical gradients through the LCP formulation of inelastic contact that exploit the sparsity of the LCP solution. We support complex contact geometry, and gradients approximating continuous-time elastic collision. We also introduce a novel method to compute complementarity-aware gradients that help downstream optimization tasks avoid stalling in saddle points. We show that an implementation of this combination in an existing physics engine (DART) is capable of a 45x single-core speedup over finite-differencing in computing analytical Jacobians for a single timestep, while preserving all the expressiveness of original DART.
Dispersion from Diffuse Reflectors and its Effect of Terahertz Wireless Communication Performance
Apr 01, 2021
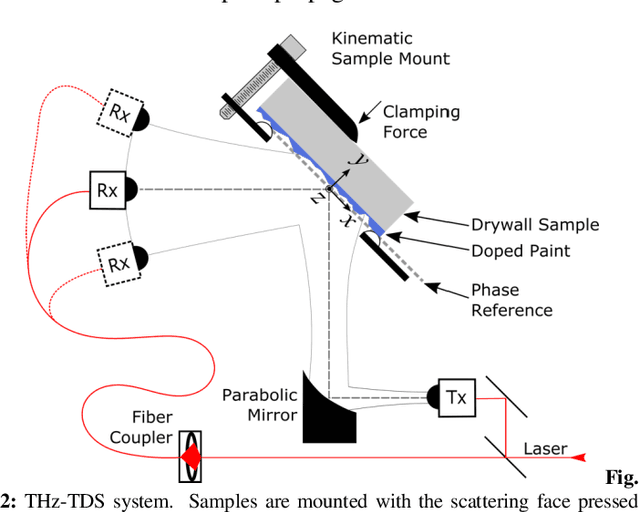
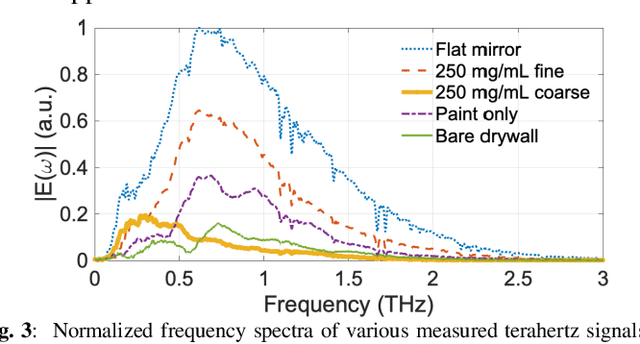
This work investigates the temporal dispersion of a wireless terahertz communication signal caused by reflection from a rough (diffuse) surface, and its subsequent impact on symbol error rate versus data rate. Broadband measurements of diffuse reflectors using terahertz time-domain spectroscopy were used to establish and validate a scattering model that uses stochastic methods to describe the effects of surface roughness on the phase and amplitude of a reflected terahertz signal, expressed as a communication channel transfer function. The modeled channel was used to simulate a quadrature phase shift keying (QPSK)- modulated wireless communication link to determine the relationships between symbol error rate and data rate as a function of surface roughness. The simulations reveal that surface roughness from wall texturing results in group delay dispersion that limits achievable data rate with low errors. A distinct dispersion limit in surface roughness is discovered beyond which unacceptable numbers of symbol errors begin to accrue for a given data rate.
Composable Augmentation Encoding for Video Representation Learning
Apr 01, 2021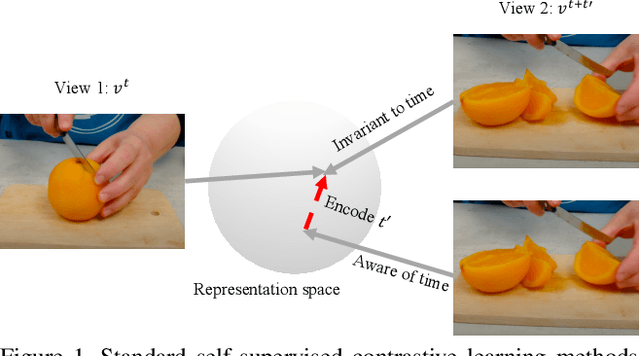

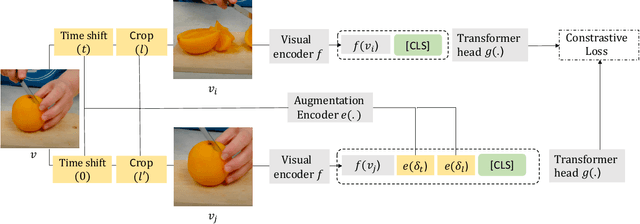

We focus on contrastive methods for self-supervised video representation learning. A common paradigm in contrastive learning is to construct positive pairs by sampling different data views for the same instance, with different data instances as negatives. These methods implicitly assume a set of representational invariances to the view selection mechanism (eg, sampling frames with temporal shifts), which may lead to poor performance on downstream tasks which violate these invariances (fine-grained video action recognition that would benefit from temporal information). To overcome this limitation, we propose an 'augmentation aware' contrastive learning framework, where we explicitly provide a sequence of augmentation parameterisations (such as the values of the time shifts used to create data views) as composable augmentation encodings (CATE) to our model when projecting the video representations for contrastive learning. We show that representations learned by our method encode valuable information about specified spatial or temporal augmentation, and in doing so also achieve state-of-the-art performance on a number of video benchmarks.