 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WATTNet: Learning to Trade FX via Hierarchical Spatio-Temporal Representation of Highly Multivariate Time Series
Sep 24, 2019

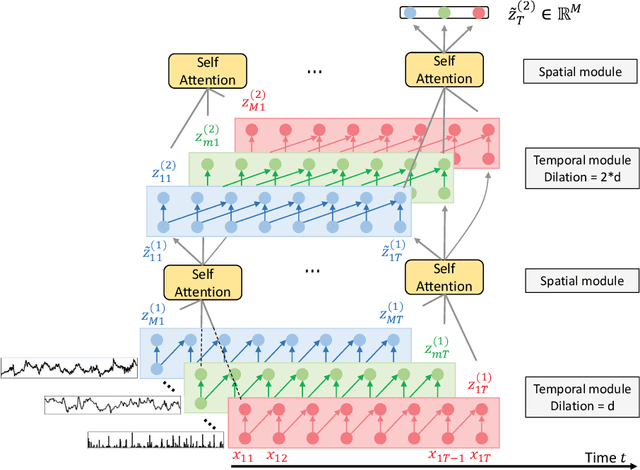
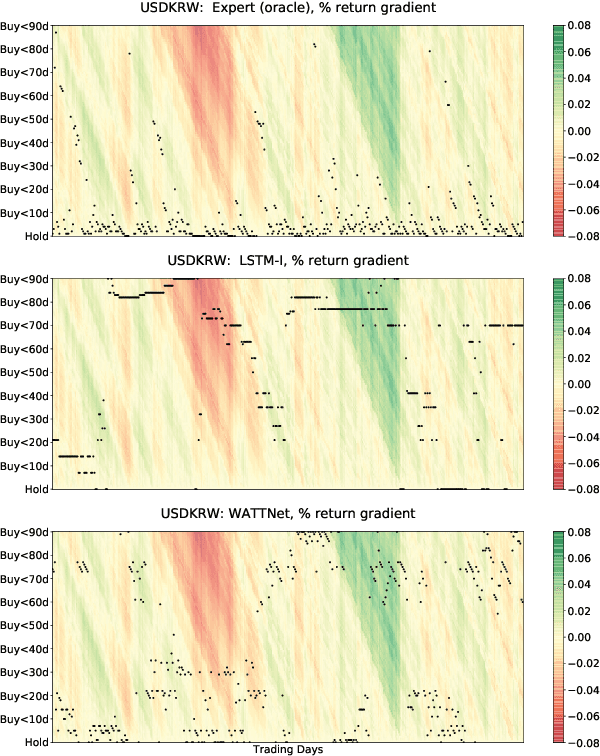
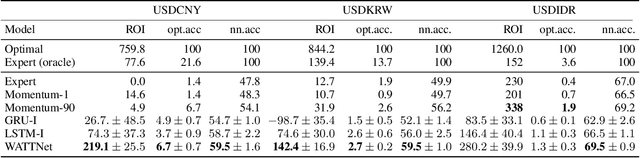
Finance is a particularly challenging application area for deep learning models due to low noise-to-signal ratio, non-stationarity, and partial observability. Non-deliverable-forwards (NDF), a derivatives contract used in foreign exchange (FX) trading, presents additional difficulty in the form of long-term planning required for an effective selection of start and end date of the contract. In this work, we focus on tackling the problem of NDF tenor selection by leveraging high-dimensional sequential data consisting of spot rates, technical indicators and expert tenor patterns. To this end, we construct a dataset from the Depository Trust & Clearing Corporation (DTCC) NDF data that includes a comprehensive list of NDF volumes and daily spot rates for 64 FX pairs. We introduce WaveATTentionNet (WATTNet), a novel temporal convolution (TCN) model for spatio-temporal modeling of highly multivariate time series, and validate it across NDF markets with varying degrees of dissimilarity between the training and test periods in terms of volatility and general market regimes. The proposed method achieves a significant positive return on investment (ROI) in all NDF markets under analysis, outperforming recurrent and classical baselines by a wide margin. Finally, we propose two orthogonal interpretability approaches to verify noise stability and detect the driving factors of the learned tenor selection strategy.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021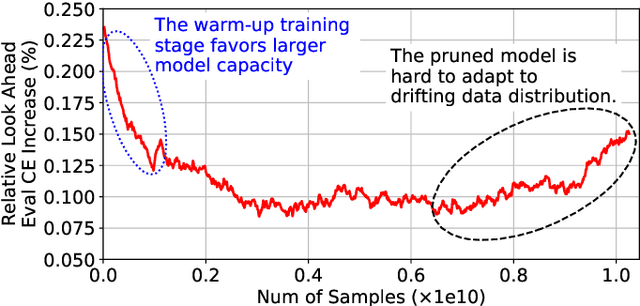

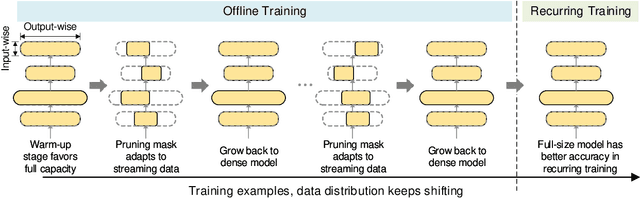

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Eliminating Sharp Minima from SGD with Truncated Heavy-tailed Noise
Feb 08, 2021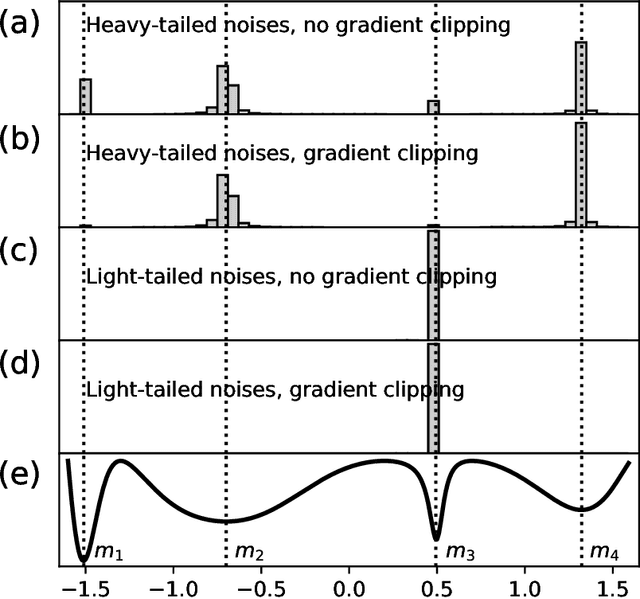
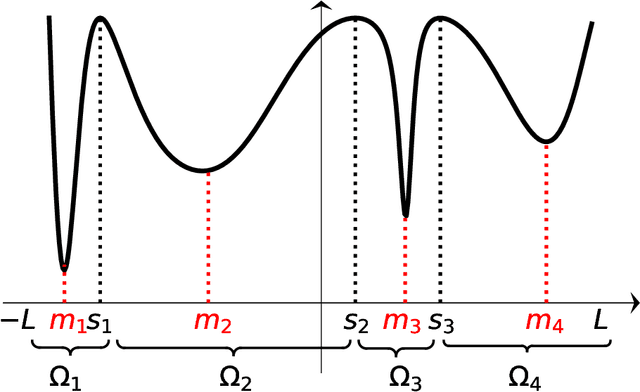
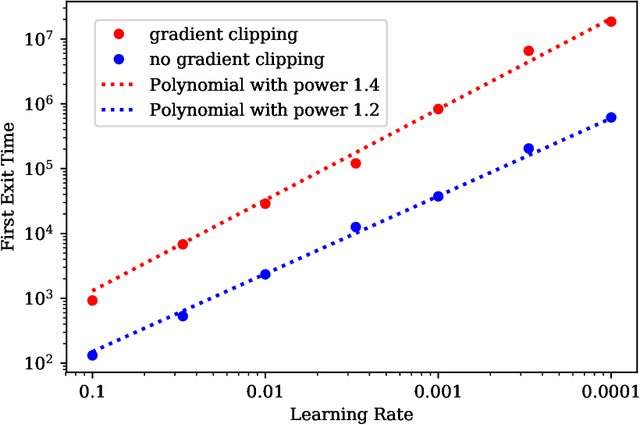
The empirical success of deep learning is often attributed to SGD's mysterious ability to avoid sharp local minima in the loss landscape, which is well known to lead to poor generalization. Recently, empirical evidence of heavy-tailed gradient noise was reported in many deep learning tasks; under the presence of such heavy-tailed noise, it can be shown that SGD can escape sharp local minima, providing a partial solution to the mystery. In this work, we analyze a popular variant of SGD where gradients are truncated above a fixed threshold. We show that it achieves a stronger notion of avoiding sharp minima; it can effectively eliminate sharp local minima entirely from its training trajectory. We characterize the dynamics of truncated SGD driven by heavy-tailed noises. First, we show that the truncation threshold and width of the attraction field dictate the order of the first exit time from the associated local minimum. Moreover, when the objective function satisfies appropriate structural conditions, we prove that as the learning rate decreases the dynamics of the heavy-tailed SGD closely resemble that of a special continuous-time Markov chain which never visits any sharp minima. We verify our theoretical results with numerical experiments and discuss the implications on the generalizability of SGD in deep learning.
Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
Apr 18, 2021
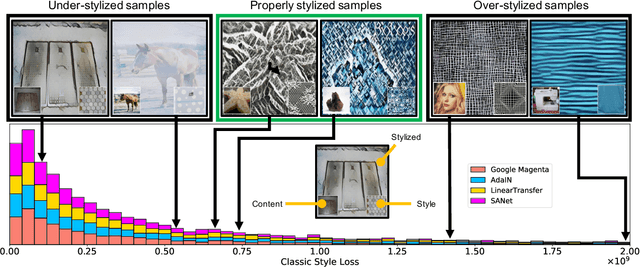
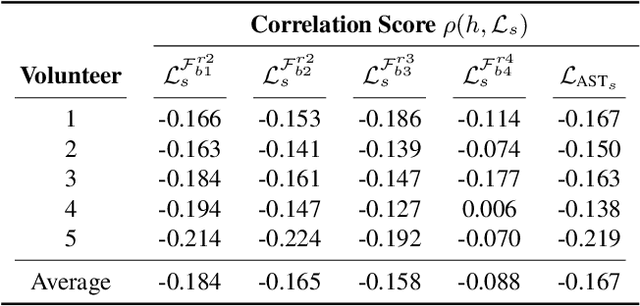
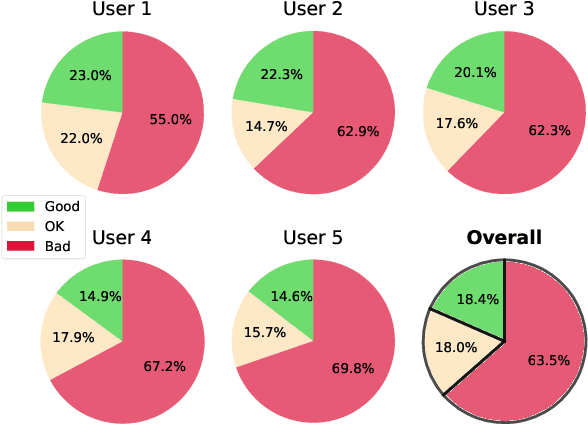
Neural Style Transfer (NST) has quickly evolved from single-style to infinite-style models, also known as Arbitrary Style Transfer (AST). Although appealing results have been widely reported in literature, our empirical studies on four well-known AST approaches (GoogleMagenta, AdaIN, LinearTransfer, and SANet) show that more than 50% of the time, AST stylized images are not acceptable to human users, typically due to under- or over-stylization. We systematically study the cause of this imbalanced style transferability (IST) and propose a simple yet effective solution to mitigate this issue. Our studies show that the IST issue is related to the conventional AST style loss, and reveal that the root cause is the equal weightage of training samples irrespective of the properties of their corresponding style images, which biases the model towards certain styles. Through investigation of the theoretical bounds of the AST style loss, we propose a new loss that largely overcomes IST. Theoretical analysis and experimental results validate the effectiveness of our loss, with over 80% relative improvement in style deception rate and 98% relatively higher preference in human evaluation.
Attention-based Clinical Note Summarization
Apr 18, 2021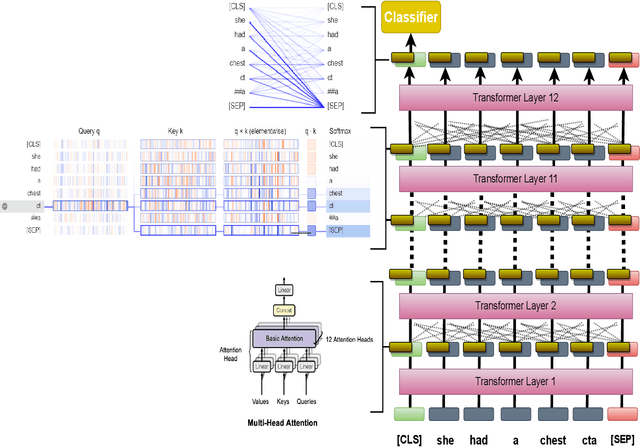

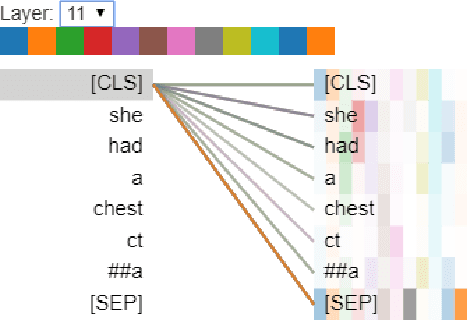
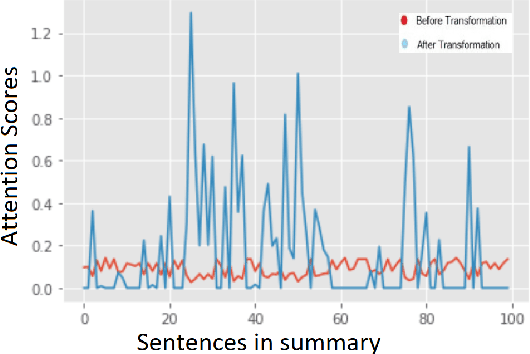
The trend of deploying digital systems in numerous industries has induced a hike in recording digital information. The health sector has observed a large adoption of digital devices and systems generating large volumes of personal medical health records. Electronic health records contain valuable information for retrospective and prospective analysis that is often not entirely exploited because of the dense information storage. The crude purpose of condensing health records is to select the information that holds most characteristics of the original documents based on reported disease. These summaries may boost diagnosis and extend a doctor's interaction time with the patient during a high workload situation like the COVID-19 pandemic. In this paper, we propose a multi-head attention-based mechanism to perform extractive summarization of meaningful phrases in clinical notes. This method finds major sentences for a summary by correlating tokens, segments and positional embeddings. The model outputs attention scores that are statistically transformed to extract key phrases and can be used for a projection on the heat-mapping tool for visual and human use.
Identifying Actions for Sound Event Classification
Apr 26, 2021
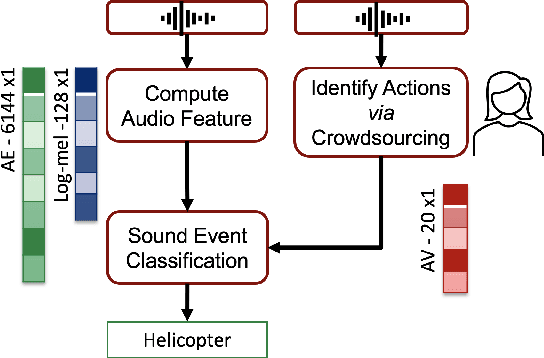
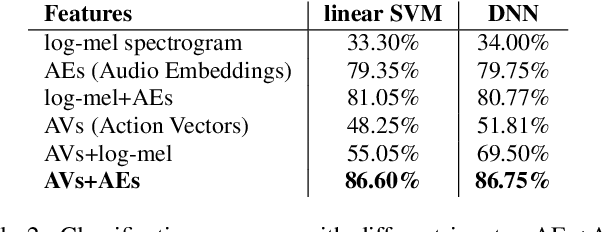

In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.
A Low-Complexity MIMO Channel Estimator with Implicit Structure of a Convolutional Neural Network
Apr 26, 2021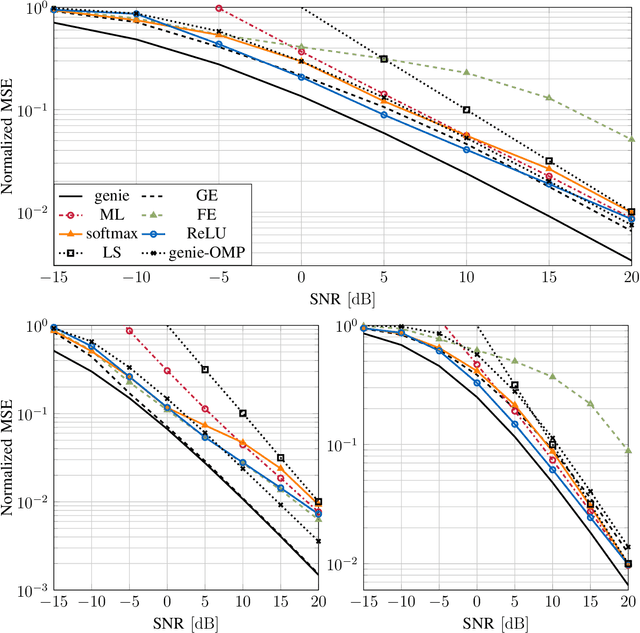
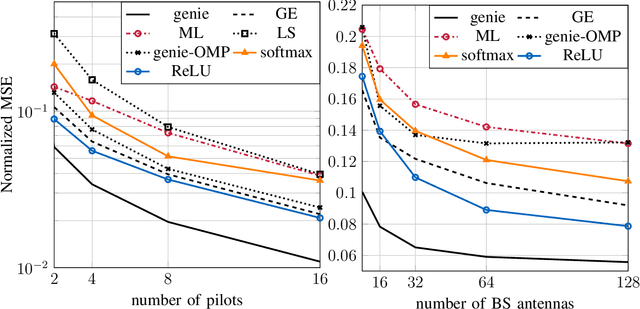
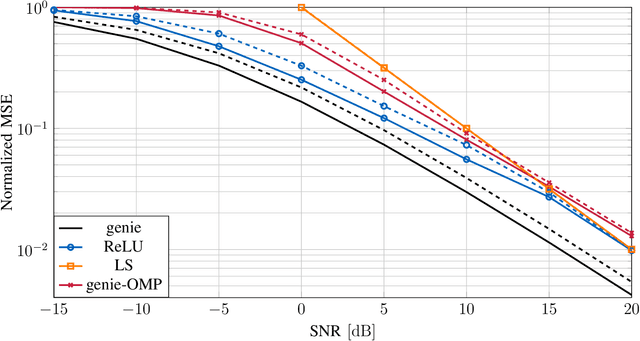
A low-complexity convolutional neural network estimator which learns the minimum mean squared error channel estimator for single-antenna users was recently proposed. We generalize the architecture to the estimation of MIMO channels with multiple-antenna users and incorporate complexity-reducing assumptions based on the channel model. Learning is used in this context to combat the mismatch between the assumptions and real scenarios where the assumptions may not hold. We derive a high-level description of the estimator for arbitrary choices of the pilot sequence. It turns out that the proposed estimator has the implicit structure of a two-layered convolutional neural network, where the derived quantities can be relaxed to learnable parameters. We show that by using discrete Fourier transform based pilots the number of learnable network parameters decreases significantly and the online run time of the estimator is reduced considerably, where we can achieve linearithmic order of complexity in the number of antennas. Numerical results demonstrate performance gains compared to state-of-the-art algorithms from the field of compressive sensing or covariance estimation of the same or even higher computational complexity. The simulation code is available online.
Classifying Cycling Hazards in Egocentric Data
Mar 15, 2021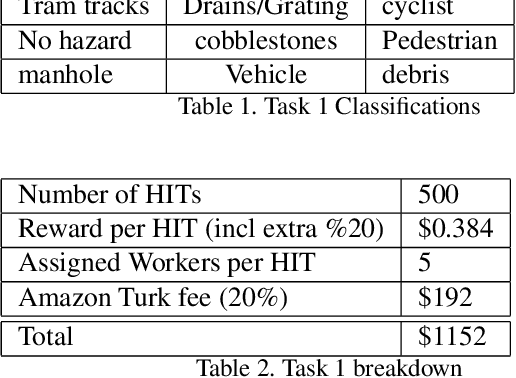

This proposal is for the creation and annotation of an egocentric video data set of hazardous cycling situations. The resulting data set will facilitate projects to improve the safety and experience of cyclists. Since cyclists are highly sensitive to road surface conditions and hazards they require more detail about road conditions when navigating their route. Features such as tram tracks, cobblestones, gratings, and utility access points can pose hazards or uncomfortable riding conditions for their journeys. Possible uses for the data set are identifying existing hazards in cycling infrastructure for municipal authorities, real time hazard and surface condition warnings for cyclists, and the identification of conditions that cause cyclists to make sudden changes in their immediate route.
Supervised Chorus Detection for Popular Music Using Convolutional Neural Network and Multi-task Learning
Mar 26, 2021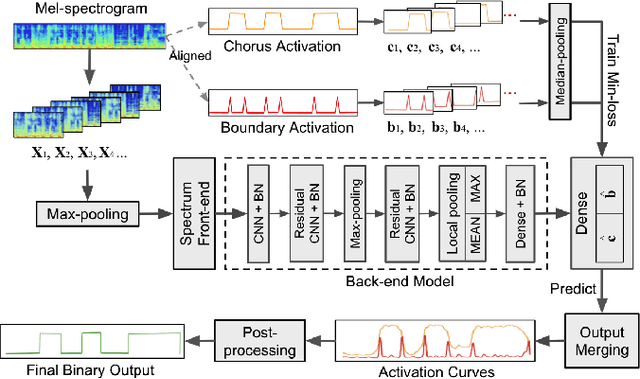
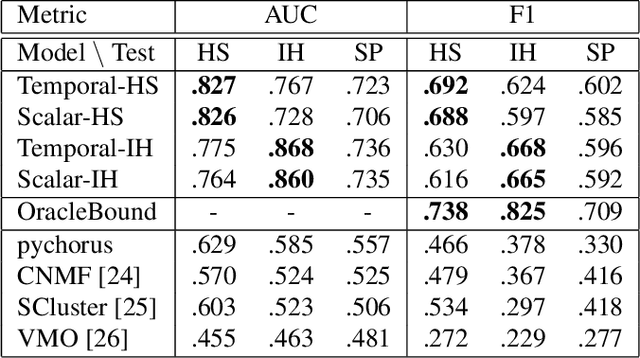
This paper presents a novel supervised approach to detecting the chorus segments in popular music. Traditional approaches to this task are mostly unsupervised, with pipelines designed to target some quality that is assumed to define "chorusness," which usually means seeking the loudest or most frequently repeated sections. We propose to use a convolutional neural network with a multi-task learning objective, which simultaneously fits two temporal activation curves: one indicating "chorusness" as a function of time, and the other the location of the boundaries. We also propose a post-processing method that jointly takes into account the chorus and boundary predictions to produce binary output. In experiments using three datasets, we compare our system to a set of public implementations of other segmentation and chorus-detection algorithms, and find our approach performs significantly better.
A Simulated Annealing Algorithm for Joint Stratification and Sample Allocation Designs
Nov 25, 2020
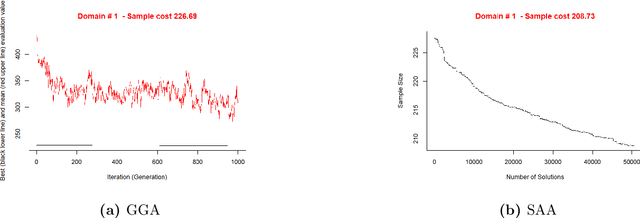
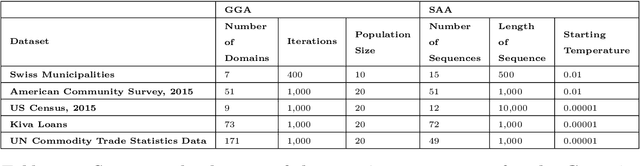
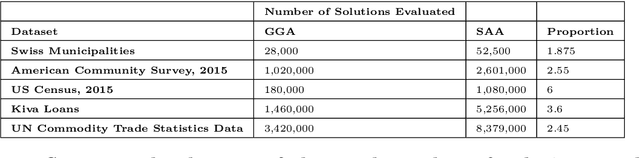
This study combined simulated annealing with delta evaluation to solve the joint stratification and sample allocation problem. In this problem, atomic strata are partitioned into mutually exclusive and collectively exhaustive strata. Each stratification is a solution, the quality of which is measured by its cost. The Bell number of possible solutions is enormous for even a moderate number of atomic strata and an additional layer of complexity is added with the evaluation time of each solution. Many larger scale combinatorial optimisation problems cannot be solved to optimality because the search for an optimum solution requires a prohibitive amount of computation time; a number of local search heuristic algorithms have been designed for this problem but these can become trapped in local minima preventing any further improvements. We add to the existing suite of local search algorithms with a simulated annealing algorithm that allows for an escape from local minima and uses delta evaluation to exploit the similarity between consecutive solutions and thereby reduce the evaluation time.