 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Machine Learning Techniques for Coq: A Comparison
Apr 12, 2021
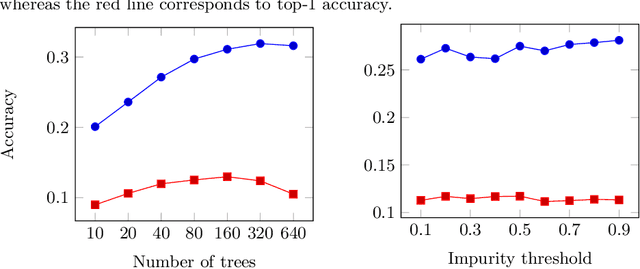
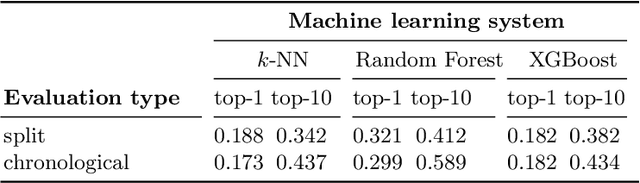
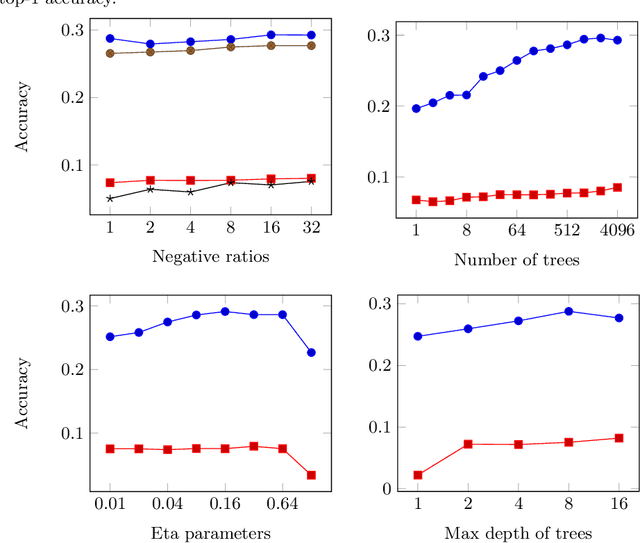
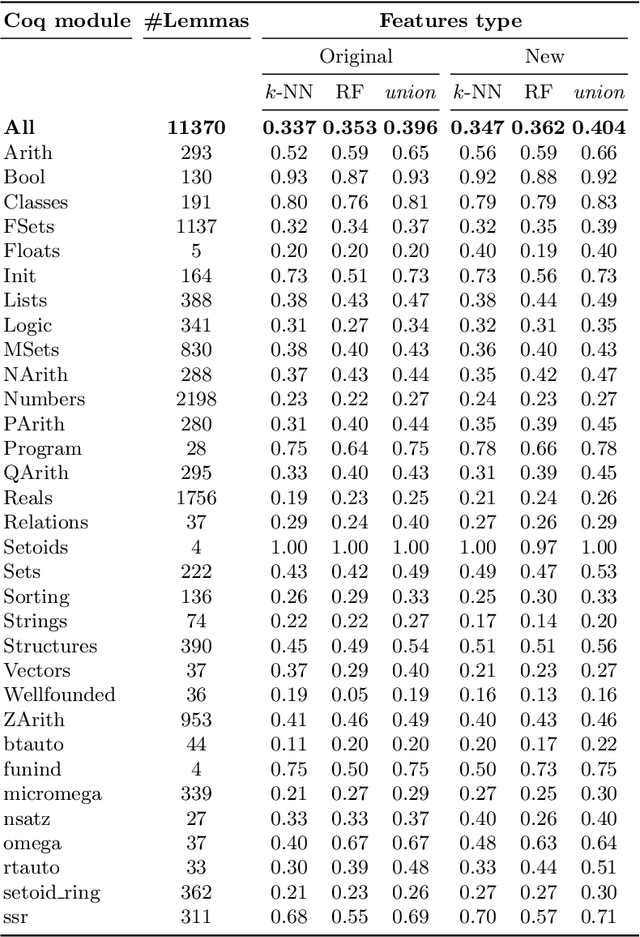
We present a comparison of several online machine learning techniques for tactical learning and proving in the Coq proof assistant. This work builds on top of Tactician, a plugin for Coq that learns from proofs written by the user to synthesize new proofs. This learning happens in an online manner -- meaning that Tactician's machine learning model is updated immediately every time the user performs a step in an interactive proof. This has important advantages compared to the more studied offline learning systems: (1) it provides the user with a seamless, interactive experience with Tactician and, (2) it takes advantage of locality of proof similarity, which means that proofs similar to the current proof are likely to be found close by. We implement two online methods, namely approximate $k$-nearest neighbors based on locality sensitive hashing forests and random decision forests. Additionally, we conduct experiments with gradient boosted trees in an offline setting using XGBoost. We compare the relative performance of Tactician using these three learning methods on Coq's standard library.
Comparing Popular Simulation Environments in the Scope of Robotics and Reinforcement Learning
Mar 08, 2021

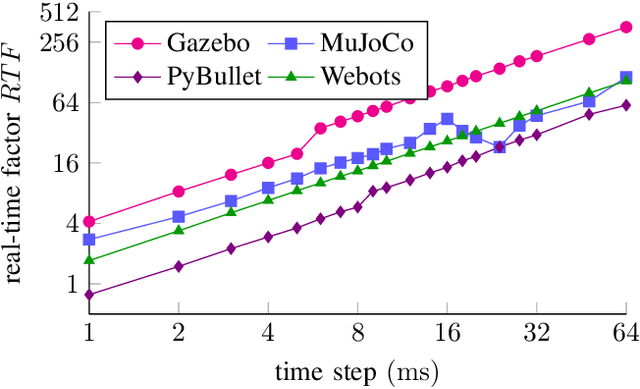
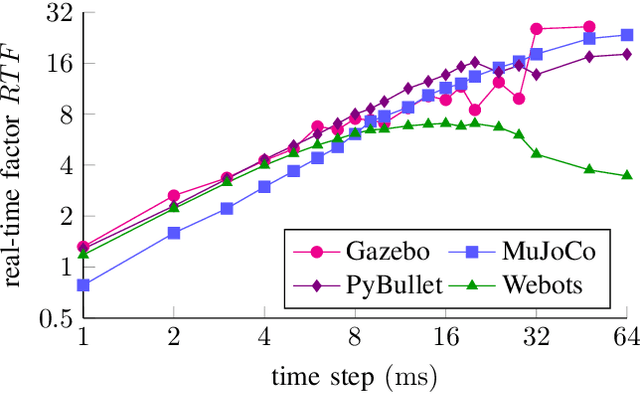
This letter compares the performance of four different, popular simulation environments for robotics and reinforcement learning (RL) through a series of benchmarks. The benchmarked scenarios are designed carefully with current industrial applications in mind. Given the need to run simulations as fast as possible to reduce the real-world training time of the RL agents, the comparison includes not only different simulation environments but also different hardware configurations, ranging from an entry-level notebook up to a dual CPU high performance server. We show that the chosen simulation environments benefit the most from single core performance. Yet, using a multi core system, multiple simulations could be run in parallel to increase the performance.
Location Trace Privacy Under Conditional Priors
Feb 23, 2021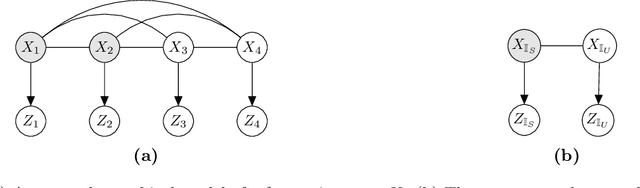
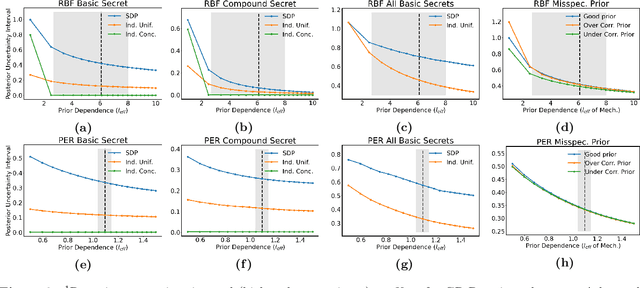
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a R\'enyi divergence based privacy framework for bounding expected privacy loss for conditionally dependent data. Additionally, we demonstrate an algorithm for achieving this privacy under Gaussian process conditional priors. This framework both exemplifies why conditionally dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user's trace.
Autotuning PolyBench Benchmarks with LLVM Clang/Polly Loop Optimization Pragmas Using Bayesian Optimization (extended version)
Apr 27, 2021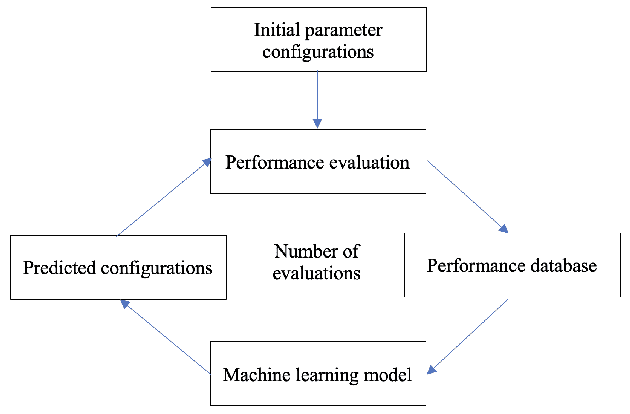

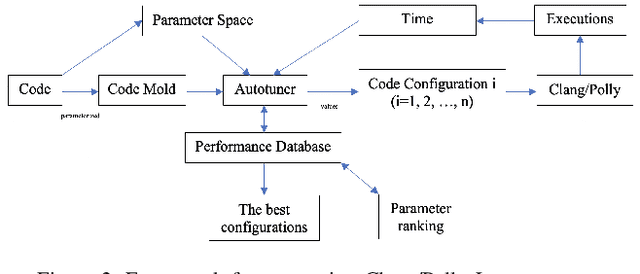

In this paper, we develop a ytopt autotuning framework that leverages Bayesian optimization to explore the parameter space search and compare four different supervised learning methods within Bayesian optimization and evaluate their effectiveness. We select six of the most complex PolyBench benchmarks and apply the newly developed LLVM Clang/Polly loop optimization pragmas to the benchmarks to optimize them. We then use the autotuning framework to optimize the pragma parameters to improve their performance. The experimental results show that our autotuning approach outperforms the other compiling methods to provide the smallest execution time for the benchmarks syr2k, 3mm, heat-3d, lu, and covariance with two large datasets in 200 code evaluations for effectively searching the parameter spaces with up to 170,368 different configurations. We find that the Floyd-Warshall benchmark did not benefit from autotuning because Polly uses heuristics to optimize the benchmark to make it run much slower. To cope with this issue, we provide some compiler option solutions to improve the performance. Then we present loop autotuning without a user's knowledge using a simple mctree autotuning framework to further improve the performance of the Floyd-Warshall benchmark. We also extend the ytopt autotuning framework to tune a deep learning application.
StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer
Apr 12, 2021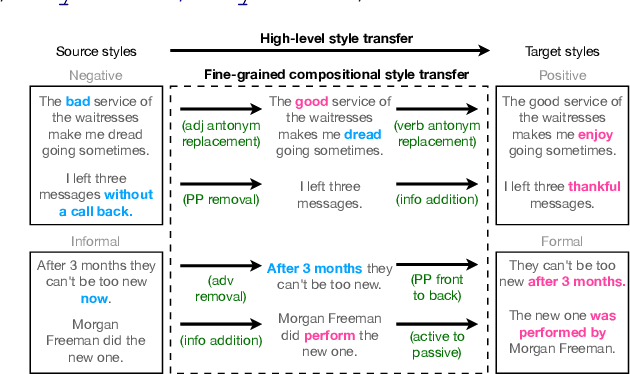
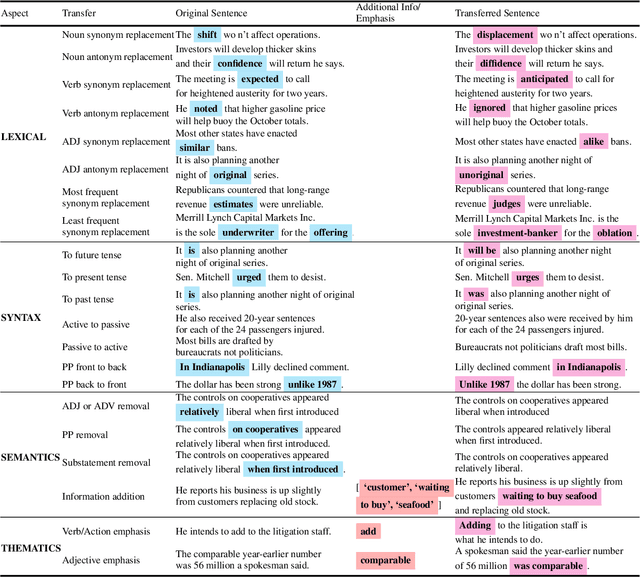
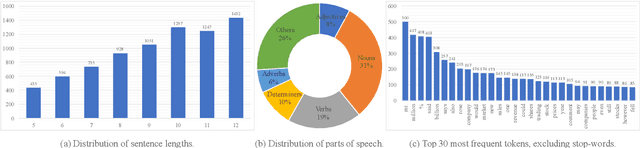
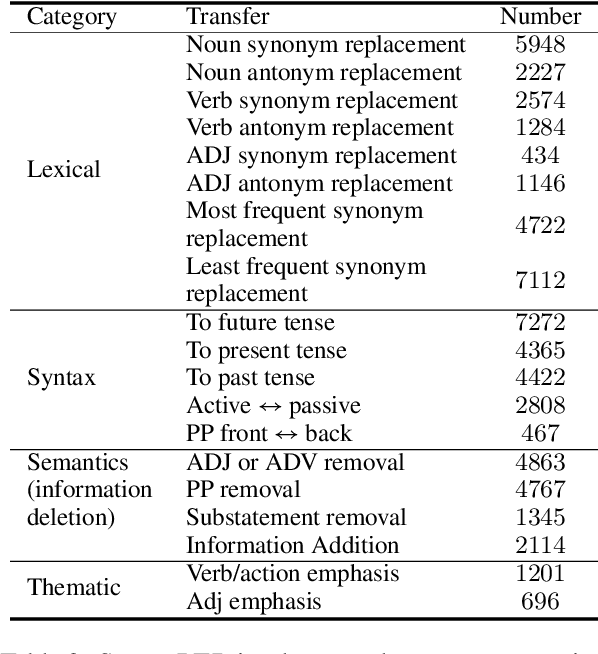
Text style transfer aims to controllably generate text with targeted stylistic changes while maintaining core meaning from the source sentence constant. Many of the existing style transfer benchmarks primarily focus on individual high-level semantic changes (e.g. positive to negative), which enable controllability at a high level but do not offer fine-grained control involving sentence structure, emphasis, and content of the sentence. In this paper, we introduce a large-scale benchmark, StylePTB, with (1) paired sentences undergoing 21 fine-grained stylistic changes spanning atomic lexical, syntactic, semantic, and thematic transfers of text, as well as (2) compositions of multiple transfers which allow modeling of fine-grained stylistic changes as building blocks for more complex, high-level transfers. By benchmarking existing methods on StylePTB, we find that they struggle to model fine-grained changes and have an even more difficult time composing multiple styles. As a result, StylePTB brings novel challenges that we hope will encourage future research in controllable text style transfer, compositional models, and learning disentangled representations. Solving these challenges would present important steps towards controllable text generation.
Supervisory Control of Quantum Discrete Event Systems
Apr 20, 2021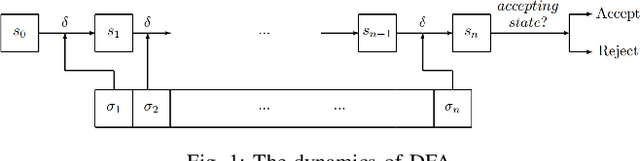
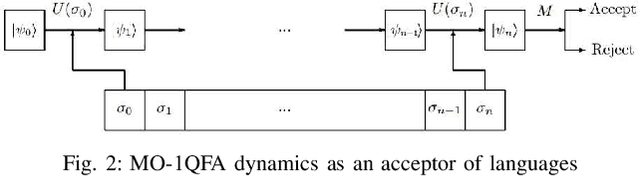
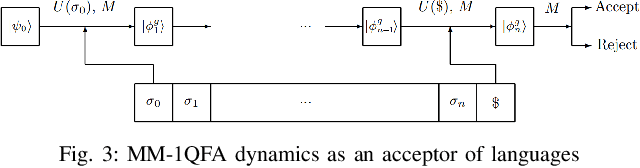
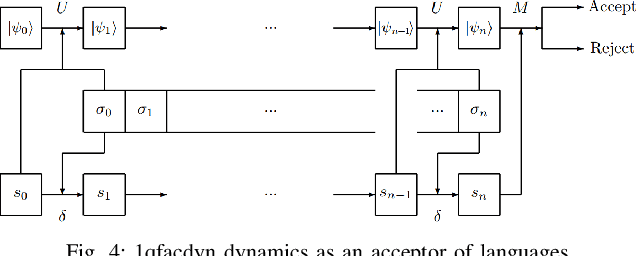
Discrete event systems (DES) have been established and deeply developed in the framework of probabilistic and fuzzy computing models due to the necessity of practical applications in fuzzy and probabilistic systems. With the development of quantum computing and quantum control, a natural problem is to simulate DES by means of quantum computing models and to establish {\it quantum DES} (QDES). The motivation is twofold: on the one hand, QDES have potential applications when DES are simulated and processed by quantum computers, where quantum systems are employed to simulate the evolution of states driven by discrete events, and on the other hand, QDES may have essential advantages over DES concerning state complexity for imitating some practical problems. The goal of this paper is to establish a basic framework of QDES by using {\it quantum finite automata} (QFA) as the modelling formalisms, and the supervisory control theorems of QDES are established and proved. Then we present a polynomial-time algorithm to decide whether or not the controllability condition holds. In particular, we construct a number of new examples of QFA to illustrate the supervisory control of QDES and to verify the essential advantages of QDES over DES in state complexity.
An Empirical Review of Deep Learning Frameworks for Change Detection: Model Design, Experimental Frameworks, Challenges and Research Needs
May 04, 2021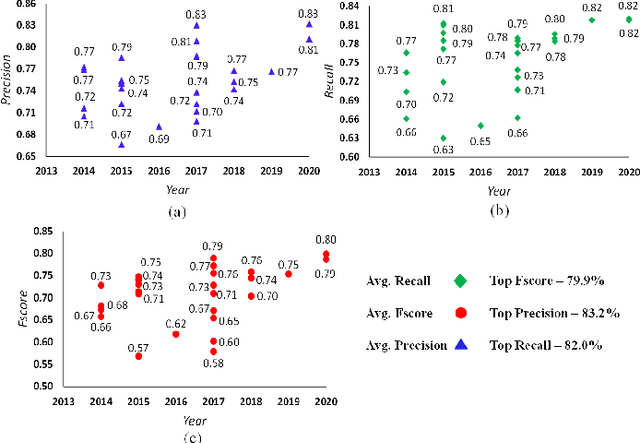
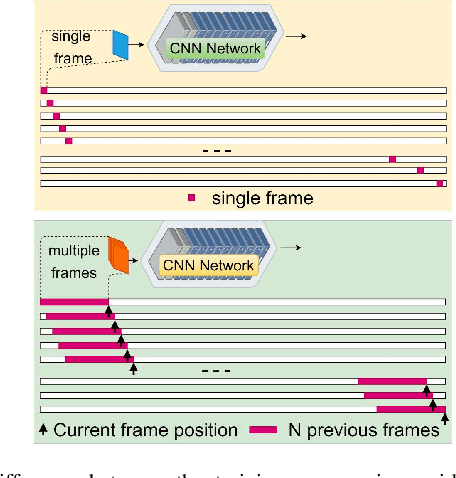
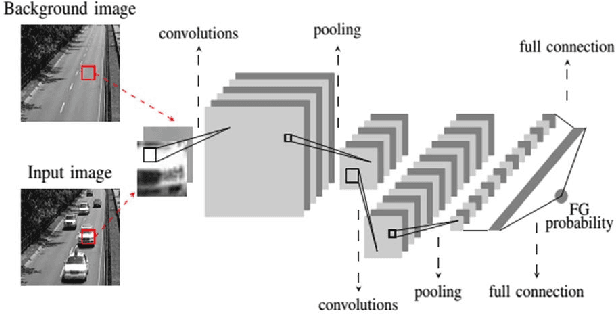
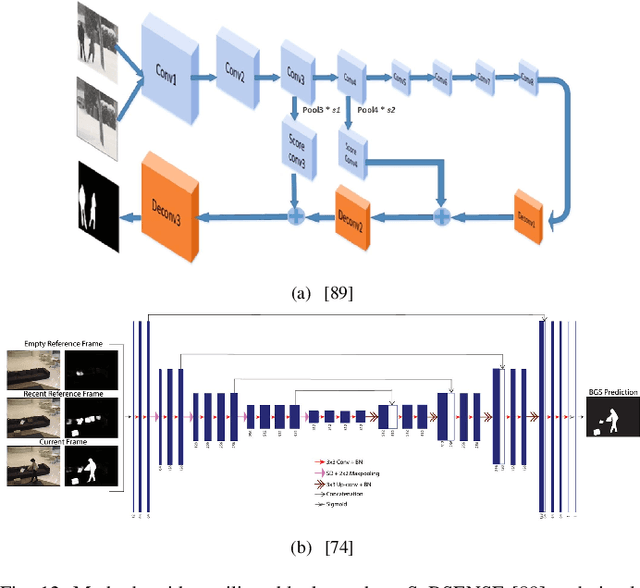
Visual change detection, aiming at segmentation of video frames into foreground and background regions, is one of the elementary tasks in computer vision and video analytics. The applications of change detection include anomaly detection, object tracking, traffic monitoring, human machine interaction, behavior analysis, action recognition, and visual surveillance. Some of the challenges in change detection include background fluctuations, illumination variation, weather changes, intermittent object motion, shadow, fast/slow object motion, camera motion, heterogeneous object shapes and real-time processing. Traditionally, this problem has been solved using hand-crafted features and background modelling techniques. In recent years, deep learning frameworks have been successfully adopted for robust change detection. This article aims to provide an empirical review of the state-of-the-art deep learning methods for change detection. More specifically, we present a detailed analysis of the technical characteristics of different model designs and experimental frameworks. We provide model design based categorization of the existing approaches, including the 2D-CNN, 3D-CNN, ConvLSTM, multi-scale features, residual connections, autoencoders and GAN based methods. Moreover, an empirical analysis of the evaluation settings adopted by the existing deep learning methods is presented. To the best of our knowledge, this is a first attempt to comparatively analyze the different evaluation frameworks used in the existing deep change detection methods. Finally, we point out the research needs, future directions and draw our own conclusions.
TimeNet: Pre-trained deep recurrent neural network for time series classification
Jun 23, 2017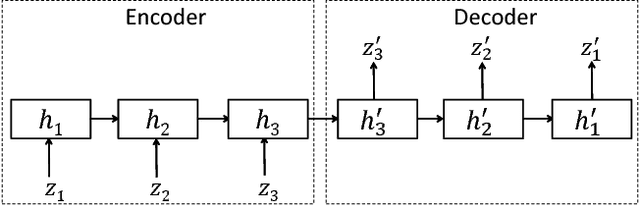
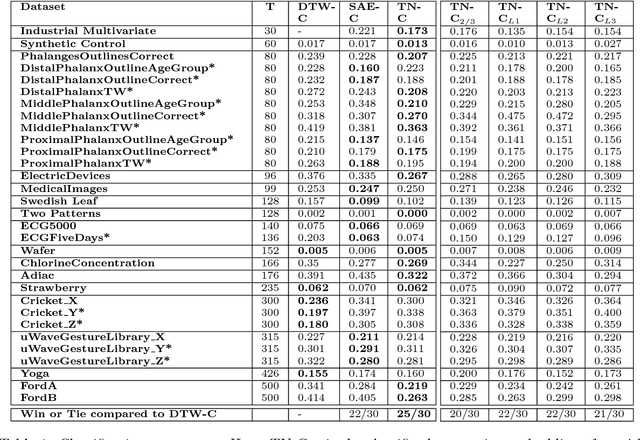

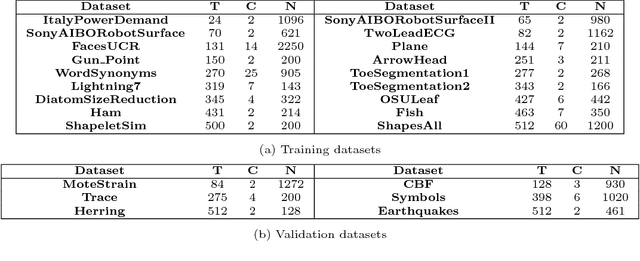
Inspired by the tremendous success of deep Convolutional Neural Networks as generic feature extractors for images, we propose TimeNet: a deep recurrent neural network (RNN) trained on diverse time series in an unsupervised manner using sequence to sequence (seq2seq) models to extract features from time series. Rather than relying on data from the problem domain, TimeNet attempts to generalize time series representation across domains by ingesting time series from several domains simultaneously. Once trained, TimeNet can be used as a generic off-the-shelf feature extractor for time series. The representations or embeddings given by a pre-trained TimeNet are found to be useful for time series classification (TSC). For several publicly available datasets from UCR TSC Archive and an industrial telematics sensor data from vehicles, we observe that a classifier learned over the TimeNet embeddings yields significantly better performance compared to (i) a classifier learned over the embeddings given by a domain-specific RNN, as well as (ii) a nearest neighbor classifier based on Dynamic Time Warping.
Real-time Egocentric Gesture Recognition on Mobile Head Mounted Displays
Dec 13, 2017
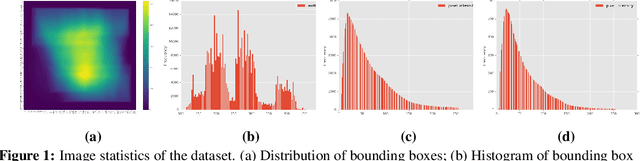
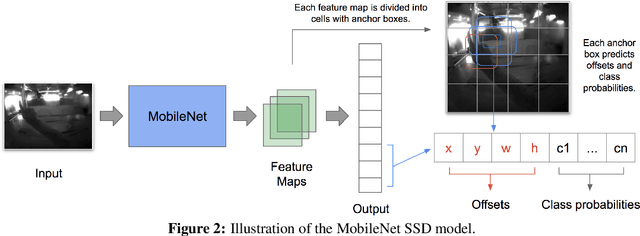
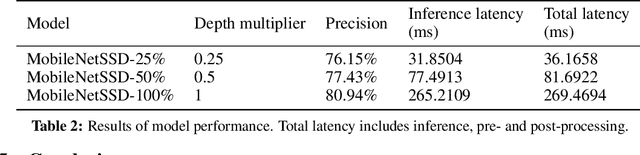
Mobile virtual reality (VR) head mounted displays (HMD) have become popular among consumers in recent years. In this work, we demonstrate real-time egocentric hand gesture detection and localization on mobile HMDs. Our main contributions are: 1) A novel mixed-reality data collection tool to automatic annotate bounding boxes and gesture labels; 2) The largest-to-date egocentric hand gesture and bounding box dataset with more than 400,000 annotated frames; 3) A neural network that runs real time on modern mobile CPUs, and achieves higher than 76% precision on gesture recognition across 8 classes.
Artificial Neural Network classification of asteroids in the M1:2 mean-motion resonance with Mars
Mar 29, 2021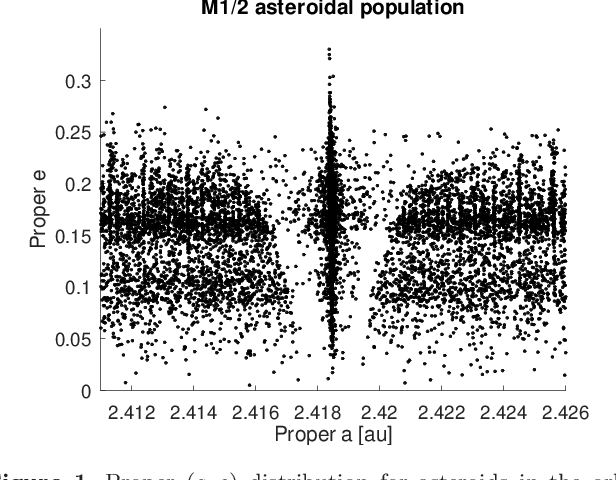

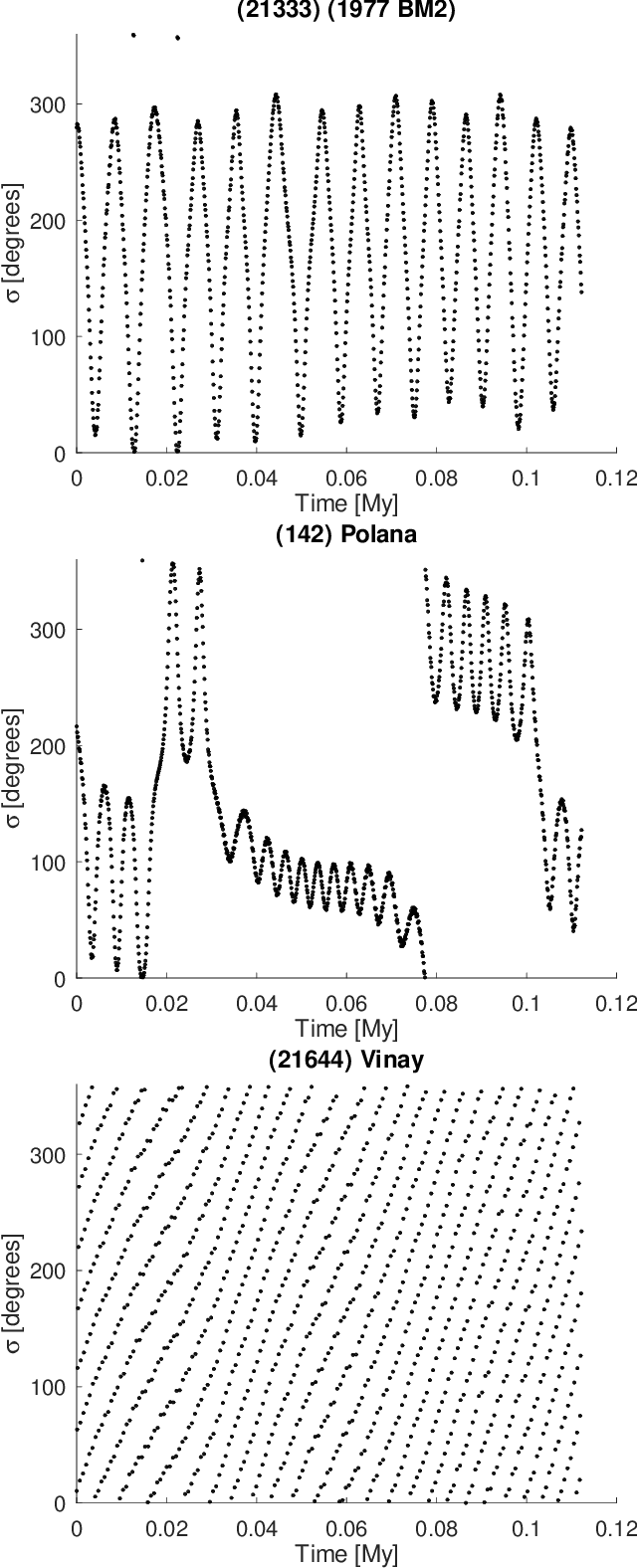
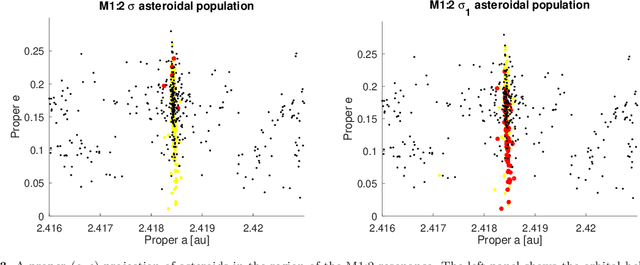
Artificial neural networks (ANN) have been successfully used in the last years to identify patterns in astronomical images. The use of ANN in the field of asteroid dynamics has been, however, so far somewhat limited. In this work we used for the first time ANN for the purpose of automatically identifying the behaviour of asteroid orbits affected by the M1:2 mean-motion resonance with Mars. Our model was able to perform well above 85% levels for identifying images of asteroid resonant arguments in term of standard metrics like accuracy, precision and recall, allowing to identify the orbital type of all numbered asteroids in the region. Using supervised machine learning methods, optimized through the use of genetic algorithms, we also predicted the orbital status of all multi-opposition asteroids in the area. We confirm that the M1:2 resonance mainly affects the orbits of the Massalia, Nysa, and Vesta asteroid families.