 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020
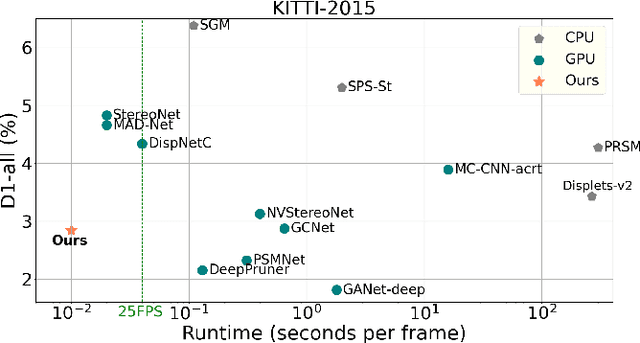

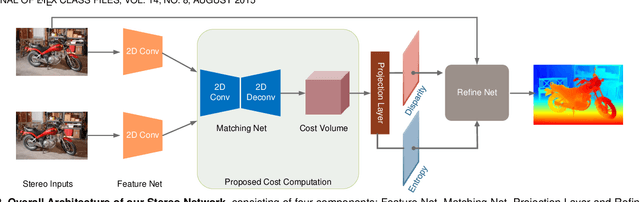
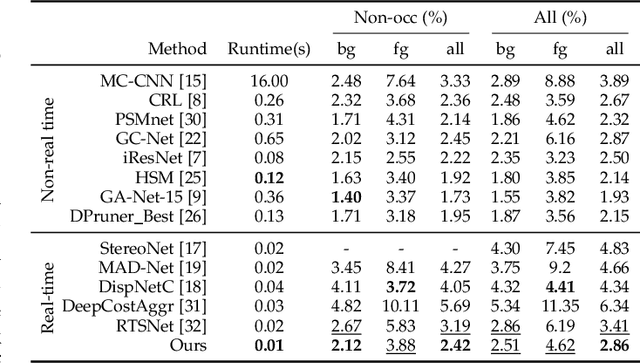
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Counterfactual Inference of the Mean Outcome under a Convergence of Average Logging Probability
Feb 17, 2021
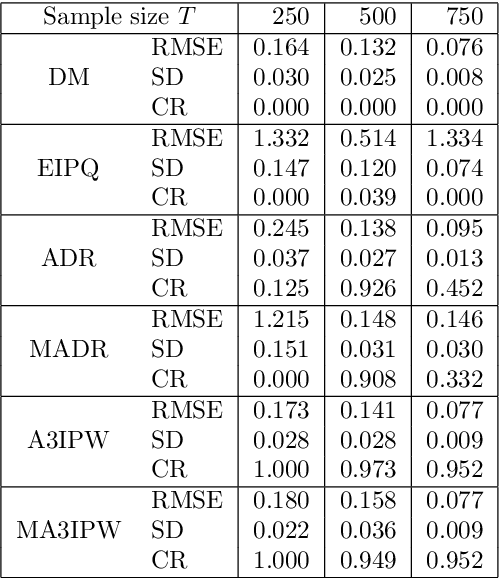
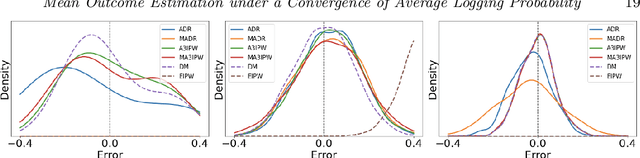
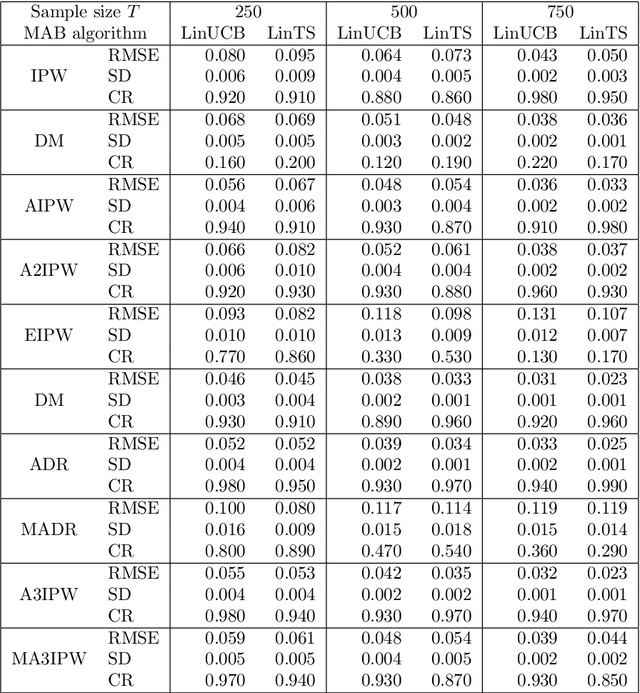
Adaptive experiments, including efficient average treatment effect estimation and multi-armed bandit algorithms, have garnered attention in various applications, such as social experiments, clinical trials, and online advertisement optimization. This paper considers estimating the mean outcome of an action from samples obtained in adaptive experiments. In causal inference, the mean outcome of an action has a crucial role, and the estimation is an essential task, where the average treatment effect estimation and off-policy value estimation are its variants. In adaptive experiments, the probability of choosing an action (logging probability) is allowed to be sequentially updated based on past observations. Due to this logging probability depending on the past observations, the samples are often not independent and identically distributed (i.i.d.), making developing an asymptotically normal estimator difficult. A typical approach for this problem is to assume that the logging probability converges in a time-invariant function. However, this assumption is restrictive in various applications, such as when the logging probability fluctuates or becomes zero at some periods. To mitigate this limitation, we propose another assumption that the average logging probability converges to a time-invariant function and show the doubly robust (DR) estimator's asymptotic normality. Under the assumption, the logging probability itself can fluctuate or be zero for some actions. We also show the empirical properties by simulations.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021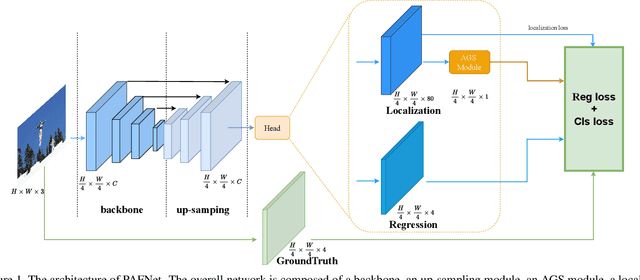
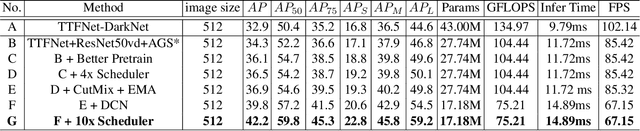
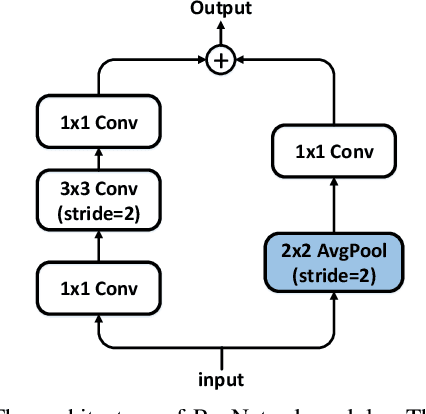

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Sparse Curriculum Reinforcement Learning for End-to-End Driving
Mar 16, 2021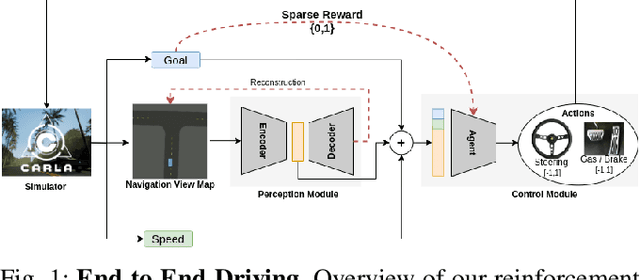
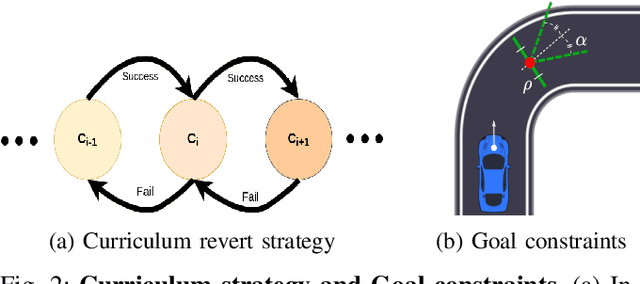
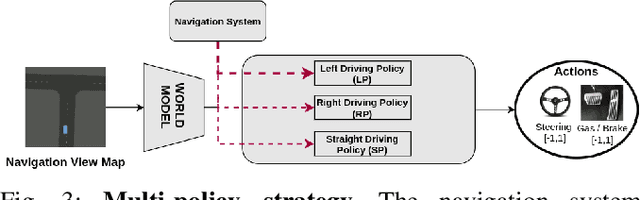
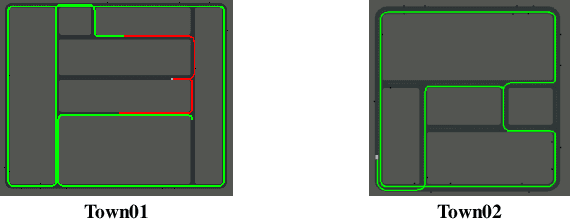
Deep reinforcement Learning for end-to-end driving is limited by the need of complex reward engineering. Sparse rewards can circumvent this challenge but suffers from long training time and leads to sub-optimal policy. In this work, we explore driving using only goal conditioned sparse rewards and propose a curriculum learning approach for end to end driving using only navigation view maps that benefit from small virtual-to-real domain gap. To address the complexity of multiple driving policies, we learn concurrent individual policies which are selected at inference by a navigation system. We demonstrate the ability of our proposal to generalize on unseen road layout, and to drive longer than in the training.
Satisficing in Time-Sensitive Bandit Learning
Mar 07, 2018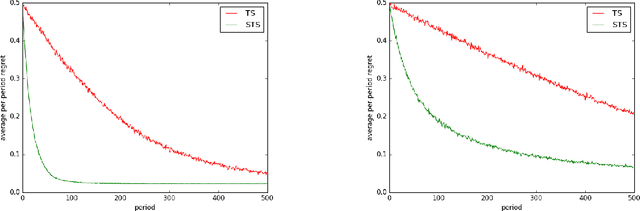
Much of the recent literature on bandit learning focuses on algorithms that aim to converge on an optimal action. One shortcoming is that this orientation does not account for time sensitivity, which can play a crucial role when learning an optimal action requires much more information than near-optimal ones. Indeed, popular approaches such as upper-confidence-bound methods and Thompson sampling can fare poorly in such situations. We consider instead learning a satisficing action, which is near-optimal while requiring less information, and propose satisficing Thompson sampling, an algorithm that serves this purpose. We establish a general bound on expected discounted regret and study the application of satisficing Thompson sampling to linear and infinite-armed bandits, demonstrating arbitrarily large benefits over Thompson sampling. We also discuss the relation between the notion of satisficing and the theory of rate distortion, which offers guidance on the selection of satisficing actions.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 24, 2021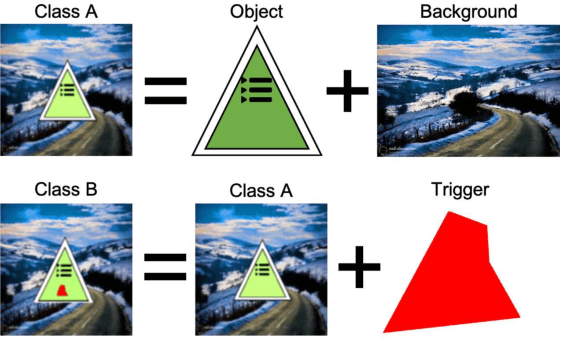

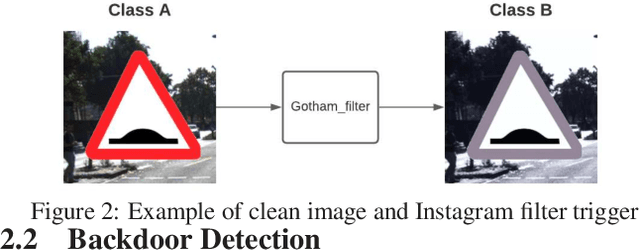
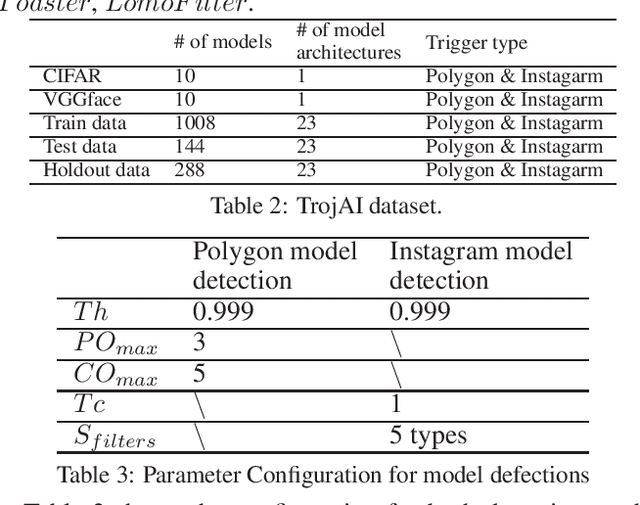
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.
Activity Recognition on a Large Scale in Short Videos - Moments in Time Dataset
Sep 13, 2018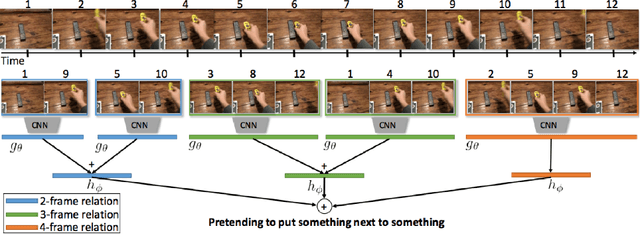
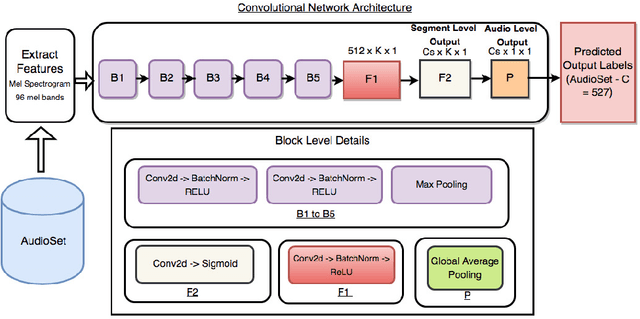
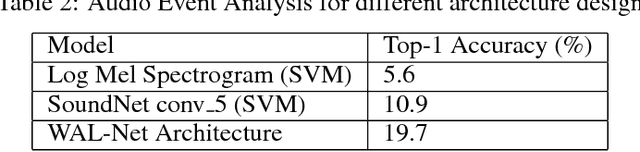
Moments capture a huge part of our lives. Accurate recognition of these moments is challenging due to the diverse and complex interpretation of the moments. Action recognition refers to the act of classifying the desired action/activity present in a given video. In this work, we perform experiments on Moments in Time dataset to recognize accurately activities occurring in 3 second clips. We use state of the art techniques for visual, auditory and spatio temporal localization and develop method to accurately classify the activity in the Moments in Time dataset. Our novel approach of using Visual Based Textual features and fusion techniques performs well providing an overall 89.23 % Top - 5 accuracy on the 20 classes - a significant improvement over the Baseline TRN model.
Holographic Transmitarray Antenna with linear Polarization in X band
Apr 19, 2021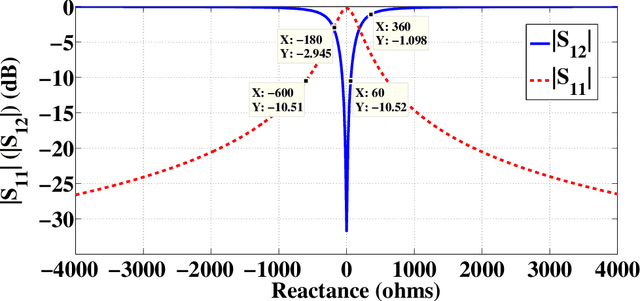

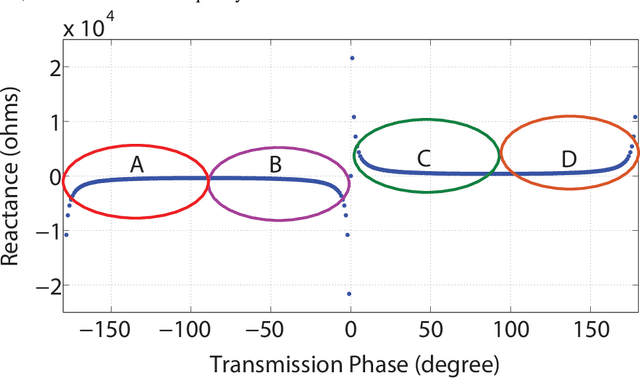
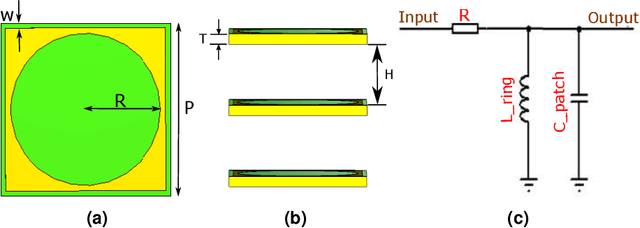
In this paper, we present the design and demonstration of transmitarray antennas (TAs) based on the holographic technique for the first time. According to the holographic theory, the amplitudes and phases of electromagnetic waves can be recorded on a surface, and then they can be reconstructed independently. This concept is used to design single-beam and multi-beam linearly polarized holographic TAs without using any iterative optimization algorithms. Initially, a transmission impedance surface is analyzed and compared with the reflection one. Then, interferograms associated with the scalar admittance distribution are defined according to the number and direction of the radiation beams. After that, a transmission metasurface of dimensions equal to 0:26l0 is hired to design holographic TAs at 12 GHz. Several examples are provided to support the method. In the end, a linearly polarized circular aperture wideband holographic transmitarray antenna with a radius of 13.3 cm has been manufactured and tested. The antenna achieves 12.5% (11.4-12.9 GHz) 1-dB gain bandwidth and 23.8 dB maximum gain, leading to 21.46% aperture efficiency.
Fundamental Performance Limits on Terahertz Wireless Links Imposed by Group Velocity Dispersion
Apr 01, 2021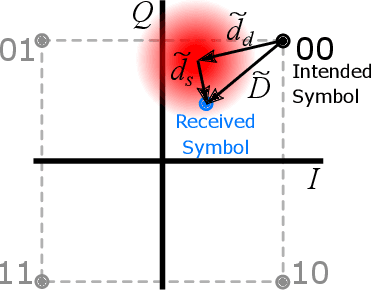
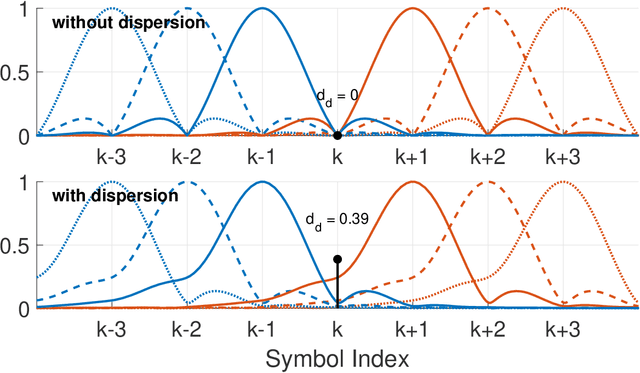
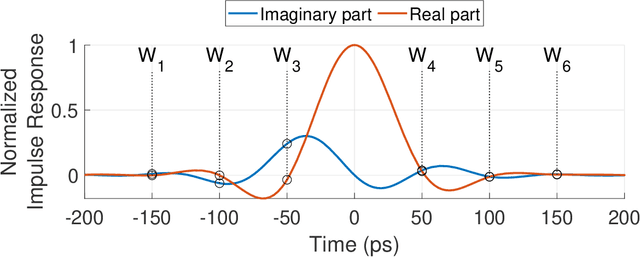
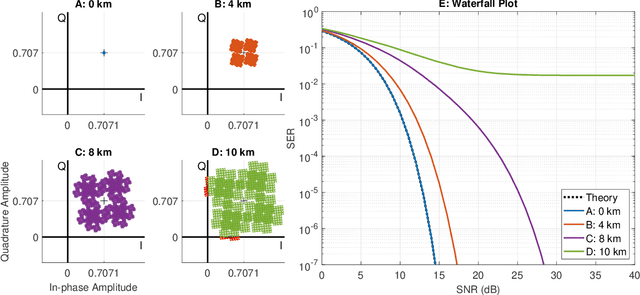
A theoretical framework and numerical simulations quantifying the impact of atmospheric group velocity dispersion on wireless terahertz communication link error rate were developed based upon experimental work. We present, for the first time, predictions of symbol error rate as a function of link distance, signal bandwidth, signal-to-noise ratio, and atmospheric conditions, revealing that long-distance, broadband terahertz communication systems may be limited by inter-symbol interference stemming from group velocity dispersion, rather than attenuation. In such dispersion limited links, increasing signal strength does not improve the symbol error rate and, consequently, theoretical predictions of symbol error rate based only on signal-to-noise ratio are invalid for the broadband case. This work establishes a new and necessary foundation for link budget analysis in future long-distance terahertz communication systems that accounts for the non-negligible effects of both attenuation and dispersion.
Replay in Deep Learning: Current Approaches and Missing Biological Elements
Apr 01, 2021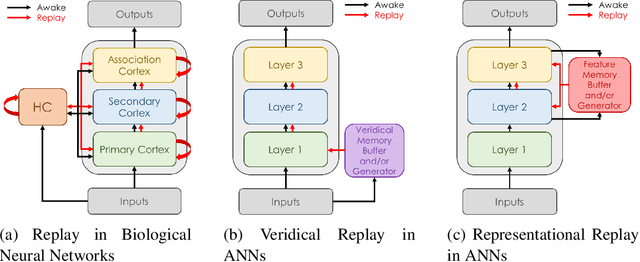
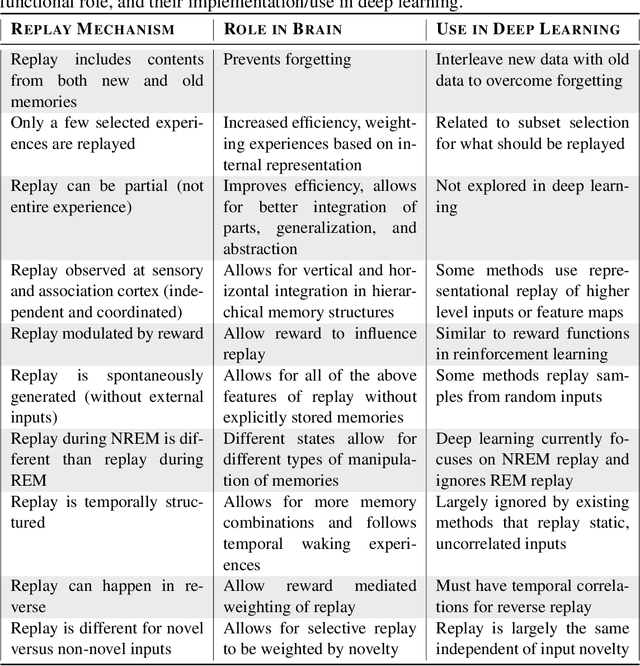
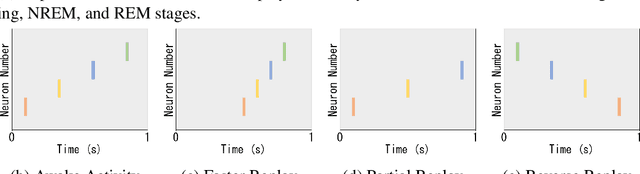
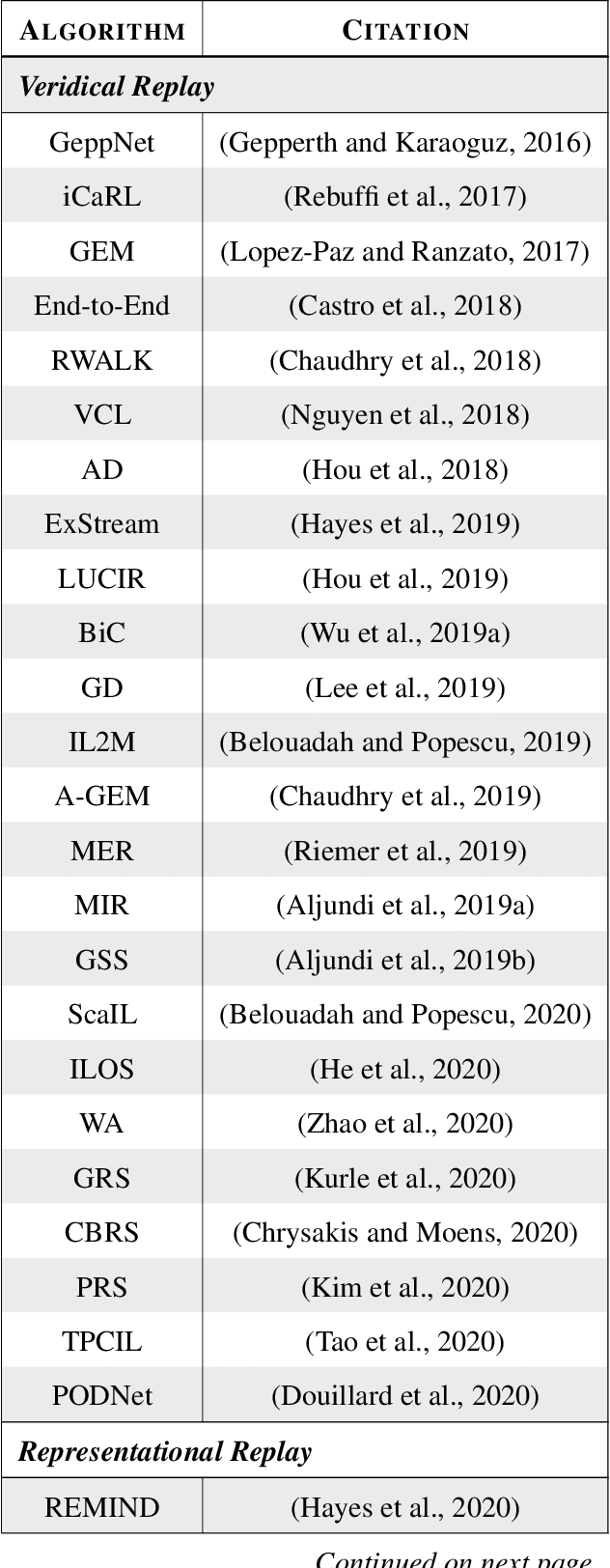
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.