 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Green Tethered UAVs for EMF-Aware Cellular Networks
Jun 03, 2021
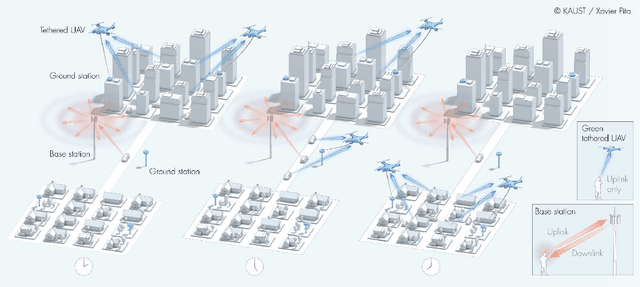
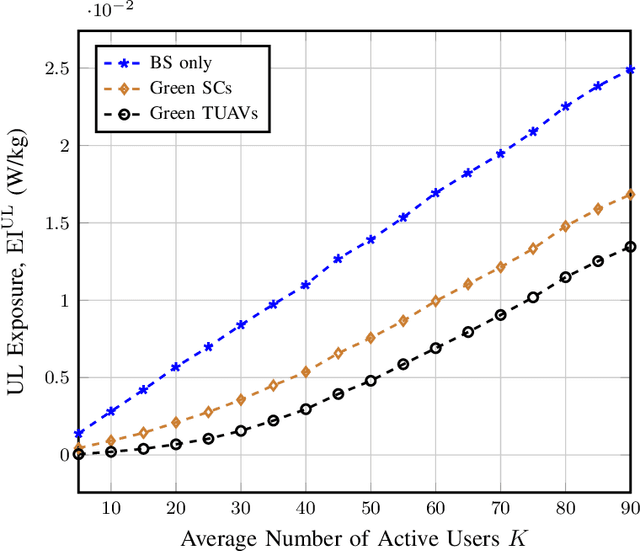
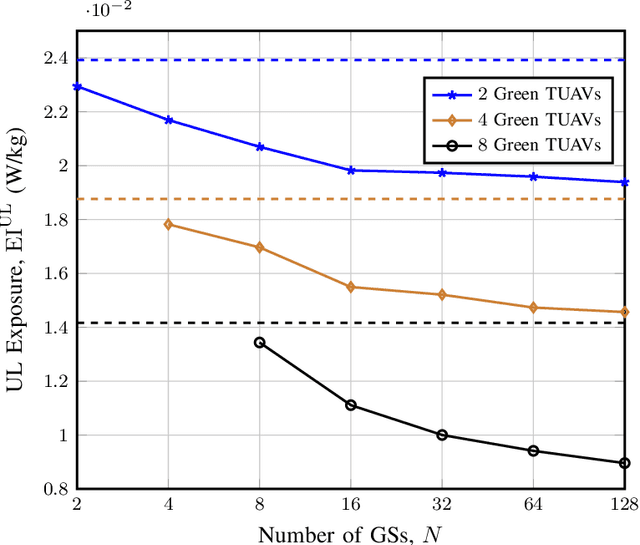
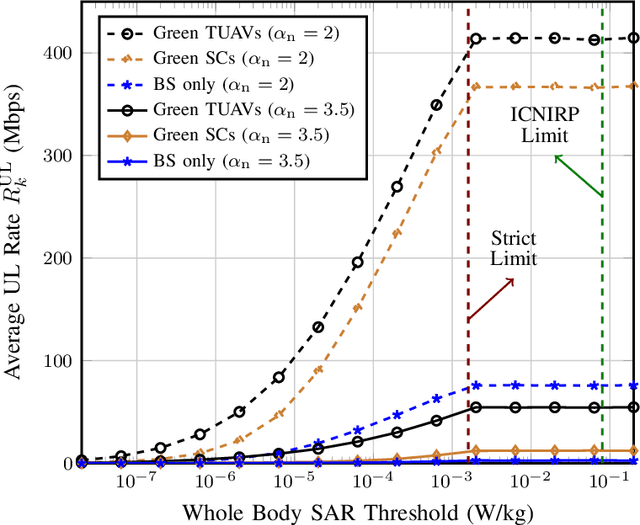
A prevalent theory circulating among the non-scientific community is that the intensive deployment of base stations over the territory significantly increases the level of electromagnetic field (EMF) exposure and affects population health. To alleviate this concern, in this work, we propose a network architecture that introduces tethered unmanned aerial vehicles (TUAVs) carrying green antennas to minimize the EMF exposure while guaranteeing a high data rate for users. In particular, each TUAV can attach itself to one of the possible ground stations at the top of some buildings. The location of the TUAVs, transmit power of user equipment and association policy are optimized to minimize the EMF exposure. Unfortunately, the problem turns out to be mixed-integer non-linear programming (MINLP), which is non-deterministic polynomial-time (NP) hard. We propose an efficient low-complexity algorithm composed of three submodules. Firstly, we propose an algorithm based on the greedy principle to determine the optimal association matrix between the users and base stations. Then, we offer two approaches, a modified K-mean and shrink and realign (SR) process, to associate each TUAV with a ground station. Finally, we put forward two algorithms based on the golden search and SR process to adjust the TUAV's position within the hovering area over the building. After that, we consider the dual problem that maximizes the sum rate while keeping the exposure below a predefined value, such as the level enforced by the regulation. Next, we perform extensive simulations to show the effectiveness of the proposed TUAVs to reduce the exposure compared to various architectures. Eventually, we show that TUAVs with green antennas can effectively mitigate the EMF exposure by more than 20% compared to fixed green small cells while achieving a higher data rate.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021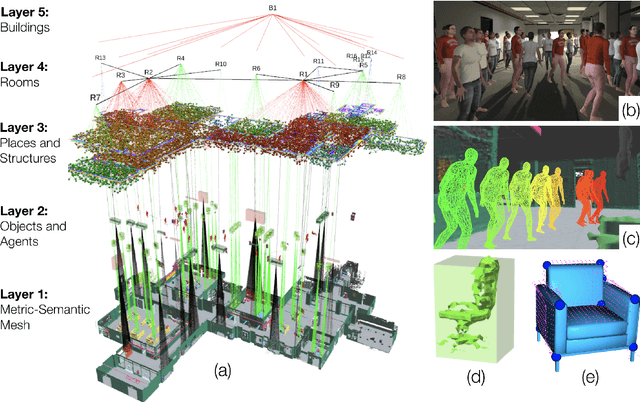
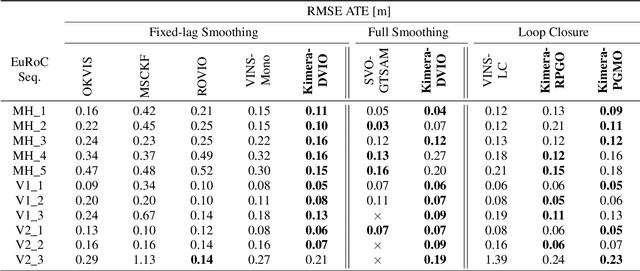
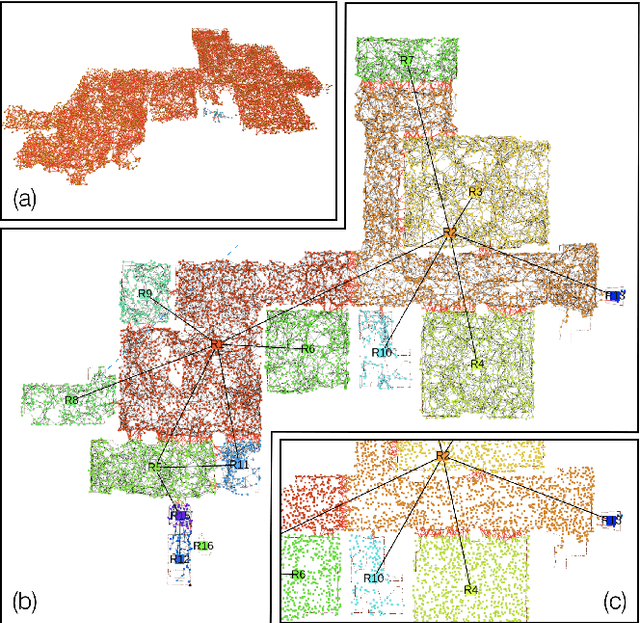
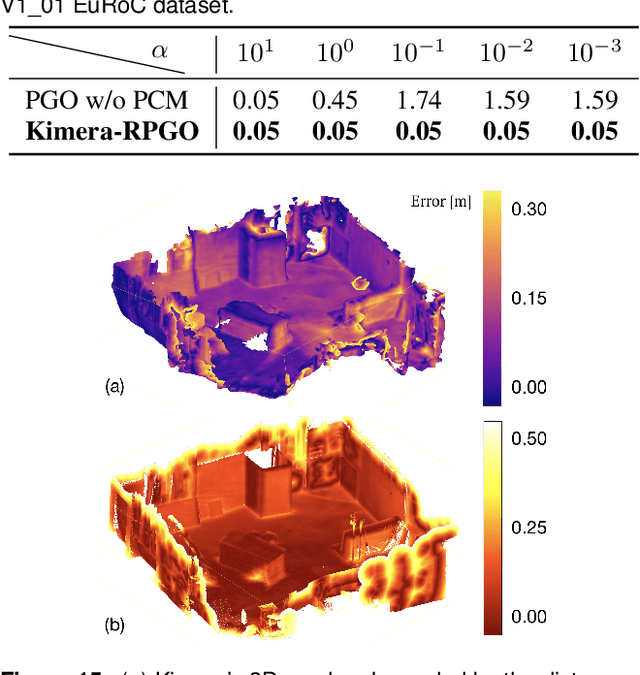
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.
Predicting Medical Interventions from Vital Parameters: Towards a Decision Support System for Remote Patient Monitoring
Apr 20, 2021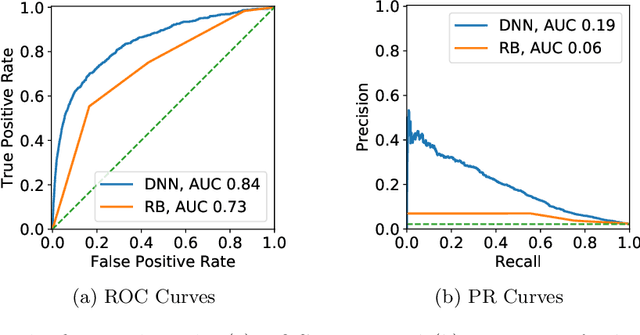
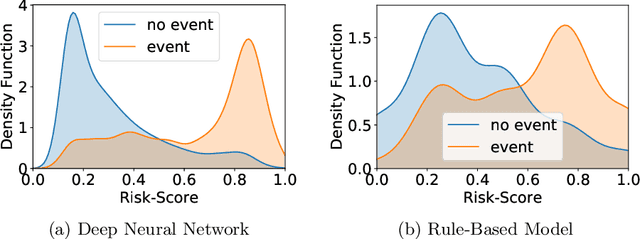
Cardiovascular diseases and heart failures in particular are the main cause of non-communicable disease mortality in the world. Constant patient monitoring enables better medical treatment as it allows practitioners to react on time and provide the appropriate treatment. Telemedicine can provide constant remote monitoring so patients can stay in their homes, only requiring medical sensing equipment and network connections. A limiting factor for telemedical centers is the amount of patients that can be monitored simultaneously. We aim to increase this amount by implementing a decision support system. This paper investigates a machine learning model to estimate a risk score based on patient vital parameters that allows sorting all cases every day to help practitioners focus their limited capacities on the most severe cases. The model we propose reaches an AUCROC of 0.84, whereas the baseline rule-based model reaches an AUCROC of 0.73. Our results indicate that the usage of deep learning to improve the efficiency of telemedical centers is feasible. This way more patients could benefit from better health-care through remote monitoring.
Non-asymptotic analysis and inference for an outlyingness induced winsorized mean
May 05, 2021
Robust estimation of a mean vector, a topic regarded as obsolete in the traditional robust statistics community, has recently surged in machine learning literature in the last decade. The latest focus is on the sub-Gaussian performance and computability of the estimators in a non-asymptotic setting. Numerous traditional robust estimators are computationally intractable, which partly contributes to the renewal of the interest in the robust mean estimation. Robust centrality estimators, however, include the trimmed mean and the sample median. The latter has the best robustness but suffers a low-efficiency drawback. Trimmed mean and median of means, %as robust alternatives to the sample mean, and achieving sub-Gaussian performance have been proposed and studied in the literature. This article investigates the robustness of leading sub-Gaussian estimators of mean and reveals that none of them can resist greater than $25\%$ contamination in data and consequently introduces an outlyingness induced winsorized mean which has the best possible robustness (can resist up to $50\%$ contamination without breakdown) meanwhile achieving high efficiency. Furthermore, it has a sub-Gaussian performance for uncontaminated samples and a bounded estimation error for contaminated samples at a given confidence level in a finite sample setting. It can be computed in linear time.
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021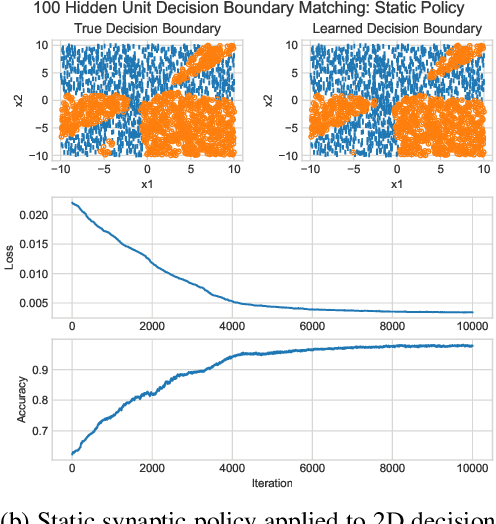
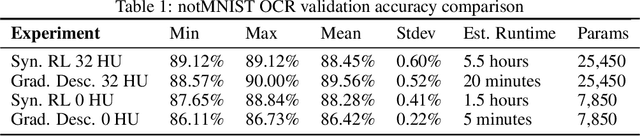
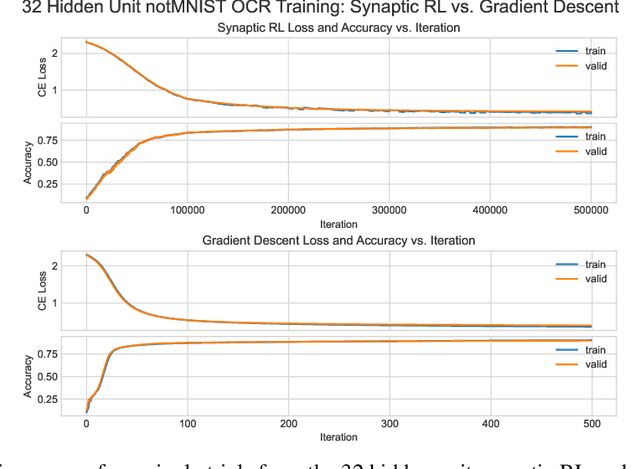
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.
Satisficing in Time-Sensitive Bandit Learning
Mar 07, 2018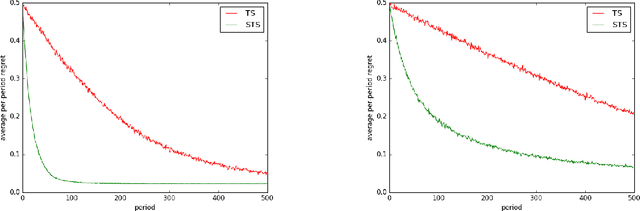
Much of the recent literature on bandit learning focuses on algorithms that aim to converge on an optimal action. One shortcoming is that this orientation does not account for time sensitivity, which can play a crucial role when learning an optimal action requires much more information than near-optimal ones. Indeed, popular approaches such as upper-confidence-bound methods and Thompson sampling can fare poorly in such situations. We consider instead learning a satisficing action, which is near-optimal while requiring less information, and propose satisficing Thompson sampling, an algorithm that serves this purpose. We establish a general bound on expected discounted regret and study the application of satisficing Thompson sampling to linear and infinite-armed bandits, demonstrating arbitrarily large benefits over Thompson sampling. We also discuss the relation between the notion of satisficing and the theory of rate distortion, which offers guidance on the selection of satisficing actions.
Surrogate assisted active subspace and active subspace assisted surrogate -- A new paradigm for high dimensional structural reliability analysis
May 12, 2021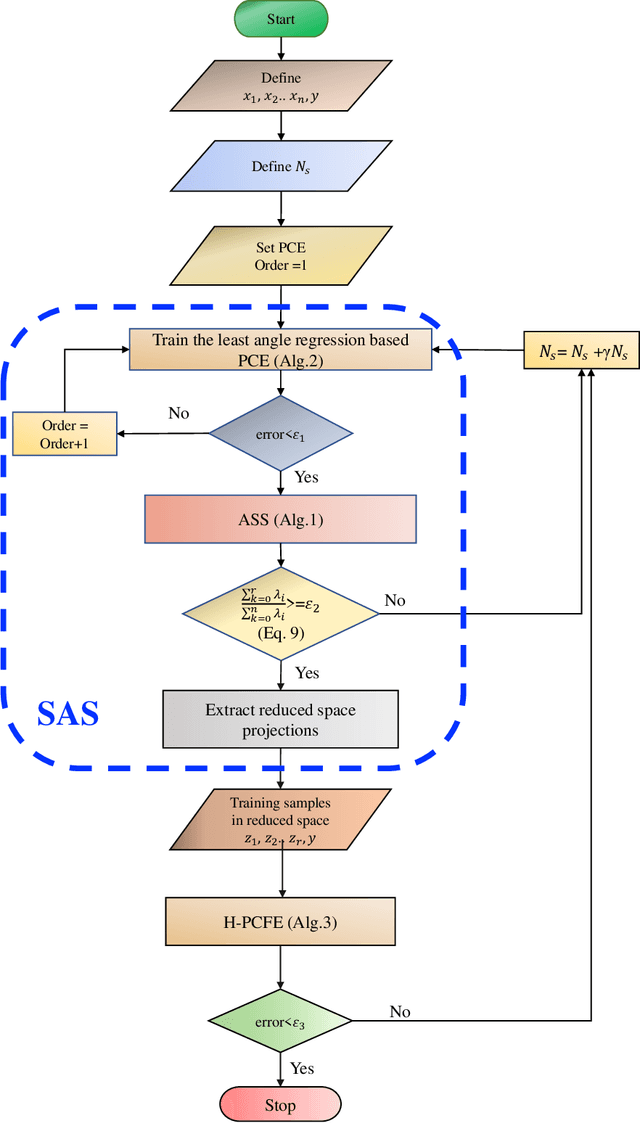
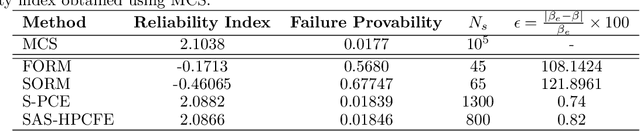
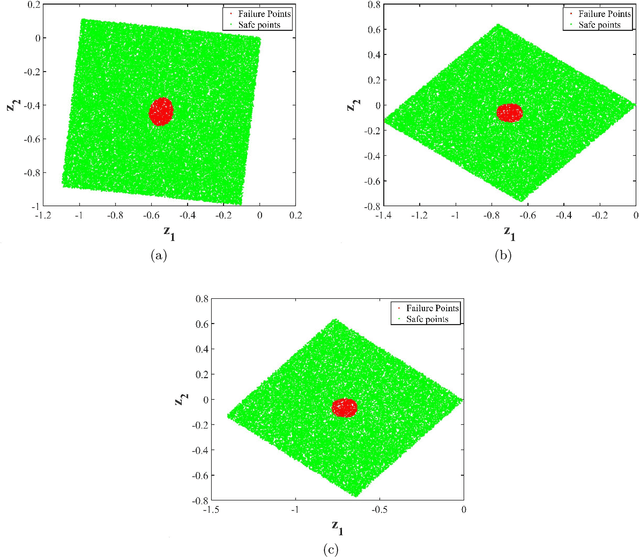
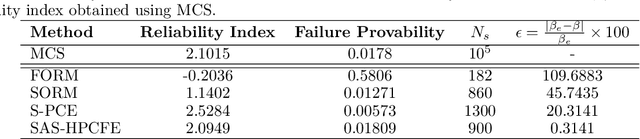
Performing reliability analysis on complex systems is often computationally expensive. In particular, when dealing with systems having high input dimensionality, reliability estimation becomes a daunting task. A popular approach to overcome the problem associated with time-consuming and expensive evaluations is building a surrogate model. However, these computationally efficient models often suffer from the curse of dimensionality. Hence, training a surrogate model for high-dimensional problems is not straightforward. Henceforth, this paper presents a framework for solving high-dimensional reliability analysis problems. The basic premise is to train the surrogate model on a low-dimensional manifold, discovered using the active subspace algorithm. However, learning the low-dimensional manifold using active subspace is non-trivial as it requires information on the gradient of the response variable. To address this issue, we propose using sparse learning algorithms in conjunction with the active subspace algorithm; the resulting algorithm is referred to as the sparse active subspace (SAS) algorithm. We project the high-dimensional inputs onto the identified low-dimensional manifold identified using SAS. A high-fidelity surrogate model is used to map the inputs on the low-dimensional manifolds to the output response. We illustrate the efficacy of the proposed framework by using three benchmark reliability analysis problems from the literature. The results obtained indicate the accuracy and efficiency of the proposed approach compared to already established reliability analysis methods in the literature.
Online detection of failures generated by storage simulator
Jan 18, 2021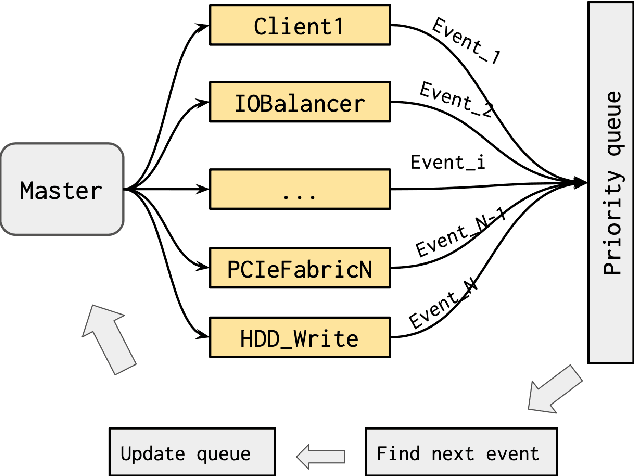

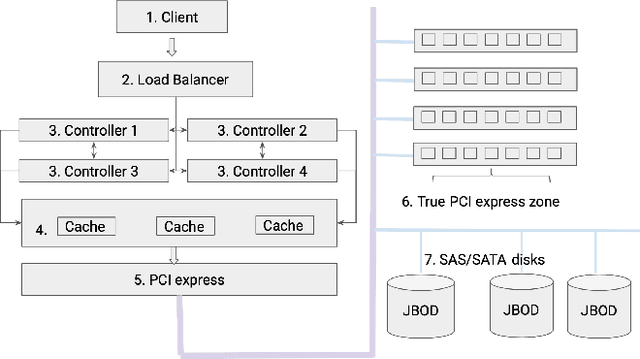
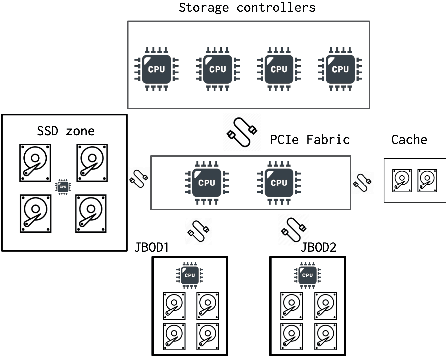
Modern large-scale data-farms consist of hundreds of thousands of storage devices that span distributed infrastructure. Devices used in modern data centers (such as controllers, links, SSD- and HDD-disks) can fail due to hardware as well as software problems. Such failures or anomalies can be detected by monitoring the activity of components using machine learning techniques. In order to use these techniques, researchers need plenty of historical data of devices in normal and failure mode for training algorithms. In this work, we challenge two problems: 1) lack of storage data in the methods above by creating a simulator and 2) applying existing online algorithms that can faster detect a failure occurred in one of the components. We created a Go-based (golang) package for simulating the behavior of modern storage infrastructure. The software is based on the discrete-event modeling paradigm and captures the structure and dynamics of high-level storage system building blocks. The package's flexible structure allows us to create a model of a real-world storage system with a configurable number of components. The primary area of interest is exploring the storage machine's behavior under stress testing or exploitation in the medium- or long-term for observing failures of its components. To discover failures in the time series distribution generated by the simulator, we modified a change point detection algorithm that works in online mode. The goal of the change-point detection is to discover differences in time series distribution. This work describes an approach for failure detection in time series data based on direct density ratio estimation via binary classifiers.
Closing the Closed-Loop Distribution Shift in Safe Imitation Learning
Feb 18, 2021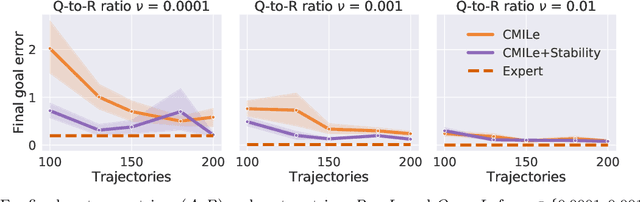
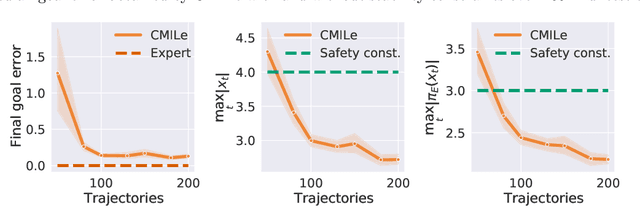
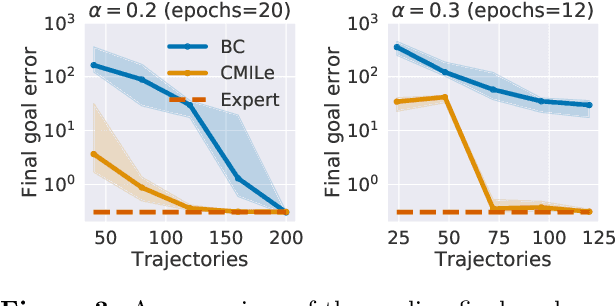
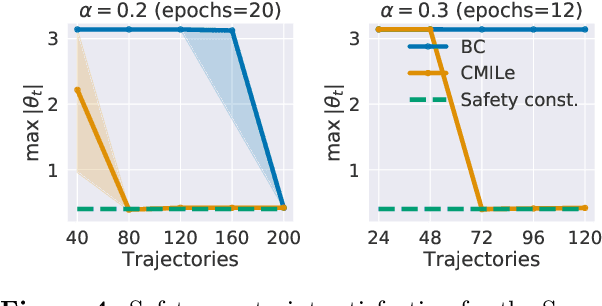
Commonly used optimization-based control strategies such as model-predictive and control Lyapunov/barrier function based controllers often enjoy provable stability, robustness, and safety properties. However, implementing such approaches requires solving optimization problems online at high-frequencies, which may not be possible on resource-constrained commodity hardware. Furthermore, how to extend the safety guarantees of such approaches to systems that use rich perceptual sensing modalities, such as cameras, remains unclear. In this paper, we address this gap by treating safe optimization-based control strategies as experts in an imitation learning problem, and train a learned policy that can be cheaply evaluated at run-time and that provably satisfies the same safety guarantees as the expert. In particular, we propose Constrained Mixing Iterative Learning (CMILe), a novel on-policy robust imitation learning algorithm that integrates ideas from stochastic mixing iterative learning, constrained policy optimization, and nonlinear robust control. Our approach allows us to control errors introduced by both the learning task of imitating an expert and by the distribution shift inherent to deviating from the original expert policy. The value of using tools from nonlinear robust control to impose stability constraints on learned policies is shown through sample-complexity bounds that are independent of the task time-horizon. We demonstrate the usefulness of CMILe through extensive experiments, including training a provably safe perception-based controller using a state-feedback-based expert.
Using Trust in Automation to Enhance Driver-(Semi)Autonomous Vehicle Interaction and Improve Team Performance
Jun 03, 2021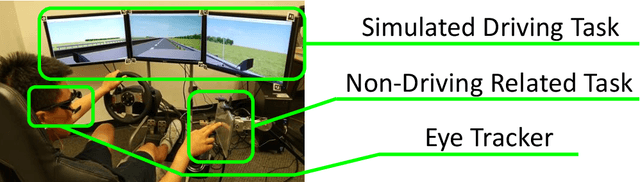
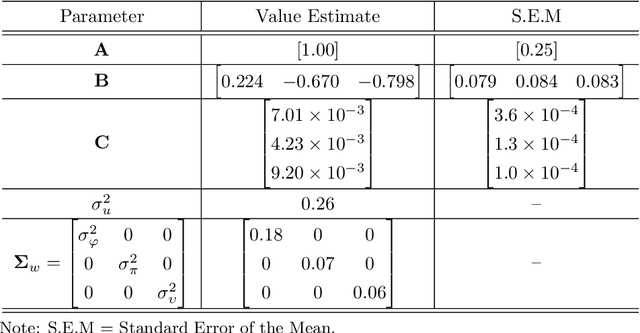
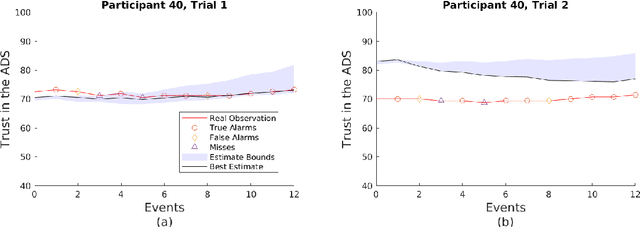
Trust in robots has been gathering attention from multiple directions, as it has special relevance in the theoretical descriptions of human-robot interactions. It is essential for reaching high acceptance and usage rates of robotic technologies in society, as well as for enabling effective human-robot teaming. Researchers have been trying to model the development of trust in robots to improve the overall rapport between humans and robots. Unfortunately, the miscalibration of trust in automation is a common issue that jeopardizes the effectiveness of automation use. It happens when a user's trust levels are not appropriate to the capabilities of the automation being used. Users can be: under-trusting the automation -- when they do not use the functionalities that the machine can perform correctly because of a lack of trust; or over-trusting the automation -- when, due to an excess of trust, they use the machine in situations where its capabilities are not adequate. The main objective of this work is to examine driver's trust development in the ADS. We aim to model how risk factors (e.g.: false alarms and misses from the ADS) and the short-term interactions associated with these risk factors influence the dynamics of drivers' trust in the ADS. The driving context facilitates the instrumentation to measure trusting behaviors, such as drivers' eye movements and usage time of the automated features. Our findings indicate that a reliable characterization of drivers' trusting behaviors and a consequent estimation of trust levels is possible. We expect that these techniques will permit the design of ADSs able to adapt their behaviors to attempt to adjust driver's trust levels. This capability could avoid under- and over-trusting, which could harm their safety or their performance.