 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wireless Sensing With Deep Spectrogram Network and Primitive Based Autoregressive Hybrid Channel Model
Apr 21, 2021
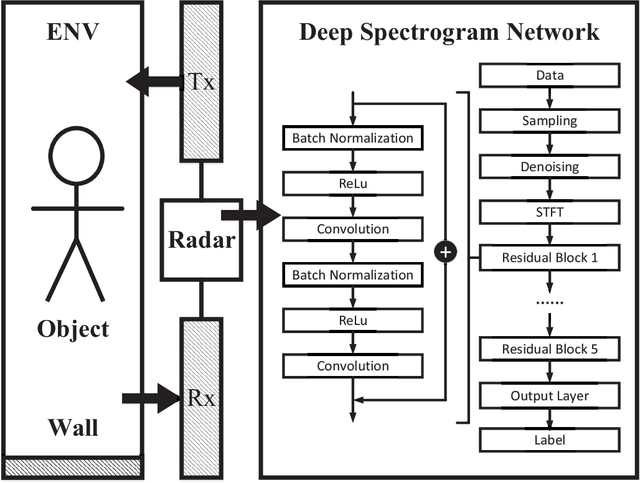

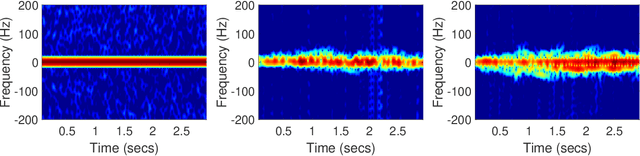
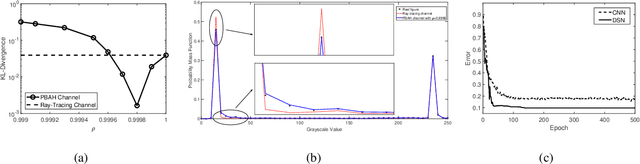
Human motion recognition (HMR) based on wireless sensing is a low-cost technique for scene understanding. Current HMR systems adopt support vector machines (SVMs) and convolutional neural networks (CNNs) to classify radar signals. However, whether a deeper learning model could improve the system performance is currently not known. On the other hand, training a machine learning model requires a large dataset, but data gathering from experiment is cost-expensive and time-consuming. Although wireless channel models can be adopted for dataset generation, current channel models are mostly designed for communication rather than sensing. To address the above problems, this paper proposes a deep spectrogram network (DSN) by leveraging the residual mapping technique to enhance the HMR performance. Furthermore, a primitive based autoregressive hybrid (PBAH) channel model is developed, which facilitates efficient training and testing dataset generation for HMR in a virtual environment. Experimental results demonstrate that the proposed PBAH channel model matches the actual experimental data very well and the proposed DSN achieves significantly smaller recognition error than that of CNN.
Optimization-Based Framework for Excavation Trajectory Generation
Oct 27, 2020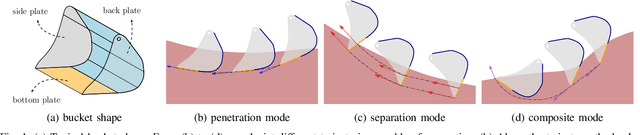
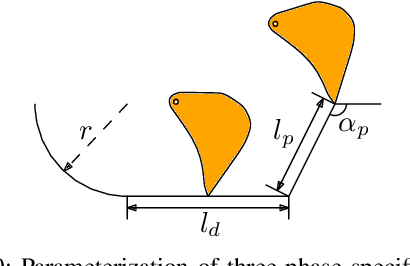
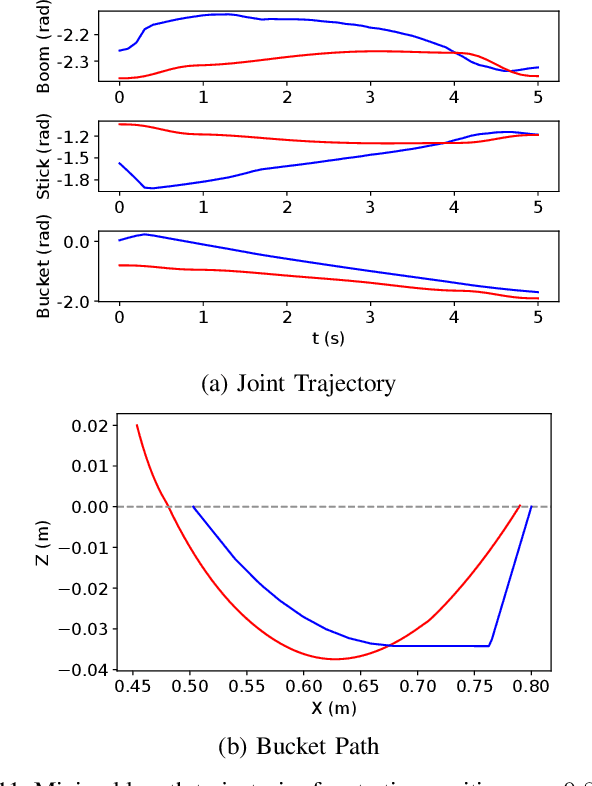
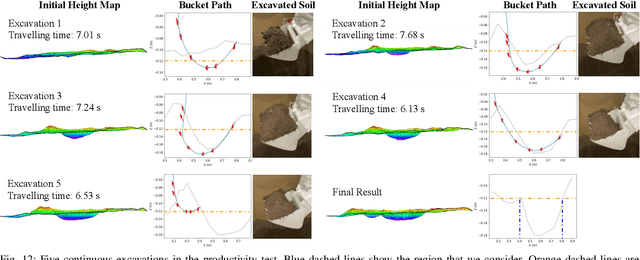
In this paper, we present a novel optimization-based framework for autonomous excavator trajectory generation under various objectives, including minimum joint displacement and minimum time. Traditional methods on excavation trajectory generation usually separate the excavation motion into a sequence of fixed phases, resulting in limited trajectory searching space. Our framework explores the space of all possible excavation trajectories represented with waypoints interpolated by a polynomial spline, thereby enabling optimization over a larger searching space. We formulate a generic task specification for excavation by constraining the instantaneous motion of the bucket and further add a target-oriented constraint, i.e. swept volume that indicates the estimated amount of excavated materials. To formulate time related objectives and constraints, we introduce time intervals between waypoints as variables into the optimization framework. We implement the proposed framework and evaluate its performance on a UR5 robotic arm. The experimental results demonstrate that the generated trajectories are able to excavate sufficient mass of soil for different terrain shapes and have 60% shorter minimal length than traditional excavation methods. We further compare our one-stage time optimal trajectory generation with the two-stage method. The result shows that trajectories generated by our one-stage method cost 18% less time on average.
TarGAN: Target-Aware Generative Adversarial Networks for Multi-modality Medical Image Translation
May 19, 2021
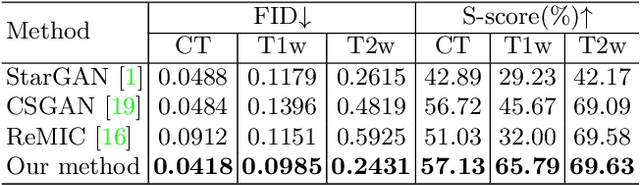
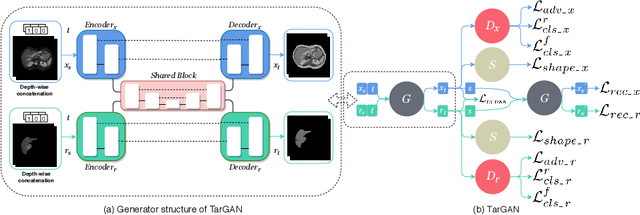
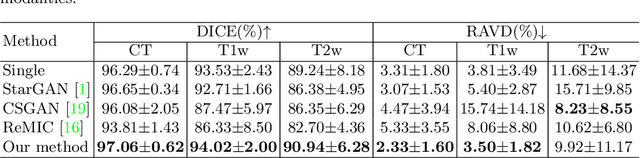
Paired multi-modality medical images, can provide complementary information to help physicians make more reasonable decisions than single modality medical images. But they are difficult to generate due to multiple factors in practice (e.g., time, cost, radiation dose). To address these problems, multi-modality medical image translation has aroused increasing research interest recently. However, the existing works mainly focus on translation effect of a whole image instead of a critical target area or Region of Interest (ROI), e.g., organ and so on. This leads to poor-quality translation of the localized target area which becomes blurry, deformed or even with extra unreasonable textures. In this paper, we propose a novel target-aware generative adversarial network called TarGAN, which is a generic multi-modality medical image translation model capable of (1) learning multi-modality medical image translation without relying on paired data, (2) enhancing quality of target area generation with the help of target area labels. The generator of TarGAN jointly learns mapping at two levels simultaneously - whole image translation mapping and target area translation mapping. These two mappings are interrelated through a proposed crossing loss. The experiments on both quantitative measures and qualitative evaluations demonstrate that TarGAN outperforms the state-of-the-art methods in all cases. Subsequent segmentation task is conducted to demonstrate effectiveness of synthetic images generated by TarGAN in a real-world application. Our code is available at https://github.com/2165998/TarGAN.
Towards Automated Satellite Conjunction Management with Bayesian Deep Learning
Dec 23, 2020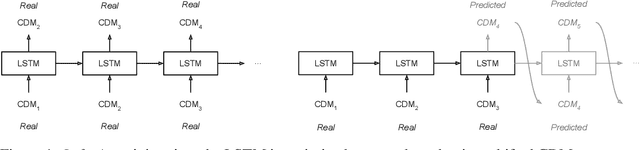

After decades of space travel, low Earth orbit is a junkyard of discarded rocket bodies, dead satellites, and millions of pieces of debris from collisions and explosions. Objects in high enough altitudes do not re-enter and burn up in the atmosphere, but stay in orbit around Earth for a long time. With a speed of 28,000 km/h, collisions in these orbits can generate fragments and potentially trigger a cascade of more collisions known as the Kessler syndrome. This could pose a planetary challenge, because the phenomenon could escalate to the point of hindering future space operations and damaging satellite infrastructure critical for space and Earth science applications. As commercial entities place mega-constellations of satellites in orbit, the burden on operators conducting collision avoidance manoeuvres will increase. For this reason, development of automated tools that predict potential collision events (conjunctions) is critical. We introduce a Bayesian deep learning approach to this problem, and develop recurrent neural network architectures (LSTMs) that work with time series of conjunction data messages (CDMs), a standard data format used by the space community. We show that our method can be used to model all CDM features simultaneously, including the time of arrival of future CDMs, providing predictions of conjunction event evolution with associated uncertainties.
On Classifying Continuous Constraint Satisfaction problems
Jun 04, 2021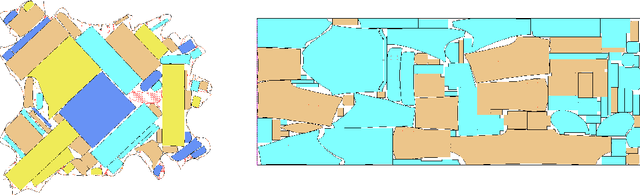
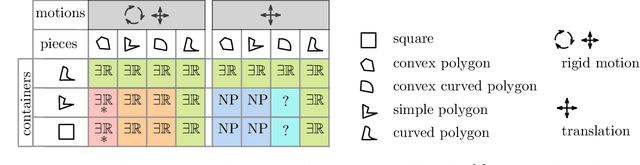
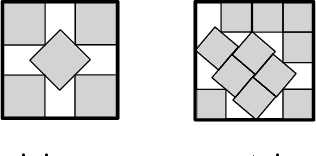
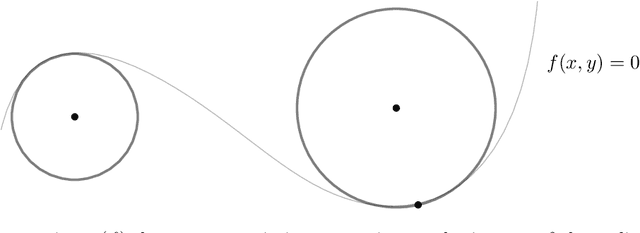
A continuous constraint satisfaction problem (CCSP) is a constraint satisfaction problem (CSP) with a domain $U \subset \mathbb{R}$. We engage in a systematic study to classify CCSPs that are complete of the Existential Theory of the Reals, i.e., ER-complete. To define this class, we first consider the problem ETR, which also stands for Existential Theory of the Reals. In an instance of this problem we are given some sentence of the form $\exists x_1, \ldots, x_n \in \mathbb{R} : \Phi(x_1, \ldots, x_n)$, where $\Phi$ is a well-formed quantifier-free formula consisting of the symbols $\{0, 1, +, \cdot, \geq, >, \wedge, \vee, \neg\}$, the goal is to check whether this sentence is true. Now the class ER is the family of all problems that admit a polynomial-time reduction to ETR. It is known that NP $\subseteq$ ER $\subseteq$ PSPACE. We restrict our attention on CCSPs with addition constraints ($x + y = z$) and some other mild technical condition. Previously, it was shown that multiplication constraints ($x \cdot y = z$), squaring constraints ($x^2 = y$), or inversion constraints ($x\cdot y = 1$) are sufficient to establish ER-completeness. We extend this in the strongest possible sense for equality constraints as follows. We show that CCSPs (with addition constraints and some other mild technical condition) that have any one well-behaved curved equality constraint ($f(x,y) = 0$) are ER-complete. We further extend our results to inequality constraints. We show that any well-behaved convexly curved and any well-behaved concavely curved inequality constraint ($f(x,y) \geq 0$ and $g(x,y) \geq 0$) imply ER-completeness on the class of such CCSPs. We apply our findings to geometric packing and answer an open question by Abrahamsen et al. [FOCS 2020]. Namely, we establish ER-completeness of packing convex pieces into a square container under rotations and translations.
Polarimetric Spatio-Temporal Light Transport Probing
May 25, 2021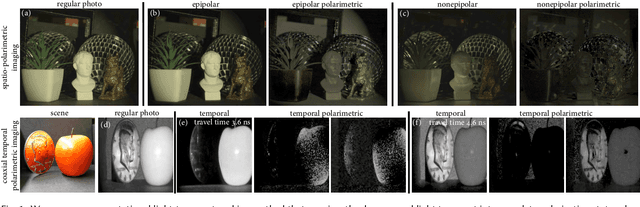
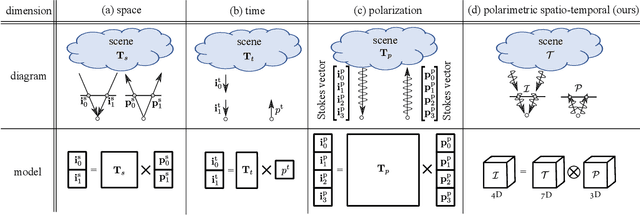
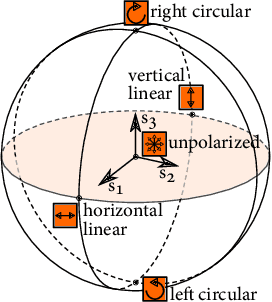

Light can undergo complex interactions with multiple scene surfaces of different material types before being reflected towards a detector. During this transport, every surface reflection and propagation is encoded in the properties of the photons that ultimately reach the detector, including travel time, direction, intensity, wavelength and polarization. Conventional imaging systems capture intensity by integrating over all other dimensions of the light into a single quantity, hiding this rich scene information in the accumulated measurements. Existing methods can untangle these into their spatial and temporal dimensions, fueling geometric scene understanding. However, examining polarimetric material properties jointly with geometric properties is an open challenge that could enable unprecedented capabilities beyond geometric understanding, allowing to incorporate material-dependent semantics. In this work, we propose a computational light-transport imaging method that captures the spatially- and temporally-resolved complete polarimetric response of a scene. Our method hinges on a novel 7D tensor theory of light transport. We discover low-rank structures in the polarimetric tensor dimension and propose a data-driven rotating ellipsometry method that learns to exploit redundancy of the polarimetric structures. We instantiate our theory in two imaging prototypes: spatio-polarimetric imaging and coaxial temporal-polarimetric imaging. This allows us to decompose scene light transport into temporal, spatial, and complete polarimetric dimensions that unveil scene properties hidden to conventional methods. We validate the applicability of our method on diverse tasks, including shape reconstruction with subsurface scattering, seeing through scattering medium, untangling multi-bounce light transport, breaking metamerism with polarization, and spatio-polarimetric decomposition of crystals.
Data Mining and Visualization to Understand Accident-prone Areas
Mar 11, 2021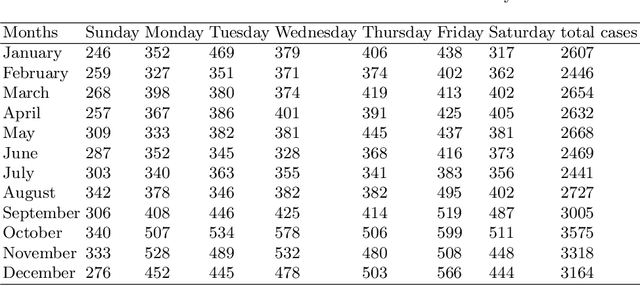
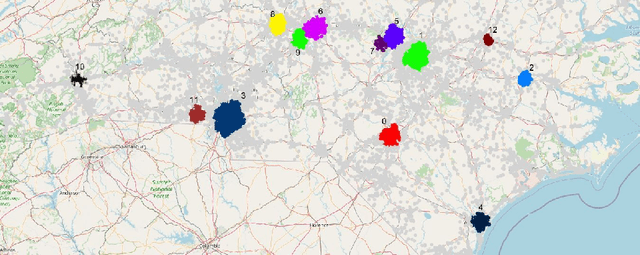
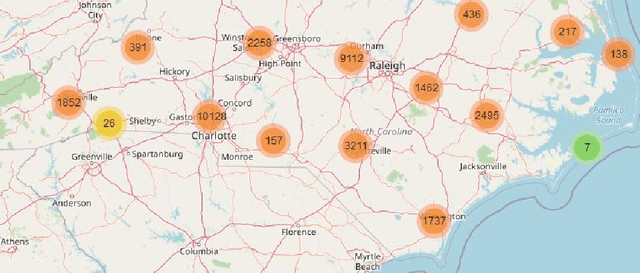
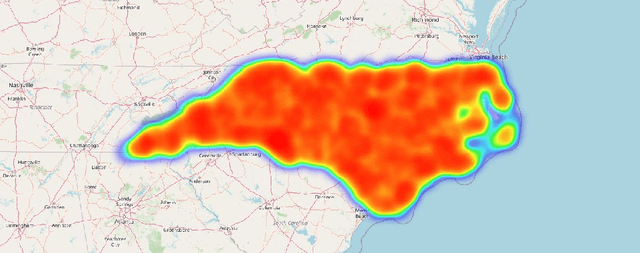
In this study, we present both data mining and information visualization techniques to identify accident-prone areas, most accident-prone time, day, and month. Also, we surveyed among volunteers to understand which visualization techniques help non-expert users to understand the findings better. Findings of this study suggest that most accidents occur in the dusk (i.e., between 6 to 7 pm), and on Fridays. Results also suggest that most accidents occurred in October, which is a popular month for tourism. These findings are consistent with social information and can help policymakers, residents, tourists, and other law enforcement agencies. This study can be extended to draw broader implications.
Causally interpretable multi-step time series forecasting: A new machine learning approach using simulated differential equations
Aug 27, 2019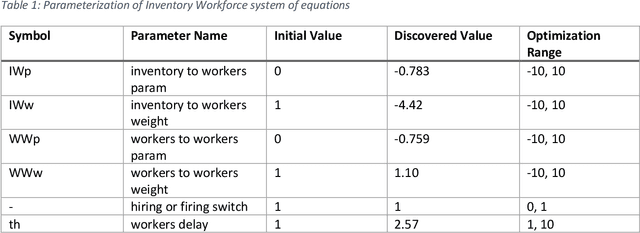
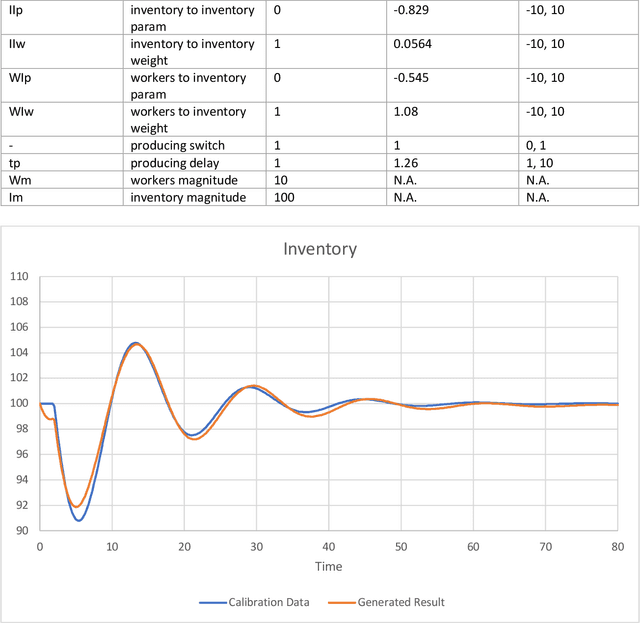
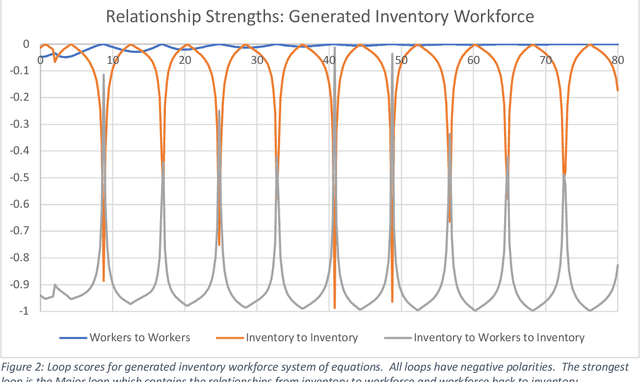
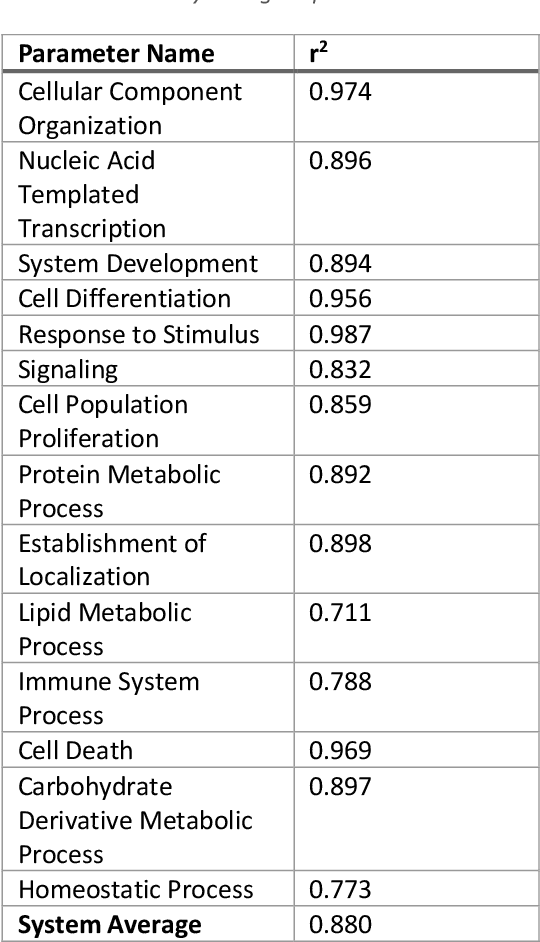
This work represents a new approach which generates then analyzes a highly non linear complex system of differential equations to do interpretable time series forecasting at a high level of accuracy. This approach provides insight and understanding into the mechanisms responsible for generating past and future behavior. Core to this method is the construction of a highly non linear complex system of differential equations that is then analyzed to determine the origins of behavior. This paper demonstrates the technique on Mass and Senge's two state Inventory Workforce model (1975) and then explores its application to the real world problem of organogenesis in mice. The organogenesis application consists of a fourteen state system where the generated set of equations reproduces observed behavior with a high level of accuracy (0.880 r^2) and when analyzed produces an interpretable and causally plausible explanation for the observed behavior.
Robust Graph Learning Under Wasserstein Uncertainty
May 13, 2021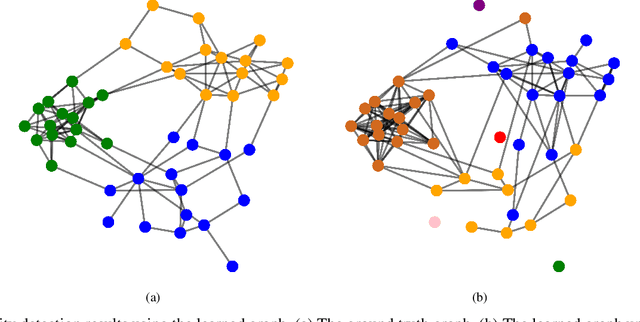
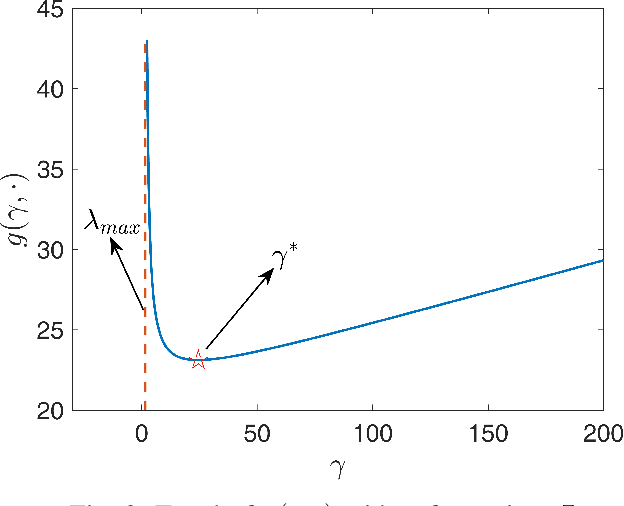
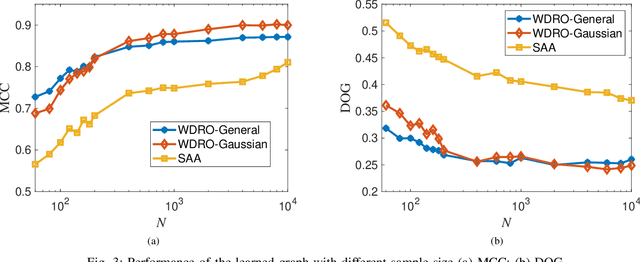
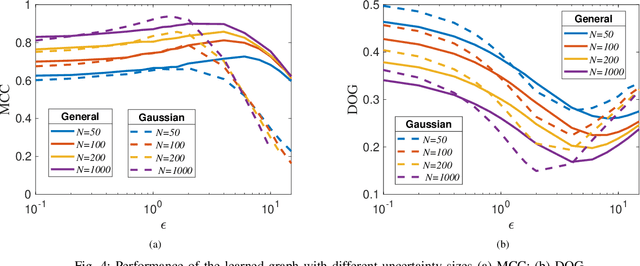
Graphs are playing a crucial role in different fields since they are powerful tools to unveil intrinsic relationships among signals. In many scenarios, an accurate graph structure representing signals is not available at all and that motivates people to learn a reliable graph structure directly from observed signals. However, in real life, it is inevitable that there exists uncertainty in the observed signals due to noise measurements or limited observability, which causes a reduction in reliability of the learned graph. To this end, we propose a graph learning framework using Wasserstein distributionally robust optimization (WDRO) which handles uncertainty in data by defining an uncertainty set on distributions of the observed data. Specifically, two models are developed, one of which assumes all distributions in uncertainty set are Gaussian distributions and the other one has no prior distributional assumption. Instead of using interior point method directly, we propose two algorithms to solve the corresponding models and show that our algorithms are more time-saving. In addition, we also reformulate both two models into Semi-Definite Programming (SDP), and illustrate that they are intractable in the scenario of large-scale graph. Experiments on both synthetic and real world data are carried out to validate the proposed framework, which show that our scheme can learn a reliable graph in the context of uncertainty.
Light-Weight RefineNet for Real-Time Semantic Segmentation
Oct 08, 2018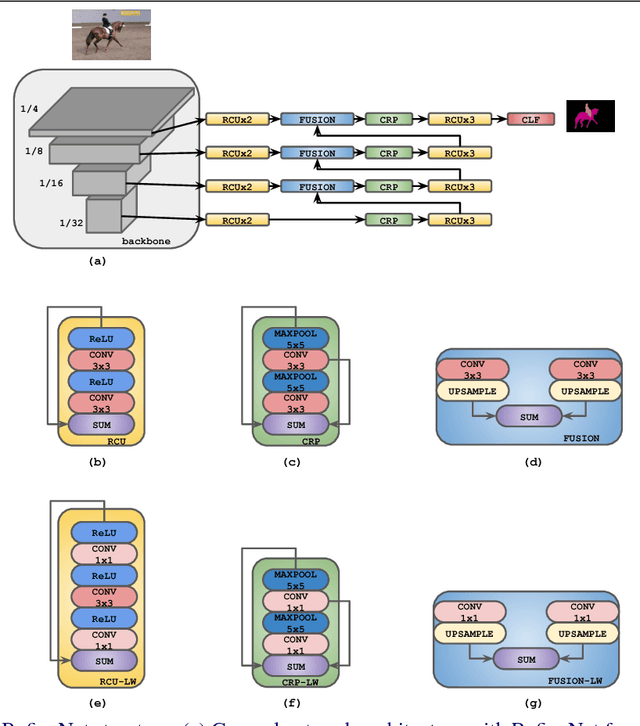

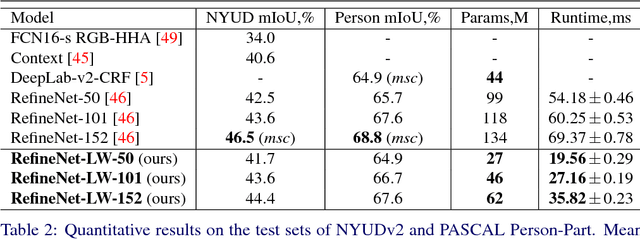

We consider an important task of effective and efficient semantic image segmentation. In particular, we adapt a powerful semantic segmentation architecture, called RefineNet, into the more compact one, suitable even for tasks requiring real-time performance on high-resolution inputs. To this end, we identify computationally expensive blocks in the original setup, and propose two modifications aimed to decrease the number of parameters and floating point operations. By doing that, we achieve more than twofold model reduction, while keeping the performance levels almost intact. Our fastest model undergoes a significant speed-up boost from 20 FPS to 55 FPS on a generic GPU card on 512x512 inputs with solid 81.1% mean iou performance on the test set of PASCAL VOC, while our slowest model with 32 FPS (from original 17 FPS) shows 82.7% mean iou on the same dataset. Alternatively, we showcase that our approach is easily mixable with light-weight classification networks: we attain 79.2% mean iou on PASCAL VOC using a model that contains only 3.3M parameters and performs only 9.3B floating point operations.