 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study of Using Spatial-Temporal Graph Convolutional Networks for Predicting Availability in Bike Sharing Schemes
Apr 21, 2021
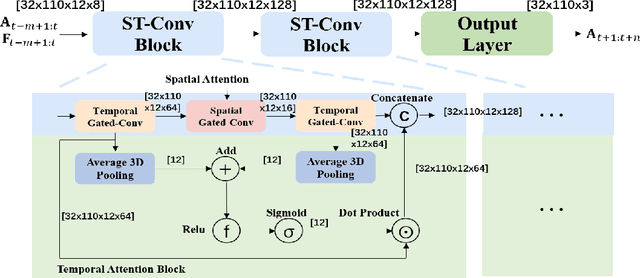
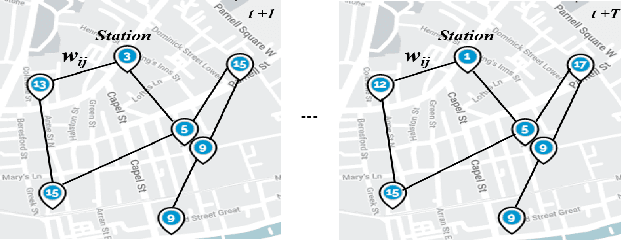
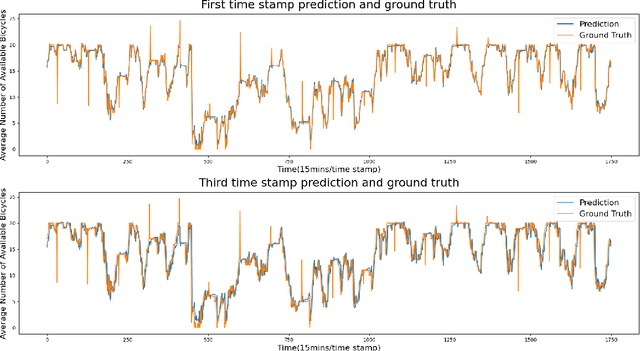
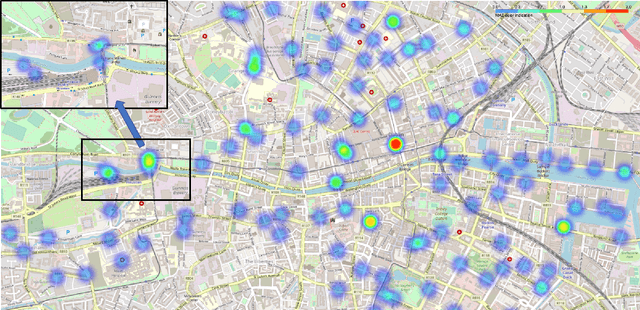
Accurately forecasting transportation demand is crucial for efficient urban traffic guidance, control and management. One solution to enhance the level of prediction accuracy is to leverage graph convolutional networks (GCN), a neural network based modelling approach with the ability to process data contained in graph based structures. As a powerful extension of GCN, a spatial-temporal graph convolutional network (ST-GCN) aims to capture the relationship of data contained in the graphical nodes across both spatial and temporal dimensions, which presents a novel deep learning paradigm for the analysis of complex time-series data that also involves spatial information as present in transportation use cases. In this paper, we present an Attention-based ST-GCN (AST-GCN) for predicting the number of available bikes in bike-sharing systems in cities, where the attention-based mechanism is introduced to further improve the performance of a ST-GCN. Furthermore, we also discuss the impacts of different modelling methods of adjacency matrices on the proposed architecture. Our experimental results are presented using two real-world datasets, Dublinbikes and NYC-Citi Bike, to illustrate the efficacy of our proposed model which outperforms the majority of existing approaches.
Efficient and Accurate Gradients for Neural SDEs
May 27, 2021
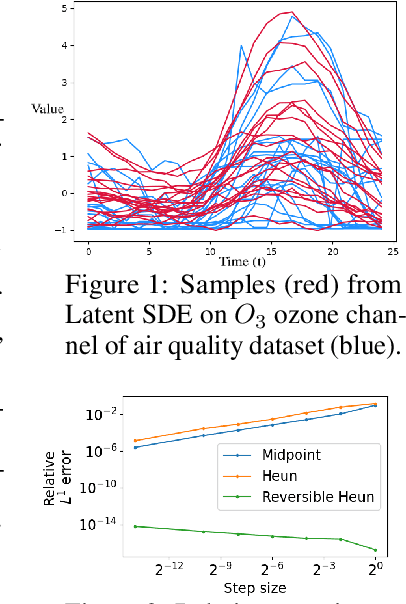

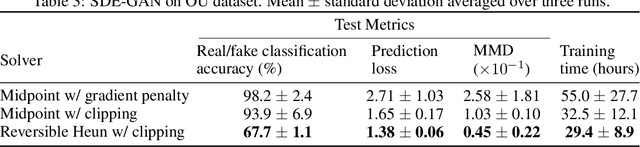
Neural SDEs combine many of the best qualities of both RNNs and SDEs, and as such are a natural choice for modelling many types of temporal dynamics. They offer memory efficiency, high-capacity function approximation, and strong priors on model space. Neural SDEs may be trained as VAEs or as GANs; in either case it is necessary to backpropagate through the SDE solve. In particular this may be done by constructing a backwards-in-time SDE whose solution is the desired parameter gradients. However, this has previously suffered from severe speed and accuracy issues, due to high computational complexity, numerical errors in the SDE solve, and the cost of reconstructing Brownian motion. Here, we make several technical innovations to overcome these issues. First, we introduce the reversible Heun method: a new SDE solver that is algebraically reversible -- which reduces numerical gradient errors to almost zero, improving several test metrics by substantial margins over state-of-the-art. Moreover it requires half as many function evaluations as comparable solvers, giving up to a $1.98\times$ speedup. Next, we introduce the Brownian interval. This is a new and computationally efficient way of exactly sampling and reconstructing Brownian motion; this is in contrast to previous reconstruction techniques that are both approximate and relatively slow. This gives up to a $10.6\times$ speed improvement over previous techniques. After that, when specifically training Neural SDEs as GANs (Kidger et al. 2021), we demonstrate how SDE-GANs may be trained through careful weight clipping and choice of activation function. This reduces computational cost (giving up to a $1.87\times$ speedup), and removes the truncation errors of the double adjoint required for gradient penalty, substantially improving several test metrics. Altogether these techniques offer substantial improvements over the state-of-the-art.
Soft and subspace robust multivariate rank tests based on entropy regularized optimal transport
Mar 16, 2021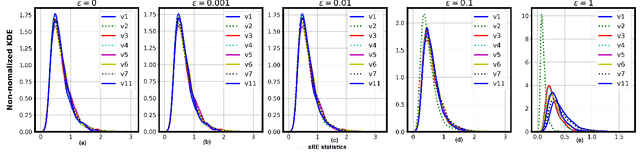
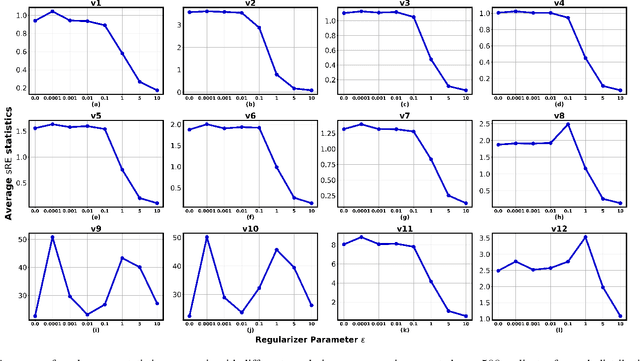
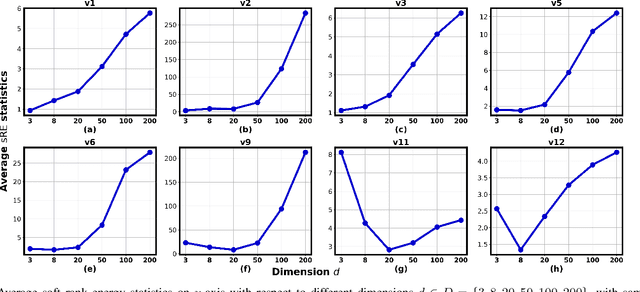
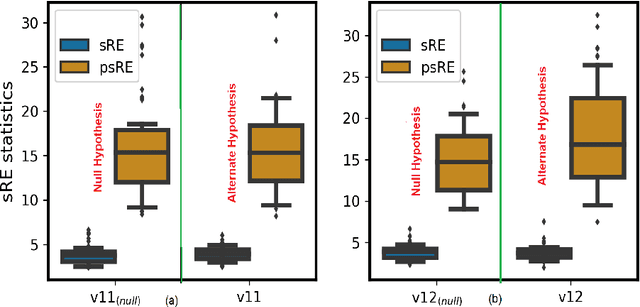
In this paper, we extend the recently proposed multivariate rank energy distance, based on the theory of optimal transport, for statistical testing of distributional similarity, to soft rank energy distance. Being differentiable, this in turn allows us to extend the rank energy to a subspace robust rank energy distance, dubbed Projected soft-Rank Energy distance, which can be computed via optimization over the Stiefel manifold. We show via experiments that using projected soft rank energy one can trade-off the detection power vs the false alarm via projections onto an appropriately selected low dimensional subspace. We also show the utility of the proposed tests on unsupervised change point detection in multivariate time series data. All codes are publicly available at the link provided in the experiment section.
Scalable photonic reinforcement learning by time-division multiplexing of laser chaos
Mar 26, 2018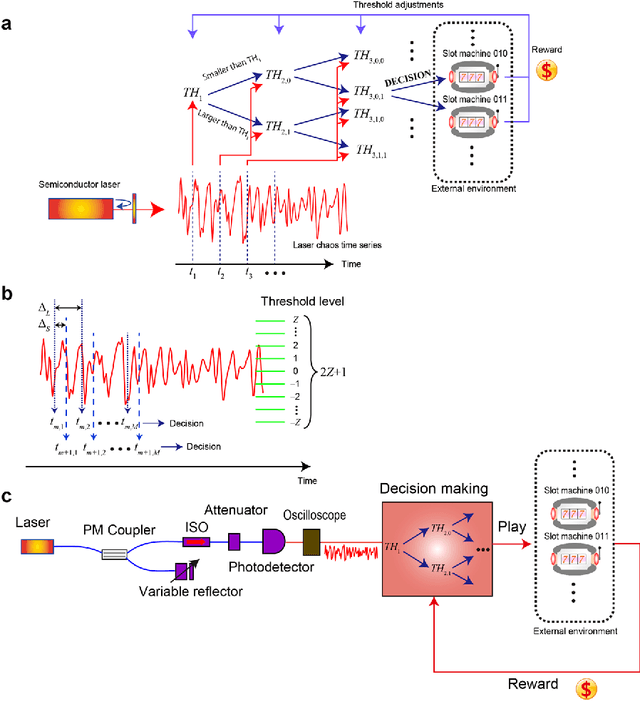
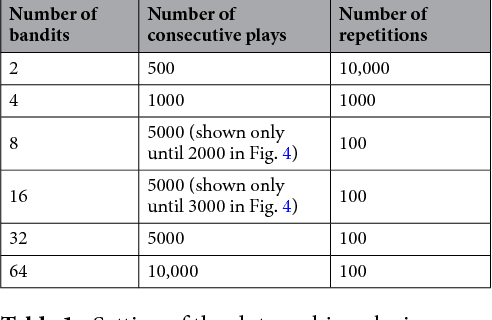
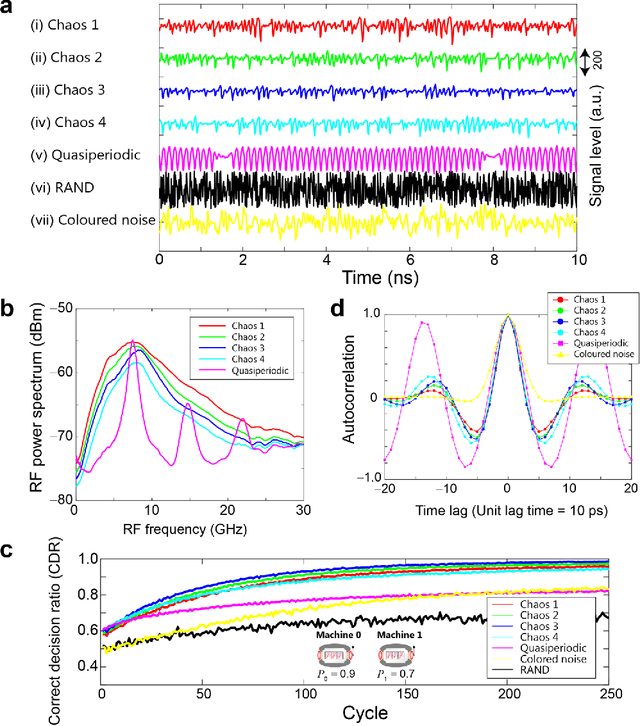
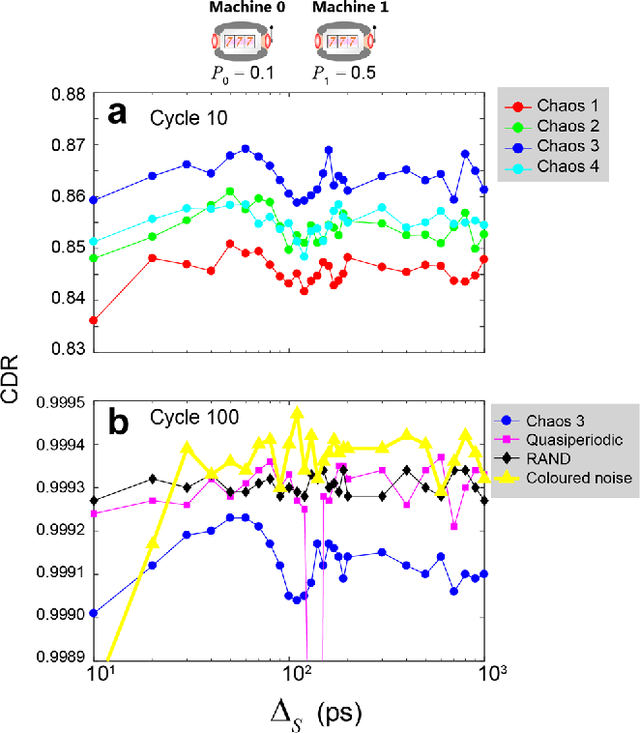
Reinforcement learning involves decision making in dynamic and uncertain environments and constitutes a crucial element of artificial intelligence. In our previous work, we experimentally demonstrated that the ultrafast chaotic oscillatory dynamics of lasers can be used to solve the two-armed bandit problem efficiently, which requires decision making concerning a class of difficult trade-offs called the exploration-exploitation dilemma. However, only two selections were employed in that research; thus, the scalability of the laser-chaos-based reinforcement learning should be clarified. In this study, we demonstrated a scalable, pipelined principle of resolving the multi-armed bandit problem by introducing time-division multiplexing of chaotically oscillated ultrafast time-series. The experimental demonstrations in which bandit problems with up to 64 arms were successfully solved are presented in this report. Detailed analyses are also provided that include performance comparisons among laser chaos signals generated in different physical conditions, which coincide with the diffusivity inherent in the time series. This study paves the way for ultrafast reinforcement learning by taking advantage of the ultrahigh bandwidths of light wave and practical enabling technologies.
BARF: Bundle-Adjusting Neural Radiance Fields
Apr 13, 2021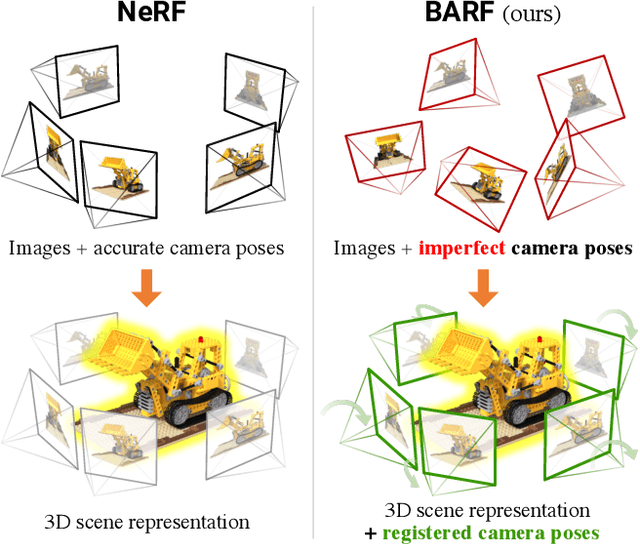
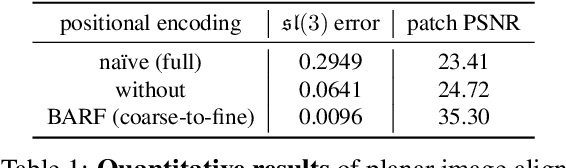
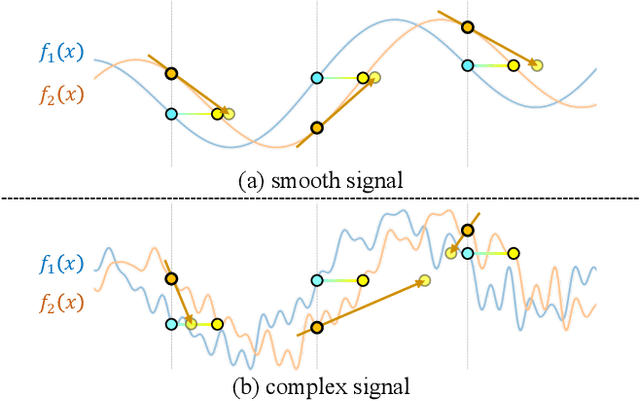
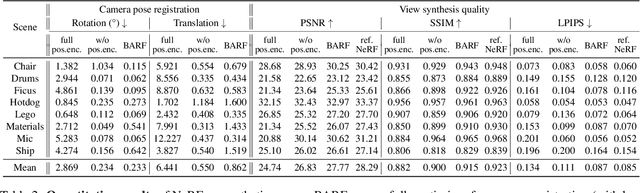
Neural Radiance Fields (NeRF) have recently gained a surge of interest within the computer vision community for its power to synthesize photorealistic novel views of real-world scenes. One limitation of NeRF, however, is its requirement of accurate camera poses to learn the scene representations. In this paper, we propose Bundle-Adjusting Neural Radiance Fields (BARF) for training NeRF from imperfect (or even unknown) camera poses -- the joint problem of learning neural 3D representations and registering camera frames. We establish a theoretical connection to classical image alignment and show that coarse-to-fine registration is also applicable to NeRF. Furthermore, we show that na\"ively applying positional encoding in NeRF has a negative impact on registration with a synthesis-based objective. Experiments on synthetic and real-world data show that BARF can effectively optimize the neural scene representations and resolve large camera pose misalignment at the same time. This enables view synthesis and localization of video sequences from unknown camera poses, opening up new avenues for visual localization systems (e.g. SLAM) and potential applications for dense 3D mapping and reconstruction.
Temporally-Reweighted Chinese Restaurant Process Mixtures for Clustering, Imputing, and Forecasting Multivariate Time Series
Apr 01, 2018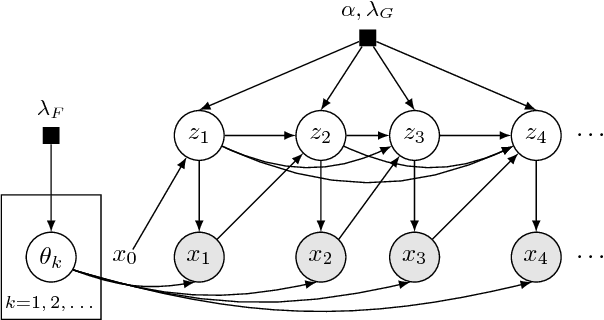
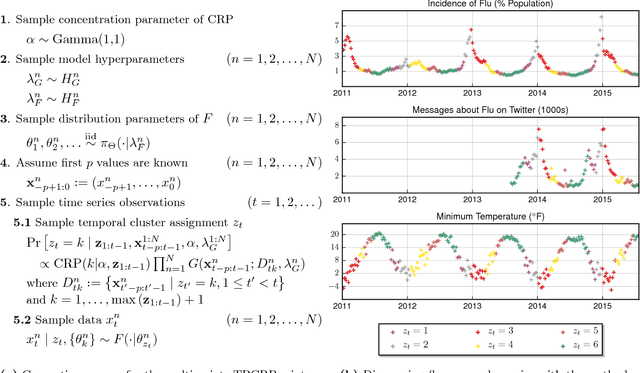
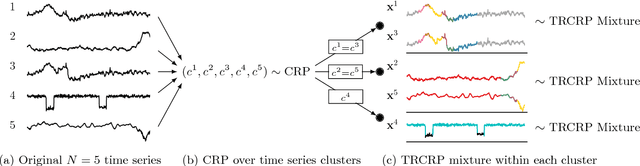
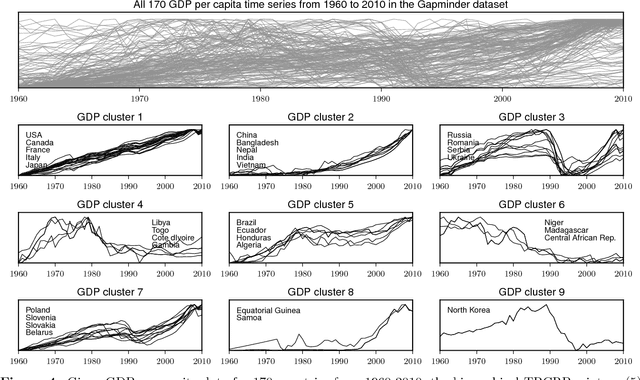
This article proposes a Bayesian nonparametric method for forecasting, imputation, and clustering in sparsely observed, multivariate time series data. The method is appropriate for jointly modeling hundreds of time series with widely varying, non-stationary dynamics. Given a collection of $N$ time series, the Bayesian model first partitions them into independent clusters using a Chinese restaurant process prior. Within a cluster, all time series are modeled jointly using a novel "temporally-reweighted" extension of the Chinese restaurant process mixture. Markov chain Monte Carlo techniques are used to obtain samples from the posterior distribution, which are then used to form predictive inferences. We apply the technique to challenging forecasting and imputation tasks using seasonal flu data from the US Center for Disease Control and Prevention, demonstrating superior forecasting accuracy and competitive imputation accuracy as compared to multiple widely used baselines. We further show that the model discovers interpretable clusters in datasets with hundreds of time series, using macroeconomic data from the Gapminder Foundation.
MLDS: A Dataset for Weight-Space Analysis of Neural Networks
Apr 21, 2021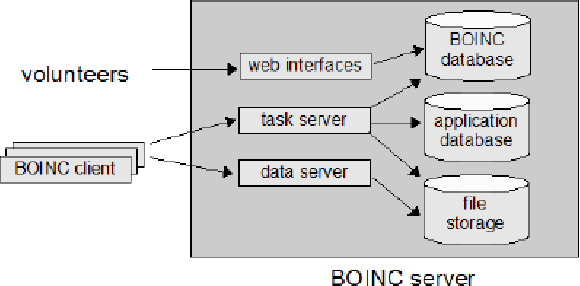


Neural networks are powerful models that solve a variety of complex real-world problems. However, the stochastic nature of training and large number of parameters in a typical neural model makes them difficult to evaluate via inspection. Research shows this opacity can hide latent undesirable behavior, be it from poorly representative training data or via malicious intent to subvert the behavior of the network, and that this behavior is difficult to detect via traditional indirect evaluation criteria such as loss. Therefore, it is time to explore direct ways to evaluate a trained neural model via its structure and weights. In this paper we present MLDS, a new dataset consisting of thousands of trained neural networks with carefully controlled parameters and generated via a global volunteer-based distributed computing platform. This dataset enables new insights into both model-to-model and model-to-training-data relationships. We use this dataset to show clustering of models in weight-space with identical training data and meaningful divergence in weight-space with even a small change to the training data, suggesting that weight-space analysis is a viable and effective alternative to loss for evaluating neural networks.
Global Convergence of Three-layer Neural Networks in the Mean Field Regime
May 11, 2021In the mean field regime, neural networks are appropriately scaled so that as the width tends to infinity, the learning dynamics tends to a nonlinear and nontrivial dynamical limit, known as the mean field limit. This lends a way to study large-width neural networks via analyzing the mean field limit. Recent works have successfully applied such analysis to two-layer networks and provided global convergence guarantees. The extension to multilayer ones however has been a highly challenging puzzle, and little is known about the optimization efficiency in the mean field regime when there are more than two layers. In this work, we prove a global convergence result for unregularized feedforward three-layer networks in the mean field regime. We first develop a rigorous framework to establish the mean field limit of three-layer networks under stochastic gradient descent training. To that end, we propose the idea of a \textit{neuronal embedding}, which comprises of a fixed probability space that encapsulates neural networks of arbitrary sizes. The identified mean field limit is then used to prove a global convergence guarantee under suitable regularity and convergence mode assumptions, which -- unlike previous works on two-layer networks -- does not rely critically on convexity. Underlying the result is a universal approximation property, natural of neural networks, which importantly is shown to hold at \textit{any} finite training time (not necessarily at convergence) via an algebraic topology argument.
RIANN -- A Robust Neural Network Outperforms Attitude Estimation Filters
May 05, 2021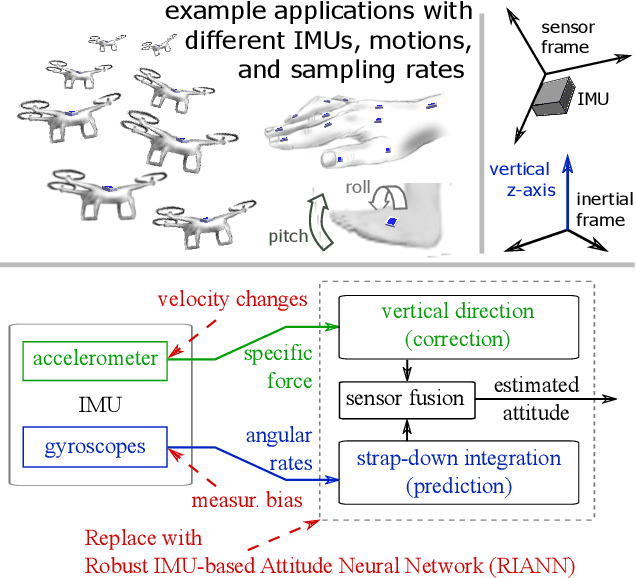
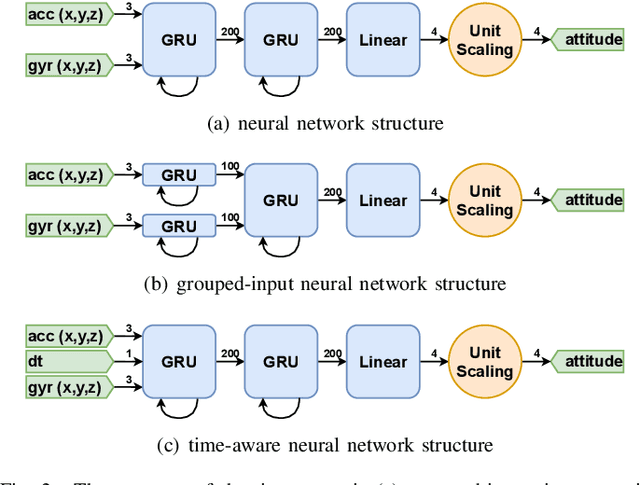
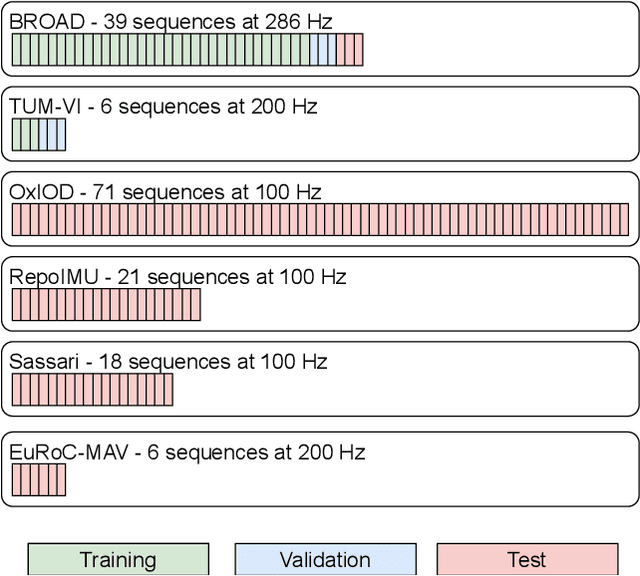
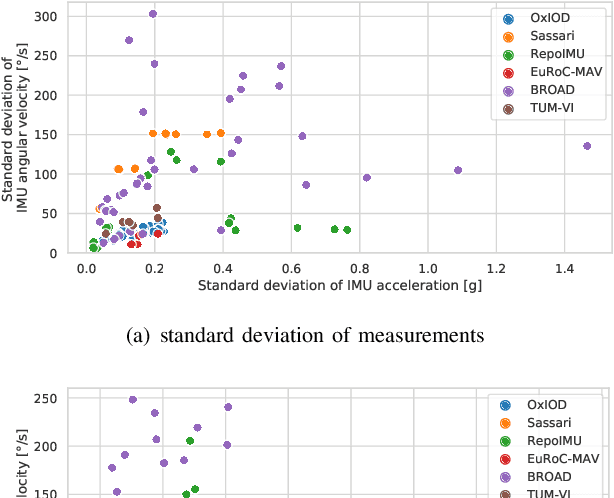
Inertial-sensor-based attitude estimation is a crucial technology in various applications, from human motion tracking to autonomous aerial and ground vehicles. Application scenarios differ in characteristics of the performed motion, presence of disturbances, and environmental conditions. Since state-of-the-art attitude estimators do not generalize well over these characteristics, their parameters must be tuned for the individual motion characteristics and circumstances. We propose RIANN, a real-time-capable neural network for robust IMU-based attitude estimation, which generalizes well across different motion dynamics, environments, and sampling rates, without the need for application-specific adaptations. We exploit two publicly available datasets for the method development and the training, and we add four completely different datasets for evaluation of the trained neural network in three different test scenarios with varying practical relevance. Results show that RIANN performs at least as well as state-of-the-art attitude estimation filters and outperforms them in several cases, even if the filter is tuned on the very same test dataset itself while RIANN has never seen data from that dataset, from the specific application, the same sensor hardware, or the same sampling frequency before. RIANN is expected to enable plug-and-play solutions in numerous applications, especially when accuracy is crucial but no ground-truth data is available for tuning or when motion and disturbance characteristics are uncertain. We made RIANN publicly available.
Camouflaged Object Segmentation with Distraction Mining
Apr 21, 2021
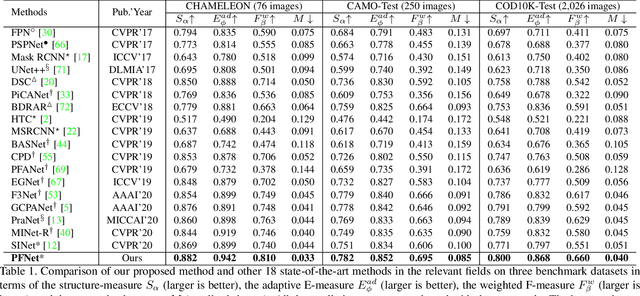
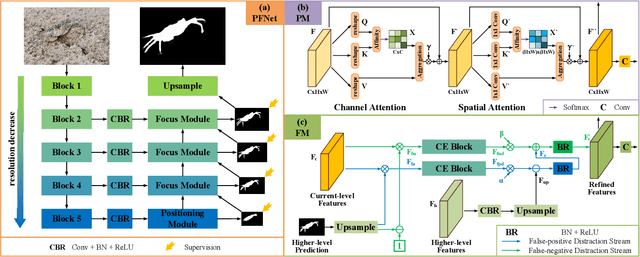
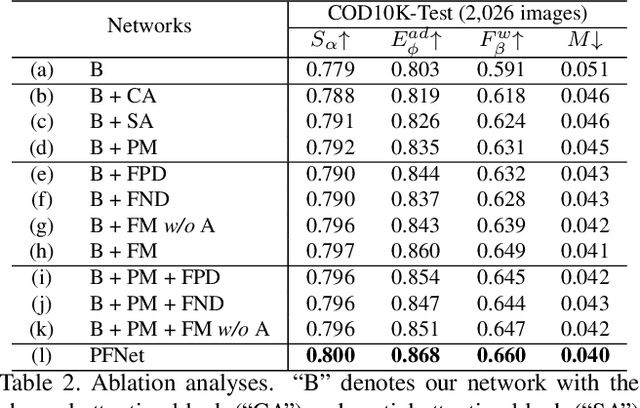
Camouflaged object segmentation (COS) aims to identify objects that are "perfectly" assimilate into their surroundings, which has a wide range of valuable applications. The key challenge of COS is that there exist high intrinsic similarities between the candidate objects and noise background. In this paper, we strive to embrace challenges towards effective and efficient COS. To this end, we develop a bio-inspired framework, termed Positioning and Focus Network (PFNet), which mimics the process of predation in nature. Specifically, our PFNet contains two key modules, i.e., the positioning module (PM) and the focus module (FM). The PM is designed to mimic the detection process in predation for positioning the potential target objects from a global perspective and the FM is then used to perform the identification process in predation for progressively refining the coarse prediction via focusing on the ambiguous regions. Notably, in the FM, we develop a novel distraction mining strategy for distraction discovery and removal, to benefit the performance of estimation. Extensive experiments demonstrate that our PFNet runs in real-time (72 FPS) and significantly outperforms 18 cutting-edge models on three challenging datasets under four standard metrics.