 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Regret Minimization Approach to Iterative Learning Control
Feb 26, 2021
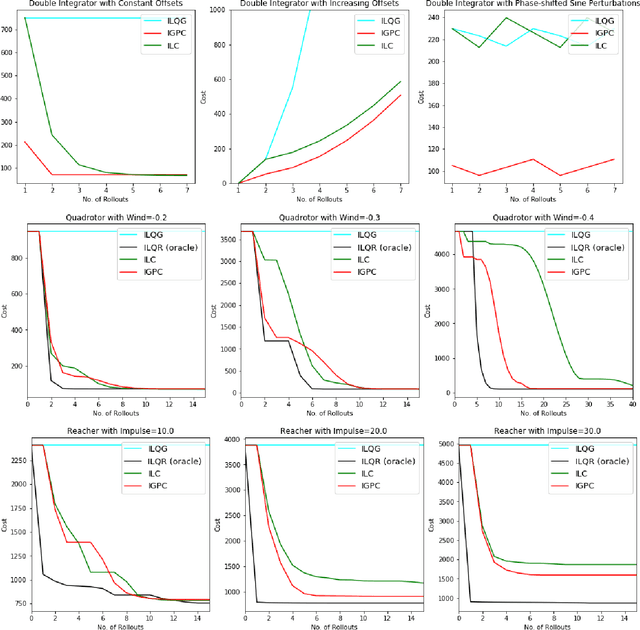
We consider the setting of iterative learning control, or model-based policy learning in the presence of uncertain, time-varying dynamics. In this setting, we propose a new performance metric, planning regret, which replaces the standard stochastic uncertainty assumptions with worst case regret. Based on recent advances in non-stochastic control, we design a new iterative algorithm for minimizing planning regret that is more robust to model mismatch and uncertainty. We provide theoretical and empirical evidence that the proposed algorithm outperforms existing methods on several benchmarks.
Composition Properties of Inferential Privacy for Time-Series Data
Jul 10, 2017With the proliferation of mobile devices and the internet of things, developing principled solutions for privacy in time series applications has become increasingly important. While differential privacy is the gold standard for database privacy, many time series applications require a different kind of guarantee, and a number of recent works have used some form of inferential privacy to address these situations. However, a major barrier to using inferential privacy in practice is its lack of graceful composition -- even if the same or related sensitive data is used in multiple releases that are safe individually, the combined release may have poor privacy properties. In this paper, we study composition properties of a form of inferential privacy called Pufferfish when applied to time-series data. We show that while general Pufferfish mechanisms may not compose gracefully, a specific Pufferfish mechanism, called the Markov Quilt Mechanism, which was recently introduced, has strong composition properties comparable to that of pure differential privacy when applied to time series data.
Augmented Networks for Faster Brain Metastases Detection in T1-Weighted Contrast-Enhanced 3D MRI
May 27, 2021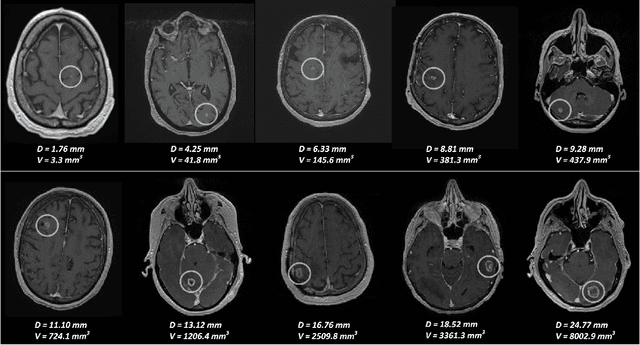
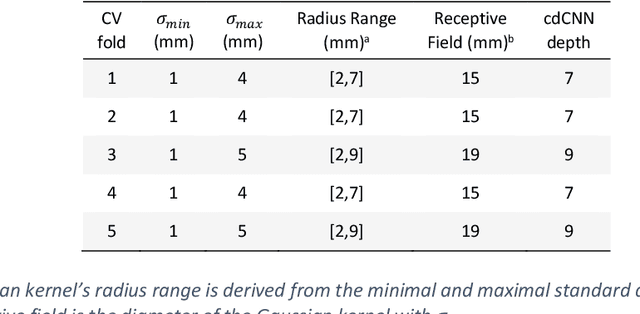
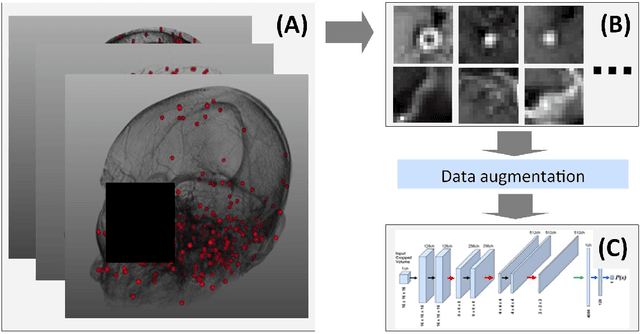
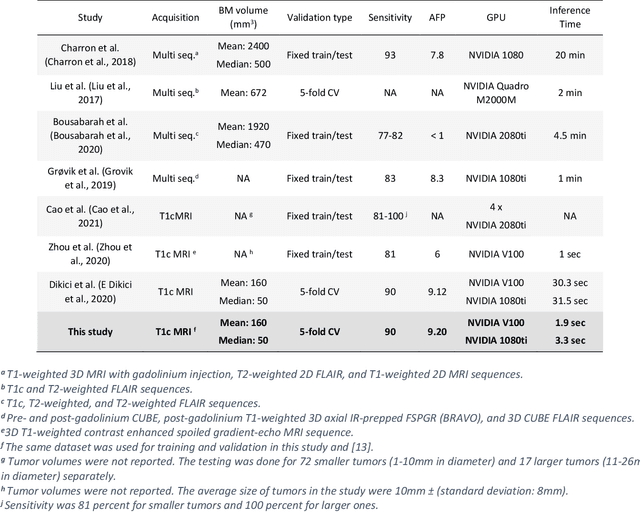
Early detection of brain metastases (BM) is one of the determining factors for the successful treatment of patients with cancer; however, the accurate detection of small BM lesions (< 15mm) remains a challenging task. We previously described a framework for the detection of small BM in single-sequence gadolinium-enhanced T1-weighted 3D MRI datasets. It combined classical image processing (IP) with a dedicated convolutional neural network, taking approximately 30 seconds to process each dataset due to computation-intensive IP stages. To overcome the speed limitation, this study aims to reformulate the framework via an augmented pair of CNNs (eliminating the IP) to reduce the processing times while preserving the BM detection performance. Our previous implementation of the BM detection algorithm utilized Laplacian of Gaussians (LoG) for the candidate selection portion of the solution. In this study, we introduce a novel BM candidate detection CNN (cdCNN) to replace this classical IP stage. The network is formulated to have (1) a similar receptive field as the LoG method, and (2) a bias for the detection of BM lesion loci. The proposed CNN is later augmented with a classification CNN to perform the BM detection task. The cdCNN achieved 97.4% BM detection sensitivity when producing 60K candidates per 3D MRI dataset, while the LoG achieved 96.5% detection sensitivity with 73K candidates. The augmented BM detection framework generated on average 9.20 false-positive BM detections per patient for 90% sensitivity, which is comparable with our previous results. However, it processes each 3D data in 1.9 seconds, presenting a 93.5% reduction in the computation time.
Robust Maximum Entropy Behavior Cloning
Jan 04, 2021
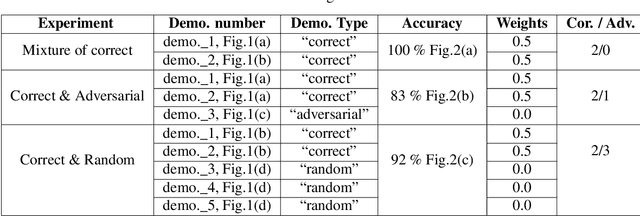

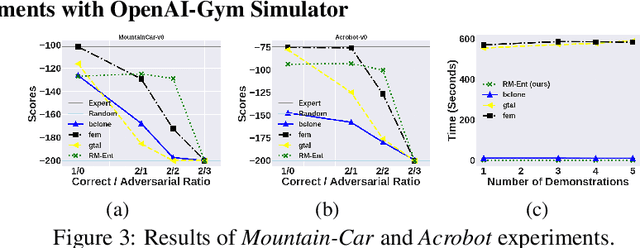
Imitation learning (IL) algorithms use expert demonstrations to learn a specific task. Most of the existing approaches assume that all expert demonstrations are reliable and trustworthy, but what if there exist some adversarial demonstrations among the given data-set? This may result in poor decision-making performance. We propose a novel general frame-work to directly generate a policy from demonstrations that autonomously detect the adversarial demonstrations and exclude them from the data set. At the same time, it's sample, time-efficient, and does not require a simulator. To model such adversarial demonstration we propose a min-max problem that leverages the entropy of the model to assign weights for each demonstration. This allows us to learn the behavior using only the correct demonstrations or a mixture of correct demonstrations.
Convolutional Neural Network-based Intrusion Detection System for AVTP Streams in Automotive Ethernet-based Networks
Feb 06, 2021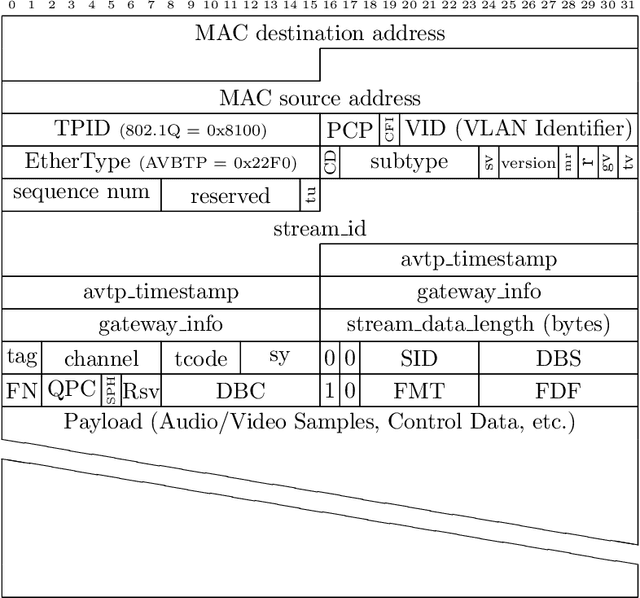
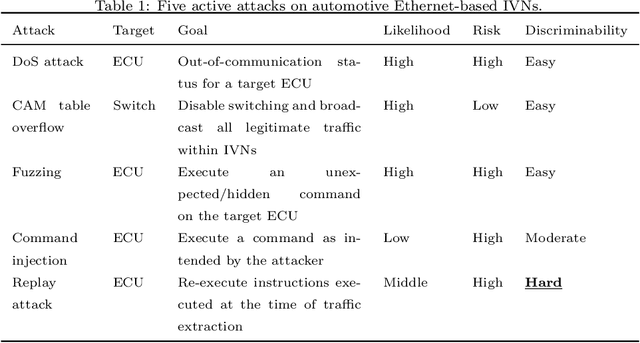
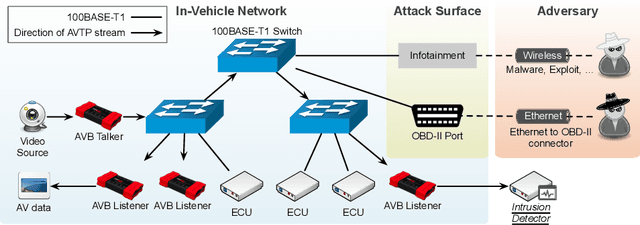
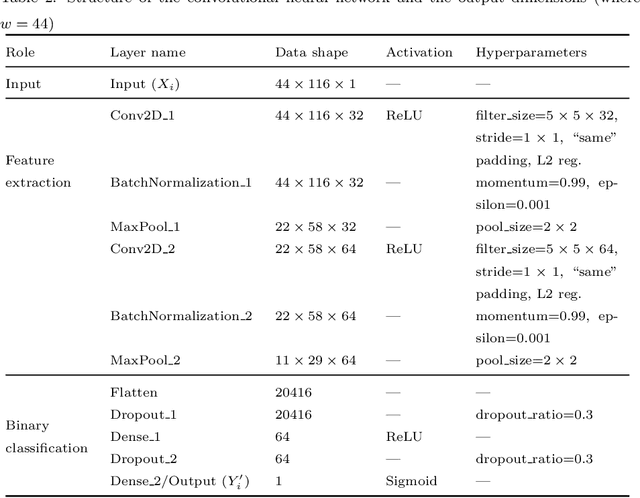
Connected and autonomous vehicles (CAVs) are an innovative form of traditional vehicles. Automotive Ethernet replaces the controller area network and FlexRay to support the large throughput required by high-definition applications. As CAVs have numerous functions, they exhibit a large attack surface and an increased vulnerability to attacks. However, no previous studies have focused on intrusion detection in automotive Ethernet-based networks. In this paper, we present an intrusion detection method for detecting audio-video transport protocol (AVTP) stream injection attacks in automotive Ethernet-based networks. To the best of our knowledge, this is the first such method developed for automotive Ethernet. The proposed intrusion detection model is based on feature generation and a convolutional neural network (CNN). To evaluate our intrusion detection system, we built a physical BroadR-Reach-based testbed and captured real AVTP packets. The experimental results show that the model exhibits outstanding performance: the F1-score and recall are greater than 0.9704 and 0.9949, respectively. In terms of the inference time per input and the generation intervals of AVTP traffic, our CNN model can readily be employed for real-time detection.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021

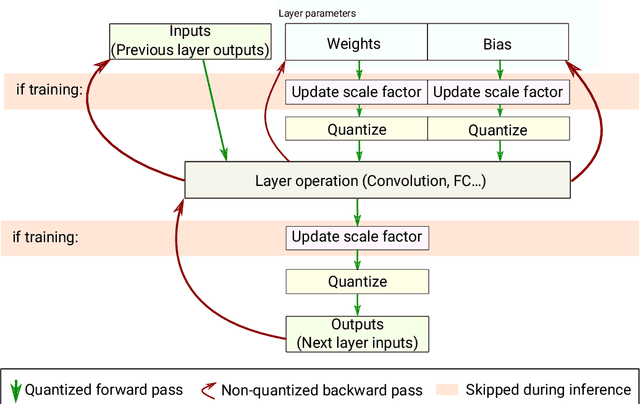
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984
Towards Optimized Distributed Multi-Robot Printing: An Algorithmic Approach
Mar 14, 2021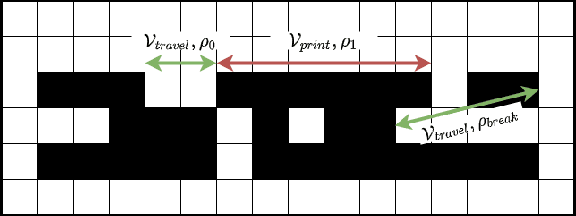
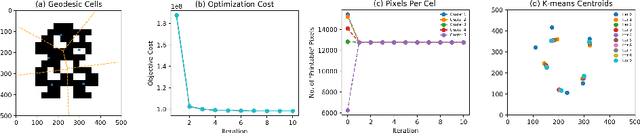
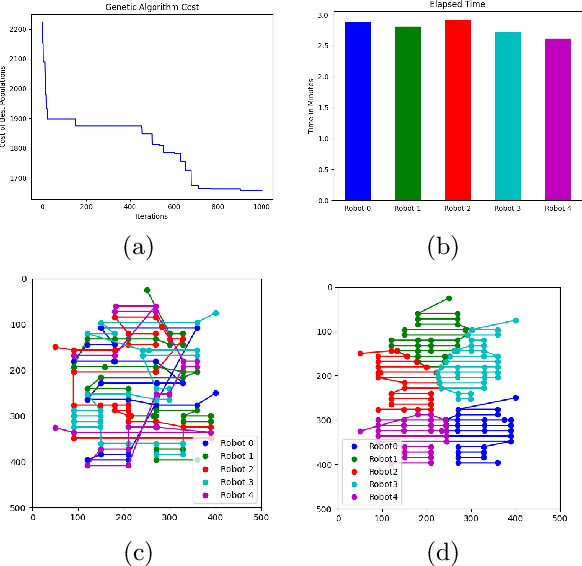
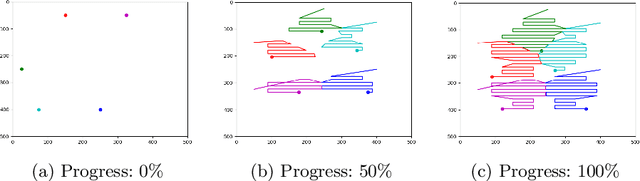
This paper presents a distributed multi-robot printing method which utilizes an optimization approach to decompose and allocate a printing task to a group of mobile robots. The motivation for this problem is to minimize the printing time of the robots by using an appropriate task decomposition algorithm. We present one such algorithm which decomposes an image into rasterized geodesic cells before allocating them to the robots for printing. In addition to this, we also present the design of a numerically controlled holonomic robot capable of spraying ink on smooth surfaces. Further, we use this robot to experimentally verify the results of this paper.
Optimal Dynamic Regret in Exp-Concave Online Learning
Apr 23, 2021

We consider the problem of the Zinkevich (2003)-style dynamic regret minimization in online learning with exp-concave losses. We show that whenever improper learning is allowed, a Strongly Adaptive online learner achieves the dynamic regret of $\tilde O(d^{3.5}n^{1/3}C_n^{2/3} \vee d\log n)$ where $C_n$ is the total variation (a.k.a. path length) of the an arbitrary sequence of comparators that may not be known to the learner ahead of time. Achieving this rate was highly nontrivial even for squared losses in 1D where the best known upper bound was $O(\sqrt{nC_n} \vee \log n)$ (Yuan and Lamperski, 2019). Our new proof techniques make elegant use of the intricate structures of the primal and dual variables imposed by the KKT conditions and could be of independent interest. Finally, we apply our results to the classical statistical problem of locally adaptive non-parametric regression (Mammen, 1991; Donoho and Johnstone, 1998) and obtain a stronger and more flexible algorithm that do not require any statistical assumptions or any hyperparameter tuning.
Non-Episodic Learning for Online LQR of Unknown Linear Gaussian System
Mar 26, 2021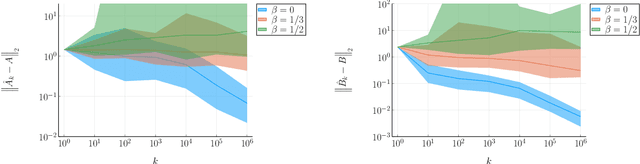
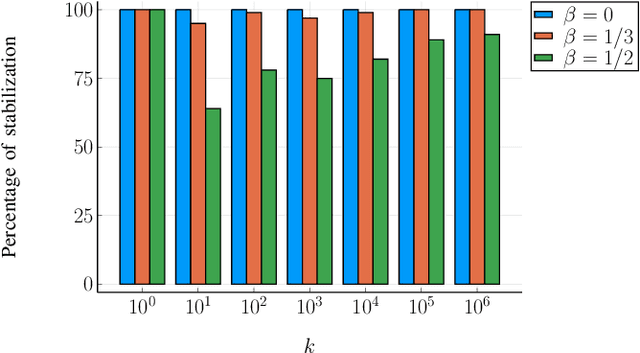
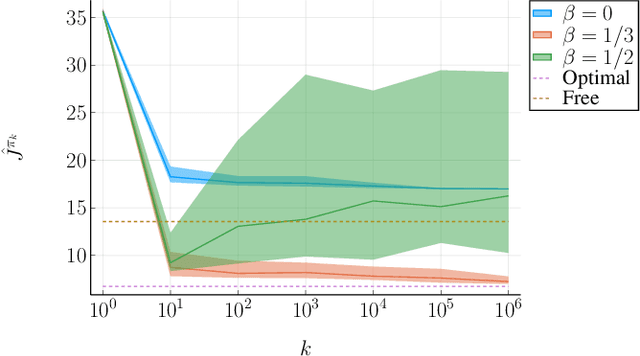
This paper considers the data-driven linear-quadratic regulation (LQR) problem where the system parameters are unknown and need to be identified in real time. Contrary to existing system identification and data-driven control methods, which typically require either offline data collection or multiple resets, we propose an online non-episodic algorithm that gains knowledge about the system from a single trajectory. The algorithm guarantees that both the identification error and the suboptimality gap of control performance in this trajectory converge to zero almost surely. Furthermore, we characterize the almost sure convergence rates of identification and control, and reveal an optimal trade-off between exploration and exploitation. We provide a numerical example to illustrate the effectiveness of our proposed strategy.
Realising Active Inference in Variational Message Passing: the Outcome-blind Certainty Seeker
Apr 23, 2021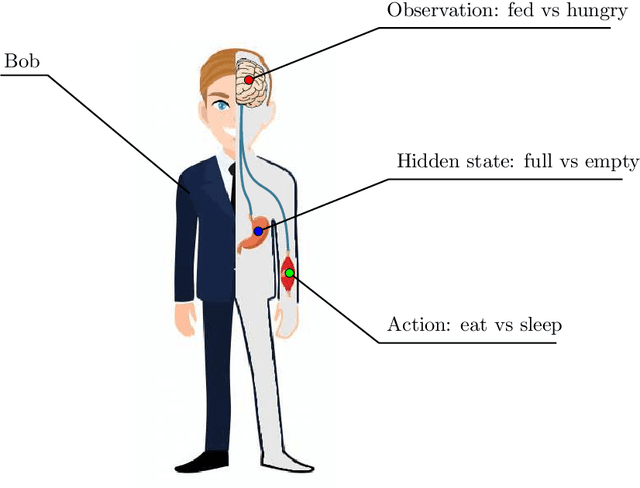
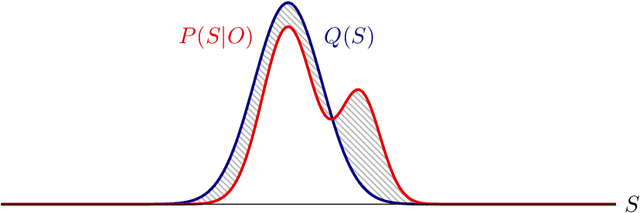

Active inference is a state-of-the-art framework in neuroscience that offers a unified theory of brain function. It is also proposed as a framework for planning in AI. Unfortunately, the complex mathematics required to create new models -- can impede application of active inference in neuroscience and AI research. This paper addresses this problem by providing a complete mathematical treatment of the active inference framework -- in discrete time and state spaces -- and the derivation of the update equations for any new model. We leverage the theoretical connection between active inference and variational message passing as describe by John Winn and Christopher M. Bishop in 2005. Since, variational message passing is a well-defined methodology for deriving Bayesian belief update equations, this paper opens the door to advanced generative models for active inference. We show that using a fully factorized variational distribution simplifies the expected free energy -- that furnishes priors over policies -- so that agents seek unambiguous states. Finally, we consider future extensions that support deep tree searches for sequential policy optimisation -- based upon structure learning and belief propagation.