 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CoachNet: An Adversarial Sampling Approach for Reinforcement Learning
Jan 07, 2021
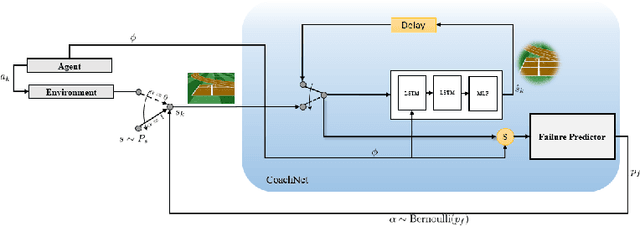

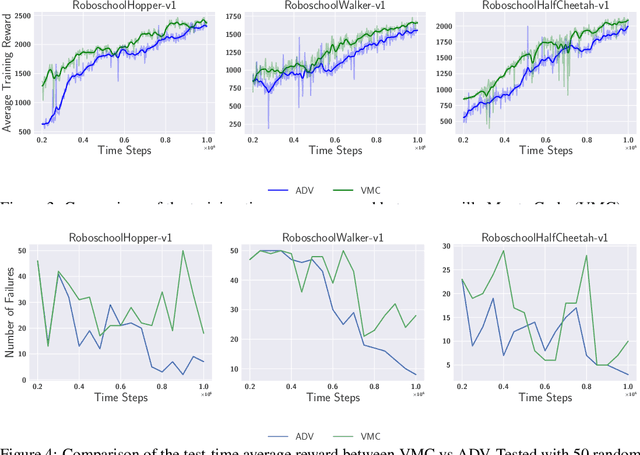
Despite the recent successes of reinforcement learning in games and robotics, it is yet to become broadly practical. Sample efficiency and unreliable performance in rare but challenging scenarios are two of the major obstacles. Drawing inspiration from the effectiveness of deliberate practice for achieving expert-level human performance, we propose a new adversarial sampling approach guided by a failure predictor named "CoachNet". CoachNet is trained online along with the agent to predict the probability of failure. This probability is then used in a stochastic sampling process to guide the agent to more challenging episodes. This way, instead of wasting time on scenarios that the agent has already mastered, training is focused on the agent's "weak spots". We present the design of CoachNet, explain its underlying principles, and empirically demonstrate its effectiveness in improving sample efficiency and test-time robustness in common continuous control tasks.
IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Apr 16, 2021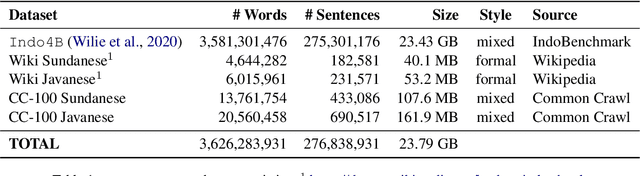
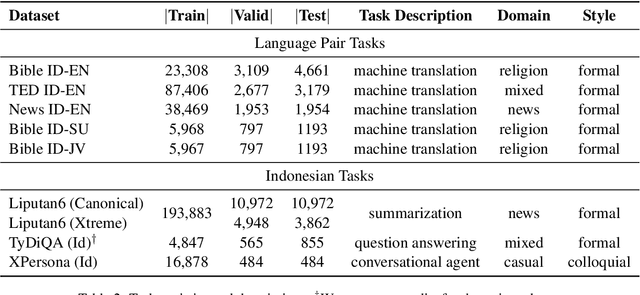
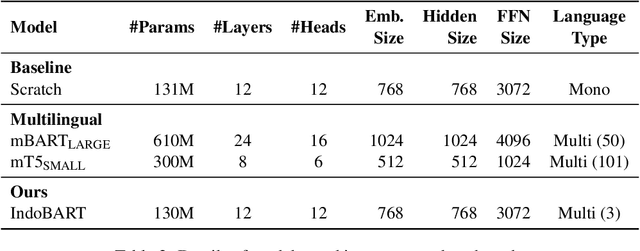
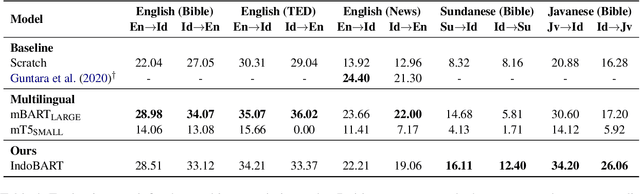
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
Dynamic DNN Decomposition for Lossless Synergistic Inference
Jan 15, 2021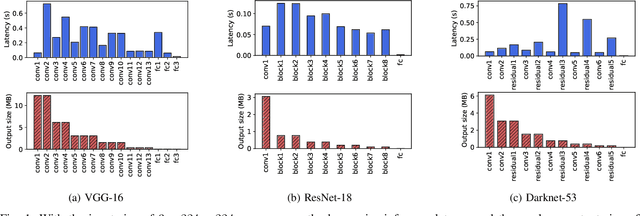

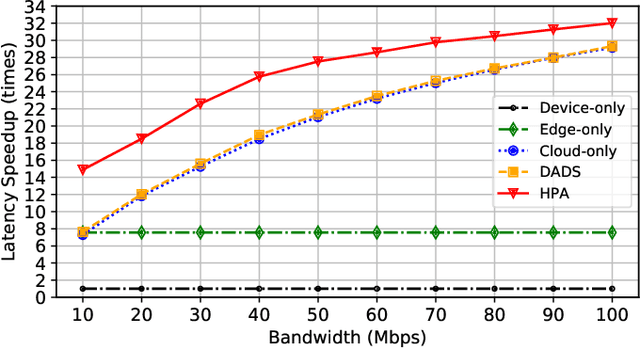
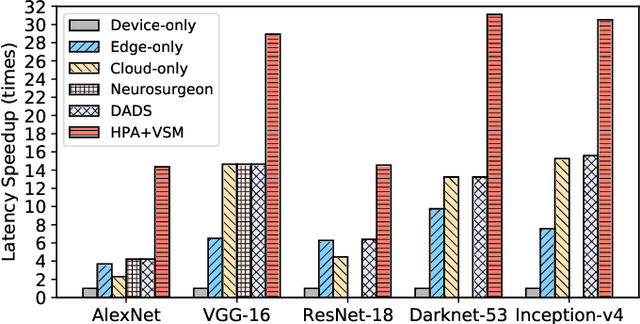
Deep neural networks (DNNs) sustain high performance in today's data processing applications. DNN inference is resource-intensive thus is difficult to fit into a mobile device. An alternative is to offload the DNN inference to a cloud server. However, such an approach requires heavy raw data transmission between the mobile device and the cloud server, which is not suitable for mission-critical and privacy-sensitive applications such as autopilot. To solve this problem, recent advances unleash DNN services using the edge computing paradigm. The existing approaches split a DNN into two parts and deploy the two partitions to computation nodes at two edge computing tiers. Nonetheless, these methods overlook collaborative device-edge-cloud computation resources. Besides, previous algorithms demand the whole DNN re-partitioning to adapt to computation resource changes and network dynamics. Moreover, for resource-demanding convolutional layers, prior works do not give a parallel processing strategy without loss of accuracy at the edge side. To tackle these issues, we propose D3, a dynamic DNN decomposition system for synergistic inference without precision loss. The proposed system introduces a heuristic algorithm named horizontal partition algorithm to split a DNN into three parts. The algorithm can partially adjust the partitions at run time according to processing time and network conditions. At the edge side, a vertical separation module separates feature maps into tiles that can be independently run on different edge nodes in parallel. Extensive quantitative evaluation of five popular DNNs illustrates that D3 outperforms the state-of-the-art counterparts up to 3.4 times in end-to-end DNN inference time and reduces backbone network communication overhead up to 3.68 times.
We Know What You Want: An Advertising Strategy Recommender System for Online Advertising
May 25, 2021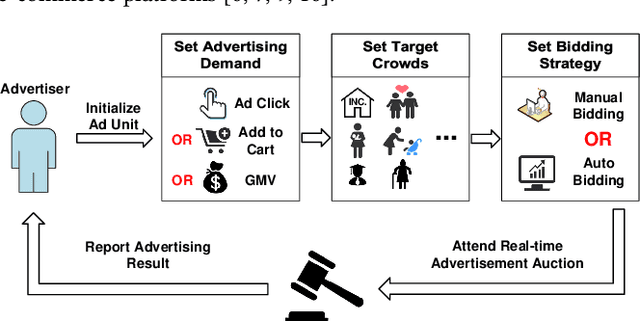
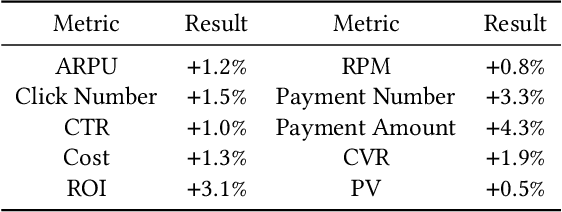
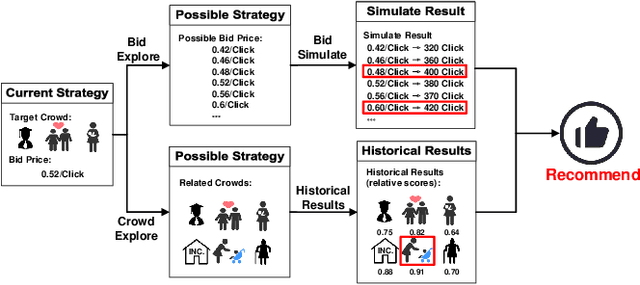
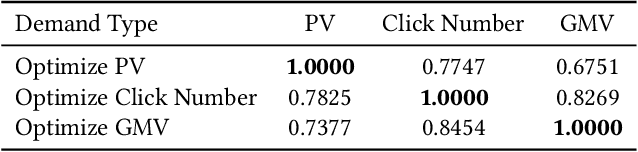
Advertisers play an important role in e-commerce platforms, whose advertising expenditures are the main source of revenue for e-commerce platforms. Therefore, providing advertisers with a better advertising experience by reducing their cost of trial and error during ad real-time bidding is crucial to the long-term revenue of e-commerce platforms. To achieve this goal, the advertising platform needs to understand the advertisers' unique marketing demands and actively recommend personalized and optimal advertising strategies for them. In this work, we first deploy a prototype recommender system on Taobao display advertising platform for constant bid and crowd optimization. Then, we propose a novel recommender system for dynamic bidding strategy recommendation, which models the advertiser's strategy recommendation problem as a contextual bandit problem. We use a neural network as the agent to predict the advertisers' demands based on their profile and historical adoption behaviors. Based on the estimated demand, we apply simulated bidding to derive the optimal bidding strategy for recommendation and interact with the advertiser by displaying the possible advertising performance. To solve the exploration/exploitation dilemma, we use Dropout to represent the uncertainty of the network, which approximately equals to conduct Thompson sampling for efficient strategy exploration. Online evaluations show that the system can optimize the advertisers' advertising performance, and advertisers are willing to open the system, select and adopt the suggestions, which further increases the platform's revenue income. Simulation experiments based on Alibaba online bidding data prove that the agent can effectively optimize the adoption rate of advertisers, and Thompson sampling can better balance exploration and exploitation to further optimize the performance of the model.
* Accepted by KDD 2021
Natural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Apr 16, 2021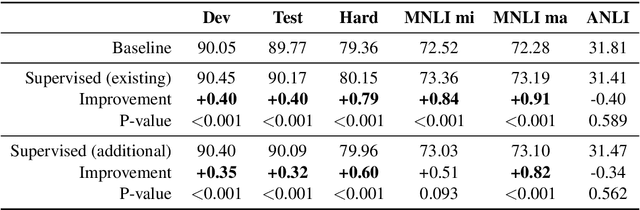
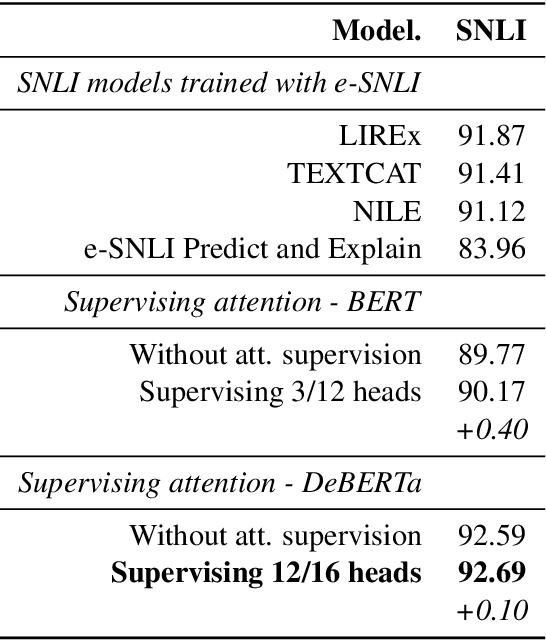
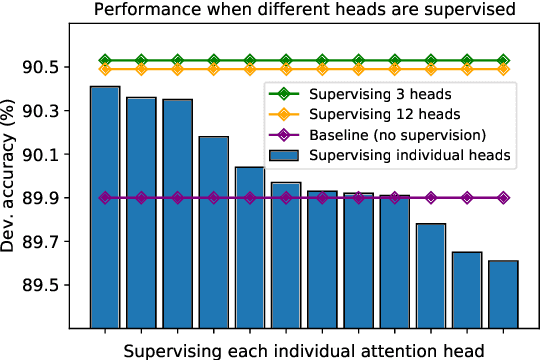
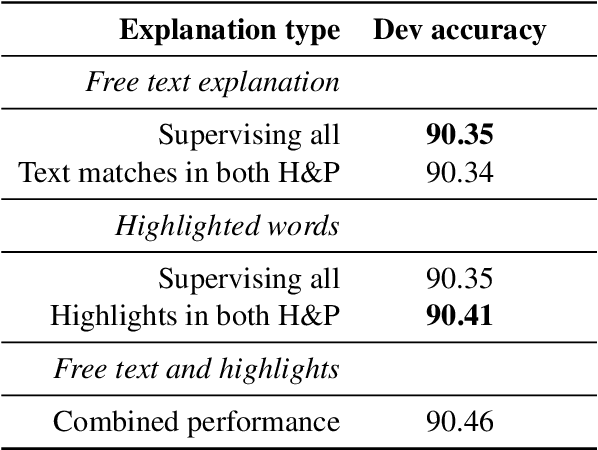
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.
Short-Term Flow-Based Bandwidth Forecasting using Machine Learning
Dec 03, 2020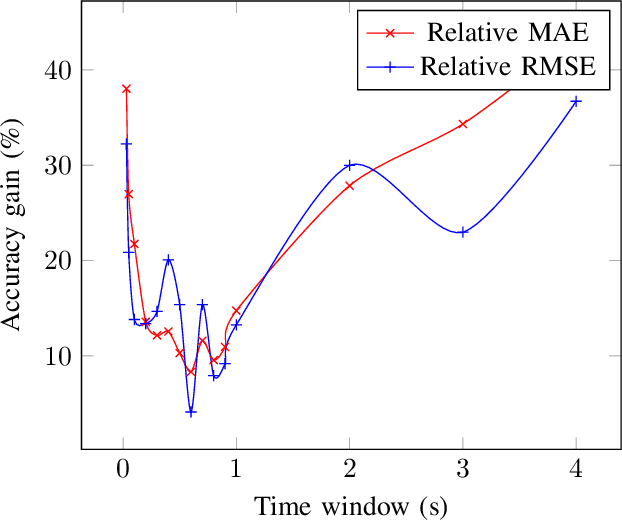
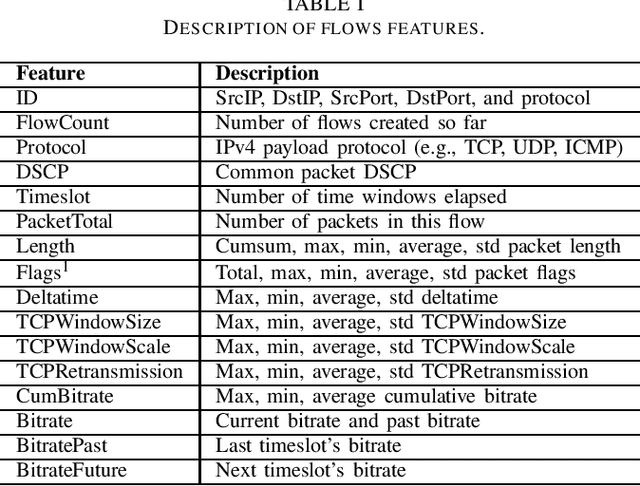
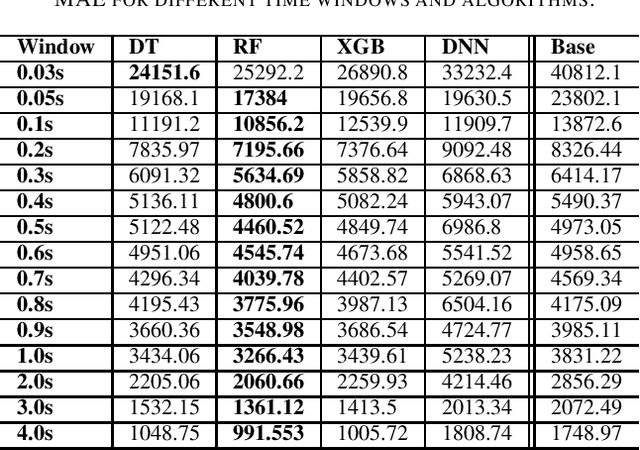
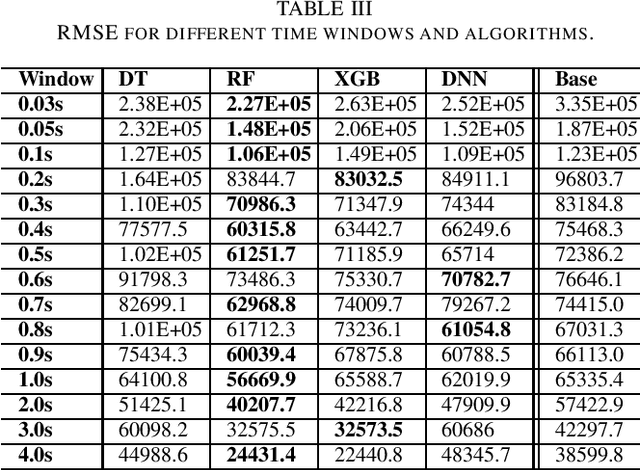
This paper proposes a novel framework to predict traffic flows' bandwidth ahead of time. Modern network management systems share a common issue: the network situation evolves between the moment the decision is made and the moment when actions (countermeasures) are applied. This framework converts packets from real-life traffic into flows containing relevant features. Machine learning models, including Decision Tree, Random Forest, XGBoost, and Deep Neural Network, are trained on these data to predict the bandwidth at the next time instance for every flow. Predictions can be fed to the management system instead of current flows bandwidth in order to take decisions on a more accurate network state. Experiments were performed on 981,774 flows and 15 different time windows (from 0.03s to 4s). They show that the Random Forest is the best performing and most reliable model, with a predictive performance consistently better than relying on the current bandwidth (+19.73% in mean absolute error and +18.00% in root mean square error). Experimental results indicate that this framework can help network management systems to take more informed decisions using a predicted network state.
Contour Proposal Networks for Biomedical Instance Segmentation
Apr 07, 2021
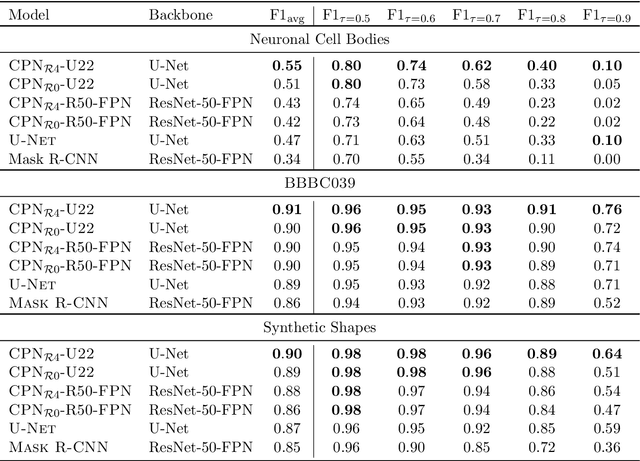


We present a conceptually simple framework for object instance segmentation called Contour Proposal Network (CPN), which detects possibly overlapping objects in an image while simultaneously fitting closed object contours using an interpretable, fixed-sized representation based on Fourier Descriptors. The CPN can incorporate state of the art object detection architectures as backbone networks into a single-stage instance segmentation model that can be trained end-to-end. We construct CPN models with different backbone networks, and apply them to instance segmentation of cells in datasets from different modalities. In our experiments, we show CPNs that outperform U-Nets and Mask R-CNNs in instance segmentation accuracy, and present variants with execution times suitable for real-time applications. The trained models generalize well across different domains of cell types. Since the main assumption of the framework are closed object contours, it is applicable to a wide range of detection problems also outside the biomedical domain. An implementation of the model architecture in PyTorch is freely available.
Towards an Adaptive Dynamic Mode Decomposition
Dec 11, 2020
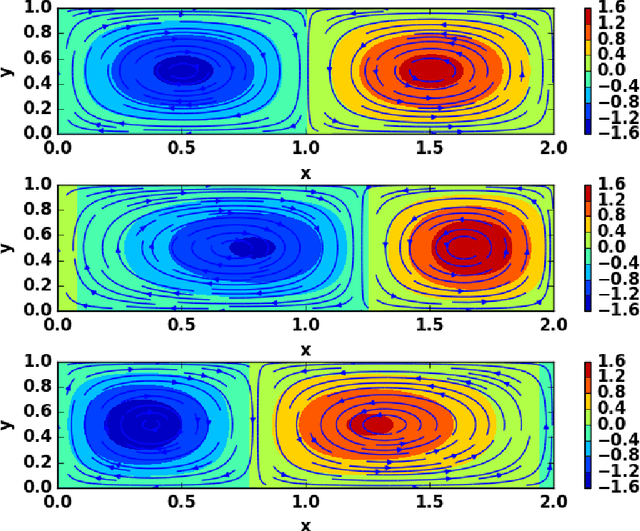

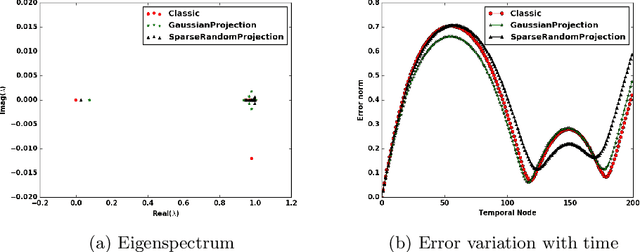
Dynamic Mode Decomposition (DMD) is a data based modeling tool that identifies a matrix to map a quantity at some time instant to the same quantity in future. We design a new version which we call Adaptive Dynamic Mode Decomposition (ADMD) that utilizes time delay coordinates, projection methods and filters as per the nature of the data to create a model for the available problem. Filters are very effective in reducing the rank of high-dimensional dataset. We have incorporated 'discrete Fourier transform' and 'augmented lagrangian multiplier' as filters in our method. The proposed ADMD is tested on several datasets of varying complexities and its performance appears to be promising.
Resilient Cooperative Adaptive Cruise Control for Autonomous Vehicles Using Machine Learning
Mar 18, 2021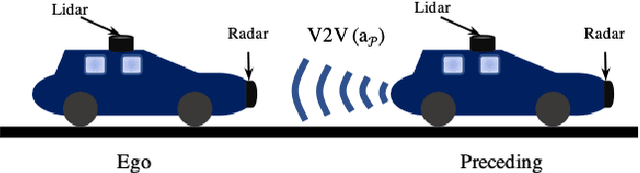
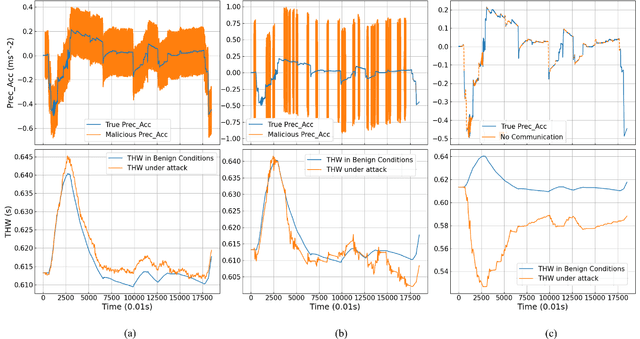
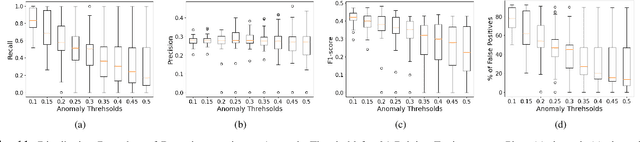
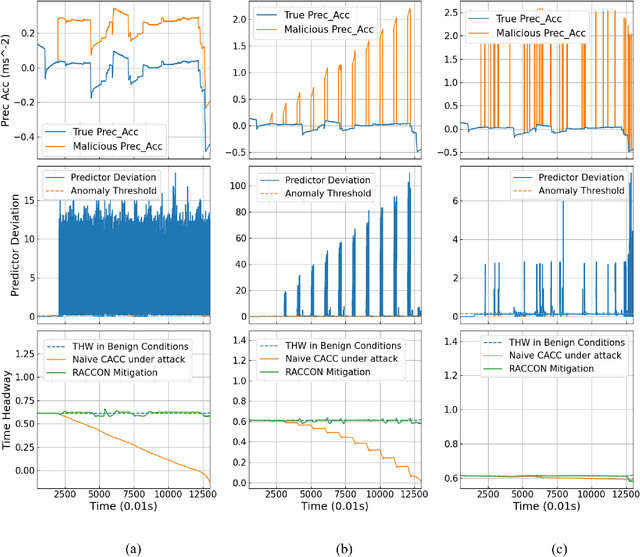
Cooperative Adaptive Cruise Control (CACC) is a fundamental connected vehicle application that extends Adaptive Cruise Control by exploiting vehicle-to-vehicle (V2V) communication. CACC is a crucial ingredient for numerous autonomous vehicle functionalities including platooning, distributed route management, etc. Unfortunately, malicious V2V communications can subvert CACC, leading to string instability and road accidents. In this paper, we develop a novel resiliency infrastructure, RACCON, for detecting and mitigating V2V attacks on CACC. RACCON uses machine learning to develop an on-board prediction model that captures anomalous vehicular responses and performs mitigation in real time. RACCON-enabled vehicles can exploit the high efficiency of CACC without compromising safety, even under potentially adversarial scenarios. We present extensive experimental evaluation to demonstrate the efficacy of RACCON.
Including Sparse Production Knowledge into Variational Autoencoders to Increase Anomaly Detection Reliability
Mar 24, 2021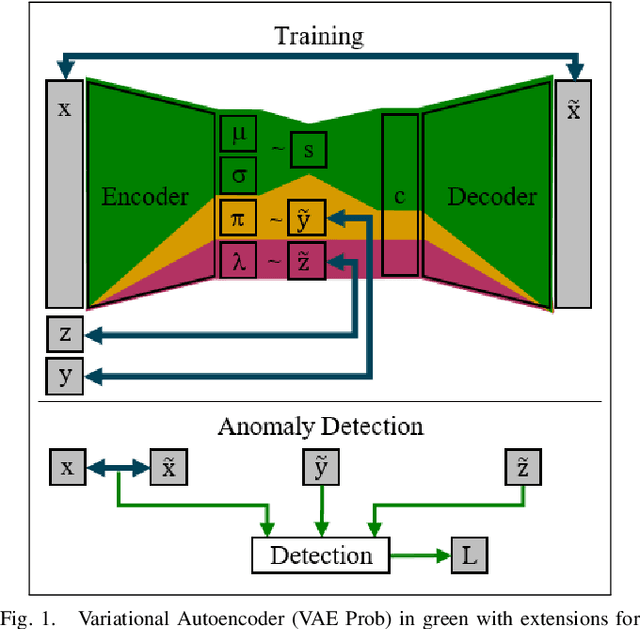
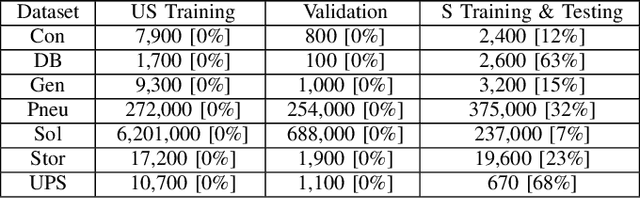
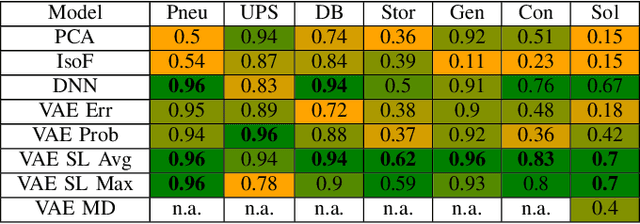
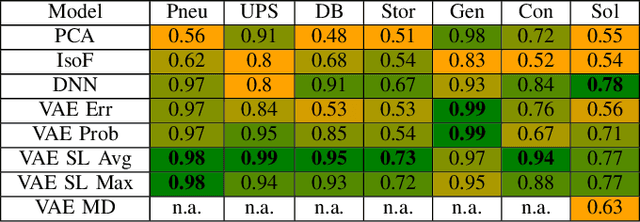
Digitalization leads to data transparency for production systems that we can benefit from with data-driven analysis methods like neural networks. For example, automated anomaly detection enables saving resources and optimizing the production. We study using rarely occurring information about labeled anomalies into Variational Autoencoder neural network structures to overcome information deficits of supervised and unsupervised approaches. This method outperforms all other models in terms of accuracy, precision, and recall. We evaluate the following methods: Principal Component Analysis, Isolation Forest, Classifying Neural Networks, and Variational Autoencoders on seven time series datasets to find the best performing detection methods. We extend this idea to include more infrequently occurring meta information about production processes. This use of sparse labels, both of anomalies or production data, allows to harness any additional information available for increasing anomaly detection performance.