 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Why Machine Learning Integrated Patient Flow Simulation?
Apr 16, 2021
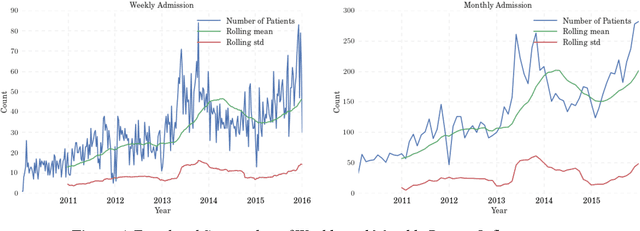
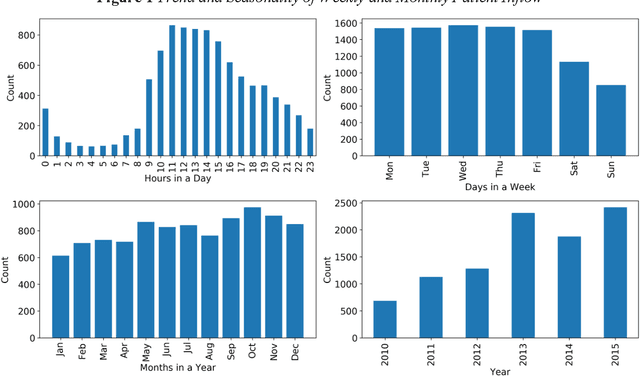
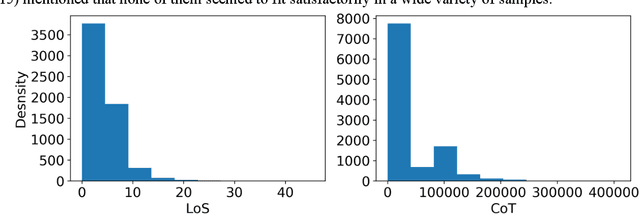
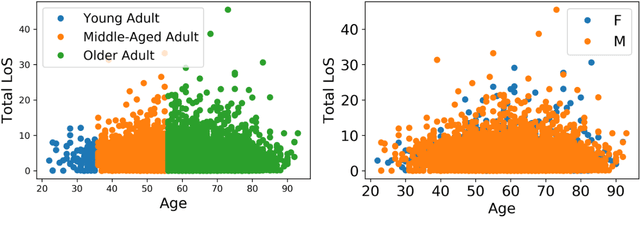
Patient flow analysis can be studied from a clinical and or operational perspective using simulation. Traditional statistical methods such as stochastic distribution methods have been used to construct patient flow simulation submodels such as patient inflow, Length of Stay (LoS), Cost of Treatment (CoT) and Clinical Pathway (CP) models. However, patient inflow demonstrates seasonality, trend and variation over time. LoS, CoT and CP are significantly determined by attributes of patients and clinical and laboratory test results. For this reason, patient flow simulation models constructed using traditional statistical methods are criticized for ignoring heterogeneity and their contribution to personalized and value based healthcare. On the other hand, machine learning methods have proven to be efficient to study and predict admission rate, LoS, CoT, and CP. This paper, hence, describes why coupling machine learning with patient flow simulation is important and proposes a conceptual architecture that shows how to integrate machine learning with patient flow simulation.
* Proceedings of the Operational Research Society Simulation Workshop 2021 (SW21)
CITIES: Contextual Inference of Tail-Item Embeddings for Sequential Recommendation
May 23, 2021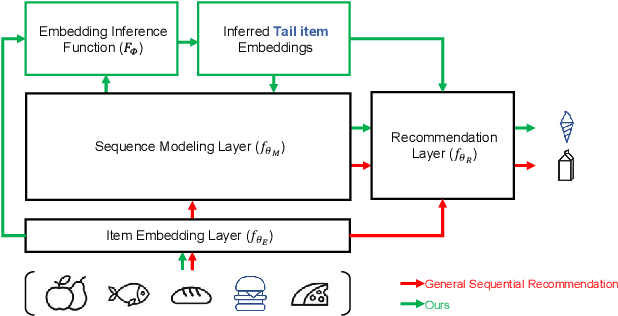
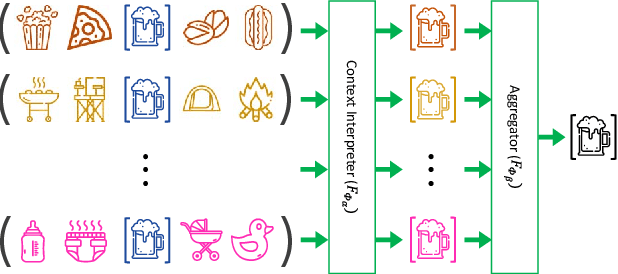
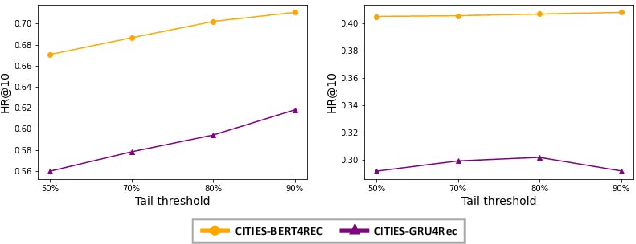
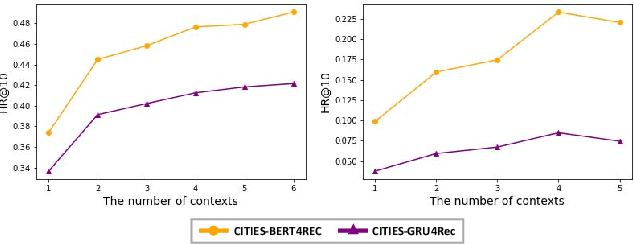
Sequential recommendation techniques provide users with product recommendations fitting their current preferences by handling dynamic user preferences over time. Previous studies have focused on modeling sequential dynamics without much regard to which of the best-selling products (i.e., head items) or niche products (i.e., tail items) should be recommended. We scrutinize the structural reason for why tail items are barely served in the current sequential recommendation model, which consists of an item-embedding layer, a sequence-modeling layer, and a recommendation layer. Well-designed sequence-modeling and recommendation layers are expected to naturally learn suitable item embeddings. However, tail items are likely to fall short of this expectation because the current model structure is not suitable for learning high-quality embeddings with insufficient data. Thus, tail items are rarely recommended. To eliminate this issue, we propose a framework called CITIES, which aims to enhance the quality of the tail-item embeddings by training an embedding-inference function using multiple contextual head items so that the recommendation performance improves for not only the tail items but also for the head items. Moreover, our framework can infer new-item embeddings without an additional learning process. Extensive experiments on two real-world datasets show that applying CITIES to the state-of-the-art methods improves recommendation performance for both tail and head items. We conduct an additional experiment to verify that CITIES can infer suitable new-item embeddings as well.
Expressing and Exploiting the Common Subgoal Structure of Classical Planning Domains Using Sketches: Extended Version
May 10, 2021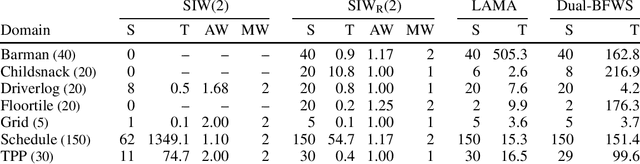
Width-based planning methods exploit the use of conjunctive goals for decomposing problems into subproblems of low width. However, algorithms like SIW fail when the goal is not serializable. In this work, we address this limitation of SIW by using a simple but powerful language for expressing problem decompositions introduced recently by Bonet and Geffner, called policy sketches. A policy sketch R consists of a set of Boolean and numerical features and a set of sketch rules that express how the values of these features are supposed to change. Like general policies, policy sketches are domain general, but unlike policies, the changes captured by sketch rules do not need to be achieved in a single step. We show that many planning domains that cannot be solved by SIW are provably solvable in low polynomial time with the SIW_R algorithm, the version of SIW that employs user-provided policy sketches. Policy sketches are thus shown to be a powerful language for expressing domain-specific knowledge in a simple and compact way and a convenient alternative to languages such as HTNs or temporal logics. Furthermore, policy sketches make it easy to express general problem decompositions and prove key properties like their complexity and width.
Projection-free Graph-based Classifier Learning using Gershgorin Disc Perfect Alignment
Jun 03, 2021
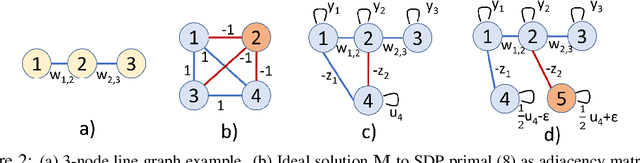
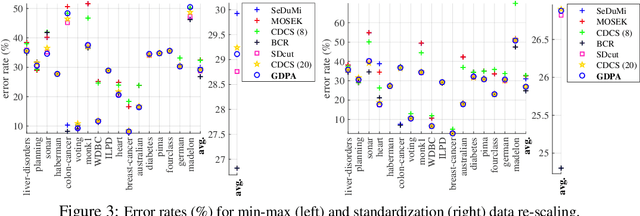
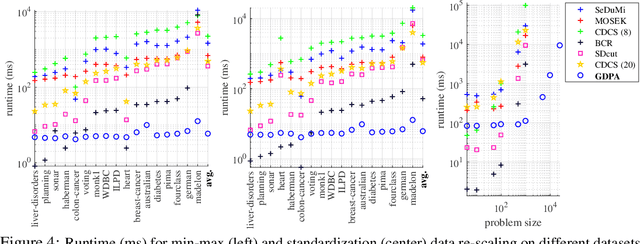
In semi-supervised graph-based binary classifier learning, a subset of known labels $\hat{x}_i$ are used to infer unknown labels, assuming that the label signal $x$ is smooth with respect to a similarity graph specified by a Laplacian matrix. When restricting labels $x_i$ to binary values, the problem is NP-hard. While a conventional semi-definite programming (SDP) relaxation can be solved in polynomial time using, for example, the alternating direction method of multipliers (ADMM), the complexity of iteratively projecting a candidate matrix $M$ onto the positive semi-definite (PSD) cone ($M \succeq 0$) remains high. In this paper, leveraging a recent linear algebraic theory called Gershgorin disc perfect alignment (GDPA), we propose a fast projection-free method by solving a sequence of linear programs (LP) instead. Specifically, we first recast the SDP relaxation to its SDP dual, where a feasible solution $H \succeq 0$ can be interpreted as a Laplacian matrix corresponding to a balanced signed graph sans the last node. To achieve graph balance, we split the last node into two that respectively contain the original positive and negative edges, resulting in a new Laplacian $\bar{H}$. We repose the SDP dual for solution $\bar{H}$, then replace the PSD cone constraint $\bar{H} \succeq 0$ with linear constraints derived from GDPA -- sufficient conditions to ensure $\bar{H}$ is PSD -- so that the optimization becomes an LP per iteration. Finally, we extract predicted labels from our converged LP solution $\bar{H}$. Experiments show that our algorithm enjoyed a $40\times$ speedup on average over the next fastest scheme while retaining comparable label prediction performance.
Overfitting in Bayesian Optimization: an empirical study and early-stopping solution
Apr 16, 2021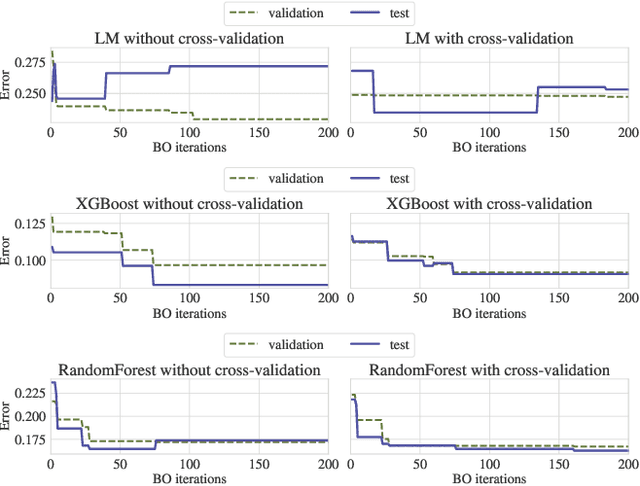
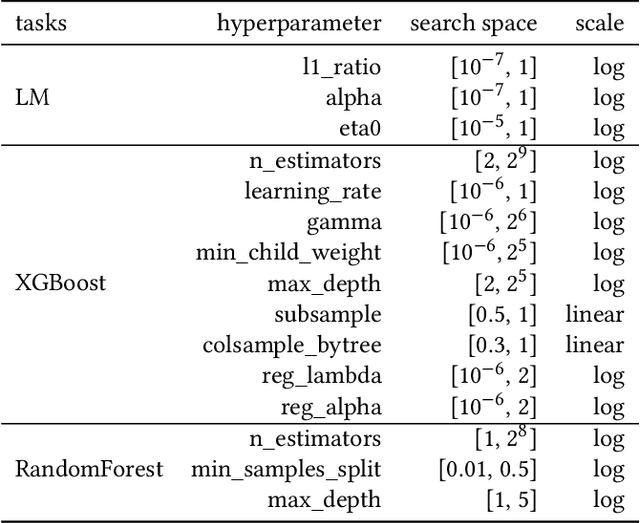
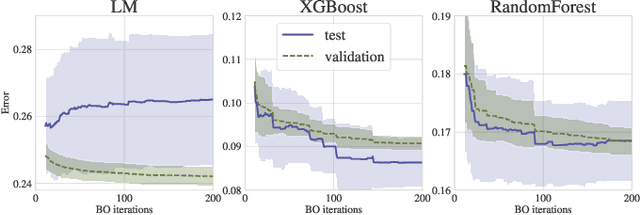
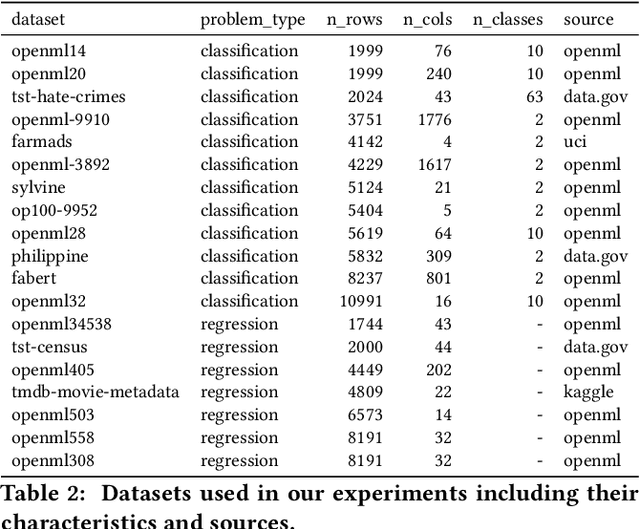
Bayesian Optimization (BO) is a successful methodology to tune the hyperparameters of machine learning algorithms. The user defines a metric of interest, such as the validation error, and BO finds the optimal hyperparameters that minimize it. However, the metric improvements on the validation set may not translate to the test set, especially on small datasets. In other words, BO can overfit. While cross-validation mitigates this, it comes with high computational cost. In this paper, we carry out the first systematic investigation of overfitting in BO and demonstrate that this is a serious yet often overlooked concern in practice. We propose the first problem-adaptive and interpretable criterion to early stop BO, reducing overfitting while mitigating the cost of cross-validation. Experimental results on real-world hyperparameter optimization tasks show that our approach can substantially reduce compute time with little to no loss of test accuracy,demonstrating a clear practical advantage over existing techniques.
FCCDN: Feature Constraint Network for VHR Image Change Detection
May 23, 2021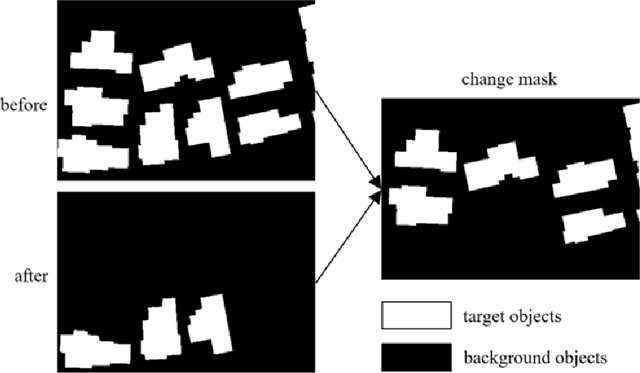

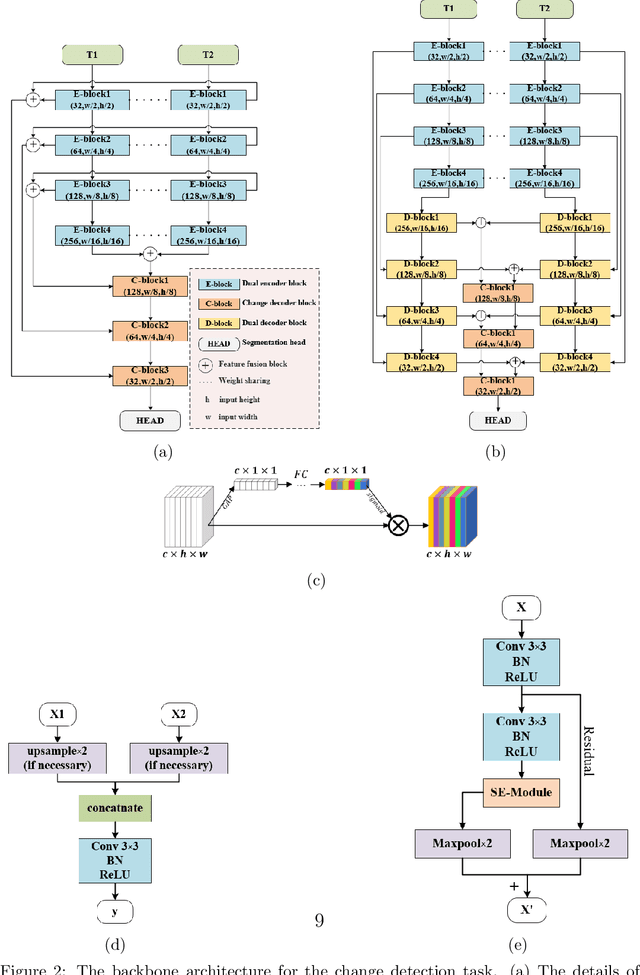
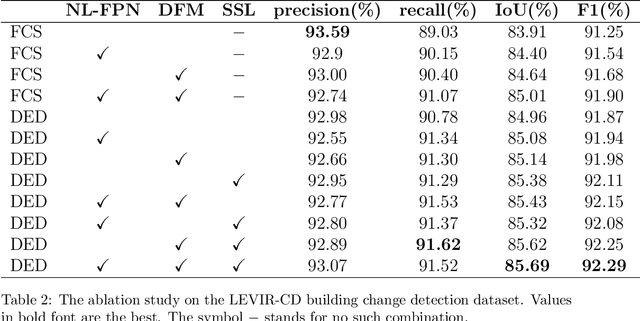
Change detection is the process of identifying pixel-wise differences of bi-temporal co-registered images. It is of great significance to Earth observation. Recently, with the emerging of deep learning (DL), deep convolutional neural networks (CNNs) based methods have shown their power and feasibility in the field of change detection. However, there is still a lack of effective supervision for change feature learning. In this work, a feature constraint change detection network (FCCDN) is proposed. We constrain features both on bi-temporal feature extraction and feature fusion. More specifically, we propose a dual encoder-decoder network backbone for the change detection task. At the center of the backbone, we design a non-local feature pyramid network to extract and fuse multi-scale features. To fuse bi-temporal features in a robust way, we build a dense connection-based feature fusion module. Moreover, a self-supervised learning-based strategy is proposed to constrain feature learning. Based on FCCDN, we achieve state-of-the-art performance on two building change detection datasets (LEVIR-CD and WHU). On the LEVIR-CD dataset, we achieve IoU of 0.8569 and F1 score of 0.9229. On the WHU dataset, we achieve IoU of 0.8820 and F1 score of 0.9373. Moreover, we, for the first time, achieve the acquire of accurate bi-temporal semantic segmentation results without using semantic segmentation labels. It is vital for the application of change detection because it saves the cost of labeling.
Equivariant neural networks for inverse problems
Feb 23, 2021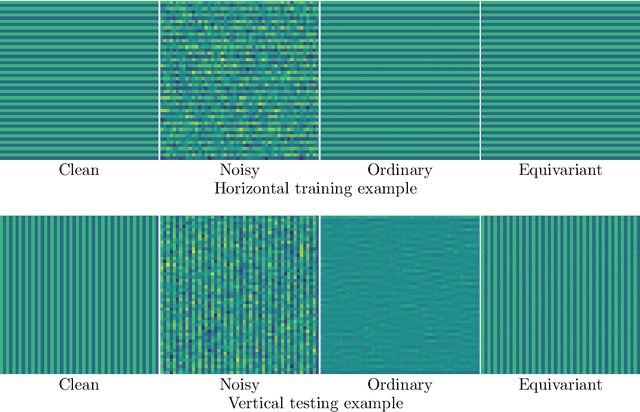

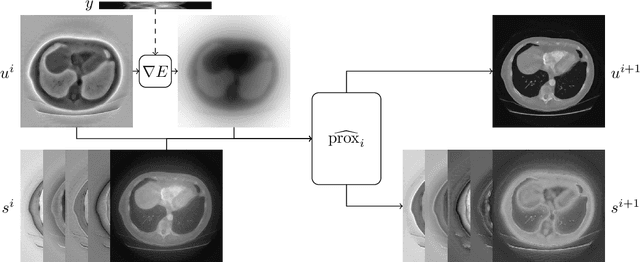
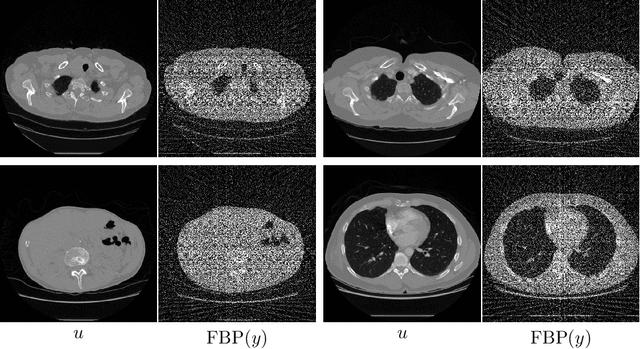
In recent years the use of convolutional layers to encode an inductive bias (translational equivariance) in neural networks has proven to be a very fruitful idea. The successes of this approach have motivated a line of research into incorporating other symmetries into deep learning methods, in the form of group equivariant convolutional neural networks. Much of this work has been focused on roto-translational symmetry of $\mathbf R^d$, but other examples are the scaling symmetry of $\mathbf R^d$ and rotational symmetry of the sphere. In this work, we demonstrate that group equivariant convolutional operations can naturally be incorporated into learned reconstruction methods for inverse problems that are motivated by the variational regularisation approach. Indeed, if the regularisation functional is invariant under a group symmetry, the corresponding proximal operator will satisfy an equivariance property with respect to the same group symmetry. As a result of this observation, we design learned iterative methods in which the proximal operators are modelled as group equivariant convolutional neural networks. We use roto-translationally equivariant operations in the proposed methodology and apply it to the problems of low-dose computerised tomography reconstruction and subsampled magnetic resonance imaging reconstruction. The proposed methodology is demonstrated to improve the reconstruction quality of a learned reconstruction method with a little extra computational cost at training time but without any extra cost at test time.
Speaker Diarization using Two-pass Leave-One-Out Gaussian PLDA Clustering of DNN Embeddings
Apr 07, 2021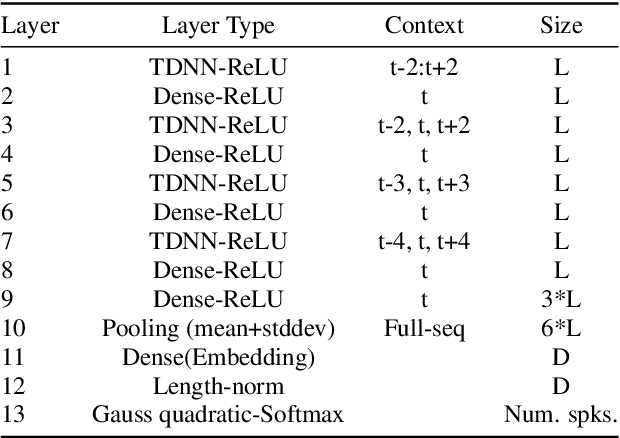
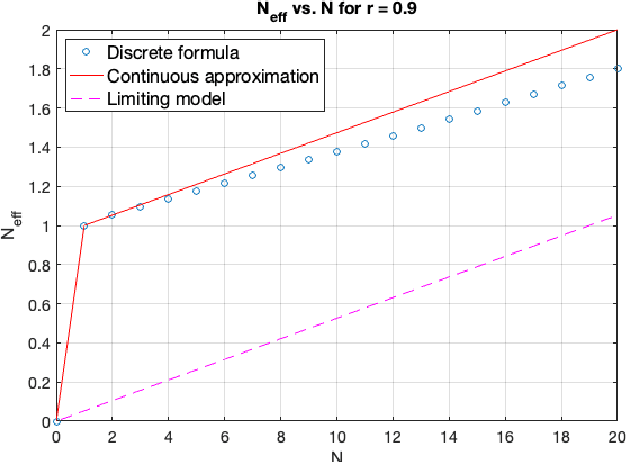
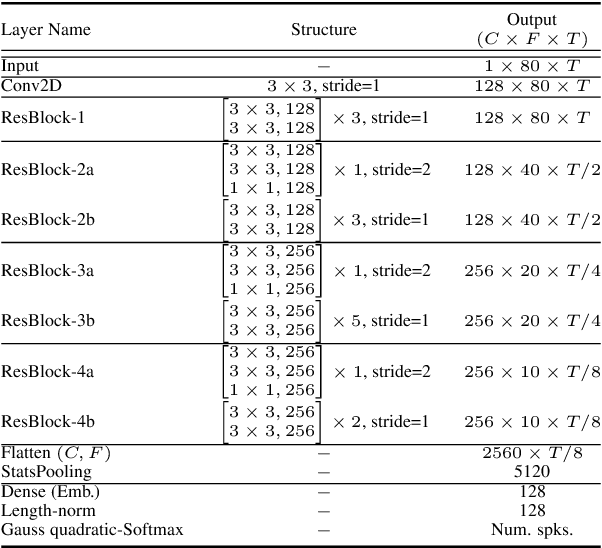
Many modern systems for speaker diarization, such as the recently-developed VBx approach, rely on clustering of DNN speaker embeddings followed by resegmentation. Two problems with this approach are that the DNN is not directly optimized for this task, and the parameters need significant retuning for different applications. We have recently presented progress in this direction with a Leave-One-Out Gaussian PLDA (LGP) clustering algorithm and an approach to training the DNN such that embeddings directly optimize performance of this scoring method. This paper presents a new two-pass version of this system, where the second pass uses finer time resolution to significantly improve overall performance. For the Callhome corpus, we achieve the first published error rate below 4\% without any task-dependent parameter tuning. We also show significant progress towards a robust single solution for multiple diarization tasks.
Learning Functional Priors and Posteriors from Data and Physics
Jun 08, 2021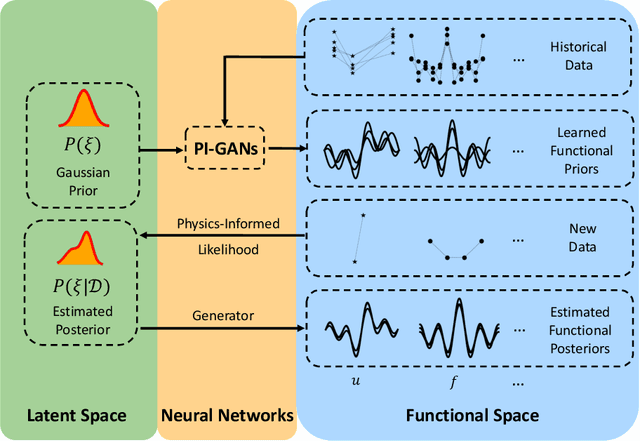
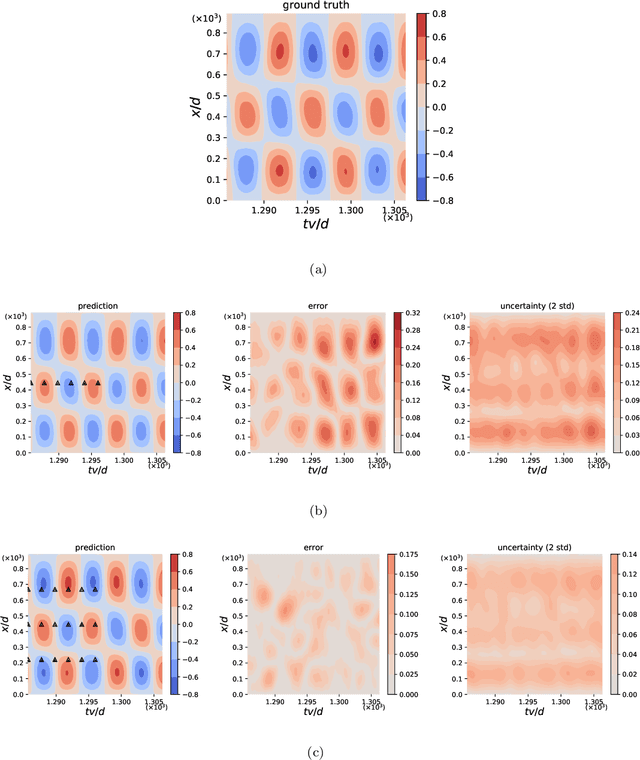
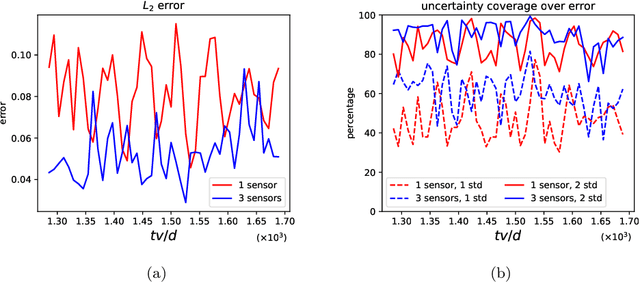
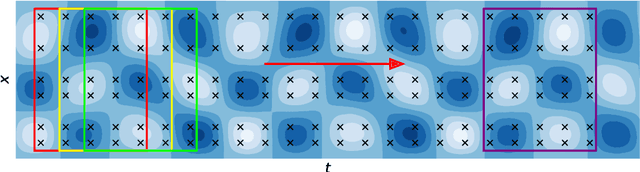
We develop a new Bayesian framework based on deep neural networks to be able to extrapolate in space-time using historical data and to quantify uncertainties arising from both noisy and gappy data in physical problems. Specifically, the proposed approach has two stages: (1) prior learning and (2) posterior estimation. At the first stage, we employ the physics-informed Generative Adversarial Networks (PI-GAN) to learn a functional prior either from a prescribed function distribution, e.g., Gaussian process, or from historical data and physics. At the second stage, we employ the Hamiltonian Monte Carlo (HMC) method to estimate the posterior in the latent space of PI-GANs. In addition, we use two different approaches to encode the physics: (1) automatic differentiation, used in the physics-informed neural networks (PINNs) for scenarios with explicitly known partial differential equations (PDEs), and (2) operator regression using the deep operator network (DeepONet) for PDE-agnostic scenarios. We then test the proposed method for (1) meta-learning for one-dimensional regression, and forward/inverse PDE problems (combined with PINNs); (2) PDE-agnostic physical problems (combined with DeepONet), e.g., fractional diffusion as well as saturated stochastic (100-dimensional) flows in heterogeneous porous media; and (3) spatial-temporal regression problems, i.e., inference of a marine riser displacement field. The results demonstrate that the proposed approach can provide accurate predictions as well as uncertainty quantification given very limited scattered and noisy data, since historical data could be available to provide informative priors. In summary, the proposed method is capable of learning flexible functional priors, and can be extended to big data problems using stochastic HMC or normalizing flows since the latent space is generally characterized as low dimensional.
Detection and Prediction of Users Attitude Based on Real-Time and Batch Sentiment Analysis of Facebook Comments
Jun 08, 2019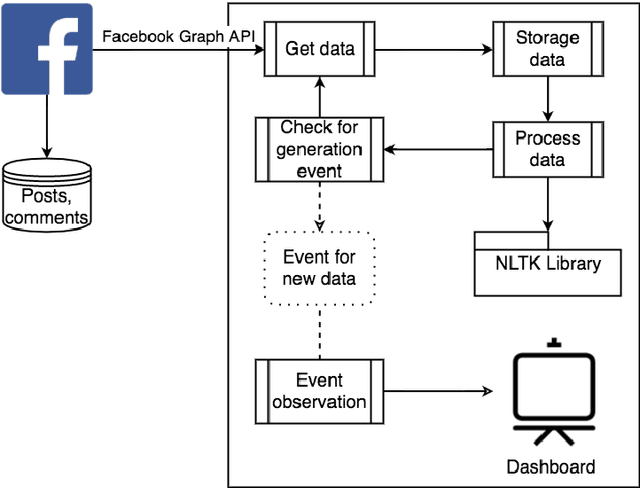
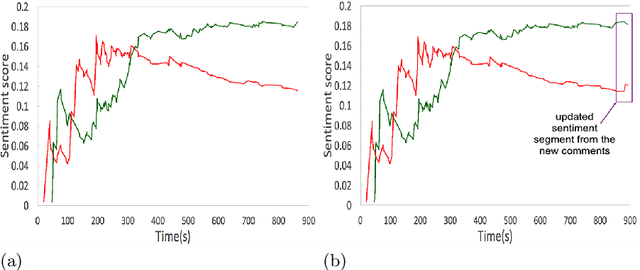
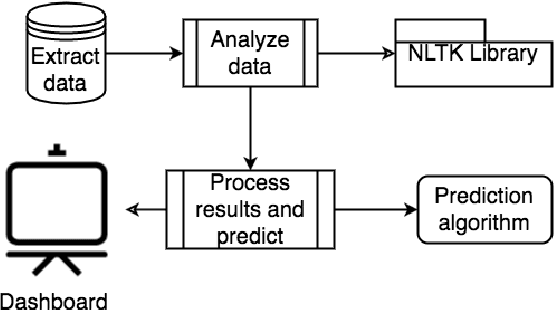
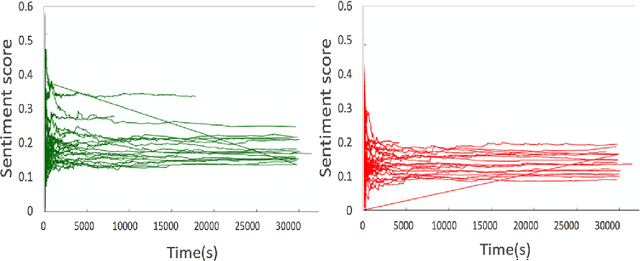
The most of the people have their account on social networks (e.g. Facebook, Vkontakte) where they express their attitude to different situations and events. Facebook provides only the positive mark as a like button and share. However, it is important to know the position of a certain user on posts even though the opinion is negative. Positive, negative and neutral attitude can be extracted from the comments of users. Overall information about positive, negative and neutral opinion can bring the understanding of how people react in a position. Moreover, it is important to know how attitude is changing during the time period. The contribution of the paper is a new method based on sentiment text analysis for detection and prediction negative and positive patterns for Facebook comments which combines (i) real-time sentiment text analysis for pattern discovery and (ii) batch data processing for creating opinion forecasting algorithm. To perform forecast we propose two-steps algorithm where: (i) patterns are clustered using unsupervised clustering techniques and (ii) trend prediction is performed based on finding the nearest pattern from the certain cluster. Case studies show the efficiency and accuracy (Avg. MAE = 0.008) of the proposed method and its practical applicability. Also, we discovered three types of users attitude patterns and described them.