 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Region Proposal Learning for Object Detection for Robotics
Nov 25, 2020
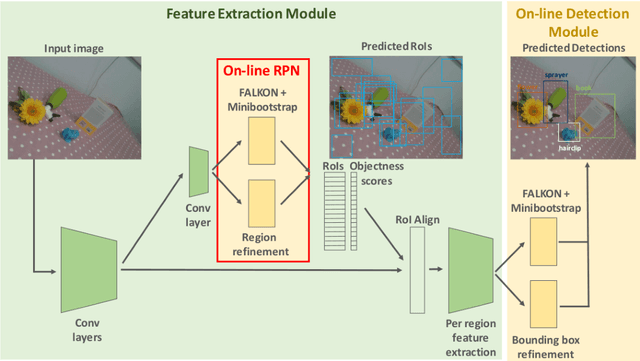
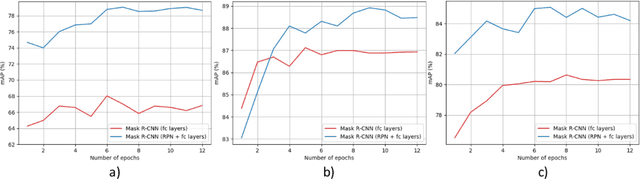
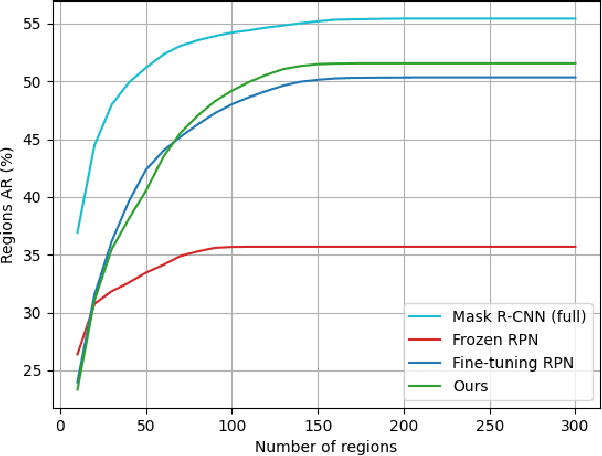
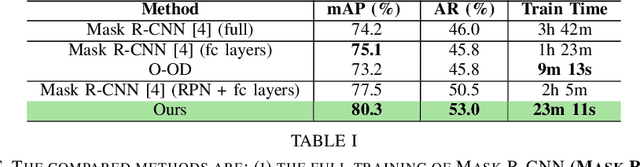
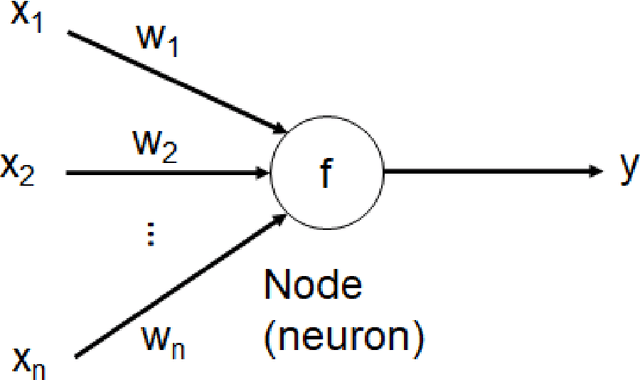
Object detection is a fundamental task for robots to operate in unstructured environments. Today, there are several deep learning algorithms that solve this task with remarkable performance. Unfortunately, training such systems requires several hours of GPU time. For robots, to successfully adapt to changes in the environment or learning new objects, it is also important that object detectors can be re-trained in a short amount of time. A recent method [1] proposes an architecture that leverages on the powerful representation of deep learning descriptors, while permitting fast adaptation time. Leveraging on the natural decomposition of the task in (i) regions candidate generation, (ii) feature extraction and (iii) regions classification, this method performs fast adaptation of the detector, by only re-training the classification layer. This shortens training time while maintaining state-of-the-art performance. In this paper, we firstly demonstrate that a further boost in accuracy can be obtained by adapting, in addition, the regions candidate generation on the task at hand. Secondly, we extend the object detection system presented in [1] with the proposed fast learning approach, showing experimental evidence on the improvement provided in terms of speed and accuracy on two different robotics datasets. The code to reproduce the experiments is publicly available on GitHub.
Learning Weakly Convex Sets in Metric Spaces
May 10, 2021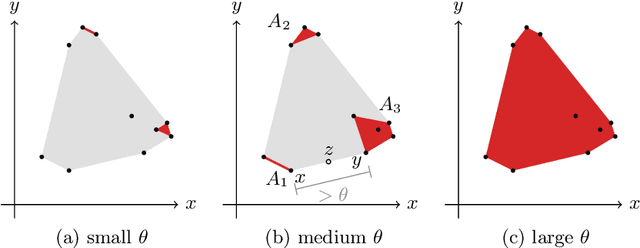
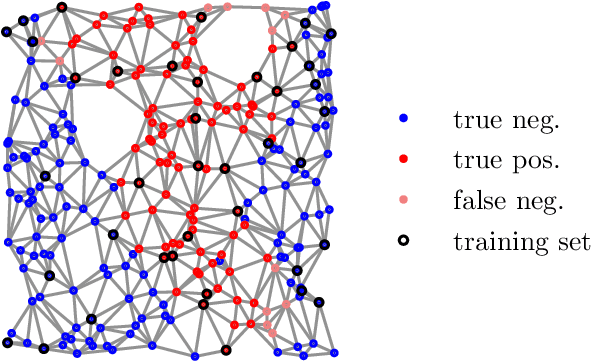
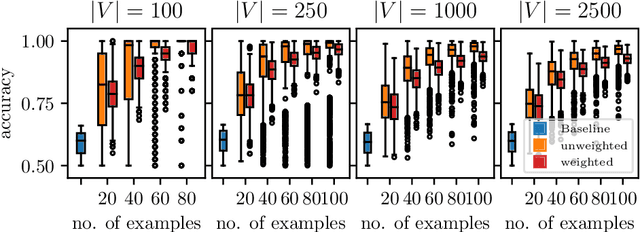
We introduce the notion of weak convexity in metric spaces, a generalization of ordinary convexity commonly used in machine learning. It is shown that weakly convex sets can be characterized by a closure operator and have a unique decomposition into a set of pairwise disjoint connected blocks. We give two generic efficient algorithms, an extensional and an intensional one for learning weakly convex concepts and study their formal properties. Our experimental results concerning vertex classification clearly demonstrate the excellent predictive performance of the extensional algorithm. Two non-trivial applications of the intensional algorithm to polynomial PAC-learnability are presented. The first one deals with learning $k$-convex Boolean functions, which are already known to be efficiently PAC-learnable. It is shown how to derive this positive result in a fairly easy way by the generic intensional algorithm. The second one is concerned with the Euclidean space equipped with the Manhattan distance. For this metric space, weakly convex sets are a union of pairwise disjoint axis-aligned hyperrectangles. We show that a weakly convex set that is consistent with a set of examples and contains a minimum number of hyperrectangles can be found in polynomial time. In contrast, this problem is known to be NP-complete if the hyperrectangles may be overlapping.
Data Distillation for Text Classification
Apr 17, 2021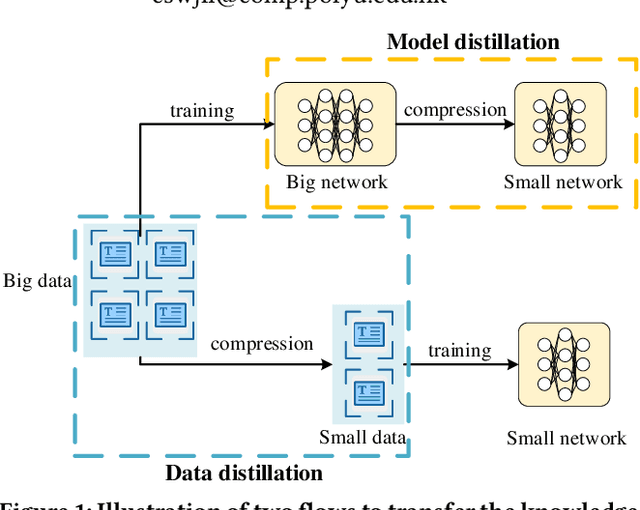
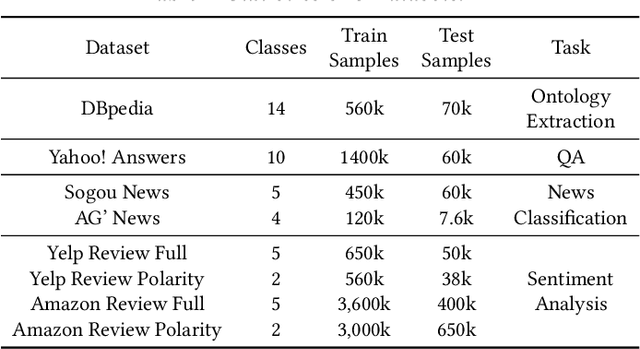
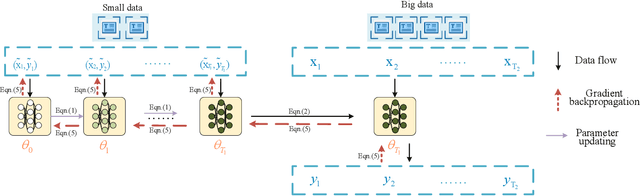

Deep learning techniques have achieved great success in many fields, while at the same time deep learning models are getting more complex and expensive to compute. It severely hinders the wide applications of these models. In order to alleviate this problem, model distillation emerges as an effective means to compress a large model into a smaller one without a significant drop in accuracy. In this paper, we study a related but orthogonal issue, data distillation, which aims to distill the knowledge from a large training dataset down to a smaller and synthetic one. It has the potential to address the large and growing neural network training problem based on the small dataset. We develop a novel data distillation method for text classification. We evaluate our method on eight benchmark datasets. The results that the distilled data with the size of 0.1% of the original text data achieves approximately 90% performance of the original is rather impressive.
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
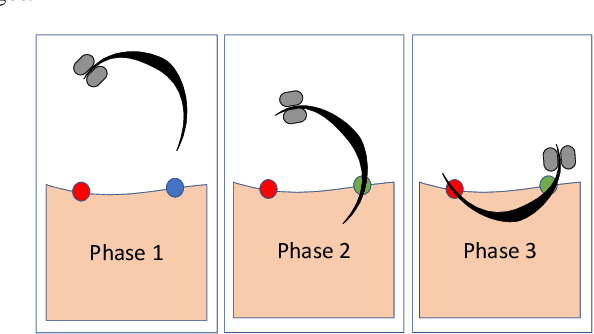
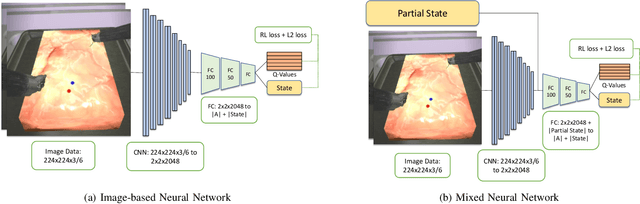
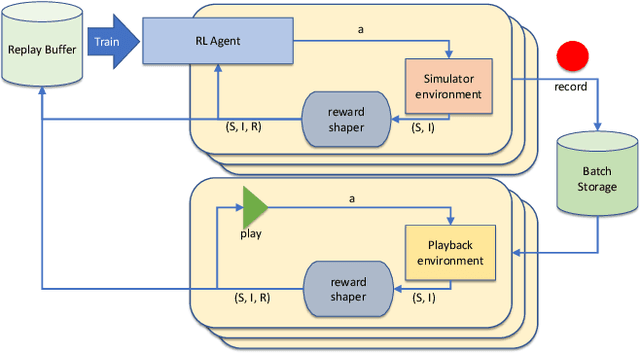
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.
Vector Neurons: A General Framework for SO(3)-Equivariant Networks
Apr 25, 2021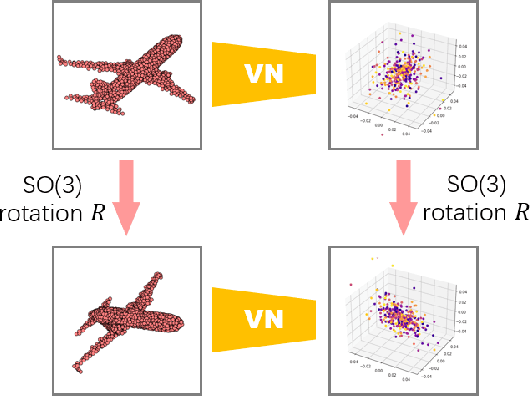
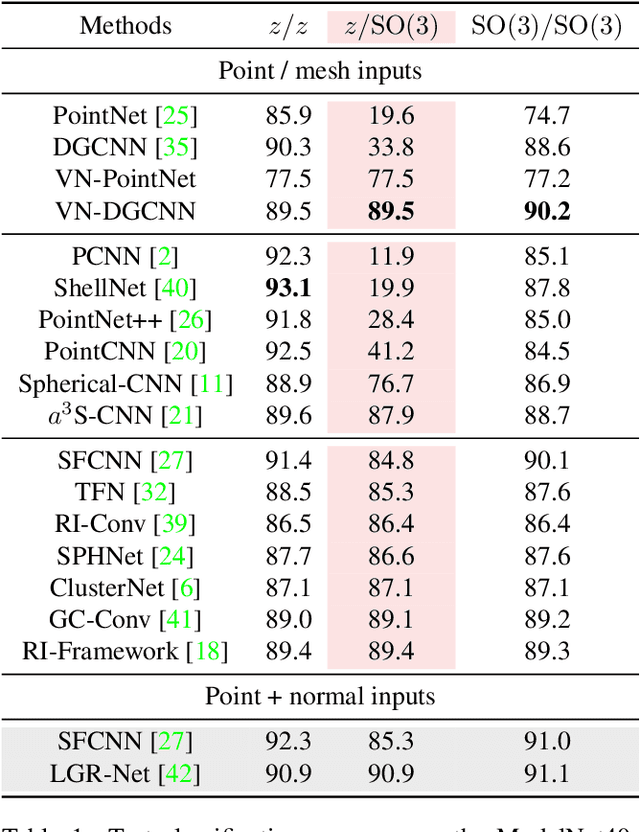
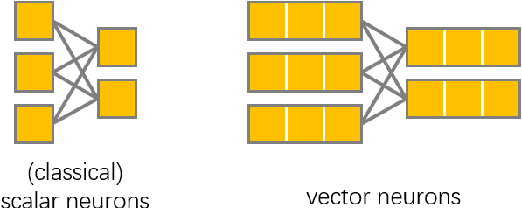
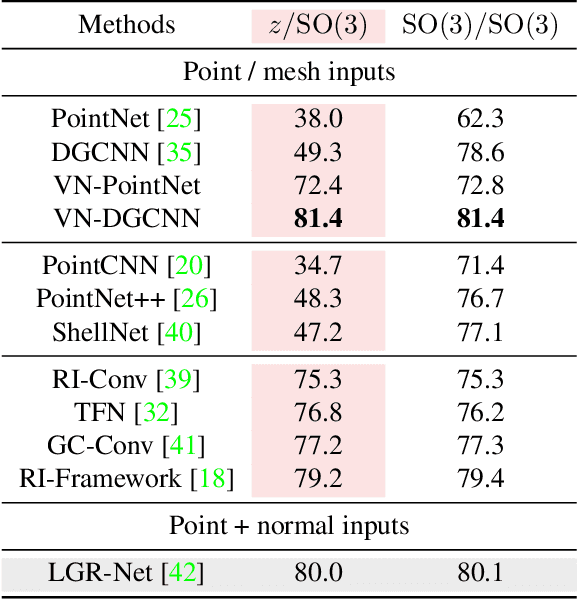
Invariance and equivariance to the rotation group have been widely discussed in the 3D deep learning community for pointclouds. Yet most proposed methods either use complex mathematical tools that may limit their accessibility, or are tied to specific input data types and network architectures. In this paper, we introduce a general framework built on top of what we call Vector Neuron representations for creating SO(3)-equivariant neural networks for pointcloud processing. Extending neurons from 1D scalars to 3D vectors, our vector neurons enable a simple mapping of SO(3) actions to latent spaces thereby providing a framework for building equivariance in common neural operations -- including linear layers, non-linearities, pooling, and normalizations. Due to their simplicity, vector neurons are versatile and, as we demonstrate, can be incorporated into diverse network architecture backbones, allowing them to process geometry inputs in arbitrary poses. Despite its simplicity, our method performs comparably well in accuracy and generalization with other more complex and specialized state-of-the-art methods on classification and segmentation tasks. We also show for the first time a rotation equivariant reconstruction network.
Doubly Robust Off-Policy Actor-Critic: Convergence and Optimality
Feb 23, 2021
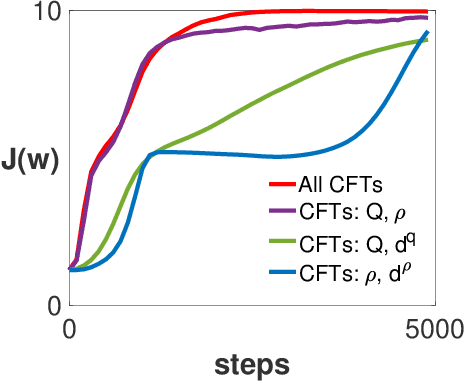
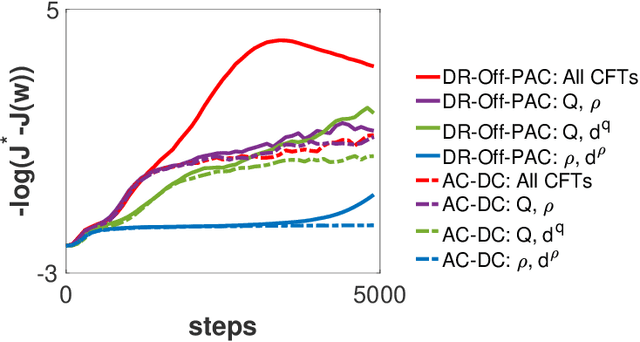
Designing off-policy reinforcement learning algorithms is typically a very challenging task, because a desirable iteration update often involves an expectation over an on-policy distribution. Prior off-policy actor-critic (AC) algorithms have introduced a new critic that uses the density ratio for adjusting the distribution mismatch in order to stabilize the convergence, but at the cost of potentially introducing high biases due to the estimation errors of both the density ratio and value function. In this paper, we develop a doubly robust off-policy AC (DR-Off-PAC) for discounted MDP, which can take advantage of learned nuisance functions to reduce estimation errors. Moreover, DR-Off-PAC adopts a single timescale structure, in which both actor and critics are updated simultaneously with constant stepsize, and is thus more sample efficient than prior algorithms that adopt either two timescale or nested-loop structure. We study the finite-time convergence rate and characterize the sample complexity for DR-Off-PAC to attain an $\epsilon$-accurate optimal policy. We also show that the overall convergence of DR-Off-PAC is doubly robust to the approximation errors that depend only on the expressive power of approximation functions. To the best of our knowledge, our study establishes the first overall sample complexity analysis for a single time-scale off-policy AC algorithm.
Automated Biodesign Engineering by Abductive Meta-Interpretive Learning
May 17, 2021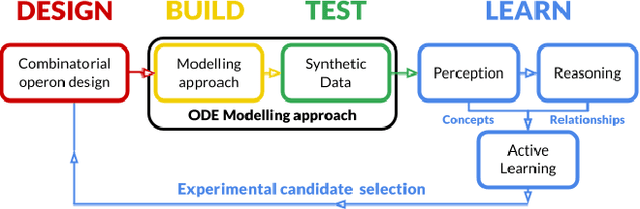
The application of Artificial Intelligence (AI) to synthetic biology will provide the foundation for the creation of a high throughput automated platform for genetic design, in which a learning machine is used to iteratively optimise the system through a design-build-test-learn (DBTL) cycle. However, mainstream machine learning techniques represented by deep learning lacks the capability to represent relational knowledge and requires prodigious amounts of annotated training data. These drawbacks strongly restrict AI's role in synthetic biology in which experimentation is inherently resource and time intensive. In this work, we propose an automated biodesign engineering framework empowered by Abductive Meta-Interpretive Learning ($Meta_{Abd}$), a novel machine learning approach that combines symbolic and sub-symbolic machine learning, to further enhance the DBTL cycle by enabling the learning machine to 1) exploit domain knowledge and learn human-interpretable models that are expressed by formal languages such as first-order logic; 2) simultaneously optimise the structure and parameters of the models to make accurate numerical predictions; 3) reduce the cost of experiments and effort on data annotation by actively generating hypotheses and examples. To verify the effectiveness of $Meta_{Abd}$, we have modelled a synthetic dataset for the production of proteins from a three gene operon in a microbial host, which represents a common synthetic biology problem.
Generic Itemset Mining Based on Reinforcement Learning
May 17, 2021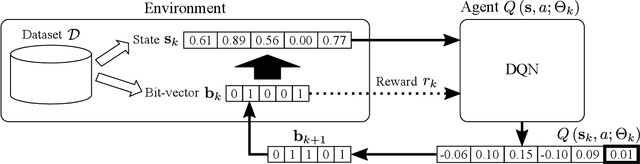

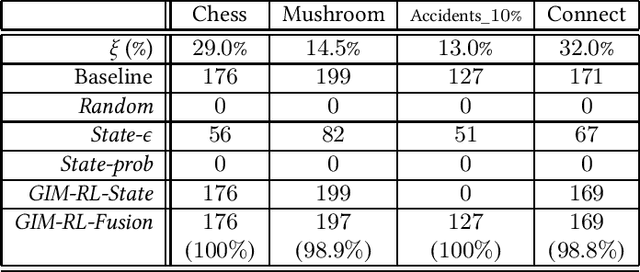
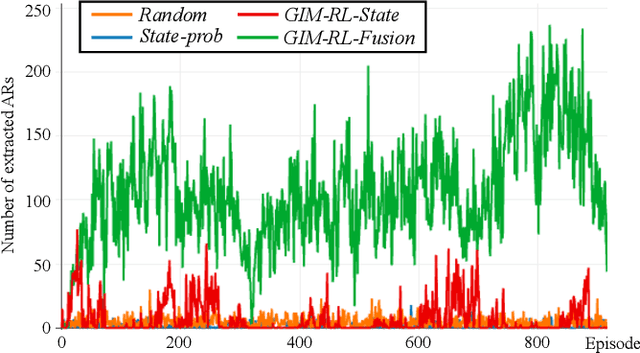
One of the biggest problems in itemset mining is the requirement of developing a data structure or algorithm, every time a user wants to extract a different type of itemsets. To overcome this, we propose a method, called Generic Itemset Mining based on Reinforcement Learning (GIM-RL), that offers a unified framework to train an agent for extracting any type of itemsets. In GIM-RL, the environment formulates iterative steps of extracting a target type of itemsets from a dataset. At each step, an agent performs an action to add or remove an item to or from the current itemset, and then obtains from the environment a reward that represents how relevant the itemset resulting from the action is to the target type. Through numerous trial-and-error steps where various rewards are obtained by diverse actions, the agent is trained to maximise cumulative rewards so that it acquires the optimal action policy for forming as many itemsets of the target type as possible. In this framework, an agent for extracting any type of itemsets can be trained as long as a reward suitable for the type can be defined. The extensive experiments on mining high utility itemsets, frequent itemsets and association rules show the general effectiveness and one remarkable potential (agent transfer) of GIM-RL. We hope that GIM-RL opens a new research direction towards learning-based itemset mining.
Artificial Neural Network Modeling for Airline Disruption Management
May 03, 2021

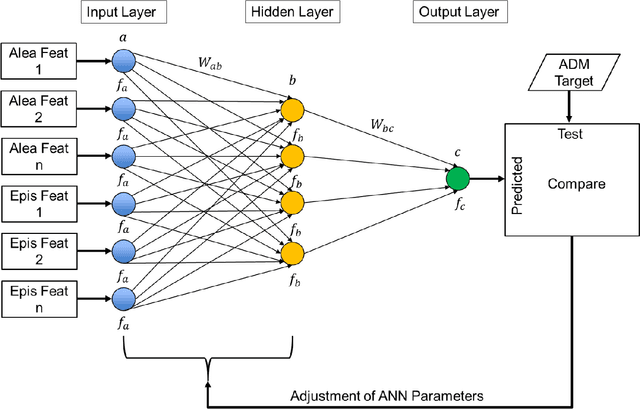
Since the 1970s, most airlines have incorporated computerized support for managing disruptions during flight schedule execution. However, existing platforms for airline disruption management (ADM) employ monolithic system design methods that rely on the creation of specific rules and requirements through explicit optimization routines, before a system that meets the specifications is designed. Thus, current platforms for ADM are unable to readily accommodate additional system complexities resulting from the introduction of new capabilities, such as the introduction of unmanned aerial systems (UAS), operations and infrastructure, to the system. To this end, we use historical data on airline scheduling and operations recovery to develop a system of artificial neural networks (ANNs), which describe a predictive transfer function model (PTFM) for promptly estimating the recovery impact of disruption resolutions at separate phases of flight schedule execution during ADM. Furthermore, we provide a modular approach for assessing and executing the PTFM by employing a parallel ensemble method to develop generative routines that amalgamate the system of ANNs. Our modular approach ensures that current industry standards for tardiness in flight schedule execution during ADM are satisfied, while accurately estimating appropriate time-based performance metrics for the separate phases of flight schedule execution.
Improving Landslide Detection on SAR Data through Deep Learning
May 03, 2021
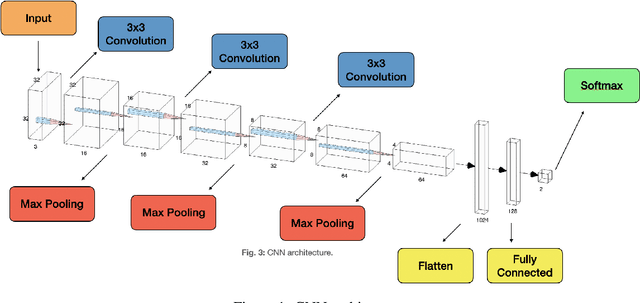

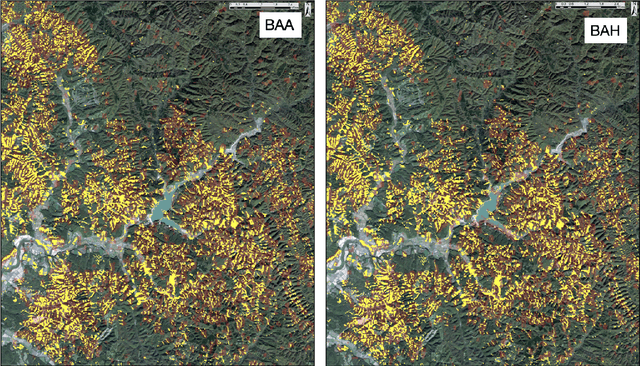
In this letter, we use deep-learning convolution neural networks (CNNs) to assess the landslide mapping and classification performances on optical images (from Sentinel-2) and SAR images (from Sentinel-1). The training and test zones used to independently evaluate the performance of the CNNs on different datasets are located in the eastern Iburi subprefecture in Hokkaido, where, at 03.08 local time (JST) on September 6, 2018, an Mw 6.6 earthquake triggered about 8000 coseismic landslides. We analyzed the conditions before and after the earthquake exploiting multi-polarization SAR as well as optical data by means of a CNN implemented in TensorFlow that points out the locations where the Landslide class is predicted as more likely. As expected, the CNN run on optical images proved itself excellent for the landslide detection task, achieving an overall accuracy of 99.20% while CNNs based on the combination of ground range detected (GRD) SAR data reached overall accuracies beyond 94%. Our findings show that the integrated use of SAR data may also allow for rapid mapping even during storms and under dense cloud cover and seems to provide comparable accuracy to classical optical change detection in landslide recognition and mapping.