 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Consumer Demand Modeling During COVID-19 Pandemic
May 03, 2021
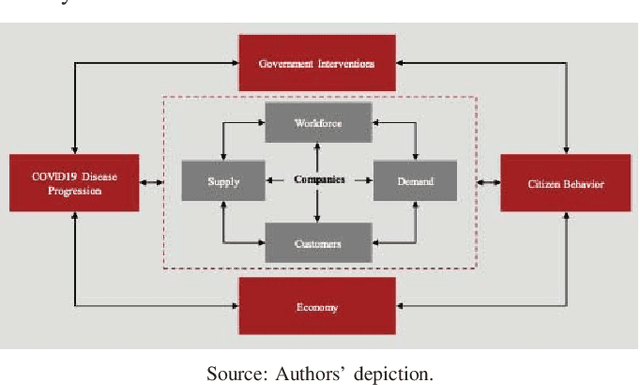
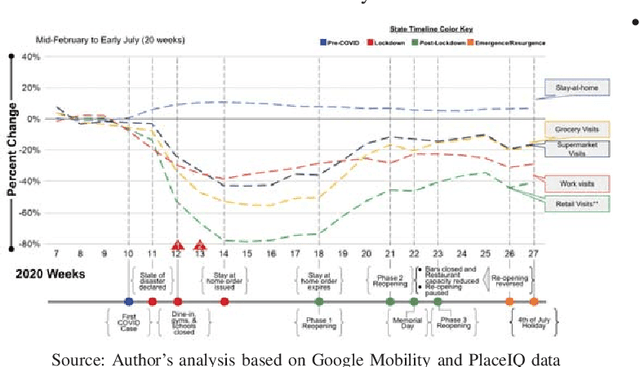
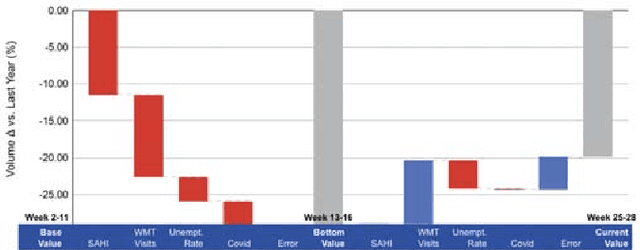
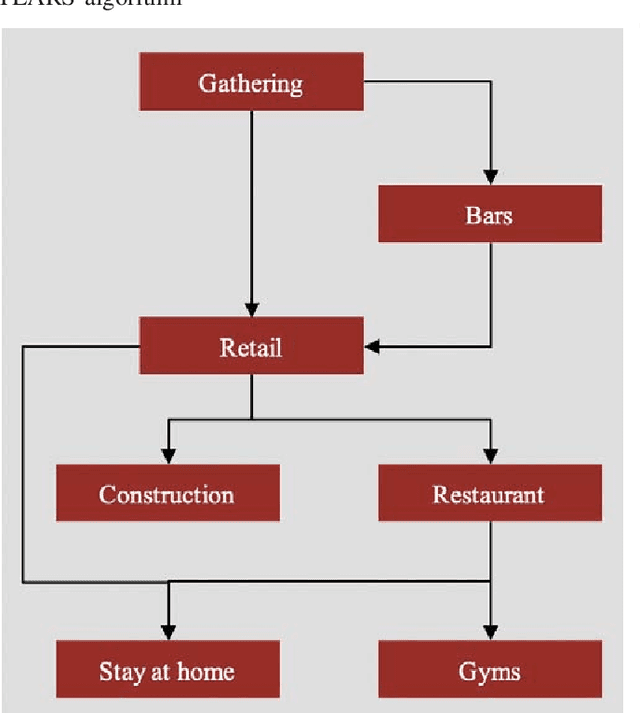
The current pandemic has introduced substantial uncertainty to traditional methods for demand planning. These uncertainties stem from the disease progression, government interventions, economy and consumer behavior. While most of the emerging literature on the pandemic has focused on disease progression, a few have focused on consequent regulations and their impact on individual behavior. The contributions of this paper include a quantitative behavior model of fear of COVID-19, impact of government interventions on consumer behavior, and impact of consumer behavior on consumer choice and hence demand for goods. It brings together multiple models for disease progression, consumer behavior and demand estimation-thus bridging the gap between disease progression and consumer demand. We use panel regression to understand the drivers of demand during the pandemic and Bayesian inference to simplify the regulation landscape that can help build scenarios for resilient demand planning. We illustrate this resilient demand planning model using a specific example of gas retailing. We find that demand is sensitive to fear of COVID-19: as the number of COVID-19 cases increase over the previous week, the demand for gas decreases -- though this dissipates over time. Further, government regulations restrict access to different services, thereby reducing mobility, which in itself reduces demand.
De-homogenization using Convolutional Neural Networks
May 10, 2021
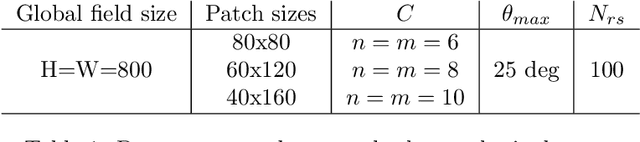
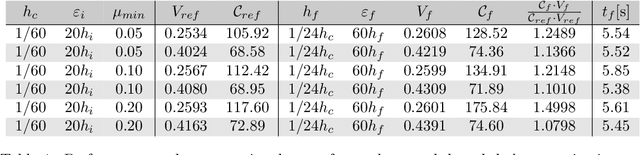
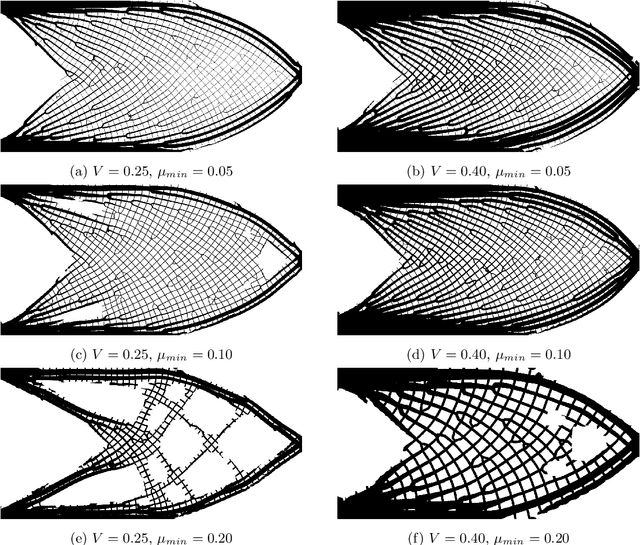
This paper presents a deep learning-based de-homogenization method for structural compliance minimization. By using a convolutional neural network to parameterize the mapping from a set of lamination parameters on a coarse mesh to a one-scale design on a fine mesh, we avoid solving the least square problems associated with traditional de-homogenization approaches and save time correspondingly. To train the neural network, a two-step custom loss function has been developed which ensures a periodic output field that follows the local lamination orientations. A key feature of the proposed method is that the training is carried out without any use of or reference to the underlying structural optimization problem, which renders the proposed method robust and insensitive wrt. domain size, boundary conditions, and loading. A post-processing procedure utilizing a distance transform on the output field skeleton is used to project the desired lamination widths onto the output field while ensuring a predefined minimum length-scale and volume fraction. To demonstrate that the deep learning approach has excellent generalization properties, numerical examples are shown for several different load and boundary conditions. For an appropriate choice of parameters, the de-homogenized designs perform within $7-25\%$ of the homogenization-based solution at a fraction of the computational cost. With several options for further improvements, the scheme may provide the basis for future interactive high-resolution topology optimization.
Robust Graph Learning Under Wasserstein Uncertainty
May 10, 2021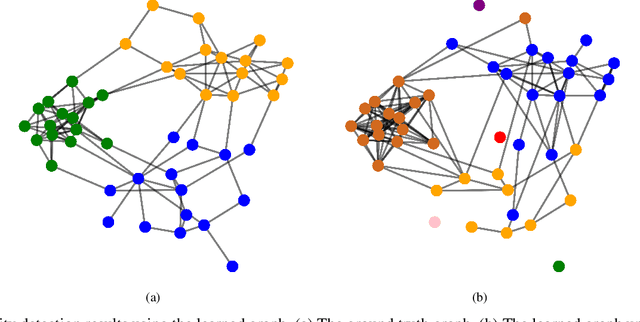
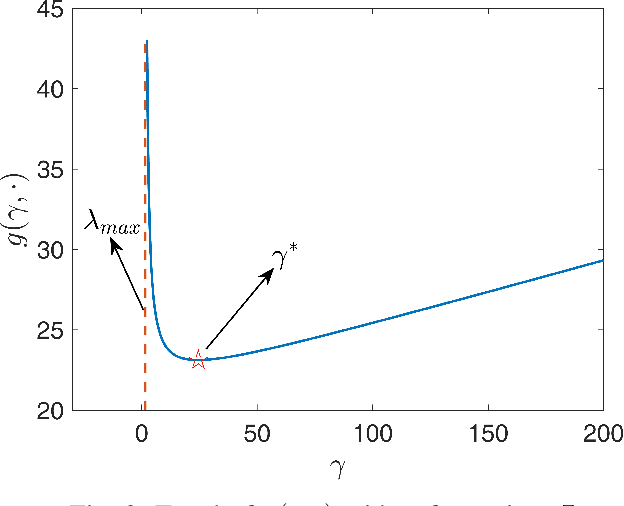
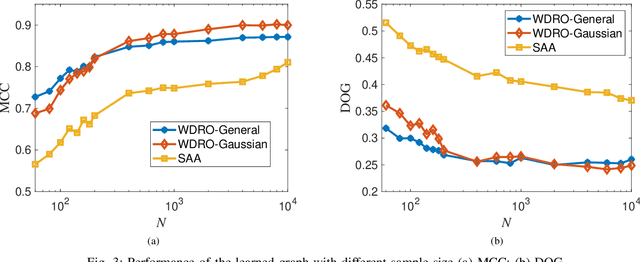
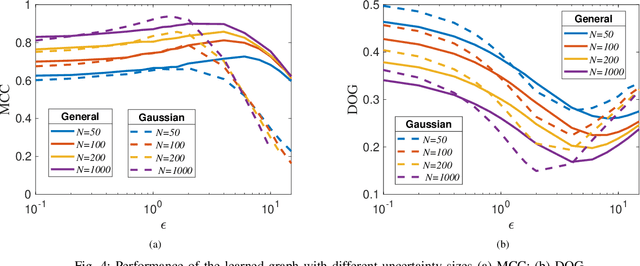
Graphs are playing a crucial role in different fields since they are powerful tools to unveil intrinsic relationships among signals. In many scenarios, an accurate graph structure representing signals is not available at all and that motivates people to learn a reliable graph structure directly from observed signals. However, in real life, it is inevitable that there exists uncertainty in the observed signals due to noise measurements or limited observability, which causes a reduction in reliability of the learned graph. To this end, we propose a graph learning framework using Wasserstein distributionally robust optimization (WDRO) which handles uncertainty in data by defining an uncertainty set on distributions of the observed data. Specifically, two models are developed, one of which assumes all distributions in uncertainty set are Gaussian distributions and the other one has no prior distributional assumption. Instead of using interior point method directly, we propose two algorithms to solve the corresponding models and show that our algorithms are more time-saving. In addition, we also reformulate both two models into Semi-Definite Programming (SDP), and illustrate that they are intractable in the scenario of large-scale graph. Experiments on both synthetic and real world data are carried out to validate the proposed framework, which show that our scheme can learn a reliable graph in the context of uncertainty.
LFI-CAM: Learning Feature Importance for Better Visual Explanation
May 03, 2021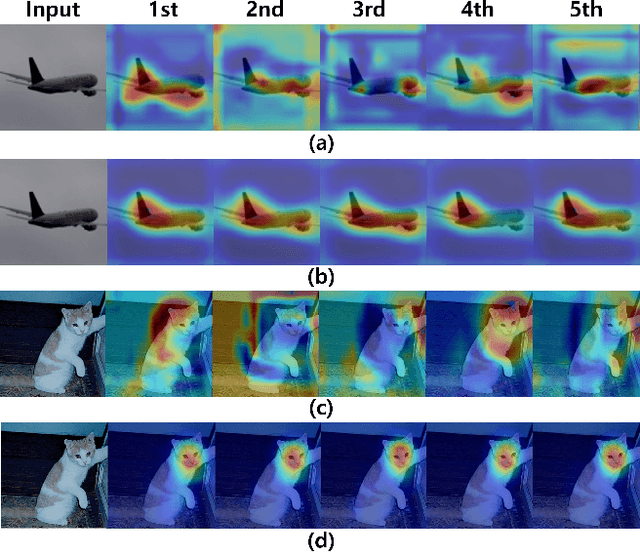
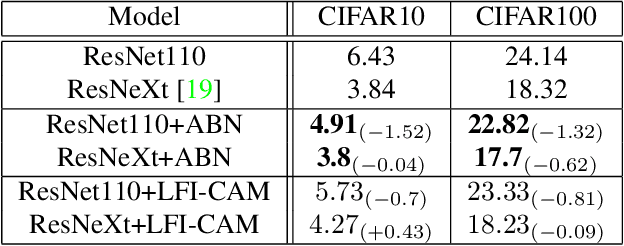
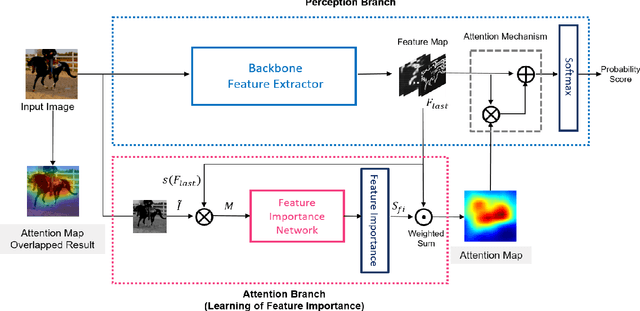
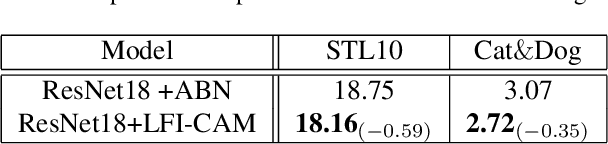
Class Activation Mapping (CAM) is a powerful technique used to understand the decision making of Convolutional Neural Network (CNN) in computer vision. Recently, there have been attempts not only to generate better visual explanations, but also to improve classification performance using visual explanations. However, the previous works still have their own drawbacks. In this paper, we propose a novel architecture, LFI-CAM, which is trainable for image classification and visual explanation in an end-to-end manner. LFI-CAM generates an attention map for visual explanation during forward propagation, at the same time, leverages the attention map to improve the classification performance through the attention mechanism. Our Feature Importance Network (FIN) focuses on learning the feature importance instead of directly learning the attention map to obtain a more reliable and consistent attention map. We confirmed that LFI-CAM model is optimized not only by learning the feature importance but also by enhancing the backbone feature representation to focus more on important features of the input image. Experimental results show that LFI-CAM outperforms the baseline models's accuracy on the classification tasks as well as significantly improves on the previous works in terms of attention map quality and stability over different hyper-parameters.
Deep EHR Spotlight: a Framework and Mechanism to Highlight Events in Electronic Health Records for Explainable Predictions
Mar 25, 2021The wide adoption of Electronic Health Records (EHR) has resulted in large amounts of clinical data becoming available, which promises to support service delivery and advance clinical and informatics research. Deep learning techniques have demonstrated performance in predictive analytic tasks using EHRs yet they typically lack model result transparency or explainability functionalities and require cumbersome pre-processing tasks. Moreover, EHRs contain heterogeneous and multi-modal data points such as text, numbers and time series which further hinder visualisation and interpretability. This paper proposes a deep learning framework to: 1) encode patient pathways from EHRs into images, 2) highlight important events within pathway images, and 3) enable more complex predictions with additional intelligibility. The proposed method relies on a deep attention mechanism for visualisation of the predictions and allows predicting multiple sequential outcomes.
* AMIA 2021 Virtual Informatics Summit
Towards Efficient Full 8-bit Integer DNN Online Training on Resource-limited Devices without Batch Normalization
May 27, 2021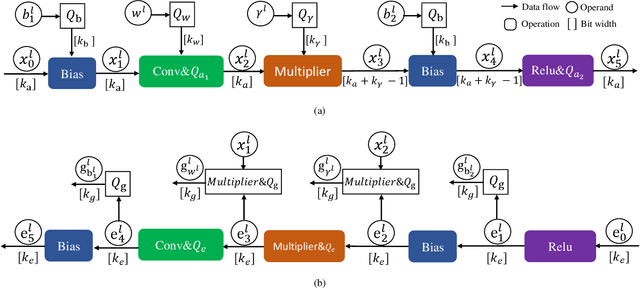

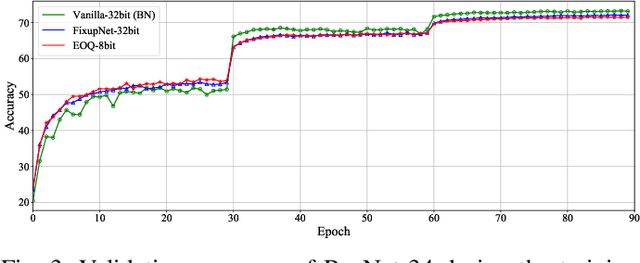
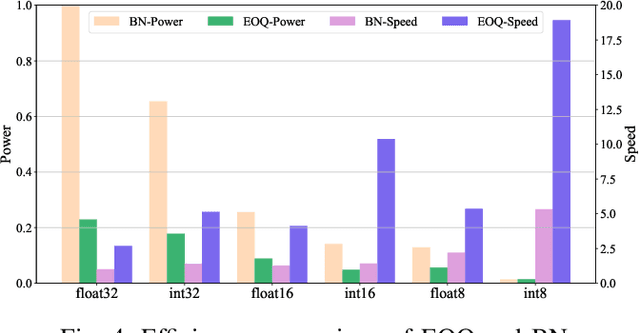
Huge computational costs brought by convolution and batch normalization (BN) have caused great challenges for the online training and corresponding applications of deep neural networks (DNNs), especially in resource-limited devices. Existing works only focus on the convolution or BN acceleration and no solution can alleviate both problems with satisfactory performance. Online training has gradually become a trend in resource-limited devices like mobile phones while there is still no complete technical scheme with acceptable model performance, processing speed, and computational cost. In this research, an efficient online-training quantization framework termed EOQ is proposed by combining Fixup initialization and a novel quantization scheme for DNN model compression and acceleration. Based on the proposed framework, we have successfully realized full 8-bit integer network training and removed BN in large-scale DNNs. Especially, weight updates are quantized to 8-bit integers for the first time. Theoretical analyses of EOQ utilizing Fixup initialization for removing BN have been further given using a novel Block Dynamical Isometry theory with weaker assumptions. Benefiting from rational quantization strategies and the absence of BN, the full 8-bit networks based on EOQ can achieve state-of-the-art accuracy and immense advantages in computational cost and processing speed. What is more, the design of deep learning chips can be profoundly simplified for the absence of unfriendly square root operations in BN. Beyond this, EOQ has been evidenced to be more advantageous in small-batch online training with fewer batch samples. In summary, the EOQ framework is specially designed for reducing the high cost of convolution and BN in network training, demonstrating a broad application prospect of online training in resource-limited devices.
Student Performance Prediction Using Dynamic Neural Models
Jun 01, 2021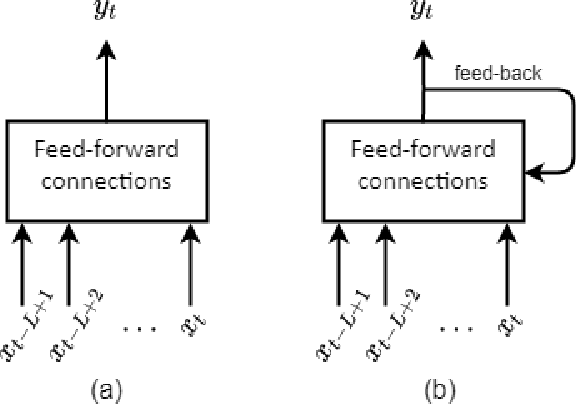
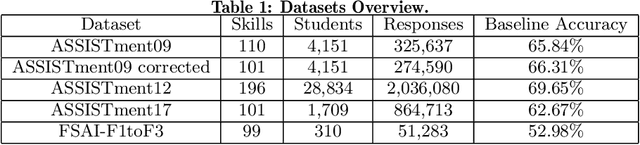
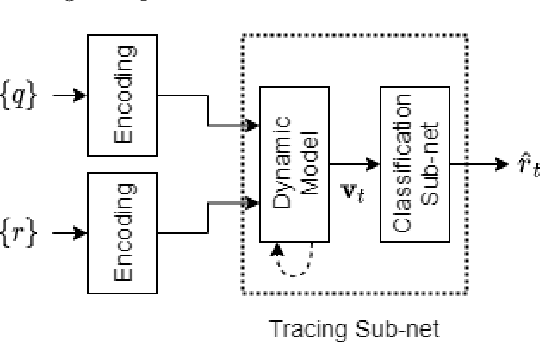
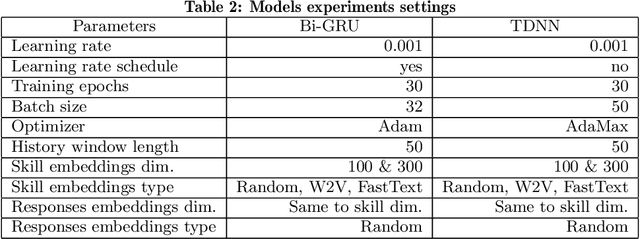
We address the problem of predicting the correctness of the student's response on the next exam question based on their previous interactions in the course of their learning and evaluation process. We model the student performance as a dynamic problem and compare the two major classes of dynamic neural architectures for its solution, namely the finite-memory Time Delay Neural Networks (TDNN) and the potentially infinite-memory Recurrent Neural Networks (RNN). Since the next response is a function of the knowledge state of the student and this, in turn, is a function of their previous responses and the skills associated with the previous questions, we propose a two-part network architecture. The first part employs a dynamic neural network (either TDNN or RNN) to trace the student knowledge state. The second part applies on top of the dynamic part and it is a multi-layer feed-forward network which completes the classification task of predicting the student response based on our estimate of the student knowledge state. Both input skills and previous responses are encoded using different embeddings. Regarding the skill embeddings we tried two different initialization schemes using (a) random vectors and (b) pretrained vectors matching the textual descriptions of the skills. Our experiments show that the performance of the RNN approach is better compared to the TDNN approach in all datasets that we have used. Also, we show that our RNN architecture outperforms the state-of-the-art models in four out of five datasets. It is worth noting that the TDNN approach also outperforms the state of the art models in four out of five datasets, although it is slightly worse than our proposed RNN approach. Finally, contrary to our expectations, we find that the initialization of skill embeddings using pretrained vectors offers practically no advantage over random initialization.
Region Proposal Networks with Contextual Selective Attention for Real-Time Organ Detection
Dec 26, 2018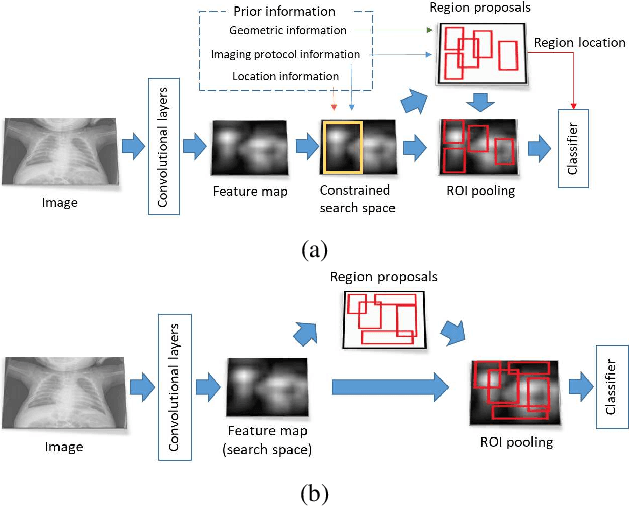
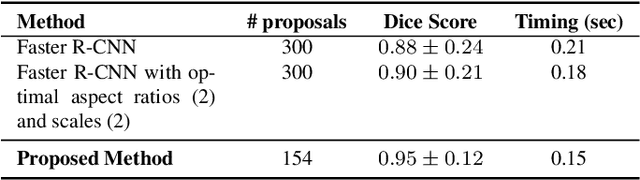
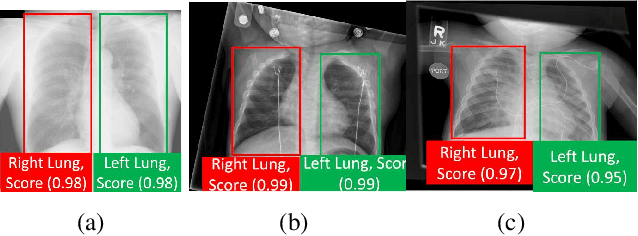
State-of-the-art methods for object detection use region proposal networks (RPN) to hypothesize object location. These networks simultaneously predicts object bounding boxes and \emph{objectness} scores at each location in the image. Unlike natural images for which RPN algorithms were originally designed, most medical images are acquired following standard protocols, thus organs in the image are typically at a similar location and possess similar geometrical characteristics (e.g. scale, aspect-ratio, etc.). Therefore, medical image acquisition protocols hold critical localization and geometric information that can be incorporated for faster and more accurate detection. This paper presents a novel attention mechanism for the detection of organs by incorporating imaging protocol information. Our novel selective attention approach (i) effectively shrinks the search space inside the feature map, (ii) appends useful localization information to the hypothesized proposal for the detection architecture to learn where to look for each organ, and (iii) modifies the pyramid of regression references in the RPN by incorporating organ- and modality-specific information, which results in additional time reduction. We evaluated the proposed framework on a dataset of 768 chest X-ray images obtained from a diverse set of sources. Our results demonstrate superior performance for the detection of the lung field compared to the state-of-the-art, both in terms of detection accuracy, demonstrating an improvement of $>7\%$ in Dice score, and reduced processing time by $27.53\%$ due to fewer hypotheses.
A Simulated Annealing Algorithm for Joint Stratification and Sample Allocation Designs
Nov 25, 2020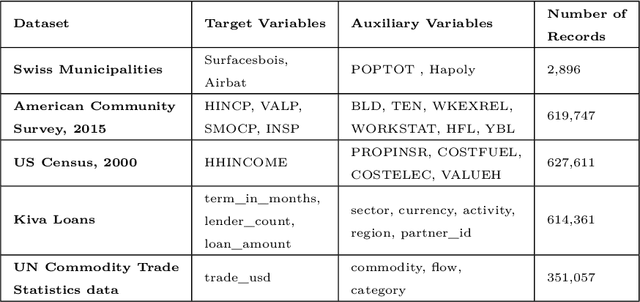
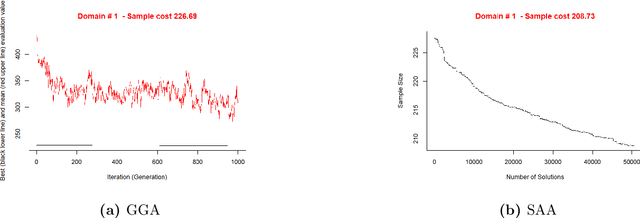
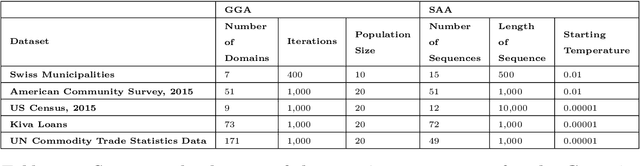
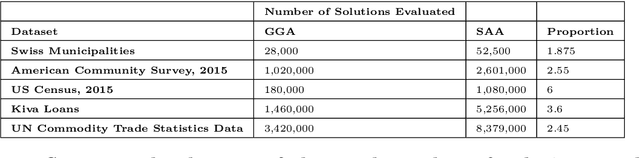
This study combined simulated annealing with delta evaluation to solve the joint stratification and sample allocation problem. In this problem, atomic strata are partitioned into mutually exclusive and collectively exhaustive strata. Each stratification is a solution, the quality of which is measured by its cost. The Bell number of possible solutions is enormous for even a moderate number of atomic strata and an additional layer of complexity is added with the evaluation time of each solution. Many larger scale combinatorial optimisation problems cannot be solved to optimality because the search for an optimum solution requires a prohibitive amount of computation time; a number of local search heuristic algorithms have been designed for this problem but these can become trapped in local minima preventing any further improvements. We add to the existing suite of local search algorithms with a simulated annealing algorithm that allows for an escape from local minima and uses delta evaluation to exploit the similarity between consecutive solutions and thereby reduce the evaluation time.
Surrogate Models for Optimization of Dynamical Systems
Jan 22, 2021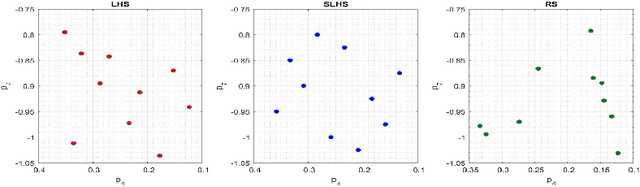
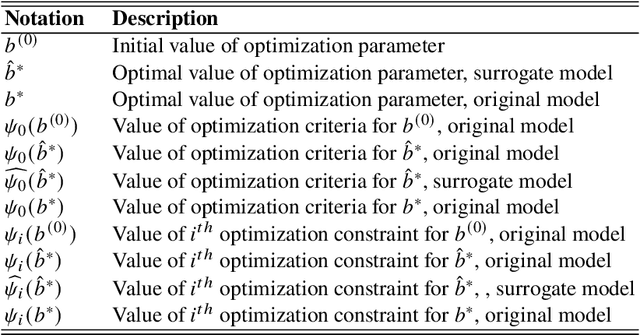
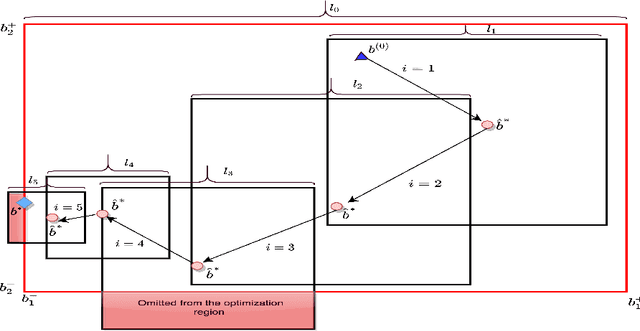

Driven by increased complexity of dynamical systems, the solution of system of differential equations through numerical simulation in optimization problems has become computationally expensive. This paper provides a smart data driven mechanism to construct low dimensional surrogate models. These surrogate models reduce the computational time for solution of the complex optimization problems by using training instances derived from the evaluations of the true objective functions. The surrogate models are constructed using combination of proper orthogonal decomposition and radial basis functions and provides system responses by simple matrix multiplication. Using relative maximum absolute error as the measure of accuracy of approximation, it is shown surrogate models with latin hypercube sampling and spline radial basis functions dominate variable order methods in computational time of optimization, while preserving the accuracy. These surrogate models also show robustness in presence of model non-linearities. Therefore, these computational efficient predictive surrogate models are applicable in various fields, specifically to solve inverse problems and optimal control problems, some examples of which are demonstrated in this paper.