 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Multi-Scale Style Control for Expressive Speech Synthesis
Apr 08, 2021
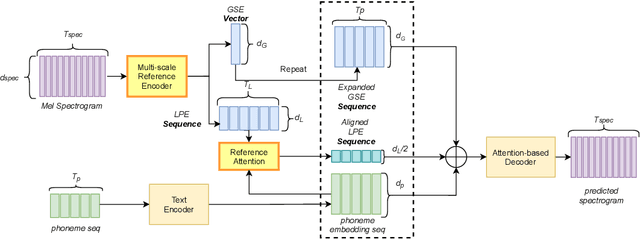
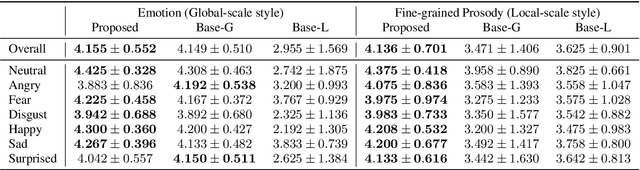
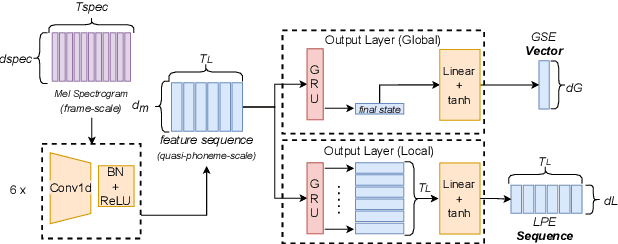
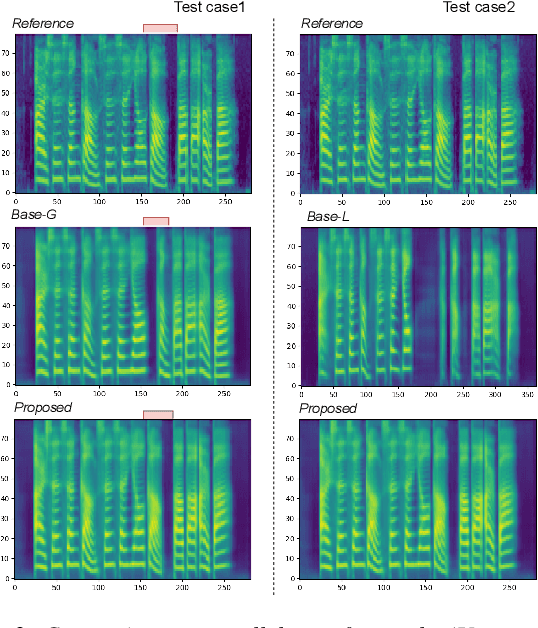
This paper introduces a multi-scale speech style modeling method for end-to-end expressive speech synthesis. The proposed method employs a multi-scale reference encoder to extract both the global-scale utterance-level and the local-scale quasi-phoneme-level style features of the target speech, which are then fed into the speech synthesis model as an extension to the input phoneme sequence. During training time, the multi-scale style model could be jointly trained with the speech synthesis model in an end-to-end fashion. By applying the proposed method to style transfer task, experimental results indicate that the controllability of the multi-scale speech style model and the expressiveness of the synthesized speech are greatly improved. Moreover, by assigning different reference speeches to extraction of style on each scale, the flexibility of the proposed method is further revealed.
Artificial Dummies for Urban Dataset Augmentation
Dec 15, 2020
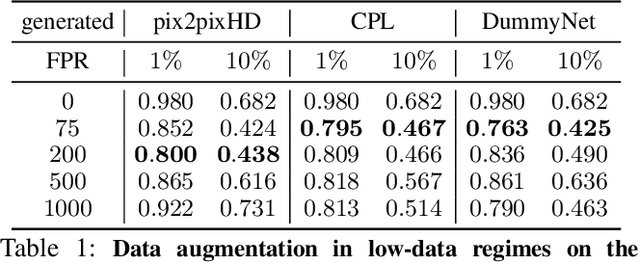
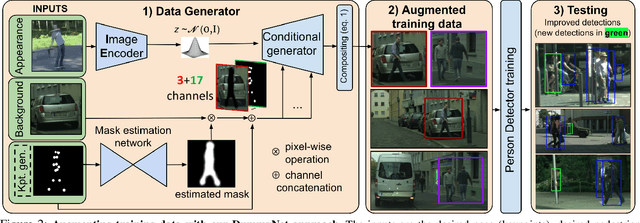
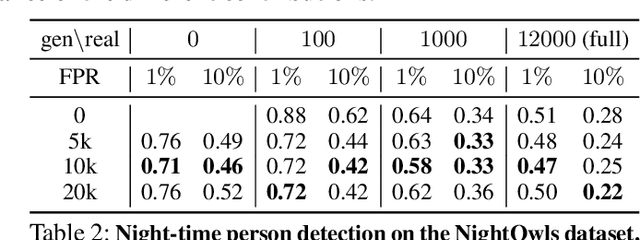
Existing datasets for training pedestrian detectors in images suffer from limited appearance and pose variation. The most challenging scenarios are rarely included because they are too difficult to capture due to safety reasons, or they are very unlikely to happen. The strict safety requirements in assisted and autonomous driving applications call for an extra high detection accuracy also in these rare situations. Having the ability to generate people images in arbitrary poses, with arbitrary appearances and embedded in different background scenes with varying illumination and weather conditions, is a crucial component for the development and testing of such applications. The contributions of this paper are three-fold. First, we describe an augmentation method for controlled synthesis of urban scenes containing people, thus producing rare or never-seen situations. This is achieved with a data generator (called DummyNet) with disentangled control of the pose, the appearance, and the target background scene. Second, the proposed generator relies on novel network architecture and associated loss that takes into account the segmentation of the foreground person and its composition into the background scene. Finally, we demonstrate that the data generated by our DummyNet improve performance of several existing person detectors across various datasets as well as in challenging situations, such as night-time conditions, where only a limited amount of training data is available. In the setup with only day-time data available, we improve the night-time detector by $17\%$ log-average miss rate over the detector trained with the day-time data only.
Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective
Dec 29, 2020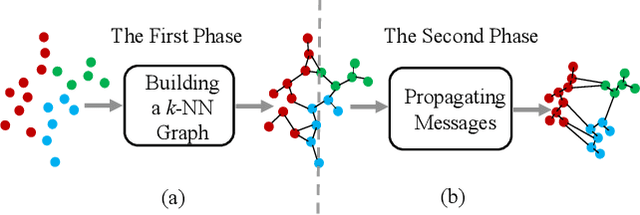

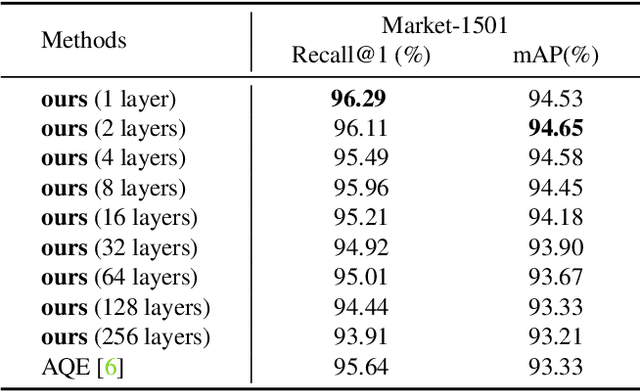
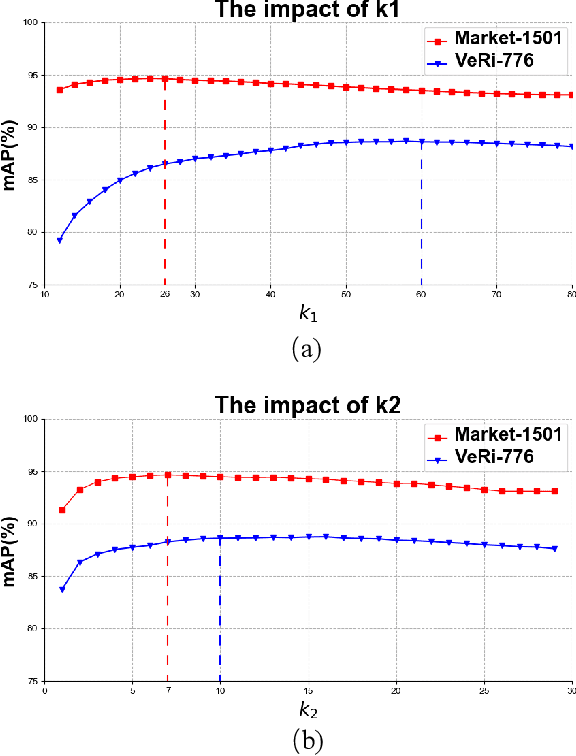
The re-ranking approach leverages high-confidence retrieved samples to refine retrieval results, which have been widely adopted as a post-processing tool for image retrieval tasks. However, we notice one main flaw of re-ranking, i.e., high computational complexity, which leads to an unaffordable time cost for real-world applications. In this paper, we revisit re-ranking and demonstrate that re-ranking can be reformulated as a high-parallelism Graph Neural Network (GNN) function. In particular, we divide the conventional re-ranking process into two phases, i.e., retrieving high-quality gallery samples and updating features. We argue that the first phase equals building the k-nearest neighbor graph, while the second phase can be viewed as spreading the message within the graph. In practice, GNN only needs to concern vertices with the connected edges. Since the graph is sparse, we can efficiently update the vertex features. On the Market-1501 dataset, we accelerate the re-ranking processing from 89.2s to 9.4ms with one K40m GPU, facilitating the real-time post-processing. Similarly, we observe that our method achieves comparable or even better retrieval results on the other four image retrieval benchmarks, i.e., VeRi-776, Oxford-5k, Paris-6k and University-1652, with limited time cost. Our code is publicly available.
Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms
May 11, 2021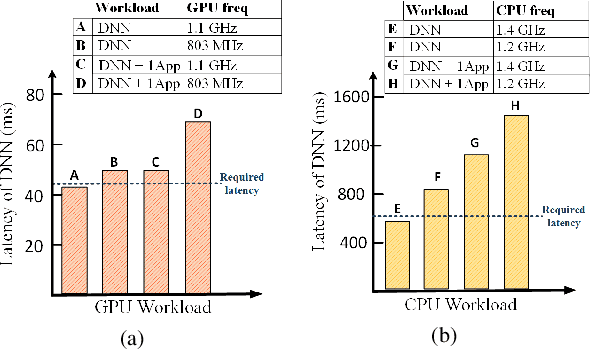

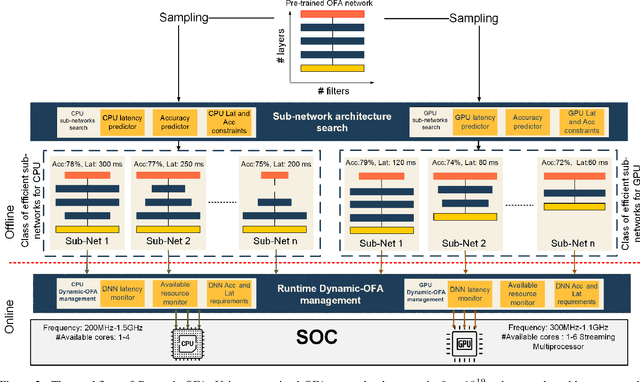
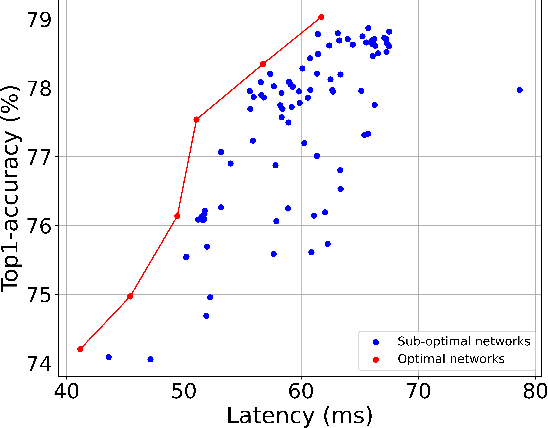
Mobile and embedded platforms are increasingly required to efficiently execute computationally demanding DNNs across heterogeneous processing elements. At runtime, the available hardware resources to DNNs can vary considerably due to other concurrently running applications. The performance requirements of the applications could also change under different scenarios. To achieve the desired performance, dynamic DNNs have been proposed in which the number of channels/layers can be scaled in real time to meet different requirements under varying resource constraints. However, the training process of such dynamic DNNs can be costly, since platform-aware models of different deployment scenarios must be retrained to become dynamic. This paper proposes Dynamic-OFA, a novel dynamic DNN approach for state-of-the-art platform-aware NAS models (i.e. Once-for-all network (OFA)). Dynamic-OFA pre-samples a family of sub-networks from a static OFA backbone model, and contains a runtime manager to choose different sub-networks under different runtime environments. As such, Dynamic-OFA does not need the traditional dynamic DNN training pipeline. Compared to the state-of-the-art, our experimental results using ImageNet on a Jetson Xavier NX show that the approach is up to 3.5x (CPU), 2.4x (GPU) faster for similar ImageNet Top-1 accuracy, or 3.8% (CPU), 5.1% (GPU) higher accuracy at similar latency.
Transient Chaos in BERT
Jun 09, 2021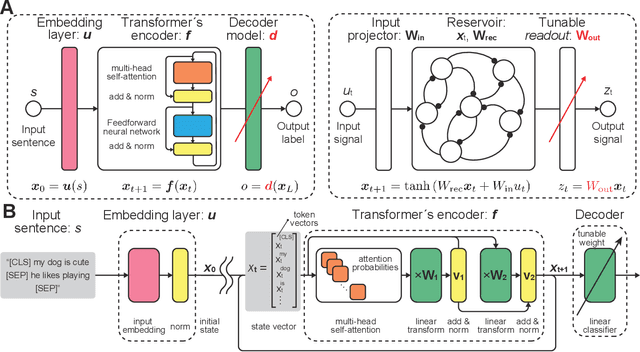
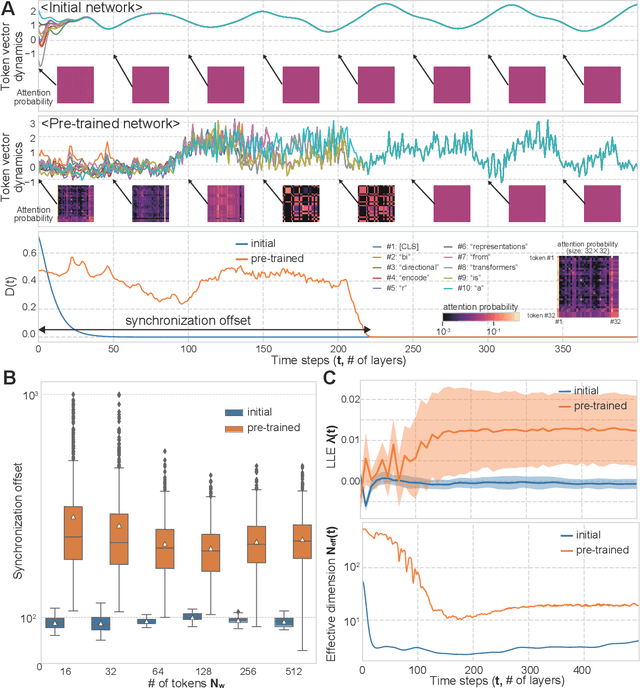
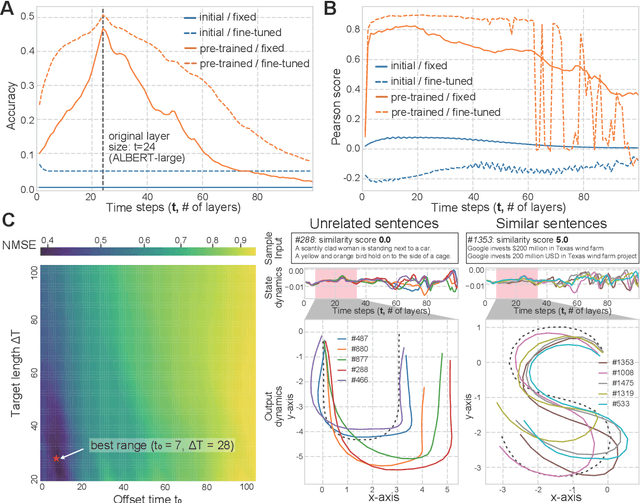
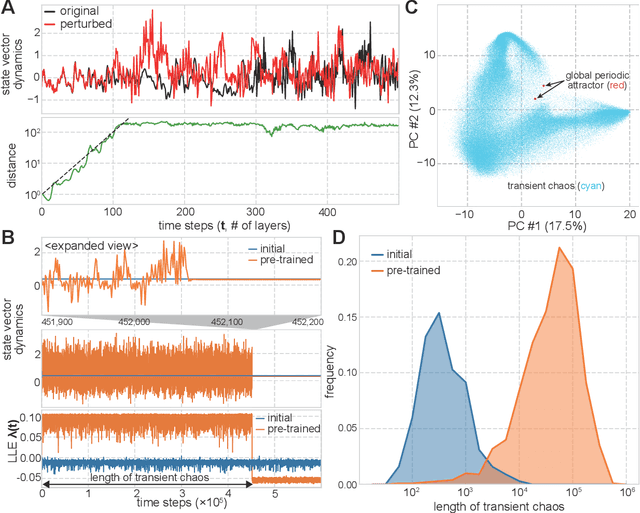
Language is an outcome of our complex and dynamic human-interactions and the technique of natural language processing (NLP) is hence built on human linguistic activities. Bidirectional Encoder Representations from Transformers (BERT) has recently gained its popularity by establishing the state-of-the-art scores in several NLP benchmarks. A Lite BERT (ALBERT) is literally characterized as a lightweight version of BERT, in which the number of BERT parameters is reduced by repeatedly applying the same neural network called Transformer's encoder layer. By pre-training the parameters with a massive amount of natural language data, ALBERT can convert input sentences into versatile high-dimensional vectors potentially capable of solving multiple NLP tasks. In that sense, ALBERT can be regarded as a well-designed high-dimensional dynamical system whose operator is the Transformer's encoder, and essential structures of human language are thus expected to be encapsulated in its dynamics. In this study, we investigated the embedded properties of ALBERT to reveal how NLP tasks are effectively solved by exploiting its dynamics. We thereby aimed to explore the nature of human language from the dynamical expressions of the NLP model. Our short-term analysis clarified that the pre-trained model stably yields trajectories with higher dimensionality, which would enhance the expressive capacity required for NLP tasks. Also, our long-term analysis revealed that ALBERT intrinsically shows transient chaos, a typical nonlinear phenomenon showing chaotic dynamics only in its transient, and the pre-trained ALBERT model tends to produce the chaotic trajectory for a significantly longer time period compared to a randomly-initialized one. Our results imply that local chaoticity would contribute to improving NLP performance, uncovering a novel aspect in the role of chaotic dynamics in human language behaviors.
Weakly-Supervised Universal Lesion Segmentation with Regional Level Set Loss
May 03, 2021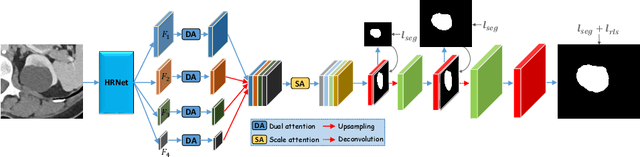
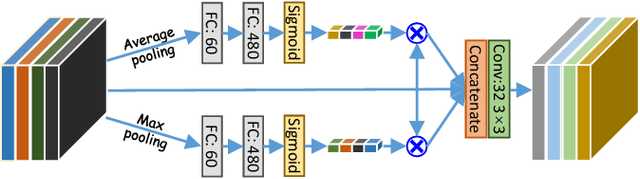
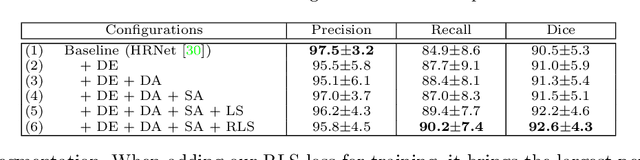
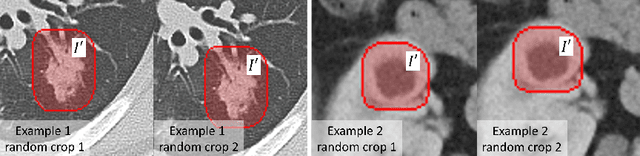
Accurately segmenting a variety of clinically significant lesions from whole body computed tomography (CT) scans is a critical task on precision oncology imaging, denoted as universal lesion segmentation (ULS). Manual annotation is the current clinical practice, being highly time-consuming and inconsistent on tumor's longitudinal assessment. Effectively training an automatic segmentation model is desirable but relies heavily on a large number of pixel-wise labelled data. Existing weakly-supervised segmentation approaches often struggle with regions nearby the lesion boundaries. In this paper, we present a novel weakly-supervised universal lesion segmentation method by building an attention enhanced model based on the High-Resolution Network (HRNet), named AHRNet, and propose a regional level set (RLS) loss for optimizing lesion boundary delineation. AHRNet provides advanced high-resolution deep image features by involving a decoder, dual-attention and scale attention mechanisms, which are crucial to performing accurate lesion segmentation. RLS can optimize the model reliably and effectively in a weakly-supervised fashion, forcing the segmentation close to lesion boundary. Extensive experimental results demonstrate that our method achieves the best performance on the publicly large-scale DeepLesion dataset and a hold-out test set.
MVFNet: Multi-View Fusion Network for Efficient Video Recognition
Jan 05, 2021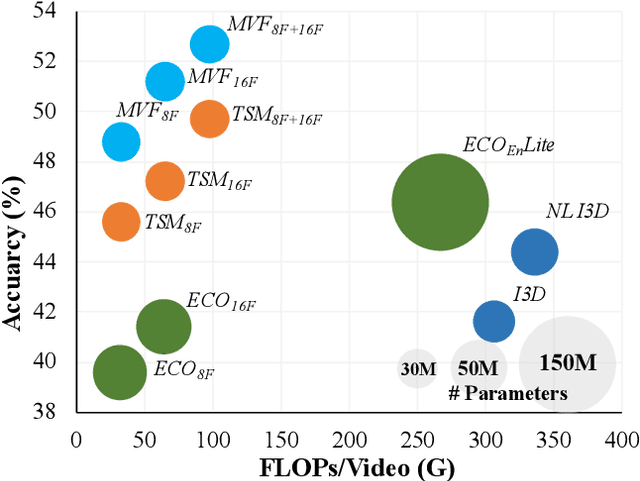
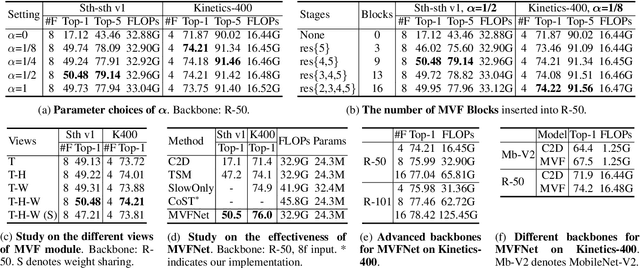
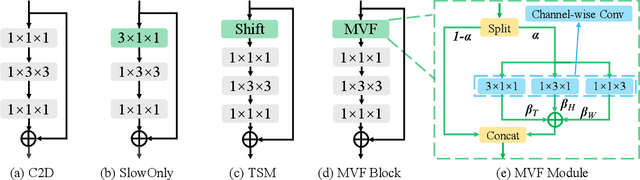
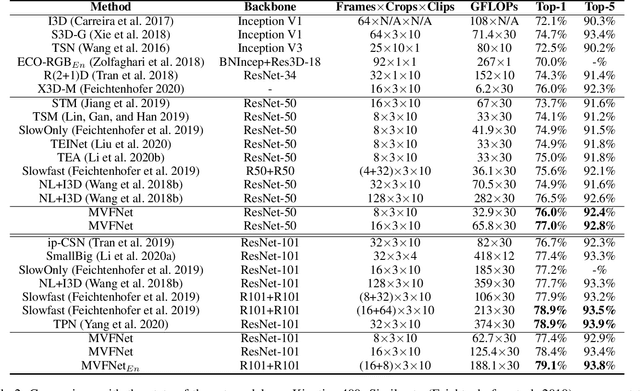
Conventionally, spatiotemporal modeling network and its complexity are the two most concentrated research topics in video action recognition. Existing state-of-the-art methods have achieved excellent accuracy regardless of the complexity meanwhile efficient spatiotemporal modeling solutions are slightly inferior in performance. In this paper, we attempt to acquire both efficiency and effectiveness simultaneously. First of all, besides traditionally treating H x W x T video frames as space-time signal (viewing from the Height-Width spatial plane), we propose to also model video from the other two Height-Time and Width-Time planes, to capture the dynamics of video thoroughly. Secondly, our model is designed based on 2D CNN backbones and model complexity is well kept in mind by design. Specifically, we introduce a novel multi-view fusion (MVF) module to exploit video dynamics using separable convolution for efficiency. It is a plug-and-play module and can be inserted into off-the-shelf 2D CNNs to form a simple yet effective model called MVFNet. Moreover, MVFNet can be thought of as a generalized video modeling framework and it can specialize to be existing methods such as C2D, SlowOnly, and TSM under different settings. Extensive experiments are conducted on popular benchmarks (i.e., Something-Something V1 & V2, Kinetics, UCF-101, and HMDB-51) to show its superiority. The proposed MVFNet can achieve state-of-the-art performance with 2D CNN's complexity.
Exact Recovery in the General Hypergraph Stochastic Block Model
May 11, 2021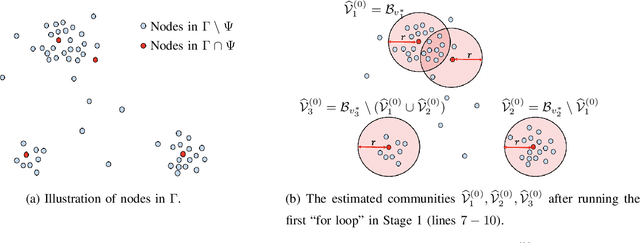
This paper investigates fundamental limits of exact recovery in the general d-uniform hypergraph stochastic block model (d-HSBM), wherein n nodes are partitioned into k disjoint communities with relative sizes (p1,..., pk). Each subset of nodes with cardinality d is generated independently as an order-d hyperedge with a certain probability that depends on the ground-truth communities that the d nodes belong to. The goal is to exactly recover the k hidden communities based on the observed hypergraph. We show that there exists a sharp threshold such that exact recovery is achievable above the threshold and impossible below the threshold (apart from a small regime of parameters that will be specified precisely). This threshold is represented in terms of a quantity which we term as the generalized Chernoff-Hellinger divergence between communities. Our result for this general model recovers prior results for the standard SBM and d-HSBM with two symmetric communities as special cases. En route to proving our achievability results, we develop a polynomial-time two-stage algorithm that meets the threshold. The first stage adopts a certain hypergraph spectral clustering method to obtain a coarse estimate of communities, and the second stage refines each node individually via local refinement steps to ensure exact recovery.
Dynamic Spectrum Access using Stochastic Multi-User Bandits
Jan 12, 2021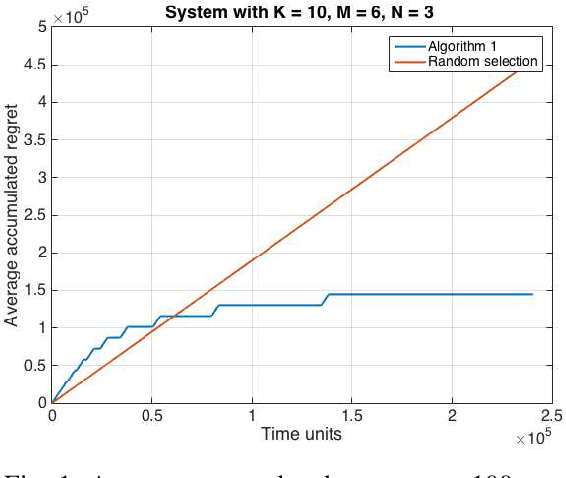
A stochastic multi-user multi-armed bandit framework is used to develop algorithms for uncoordinated spectrum access. In contrast to prior work, it is assumed that rewards can be non-zero even under collisions, thus allowing for the number of users to be greater than the number of channels. The proposed algorithm consists of an estimation phase and an allocation phase. It is shown that if every user adopts the algorithm, the system wide regret is order-optimal of order $O(\log T)$ over a time-horizon of duration $T$. The regret guarantees hold for both the cases where the number of users is greater than or less than the number of channels. The algorithm is extended to the dynamic case where the number of users in the system evolves over time, and is shown to lead to sub-linear regret.
Real-Time Dense Stereo Embedded in A UAV for Road Inspection
Apr 12, 2019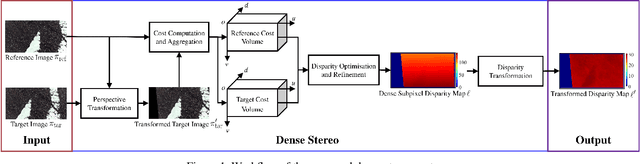
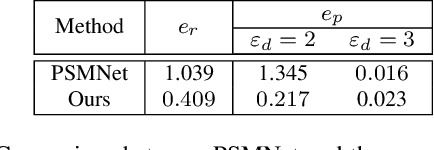

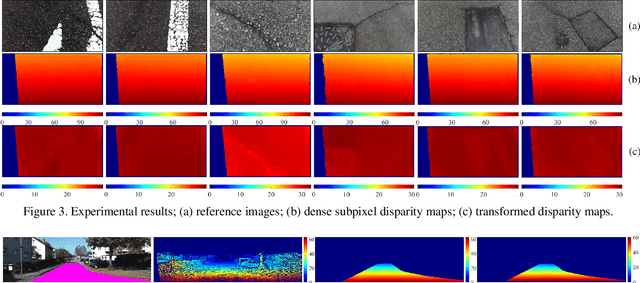
The condition assessment of road surfaces is essential to ensure their serviceability while still providing maximum road traffic safety. This paper presents a robust stereo vision system embedded in an unmanned aerial vehicle (UAV). The perspective view of the target image is first transformed into the reference view, and this not only improves the disparity accuracy, but also reduces the algorithm's computational complexity. The cost volumes generated from stereo matching are then filtered using a bilateral filter. The latter has been proved to be a feasible solution for the functional minimisation problem in a fully connected Markov random field model. Finally, the disparity maps are transformed by minimising an energy function with respect to the roll angle and disparity projection model. This makes the damaged road areas more distinguishable from the road surface. The proposed system is implemented on an NVIDIA Jetson TX2 GPU with CUDA for real-time purposes. It is demonstrated through experiments that the damaged road areas can be easily distinguished from the transformed disparity maps.