 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Low-Complexity MIMO Channel Estimator with Implicit Structure of a Convolutional Neural Network
Apr 26, 2021
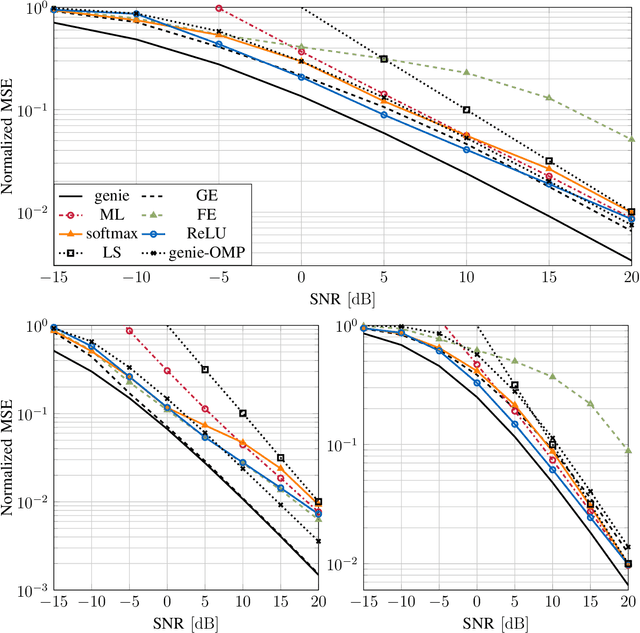
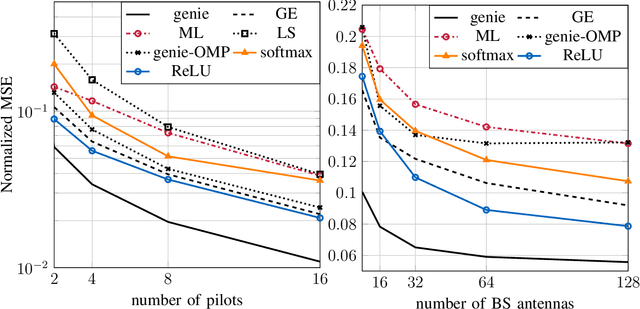
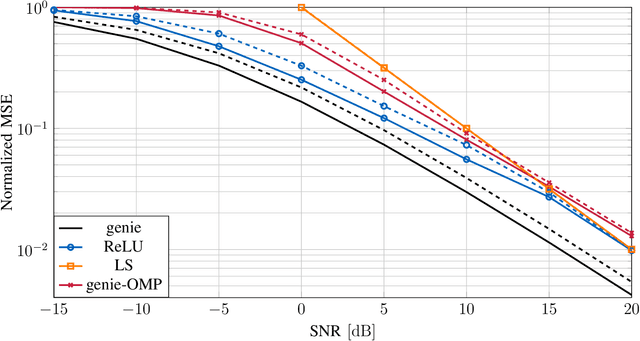
A low-complexity convolutional neural network estimator which learns the minimum mean squared error channel estimator for single-antenna users was recently proposed. We generalize the architecture to the estimation of MIMO channels with multiple-antenna users and incorporate complexity-reducing assumptions based on the channel model. Learning is used in this context to combat the mismatch between the assumptions and real scenarios where the assumptions may not hold. We derive a high-level description of the estimator for arbitrary choices of the pilot sequence. It turns out that the proposed estimator has the implicit structure of a two-layered convolutional neural network, where the derived quantities can be relaxed to learnable parameters. We show that by using discrete Fourier transform based pilots the number of learnable network parameters decreases significantly and the online run time of the estimator is reduced considerably, where we can achieve linearithmic order of complexity in the number of antennas. Numerical results demonstrate performance gains compared to state-of-the-art algorithms from the field of compressive sensing or covariance estimation of the same or even higher computational complexity. The simulation code is available online.
Loss Rank Mining: A General Hard Example Mining Method for Real-time Detectors
Apr 10, 2018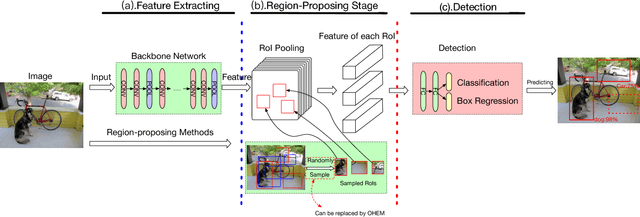



Modern object detectors usually suffer from low accuracy issues, as foregrounds always drown in tons of backgrounds and become hard examples during training. Compared with those proposal-based ones, real-time detectors are in far more serious trouble since they renounce the use of region-proposing stage which is used to filter a majority of backgrounds for achieving real-time rates. Though foregrounds as hard examples are in urgent need of being mined from tons of backgrounds, a considerable number of state-of-the-art real-time detectors, like YOLO series, have yet to profit from existing hard example mining methods, as using these methods need detectors fit series of prerequisites. In this paper, we propose a general hard example mining method named Loss Rank Mining (LRM) to fill the gap. LRM is a general method for real-time detectors, as it utilizes the final feature map which exists in all real-time detectors to mine hard examples. By using LRM, some elements representing easy examples in final feature map are filtered and detectors are forced to concentrate on hard examples during training. Extensive experiments validate the effectiveness of our method. With our method, the improvements of YOLOv2 detector on auto-driving related dataset KITTI and more general dataset PASCAL VOC are over 5% and 2% mAP, respectively. In addition, LRM is the first hard example mining strategy which could fit YOLOv2 perfectly and make it better applied in series of real scenarios where both real-time rates and accurate detection are strongly demanded.
Student Performance Prediction Using Dynamic Neural Models
Jun 01, 2021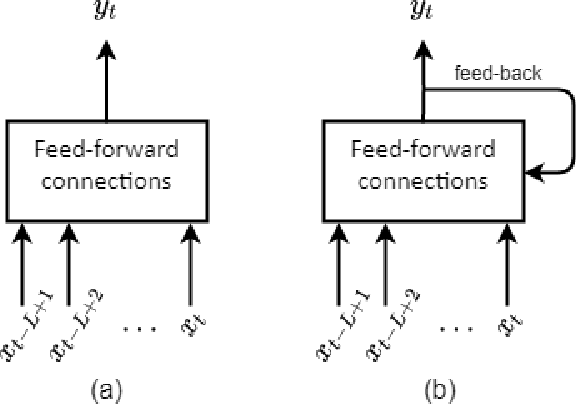
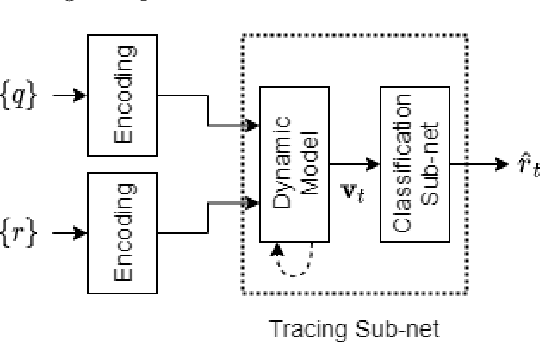
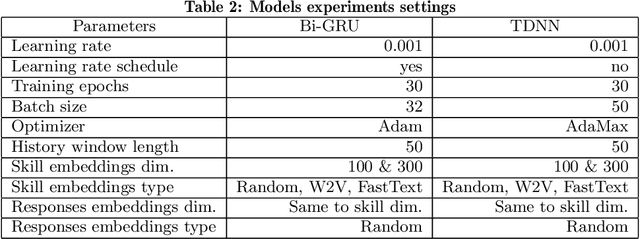
We address the problem of predicting the correctness of the student's response on the next exam question based on their previous interactions in the course of their learning and evaluation process. We model the student performance as a dynamic problem and compare the two major classes of dynamic neural architectures for its solution, namely the finite-memory Time Delay Neural Networks (TDNN) and the potentially infinite-memory Recurrent Neural Networks (RNN). Since the next response is a function of the knowledge state of the student and this, in turn, is a function of their previous responses and the skills associated with the previous questions, we propose a two-part network architecture. The first part employs a dynamic neural network (either TDNN or RNN) to trace the student knowledge state. The second part applies on top of the dynamic part and it is a multi-layer feed-forward network which completes the classification task of predicting the student response based on our estimate of the student knowledge state. Both input skills and previous responses are encoded using different embeddings. Regarding the skill embeddings we tried two different initialization schemes using (a) random vectors and (b) pretrained vectors matching the textual descriptions of the skills. Our experiments show that the performance of the RNN approach is better compared to the TDNN approach in all datasets that we have used. Also, we show that our RNN architecture outperforms the state-of-the-art models in four out of five datasets. It is worth noting that the TDNN approach also outperforms the state of the art models in four out of five datasets, although it is slightly worse than our proposed RNN approach. Finally, contrary to our expectations, we find that the initialization of skill embeddings using pretrained vectors offers practically no advantage over random initialization.
Ray-based framework for state identification in quantum dot devices
Feb 23, 2021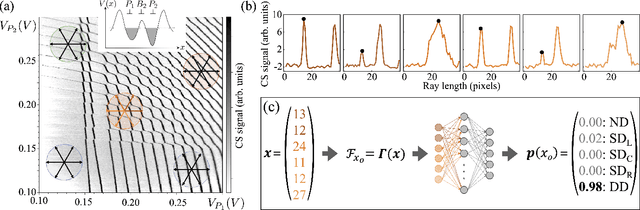
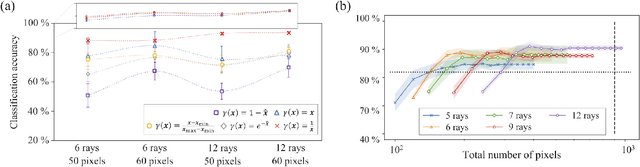
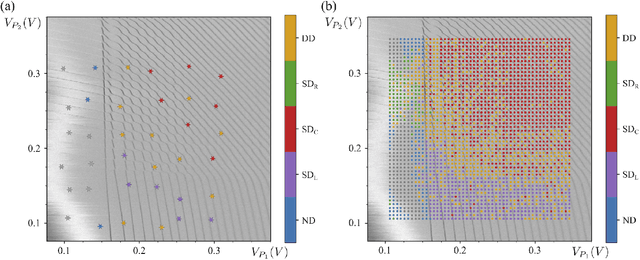
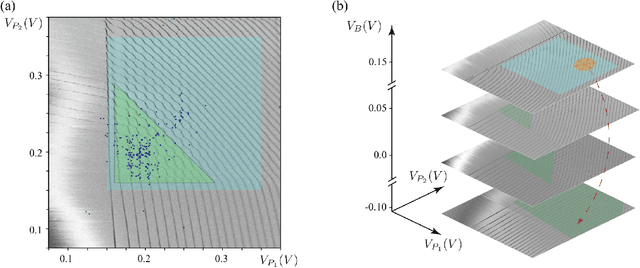
Quantum dots (QDs) defined with electrostatic gates are a leading platform for a scalable quantum computing implementation. However, with increasing numbers of qubits, the complexity of the control parameter space also grows. Traditional measurement techniques, relying on complete or near-complete exploration via two-parameter scans (images) of the device response, quickly become impractical with increasing numbers of gates. Here, we propose to circumvent this challenge by introducing a measurement technique relying on one-dimensional projections of the device response in the multi-dimensional parameter space. Dubbed as the ray-based classification (RBC) framework, we use this machine learning (ML) approach to implement a classifier for QD states, enabling automated recognition of qubit-relevant parameter regimes. We show that RBC surpasses the 82 % accuracy benchmark from the experimental implementation of image-based classification techniques from prior work while cutting down the number of measurement points needed by up to 70 %. The reduction in measurement cost is a significant gain for time-intensive QD measurements and is a step forward towards the scalability of these devices. We also discuss how the RBC-based optimizer, which tunes the device to a multi-qubit regime, performs when tuning in the two- and three-dimensional parameter spaces defined by plunger and barrier gates that control the dots. This work provides experimental validation of both efficient state identification and optimization with ML techniques for non-traditional measurements in quantum systems with high-dimensional parameter spaces and time-intensive measurements.
Towards Efficient Full 8-bit Integer DNN Online Training on Resource-limited Devices without Batch Normalization
May 27, 2021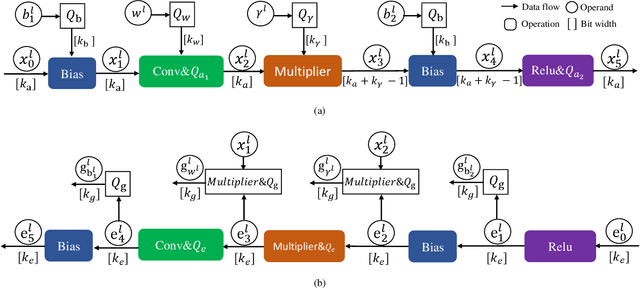

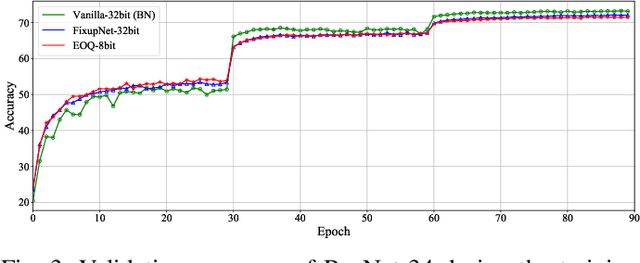
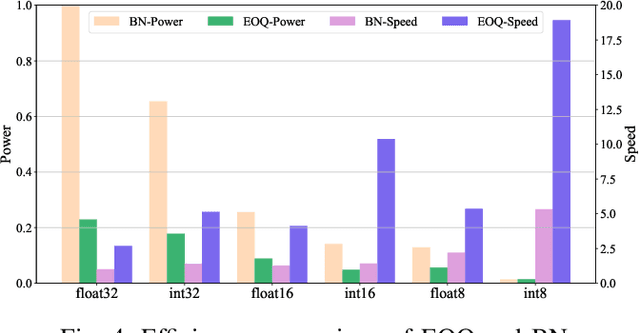
Huge computational costs brought by convolution and batch normalization (BN) have caused great challenges for the online training and corresponding applications of deep neural networks (DNNs), especially in resource-limited devices. Existing works only focus on the convolution or BN acceleration and no solution can alleviate both problems with satisfactory performance. Online training has gradually become a trend in resource-limited devices like mobile phones while there is still no complete technical scheme with acceptable model performance, processing speed, and computational cost. In this research, an efficient online-training quantization framework termed EOQ is proposed by combining Fixup initialization and a novel quantization scheme for DNN model compression and acceleration. Based on the proposed framework, we have successfully realized full 8-bit integer network training and removed BN in large-scale DNNs. Especially, weight updates are quantized to 8-bit integers for the first time. Theoretical analyses of EOQ utilizing Fixup initialization for removing BN have been further given using a novel Block Dynamical Isometry theory with weaker assumptions. Benefiting from rational quantization strategies and the absence of BN, the full 8-bit networks based on EOQ can achieve state-of-the-art accuracy and immense advantages in computational cost and processing speed. What is more, the design of deep learning chips can be profoundly simplified for the absence of unfriendly square root operations in BN. Beyond this, EOQ has been evidenced to be more advantageous in small-batch online training with fewer batch samples. In summary, the EOQ framework is specially designed for reducing the high cost of convolution and BN in network training, demonstrating a broad application prospect of online training in resource-limited devices.
De-homogenization using Convolutional Neural Networks
May 10, 2021
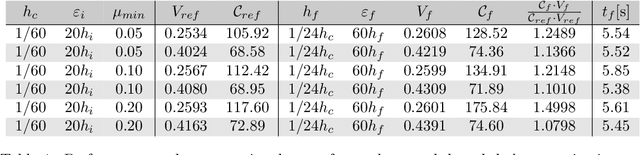
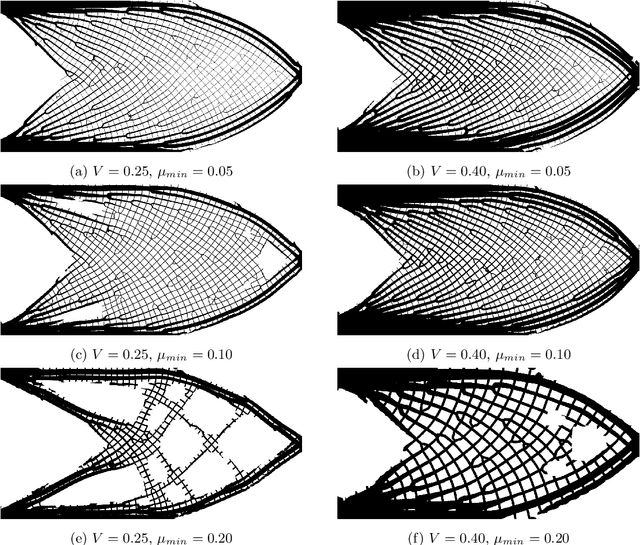
This paper presents a deep learning-based de-homogenization method for structural compliance minimization. By using a convolutional neural network to parameterize the mapping from a set of lamination parameters on a coarse mesh to a one-scale design on a fine mesh, we avoid solving the least square problems associated with traditional de-homogenization approaches and save time correspondingly. To train the neural network, a two-step custom loss function has been developed which ensures a periodic output field that follows the local lamination orientations. A key feature of the proposed method is that the training is carried out without any use of or reference to the underlying structural optimization problem, which renders the proposed method robust and insensitive wrt. domain size, boundary conditions, and loading. A post-processing procedure utilizing a distance transform on the output field skeleton is used to project the desired lamination widths onto the output field while ensuring a predefined minimum length-scale and volume fraction. To demonstrate that the deep learning approach has excellent generalization properties, numerical examples are shown for several different load and boundary conditions. For an appropriate choice of parameters, the de-homogenized designs perform within $7-25\%$ of the homogenization-based solution at a fraction of the computational cost. With several options for further improvements, the scheme may provide the basis for future interactive high-resolution topology optimization.
Consumer Demand Modeling During COVID-19 Pandemic
May 03, 2021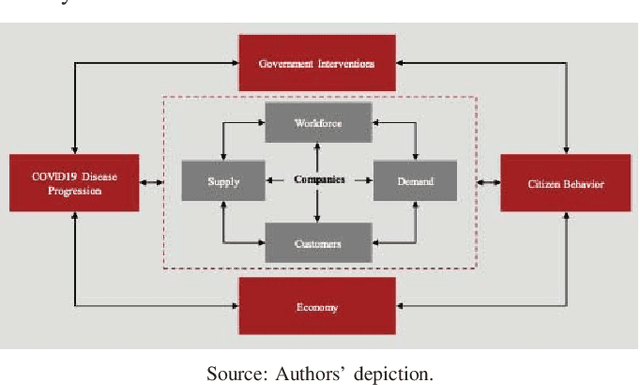
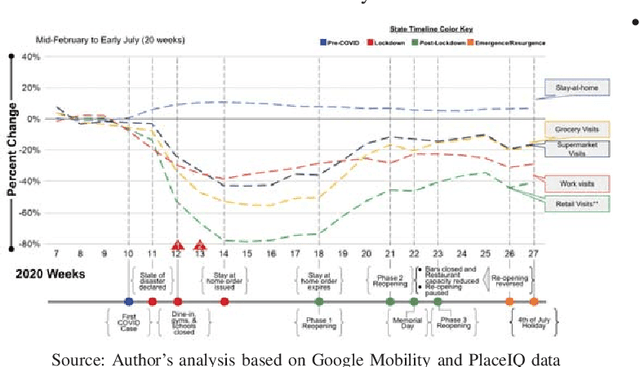
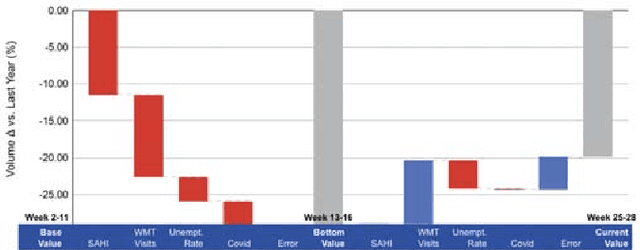
The current pandemic has introduced substantial uncertainty to traditional methods for demand planning. These uncertainties stem from the disease progression, government interventions, economy and consumer behavior. While most of the emerging literature on the pandemic has focused on disease progression, a few have focused on consequent regulations and their impact on individual behavior. The contributions of this paper include a quantitative behavior model of fear of COVID-19, impact of government interventions on consumer behavior, and impact of consumer behavior on consumer choice and hence demand for goods. It brings together multiple models for disease progression, consumer behavior and demand estimation-thus bridging the gap between disease progression and consumer demand. We use panel regression to understand the drivers of demand during the pandemic and Bayesian inference to simplify the regulation landscape that can help build scenarios for resilient demand planning. We illustrate this resilient demand planning model using a specific example of gas retailing. We find that demand is sensitive to fear of COVID-19: as the number of COVID-19 cases increase over the previous week, the demand for gas decreases -- though this dissipates over time. Further, government regulations restrict access to different services, thereby reducing mobility, which in itself reduces demand.
Fake-image detection with Robust Hashing
Feb 02, 2021
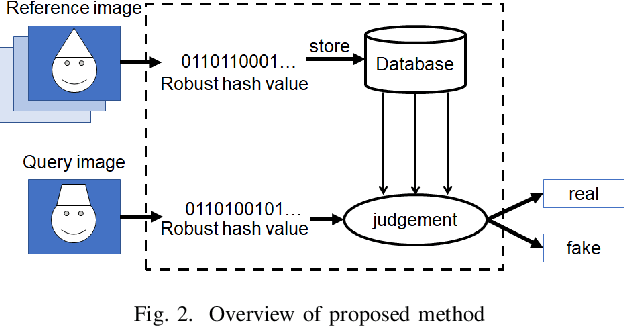

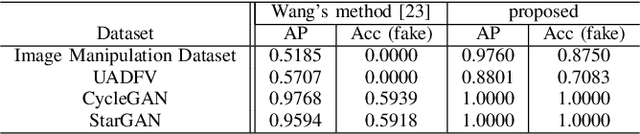
In this paper, we investigate whether robust hashing has a possibility to robustly detect fake-images even when multiple manipulation techniques such as JPEG compression are applied to images for the first time. In an experiment, the proposed fake detection with robust hashing is demonstrated to outperform state-of-the-art one under the use of various datasets including fake images generated with GANs.
Robust Graph Learning Under Wasserstein Uncertainty
May 10, 2021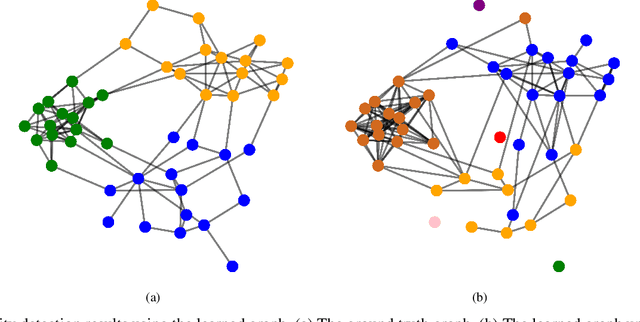
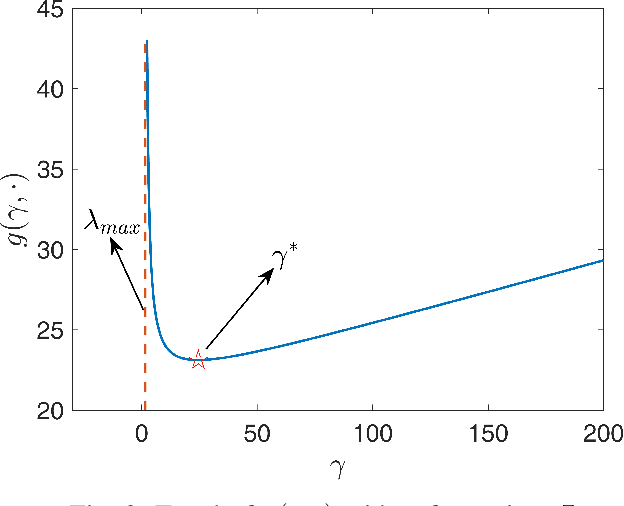
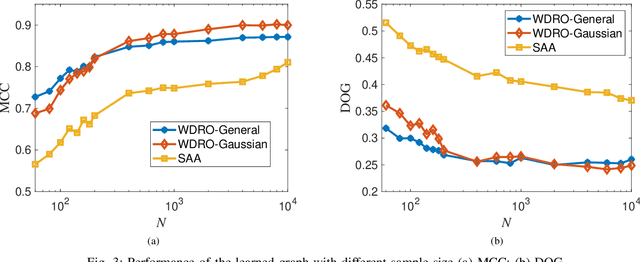
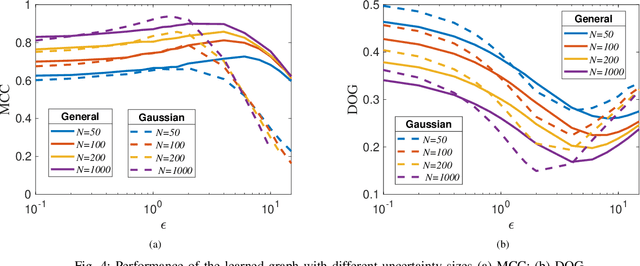
Graphs are playing a crucial role in different fields since they are powerful tools to unveil intrinsic relationships among signals. In many scenarios, an accurate graph structure representing signals is not available at all and that motivates people to learn a reliable graph structure directly from observed signals. However, in real life, it is inevitable that there exists uncertainty in the observed signals due to noise measurements or limited observability, which causes a reduction in reliability of the learned graph. To this end, we propose a graph learning framework using Wasserstein distributionally robust optimization (WDRO) which handles uncertainty in data by defining an uncertainty set on distributions of the observed data. Specifically, two models are developed, one of which assumes all distributions in uncertainty set are Gaussian distributions and the other one has no prior distributional assumption. Instead of using interior point method directly, we propose two algorithms to solve the corresponding models and show that our algorithms are more time-saving. In addition, we also reformulate both two models into Semi-Definite Programming (SDP), and illustrate that they are intractable in the scenario of large-scale graph. Experiments on both synthetic and real world data are carried out to validate the proposed framework, which show that our scheme can learn a reliable graph in the context of uncertainty.
Modeling Graph Node Correlations with Neighbor Mixture Models
Apr 18, 2021
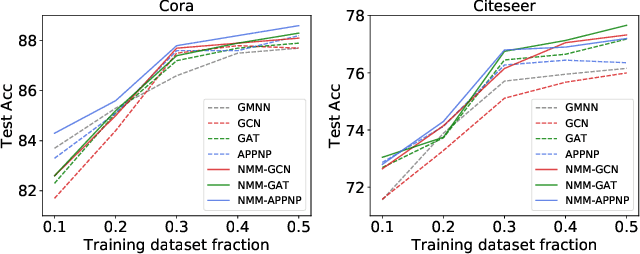
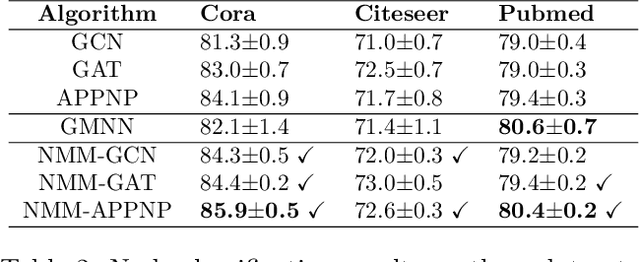
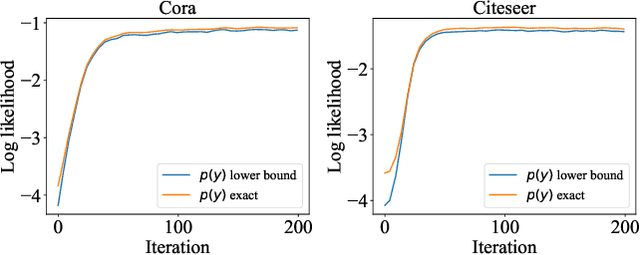
We propose a new model, the Neighbor Mixture Model (NMM), for modeling node labels in a graph. This model aims to capture correlations between the labels of nodes in a local neighborhood. We carefully design the model so it could be an alternative to a Markov Random Field but with more affordable computations. In particular, drawing samples and evaluating marginal probabilities of single labels can be done in linear time. To scale computations to large graphs, we devise a variational approximation without introducing extra parameters. We further use graph neural networks (GNNs) to parameterize the NMM, which reduces the number of learnable parameters while allowing expressive representation learning. The proposed model can be either fit directly to large observed graphs or used to enable scalable inference that preserves correlations for other distributions such as deep generative graph models. Across a diverse set of node classification, image denoising, and link prediction tasks, we show our proposed NMM advances the state-of-the-art in modeling real-world labeled graphs.