 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rank Based Pseudoinverse Computation in Extreme Learning Machine for Large Datasets
Nov 04, 2020
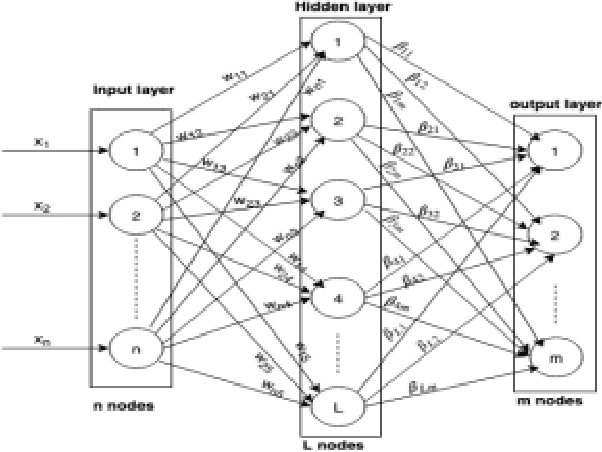
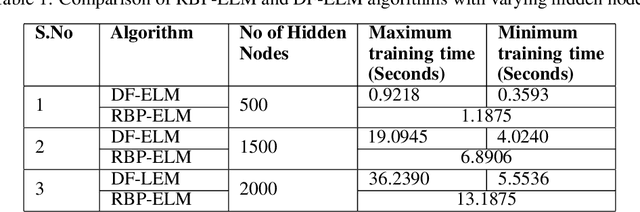
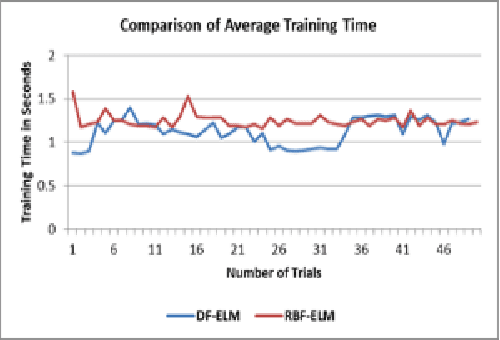

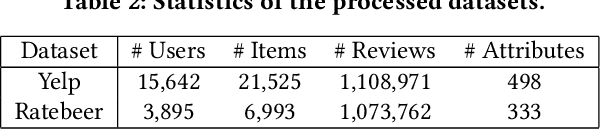
Extreme Learning Machine (ELM) is an efficient and effective least-square-based learning algorithm for classification, regression problems based on single hidden layer feed-forward neural network (SLFN). It has been shown in the literature that it has faster convergence and good generalization ability for moderate datasets. But, there is great deal of challenge involved in computing the pseudoinverse when there are large numbers of hidden nodes or for large number of instances to train complex pattern recognition problems. To address this problem, a few approaches such as EM-ELM, DF-ELM have been proposed in the literature. In this paper, a new rank-based matrix decomposition of the hidden layer matrix is introduced to have the optimal training time and reduce the computational complexity for a large number of hidden nodes in the hidden layer. The results show that it has constant training time which is closer towards the minimal training time and very far from worst-case training time of the DF-ELM algorithm that has been shown efficient in the recent literature.
Explanation as a Defense of Recommendation
Jan 24, 2021
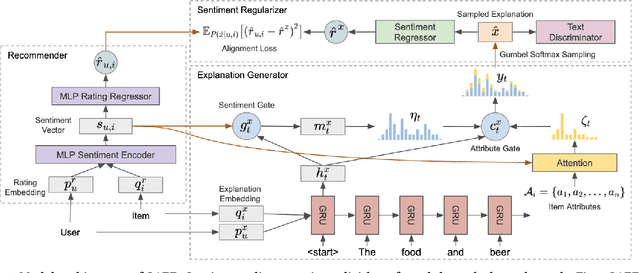
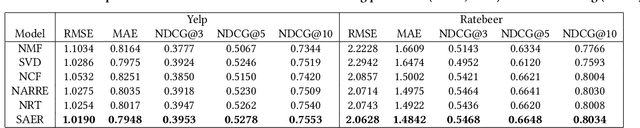
Textual explanations have proved to help improve user satisfaction on machine-made recommendations. However, current mainstream solutions loosely connect the learning of explanation with the learning of recommendation: for example, they are often separately modeled as rating prediction and content generation tasks. In this work, we propose to strengthen their connection by enforcing the idea of sentiment alignment between a recommendation and its corresponding explanation. At training time, the two learning tasks are joined by a latent sentiment vector, which is encoded by the recommendation module and used to make word choices for explanation generation. At both training and inference time, the explanation module is required to generate explanation text that matches sentiment predicted by the recommendation module. Extensive experiments demonstrate our solution outperforms a rich set of baselines in both recommendation and explanation tasks, especially on the improved quality of its generated explanations. More importantly, our user studies confirm our generated explanations help users better recognize the differences between recommended items and understand why an item is recommended.
An Online Prediction Approach Based on Incremental Support Vector Machine for Dynamic Multiobjective Optimization
Feb 24, 2021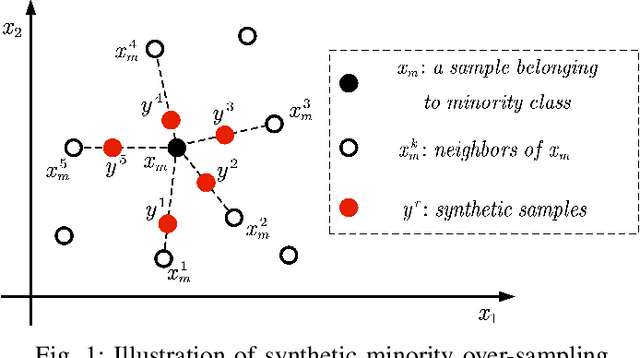

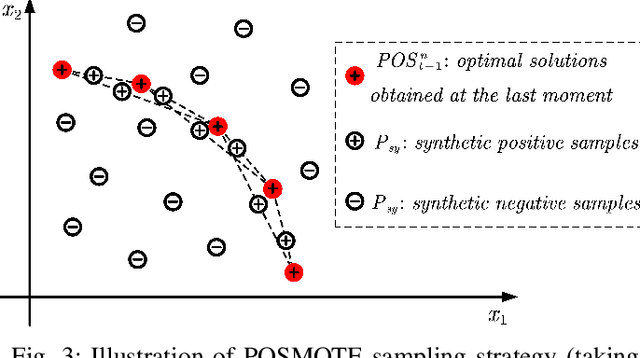
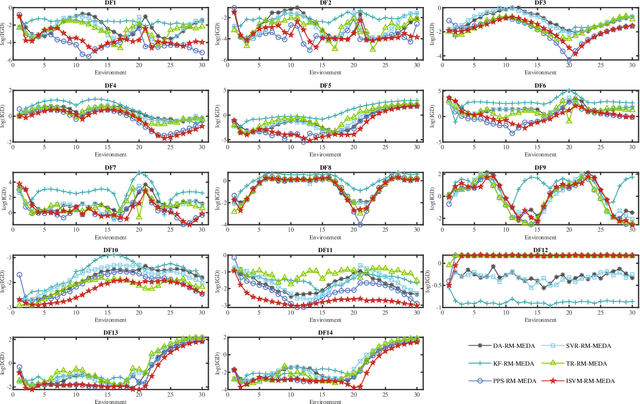
Real-world multiobjective optimization problems usually involve conflicting objectives that change over time, which requires the optimization algorithms to quickly track the Pareto optimal front (POF) when the environment changes. In recent years, evolutionary algorithms based on prediction models have been considered promising. However, most existing approaches only make predictions based on the linear correlation between a finite number of optimal solutions in two or three previous environments. These incomplete information extraction strategies may lead to low prediction accuracy in some instances. In this paper, a novel prediction algorithm based on incremental support vector machine (ISVM) is proposed, called ISVM-DMOEA. We treat the solving of dynamic multiobjective optimization problems (DMOPs) as an online learning process, using the continuously obtained optimal solution to update an incremental support vector machine without discarding the solution information at earlier time. ISVM is then used to filter random solutions and generate an initial population for the next moment. To overcome the obstacle of insufficient training samples, a synthetic minority oversampling strategy is implemented before the training of ISVM. The advantage of this approach is that the nonlinear correlation between solutions can be explored online by ISVM, and the information contained in all historical optimal solutions can be exploited to a greater extent. The experimental results and comparison with chosen state-of-the-art algorithms demonstrate that the proposed algorithm can effectively tackle dynamic multiobjective optimization problems.
Scalable, End-to-End, Deep-Learning-Based Data Reconstruction Chain for Particle Imaging Detectors
Feb 01, 2021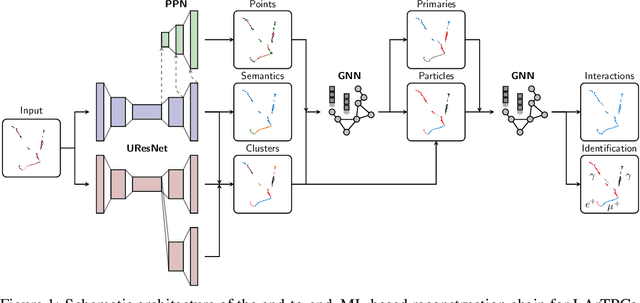
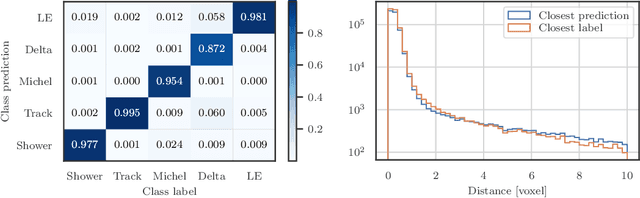
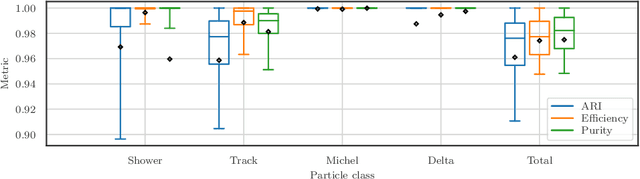
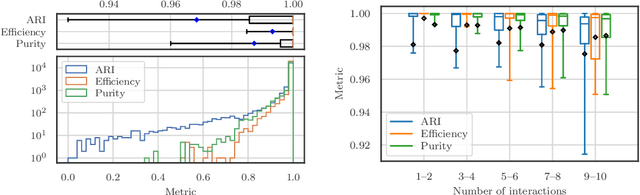
Recent inroads in Computer Vision (CV) and Machine Learning (ML) have motivated a new approach to the analysis of particle imaging detector data. Unlike previous efforts which tackled isolated CV tasks, this paper introduces an end-to-end, ML-based data reconstruction chain for Liquid Argon Time Projection Chambers (LArTPCs), the state-of-the-art in precision imaging at the intensity frontier of neutrino physics. The chain is a multi-task network cascade which combines voxel-level feature extraction using Sparse Convolutional Neural Networks and particle superstructure formation using Graph Neural Networks. Each algorithm incorporates physics-informed inductive biases, while their collective hierarchy is used to enforce a causal structure. The output is a comprehensive description of an event that may be used for high-level physics inference. The chain is end-to-end optimizable, eliminating the need for time-intensive manual software adjustments. It is also the first implementation to handle the unprecedented pile-up of dozens of high energy neutrino interactions, expected in the 3D-imaging LArTPC of the Deep Underground Neutrino Experiment. The chain is trained as a whole and its performance is assessed at each step using an open simulated data set.
Neural Unsupervised Semantic Role Labeling
Apr 19, 2021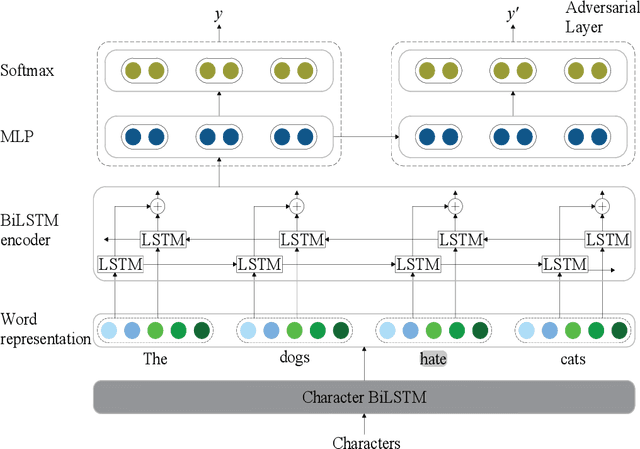
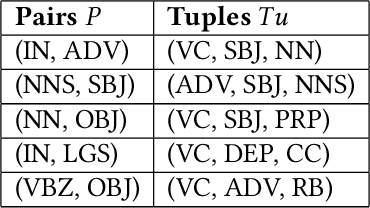
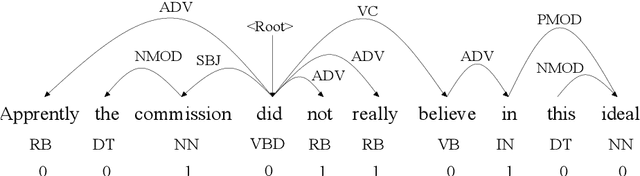
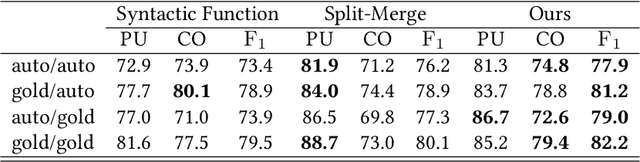
The task of semantic role labeling (SRL) is dedicated to finding the predicate-argument structure. Previous works on SRL are mostly supervised and do not consider the difficulty in labeling each example which can be very expensive and time-consuming. In this paper, we present the first neural unsupervised model for SRL. To decompose the task as two argument related subtasks, identification and clustering, we propose a pipeline that correspondingly consists of two neural modules. First, we train a neural model on two syntax-aware statistically developed rules. The neural model gets the relevance signal for each token in a sentence, to feed into a BiLSTM, and then an adversarial layer for noise-adding and classifying simultaneously, thus enabling the model to learn the semantic structure of a sentence. Then we propose another neural model for argument role clustering, which is done through clustering the learned argument embeddings biased towards their dependency relations. Experiments on CoNLL-2009 English dataset demonstrate that our model outperforms previous state-of-the-art baseline in terms of non-neural models for argument identification and classification.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020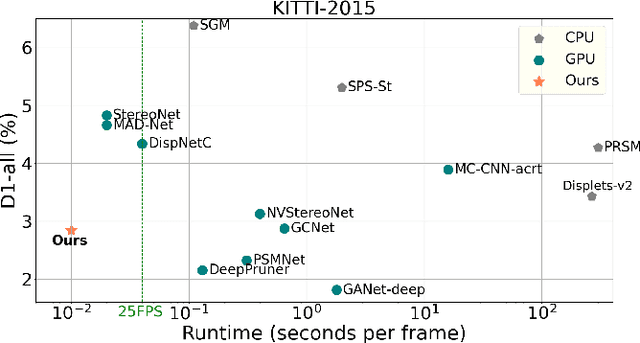

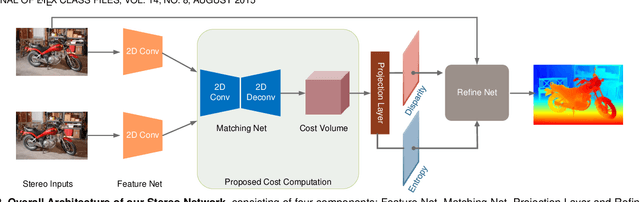
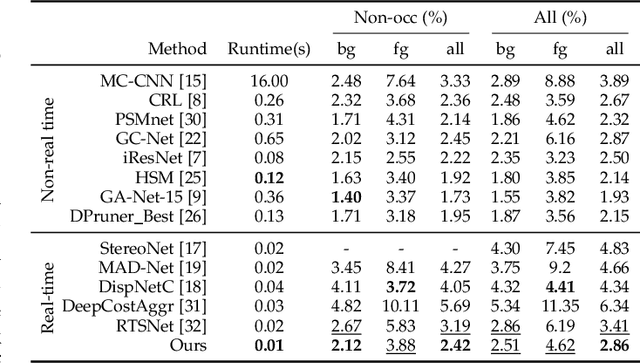
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Can Predominant Credible Information Suppress Misinformation in Crises? Empirical Studies of Tweets Related to Prevention Measures during COVID-19
Feb 01, 2021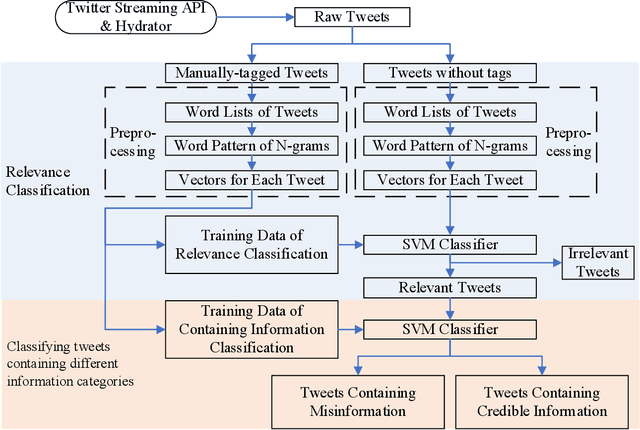
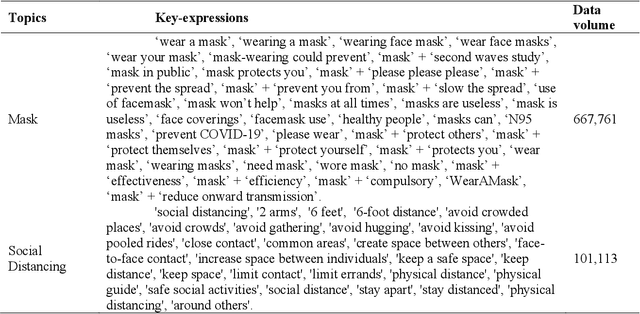
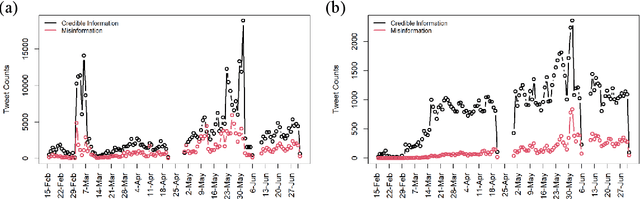
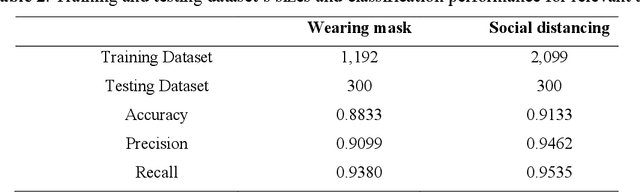
During COVID-19, misinformation on social media affects the adoption of appropriate prevention behaviors. It is urgent to suppress the misinformation to prevent negative public health consequences. Although an array of studies has proposed misinformation suppression strategies, few have investigated the role of predominant credible information during crises. None has examined its effect quantitatively using longitudinal social media data. Therefore, this research investigates the temporal correlations between credible information and misinformation, and whether predominant credible information can suppress misinformation for two prevention measures (i.e. topics), i.e. wearing masks and social distancing using tweets collected from February 15 to June 30, 2020. We trained Support Vector Machine classifiers to retrieve relevant tweets and classify tweets containing credible information and misinformation for each topic. Based on cross-correlation analyses of credible and misinformation time series for both topics, we find that the previously predominant credible information can lead to the decrease of misinformation (i.e. suppression) with a time lag. The research findings provide empirical evidence for suppressing misinformation with credible information in complex online environments and suggest practical strategies for future information management during crises and emergencies.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
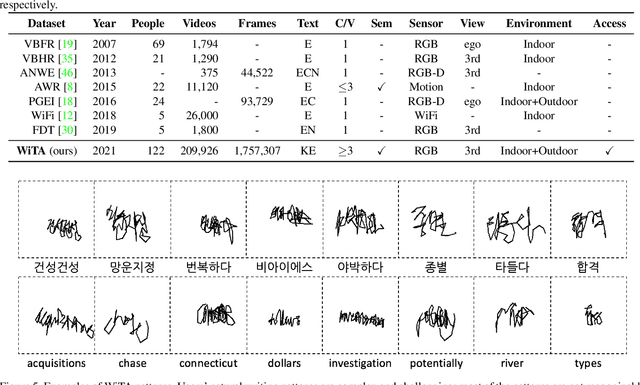

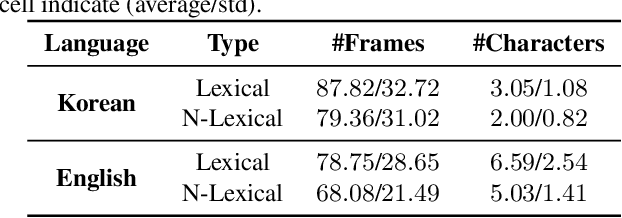
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.
Labels, Information, and Computation: Efficient, Privacy-Preserving Learning Using Sufficient Labels
Apr 19, 2021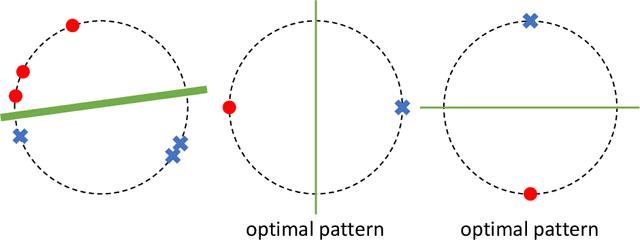
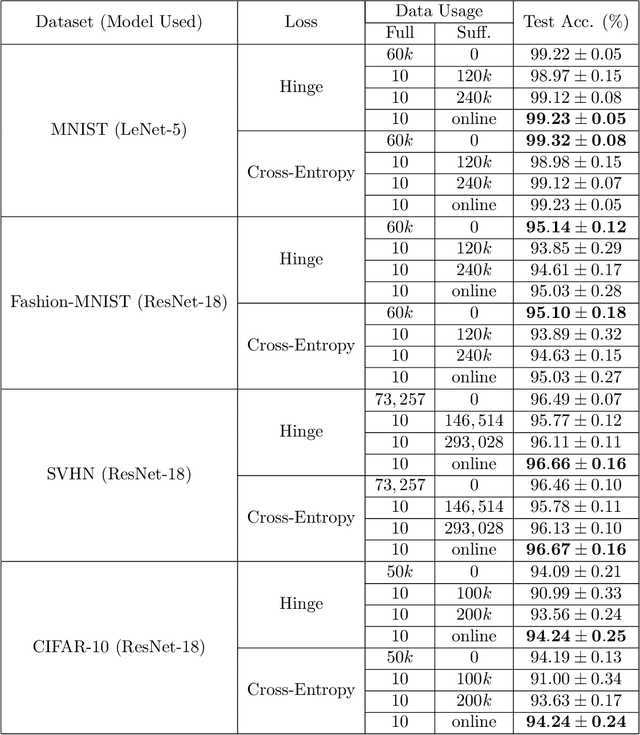
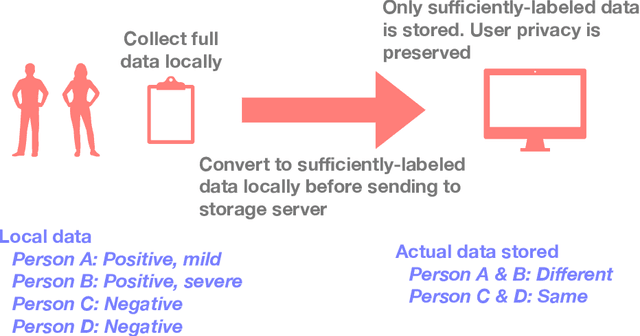
In supervised learning, obtaining a large set of fully-labeled training data is expensive. We show that we do not always need full label information on every single training example to train a competent classifier. Specifically, inspired by the principle of sufficiency in statistics, we present a statistic (a summary) of the fully-labeled training set that captures almost all the relevant information for classification but at the same time is easier to obtain directly. We call this statistic "sufficiently-labeled data" and prove its sufficiency and efficiency for finding the optimal hidden representations, on which competent classifier heads can be trained using as few as a single randomly-chosen fully-labeled example per class. Sufficiently-labeled data can be obtained from annotators directly without collecting the fully-labeled data first. And we prove that it is easier to directly obtain sufficiently-labeled data than obtaining fully-labeled data. Furthermore, sufficiently-labeled data naturally preserves user privacy by storing relative, instead of absolute, information. Extensive experimental results are provided to support our theory.
Machine learning pipeline for battery state of health estimation
Feb 01, 2021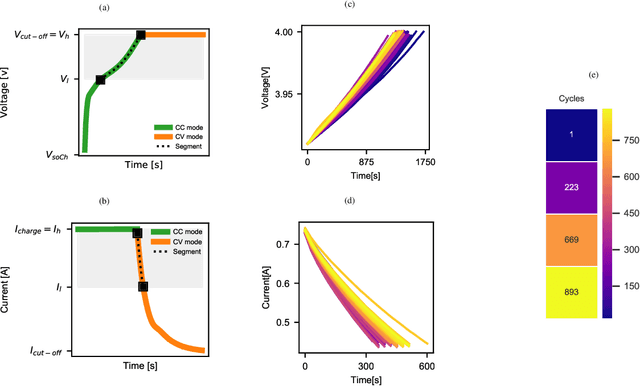
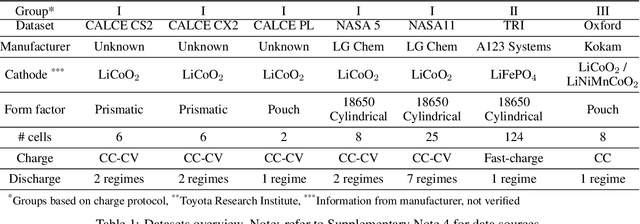
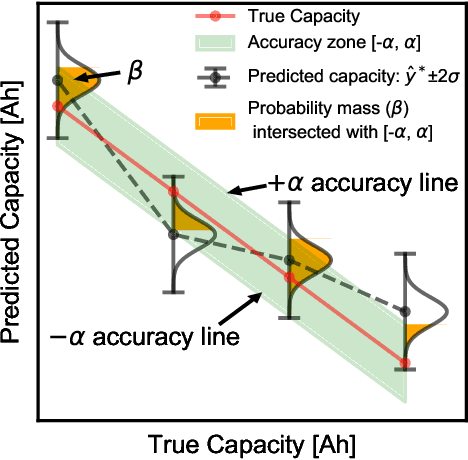
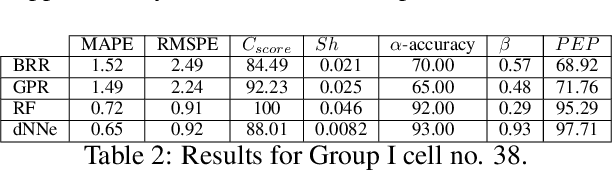
Lithium-ion batteries are ubiquitous in modern day applications ranging from portable electronics to electric vehicles. Irrespective of the application, reliable real-time estimation of battery state of health (SOH) by on-board computers is crucial to the safe operation of the battery, ultimately safeguarding asset integrity. In this paper, we design and evaluate a machine learning pipeline for estimation of battery capacity fade - a metric of battery health - on 179 cells cycled under various conditions. The pipeline estimates battery SOH with an associated confidence interval by using two parametric and two non-parametric algorithms. Using segments of charge voltage and current curves, the pipeline engineers 30 features, performs automatic feature selection and calibrates the algorithms. When deployed on cells operated under the fast-charging protocol, the best model achieves a root mean squared percent error of 0.45\%. This work provides insights into the design of scalable data-driven models for battery SOH estimation, emphasising the value of confidence bounds around the prediction. The pipeline methodology combines experimental data with machine learning modelling and can be generalized to other critical components that require real-time estimation of SOH.