 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
cMinMax: A Fast Algorithm to Find the Corners of an N-dimensional Convex Polytope
Nov 28, 2020
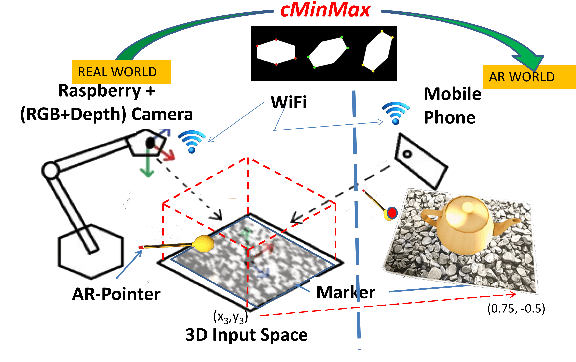
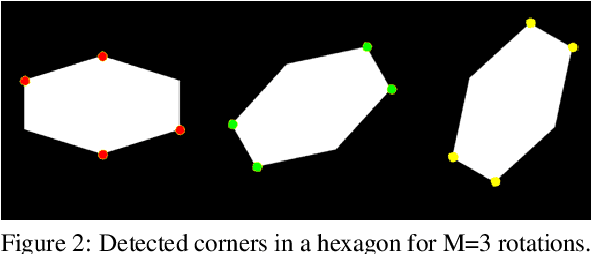
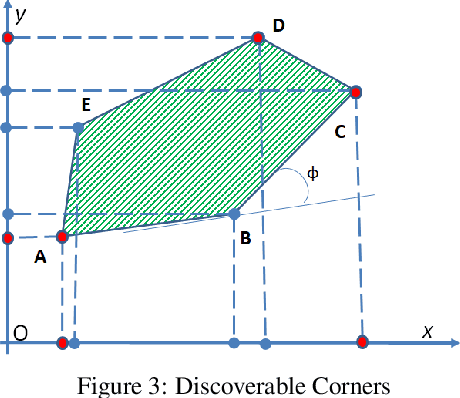
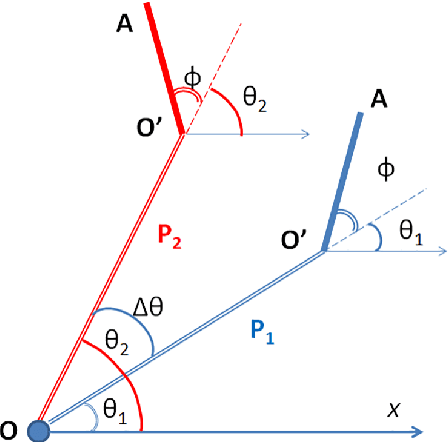
During the last years, the emerging field of Augmented & Virtual Reality (AR-VR) has seen tremendousgrowth. At the same time there is a trend to develop low cost high-quality AR systems where computing poweris in demand. Feature points are extensively used in these real-time frame-rate and 3D applications, thereforeefficient high-speed feature detectors are necessary. Corners are such special features and often are used as thefirst step in the marker alignment in Augmented Reality (AR). Corners are also used in image registration andrecognition, tracking, SLAM, robot path finding and 2D or 3D object detection and retrieval. Therefore thereis a large number of corner detection algorithms but most of them are too computationally intensive for use inreal-time applications of any complexity. Many times the border of the image is a convex polygon. For thisspecial, but quite common case, we have developed a specific algorithm, cMinMax. The proposed algorithmis faster, approximately by a factor of 5 compared to the widely used Harris Corner Detection algorithm. Inaddition is highly parallelizable. The algorithm is suitable for the fast registration of markers in augmentedreality systems and in applications where a computationally efficient real time feature detector is necessary.The algorithm can also be extended to N-dimensional polyhedrons.
Analyzing the Performance of Smart Industry 4.0 Applications on Cloud Computing Systems
Dec 11, 2020

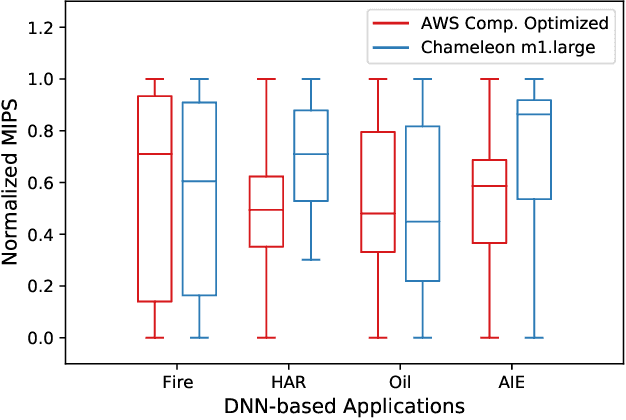
Cloud-based Deep Neural Network (DNN) applications that make latency-sensitive inference are becoming an indispensable part of Industry 4.0. Due to the multi-tenancy and resource heterogeneity, both inherent to the cloud computing environments, the inference time of DNN-based applications are stochastic. Such stochasticity, if not captured, can potentially lead to low Quality of Service (QoS) or even a disaster in critical sectors, such as Oil and Gas industry. To make Industry 4.0 robust, solution architects and researchers need to understand the behavior of DNN-based applications and capture the stochasticity exists in their inference times. Accordingly, in this study, we provide a descriptive analysis of the inference time from two perspectives. First, we perform an application-centric analysis and statistically model the execution time of four categorically different DNN applications on both Amazon and Chameleon clouds. Second, we take a resource-centric approach and analyze a rate-based metric in form of Million Instruction Per Second (MIPS) for heterogeneous machines in the cloud. This non-parametric modeling, achieved via Jackknife and Bootstrap re-sampling methods, provides the confidence interval of MIPS for heterogeneous cloud machines. The findings of this research can be helpful for researchers and cloud solution architects to develop solutions that are robust against the stochastic nature of the inference time of DNN applications in the cloud and can offer a higher QoS to their users and avoid unintended outcomes.
A Perceptual Model for Eccentricity-dependent Spatio-temporal Flicker Fusion and its Applications to Foveated Graphics
May 05, 2021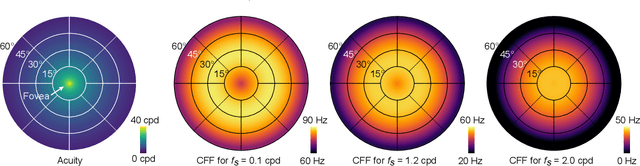
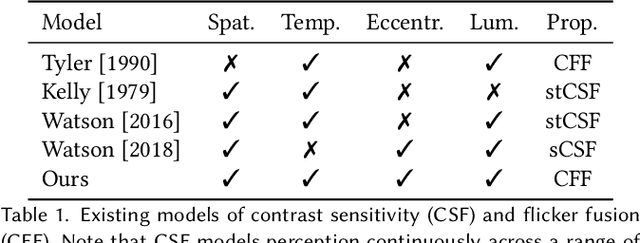

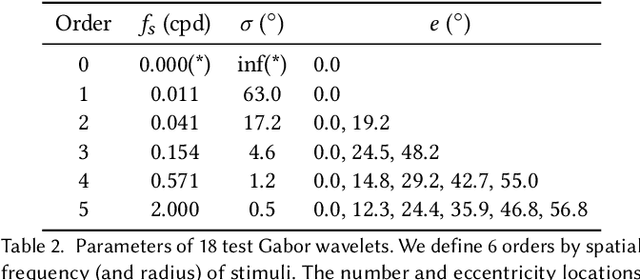
Virtual and augmented reality (VR/AR) displays strive to provide a resolution, framerate and field of view that matches the perceptual capabilities of the human visual system, all while constrained by limited compute budgets and transmission bandwidths of wearable computing systems. Foveated graphics techniques have emerged that could achieve these goals by exploiting the falloff of spatial acuity in the periphery of the visual field. However, considerably less attention has been given to temporal aspects of human vision, which also vary across the retina. This is in part due to limitations of current eccentricity-dependent models of the visual system. We introduce a new model, experimentally measuring and computationally fitting eccentricity-dependent critical flicker fusion thresholds jointly for both space and time. In this way, our model is unique in enabling the prediction of temporal information that is imperceptible for a certain spatial frequency, eccentricity, and range of luminance levels. We validate our model with an image quality user study, and use it to predict potential bandwidth savings 7x higher than those afforded by current spatial-only foveated models. As such, this work forms the enabling foundation for new temporally foveated graphics techniques.
Weakly Supervised Pseudo-Label assisted Learning for ALS Point Cloud Semantic Segmentation
May 05, 2021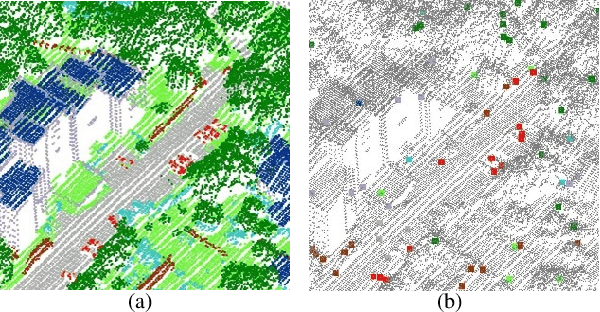
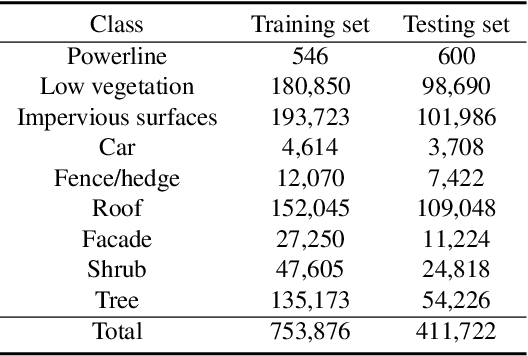
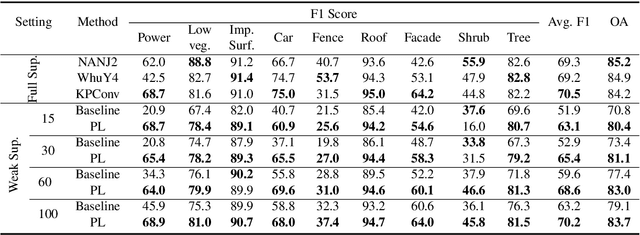
Competitive point cloud semantic segmentation results usually rely on a large amount of labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for three-dimensional point cloud data. Thus, obtaining accurate results with limited ground truth as training data is considerably important. As a simple and effective method, pseudo labels can use information from unlabeled data for training neural networks. In this study, we propose a pseudo-label-assisted point cloud segmentation method with very few sparsely sampled labels that are normally randomly selected for each class. An adaptive thresholding strategy was proposed to generate a pseudo-label based on the prediction probability. Pseudo-label learning is an iterative process, and pseudo labels were updated solely on ground-truth weak labels as the model converged to improve the training efficiency. Experiments using the ISPRS 3D sematic labeling benchmark dataset indicated that our proposed method achieved an equally competitive result compared to that using a full supervision scheme with only up to 2$\unicode{x2030}$ of labeled points from the original training set, with an overall accuracy of 83.7% and an average F1 score of 70.2%.
4DComplete: Non-Rigid Motion Estimation Beyond the Observable Surface
May 05, 2021
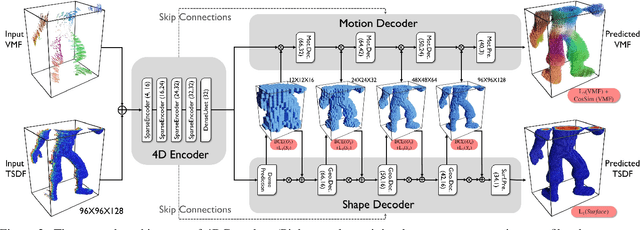

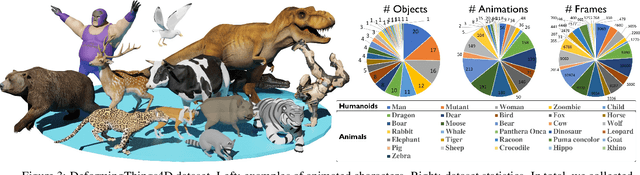
Tracking non-rigidly deforming scenes using range sensors has numerous applications including computer vision, AR/VR, and robotics. However, due to occlusions and physical limitations of range sensors, existing methods only handle the visible surface, thus causing discontinuities and incompleteness in the motion field. To this end, we introduce 4DComplete, a novel data-driven approach that estimates the non-rigid motion for the unobserved geometry. 4DComplete takes as input a partial shape and motion observation, extracts 4D time-space embedding, and jointly infers the missing geometry and motion field using a sparse fully-convolutional network. For network training, we constructed a large-scale synthetic dataset called DeformingThings4D, which consists of 1972 animation sequences spanning 31 different animals or humanoid categories with dense 4D annotation. Experiments show that 4DComplete 1) reconstructs high-resolution volumetric shape and motion field from a partial observation, 2) learns an entangled 4D feature representation that benefits both shape and motion estimation, 3) yields more accurate and natural deformation than classic non-rigid priors such as As-Rigid-As-Possible (ARAP) deformation, and 4) generalizes well to unseen objects in real-world sequences.
Prediction of Reaction Time and Vigilance Variability from Spatiospectral Features of Resting-State EEG in a Long Sustained Attention Task
Oct 21, 2019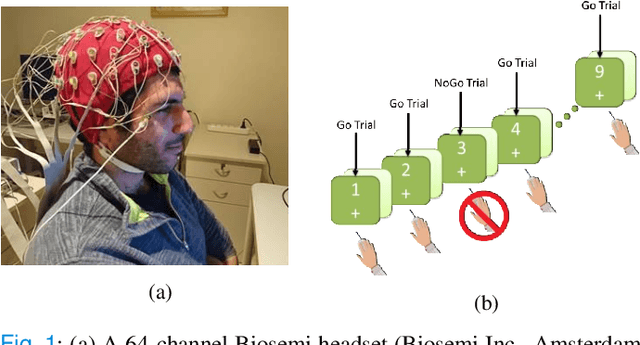
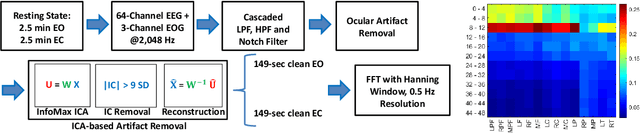
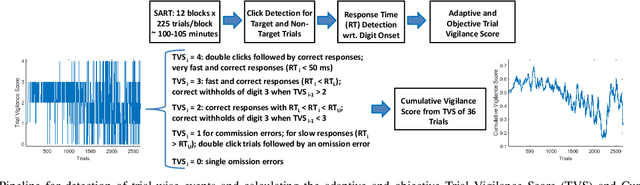
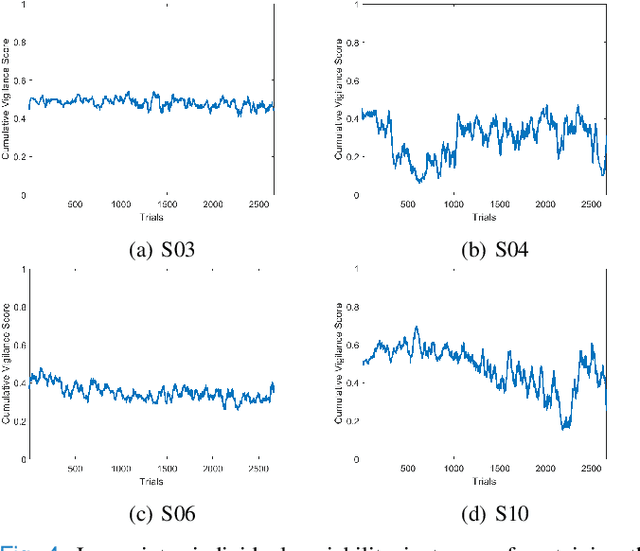
Resting-state brain networks represent the intrinsic state of the brain during the majority of cognitive and sensorimotor tasks. However, no study has yet presented concise predictors of task-induced vigilance variability from spectrospatial features of the pre-task, resting-state electroencephalograms (EEG). We asked ten healthy volunteers (6 females, 4 males) to participate in 105-minute fixed-sequence-varying-duration sessions of sustained attention to response task (SART). A novel and adaptive vigilance scoring scheme was designed based on the performance and response time in consecutive trials, and demonstrated large inter-participant variability in terms of maintaining consistent tonic performance. Multiple linear regression using feature relevance analysis obtained significant predictors of the mean cumulative vigilance score (CVS), mean response time, and variabilities of these scores from the resting-state, band-power ratios of EEG signals, p<0.05. Single-layer neural networks trained with cross-validation also captured different associations for the beta sub-bands. Increase in the gamma (28-48 Hz) and upper beta ratios from the left central and temporal regions predicted slower reactions and more inconsistent vigilance as explained by the increased activation of default mode network (DMN) and differences between the high- and low-attention networks at temporal regions. Higher ratios of parietal alpha from the Brodmann's areas 18, 19, and 37 during the eyes-open states predicted slower responses but more consistent CVS and reactions associated with the superior ability in vigilance maintenance. The proposed framework and these findings on the most stable and significant attention predictors from the intrinsic EEG power ratios can be used to model attention variations during the calibration sessions of BCI applications and vigilance monitoring systems.
Mixture of ELM based experts with trainable gating network
May 25, 2021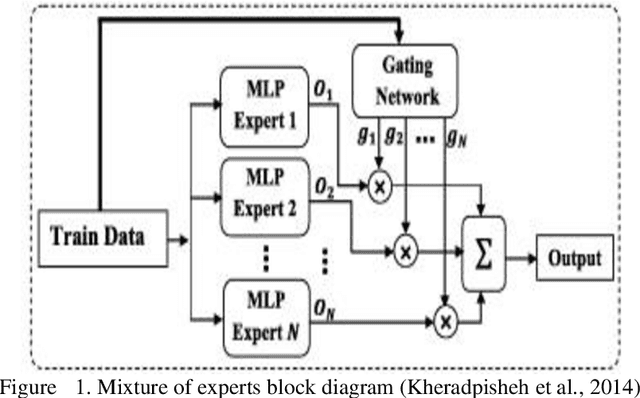
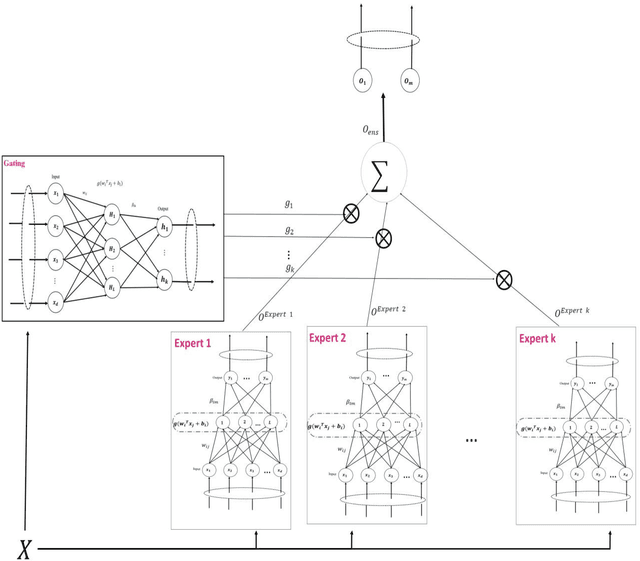
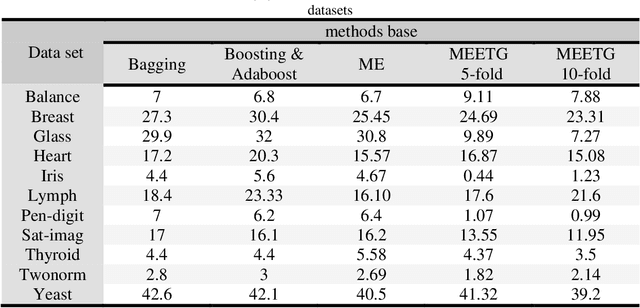
Mixture of experts method is a neural network based ensemble learning that has great ability to improve the overall classification accuracy. This method is based on the divide and conquer principle, in which the problem space is divided between several experts by supervisition of gating network. In this paper, we propose an ensemble learning method based on mixture of experts which is named mixture of ELM based experts with trainable gating network (MEETG) to improve the computing cost and to speed up the learning process of ME. The structure of ME consists of multi layer perceptrons (MLPs) as base experts and gating network, in which gradient-based learning algorithm is applied for training the MLPs which is an iterative and time consuming process. In order to overcome on these problems, we use the advantages of extreme learning machine (ELM) for designing the structure of ME. ELM as a learning algorithm for single hidden-layer feed forward neural networks provides much faster learning process and better generalization ability in comparision with some other traditional learning algorithms. Also, in the proposed method a trainable gating network is applied to aggregate the outputs of the experts dynamically according to the input sample. Our experimental results and statistical analysis on 11 benchmark datasets confirm that MEETG has an acceptable performance in classification problems. Furthermore, our experimental results show that the proposed approach outperforms the original ELM on prediction stability and classification accuracy.
Graph Neural Networks for Traffic Forecasting
Apr 27, 2021



The significant increase in world population and urbanisation has brought several important challenges, in particular regarding the sustainability, maintenance and planning of urban mobility. At the same time, the exponential increase of computing capability and of available sensor and location data have offered the potential for innovative solutions to these challenges. In this work, we focus on the challenge of traffic forecasting and review the recent development and application of graph neural networks (GNN) to this problem. GNNs are a class of deep learning methods that directly process the input as graph data. This leverages more directly the spatial dependencies of traffic data and makes use of the advantages of deep learning producing state-of-the-art results. We introduce and review the emerging topic of GNNs, including their most common variants, with a focus on its application to traffic forecasting. We address the different ways of modelling traffic forecasting as a (temporal) graph, the different approaches developed so far to combine the graph and temporal learning components, as well as current limitations and research opportunities.
Identifying Helpful Sentences in Product Reviews
May 05, 2021
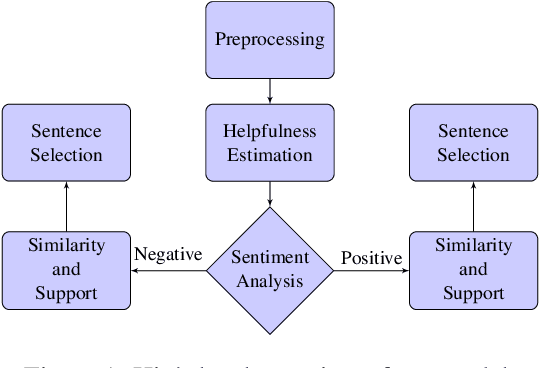

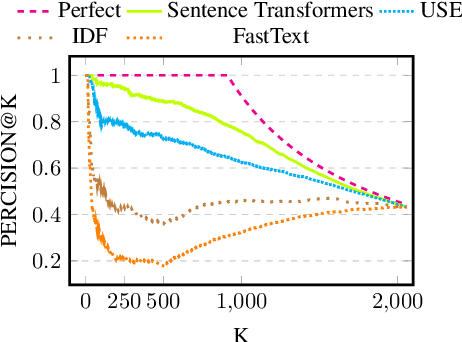
In recent years online shopping has gained momentum and became an important venue for customers wishing to save time and simplify their shopping process. A key advantage of shopping online is the ability to read what other customers are saying about products of interest. In this work, we aim to maintain this advantage in situations where extreme brevity is needed, for example, when shopping by voice. We suggest a novel task of extracting a single representative helpful sentence from a set of reviews for a given product. The selected sentence should meet two conditions: first, it should be helpful for a purchase decision and second, the opinion it expresses should be supported by multiple reviewers. This task is closely related to the task of Multi Document Summarization in the product reviews domain but differs in its objective and its level of conciseness. We collect a dataset in English of sentence helpfulness scores via crowd-sourcing and demonstrate its reliability despite the inherent subjectivity involved. Next, we describe a complete model that extracts representative helpful sentences with positive and negative sentiment towards the product and demonstrate that it outperforms several baselines.
Training a Neural Speech Waveform Model using Spectral Losses of Short-Time Fourier Transform and Continuous Wavelet Transform
Apr 07, 2019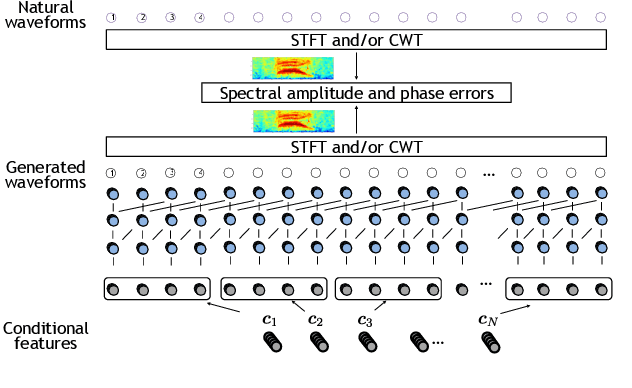

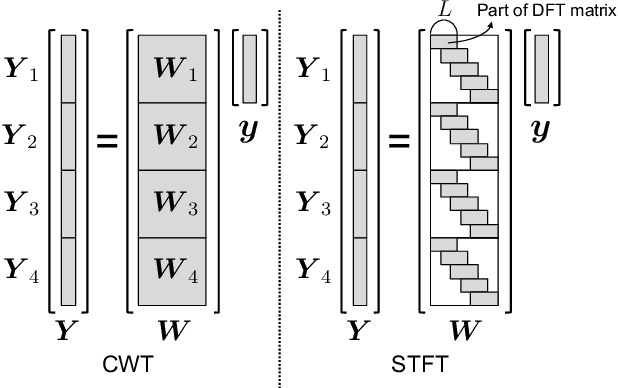
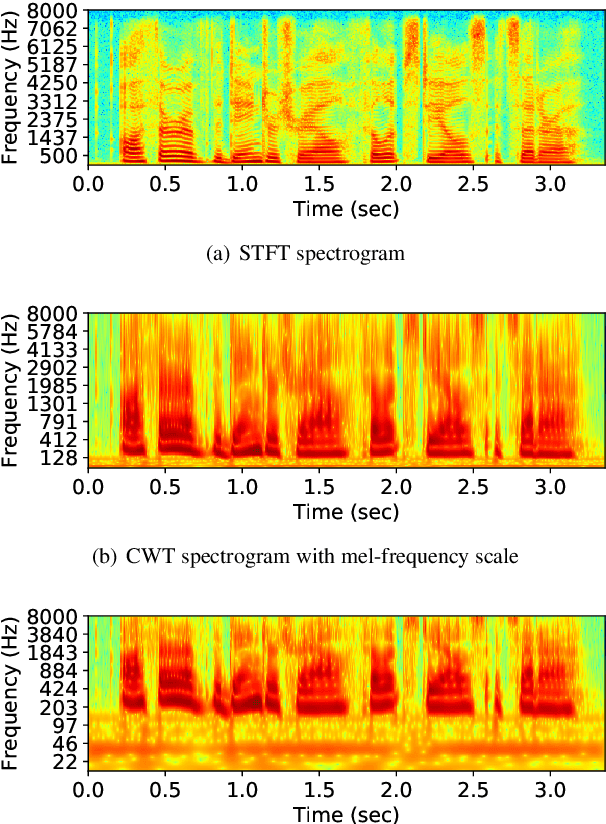
Recently, we proposed short-time Fourier transform (STFT)-based loss functions for training a neural speech waveform model. In this paper, we generalize the above framework and propose a training scheme for such models based on spectral amplitude and phase losses obtained by either STFT or continuous wavelet transform (CWT), or both of them. Since CWT is capable of having time and frequency resolutions different from those of STFT and is cable of considering those closer to human auditory scales, the proposed loss functions could provide complementary information on speech signals. Experimental results showed that it is possible to train a high-quality model by using the proposed CWT spectral loss and is as good as one using STFT-based loss.