 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BM-NAS: Bilevel Multimodal Neural Architecture Search
Apr 19, 2021
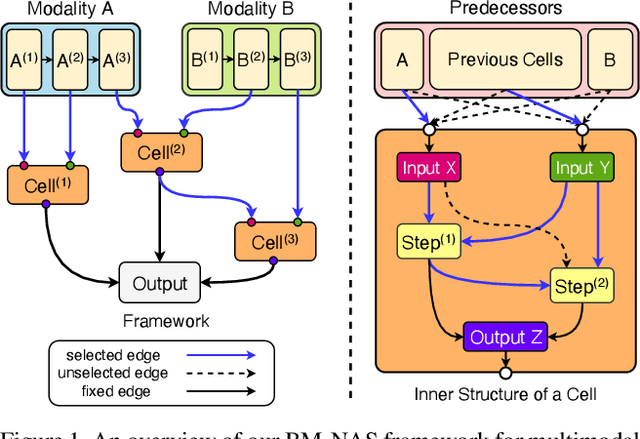
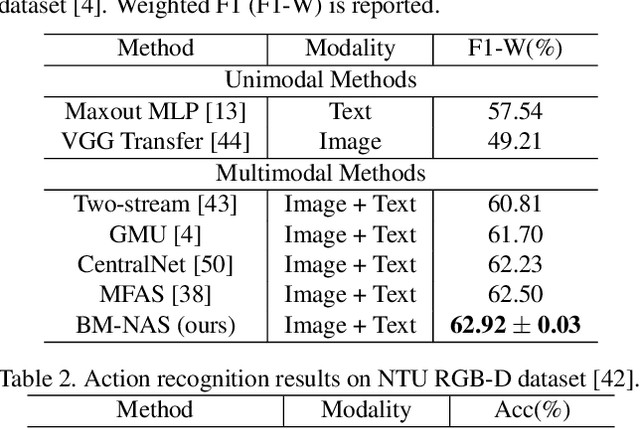
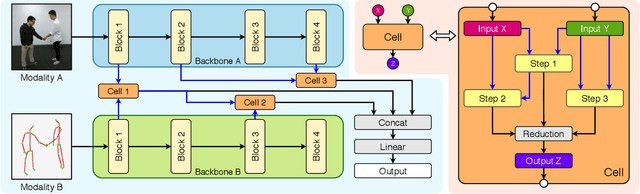
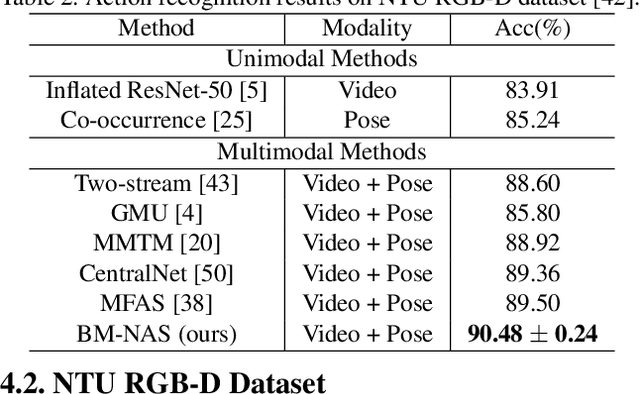
Deep neural networks (DNNs) have shown superior performances on various multimodal learning problems. However, it often requires huge efforts to adapt DNNs to individual multimodal tasks by manually engineering unimodal features and designing multimodal feature fusion strategies. This paper proposes Bilevel Multimodal Neural Architecture Search (BM-NAS) framework, which makes the architecture of multimodal fusion models fully searchable via a bilevel searching scheme. At the upper level, BM-NAS selects the inter/intra-modal feature pairs from the pretrained unimodal backbones. At the lower level, BM-NAS learns the fusion strategy for each feature pair, which is a combination of predefined primitive operations. The primitive operations are elaborately designed and they can be flexibly combined to accommodate various effective feature fusion modules such as multi-head attention (Transformer) and Attention on Attention (AoA). Experimental results on three multimodal tasks demonstrate the effectiveness and efficiency of the proposed BM-NAS framework. BM-NAS achieves competitive performances with much less search time and fewer model parameters in comparison with the existing generalized multimodal NAS methods.
Fostering Generalization in Single-view 3D Reconstruction by Learning a Hierarchy of Local and Global Shape Priors
Apr 01, 2021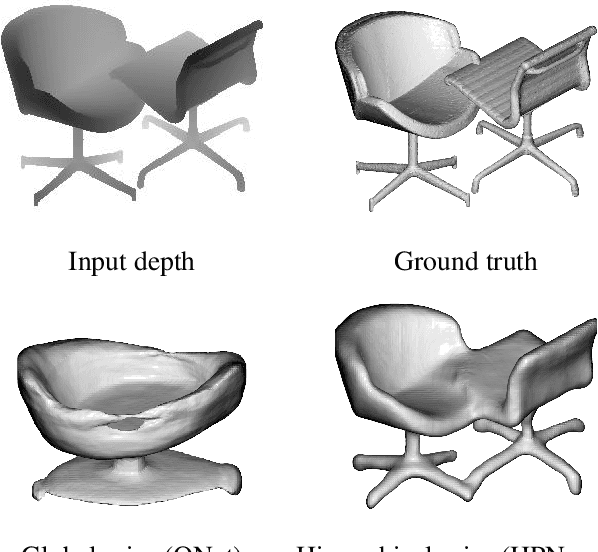
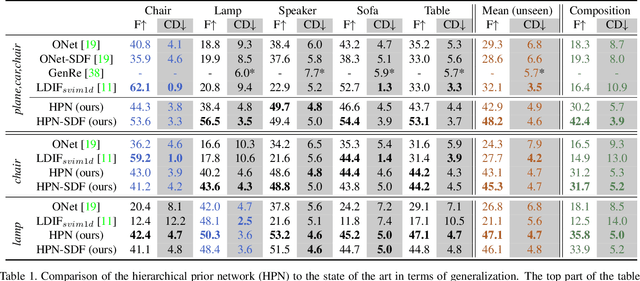
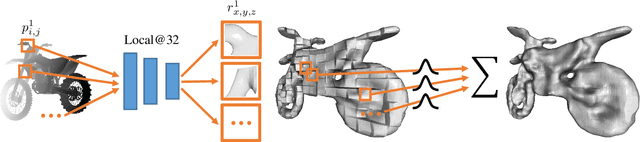
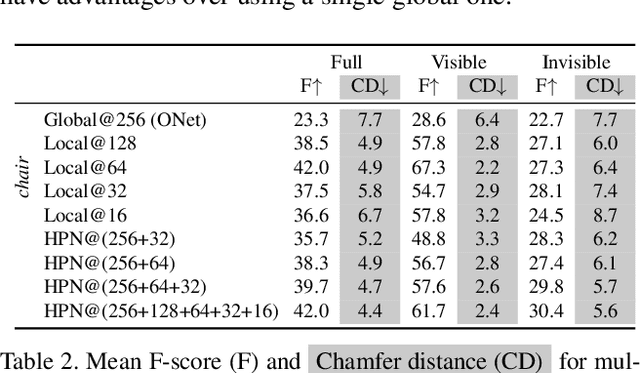
Single-view 3D object reconstruction has seen much progress, yet methods still struggle generalizing to novel shapes unseen during training. Common approaches predominantly rely on learned global shape priors and, hence, disregard detailed local observations. In this work, we address this issue by learning a hierarchy of priors at different levels of locality from ground truth input depth maps. We argue that exploiting local priors allows our method to efficiently use input observations, thus improving generalization in visible areas of novel shapes. At the same time, the combination of local and global priors enables meaningful hallucination of unobserved parts resulting in consistent 3D shapes. We show that the hierarchical approach generalizes much better than the global approach. It generalizes not only between different instances of a class but also across classes and to unseen arrangements of objects.
Counterfactual Inference of the Mean Outcome under a Convergence of Average Logging Probability
Feb 17, 2021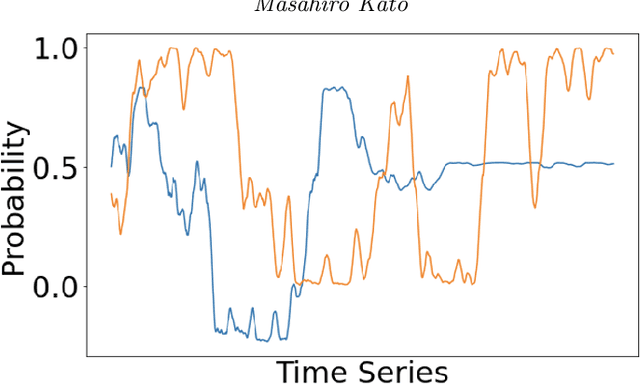
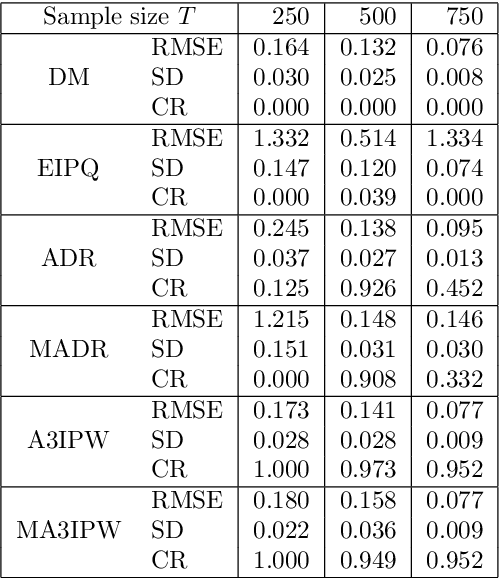
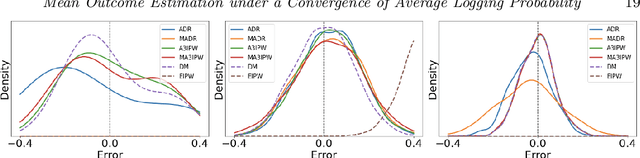
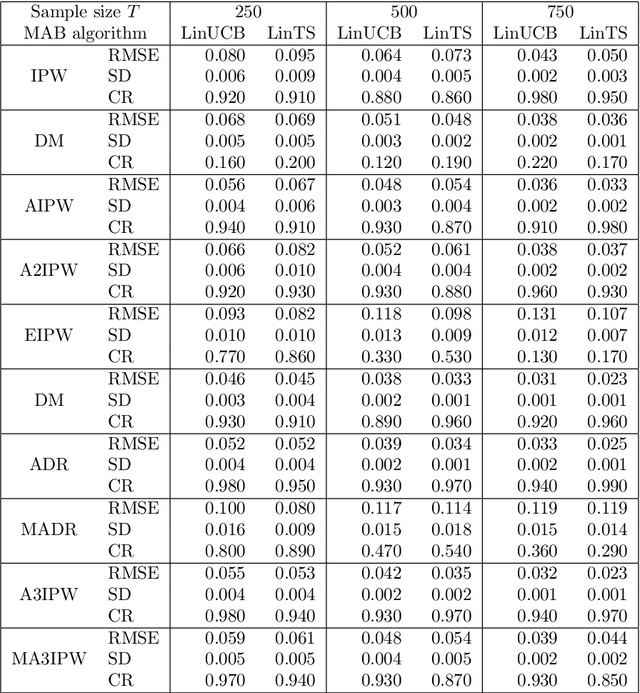
Adaptive experiments, including efficient average treatment effect estimation and multi-armed bandit algorithms, have garnered attention in various applications, such as social experiments, clinical trials, and online advertisement optimization. This paper considers estimating the mean outcome of an action from samples obtained in adaptive experiments. In causal inference, the mean outcome of an action has a crucial role, and the estimation is an essential task, where the average treatment effect estimation and off-policy value estimation are its variants. In adaptive experiments, the probability of choosing an action (logging probability) is allowed to be sequentially updated based on past observations. Due to this logging probability depending on the past observations, the samples are often not independent and identically distributed (i.i.d.), making developing an asymptotically normal estimator difficult. A typical approach for this problem is to assume that the logging probability converges in a time-invariant function. However, this assumption is restrictive in various applications, such as when the logging probability fluctuates or becomes zero at some periods. To mitigate this limitation, we propose another assumption that the average logging probability converges to a time-invariant function and show the doubly robust (DR) estimator's asymptotic normality. Under the assumption, the logging probability itself can fluctuate or be zero for some actions. We also show the empirical properties by simulations.
Understanding the Performance of Knowledge Graph Embeddings in Drug Discovery
May 17, 2021
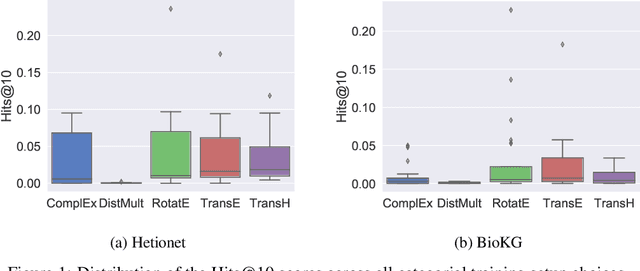
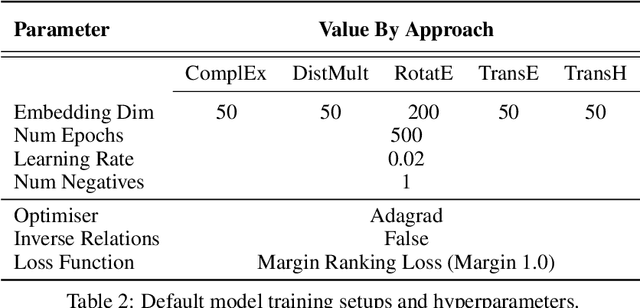
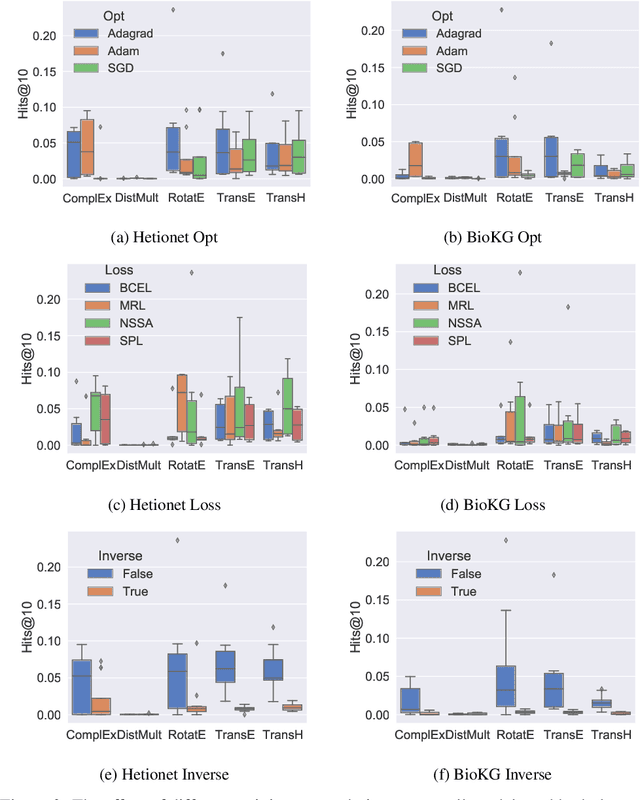
Knowledge Graphs (KG) and associated Knowledge Graph Embedding (KGE) models have recently begun to be explored in the context of drug discovery and have the potential to assist in key challenges such as target identification. In the drug discovery domain, KGs can be employed as part of a process which can result in lab-based experiments being performed, or impact on other decisions, incurring significant time and financial costs and most importantly, ultimately influencing patient healthcare. For KGE models to have impact in this domain, a better understanding of not only of performance, but also the various factors which determine it, is required. In this study we investigate, over the course of many thousands of experiments, the predictive performance of five KGE models on two public drug discovery-oriented KGs. Our goal is not to focus on the best overall model or configuration, instead we take a deeper look at how performance can be affected by changes in the training setup, choice of hyperparameters, model parameter initialisation seed and different splits of the datasets. Our results highlight that these factors have significant impact on performance and can even affect the ranking of models. Indeed these factors should be reported along with model architectures to ensure complete reproducibility and fair comparisons of future work, and we argue this is critical for the acceptance of use, and impact of KGEs in a biomedical setting. To aid reproducibility of our own work, we release all experimentation code.
Concept Drift and Covariate Shift Detection Ensemble with Lagged Labels
Dec 15, 2020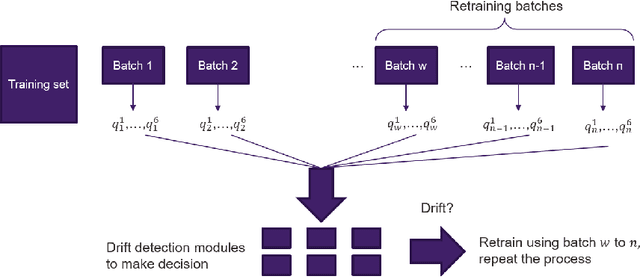
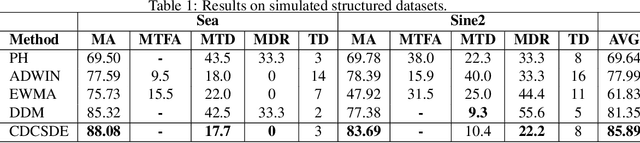
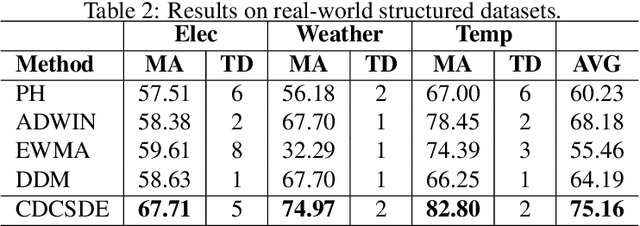
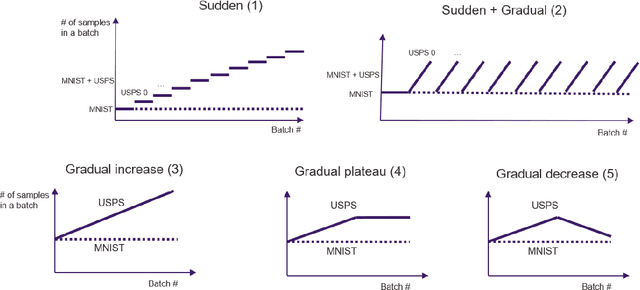
In model serving, having one fixed model during the entire often life-long inference process is usually detrimental to model performance, as data distribution evolves over time, resulting in lack of reliability of the model trained on historical data. It is important to detect changes and retrain the model in time. The existing methods generally have three weaknesses: 1) using only classification error rate as signal, 2) assuming ground truth labels are immediately available after features from samples are received and 3) unable to decide what data to use to retrain the model when change occurs. We address the first problem by utilizing six different signals to capture a wide range of characteristics of data, and we address the second problem by allowing lag of labels, where labels of corresponding features are received after a lag in time. For the third problem, our proposed method automatically decides what data to use to retrain based on the signals. Extensive experiments on structured and unstructured data for different type of data changes establish that our method consistently outperforms the state-of-the-art methods by a large margin.
Slow Momentum with Fast Reversion: A Trading Strategy Using Deep Learning and Changepoint Detection
May 28, 2021Momentum strategies are an important part of alternative investments and are at the heart of commodity trading advisors (CTAs). These strategies have however been found to have difficulties adjusting to rapid changes in market conditions, such as during the 2020 market crash. In particular, immediately after momentum turning points, where a trend reverses from an uptrend (downtrend) to a downtrend (uptrend), time-series momentum (TSMOM) strategies are prone to making bad bets. To improve the response to regime change, we introduce a novel approach, where we insert an online change-point detection (CPD) module into a Deep Momentum Network (DMN) [1904.04912] pipeline, which uses an LSTM deep-learning architecture to simultaneously learn both trend estimation and position sizing. Furthermore, our model is able to optimise the way in which it balances 1) a slow momentum strategy which exploits persisting trends, but does not overreact to localised price moves, and 2) a fast mean-reversion strategy regime by quickly flipping its position, then swapping it back again to exploit localised price moves. Our CPD module outputs a changepoint location and severity score, allowing our model to learn to respond to varying degrees of disequilibrium, or smaller and more localised changepoints, in a data driven manner. Using a portfolio of 50, liquid, continuous futures contracts over the period 1990-2020, the addition of the CPD module leads to an improvement in Sharpe ratio of $33\%$. Even more notably, this module is especially beneficial in periods of significant nonstationarity, and in particular, over the most recent years tested (2015-2020) the performance boost is approximately $400\%$. This is especially interesting as traditional momentum strategies have been underperforming in this period.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 24, 2021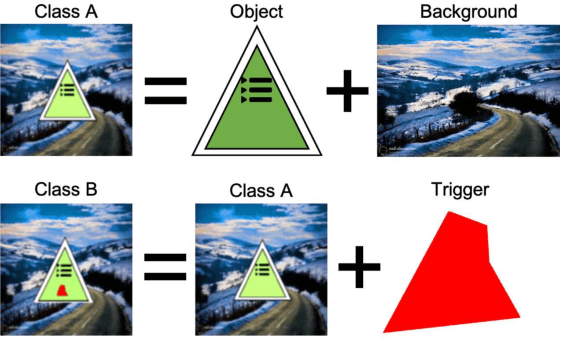

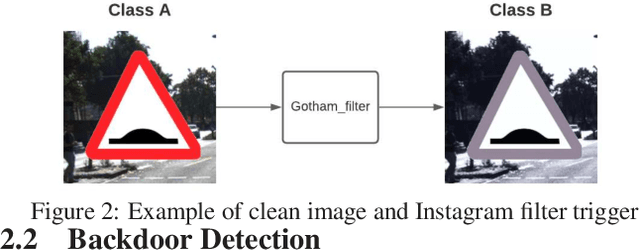
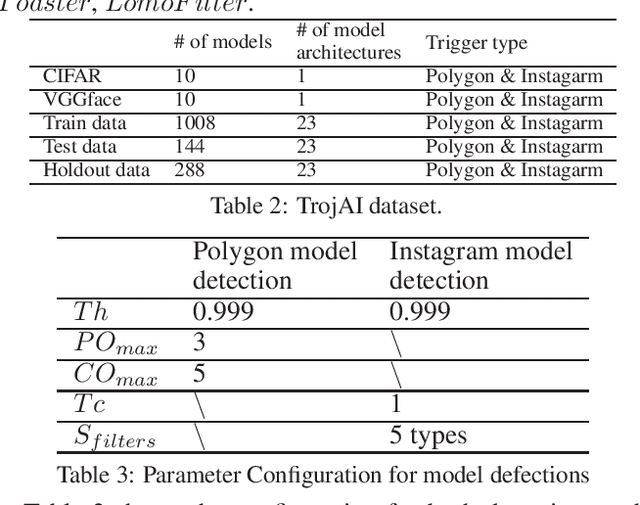
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.
Transparent FPGA Acceleration with TensorFlow
Feb 02, 2021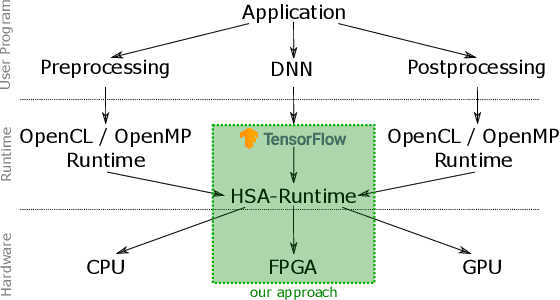
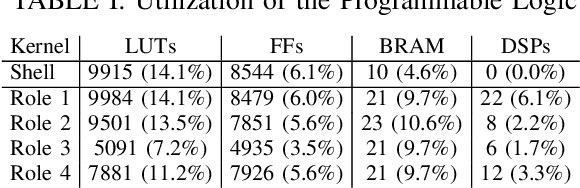

Today, artificial neural networks are one of the major innovators pushing the progress of machine learning. This has particularly affected the development of neural network accelerating hardware. However, since most of these architectures require specialized toolchains, there is a certain amount of additional effort for developers each time they want to make use of a new deep learning accelerator. Furthermore the flexibility of the device is bound to the architecture itself, as well as to the functionality of the runtime environment. In this paper we propose a toolflow using TensorFlow as frontend, thus offering developers the opportunity of using a familiar environment. On the backend we use an FPGA, which is addressable via an HSA runtime environment. In this way we are able to hide the complexity of controlling new hardware from the user, while at the same time maintaining a high amount of flexibility. This can be achieved by our HSA toolflow, since the hardware is not statically configured with the structure of the network. Instead, it can be dynamically reconfigured during runtime with the respective kernels executed by the network and simultaneously from other sources e.g. OpenCL/OpenMP.
Continual Learning with Fully Probabilistic Models
Apr 19, 2021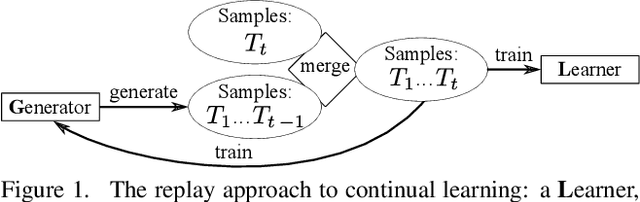

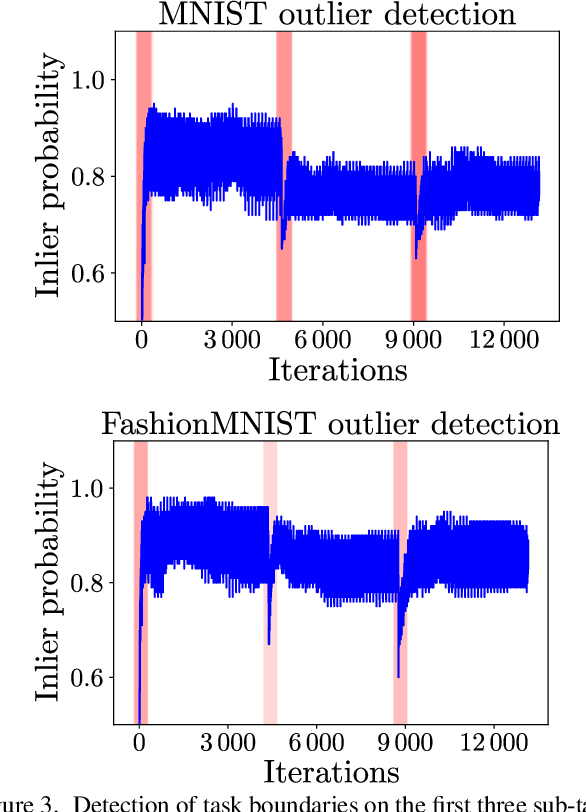
We present an approach for continual learning (CL) that is based on fully probabilistic (or generative) models of machine learning. In contrast to, e.g., GANs that are "generative" in the sense that they can generate samples, fully probabilistic models aim at modeling the data distribution directly. Consequently, they provide functionalities that are highly relevant for continual learning, such as density estimation (outlier detection) and sample generation. As a concrete realization of generative continual learning, we propose Gaussian Mixture Replay (GMR). GMR is a pseudo-rehearsal approach using a Gaussian Mixture Model (GMM) instance for both generator and classifier functionalities. Relying on the MNIST, FashionMNIST and Devanagari benchmarks, we first demonstrate unsupervised task boundary detection by GMM density estimation, which we also use to reject untypical generated samples. In addition, we show that GMR is capable of class-conditional sampling in the way of a cGAN. Lastly, we verify that GMR, despite its simple structure, achieves state-of-the-art performance on common class-incremental learning problems at very competitive time and memory complexity.
Sentiment and Emotion Classification of Epidemic Related Bilingual data from Social Media
May 04, 2021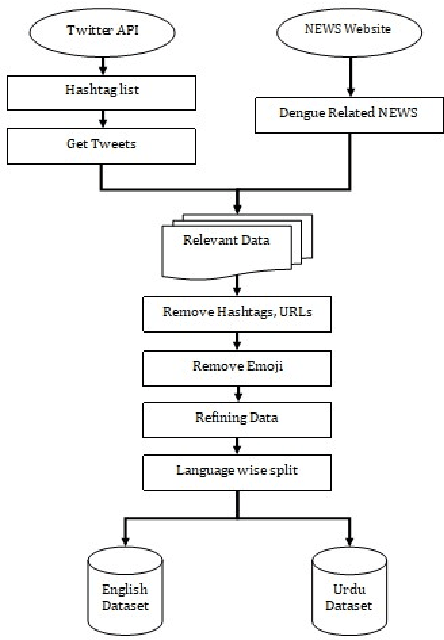
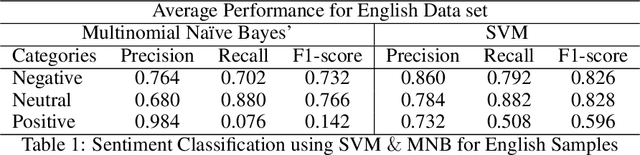
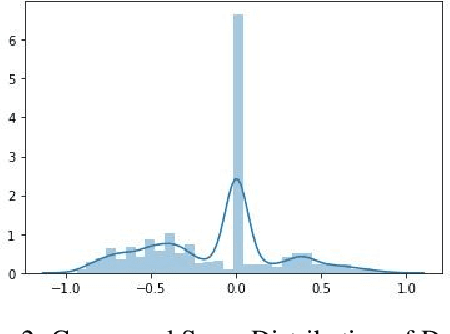
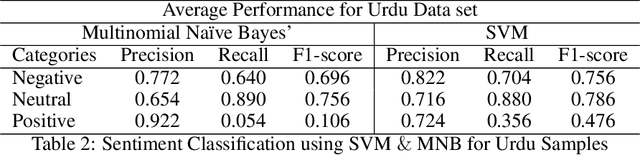
In recent years, sentiment analysis and emotion classification are two of the most abundantly used techniques in the field of Natural Language Processing (NLP). Although sentiment analysis and emotion classification are used commonly in applications such as analyzing customer reviews, the popularity of candidates contesting in elections, and comments about various sporting events; however, in this study, we have examined their application for epidemic outbreak detection. Early outbreak detection is the key to deal with epidemics effectively, however, the traditional ways of outbreak detection are time-consuming which inhibits prompt response from the respective departments. Social media platforms such as Twitter, Facebook, Instagram, etc. allow the users to express their thoughts related to different aspects of life, and therefore, serve as a substantial source of information in such situations. The proposed study exploits the bilingual (Urdu and English) data from Twitter and NEWS websites related to the dengue epidemic in Pakistan, and sentiment analysis and emotion classification are performed to acquire deep insights from the data set for gaining a fair idea related to an epidemic outbreak. Machine learning and deep learning algorithms have been used to train and implement the models for the execution of both tasks. The comparative performance of each model has been evaluated using accuracy, precision, recall, and f1-measure.