 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition
Apr 19, 2021
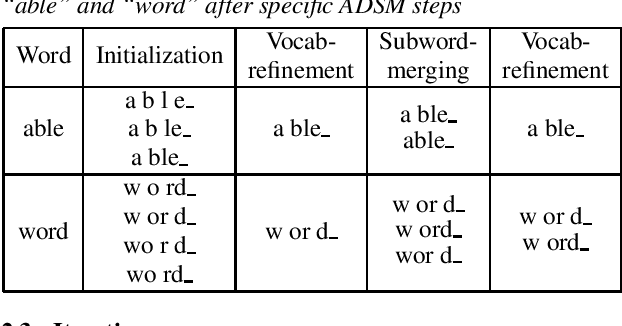
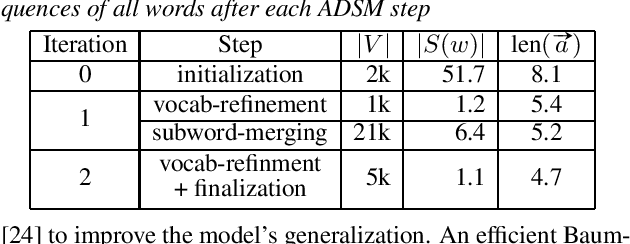
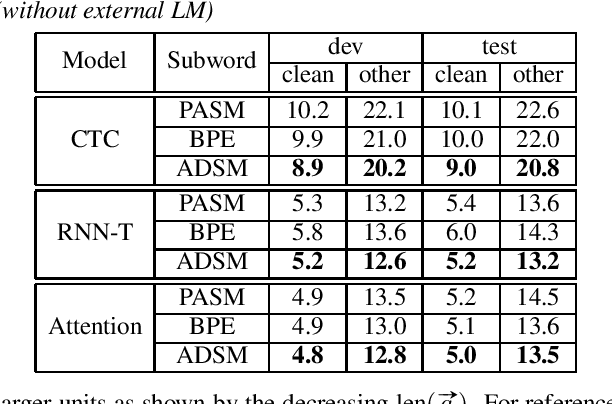

Subword units are commonly used for end-to-end automatic speech recognition (ASR), while a fully acoustic-oriented subword modeling approach is somewhat missing. We propose an acoustic data-driven subword modeling (ADSM) approach that adapts the advantages of several text-based and acoustic-based subword methods into one pipeline. With a fully acoustic-oriented label design and learning process, ADSM produces acoustic-structured subword units and acoustic-matched target sequence for further ASR training. The obtained ADSM labels are evaluated with different end-to-end ASR approaches including CTC, RNN-transducer and attention models. Experiments on the LibriSpeech corpus show that ADSM clearly outperforms both byte pair encoding (BPE) and pronunciation-assisted subword modeling (PASM) in all cases. Detailed analysis shows that ADSM achieves acoustically more logical word segmentation and more balanced sequence length, and thus, is suitable for both time-synchronous and label-synchronous models. We also briefly describe how to apply acoustic-based subword regularization and unseen text segmentation using ADSM.
Interpretable Models for Granger Causality Using Self-explaining Neural Networks
Jan 19, 2021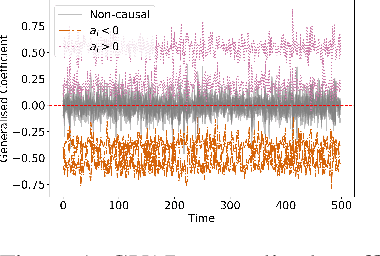
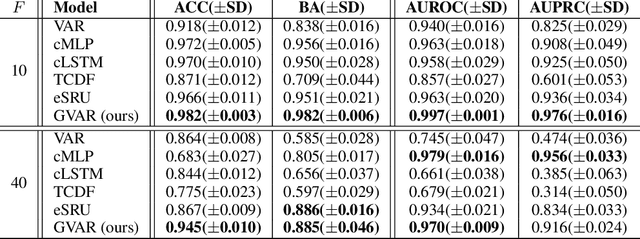


Exploratory analysis of time series data can yield a better understanding of complex dynamical systems. Granger causality is a practical framework for analysing interactions in sequential data, applied in a wide range of domains. In this paper, we propose a novel framework for inferring multivariate Granger causality under nonlinear dynamics based on an extension of self-explaining neural networks. This framework is more interpretable than other neural-network-based techniques for inferring Granger causality, since in addition to relational inference, it also allows detecting signs of Granger-causal effects and inspecting their variability over time. In comprehensive experiments on simulated data, we show that our framework performs on par with several powerful baseline methods at inferring Granger causality and that it achieves better performance at inferring interaction signs. The results suggest that our framework is a viable and more interpretable alternative to sparse-input neural networks for inferring Granger causality.
Learning Free-Form Deformation for 3D Face Reconstruction from In-The-Wild Images
May 31, 2021
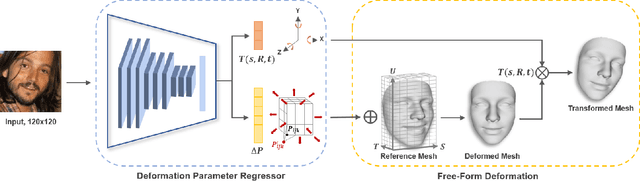

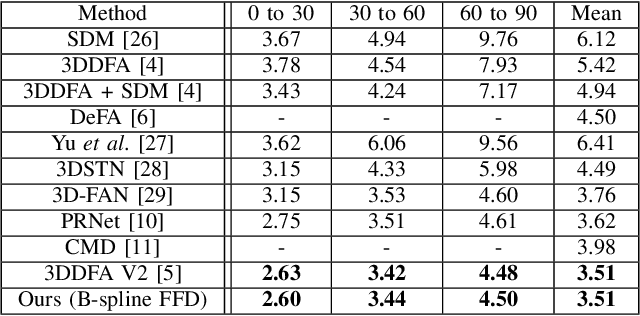
The 3D Morphable Model (3DMM), which is a Principal Component Analysis (PCA) based statistical model that represents a 3D face using linear basis functions, has shown promising results for reconstructing 3D faces from single-view in-the-wild images. However, 3DMM has restricted representation power due to the limited number of 3D scans and the global linear basis. To address the limitations of 3DMM, we propose a straightforward learning-based method that reconstructs a 3D face mesh through Free-Form Deformation (FFD) for the first time. FFD is a geometric modeling method that embeds a reference mesh within a parallelepiped grid and deforms the mesh by moving the sparse control points of the grid. As FFD is based on mathematically defined basis functions, it has no limitation in representation power. Thus, we can recover accurate 3D face meshes by estimating appropriate deviation of control points as deformation parameters. Although both 3DMM and FFD are parametric models, it is difficult to predict the effect of the 3DMM parameters on the face shape, while the deformation parameters of FFD are interpretable in terms of their effect on the final shape of the mesh. This practical advantage of FFD allows the resulting mesh and control points to serve as a good starting point for 3D face modeling, in that ordinary users can fine-tune the mesh by using widely available 3D software tools. Experiments on multiple datasets demonstrate how our method successfully estimates the 3D face geometry and facial expressions from 2D face images, achieving comparable performance to the state-of-the-art methods.
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021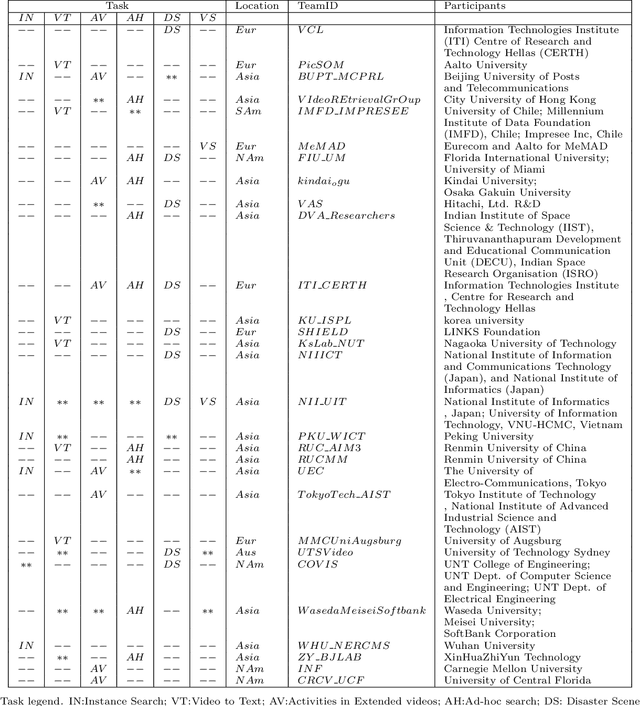

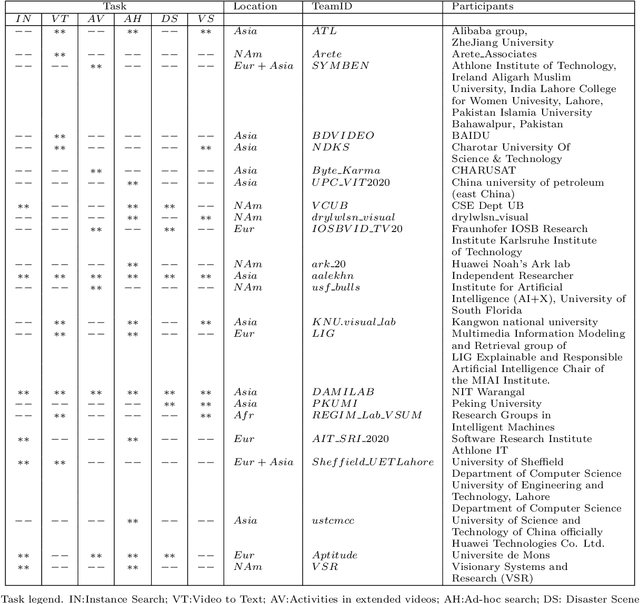
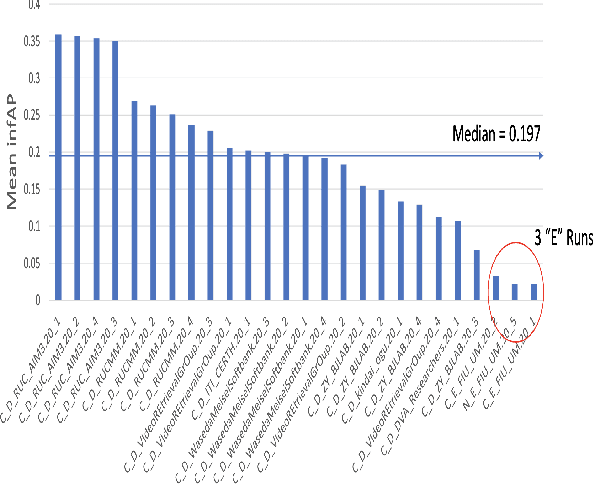
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
An Oracle for Guiding Large-Scale Model/Hybrid Parallel Training of Convolutional Neural Networks
Apr 19, 2021
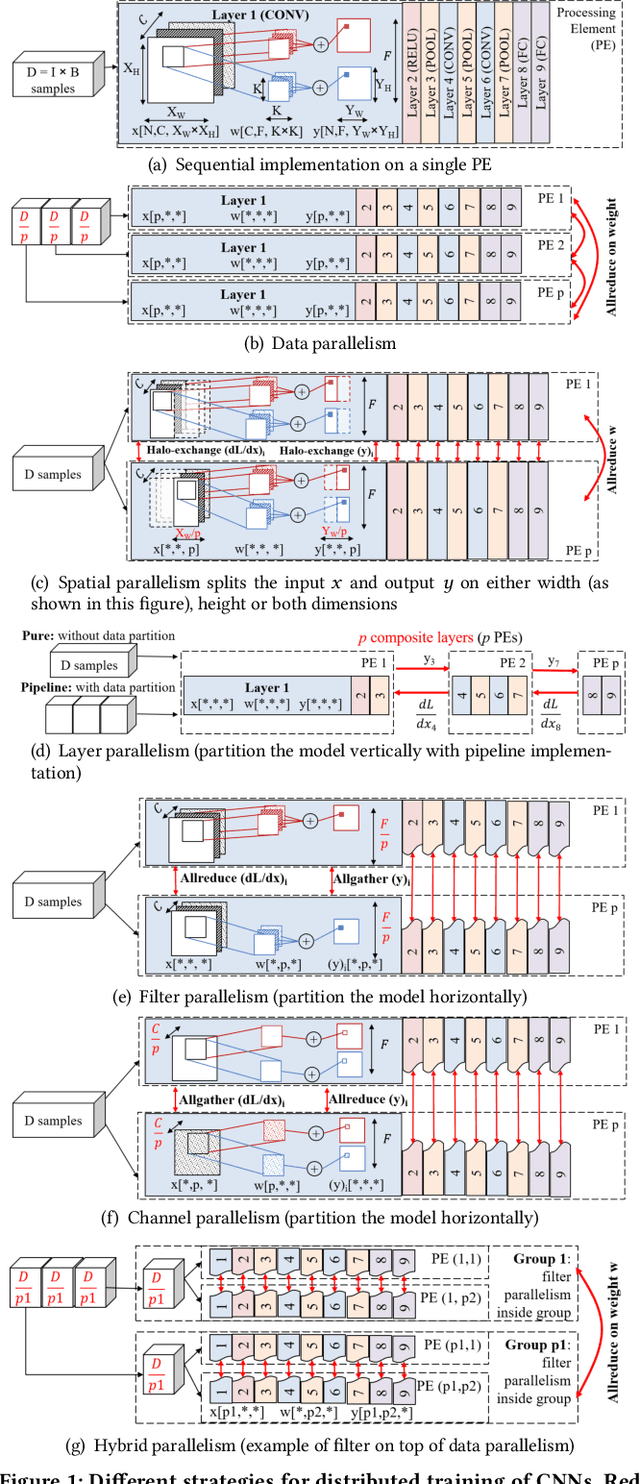
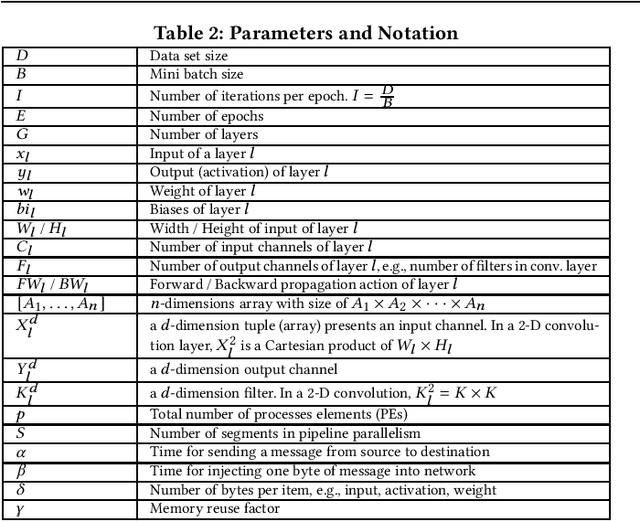
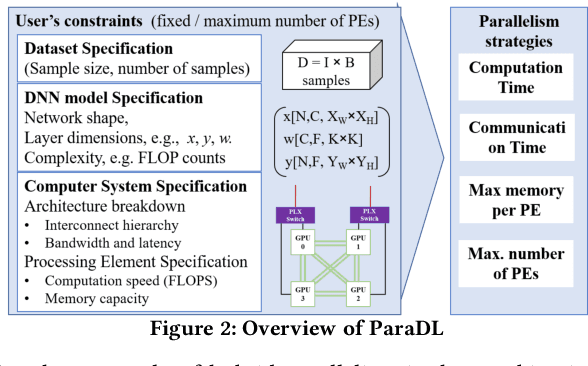
Deep Neural Network (DNN) frameworks use distributed training to enable faster time to convergence and alleviate memory capacity limitations when training large models and/or using high dimension inputs. With the steady increase in datasets and model sizes, model/hybrid parallelism is deemed to have an important role in the future of distributed training of DNNs. We analyze the compute, communication, and memory requirements of Convolutional Neural Networks (CNNs) to understand the trade-offs between different parallelism approaches on performance and scalability. We leverage our model-driven analysis to be the basis for an oracle utility which can help in detecting the limitations and bottlenecks of different parallelism approaches at scale. We evaluate the oracle on six parallelization strategies, with four CNN models and multiple datasets (2D and 3D), on up to 1024 GPUs. The results demonstrate that the oracle has an average accuracy of about 86.74% when compared to empirical results, and as high as 97.57% for data parallelism.
Honest-but-Curious Nets: Sensitive Attributes of Private Inputs can be Secretly Coded into the Entropy of Classifiers' Outputs
May 25, 2021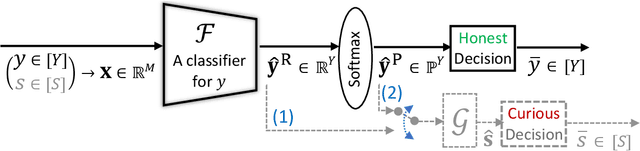
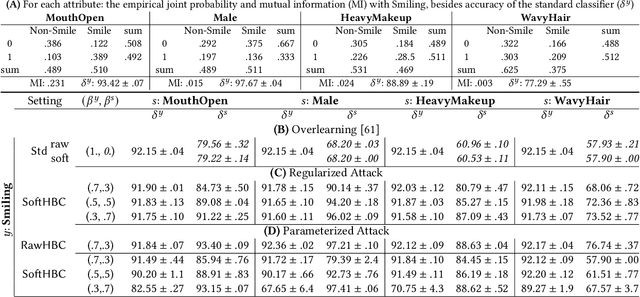
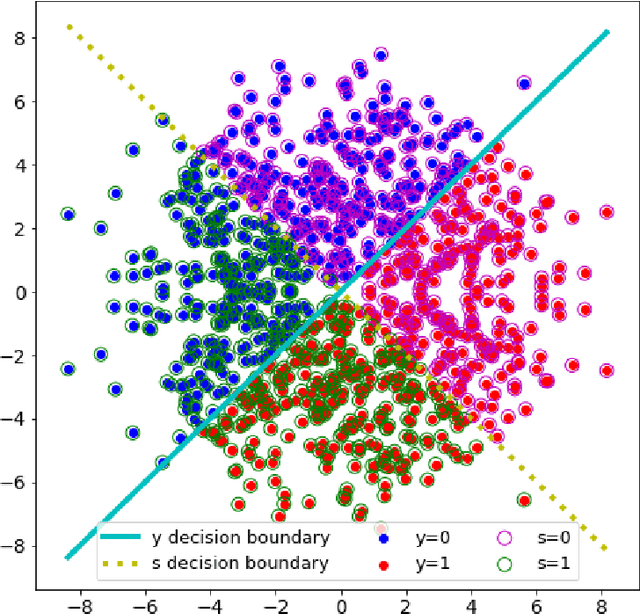
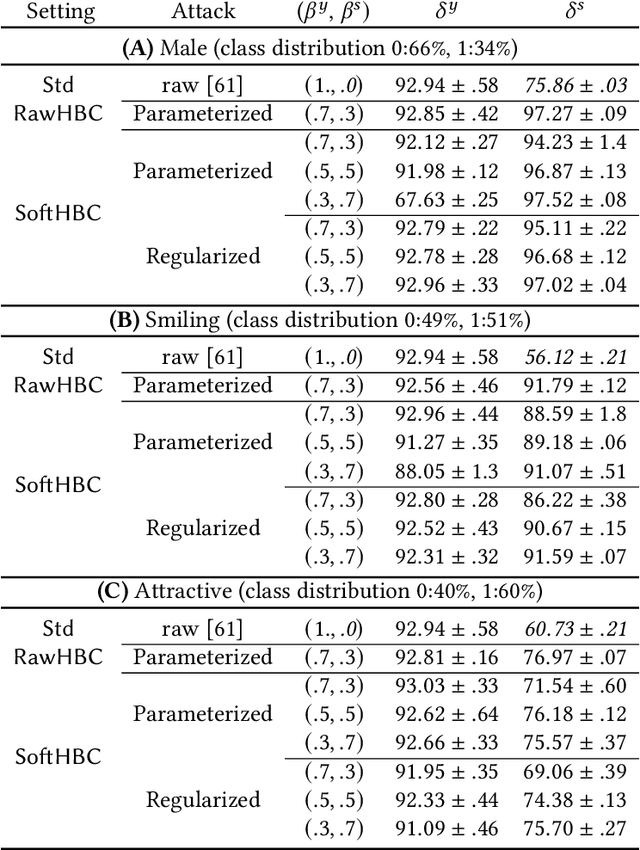
It is known that deep neural networks, trained for the classification of a non-sensitive target attribute, can reveal sensitive attributes of their input data; through features of different granularity extracted by the classifier. We, taking a step forward, show that deep classifiers can be trained to secretly encode a sensitive attribute of users' input data, at inference time, into the classifier's outputs for the target attribute. An attack that works even if users have a white-box view of the classifier, and can keep all internal representations hidden except for the classifier's estimation of the target attribute. We introduce an information-theoretical formulation of such adversaries and present efficient empirical implementations for training honest-but-curious (HBC) classifiers based on this formulation: deep models that can be accurate in predicting the target attribute, but also can utilize their outputs to secretly encode a sensitive attribute. Our evaluations on several tasks in real-world datasets show that a semi-trusted server can build a classifier that is not only perfectly honest but also accurately curious. Our work highlights a vulnerability that can be exploited by malicious machine learning service providers to attack their user's privacy in several seemingly safe scenarios; such as encrypted inferences, computations at the edge, or private knowledge distillation. We conclude by showing the difficulties in distinguishing between standard and HBC classifiers and discussing potential proactive defenses against this vulnerability of deep classifiers.
MediaSpeech: Multilanguage ASR Benchmark and Dataset
Mar 30, 2021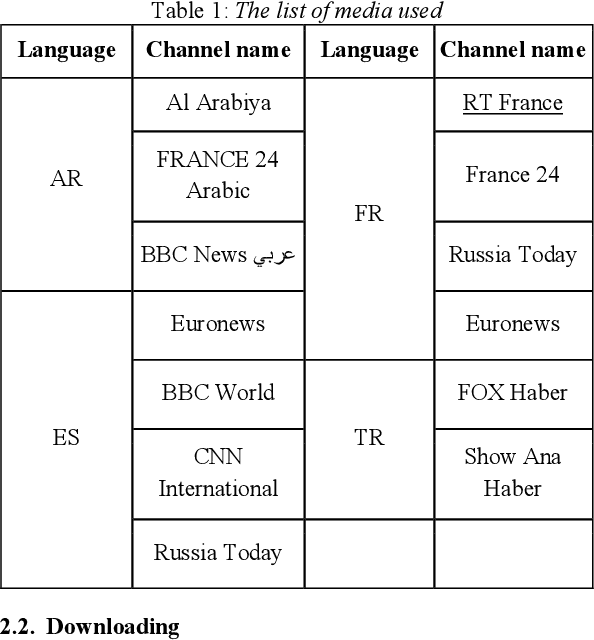
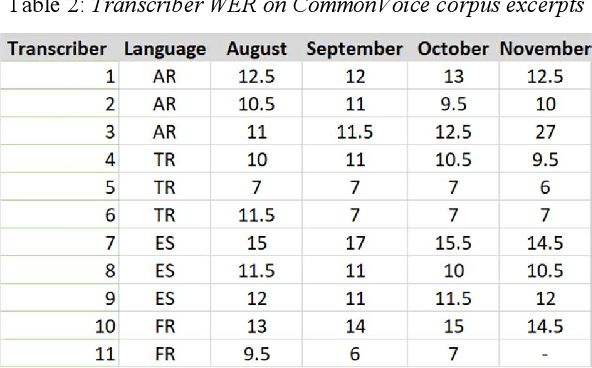
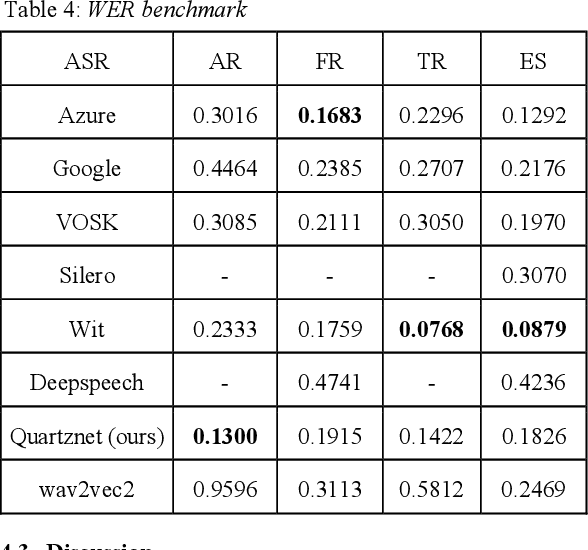
The performance of automated speech recognition (ASR) systems is well known to differ for varied application domains. At the same time, vendors and research groups typically report ASR quality results either for limited use simplistic domains (audiobooks, TED talks), or proprietary datasets. To fill this gap, we provide an open-source 10-hour ASR system evaluation dataset NTR MediaSpeech for 4 languages: Spanish, French, Turkish and Arabic. The dataset was collected from the official youtube channels of media in the respective languages, and manually transcribed. We estimate that the WER of the dataset is under 5%. We have benchmarked many ASR systems available both commercially and freely, and provide the benchmark results. We also open-source baseline QuartzNet models for each language.
Incident Detection on Junctions Using Image Processing
Apr 27, 2021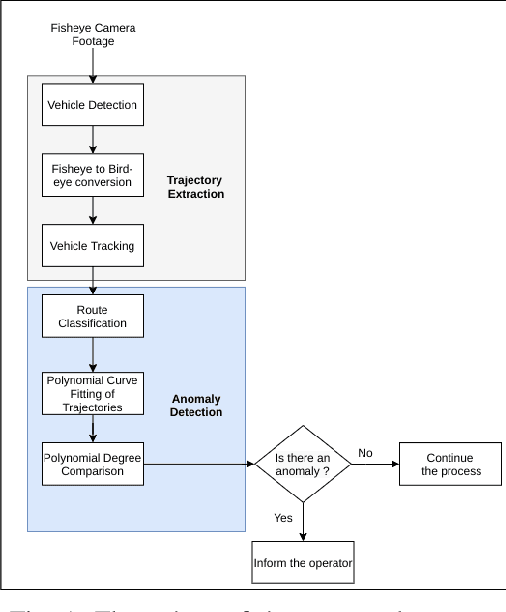
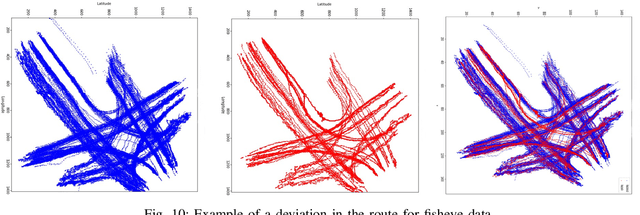

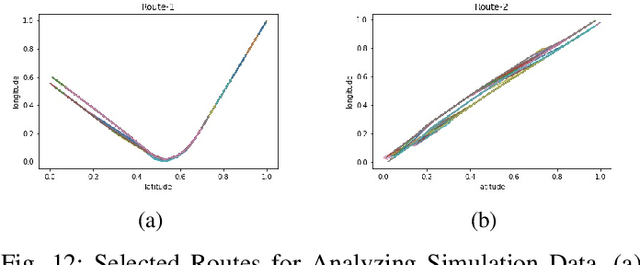
In traffic management, it is a very important issue to shorten the response time by detecting the incidents (accident, vehicle breakdown, an object falling on the road, etc.) and informing the corresponding personnel. In this study, an anomaly detection framework for road junctions is proposed. The final judgment is based on the trajectories followed by the vehicles. Trajectory information is provided by vehicle detection and tracking algorithms on visual data streamed from a fisheye camera. Deep learning algorithms are used for vehicle detection, and Kalman Filter is used for tracking. To observe the trajectories more accurately, the detected vehicle coordinates are transferred to the bird's eye view coordinates using the lens distortion model prediction algorithm. The system determines whether there is an abnormality in trajectories by comparing historical trajectory data and instantaneous incoming data. The proposed system has achieved 84.6% success in vehicle detection and 96.8% success in abnormality detection on synthetic data. The system also works with a 97.3% success rate in detecting abnormalities on real data.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021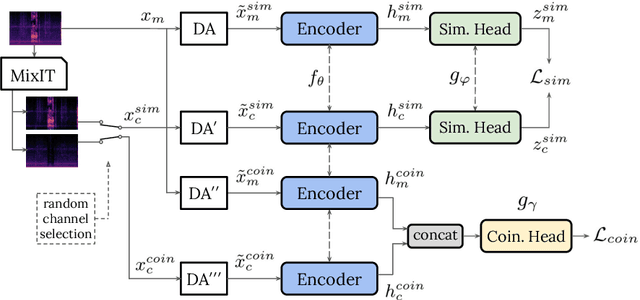
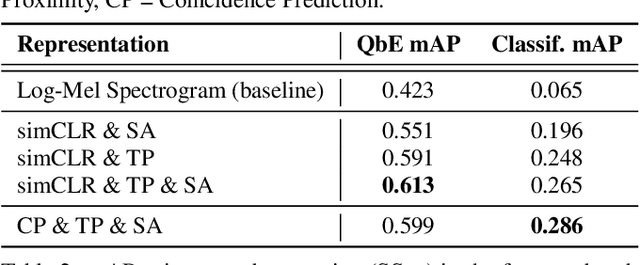

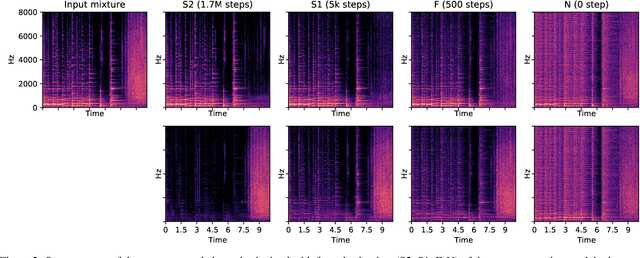
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
Pivotal Tuning for Latent-based Editing of Real Images
Jun 10, 2021
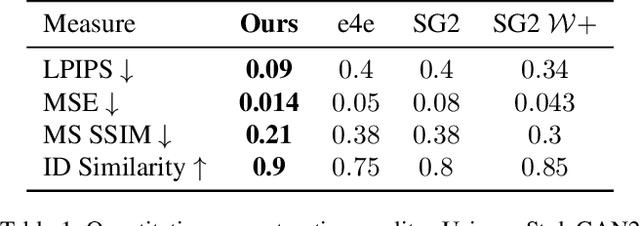
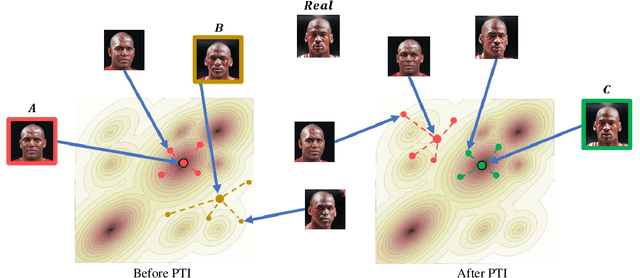
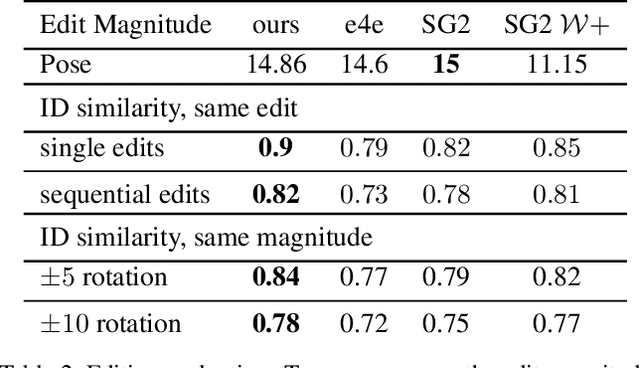
Recently, a surge of advanced facial editing techniques have been proposed that leverage the generative power of a pre-trained StyleGAN. To successfully edit an image this way, one must first project (or invert) the image into the pre-trained generator's domain. As it turns out, however, StyleGAN's latent space induces an inherent tradeoff between distortion and editability, i.e. between maintaining the original appearance and convincingly altering some of its attributes. Practically, this means it is still challenging to apply ID-preserving facial latent-space editing to faces which are out of the generator's domain. In this paper, we present an approach to bridge this gap. Our technique slightly alters the generator, so that an out-of-domain image is faithfully mapped into an in-domain latent code. The key idea is pivotal tuning - a brief training process that preserves the editing quality of an in-domain latent region, while changing its portrayed identity and appearance. In Pivotal Tuning Inversion (PTI), an initial inverted latent code serves as a pivot, around which the generator is fined-tuned. At the same time, a regularization term keeps nearby identities intact, to locally contain the effect. This surgical training process ends up altering appearance features that represent mostly identity, without affecting editing capabilities. We validate our technique through inversion and editing metrics, and show preferable scores to state-of-the-art methods. We further qualitatively demonstrate our technique by applying advanced edits (such as pose, age, or expression) to numerous images of well-known and recognizable identities. Finally, we demonstrate resilience to harder cases, including heavy make-up, elaborate hairstyles and/or headwear, which otherwise could not have been successfully inverted and edited by state-of-the-art methods.