 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Your Finetuned Large Language Model is Already a Powerful Out-of-distribution Detector
Apr 07, 2024
We revisit the likelihood ratio between a pretrained large language model (LLM) and its finetuned variant as a criterion for out-of-distribution (OOD) detection. The intuition behind such a criterion is that, the pretrained LLM has the prior knowledge about OOD data due to its large amount of training data, and once finetuned with the in-distribution data, the LLM has sufficient knowledge to distinguish their difference. Leveraging the power of LLMs, we show that, for the first time, the likelihood ratio can serve as an effective OOD detector. Moreover, we apply the proposed LLM-based likelihood ratio to detect OOD questions in question-answering (QA) systems, which can be used to improve the performance of specialized LLMs for general questions. Given that likelihood can be easily obtained by the loss functions within contemporary neural network frameworks, it is straightforward to implement this approach in practice. Since both the pretrained LLMs and its various finetuned models are available, our proposed criterion can be effortlessly incorporated for OOD detection without the need for further training. We conduct comprehensive evaluation across on multiple settings, including far OOD, near OOD, spam detection, and QA scenarios, to demonstrate the effectiveness of the method.
A Linear Time and Space Local Point Cloud Geometry Encoder via Vectorized Kernel Mixture (VecKM)
Apr 02, 2024We propose VecKM, a novel local point cloud geometry encoder that is descriptive, efficient and robust to noise. VecKM leverages a unique approach by vectorizing a kernel mixture to represent the local point clouds. Such representation is descriptive and robust to noise, which is supported by two theorems that confirm its ability to reconstruct and preserve the similarity of the local shape. Moreover, VecKM is the first successful attempt to reduce the computation and memory costs from $O(n^2+nKd)$ to $O(nd)$ by sacrificing a marginal constant factor, where $n$ is the size of the point cloud and $K$ is neighborhood size. The efficiency is primarily due to VecKM's unique factorizable property that eliminates the need of explicitly grouping points into neighborhoods. In the normal estimation task, VecKM demonstrates not only 100x faster inference speed but also strongest descriptiveness and robustness compared with existing popular encoders. In classification and segmentation tasks, integrating VecKM as a preprocessing module achieves consistently better performance than the PointNet, PointNet++, and point transformer baselines, and runs consistently faster by up to 10x.
AdaBM: On-the-Fly Adaptive Bit Mapping for Image Super-Resolution
Apr 04, 2024Although image super-resolution (SR) problem has experienced unprecedented restoration accuracy with deep neural networks, it has yet limited versatile applications due to the substantial computational costs. Since different input images for SR face different restoration difficulties, adapting computational costs based on the input image, referred to as adaptive inference, has emerged as a promising solution to compress SR networks. Specifically, adapting the quantization bit-widths has successfully reduced the inference and memory cost without sacrificing the accuracy. However, despite the benefits of the resultant adaptive network, existing works rely on time-intensive quantization-aware training with full access to the original training pairs to learn the appropriate bit allocation policies, which limits its ubiquitous usage. To this end, we introduce the first on-the-fly adaptive quantization framework that accelerates the processing time from hours to seconds. We formulate the bit allocation problem with only two bit mapping modules: one to map the input image to the image-wise bit adaptation factor and one to obtain the layer-wise adaptation factors. These bit mappings are calibrated and fine-tuned using only a small number of calibration images. We achieve competitive performance with the previous adaptive quantization methods, while the processing time is accelerated by x2000. Codes are available at https://github.com/Cheeun/AdaBM.
Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians
Mar 26, 2024The recent 3D Gaussian splatting (3D-GS) has shown remarkable rendering fidelity and efficiency compared to NeRF-based neural scene representations. While demonstrating the potential for real-time rendering, 3D-GS encounters rendering bottlenecks in large scenes with complex details due to an excessive number of Gaussian primitives located within the viewing frustum. This limitation is particularly noticeable in zoom-out views and can lead to inconsistent rendering speeds in scenes with varying details. Moreover, it often struggles to capture the corresponding level of details at different scales with its heuristic density control operation. Inspired by the Level-of-Detail (LOD) techniques, we introduce Octree-GS, featuring an LOD-structured 3D Gaussian approach supporting level-of-detail decomposition for scene representation that contributes to the final rendering results. Our model dynamically selects the appropriate level from the set of multi-resolution anchor points, ensuring consistent rendering performance with adaptive LOD adjustments while maintaining high-fidelity rendering results.
MUTE-SLAM: Real-Time Neural SLAM with Multiple Tri-Plane Hash Representations
Mar 26, 2024We introduce MUTE-SLAM, a real-time neural RGB-D SLAM system employing multiple tri-plane hash-encodings for efficient scene representation. MUTE-SLAM effectively tracks camera positions and incrementally builds a scalable multi-map representation for both small and large indoor environments. It dynamically allocates sub-maps for newly observed local regions, enabling constraint-free mapping without prior scene information. Unlike traditional grid-based methods, we use three orthogonal axis-aligned planes for hash-encoding scene properties, significantly reducing hash collisions and the number of trainable parameters. This hybrid approach not only speeds up convergence but also enhances the fidelity of surface reconstruction. Furthermore, our optimization strategy concurrently optimizes all sub-maps intersecting with the current camera frustum, ensuring global consistency. Extensive testing on both real-world and synthetic datasets has shown that MUTE-SLAM delivers state-of-the-art surface reconstruction quality and competitive tracking performance across diverse indoor settings. The code will be made public upon acceptance of the paper.
WALT3D: Generating Realistic Training Data from Time-Lapse Imagery for Reconstructing Dynamic Objects under Occlusion
Mar 27, 2024Current methods for 2D and 3D object understanding struggle with severe occlusions in busy urban environments, partly due to the lack of large-scale labeled ground-truth annotations for learning occlusion. In this work, we introduce a novel framework for automatically generating a large, realistic dataset of dynamic objects under occlusions using freely available time-lapse imagery. By leveraging off-the-shelf 2D (bounding box, segmentation, keypoint) and 3D (pose, shape) predictions as pseudo-groundtruth, unoccluded 3D objects are identified automatically and composited into the background in a clip-art style, ensuring realistic appearances and physically accurate occlusion configurations. The resulting clip-art image with pseudo-groundtruth enables efficient training of object reconstruction methods that are robust to occlusions. Our method demonstrates significant improvements in both 2D and 3D reconstruction, particularly in scenarios with heavily occluded objects like vehicles and people in urban scenes.
Suppressing Modulation Instability with Reinforcement Learning
Apr 05, 2024Modulation instability is a phenomenon of spontaneous pattern formation in nonlinear media, oftentimes leading to an unpredictable behaviour and a degradation of a signal of interest. We propose an approach based on reinforcement learning to suppress the unstable modes by optimizing the parameters for the time modulation of the potential in the nonlinear system. We test our approach in 1D and 2D cases and propose a new class of physically-meaningful reward functions to guarantee tamed instability.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024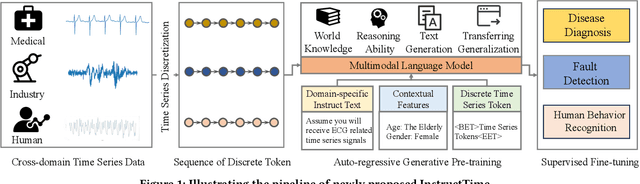
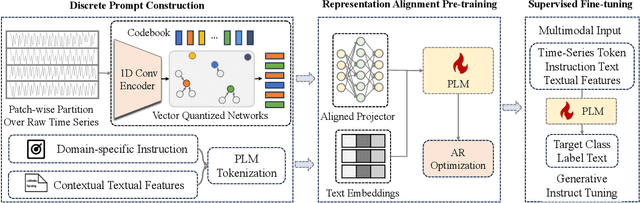
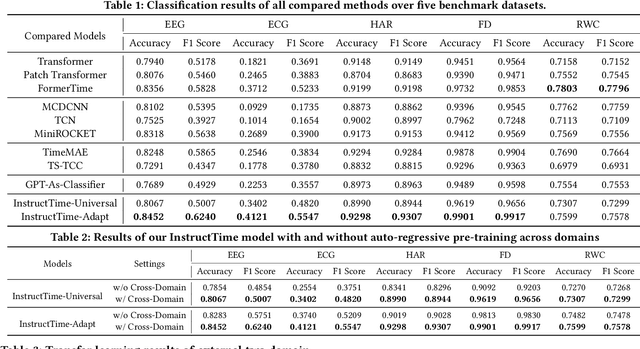

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.
POMDP-Guided Active Force-Based Search for Robotic Insertion
Apr 05, 2024In robotic insertion tasks where the uncertainty exceeds the allowable tolerance, a good search strategy is essential for successful insertion and significantly influences efficiency. The commonly used blind search method is time-consuming and does not exploit the rich contact information. In this paper, we propose a novel search strategy that actively utilizes the information contained in the contact configuration and shows high efficiency. In particular, we formulate this problem as a Partially Observable Markov Decision Process (POMDP) with carefully designed primitives based on an in-depth analysis of the contact configuration's static stability. From the formulated POMDP, we can derive a novel search strategy. Thanks to its simplicity, this search strategy can be incorporated into a Finite-State-Machine (FSM) controller. The behaviors of the FSM controller are realized through a low-level Cartesian Impedance Controller. Our method is based purely on the robot's proprioceptive sensing and does not need visual or tactile sensors. To evaluate the effectiveness of our proposed strategy and control framework, we conduct extensive comparison experiments in simulation, where we compare our method with the baseline approach. The results demonstrate that our proposed method achieves a higher success rate with a shorter search time and search trajectory length compared to the baseline method. Additionally, we show that our method is robust to various initial displacement errors.
AirShot: Efficient Few-Shot Detection for Autonomous Exploration
Apr 07, 2024Few-shot object detection has drawn increasing attention in the field of robotic exploration, where robots are required to find unseen objects with a few online provided examples. Despite recent efforts have been made to yield online processing capabilities, slow inference speeds of low-powered robots fail to meet the demands of real-time detection-making them impractical for autonomous exploration. Existing methods still face performance and efficiency challenges, mainly due to unreliable features and exhaustive class loops. In this work, we propose a new paradigm AirShot, and discover that, by fully exploiting the valuable correlation map, AirShot can result in a more robust and faster few-shot object detection system, which is more applicable to robotics community. The core module Top Prediction Filter (TPF) can operate on multi-scale correlation maps in both the training and inference stages. During training, TPF supervises the generation of a more representative correlation map, while during inference, it reduces looping iterations by selecting top-ranked classes, thus cutting down on computational costs with better performance. Surprisingly, this dual functionality exhibits general effectiveness and efficiency on various off-the-shelf models. Exhaustive experiments on COCO2017, VOC2014, and SubT datasets demonstrate that TPF can significantly boost the efficacy and efficiency of most off-the-shelf models, achieving up to 36.4% precision improvements along with 56.3% faster inference speed. Code and Data are at: https://github.com/ImNotPrepared/AirShot.