 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Holographic Transmitarray Antenna with linear Polarization in X band
Apr 19, 2021
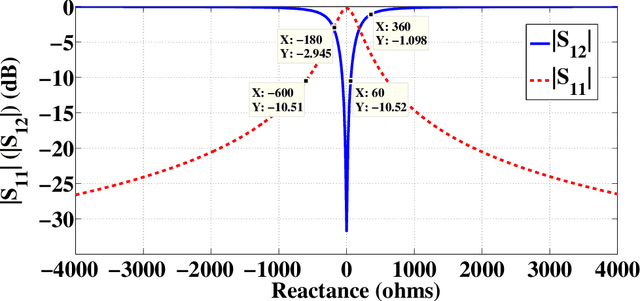

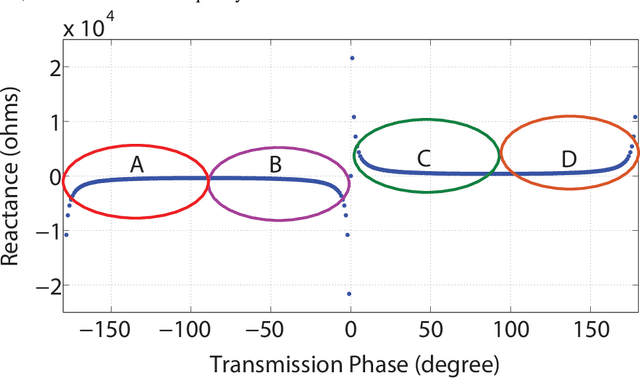
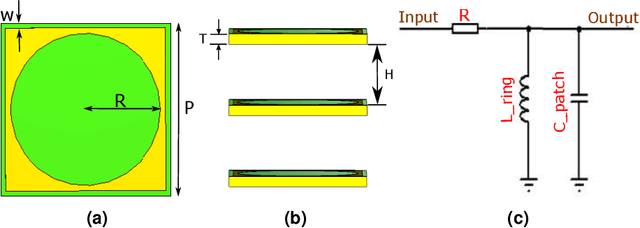
In this paper, we present the design and demonstration of transmitarray antennas (TAs) based on the holographic technique for the first time. According to the holographic theory, the amplitudes and phases of electromagnetic waves can be recorded on a surface, and then they can be reconstructed independently. This concept is used to design single-beam and multi-beam linearly polarized holographic TAs without using any iterative optimization algorithms. Initially, a transmission impedance surface is analyzed and compared with the reflection one. Then, interferograms associated with the scalar admittance distribution are defined according to the number and direction of the radiation beams. After that, a transmission metasurface of dimensions equal to 0:26l0 is hired to design holographic TAs at 12 GHz. Several examples are provided to support the method. In the end, a linearly polarized circular aperture wideband holographic transmitarray antenna with a radius of 13.3 cm has been manufactured and tested. The antenna achieves 12.5% (11.4-12.9 GHz) 1-dB gain bandwidth and 23.8 dB maximum gain, leading to 21.46% aperture efficiency.
Closing the Closed-Loop Distribution Shift in Safe Imitation Learning
Feb 18, 2021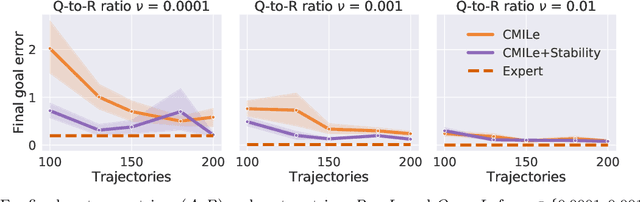
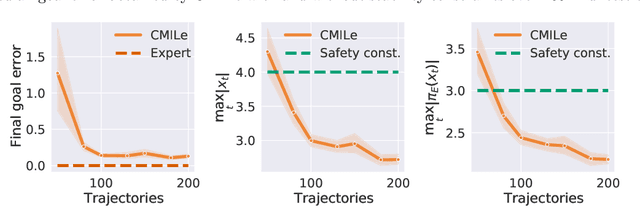
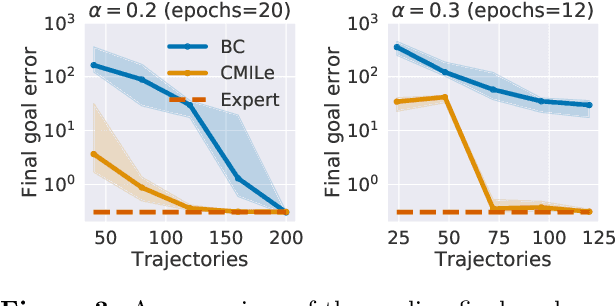
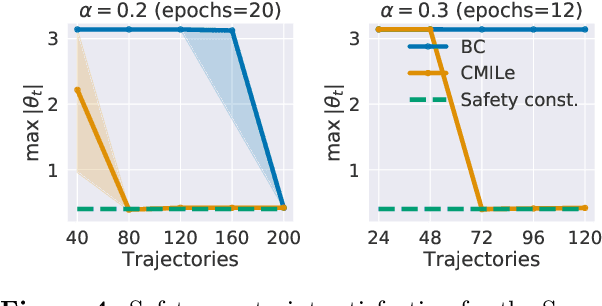
Commonly used optimization-based control strategies such as model-predictive and control Lyapunov/barrier function based controllers often enjoy provable stability, robustness, and safety properties. However, implementing such approaches requires solving optimization problems online at high-frequencies, which may not be possible on resource-constrained commodity hardware. Furthermore, how to extend the safety guarantees of such approaches to systems that use rich perceptual sensing modalities, such as cameras, remains unclear. In this paper, we address this gap by treating safe optimization-based control strategies as experts in an imitation learning problem, and train a learned policy that can be cheaply evaluated at run-time and that provably satisfies the same safety guarantees as the expert. In particular, we propose Constrained Mixing Iterative Learning (CMILe), a novel on-policy robust imitation learning algorithm that integrates ideas from stochastic mixing iterative learning, constrained policy optimization, and nonlinear robust control. Our approach allows us to control errors introduced by both the learning task of imitating an expert and by the distribution shift inherent to deviating from the original expert policy. The value of using tools from nonlinear robust control to impose stability constraints on learned policies is shown through sample-complexity bounds that are independent of the task time-horizon. We demonstrate the usefulness of CMILe through extensive experiments, including training a provably safe perception-based controller using a state-feedback-based expert.
Semi-supervised Interactive Intent Labeling
Apr 27, 2021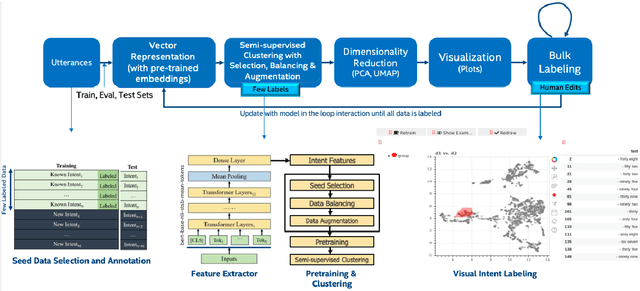

Building the Natural Language Understanding (NLU) modules of task-oriented Spoken Dialogue Systems (SDS) involves a definition of intents and entities, collection of task-relevant data, annotating the data with intents and entities, and then repeating the same process over and over again for adding any functionality/enhancement to the SDS. In this work, we have developed an Intent Bulk Labeling system for SDS developers. The users can interactively label and augment training data from unlabeled utterance corpora using advanced clustering and visual labeling methods. We extend the Deep Aligned Clustering work with a better backbone BERT model, explore techniques to select the seed data for labeling, and develop a data balancing method using an oversampling technique that utilizes paraphrasing models. We also look at the effect of data augmentation on the clustering process. Our results show that we can achieve over 10% gain in clustering accuracy on some datasets using the combination of the above techniques. Finally, we extract utterance embeddings from the clustering model and plot the data to interactively bulk label the data, reducing the time and effort for data labeling of the whole dataset significantly.
Complex-YOLO: Real-time 3D Object Detection on Point Clouds
Sep 24, 2018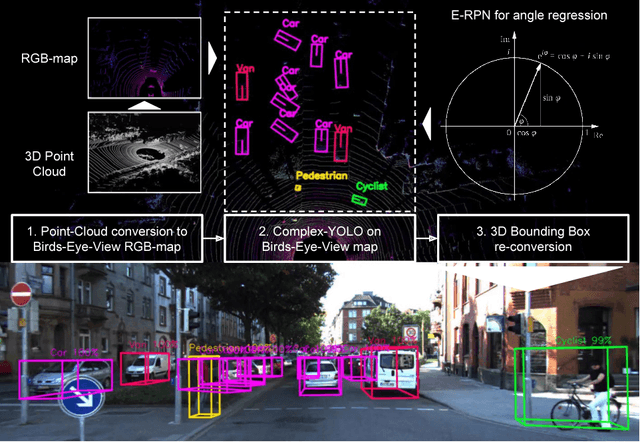
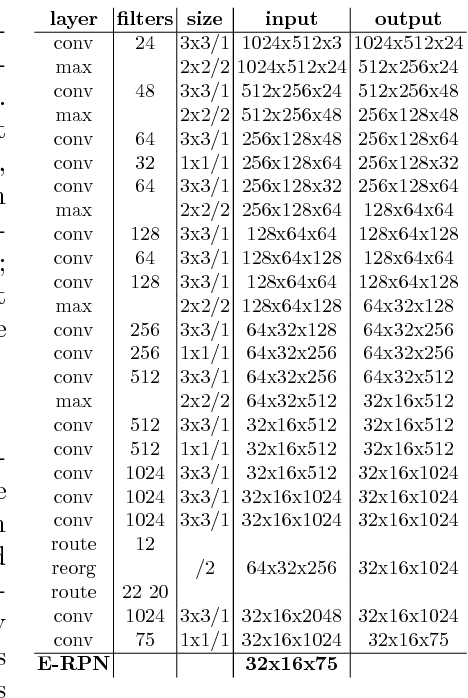
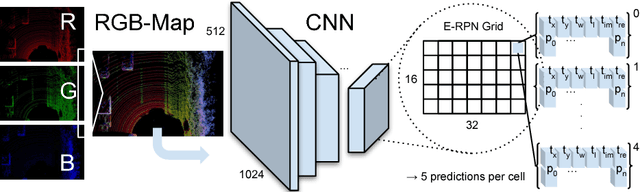
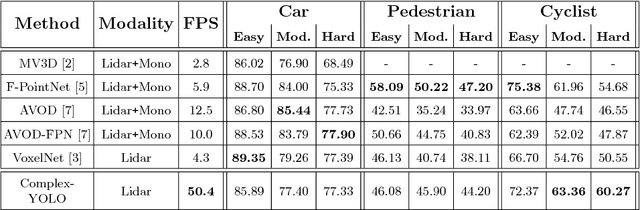
Lidar based 3D object detection is inevitable for autonomous driving, because it directly links to environmental understanding and therefore builds the base for prediction and motion planning. The capacity of inferencing highly sparse 3D data in real-time is an ill-posed problem for lots of other application areas besides automated vehicles, e.g. augmented reality, personal robotics or industrial automation. We introduce Complex-YOLO, a state of the art real-time 3D object detection network on point clouds only. In this work, we describe a network that expands YOLOv2, a fast 2D standard object detector for RGB images, by a specific complex regression strategy to estimate multi-class 3D boxes in Cartesian space. Thus, we propose a specific Euler-Region-Proposal Network (E-RPN) to estimate the pose of the object by adding an imaginary and a real fraction to the regression network. This ends up in a closed complex space and avoids singularities, which occur by single angle estimations. The E-RPN supports to generalize well during training. Our experiments on the KITTI benchmark suite show that we outperform current leading methods for 3D object detection specifically in terms of efficiency. We achieve state of the art results for cars, pedestrians and cyclists by being more than five times faster than the fastest competitor. Further, our model is capable of estimating all eight KITTI-classes, including Vans, Trucks or sitting pedestrians simultaneously with high accuracy.
Let There be Light: Improved Traffic Surveillance via Detail Preserving Night-to-Day Transfer
May 11, 2021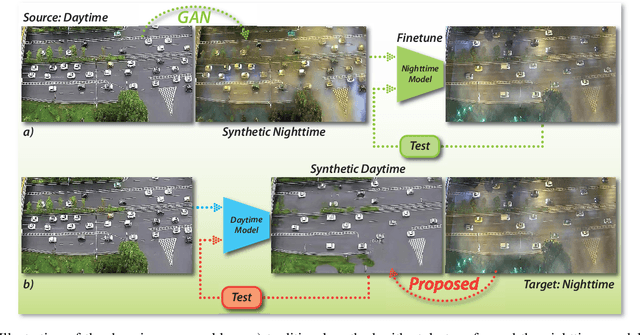

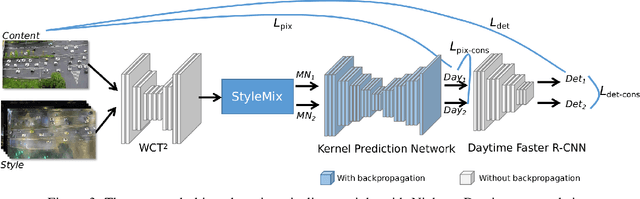
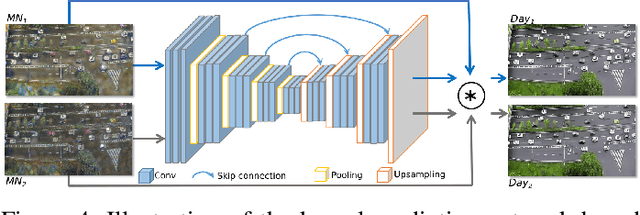
In recent years, image and video surveillance have made considerable progresses to the Intelligent Transportation Systems (ITS) with the help of deep Convolutional Neural Networks (CNNs). As one of the state-of-the-art perception approaches, detecting the interested objects in each frame of video surveillance is widely desired by ITS. Currently, object detection shows remarkable efficiency and reliability in standard scenarios such as daytime scenes with favorable illumination conditions. However, in face of adverse conditions such as the nighttime, object detection loses its accuracy significantly. One of the main causes of the problem is the lack of sufficient annotated detection datasets of nighttime scenes. In this paper, we propose a framework to alleviate the accuracy decline when object detection is taken to adverse conditions by using image translation method. We propose to utilize style translation based StyleMix method to acquire pairs of day time image and nighttime image as training data for following nighttime to daytime image translation. To alleviate the detail corruptions caused by Generative Adversarial Networks (GANs), we propose to utilize Kernel Prediction Network (KPN) based method to refine the nighttime to daytime image translation. The KPN network is trained with object detection task together to adapt the trained daytime model to nighttime vehicle detection directly. Experiments on vehicle detection verified the accuracy and effectiveness of the proposed approach.
Surrogate assisted active subspace and active subspace assisted surrogate -- A new paradigm for high dimensional structural reliability analysis
May 11, 2021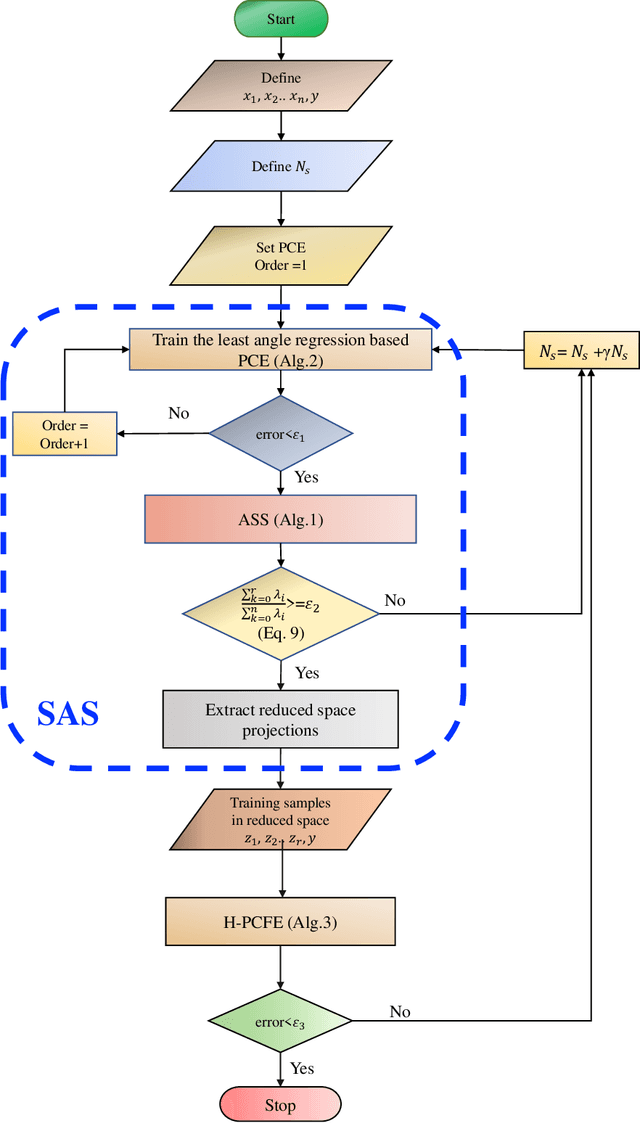
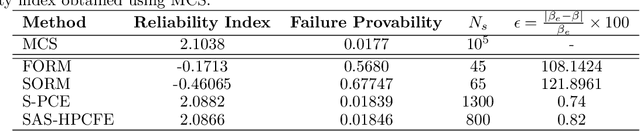
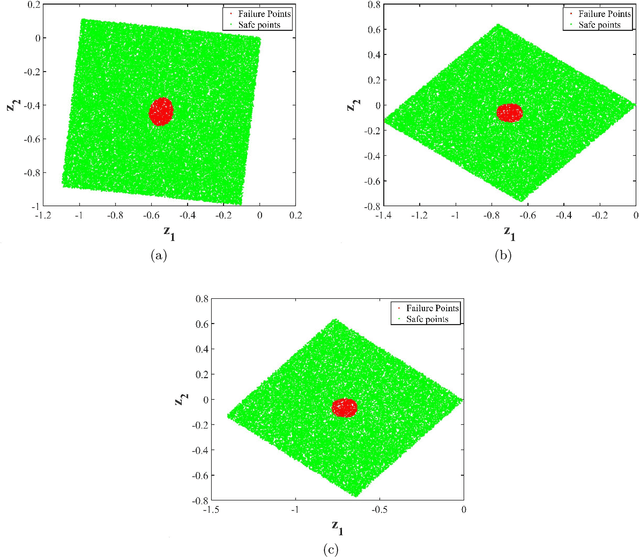
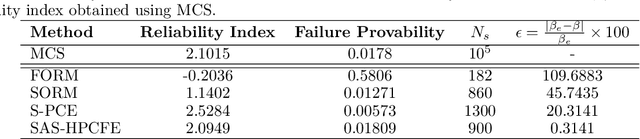
Performing reliability analysis on complex systems is often computationally expensive. In particular, when dealing with systems having high input dimensionality, reliability estimation becomes a daunting task. A popular approach to overcome the problem associated with time-consuming and expensive evaluations is building a surrogate model. However, these computationally efficient models often suffer from the curse of dimensionality. Hence, training a surrogate model for high-dimensional problems is not straightforward. Henceforth, this paper presents a framework for solving high-dimensional reliability analysis problems. The basic premise is to train the surrogate model on a low-dimensional manifold, discovered using the active subspace algorithm. However, learning the low-dimensional manifold using active subspace is non-trivial as it requires information on the gradient of the response variable. To address this issue, we propose using sparse learning algorithms in conjunction with the active subspace algorithm; the resulting algorithm is referred to as the sparse active subspace (SAS) algorithm. We project the high-dimensional inputs onto the identified low-dimensional manifold identified using SAS. A high-fidelity surrogate model is used to map the inputs on the low-dimensional manifolds to the output response. We illustrate the efficacy of the proposed framework by using three benchmark reliability analysis problems from the literature. The results obtained indicate the accuracy and efficiency of the proposed approach compared to already established reliability analysis methods in the literature.
Probing Causal Common Sense in Dialogue Response Generation
Apr 19, 2021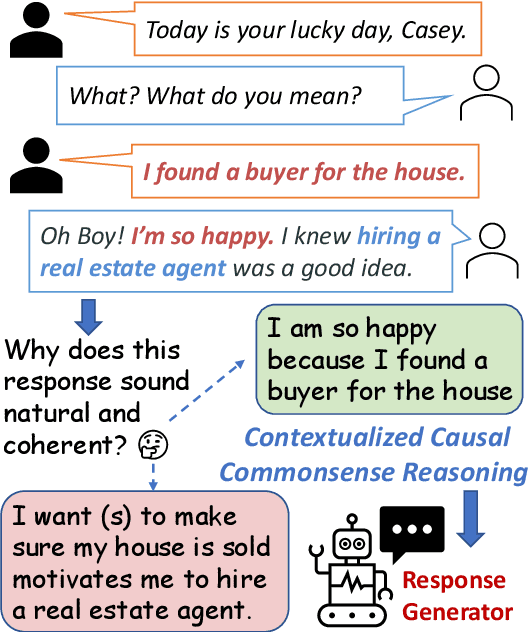
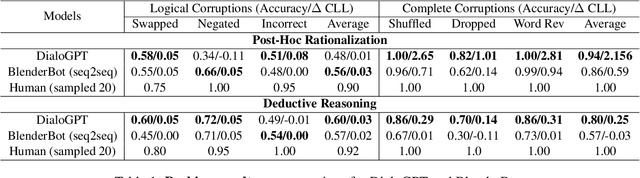


Communication is a cooperative effort that requires reaching mutual understanding among the participants. Humans use commonsense reasoning implicitly to produce natural and logically-coherent responses. As a step towards fluid human-AI communication, we study if response generation (RG) models can emulate human reasoning process and use common sense to help produce better-quality responses. We aim to tackle two research questions: how to formalize conversational common sense and how to examine RG models capability to use common sense? We first propose a task, CEDAR: Causal common sEnse in DiAlogue Response generation, that concretizes common sense as textual explanations for what might lead to the response and evaluates RG models behavior by comparing the modeling loss given a valid explanation with an invalid one. Then we introduce a process that automatically generates such explanations and ask humans to verify them. Finally, we design two probing settings for RG models targeting two reasoning capabilities using verified explanations. We find that RG models have a hard time determining the logical validity of explanations but can identify grammatical naturalness of the explanation easily.
Towards Automated Satellite Conjunction Management with Bayesian Deep Learning
Dec 23, 2020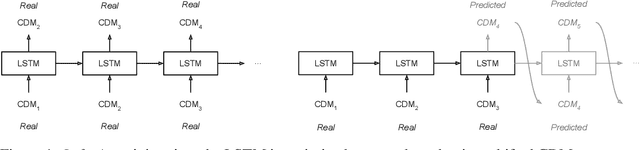

After decades of space travel, low Earth orbit is a junkyard of discarded rocket bodies, dead satellites, and millions of pieces of debris from collisions and explosions. Objects in high enough altitudes do not re-enter and burn up in the atmosphere, but stay in orbit around Earth for a long time. With a speed of 28,000 km/h, collisions in these orbits can generate fragments and potentially trigger a cascade of more collisions known as the Kessler syndrome. This could pose a planetary challenge, because the phenomenon could escalate to the point of hindering future space operations and damaging satellite infrastructure critical for space and Earth science applications. As commercial entities place mega-constellations of satellites in orbit, the burden on operators conducting collision avoidance manoeuvres will increase. For this reason, development of automated tools that predict potential collision events (conjunctions) is critical. We introduce a Bayesian deep learning approach to this problem, and develop recurrent neural network architectures (LSTMs) that work with time series of conjunction data messages (CDMs), a standard data format used by the space community. We show that our method can be used to model all CDM features simultaneously, including the time of arrival of future CDMs, providing predictions of conjunction event evolution with associated uncertainties.
Deep Learning for EEG Seizure Detection in Preterm Infants
May 28, 2021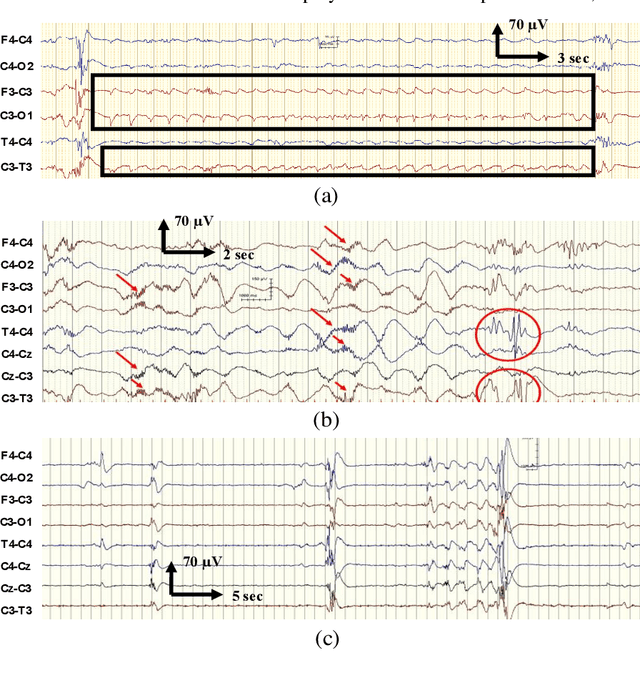

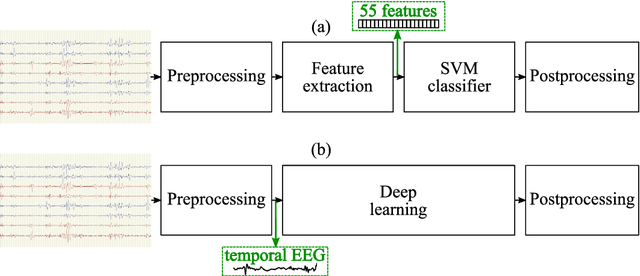
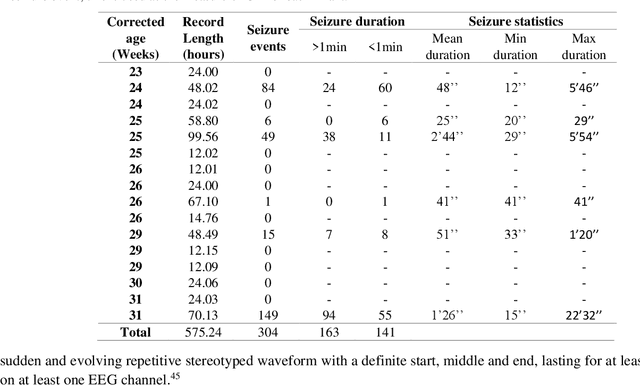
EEG is the gold standard for seizure detection in the newborn infant, but EEG interpretation in the preterm group is particularly challenging; trained experts are scarce and the task of interpreting EEG in real-time is arduous. Preterm infants are reported to have a higher incidence of seizures compared to term infants. Preterm EEG morphology differs from that of term infants, which implies that seizure detection algorithms trained on term EEG may not be appropriate. The task of developing preterm specific algorithms becomes extra-challenging given the limited amount of annotated preterm EEG data available. This paper explores novel deep learning (DL) architectures for the task of neonatal seizure detection in preterm infants. The study tests and compares several approaches to address the problem: training on data from full-term infants; training on data from preterm infants; training on age-specific preterm data and transfer learning. The system performance is assessed on a large database of continuous EEG recordings of 575h in duration. It is shown that the accuracy of a validated term-trained EEG seizure detection algorithm, based on a support vector machine classifier, when tested on preterm infants falls well short of the performance achieved for full-term infants. An AUC of 88.3% was obtained when tested on preterm EEG as compared to 96.6% obtained when tested on term EEG. When re-trained on preterm EEG, the performance marginally increases to 89.7%. An alternative DL approach shows a more stable trend when tested on the preterm cohort, starting with an AUC of 93.3% for the term-trained algorithm and reaching 95.0% by transfer learning from the term model using available preterm data.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 24, 2021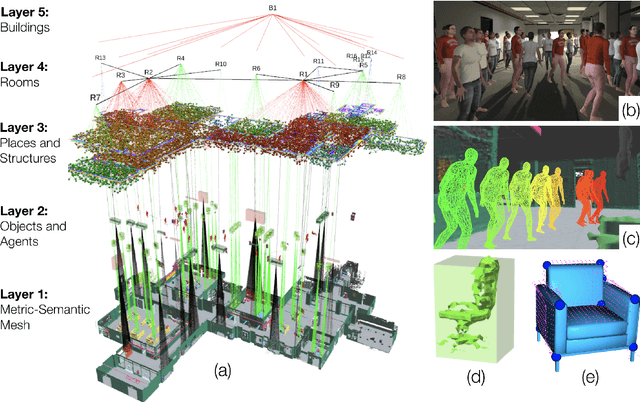
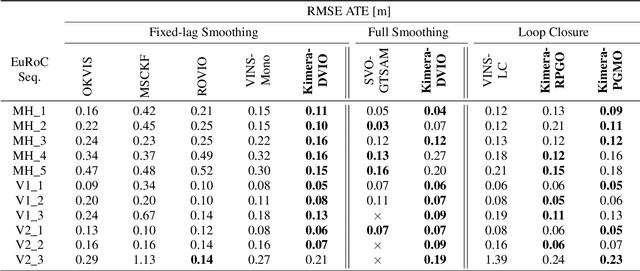
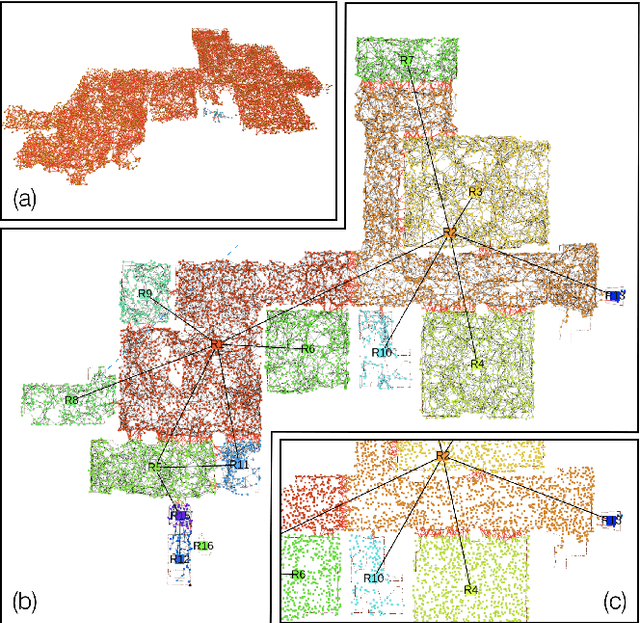
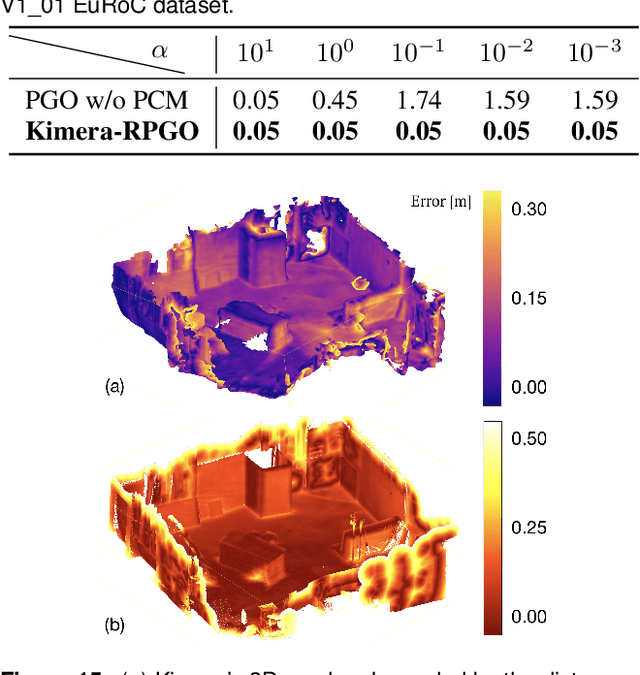
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.