 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine learning for nocturnal diagnosis of chronic obstructive pulmonary disease using digital oximetry biomarkers
Dec 10, 2020
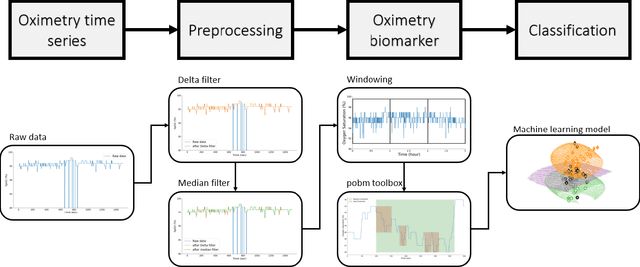
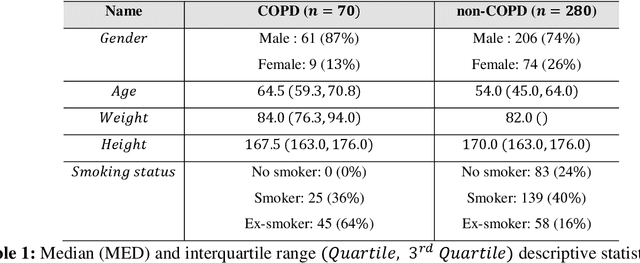
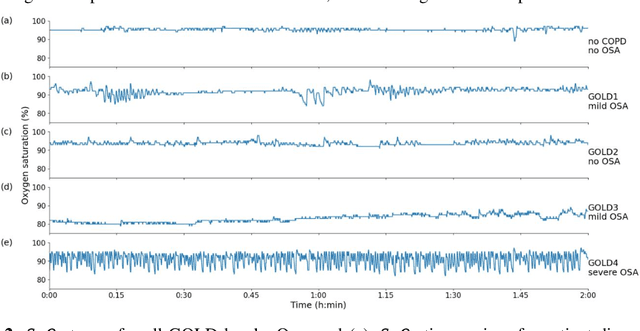

Objective: Chronic obstructive pulmonary disease (COPD) is a highly prevalent chronic condition. COPD is a major source of morbidity, mortality and healthcare costs. Spirometry is the gold standard test for a definitive diagnosis and severity grading of COPD. However, a large proportion of individuals with COPD are undiagnosed and untreated. Given the high prevalence of COPD and its clinical importance, it is critical to develop new algorithms to identify undiagnosed COPD, especially in specific groups at risk, such as those with sleep disorder breathing. To our knowledge, no research has looked at the feasibility of COPD diagnosis from the nocturnal oximetry time series. Approach: We hypothesize that patients with COPD will exert certain patterns and/or dynamics of their overnight oximetry time series that are unique to this condition. We introduce a novel approach to nocturnal COPD diagnosis using 44 oximetry digital biomarkers and 5 demographic features and assess its performance in a population sample at risk of sleep-disordered breathing. A total of n=350 unique patients polysomnography (PSG) recordings. A random forest (RF) classifier is trained using these features and evaluated using the nested cross-validation procedure. Significance: Our research makes a number of novel scientific contributions. First, we demonstrated for the first time, the feasibility of COPD diagnosis from nocturnal oximetry time series in a population sample at risk of sleep disordered breathing. We highlighted what digital oximetry biomarkers best reflect how COPD manifests overnight. The results motivate that overnight single channel oximetry is a valuable pathway for COPD diagnosis.
Design to automate the detection and counting of Tuberculosis(TB) bacilli
May 24, 2021
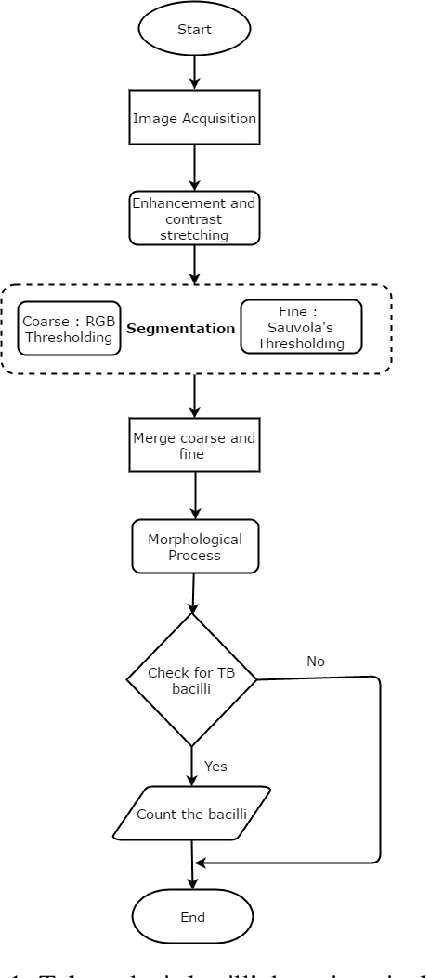


Tuberculosis is a contagious disease which is one of the leading causes of death, globally. The general diagnosis methods for tuberculosis include microscopic examination, tuberculin skin test, culture method, enzyme linked immunosorbent assay (ELISA) and electronic nose system. World Health Organization (WHO) recommends standard microscopic examination for early diagnosis of tuberculosis. In microscopy, the technician examines field of views (FOVs) in sputum smear for presence of any TB bacilli and counts the number of TB bacilli per FOV to report the level of severity. This process is time consuming with an increased concentration for an experienced staff to examine a single sputum smear. The examination demands for skilled technicians in high-prevalence countries which may lead to overload, fatigue and diminishes the quality of microscopy. Thus, a computer assisted system is proposed and designed for the detection of tuberculosis bacilli to assist pathologists with increased sensitivity and specificity. The manual efforts in detecting and counting the number of TB bacilli is greatly minimized. The system obtains Ziehl-Neelsen stained microscopic images from conventional microscope at 100x magnification and passes the data to the detection system. Initially the segmentation of TB bacilli was done using RGB thresholding and Sauvola's adaptive thresholding algorithm. To eliminate the non-TB bacilli from coarse level segmentation, shape descriptors like area, perimeter, convex hull, major axis length and eccentricity are used to extract only the TB bacilli features. Finally, the TB bacilli are counted using the generated bounding boxes to report the level of severity.
Green Tethered UAVs for EMF-Aware Cellular Networks
Jun 03, 2021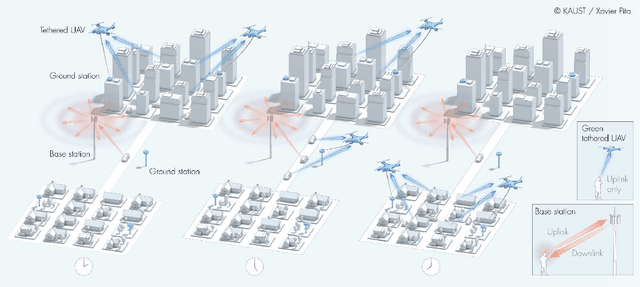
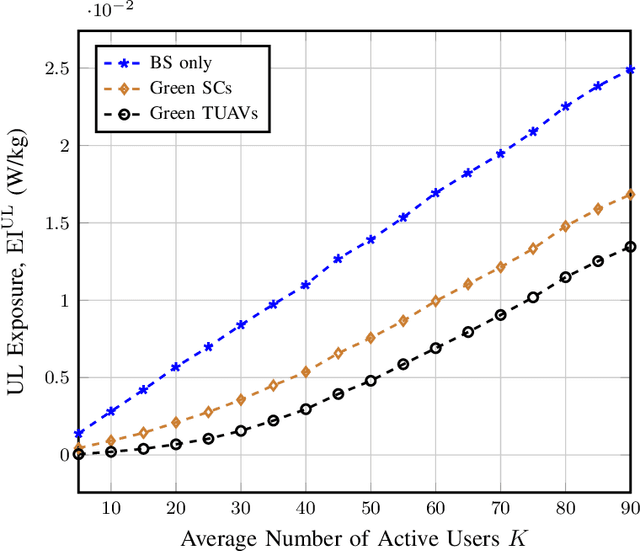
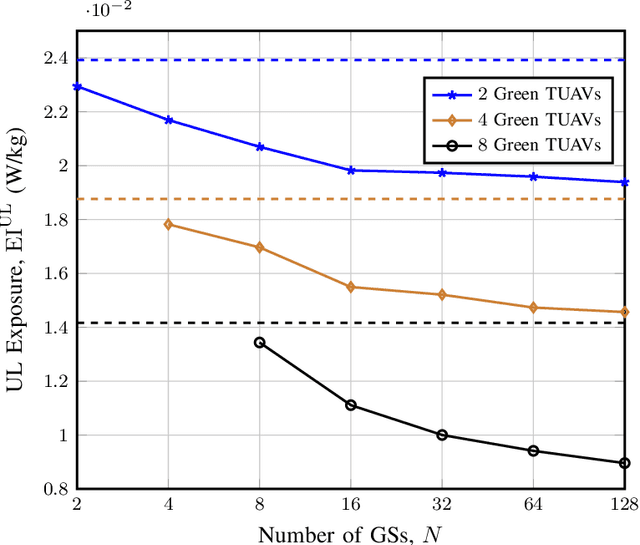
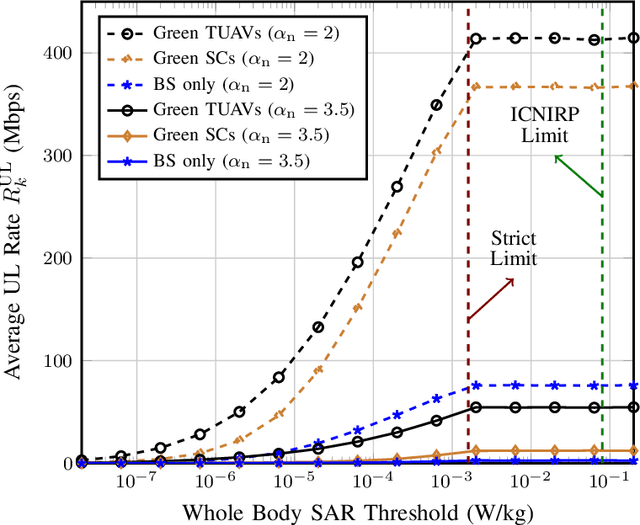
A prevalent theory circulating among the non-scientific community is that the intensive deployment of base stations over the territory significantly increases the level of electromagnetic field (EMF) exposure and affects population health. To alleviate this concern, in this work, we propose a network architecture that introduces tethered unmanned aerial vehicles (TUAVs) carrying green antennas to minimize the EMF exposure while guaranteeing a high data rate for users. In particular, each TUAV can attach itself to one of the possible ground stations at the top of some buildings. The location of the TUAVs, transmit power of user equipment and association policy are optimized to minimize the EMF exposure. Unfortunately, the problem turns out to be mixed-integer non-linear programming (MINLP), which is non-deterministic polynomial-time (NP) hard. We propose an efficient low-complexity algorithm composed of three submodules. Firstly, we propose an algorithm based on the greedy principle to determine the optimal association matrix between the users and base stations. Then, we offer two approaches, a modified K-mean and shrink and realign (SR) process, to associate each TUAV with a ground station. Finally, we put forward two algorithms based on the golden search and SR process to adjust the TUAV's position within the hovering area over the building. After that, we consider the dual problem that maximizes the sum rate while keeping the exposure below a predefined value, such as the level enforced by the regulation. Next, we perform extensive simulations to show the effectiveness of the proposed TUAVs to reduce the exposure compared to various architectures. Eventually, we show that TUAVs with green antennas can effectively mitigate the EMF exposure by more than 20% compared to fixed green small cells while achieving a higher data rate.
Towards Exploratory Landscape Analysis for Large-scale Optimization: A Dimensionality Reduction Framework
Apr 21, 2021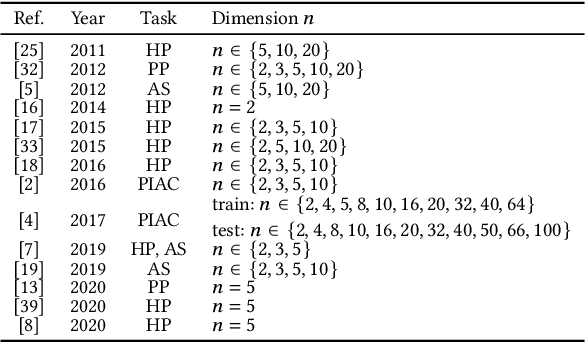
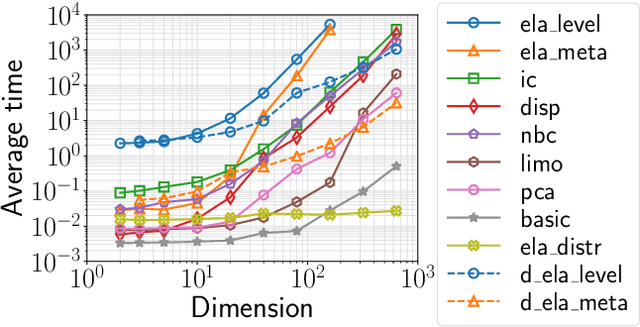
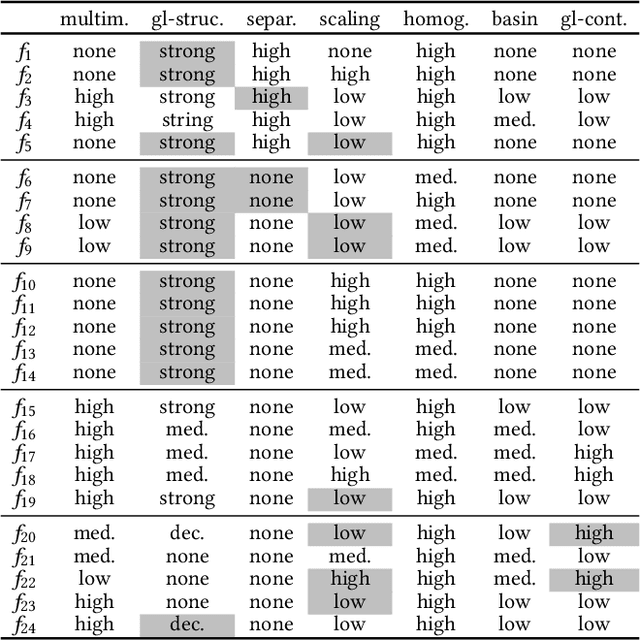
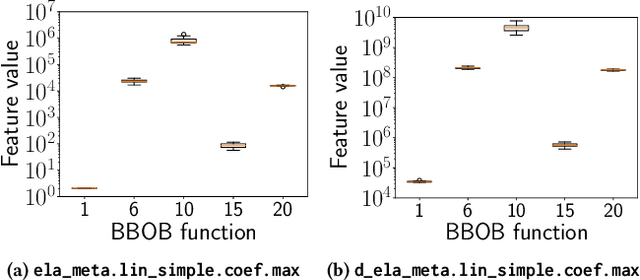
Although exploratory landscape analysis (ELA) has shown its effectiveness in various applications, most previous studies focused only on low- and moderate-dimensional problems. Thus, little is known about the scalability of the ELA approach for large-scale optimization. In this context, first, this paper analyzes the computational cost of features in the flacco package. Our results reveal that two important feature classes (ela_level and ela_meta) cannot be applied to large-scale optimization due to their high computational cost. To improve the scalability of the ELA approach, this paper proposes a dimensionality reduction framework that computes features in a reduced lower-dimensional space than the original solution space. We demonstrate that the proposed framework can drastically reduce the computation time of ela_level and ela_meta for large dimensions. In addition, the proposed framework can make the cell-mapping feature classes scalable for large-scale optimization. Our results also show that features computed by the proposed framework are beneficial for predicting the high-level properties of the 24 large-scale BBOB functions.
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Jan 25, 2021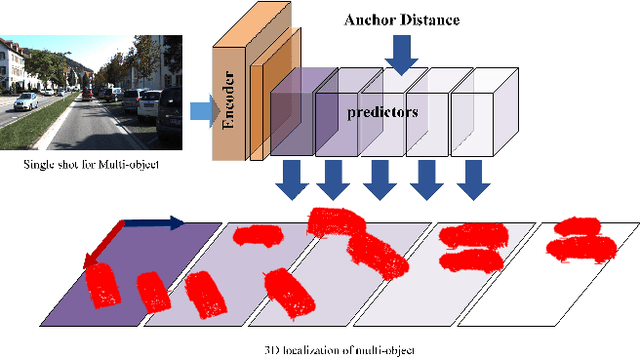
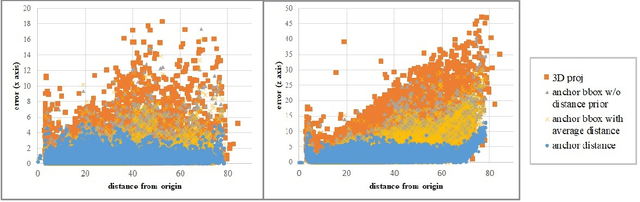
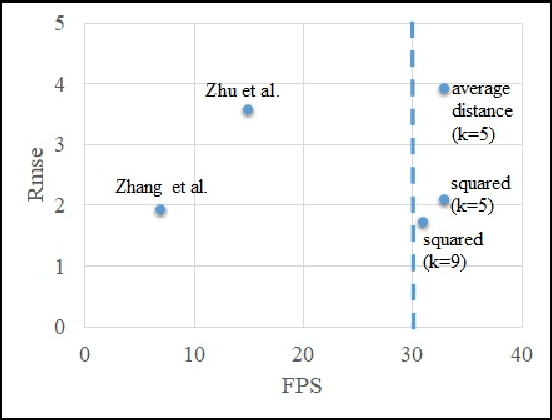
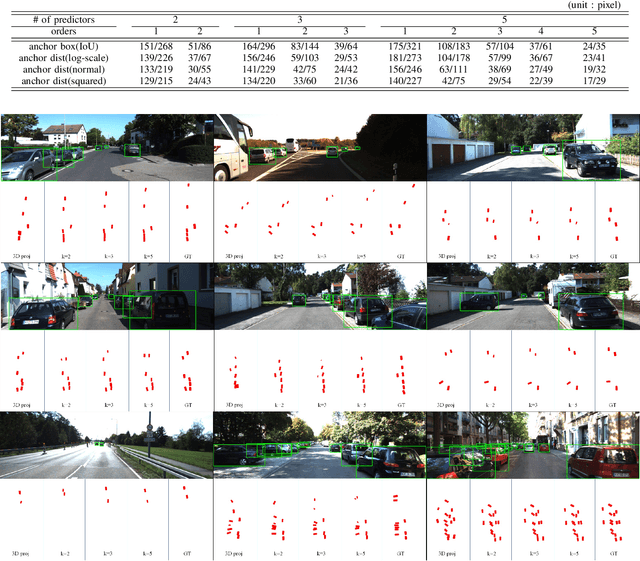
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.
Using Trust in Automation to Enhance Driver-(Semi)Autonomous Vehicle Interaction and Improve Team Performance
Jun 03, 2021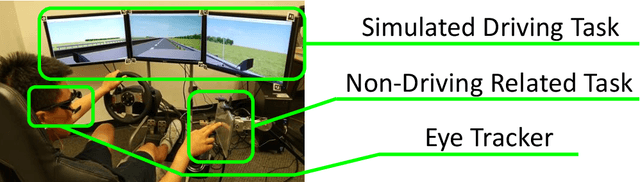
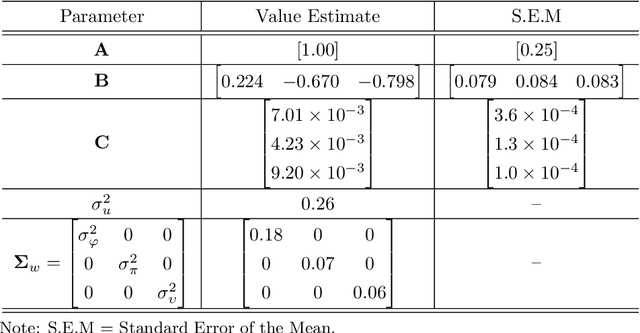
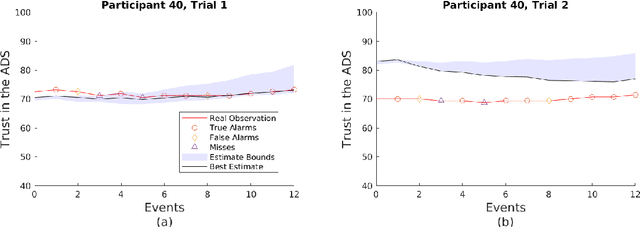
Trust in robots has been gathering attention from multiple directions, as it has special relevance in the theoretical descriptions of human-robot interactions. It is essential for reaching high acceptance and usage rates of robotic technologies in society, as well as for enabling effective human-robot teaming. Researchers have been trying to model the development of trust in robots to improve the overall rapport between humans and robots. Unfortunately, the miscalibration of trust in automation is a common issue that jeopardizes the effectiveness of automation use. It happens when a user's trust levels are not appropriate to the capabilities of the automation being used. Users can be: under-trusting the automation -- when they do not use the functionalities that the machine can perform correctly because of a lack of trust; or over-trusting the automation -- when, due to an excess of trust, they use the machine in situations where its capabilities are not adequate. The main objective of this work is to examine driver's trust development in the ADS. We aim to model how risk factors (e.g.: false alarms and misses from the ADS) and the short-term interactions associated with these risk factors influence the dynamics of drivers' trust in the ADS. The driving context facilitates the instrumentation to measure trusting behaviors, such as drivers' eye movements and usage time of the automated features. Our findings indicate that a reliable characterization of drivers' trusting behaviors and a consequent estimation of trust levels is possible. We expect that these techniques will permit the design of ADSs able to adapt their behaviors to attempt to adjust driver's trust levels. This capability could avoid under- and over-trusting, which could harm their safety or their performance.
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning
May 29, 2021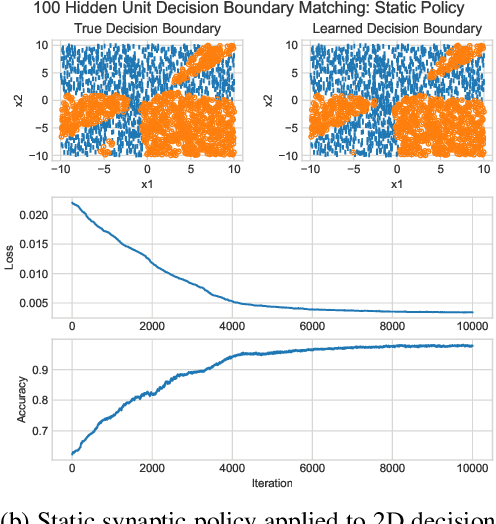
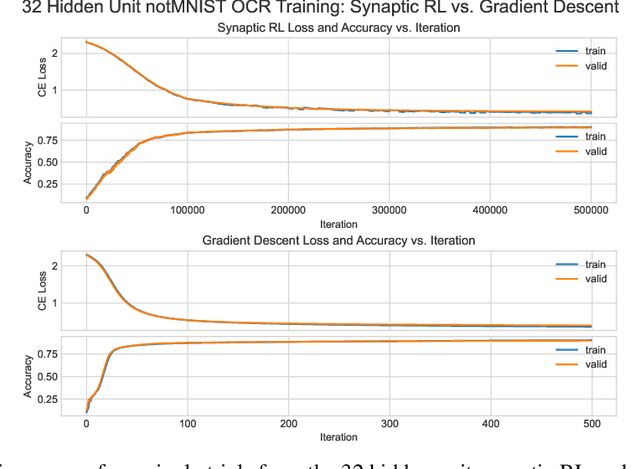
An ongoing challenge in neural information processing is: how do neurons adjust their connectivity to improve task performance over time (i.e., actualize learning)? It is widely believed that there is a consistent, synaptic-level learning mechanism in specific brain regions that actualizes learning. However, the exact nature of this mechanism remains unclear. Here we propose an algorithm based on reinforcement learning (RL) to generate and apply a simple synaptic-level learning policy for multi-layer perceptron (MLP) models. In this algorithm, the action space for each MLP synapse consists of a small increase, decrease, or null action on the synapse weight, and the state for each synapse consists of the last two actions and reward signals. A binary reward signal indicates improvement or deterioration in task performance. The static policy produces superior training relative to the adaptive policy and is agnostic to activation function, network shape, and task. Trained MLPs yield character recognition performance comparable to identically shaped networks trained with gradient descent. 0 hidden unit character recognition tests yielded an average validation accuracy of 88.28%, 1.86$\pm$0.47% higher than the same MLP trained with gradient descent. 32 hidden unit character recognition tests yielded an average validation accuracy of 88.45%, 1.11$\pm$0.79% lower than the same MLP trained with gradient descent. The robustness and lack of reliance on gradient computations opens the door for new techniques for training difficult-to-differentiate artificial neural networks such as spiking neural networks (SNNs) and recurrent neural networks (RNNs). Further, the method's simplicity provides a unique opportunity for further development of local rule-driven multi-agent connectionist models for machine intelligence analogous to cellular automata.
From SIR to SEAIRD: a novel data-driven modeling approach based on the Grey-box System Theory to predict the dynamics of COVID-19
May 29, 2021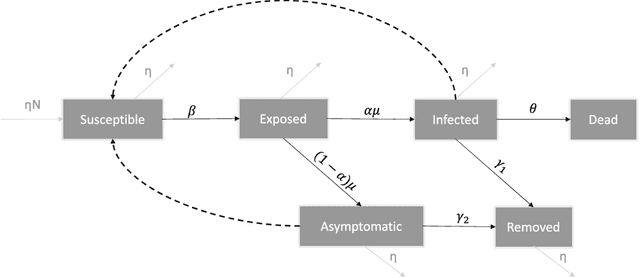
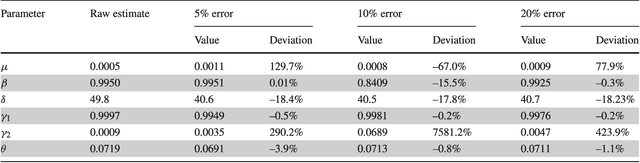
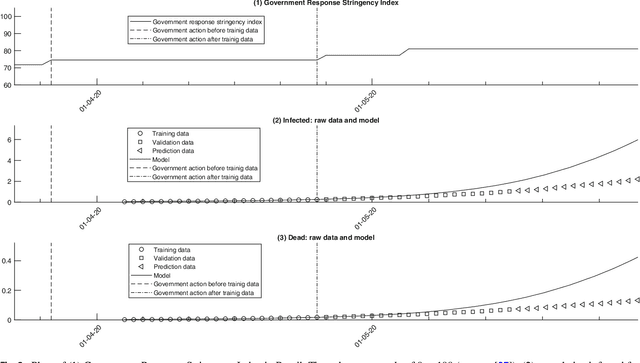
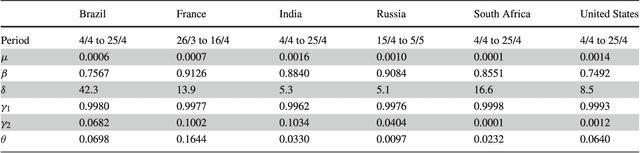
Common compartmental modeling for COVID-19 is based on a priori knowledge and numerous assumptions. Additionally, they do not systematically incorporate asymptomatic cases. Our study aimed at providing a framework for data-driven approaches, by leveraging the strengths of the grey-box system theory or grey-box identification, known for its robustness in problem solving under partial, incomplete, or uncertain data. Empirical data on confirmed cases and deaths, extracted from an open source repository were used to develop the SEAIRD compartment model. Adjustments were made to fit current knowledge on the COVID-19 behavior. The model was implemented and solved using an Ordinary Differential Equation solver and an optimization tool. A cross-validation technique was applied, and the coefficient of determination $R^2$ was computed in order to evaluate the goodness-of-fit of the model. %to the data. Key epidemiological parameters were finally estimated and we provided the rationale for the construction of SEAIRD model. When applied to Brazil's cases, SEAIRD produced an excellent agreement to the data, with an %coefficient of determination $R^2$ $\geq 90\%$. The probability of COVID-19 transmission was generally high ($\geq 95\%$). On the basis of a 20-day modeling data, the incidence rate of COVID-19 was as low as 3 infected cases per 100,000 exposed persons in Brazil and France. Within the same time frame, the fatality rate of COVID-19 was the highest in France (16.4\%) followed by Brazil (6.9\%), and the lowest in Russia ($\leq 1\%$). SEAIRD represents an asset for modeling infectious diseases in their dynamical stable phase, especially for new viruses when pathophysiology knowledge is very limited.
Aging Bandits: Regret Analysis and Order-Optimal Learning Algorithm for Wireless Networks with Stochastic Arrivals
Dec 16, 2020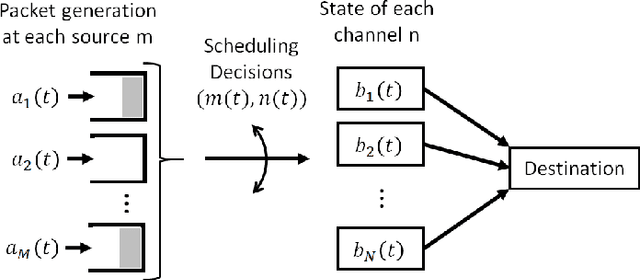
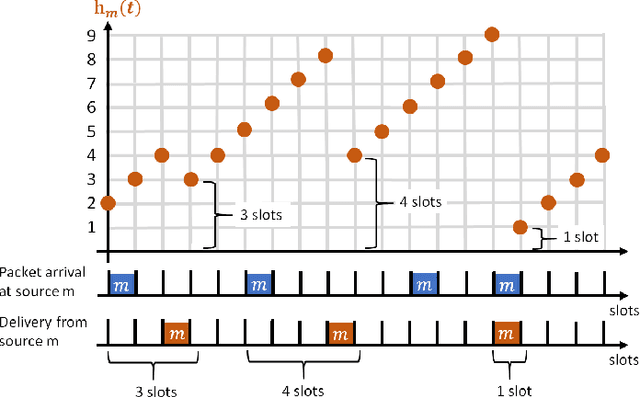
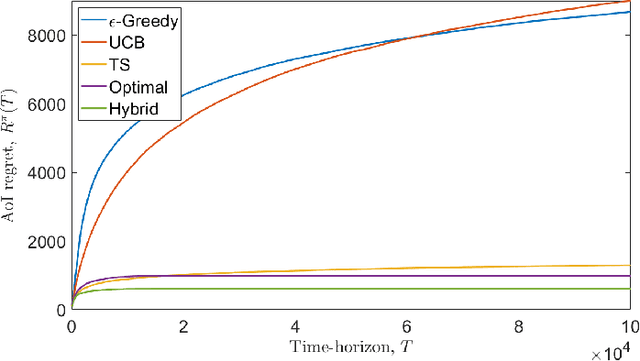
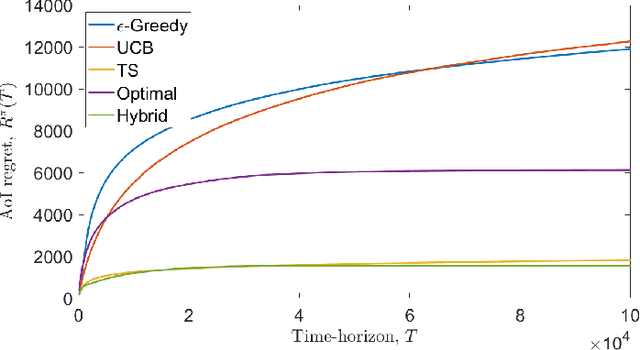
We consider a single-hop wireless network with sources transmitting time-sensitive information to the destination over multiple unreliable channels. Packets from each source are generated according to a stochastic process with known statistics and the state of each wireless channel (ON/OFF) varies according to a stochastic process with unknown statistics. The reliability of the wireless channels is to be learned through observation. At every time slot, the learning algorithm selects a single pair (source, channel) and the selected source attempts to transmit its packet via the selected channel. The probability of a successful transmission to the destination depends on the reliability of the selected channel. The goal of the learning algorithm is to minimize the Age-of-Information (AoI) in the network over $T$ time slots. To analyze the performance of the learning algorithm, we introduce the notion of AoI regret, which is the difference between the expected cumulative AoI of the learning algorithm under consideration and the expected cumulative AoI of a genie algorithm that knows the reliability of the channels a priori. The AoI regret captures the penalty incurred by having to learn the statistics of the channels over the $T$ time slots. The results are two-fold: first, we consider learning algorithms that employ well-known solutions to the stochastic multi-armed bandit problem (such as $\epsilon$-Greedy, Upper Confidence Bound, and Thompson Sampling) and show that their AoI regret scales as $\Theta(\log T)$; second, we develop a novel learning algorithm and show that it has $O(1)$ regret. To the best of our knowledge, this is the first learning algorithm with bounded AoI regret.
A self-supervised learning strategy for postoperative brain cavity segmentation simulating resections
May 24, 2021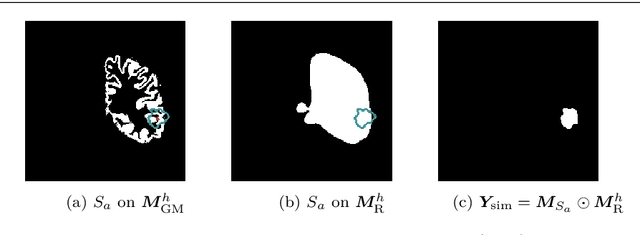
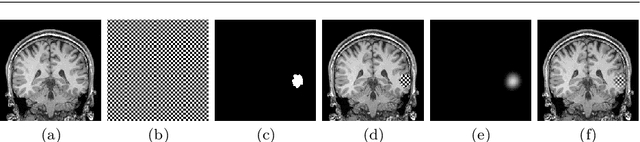
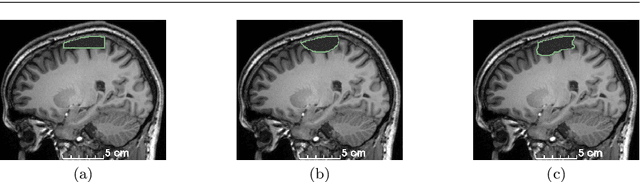
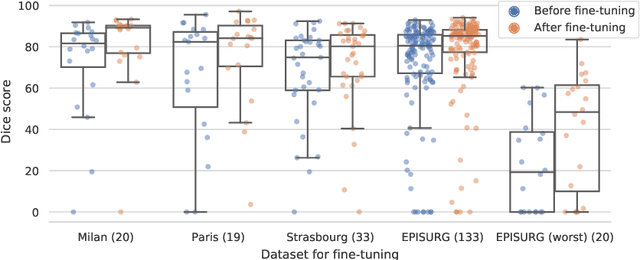
Accurate segmentation of brain resection cavities (RCs) aids in postoperative analysis and determining follow-up treatment. Convolutional neural networks (CNNs) are the state-of-the-art image segmentation technique, but require large annotated datasets for training. Annotation of 3D medical images is time-consuming, requires highly-trained raters, and may suffer from high inter-rater variability. Self-supervised learning strategies can leverage unlabeled data for training. We developed an algorithm to simulate resections from preoperative magnetic resonance images (MRIs). We performed self-supervised training of a 3D CNN for RC segmentation using our simulation method. We curated EPISURG, a dataset comprising 430 postoperative and 268 preoperative MRIs from 430 refractory epilepsy patients who underwent resective neurosurgery. We fine-tuned our model on three small annotated datasets from different institutions and on the annotated images in EPISURG, comprising 20, 33, 19 and 133 subjects. The model trained on data with simulated resections obtained median (interquartile range) Dice score coefficients (DSCs) of 81.7 (16.4), 82.4 (36.4), 74.9 (24.2) and 80.5 (18.7) for each of the four datasets. After fine-tuning, DSCs were 89.2 (13.3), 84.1 (19.8), 80.2 (20.1) and 85.2 (10.8). For comparison, inter-rater agreement between human annotators from our previous study was 84.0 (9.9). We present a self-supervised learning strategy for 3D CNNs using simulated RCs to accurately segment real RCs on postoperative MRI. Our method generalizes well to data from different institutions, pathologies and modalities. Source code, segmentation models and the EPISURG dataset are available at https://github.com/fepegar/ressegijcars .