 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast deep learning correspondence for neuron tracking and identification in C.elegans using synthetic training
Jan 20, 2021
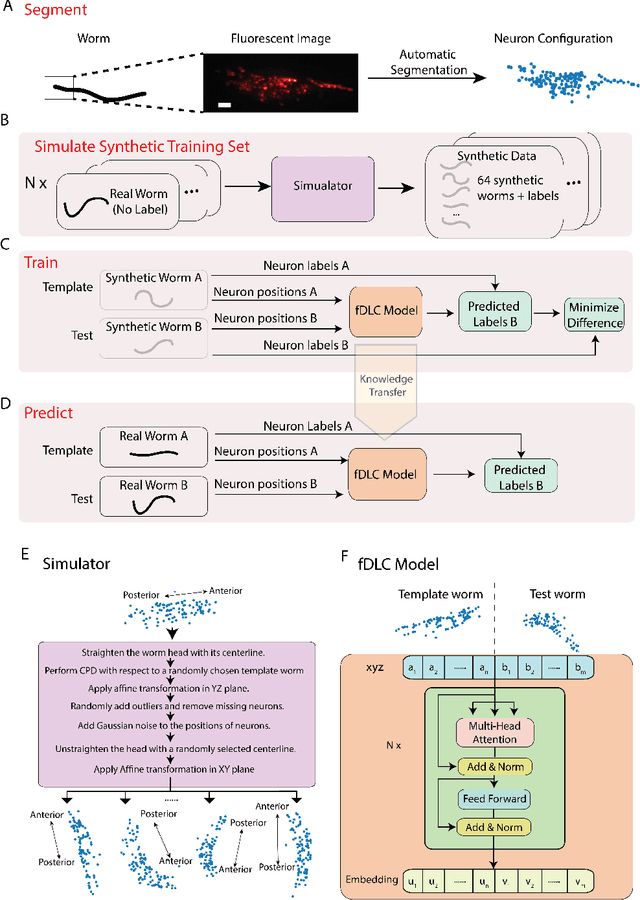
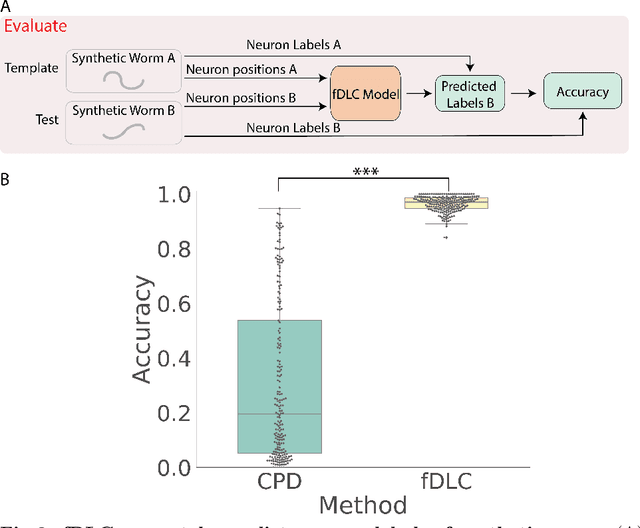
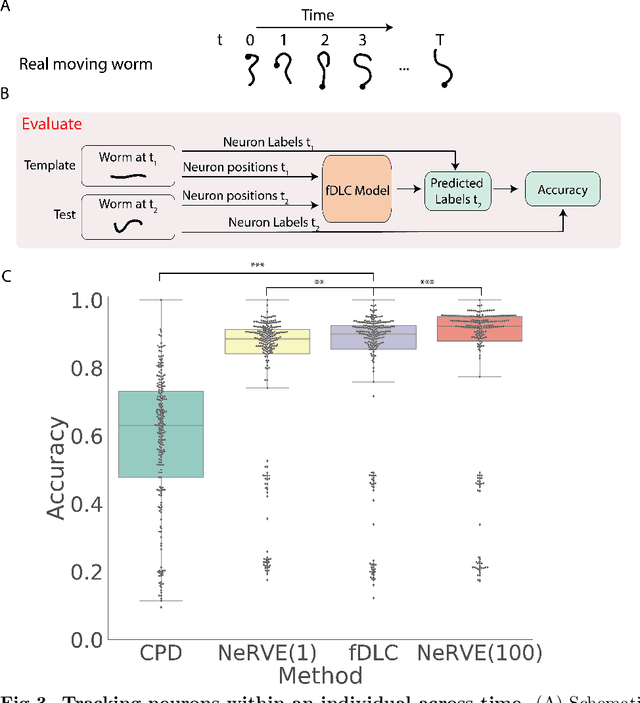
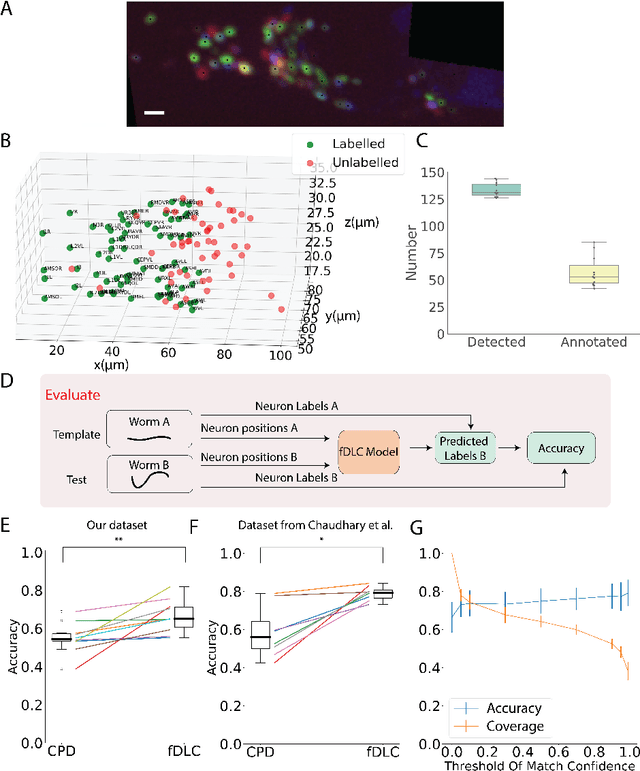
We present an automated method to track and identify neurons in C. elegans, called "fast Deep Learning Correspondence" or fDLC, based on the transformer network architecture. The model is trained once on empirically derived synthetic data and then predicts neural correspondence across held-out real animals via transfer learning. The same pre-trained model both tracks neurons across time and identifies corresponding neurons across individuals. Performance is evaluated against hand-annotated datasets, including NeuroPAL [1]. Using only position information, the method achieves 80.0% accuracy at tracking neurons within an individual and 65.8% accuracy at identifying neurons across individuals. Accuracy is even higher on a published dataset [2]. Accuracy reaches 76.5% when using color information from NeuroPAL. Unlike previous methods, fDLC does not require straightening or transforming the animal into a canonical coordinate system. The method is fast and predicts correspondence in 10 ms making it suitable for future real-time applications.
Intra-Document Cascading: Learning to Select Passages for Neural Document Ranking
May 20, 2021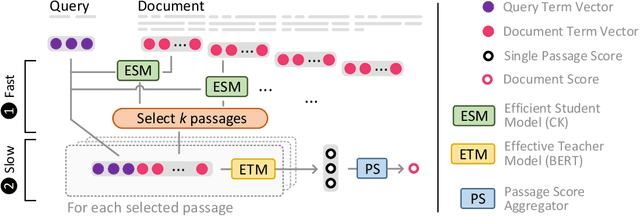
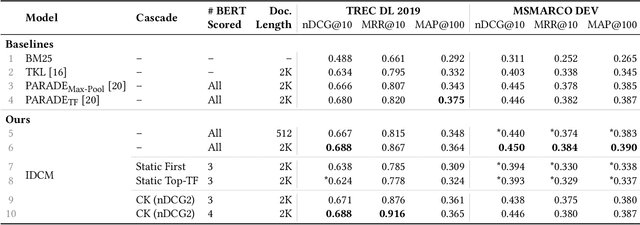
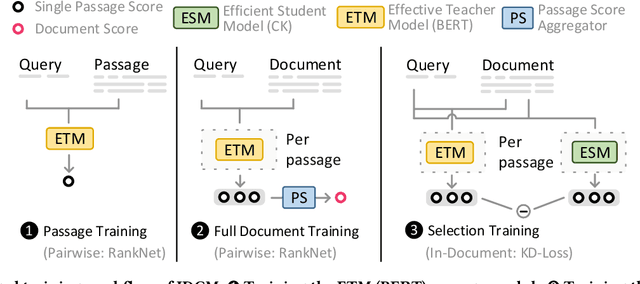
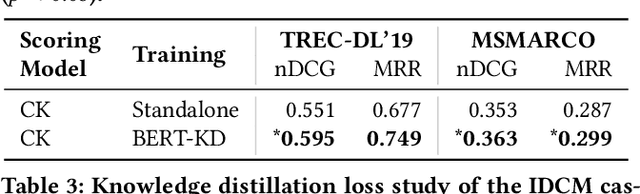
An emerging recipe for achieving state-of-the-art effectiveness in neural document re-ranking involves utilizing large pre-trained language models - e.g., BERT - to evaluate all individual passages in the document and then aggregating the outputs by pooling or additional Transformer layers. A major drawback of this approach is high query latency due to the cost of evaluating every passage in the document with BERT. To make matters worse, this high inference cost and latency varies based on the length of the document, with longer documents requiring more time and computation. To address this challenge, we adopt an intra-document cascading strategy, which prunes passages of a candidate document using a less expensive model, called ESM, before running a scoring model that is more expensive and effective, called ETM. We found it best to train ESM (short for Efficient Student Model) via knowledge distillation from the ETM (short for Effective Teacher Model) e.g., BERT. This pruning allows us to only run the ETM model on a smaller set of passages whose size does not vary by document length. Our experiments on the MS MARCO and TREC Deep Learning Track benchmarks suggest that the proposed Intra-Document Cascaded Ranking Model (IDCM) leads to over 400% lower query latency by providing essentially the same effectiveness as the state-of-the-art BERT-based document ranking models.
Straggler-Resilient Distributed Machine Learning with Dynamic Backup Workers
Feb 11, 2021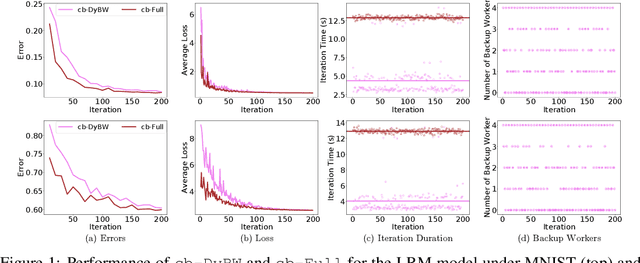

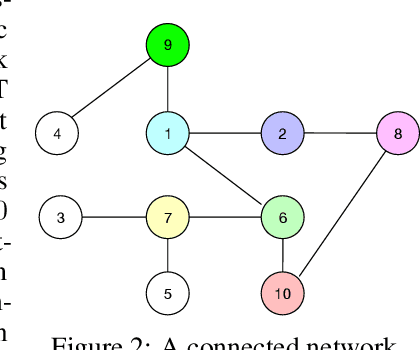
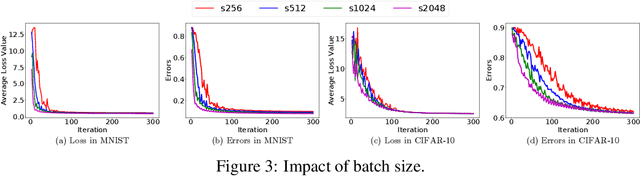
With the increasing demand for large-scale training of machine learning models, consensus-based distributed optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase can be time consuming due to the need to wait for \textit{stragglers}, i.e., slower workers. An efficient way to mitigate this effect is to let each worker wait only for updates from the fastest neighbors before updating its local parameter. The remaining neighbors are called \textit{backup workers.} To minimize the globally training time over the network, we propose a fully distributed algorithm to dynamically determine the number of backup workers for each worker. We show that our algorithm achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). We conduct extensive experiments on MNIST and CIFAR-10 to verify our theoretical results.
Randomized Histogram Matching: A Simple Augmentation for Unsupervised Domain Adaptation in Overhead Imagery
Apr 28, 2021
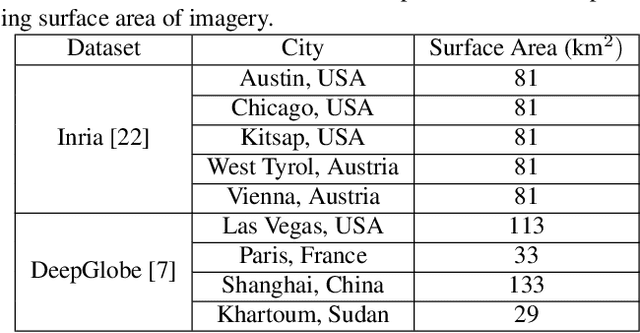
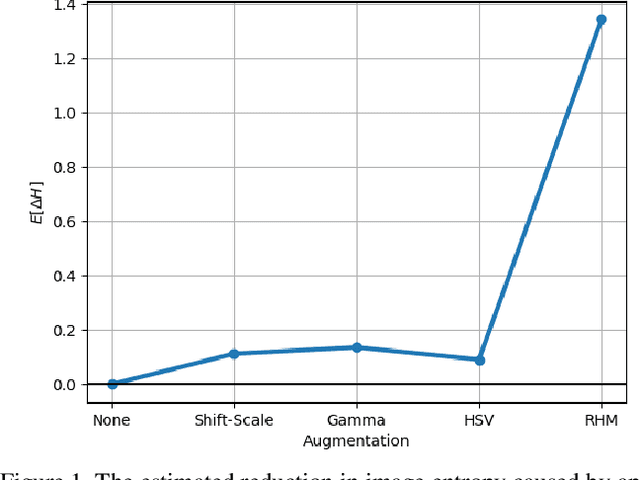
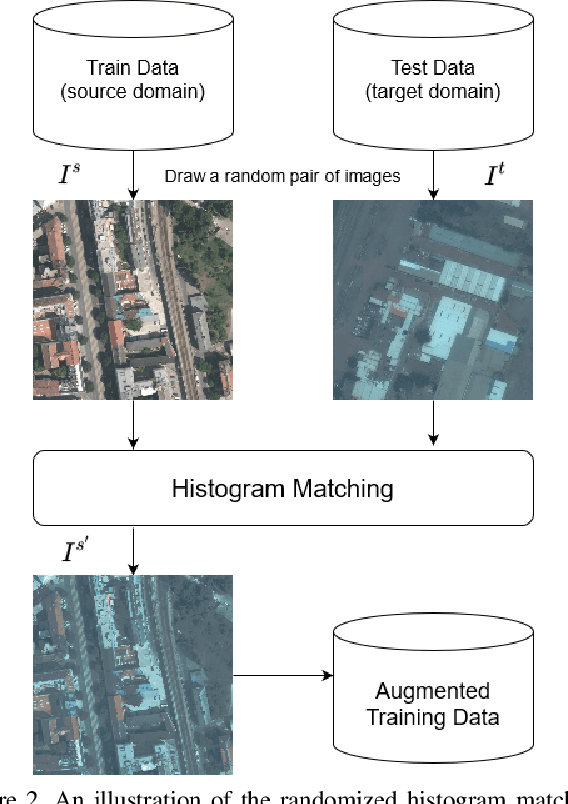
Modern deep neural networks (DNNs) achieve highly accurate results for many recognition tasks on overhead (e.g., satellite) imagery. One challenge however is visual domain shifts (i.e., statistical changes), which can cause the accuracy of DNNs to degrade substantially and unpredictably when tested on new sets of imagery. In this work we model domain shifts caused by variations in imaging hardware, lighting, and other conditions as non-linear pixel-wise transformations; and we show that modern DNNs can become largely invariant to these types of transformations, if provided with appropriate training data augmentation. In general, however, we do not know the transformation between two sets of imagery. To overcome this problem, we propose a simple real-time unsupervised training augmentation technique, termed randomized histogram matching (RHM). We conduct experiments with two large public benchmark datasets for building segmentation and find that RHM consistently yields comparable performance to recent state-of-the-art unsupervised domain adaptation approaches despite being simpler and faster. RHM also offers substantially better performance than other comparably simple approaches that are widely-used in overhead imagery.
Deep Learning based Efficient Symbol-Level Precoding Design for MU-MISO Systems
Apr 20, 2021
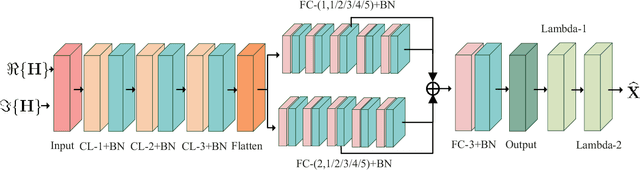
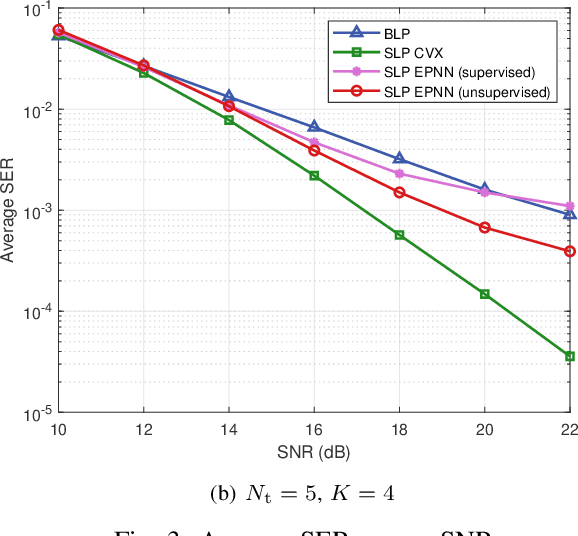
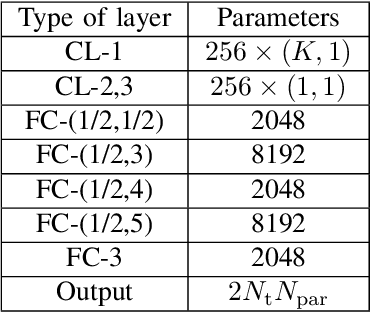
The recently emerged symbol-level precoding (SLP) technique has been regarded as a promising solution in multi-user wireless communication systems, since it can convert harmful multi-user interference (MUI) into beneficial signals for enhancing system performance. However, the tremendous computational complexity of conventional symbol-level precoding designs severely hinders the practical implementations. In order to tackle this difficulty, we propose a novel deep learning (DL) based approach to efficiently design the symbol-level precoders. Particularly, in this correspondence, we consider a multi-user multi-input single-output (MU-MISO) downlink system. An efficient precoding neural network (EPNN) is introduced to optimize the symbol-level precoders for maximizing the minimum quality-of-service (QoS) of all users under the power constraint. Simulation results demonstrate that the proposed EPNN based SLP design can dramatically reduce the computing time at the price of slight performance loss compared with the conventional convex optimization based SLP design.
Algorithmic Ethics: Formalization and Verification of Autonomous Vehicle Obligations
May 06, 2021
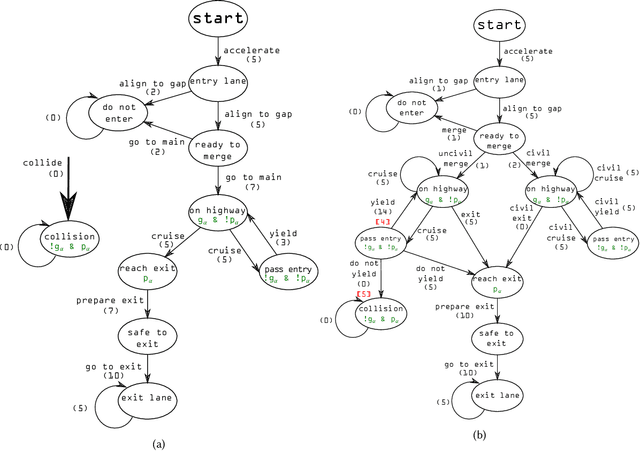
We develop a formal framework for automatic reasoning about the obligations of autonomous cyber-physical systems, including their social and ethical obligations. Obligations, permissions and prohibitions are distinct from a system's mission, and are a necessary part of specifying advanced, adaptive AI-equipped systems. They need a dedicated deontic logic of obligations to formalize them. Most existing deontic logics lack corresponding algorithms and system models that permit automatic verification. We demonstrate how a particular deontic logic, Dominance Act Utilitarianism (DAU), is a suitable starting point for formalizing the obligations of autonomous systems like self-driving cars. We demonstrate its usefulness by formalizing a subset of Responsibility-Sensitive Safety (RSS) in DAU; RSS is an industrial proposal for how self-driving cars should and should not behave in traffic. We show that certain logical consequences of RSS are undesirable, indicating a need to further refine the proposal. We also demonstrate how obligations can change over time, which is necessary for long-term autonomy. We then demonstrate a model-checking algorithm for DAU formulas on weighted transition systems, and illustrate it by model-checking obligations of a self-driving car controller from the literature.
Image Segmentation Methods for Non-destructive testing Applications
Mar 13, 2021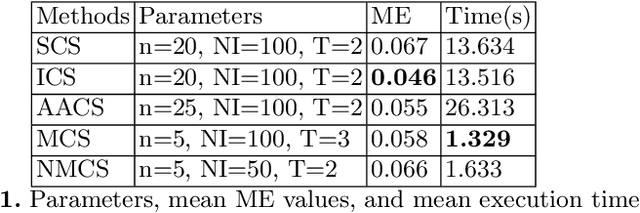
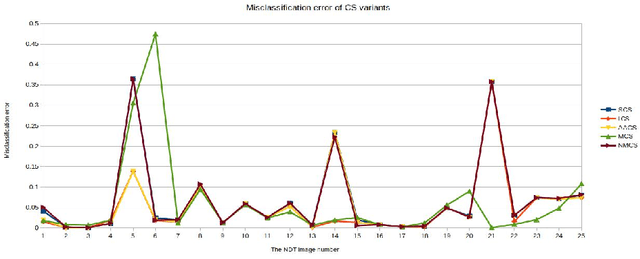
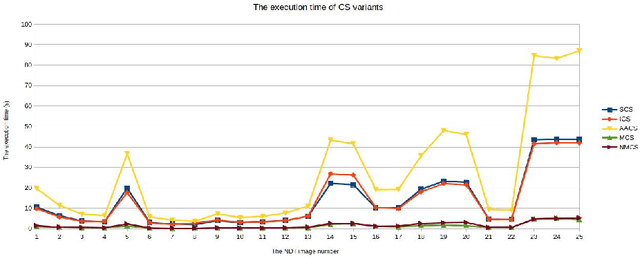

In this paper, we present new image segmentation methods based on hidden Markov random fields (HMRFs) and cuckoo search (CS) variants. HMRFs model the segmentation problem as a minimization of an energy function. CS algorithm is one of the recent powerful optimization techniques. Therefore, five variants of the CS algorithm are used to compute a solution. Through tests, we conduct a study to choose the CS variant with parameters that give good results (execution time and quality of segmentation). CS variants are evaluated and compared with non-destructive testing (NDT) images using a misclassification error (ME) criterion.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
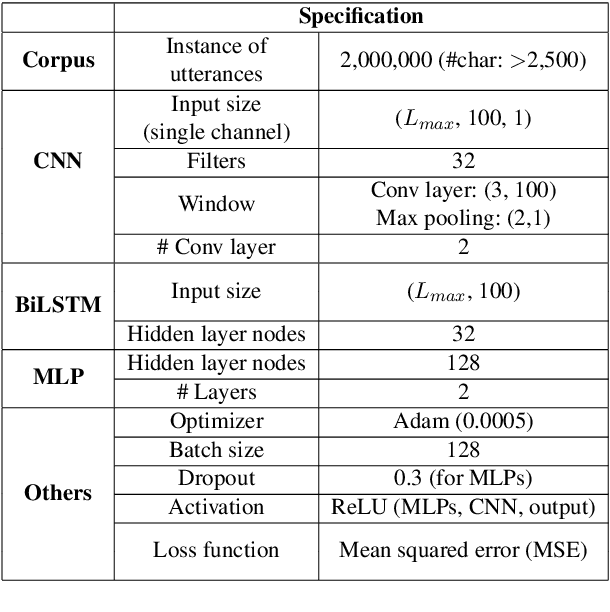
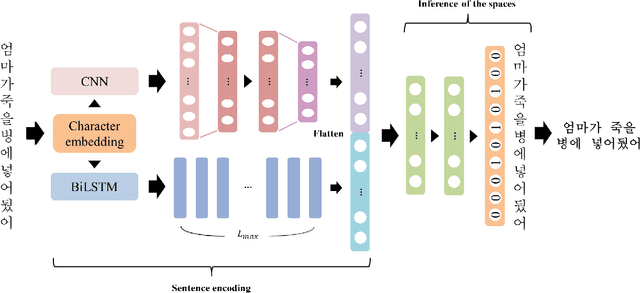
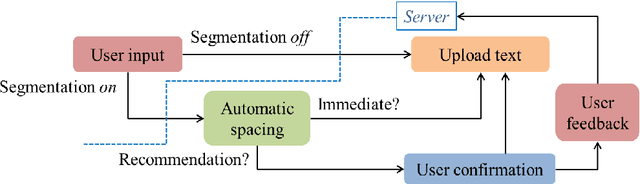
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.
MS2: Multi-Document Summarization of Medical Studies
Apr 15, 2021

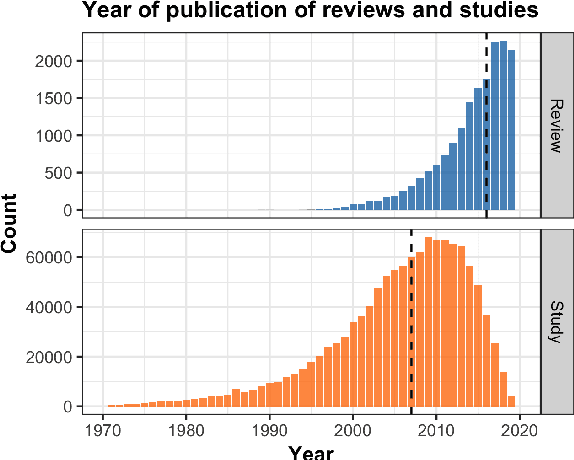
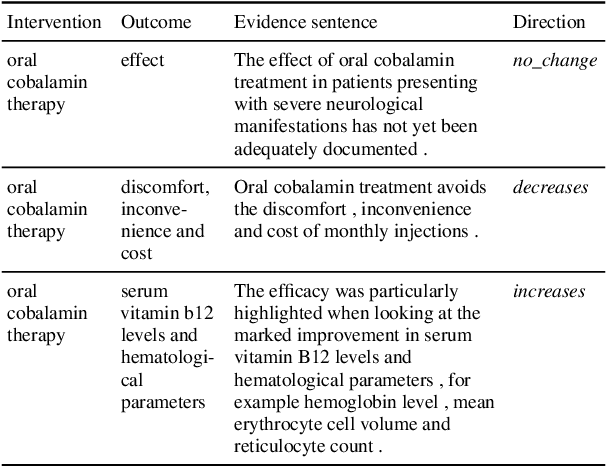
To assess the effectiveness of any medical intervention, researchers must conduct a time-intensive and highly manual literature review. NLP systems can help to automate or assist in parts of this expensive process. In support of this goal, we release MS^2 (Multi-Document Summarization of Medical Studies), a dataset of over 470k documents and 20k summaries derived from the scientific literature. This dataset facilitates the development of systems that can assess and aggregate contradictory evidence across multiple studies, and is the first large-scale, publicly available multi-document summarization dataset in the biomedical domain. We experiment with a summarization system based on BART, with promising early results. We formulate our summarization inputs and targets in both free text and structured forms and modify a recently proposed metric to assess the quality of our system's generated summaries. Data and models are available at https://github.com/allenai/ms2
Adaptive Robust Model Predictive Control with Matched and Unmatched Uncertainty
May 13, 2021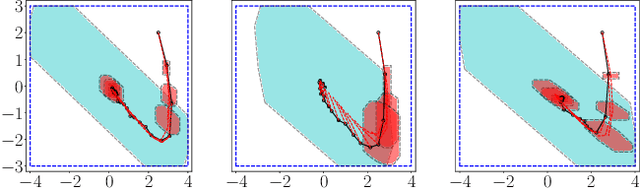
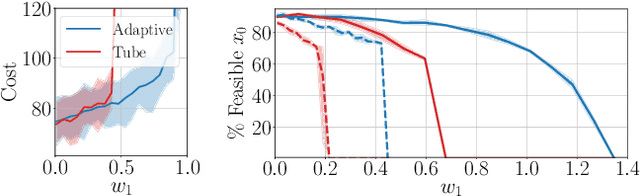
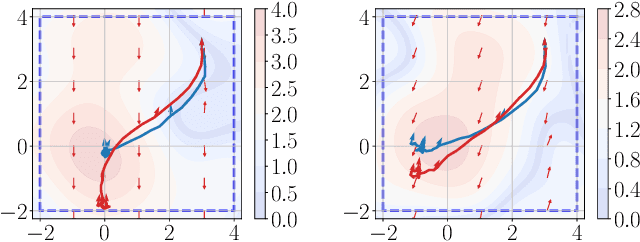
We propose a learning-based robust predictive control algorithm that can handle large uncertainty in the dynamics for a class of discrete-time systems that are nominally linear with an additive nonlinear dynamics component. Such systems commonly model the nonlinear effects of an unknown environment on a nominal system. Motivated by an inability of existing learning-based predictive control algorithms to achieve safety guarantees in the presence of uncertainties of large magnitude in this setting, we achieve significant performance improvements by optimizing over a novel class of nonlinear feedback policies inspired by certainty equivalent "estimate-and-cancel" control laws pioneered in classical adaptive control. In contrast with previous work in robust adaptive MPC, this allows us to take advantage of the structure in the a priori unknown dynamics that are learned online through function approximation. Our approach also extends typical nonlinear adaptive control methods to systems with state and input constraints even when an additive uncertain function cannot directly be canceled from the dynamics. Moreover, our approach allows us to apply contemporary statistical estimation techniques to certify the safety of the system through persistent constraint satisfaction with high probability. We show that our method allows us to consider larger unknown terms in the dynamics than existing methods through simulated examples.