 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hide and Seek tracker: Real-time recovery from target loss
Jun 20, 2018
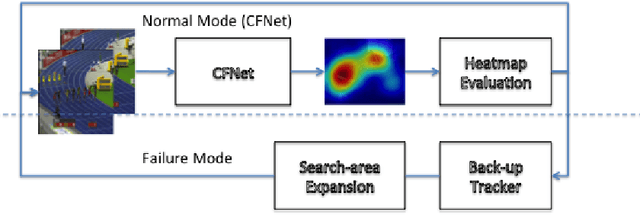

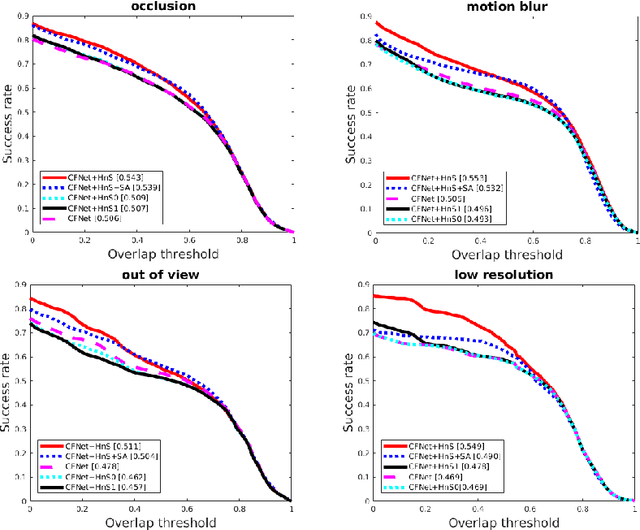
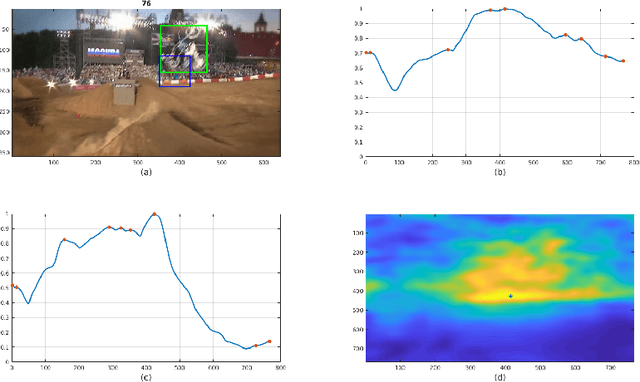
In this paper, we examine the real-time recovery of a video tracker from a target loss, using information that is already available from the original tracker and without a significant computational overhead. More specifically, before using the tracker output to update the target position we estimate the detection confidence. In the case of a low confidence, the position update is rejected and the tracker passes to a single-frame failure mode, during which the patch low-level visual content is used to swiftly update the object position, before recovering from the target loss in the next frame. Orthogonally to this improvement, we further enhance the running average method used for creating the query model in tracking-through-similarity. The experimental evidence provided by evaluation on standard tracking datasets (OTB-50, OTB-100 and OTB-2013) validate that target recovery can be successfully achieved without compromising the real-time update of the target position.
Search Algorithms for Automated Hyper-Parameter Tuning
Apr 29, 2021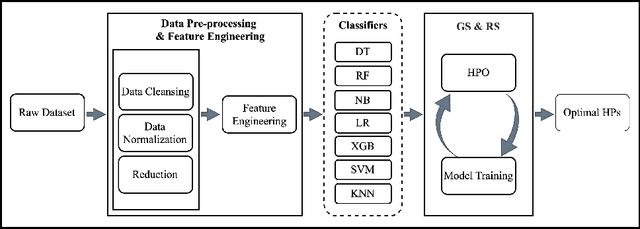
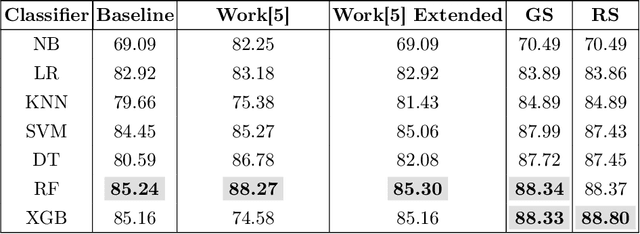
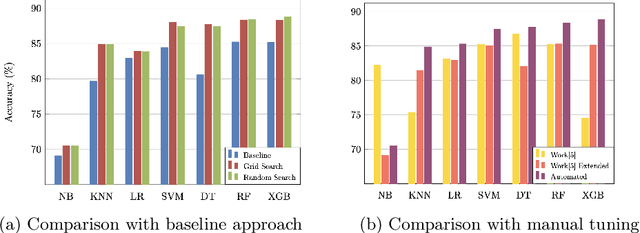
Machine learning is a powerful method for modeling in different fields such as education. Its capability to accurately predict students' success makes it an ideal tool for decision-making tasks related to higher education. The accuracy of machine learning models depends on selecting the proper hyper-parameters. However, it is not an easy task because it requires time and expertise to tune the hyper-parameters to fit the machine learning model. In this paper, we examine the effectiveness of automated hyper-parameter tuning techniques to the realm of students' success. Therefore, we develop two automated Hyper-Parameter Optimization methods, namely grid search and random search, to assess and improve a previous study's performance. The experiment results show that applying random search and grid search on machine learning algorithms improves accuracy. We empirically show automated methods' superiority on real-world educational data (MIDFIELD) for tuning HPs of conventional machine learning classifiers. This work emphasizes the effectiveness of automated hyper-parameter optimization while applying machine learning in the education field to aid faculties, directors', or non-expert users' decisions to improve students' success.
Large-Scale Gravitational Lens Modeling with Bayesian Neural Networks for Accurate and Precise Inference of the Hubble Constant
Nov 30, 2020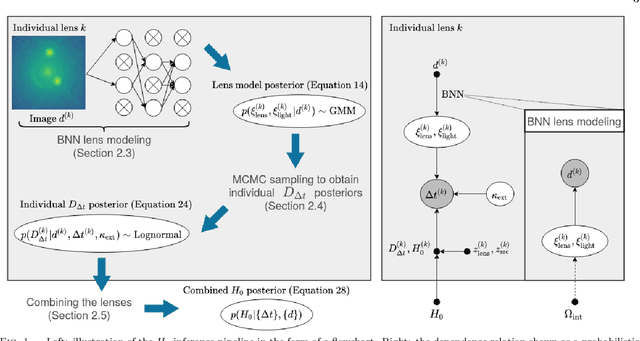
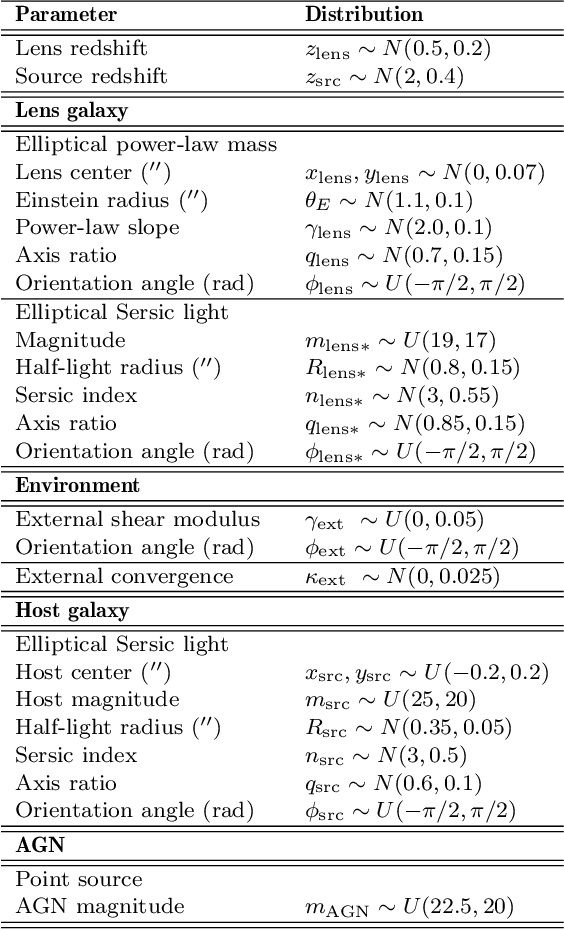
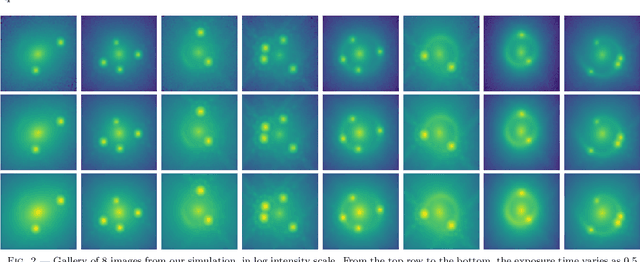
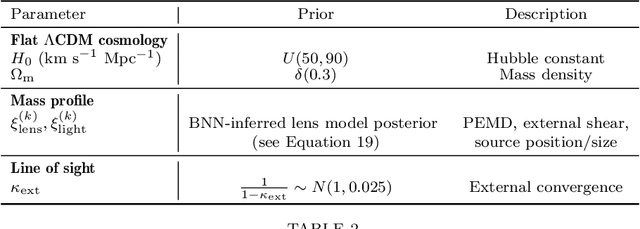
We investigate the use of approximate Bayesian neural networks (BNNs) in modeling hundreds of time-delay gravitational lenses for Hubble constant ($H_0$) determination. Our BNN was trained on synthetic HST-quality images of strongly lensed active galactic nuclei (AGN) with lens galaxy light included. The BNN can accurately characterize the posterior PDFs of model parameters governing the elliptical power-law mass profile in an external shear field. We then propagate the BNN-inferred posterior PDFs into ensemble $H_0$ inference, using simulated time delay measurements from a plausible dedicated monitoring campaign. Assuming well-measured time delays and a reasonable set of priors on the environment of the lens, we achieve a median precision of $9.3$\% per lens in the inferred $H_0$. A simple combination of 200 test-set lenses results in a precision of 0.5 $\textrm{km s}^{-1} \textrm{ Mpc}^{-1}$ ($0.7\%$), with no detectable bias in this $H_0$ recovery test. The computation time for the entire pipeline -- including the training set generation, BNN training, and $H_0$ inference -- translates to 9 minutes per lens on average for 200 lenses and converges to 6 minutes per lens as the sample size is increased. Being fully automated and efficient, our pipeline is a promising tool for exploring ensemble-level systematics in lens modeling for $H_0$ inference.
FPT Approximation for Socially Fair Clustering
Jun 12, 2021In this work, we study the socially fair $k$-median/$k$-means problem. We are given a set of points $P$ in a metric space $\mathcal{X}$ with a distance function $d(.,.)$. There are $\ell$ groups: $P_1,\dotsc,P_{\ell} \subseteq P$. We are also given a set $F$ of feasible centers in $\mathcal{X}$. The goal of the socially fair $k$-median problem is to find a set $C \subseteq F$ of $k$ centers that minimizes the maximum average cost over all the groups. That is, find $C$ that minimizes the objective function $\Phi(C,P) \equiv \max_{j} \sum_{x \in P_j} d(C,x)/|P_j|$, where $d(C,x)$ is the distance of $x$ to the closest center in $C$. The socially fair $k$-means problem is defined similarly by using squared distances, i.e., $d^{2}(.,.)$ instead of $d(.,.)$. In this work, we design $(5+\varepsilon)$ and $(33 + \varepsilon)$ approximation algorithms for the socially fair $k$-median and $k$-means problems, respectively. For the parameters: $k$ and $\ell$, the algorithms have an FPT (fixed parameter tractable) running time of $f(k,\ell,\varepsilon) \cdot n$ for $f(k,\ell,\varepsilon) = 2^{{O}(k \, \ell/\varepsilon)}$ and $n = |P \cup F|$. We also study a special case of the problem where the centers are allowed to be chosen from the point set $P$, i.e., $P \subseteq F$. For this special case, our algorithms give better approximation guarantees of $(4+\varepsilon)$ and $(18+\varepsilon)$ for the socially fair $k$-median and $k$-means problems, respectively. Furthermore, we convert these algorithms to constant pass log-space streaming algorithms. Lastly, we show FPT hardness of approximation results for the problem with a small gap between our upper and lower bounds.
Morphological Change Forecasting for Prostate Glands using Feature-based Registration and Kernel Density Extrapolation
Jan 16, 2021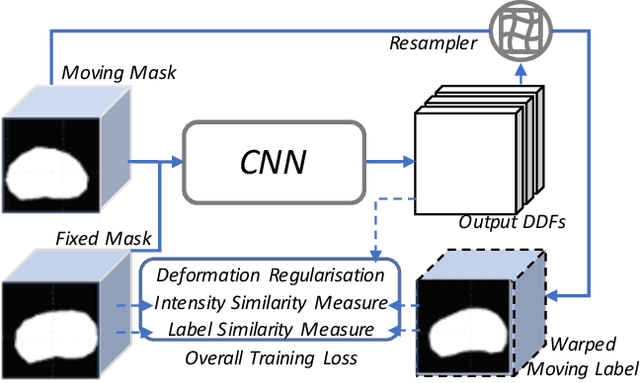
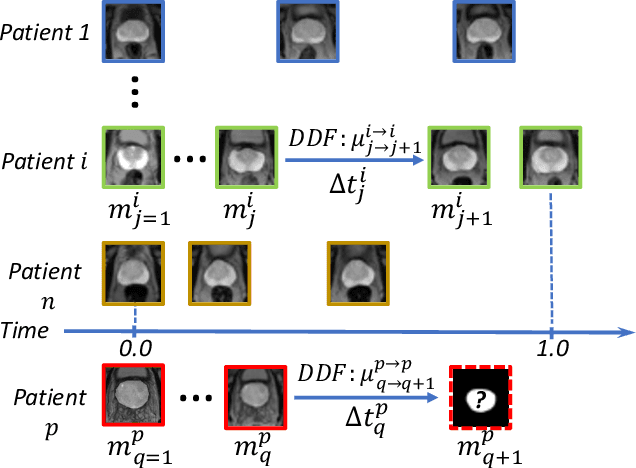
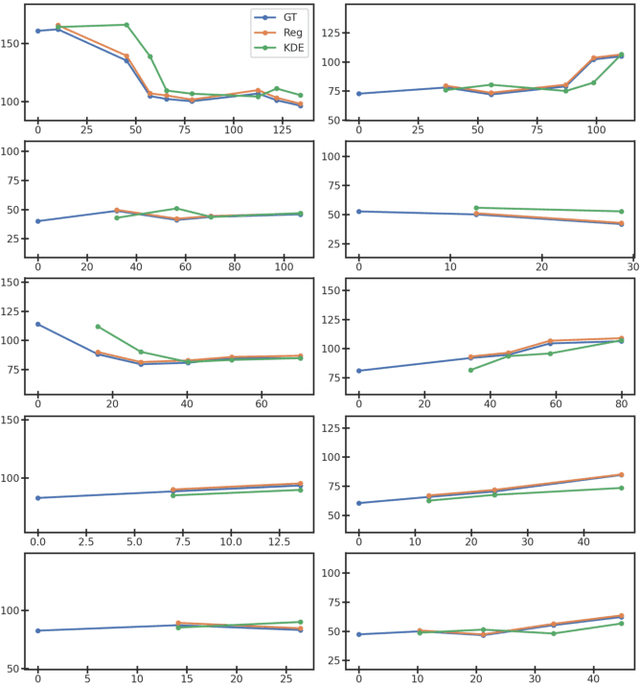
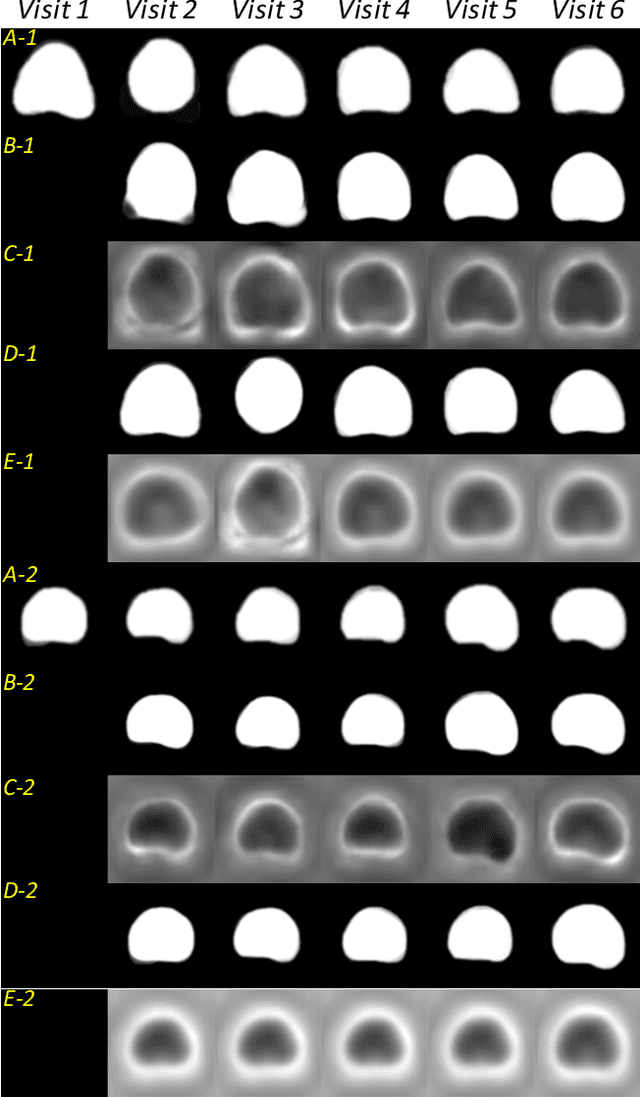
Organ morphology is a key indicator for prostate disease diagnosis and prognosis. For instance, In longitudinal study of prostate cancer patients under active surveillance, the volume, boundary smoothness and their changes are closely monitored on time-series MR image data. In this paper, we describe a new framework for forecasting prostate morphological changes, as the ability to detect such changes earlier than what is currently possible may enable timely treatment or avoiding unnecessary confirmatory biopsies. In this work, an efficient feature-based MR image registration is first developed to align delineated prostate gland capsules to quantify the morphological changes using the inferred dense displacement fields (DDFs). We then propose to use kernel density estimation (KDE) of the probability density of the DDF-represented \textit{future morphology changes}, between current and future time points, before the future data become available. The KDE utilises a novel distance function that takes into account morphology, stage-of-progression and duration-of-change, which are considered factors in such subject-specific forecasting. We validate the proposed approach on image masks unseen to registration network training, without using any data acquired at the future target time points. The experiment results are presented on a longitudinal data set with 331 images from 73 patients, yielding an average Dice score of 0.865 on a holdout set, between the ground-truth and the image masks warped by the KDE-predicted-DDFs.
Adversarial autoencoders and adversarial LSTM for improved forecasts of urban air pollution simulations
Apr 16, 2021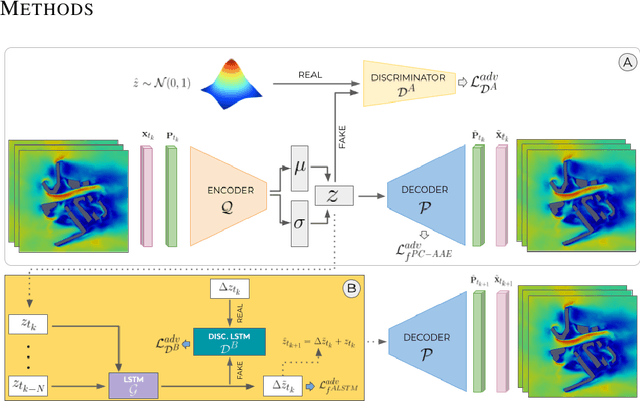
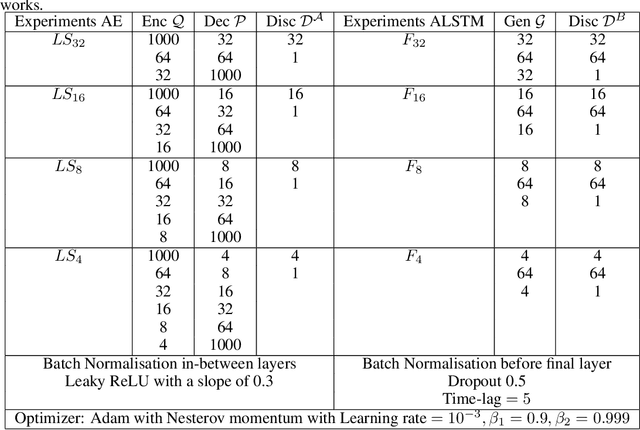
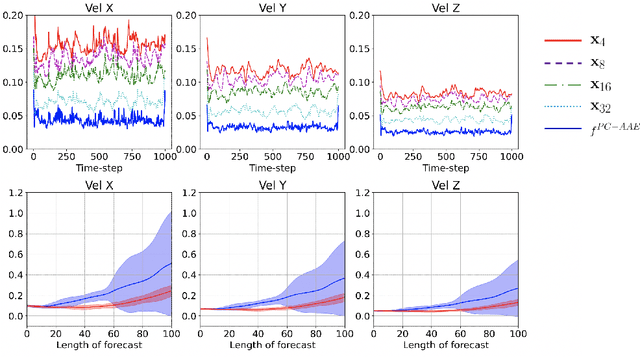
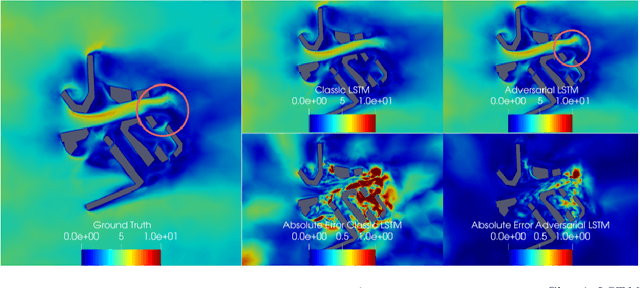
This paper presents an approach to improve the forecast of computational fluid dynamics (CFD) simulations of urban air pollution using deep learning, and most specifically adversarial training. This adversarial approach aims to reduce the divergence of the forecasts from the underlying physical model. Our two-step method integrates a Principal Components Analysis (PCA) based adversarial autoencoder (PC-AAE) with adversarial Long short-term memory (LSTM) networks. Once the reduced-order model (ROM) of the CFD solution is obtained via PCA, an adversarial autoencoder is used on the principal components time series. Subsequentially, a Long Short-Term Memory network (LSTM) is adversarially trained on the latent space produced by the PC-AAE to make forecasts. Once trained, the adversarially trained LSTM outperforms a LSTM trained in a classical way. The study area is in South London, including three-dimensional velocity vectors in a busy traffic junction.
Yes We Care! -- Certification for Machine Learning Methods through the Care Label Framework
May 21, 2021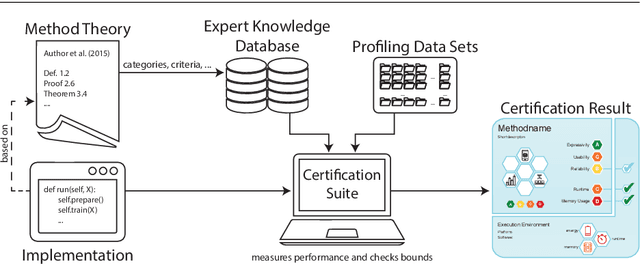
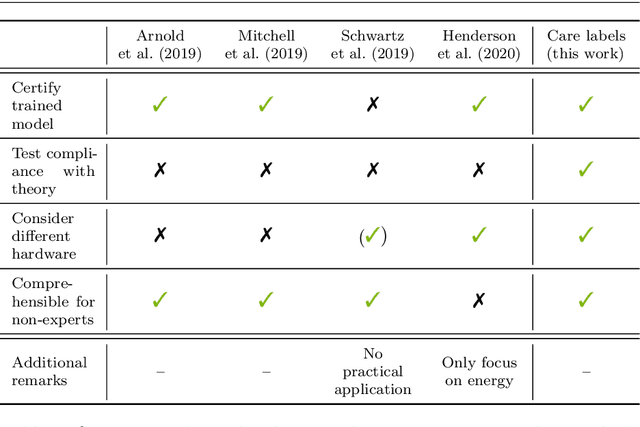
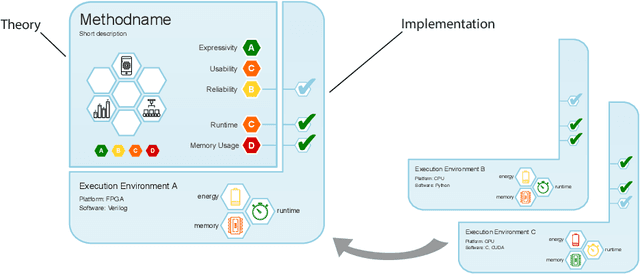
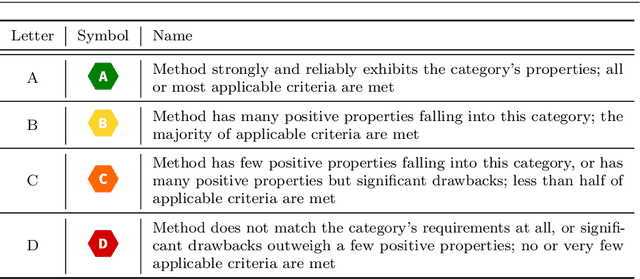
Machine learning applications have become ubiquitous. Their applications from machine embedded control in production over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address knowledgeable users and application engineers. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time understanding the model. Instead, they want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to stakeholders without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a model? These questions move far beyond the current state-of-the-art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds. In this paper, we illustrate care labels by a prototype implementation of a certification suite for a selection of probabilistic graphical models.
The Generalized Mean Densest Subgraph Problem
Jun 02, 2021



Finding dense subgraphs of a large graph is a standard problem in graph mining that has been studied extensively both for its theoretical richness and its many practical applications. In this paper we introduce a new family of dense subgraph objectives, parameterized by a single parameter $p$, based on computing generalized means of degree sequences of a subgraph. Our objective captures both the standard densest subgraph problem and the maximum $k$-core as special cases, and provides a way to interpolate between and extrapolate beyond these two objectives when searching for other notions of dense subgraphs. In terms of algorithmic contributions, we first show that our objective can be minimized in polynomial time for all $p \geq 1$ using repeated submodular minimization. A major contribution of our work is analyzing the performance of different types of peeling algorithms for dense subgraphs both in theory and practice. We prove that the standard peeling algorithm can perform arbitrarily poorly on our generalized objective, but we then design a more sophisticated peeling method which for $p \geq 1$ has an approximation guarantee that is always at least $1/2$ and converges to 1 as $p \rightarrow \infty$. In practice, we show that this algorithm obtains extremely good approximations to the optimal solution, scales to large graphs, and highlights a range of different meaningful notions of density on graphs coming from numerous domains. Furthermore, it is typically able to approximate the densest subgraph problem better than the standard peeling algorithm, by better accounting for how the removal of one node affects other nodes in its neighborhood.
iLQR for Piecewise-Smooth Hybrid Dynamical Systems
Mar 26, 2021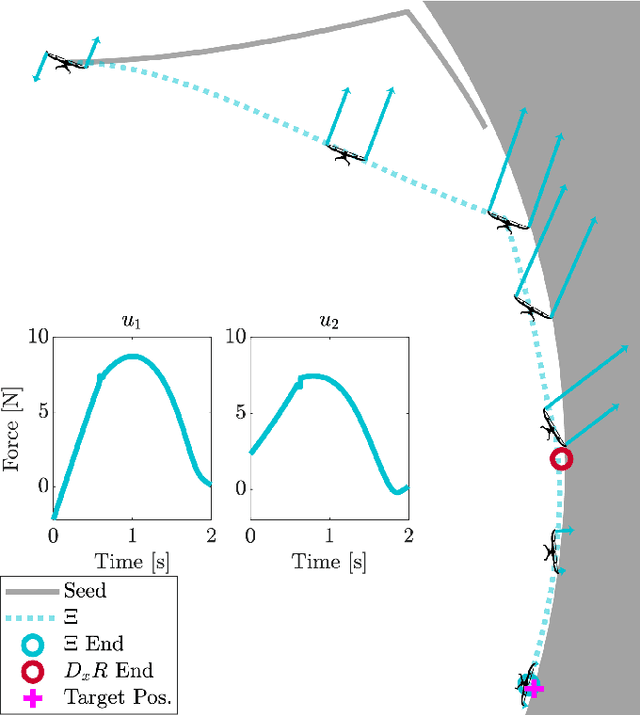
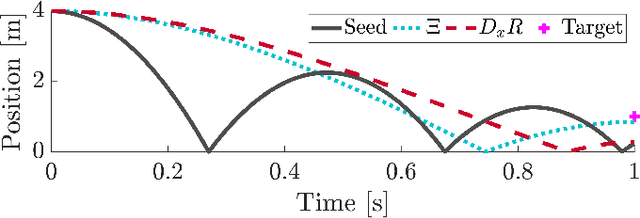
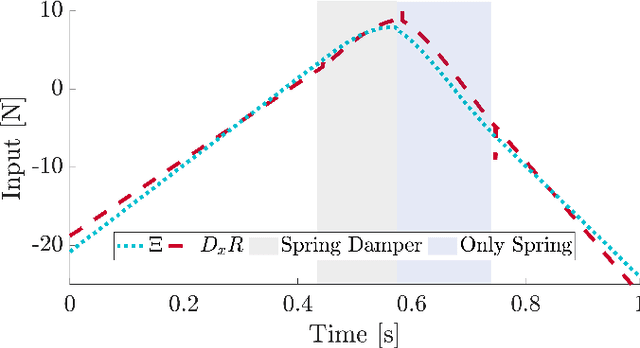
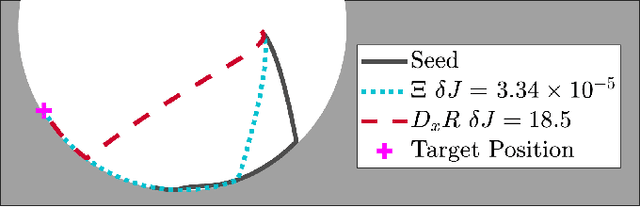
Trajectory optimization is a popular strategy for planning trajectories for robotic systems. However, many robotic tasks require changing contact conditions, which is difficult due to the hybrid nature of the dynamics. The optimal sequence and timing of these modes are typically not known ahead of time. In this work, we extend the Iterative Linear Quadratic Regulator (iLQR) method to a class of piecewise smooth hybrid dynamical systems by allowing for changing hybrid modes in the forward pass, using the saltation matrix to update the gradient information in the backwards pass, and using a reference extension to account for mode mismatch. We demonstrate these changes on a variety of hybrid systems and compare the different strategies for computing the gradients.
Enhancing Safety of Students with Mobile Air Filtration during School Reopening from COVID-19
Apr 29, 2021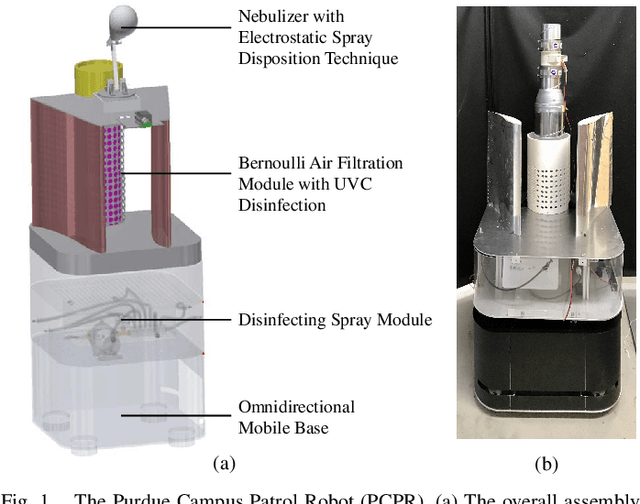
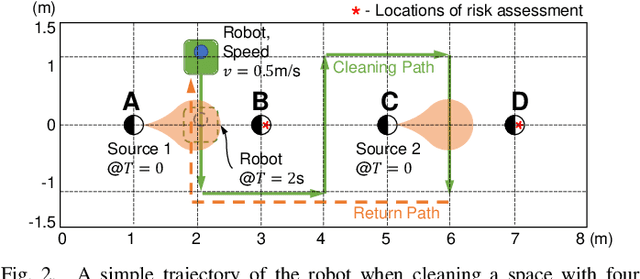
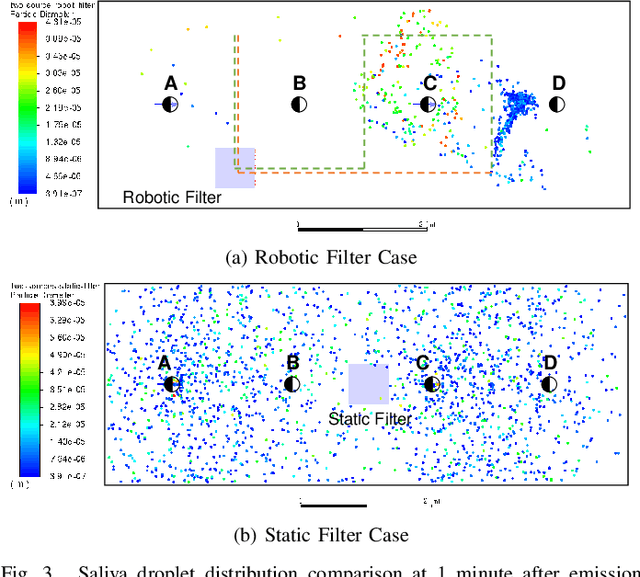
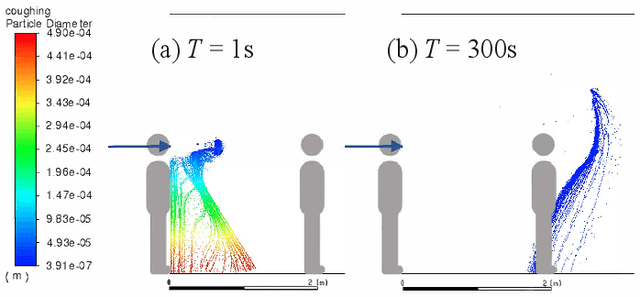
The paper discusses how robots enable occupant-safe continuous protection for students when schools reopen. Conventionally, fixed air filters are not used as a key pandemic prevention method for public indoor spaces because they are unable to trap the airborne pathogens in time in the entire room. However, by combining the mobility of a robot with air filtration, the efficacy of cleaning up the air around multiple people is largely increased. A disinfection co-robot prototype is thus developed to provide continuous and occupant-friendly protection to people gathering indoors, specifically for students in a classroom scenario. In a static classroom with students sitting in a grid pattern, the mobile robot is able to serve up to 14 students per cycle while reducing the worst-case pathogen dosage by 20%, and with higher robustness compared to a static filter. The extent of robot protection is optimized by tuning the passing distance and speed, such that a robot is able to serve more people given a threshold of worst-case dosage a person can receive.