 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MBA-VO: Motion Blur Aware Visual Odometry
Mar 25, 2021

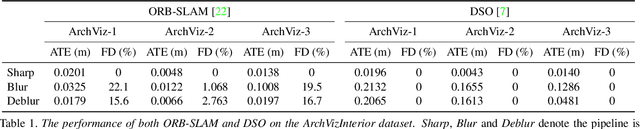
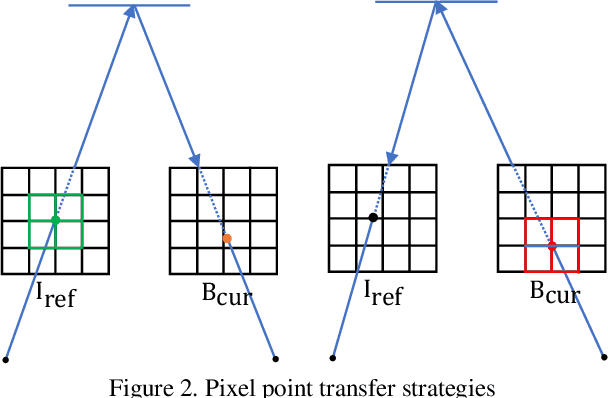
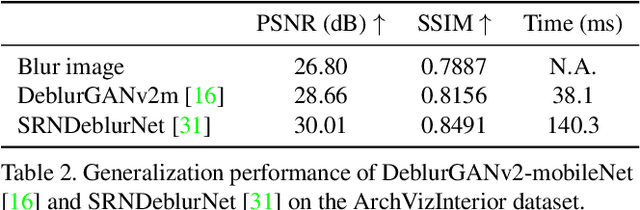
Motion blur is one of the major challenges remaining for visual odometry methods. In low-light conditions where longer exposure times are necessary, motion blur can appear even for relatively slow camera motions. In this paper we present a novel hybrid visual odometry pipeline with direct approach that explicitly models and estimates the camera's local trajectory within the exposure time. This allows us to actively compensate for any motion blur that occurs due to the camera motion. In addition, we also contribute a novel benchmarking dataset for motion blur aware visual odometry. In experiments we show that by directly modeling the image formation process, we are able to improve robustness of the visual odometry, while keeping comparable accuracy as that for images without motion blur.
Survey on Modeling Intensity Function of Hawkes Process Using Neural Models
Apr 22, 2021
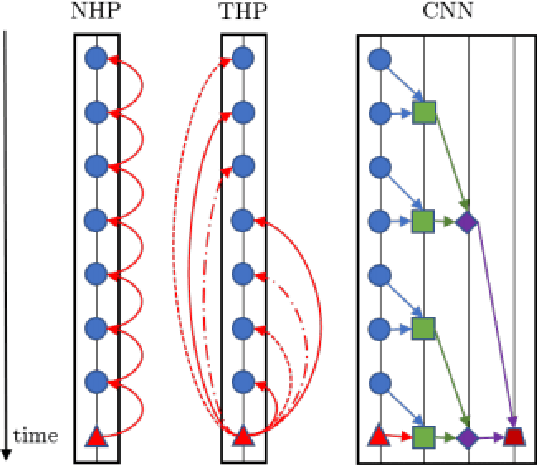
The event sequence of many diverse systems is represented as a sequence of discrete events in a continuous space. Examples of such an event sequence are earthquake aftershock events, financial transactions, e-commerce transactions, social network activity of a user, and the user's web search pattern. Finding such an intricate pattern helps discover which event will occur in the future and when it will occur. A Hawkes process is a mathematical tool used for modeling such time series discrete events. Traditionally, the Hawkes process uses a critical component for modeling data as an intensity function with a parameterized kernel function. The Hawkes process's intensity function involves two components: the background intensity and the effect of events' history. However, such parameterized assumption can not capture future event characteristics using past events data precisely due to bias in modeling kernel function. This paper explores the recent advancement using novel deep learning-based methods to model kernel function to remove such parametrized kernel function. In the end, we will give potential future research directions to improve modeling using the Hawkes process.
Solving the Workflow Satisfiability Problem using General Purpose Solvers
May 07, 2021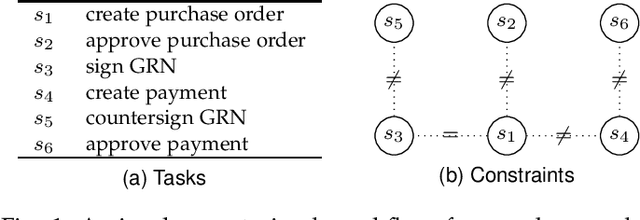

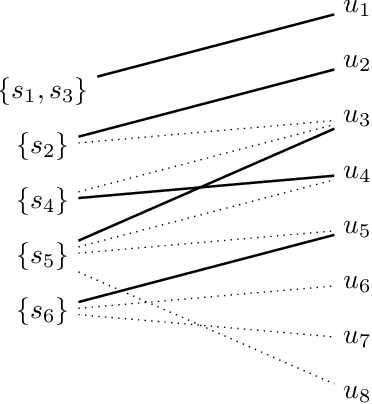
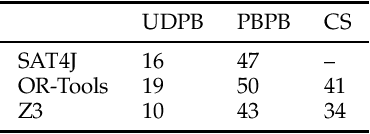
The workflow satisfiability problem (WSP) is a well-studied problem in access control seeking allocation of authorised users to every step of the workflow, subject to workflow specification constraints. It was noticed that the number $k$ of steps is typically small compared to the number of users in the real-world instances of WSP; therefore $k$ is considered as the parameter in WSP parametrised complexity research. While WSP in general was shown to be W[1]-hard, WSP restricted to a special case of user-independent (UI) constraints is fixed-parameter tractable (FPT). However, restriction to the UI constraints might be impractical. To efficiently handle non-UI constraints, we introduce the notion of branching factor of a constraint. As long as the branching factors of the constraints are relatively small and the number of non-UI constraints is reasonable, WSP can be solved in FPT time. Extending the results from Karapetyan et al. (2019), we demonstrate that general-purpose solvers are capable of achieving FPT-like performance on WSP with arbitrary constraints when used with appropriate formulations. This enables one to tackle most of practical WSP instances. While important on its own, we hope that this result will also motivate researchers to look for FPT-aware formulations of other FPT problems.
Temporal Logistic Neural Bag-of-Features for Financial Time series Forecasting leveraging Limit Order Book Data
Jan 24, 2019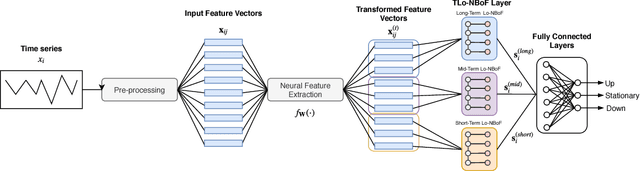

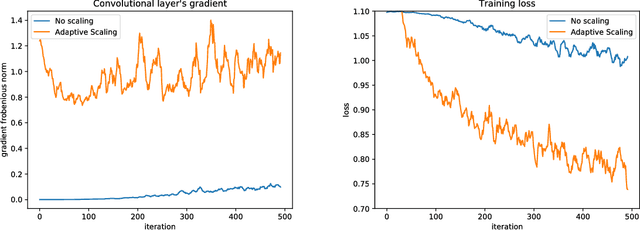

Time series forecasting is a crucial component of many important applications, ranging from forecasting the stock markets to energy load prediction. The high-dimensionality, velocity and variety of the data collected in these applications pose significant and unique challenges that must be carefully addressed for each of them. In this work, a novel Temporal Logistic Neural Bag-of-Features approach, that can be used to tackle these challenges, is proposed. The proposed method can be effectively combined with deep neural networks, leading to powerful deep learning models for time series analysis. However, combining existing BoF formulations with deep feature extractors pose significant challenges: the distribution of the input features is not stationary, tuning the hyper-parameters of the model can be especially difficult and the normalizations involved in the BoF model can cause significant instabilities during the training process. The proposed method is capable of overcoming these limitations by a employing a novel adaptive scaling mechanism and replacing the classical Gaussian-based density estimation involved in the regular BoF model with a logistic kernel. The effectiveness of the proposed approach is demonstrated using extensive experiments on a large-scale financial time series dataset that consists of more than 4 million limit orders.
Intelligent Intersection: Two-Stream Convolutional Networks for Real-time Near Accident Detection in Traffic Video
Jan 04, 2019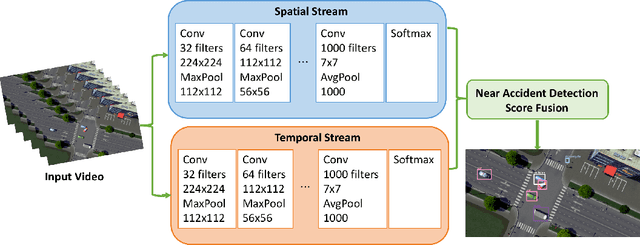
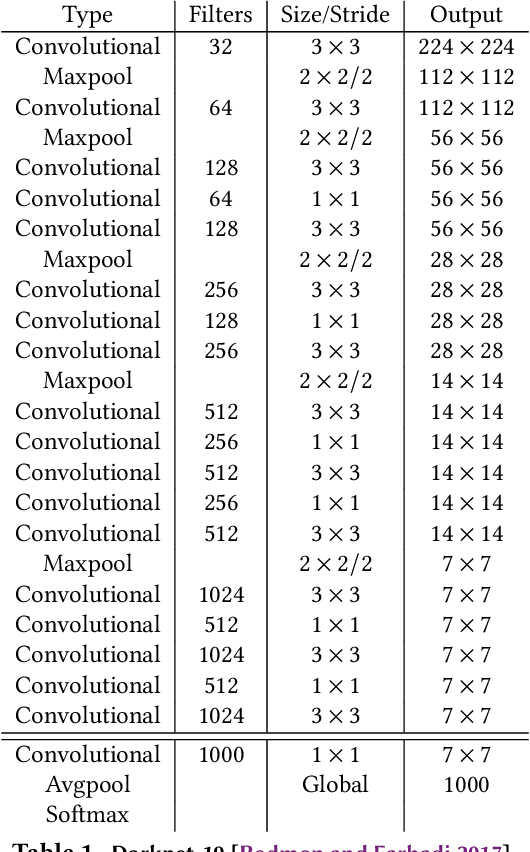
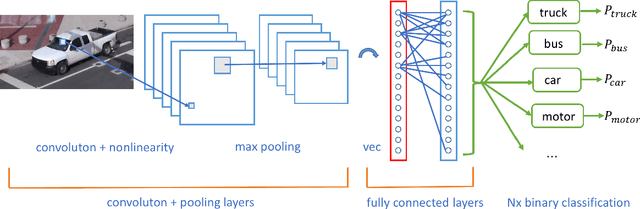
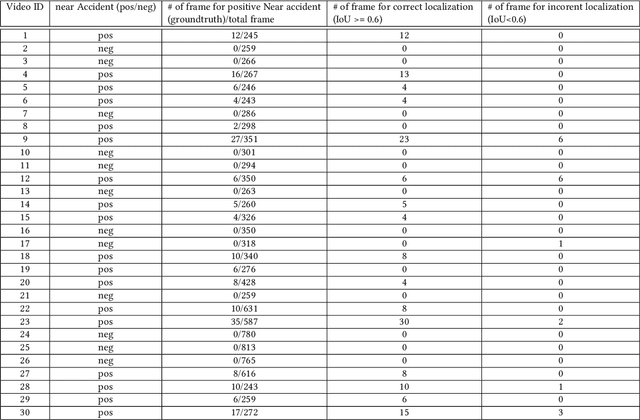
In Intelligent Transportation System, real-time systems that monitor and analyze road users become increasingly critical as we march toward the smart city era. Vision-based frameworks for Object Detection, Multiple Object Tracking, and Traffic Near Accident Detection are important applications of Intelligent Transportation System, particularly in video surveillance and etc. Although deep neural networks have recently achieved great success in many computer vision tasks, a uniformed framework for all the three tasks is still challenging where the challenges multiply from demand for real-time performance, complex urban setting, highly dynamic traffic event, and many traffic movements. In this paper, we propose a two-stream Convolutional Network architecture that performs real-time detection, tracking, and near accident detection of road users in traffic video data. The two-stream model consists of a spatial stream network for Object Detection and a temporal stream network to leverage motion features for Multiple Object Tracking. We detect near accidents by incorporating appearance features and motion features from two-stream networks. Using aerial videos, we propose a Traffic Near Accident Dataset (TNAD) covering various types of traffic interactions that is suitable for vision-based traffic analysis tasks. Our experiments demonstrate the advantage of our framework with an overall competitive qualitative and quantitative performance at high frame rates on the TNAD dataset.
Out-of-distribution detection in satellite image classification
Apr 09, 2021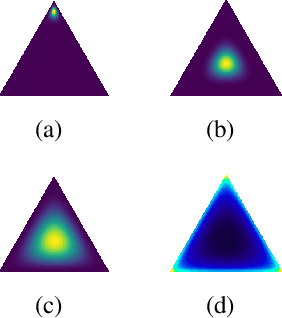
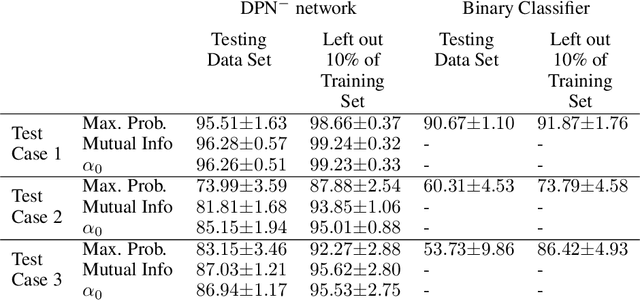
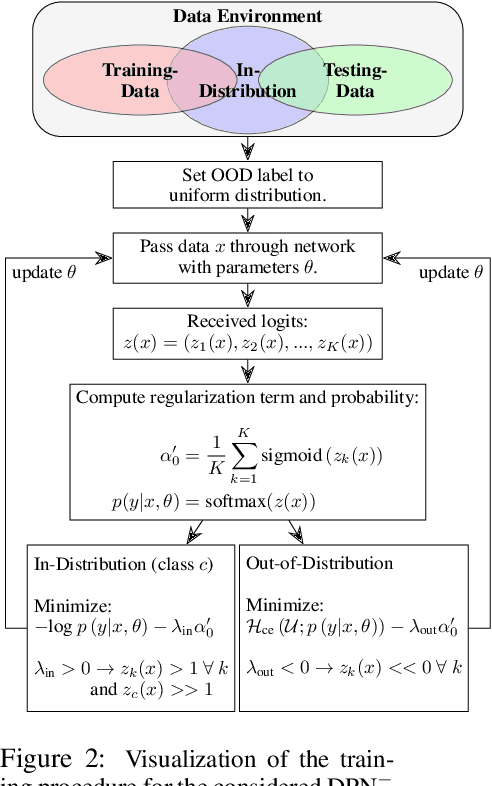

In satellite image analysis, distributional mismatch between the training and test data may arise due to several reasons, including unseen classes in the test data and differences in the geographic area. Deep learning based models may behave in unexpected manner when subjected to test data that has such distributional shifts from the training data, also called out-of-distribution (OOD) examples. Predictive uncertainly analysis is an emerging research topic which has not been explored much in context of satellite image analysis. Towards this, we adopt a Dirichlet Prior Network based model to quantify distributional uncertainty of deep learning models for remote sensing. The approach seeks to maximize the representation gap between the in-domain and OOD examples for a better identification of unknown examples at test time. Experimental results on three exemplary test scenarios show the efficacy of the model in satellite image analysis.
An Extension of BIM Using AI: a Multi Working-Machines Pathfinding Solution
May 14, 2021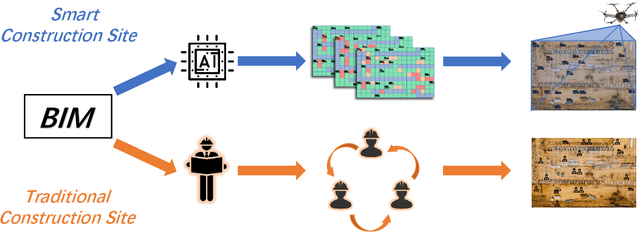
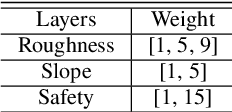
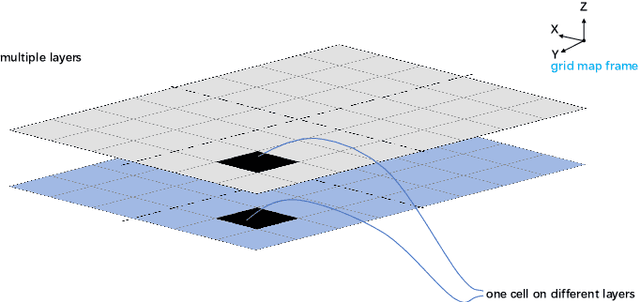
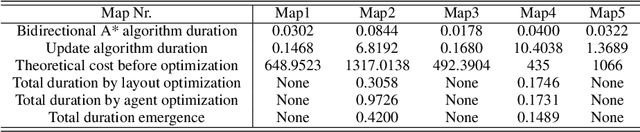
Multi working-machines pathfinding solution enables more mobile machines simultaneously to work inside of a working site so that the productivity can be expected to increase evolutionary. To date, the potential cooperation conflicts among construction machinery limit the amount of construction machinery investment in a concrete working site. To solve the cooperation problem, civil engineers optimize the working site from a logistic perspective while computer scientists improve pathfinding algorithms' performance on the given benchmark maps. In the practical implementation of a construction site, it is sensible to solve the problem with a hybrid solution; therefore, in our study, we proposed an algorithm based on a cutting-edge multi-pathfinding algorithm to enable the massive number of machines cooperation and offer the advice to modify the unreasonable part of the working site in the meantime. Using the logistic information from BIM, such as unloading and loading point, we added a pathfinding solution for multi machines to improve the whole construction fleet's productivity. In the previous study, the experiments were limited to no more than ten participants, and the computational time to gather the solution was not given; thus, we publish our pseudo-code, our tested map, and benchmark our results. Our algorithm's most extensive feature is that it can quickly replan the path to overcome the emergency on a construction site.
Scaling End-to-End Models for Large-Scale Multilingual ASR
Apr 30, 2021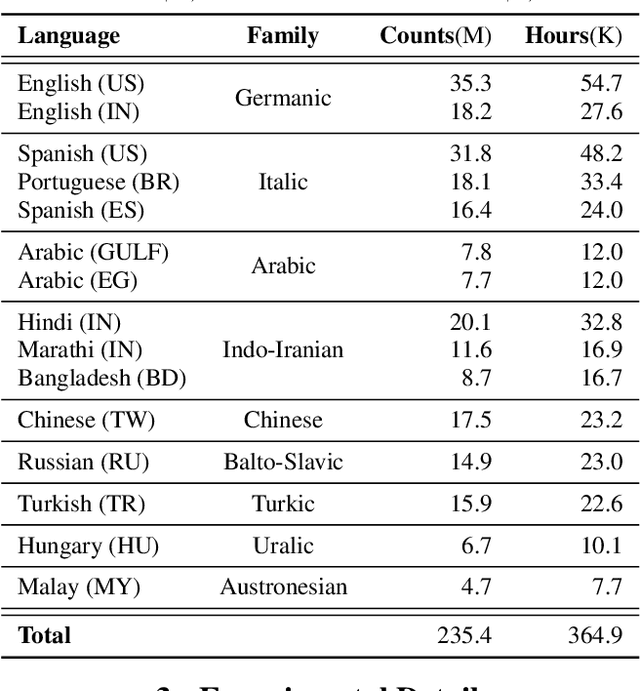
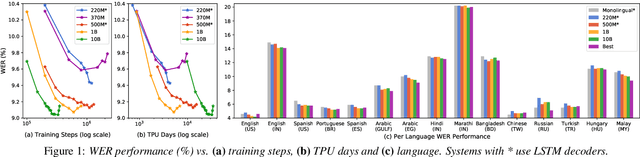
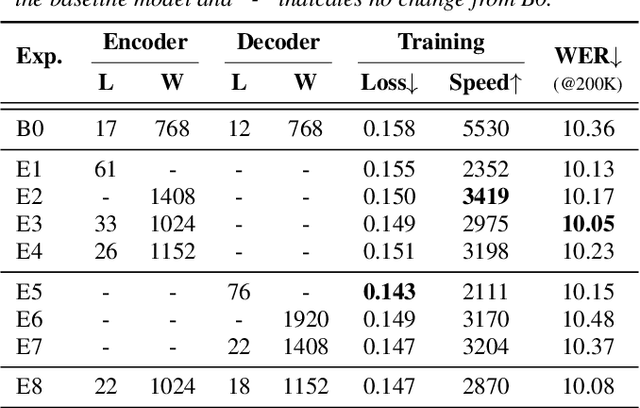
Building ASR models across many language families is a challenging multi-task learning problem due to large language variations and heavily unbalanced data. Existing work has shown positive transfer from high resource to low resource languages. However, degradations on high resource languages are commonly observed due to interference from the heterogeneous multilingual data and reduction in per-language capacity. We conduct a capacity study on a 15-language task, with the amount of data per language varying from 7.7K to 54.7K hours. We adopt GShard [1] to efficiently scale up to 10B parameters. Empirically, we find that (1) scaling the number of model parameters is an effective way to solve the capacity bottleneck - our 500M-param model is already better than monolingual baselines and scaling it to 1B and 10B brought further quality gains; (2) larger models are not only more data efficient, but also more efficient in terms of training cost as measured in TPU days - the 1B-param model reaches the same accuracy at 34% of training time as the 500M-param model; (3) given a fixed capacity budget, adding depth usually works better than width and large encoders tend to do better than large decoders.
GATSBI: Generative Agent-centric Spatio-temporal Object Interaction
Apr 09, 2021
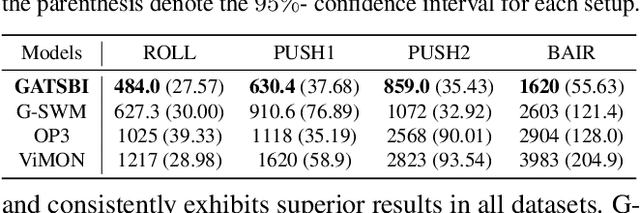
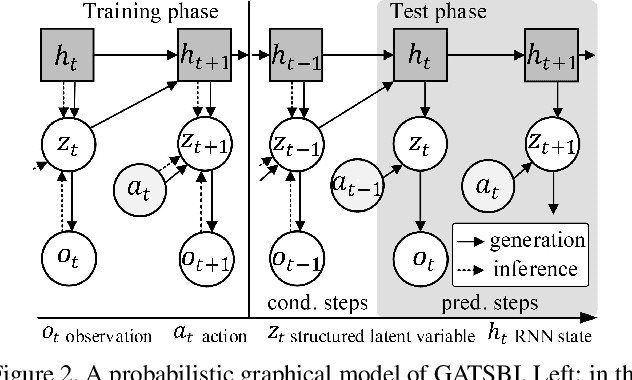
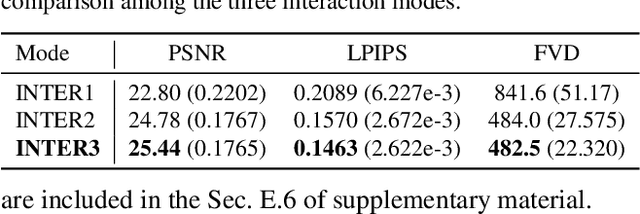
We present GATSBI, a generative model that can transform a sequence of raw observations into a structured latent representation that fully captures the spatio-temporal context of the agent's actions. In vision-based decision-making scenarios, an agent faces complex high-dimensional observations where multiple entities interact with each other. The agent requires a good scene representation of the visual observation that discerns essential components and consistently propagates along the time horizon. Our method, GATSBI, utilizes unsupervised object-centric scene representation learning to separate an active agent, static background, and passive objects. GATSBI then models the interactions reflecting the causal relationships among decomposed entities and predicts physically plausible future states. Our model generalizes to a variety of environments where different types of robots and objects dynamically interact with each other. We show GATSBI achieves superior performance on scene decomposition and video prediction compared to its state-of-the-art counterparts.
ELSKE: Efficient Large-Scale Keyphrase Extraction
Feb 10, 2021
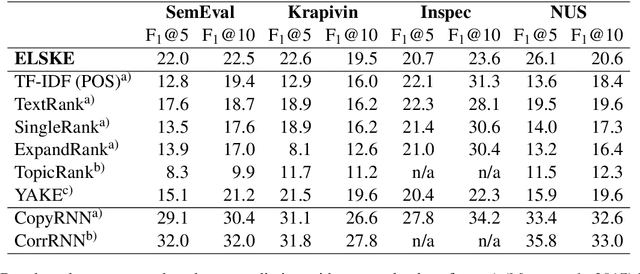
Keyphrase extraction methods can provide insights into large collections of documents such as social media posts. Existing methods, however, are less suited for the real-time analysis of streaming data, because they are computationally too expensive or require restrictive constraints regarding the structure of keyphrases. We propose an efficient approach to extract keyphrases from large document collections and show that the method also performs competitively on individual documents.