 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inter-Carrier Interference Mitigation for Differentially Coherent Detection in Underwater Acoustic OFDM Systems
Mar 07, 2021
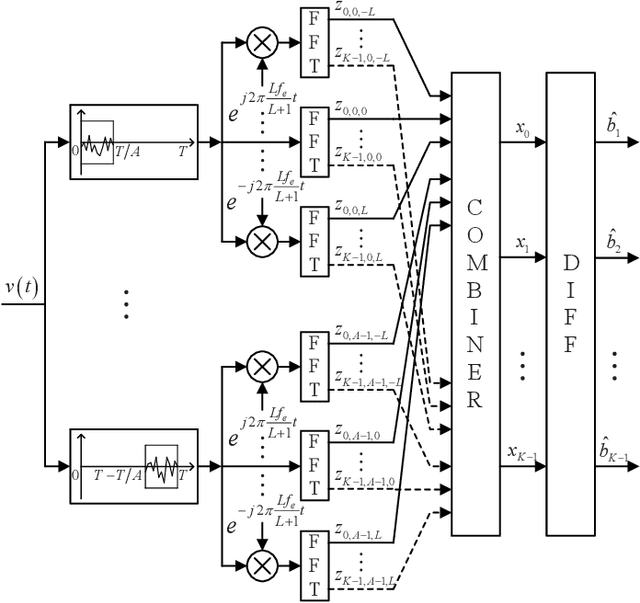
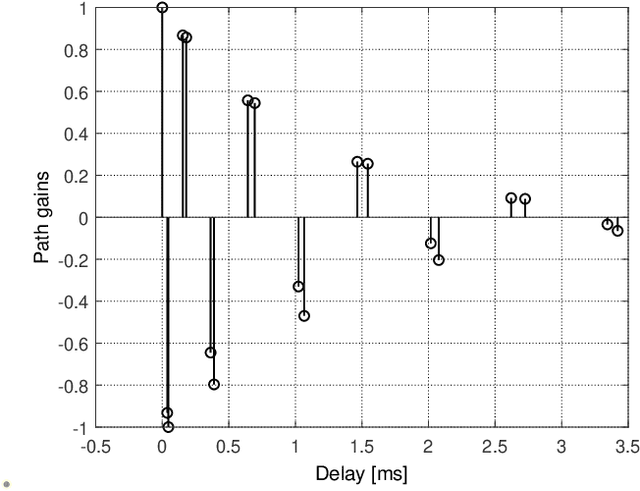
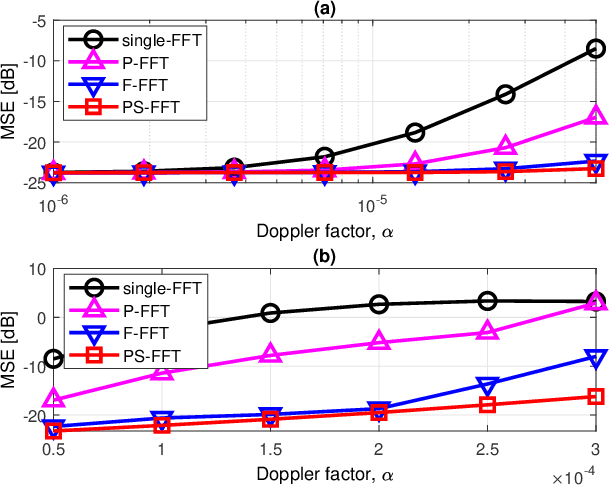
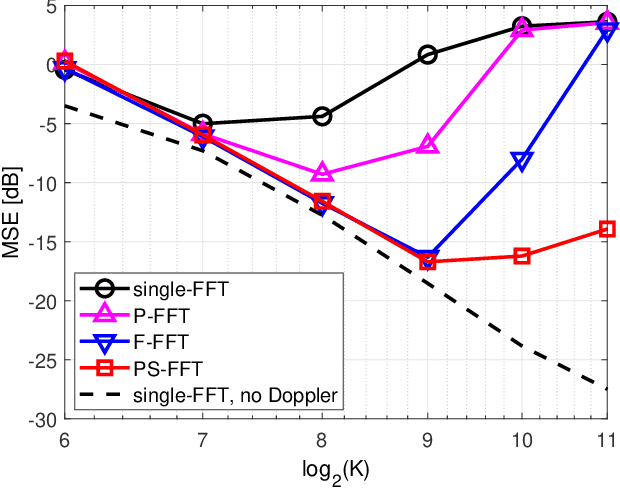
Suppressing the inter-carrier interference (ICI) is crucial for differentially coherent detection in underwater acoustic (UWA) orthogonal frequency division multiplexing (OFDM) systems due to the fact that the UWA channel is inherently violently Doppler-shifted. In this paper, we propose a new ICI suppression method, referred to as the partially-shifted fast Fourier transform (PS-FFT), which eliminates the ICI from both the time and frequency domains. Specifically, the PS-FFT first divides the received signal in the entire block duration into several short non-overlapping ones to reduce the channel variation in the time domain. It then applies the Fourier transform at several predefined frequencies to the received signal in each of these intervals to compensate Doppler shifts in the frequency domain. Finally, it weightedly combines the multiple demodulator outputs at each carrier as one output for symbol detection, with the combiner weights being solved by the stochastic gradient algorithm. Simulation results show that the PS-FFT dramatically outperforms the existing classical methods, the partial fast Fourier transform (P-FFT) and the fractional fast Fourier transform (F-FFT), for both medium and high Doppler factors and large carrier numbers in terms of the mean squared error (MSE). Numerically, the MSE of the PS-FFT is reduced by $\bf{61.83\%-84.89\%}$ compared to that of the F-FFT when the input signal-to-noise ratio (SNR) at the receiver ranges from 10 dB to 30 dB at a Doppler factor of $\bf{3\times 10^{-4}}$ and a carrier number of 1024 where the P-FFT even cannot work.
Convolutional Neural Network-based Intrusion Detection System for AVTP Streams in Automotive Ethernet-based Networks
Feb 06, 2021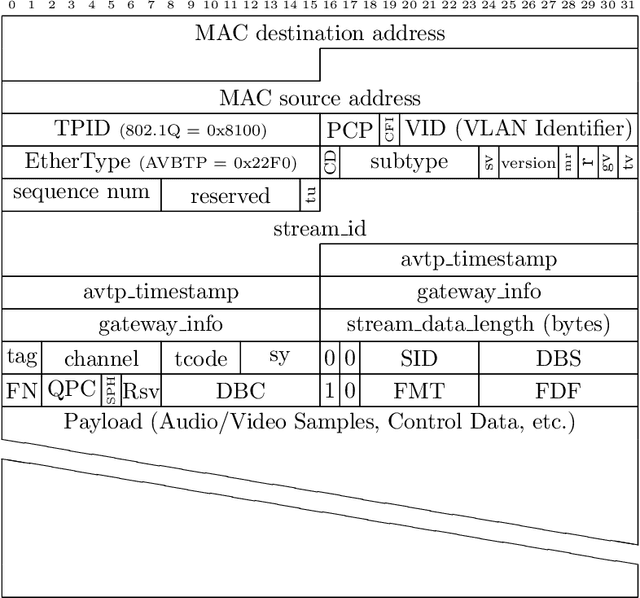
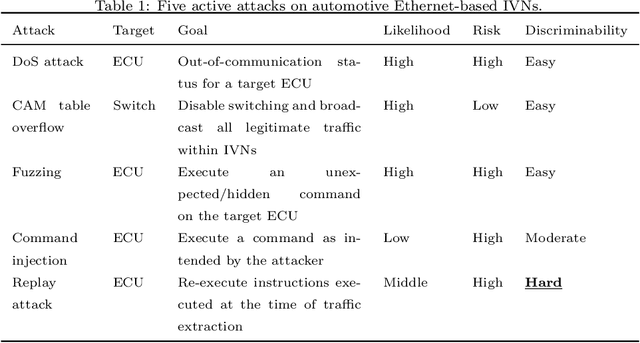
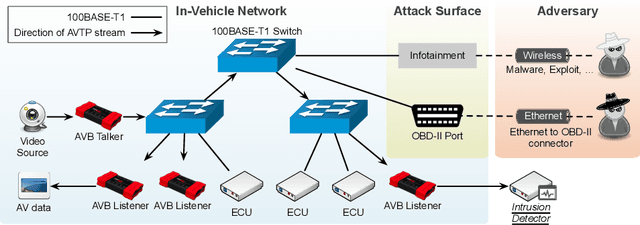
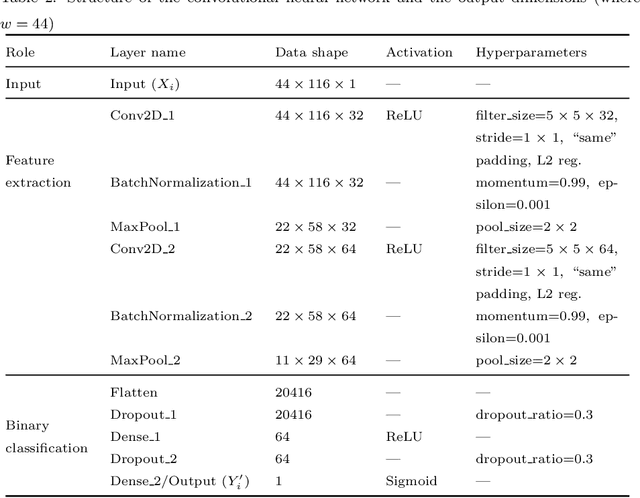
Connected and autonomous vehicles (CAVs) are an innovative form of traditional vehicles. Automotive Ethernet replaces the controller area network and FlexRay to support the large throughput required by high-definition applications. As CAVs have numerous functions, they exhibit a large attack surface and an increased vulnerability to attacks. However, no previous studies have focused on intrusion detection in automotive Ethernet-based networks. In this paper, we present an intrusion detection method for detecting audio-video transport protocol (AVTP) stream injection attacks in automotive Ethernet-based networks. To the best of our knowledge, this is the first such method developed for automotive Ethernet. The proposed intrusion detection model is based on feature generation and a convolutional neural network (CNN). To evaluate our intrusion detection system, we built a physical BroadR-Reach-based testbed and captured real AVTP packets. The experimental results show that the model exhibits outstanding performance: the F1-score and recall are greater than 0.9704 and 0.9949, respectively. In terms of the inference time per input and the generation intervals of AVTP traffic, our CNN model can readily be employed for real-time detection.
End-to-End Intersection Handling using Multi-Agent Deep Reinforcement Learning
May 01, 2021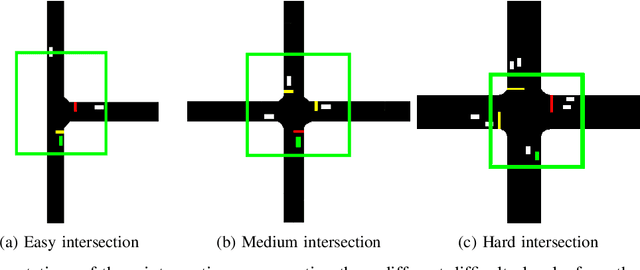
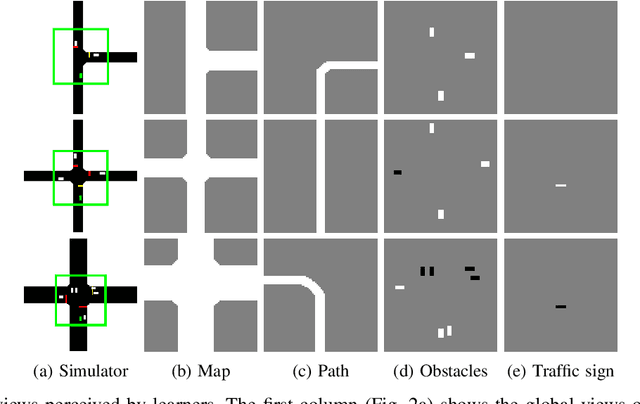
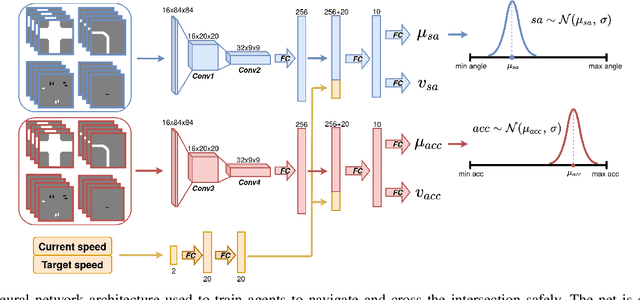
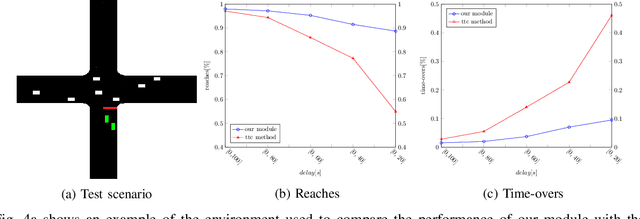
Navigating through intersections is one of the main challenging tasks for an autonomous vehicle. However, for the majority of intersections regulated by traffic lights, the problem could be solved by a simple rule-based method in which the autonomous vehicle behavior is closely related to the traffic light states. In this work, we focus on the implementation of a system able to navigate through intersections where only traffic signs are provided. We propose a multi-agent system using a continuous, model-free Deep Reinforcement Learning algorithm used to train a neural network for predicting both the acceleration and the steering angle at each time step. We demonstrate that agents learn both the basic rules needed to handle intersections by understanding the priorities of other learners inside the environment, and to drive safely along their paths. Moreover, a comparison between our system and a rule-based method proves that our model achieves better results especially with dense traffic conditions. Finally, we test our system on real world scenarios using real recorded traffic data, proving that our module is able to generalize both to unseen environments and to different traffic conditions.
Control Synthesis using Signal Temporal Logic Specifications with Integral and Derivative Predicates
Mar 26, 2021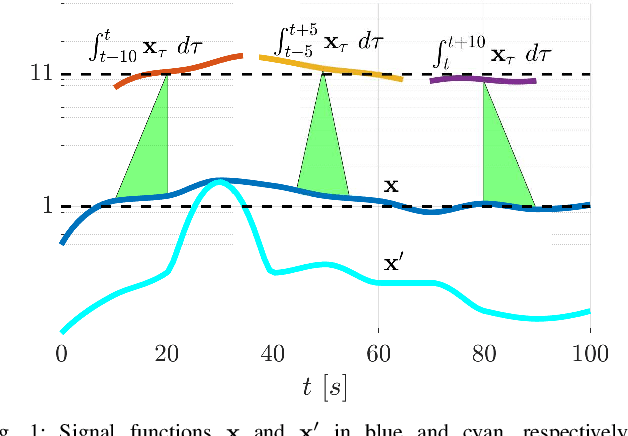
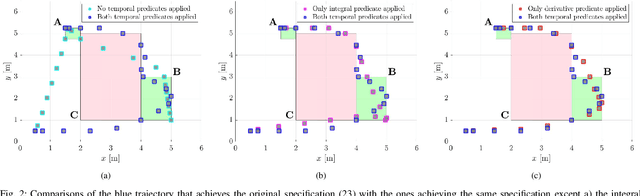
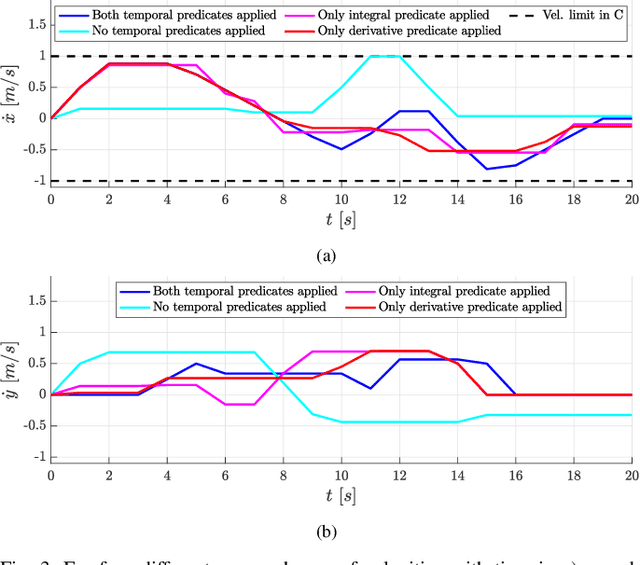
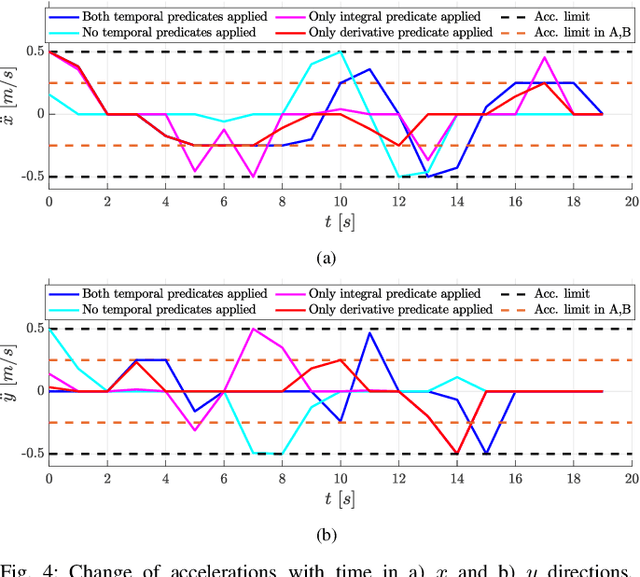
In many applications, the integrals and derivatives of signals carry valuable information (e.g., cumulative success over a time window, the rate of change) regarding the behavior of the underlying system. In this paper, we extend the expressiveness of Signal Temporal Logic (STL) by introducing predicates that can define rich properties related to the integral and derivative of a signal. For control synthesis, the new predicates are encoded into mixed-integer linear inequalities and are used in the formulation of a mixed-integer linear program to find a trajectory that satisfies an STL specification. We discuss the benefits of using the new predicates and illustrate them in a case study showing the influence of the new predicates on the trajectories of an autonomous robot.
Nearly Minimax-Optimal Rates for Noisy Sparse Phase Retrieval via Early-Stopped Mirror Descent
May 08, 2021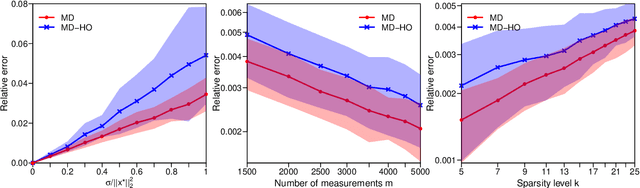
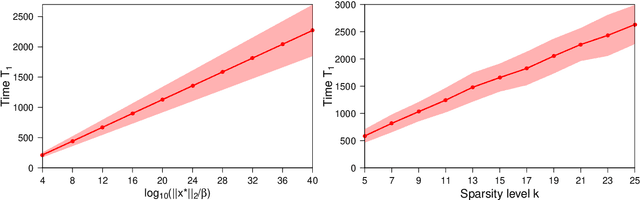
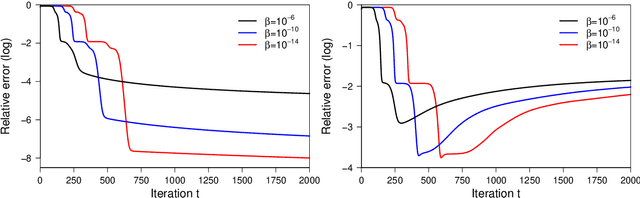
This paper studies early-stopped mirror descent applied to noisy sparse phase retrieval, which is the problem of recovering a $k$-sparse signal $\mathbf{x}^\star\in\mathbb{R}^n$ from a set of quadratic Gaussian measurements corrupted by sub-exponential noise. We consider the (non-convex) unregularized empirical risk minimization problem and show that early-stopped mirror descent, when equipped with the hyperbolic entropy mirror map and proper initialization, achieves a nearly minimax-optimal rate of convergence, provided the sample size is at least of order $k^2$ (modulo logarithmic term) and the minimum (in modulus) non-zero entry of the signal is on the order of $\|\mathbf{x}^\star\|_2/\sqrt{k}$. Our theory leads to a simple algorithm that does not rely on explicit regularization or thresholding steps to promote sparsity. More generally, our results establish a connection between mirror descent and sparsity in the non-convex problem of noisy sparse phase retrieval, adding to the literature on early stopping that has mostly focused on non-sparse, Euclidean, and convex settings via gradient descent. Our proof combines a potential-based analysis of mirror descent with a quantitative control on a variational coherence property that we establish along the path of mirror descent, up to a prescribed stopping time.
Machine Learning Based Anxiety Detection in Older Adults using Wristband Sensors and Context Feature
Jun 06, 2021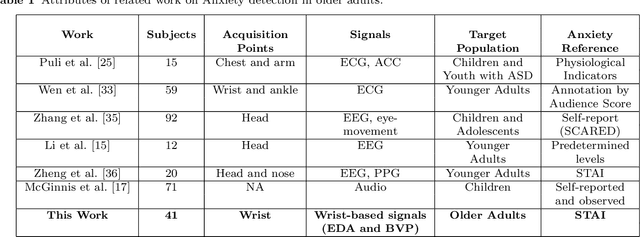
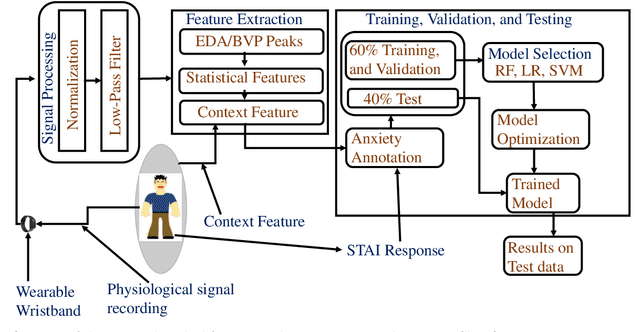
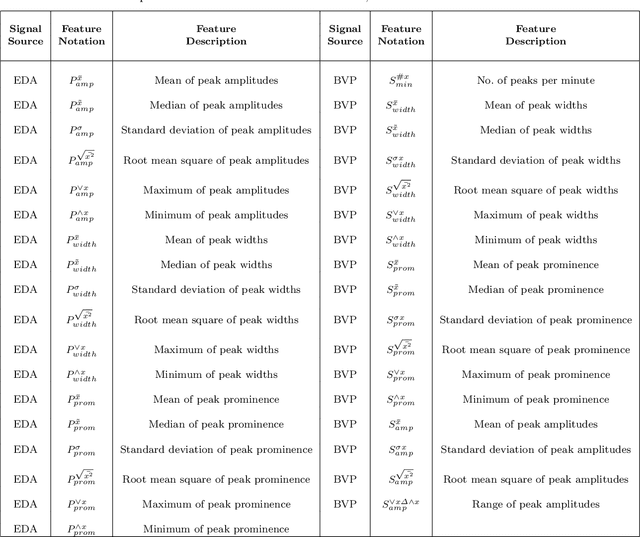
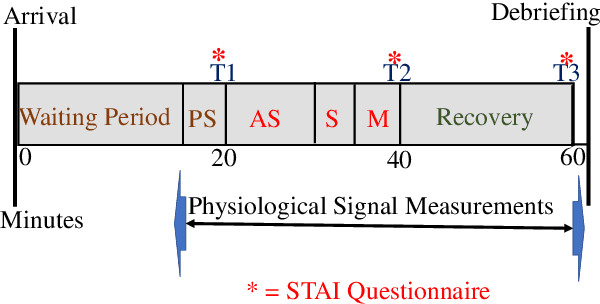
This paper explores a novel method for anxiety detection in older adults using simple wristband sensors such as Electrodermal Activity (EDA) and Photoplethysmogram (PPG) and a context-based feature. The proposed method for anxiety detection combines features from a single physiological signal with an experimental context-based feature to improve the performance of the anxiety detection model. The experimental data for this work is obtained from a year-long experiment on 41 healthy older adults (26 females and 15 males) in the age range 60-80 with mean age 73.36+-5.25 during a Trier Social Stress Test (TSST) protocol. The anxiety level ground truth was obtained from State-Trait Anxiety Inventory (STAI), which is regarded as the gold standard to measure perceived anxiety. EDA and Blood Volume Pulse (BVP) signals were recorded using a wrist-worn EDA and PPG sensor respectively. 47 features were computed from EDA and BVP signal, out of which a final set of 24 significantly correlated features were selected for analysis. The phases of the experimental study are encoded as unique integers to generate the context feature vector. A combination of features from a single sensor with the context feature vector is used for training a machine learning model to distinguish between anxious and not-anxious states. Results and analysis showed that the EDA and BVP machine learning models that combined the context feature along with the physiological features achieved 3.37% and 6.41% higher accuracy respectively than the models that used only physiological features. Further, end-to-end processing of EDA and BVP signals was simulated for real-time anxiety level detection. This work demonstrates the practicality of the proposed anxiety detection method in facilitating long-term monitoring of anxiety in older adults using low-cost consumer devices.
* 13 pages
Sequential convolutional network for behavioral pattern extraction in gait recognition
Apr 23, 2021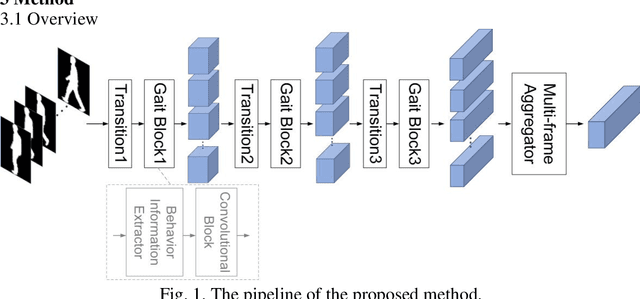
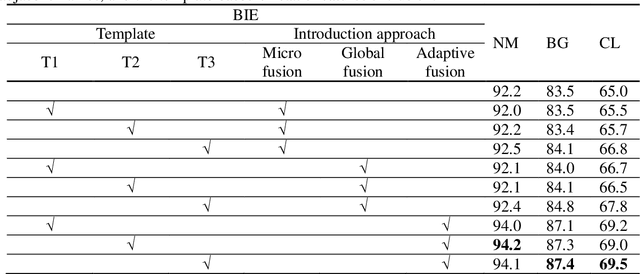
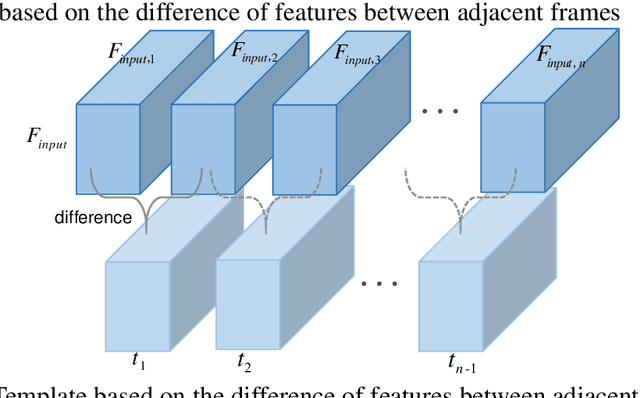
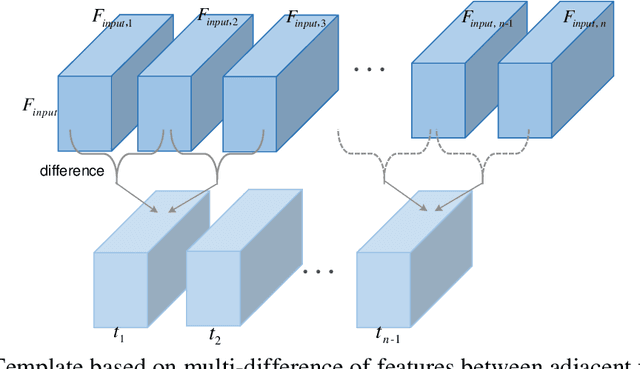
As a unique and promising biometric, video-based gait recognition has broad applications. The key step of this methodology is to learn the walking pattern of individuals, which, however, often suffers challenges to extract the behavioral feature from a sequence directly. Most existing methods just focus on either the appearance or the motion pattern. To overcome these limitations, we propose a sequential convolutional network (SCN) from a novel perspective, where spatiotemporal features can be learned by a basic convolutional backbone. In SCN, behavioral information extractors (BIE) are constructed to comprehend intermediate feature maps in time series through motion templates where the relationship between frames can be analyzed, thereby distilling the information of the walking pattern. Furthermore, a multi-frame aggregator in SCN performs feature integration on a sequence whose length is uncertain, via a mobile 3D convolutional layer. To demonstrate the effectiveness, experiments have been conducted on two popular public benchmarks, CASIA-B and OU-MVLP, and our approach is demonstrated superior performance, comparing with the state-of-art methods.
Finite-Time 4-Expert Prediction Problem
Nov 22, 2019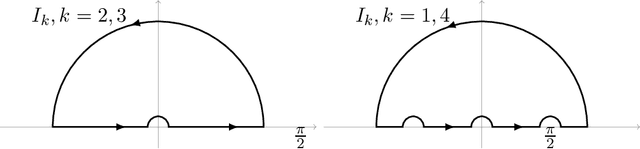
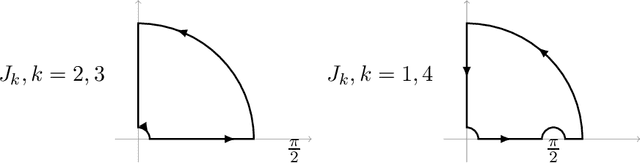
We explicitly solve the nonlinear PDE that is the continuous limit of dynamic programming of \emph{expert prediction problem} in finite horizon setting with $N=4$ experts. The \emph{expert prediction problem} is formulated as a zero sum game between a player and an adversary. By showing that the solution is $\mathcal{C}^2$, we are able to show that the strategies conjectured in arXiv:1409.3040G form an asymptotic Nash equilibrium. We also prove the "Finite vs Geometric regret" conjecture proposed in arXiv:1409.3040G for $N=4$, and we give a stronger conjecture which characterizes the relation between the finite and geometric stopping.
An Update to the Minho Quotation Resource
Apr 14, 2021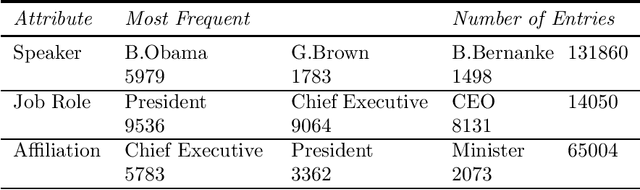
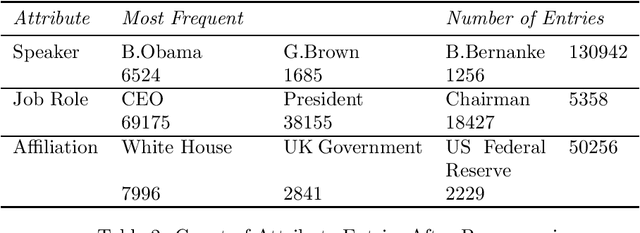

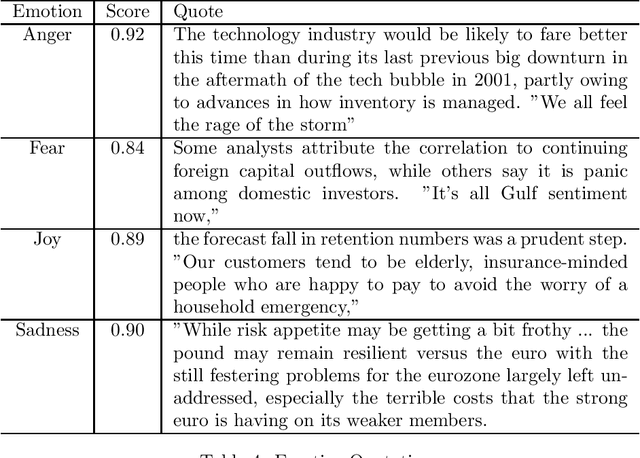
The Minho Quotation Resource was originally released in 2012. It provided approximately 500,000 quotes from business leaders, analysts and politicians that spanned the period from 2008 to 2012. The original resource had several failings which include a large number of missing job titles and affiliations as well as unnormalised job titles which produced a large variation in spellings and formats of the same employment position. Also, there were numerous duplicate posts. This update has standardised the job title text as well as the imputation of missing job titles and affiliations. Duplicate quotes have been deleted. This update also provides some metaphor and simile extraction as well as an emotion distribution of the quotes. This update has also replaced an antiquated version of Lucene index with a JSONL format as well as a rudimentary interface that can query the data supplied with the resource. It is hoped that this update will encourage the study of business communication in a time of a financial crisis.
Aligning Latent and Image Spaces to Connect the Unconnectable
Apr 14, 2021
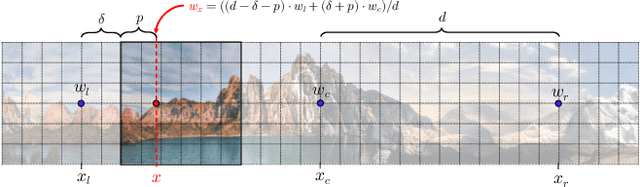

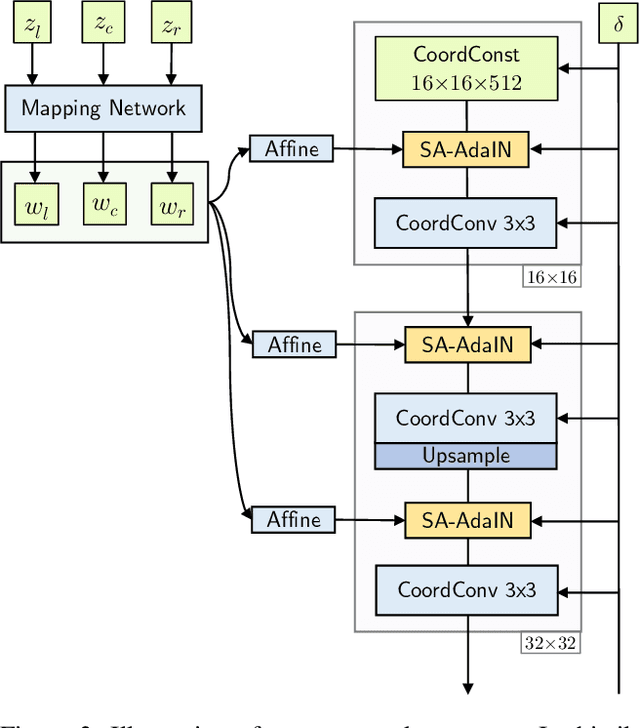
In this work, we develop a method to generate infinite high-resolution images with diverse and complex content. It is based on a perfectly equivariant generator with synchronous interpolations in the image and latent spaces. Latent codes, when sampled, are positioned on the coordinate grid, and each pixel is computed from an interpolation of the nearby style codes. We modify the AdaIN mechanism to work in such a setup and train the generator in an adversarial setting to produce images positioned between any two latent vectors. At test time, this allows for generating complex and diverse infinite images and connecting any two unrelated scenes into a single arbitrarily large panorama. Apart from that, we introduce LHQ: a new dataset of \lhqsize high-resolution nature landscapes. We test the approach on LHQ, LSUN Tower and LSUN Bridge and outperform the baselines by at least 4 times in terms of quality and diversity of the produced infinite images. The project page is located at https://universome.github.io/alis.