 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Weakly Supervised Video Salient Object Detection
Apr 06, 2021

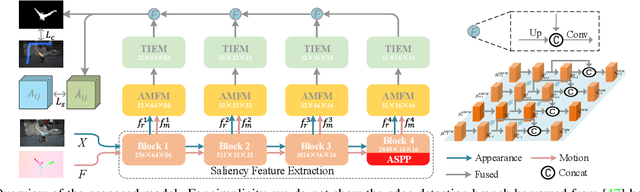
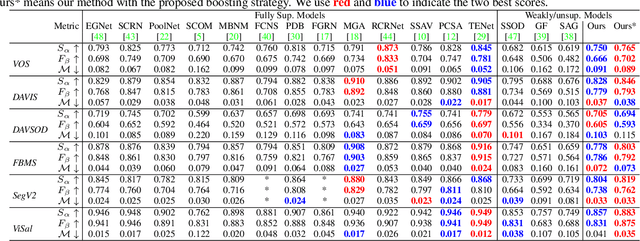
Significant performance improvement has been achieved for fully-supervised video salient object detection with the pixel-wise labeled training datasets, which are time-consuming and expensive to obtain. To relieve the burden of data annotation, we present the first weakly supervised video salient object detection model based on relabeled "fixation guided scribble annotations". Specifically, an "Appearance-motion fusion module" and bidirectional ConvLSTM based framework are proposed to achieve effective multi-modal learning and long-term temporal context modeling based on our new weak annotations. Further, we design a novel foreground-background similarity loss to further explore the labeling similarity across frames. A weak annotation boosting strategy is also introduced to boost our model performance with a new pseudo-label generation technique. Extensive experimental results on six benchmark video saliency detection datasets illustrate the effectiveness of our solution.
Augmented Networks for Faster Brain Metastases Detection in T1-Weighted Contrast-Enhanced 3D MRI
May 27, 2021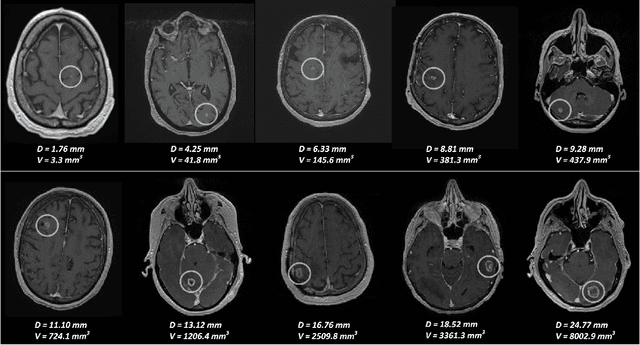
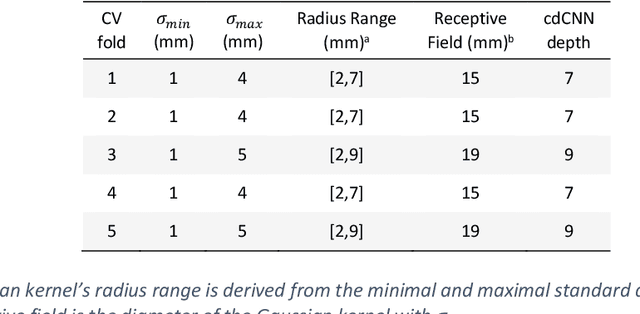
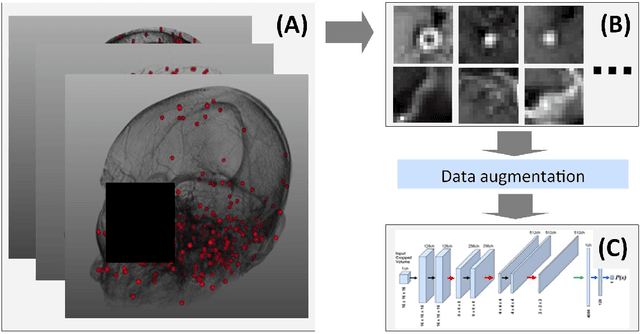
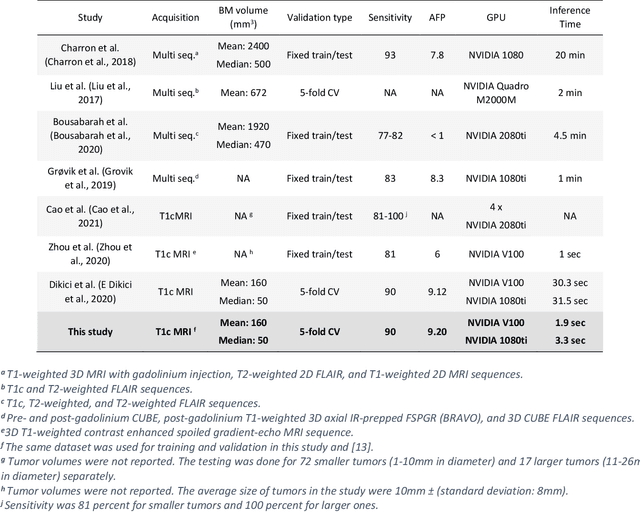
Early detection of brain metastases (BM) is one of the determining factors for the successful treatment of patients with cancer; however, the accurate detection of small BM lesions (< 15mm) remains a challenging task. We previously described a framework for the detection of small BM in single-sequence gadolinium-enhanced T1-weighted 3D MRI datasets. It combined classical image processing (IP) with a dedicated convolutional neural network, taking approximately 30 seconds to process each dataset due to computation-intensive IP stages. To overcome the speed limitation, this study aims to reformulate the framework via an augmented pair of CNNs (eliminating the IP) to reduce the processing times while preserving the BM detection performance. Our previous implementation of the BM detection algorithm utilized Laplacian of Gaussians (LoG) for the candidate selection portion of the solution. In this study, we introduce a novel BM candidate detection CNN (cdCNN) to replace this classical IP stage. The network is formulated to have (1) a similar receptive field as the LoG method, and (2) a bias for the detection of BM lesion loci. The proposed CNN is later augmented with a classification CNN to perform the BM detection task. The cdCNN achieved 97.4% BM detection sensitivity when producing 60K candidates per 3D MRI dataset, while the LoG achieved 96.5% detection sensitivity with 73K candidates. The augmented BM detection framework generated on average 9.20 false-positive BM detections per patient for 90% sensitivity, which is comparable with our previous results. However, it processes each 3D data in 1.9 seconds, presenting a 93.5% reduction in the computation time.
A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation
Apr 15, 2021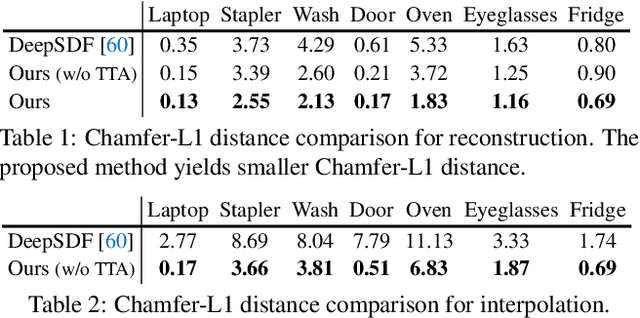
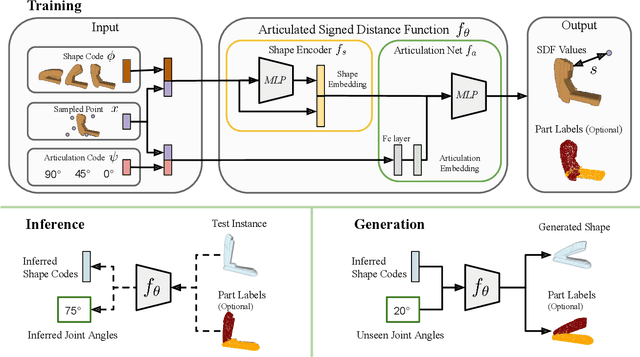
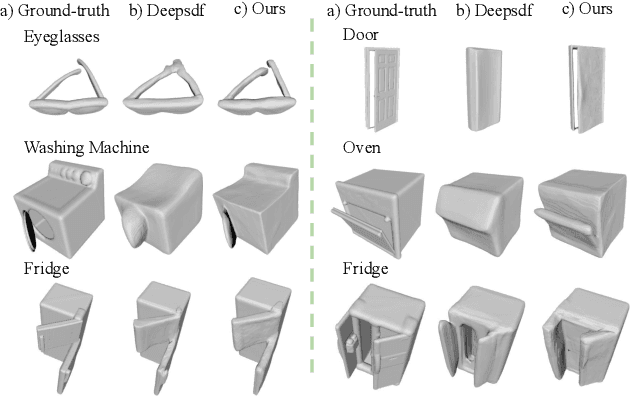

Recent work has made significant progress on using implicit functions, as a continuous representation for 3D rigid object shape reconstruction. However, much less effort has been devoted to modeling general articulated objects. Compared to rigid objects, articulated objects have higher degrees of freedom, which makes it hard to generalize to unseen shapes. To deal with the large shape variance, we introduce Articulated Signed Distance Functions (A-SDF) to represent articulated shapes with a disentangled latent space, where we have separate codes for encoding shape and articulation. We assume no prior knowledge on part geometry, articulation status, joint type, joint axis, and joint location. With this disentangled continuous representation, we demonstrate that we can control the articulation input and animate unseen instances with unseen joint angles. Furthermore, we propose a Test-Time Adaptation inference algorithm to adjust our model during inference. We demonstrate our model generalize well to out-of-distribution and unseen data, e.g., partial point clouds and real-world depth images.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021

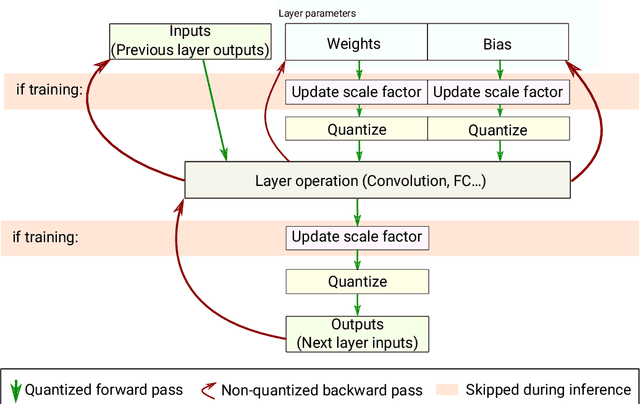
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984
Action Segmentation with Mixed Temporal Domain Adaptation
Apr 15, 2021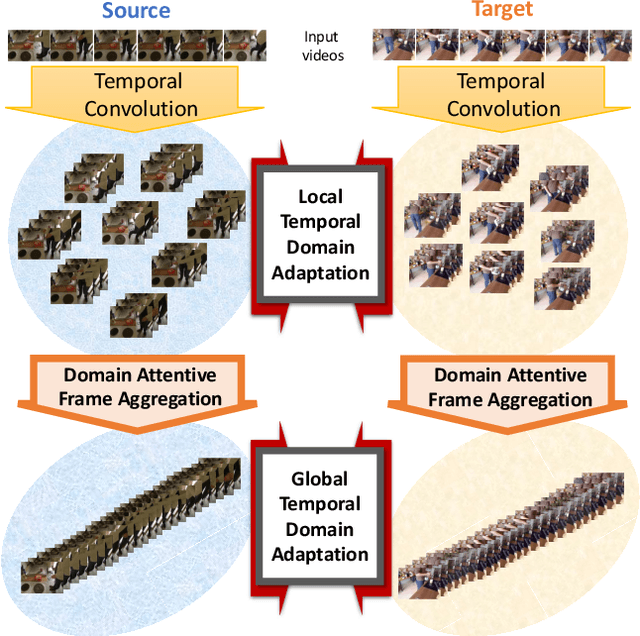
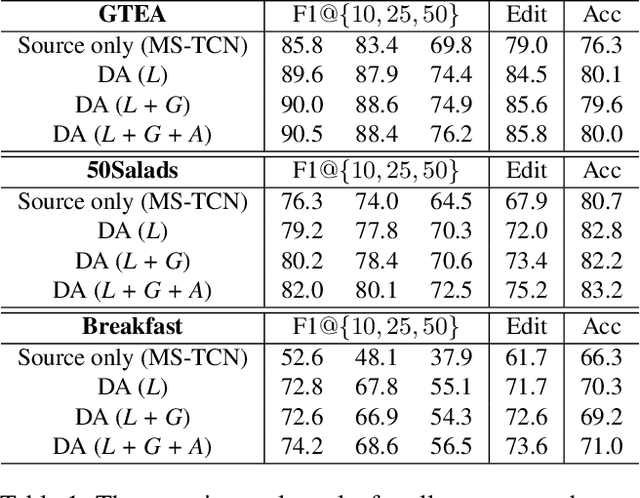
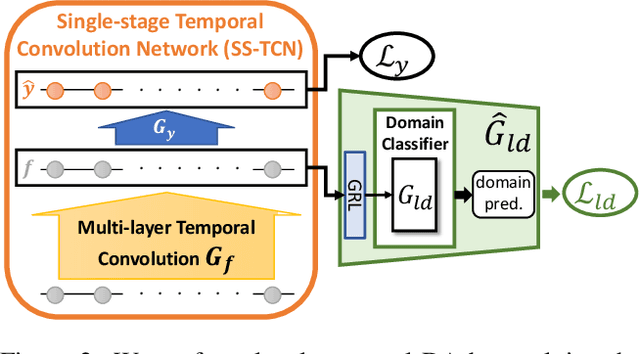
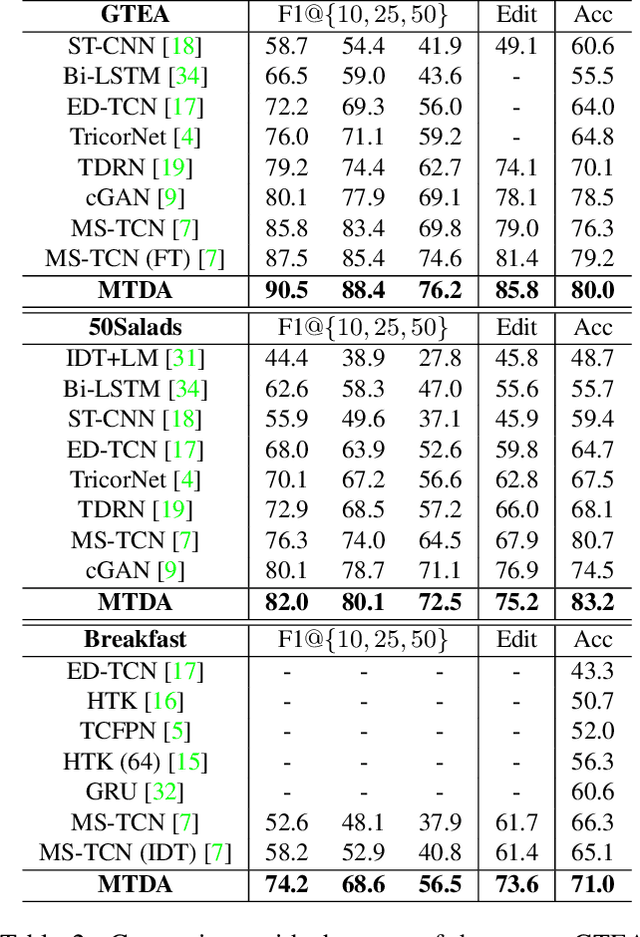
The main progress for action segmentation comes from densely-annotated data for fully-supervised learning. Since manual annotation for frame-level actions is time-consuming and challenging, we propose to exploit auxiliary unlabeled videos, which are much easier to obtain, by shaping this problem as a domain adaptation (DA) problem. Although various DA techniques have been proposed in recent years, most of them have been developed only for the spatial direction. Therefore, we propose Mixed Temporal Domain Adaptation (MTDA) to jointly align frame- and video-level embedded feature spaces across domains, and further integrate with the domain attention mechanism to focus on aligning the frame-level features with higher domain discrepancy, leading to more effective domain adaptation. Finally, we evaluate our proposed methods on three challenging datasets (GTEA, 50Salads, and Breakfast), and validate that MTDA outperforms the current state-of-the-art methods on all three datasets by large margins (e.g. 6.4% gain on F1@50 and 6.8% gain on the edit score for GTEA).
Alpha Matte Generation from Single Input for Portrait Matting
Jun 06, 2021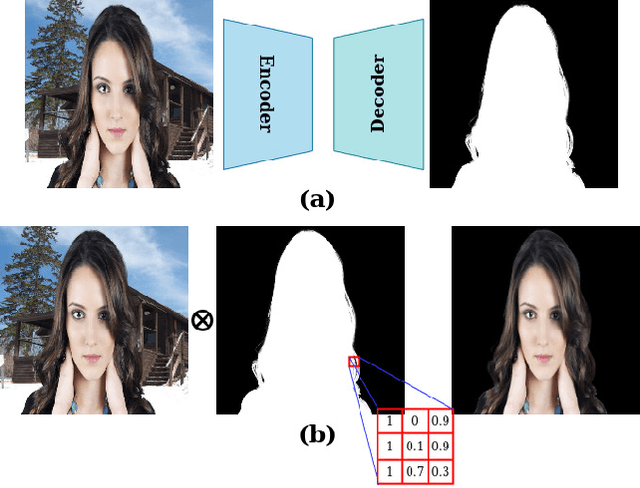
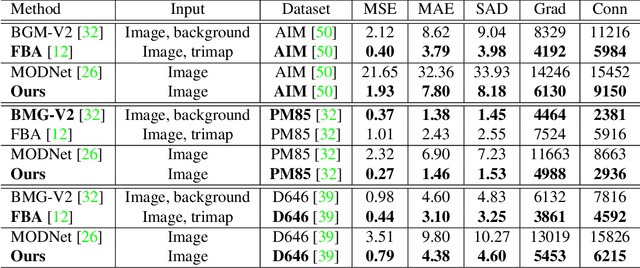
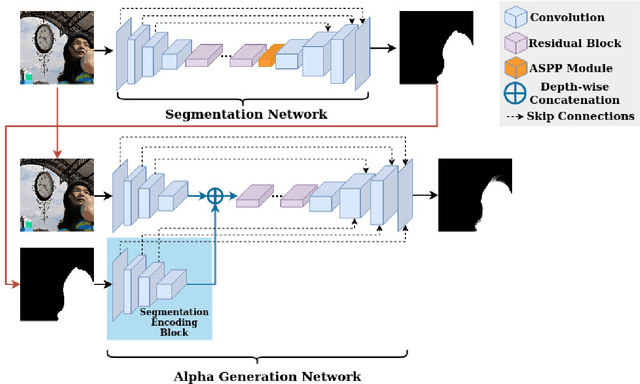
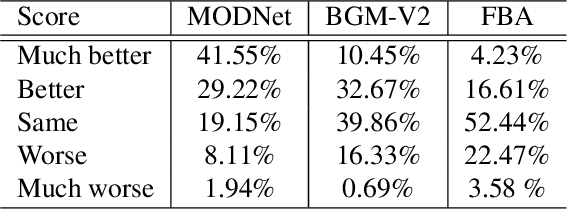
Portrait matting is an important research problem with a wide range of applications, such as video conference app, image/video editing, and post-production. The goal is to predict an alpha matte that identifies the effect of each pixel on the foreground subject. Traditional approaches and most of the existing works utilized an additional input, e.g., trimap, background image, to predict alpha matte. However, providing additional input is not always practical. Besides, models are too sensitive to these additional inputs. In this paper, we introduce an additional input-free approach to perform portrait matting using Generative Adversarial Nets (GANs). We divide the main task into two subtasks. For this, we propose a segmentation network for the person segmentation and the alpha generation network for alpha matte prediction. While the segmentation network takes an input image and produces a coarse segmentation map, the alpha generation network utilizes the same input image as well as a coarse segmentation map that is produced by the segmentation network to predict the alpha matte. Besides, we present a segmentation encoding block to downsample the coarse segmentation map and provide feature representation to the residual block. Furthermore, we propose border loss to penalize only the borders of the subject separately which is more likely to be challenging and we also adapt perceptual loss for portrait matting. To train the proposed system, we combine two different popular training datasets to improve the amount of data as well as diversity to address domain shift problems in the inference time. We tested our model on three different benchmark datasets, namely Adobe Image Matting dataset, Portrait Matting dataset, and Distinctions dataset. The proposed method outperformed the MODNet method that also takes a single input.
Search Methods for Sufficient, Socially-Aligned Feature Importance Explanations with In-Distribution Counterfactuals
Jun 01, 2021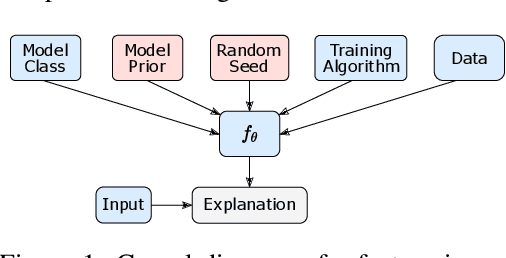

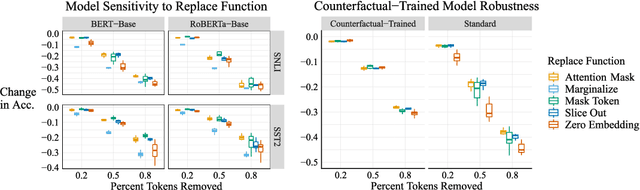
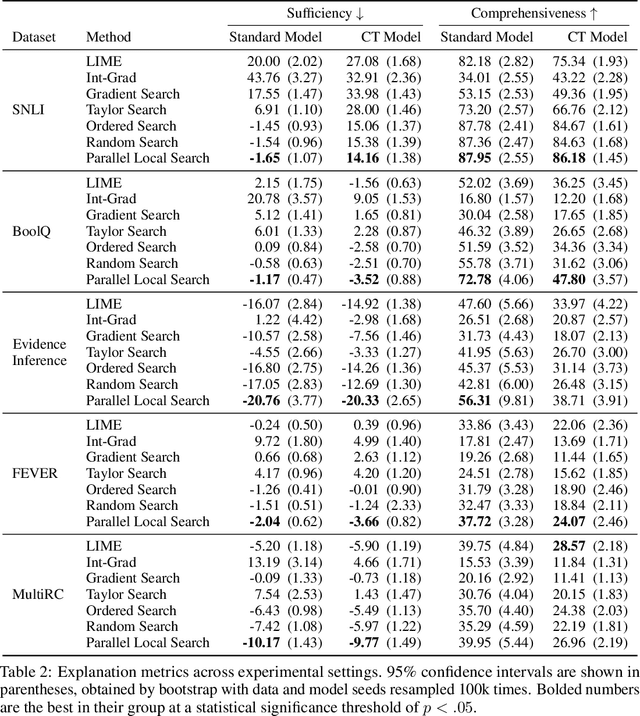
Feature importance (FI) estimates are a popular form of explanation, and they are commonly created and evaluated by computing the change in model confidence caused by removing certain input features at test time. For example, in the standard Sufficiency metric, only the top-k most important tokens are kept. In this paper, we study several under-explored dimensions of FI-based explanations, providing conceptual and empirical improvements for this form of explanation. First, we advance a new argument for why it can be problematic to remove features from an input when creating or evaluating explanations: the fact that these counterfactual inputs are out-of-distribution (OOD) to models implies that the resulting explanations are socially misaligned. The crux of the problem is that the model prior and random weight initialization influence the explanations (and explanation metrics) in unintended ways. To resolve this issue, we propose a simple alteration to the model training process, which results in more socially aligned explanations and metrics. Second, we compare among five approaches for removing features from model inputs. We find that some methods produce more OOD counterfactuals than others, and we make recommendations for selecting a feature-replacement function. Finally, we introduce four search-based methods for identifying FI explanations and compare them to strong baselines, including LIME, Integrated Gradients, and random search. On experiments with six diverse text classification datasets, we find that the only method that consistently outperforms random search is a Parallel Local Search that we introduce. Improvements over the second-best method are as large as 5.4 points for Sufficiency and 17 points for Comprehensiveness. All supporting code is publicly available at https://github.com/peterbhase/ExplanationSearch.
Autoregressive Convolutional Recurrent Neural Network for Univariate and Multivariate Time Series Prediction
Mar 06, 2019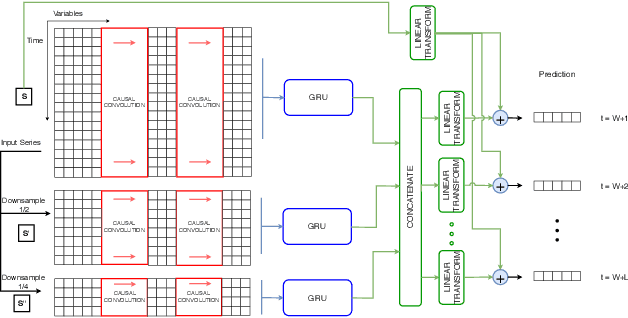
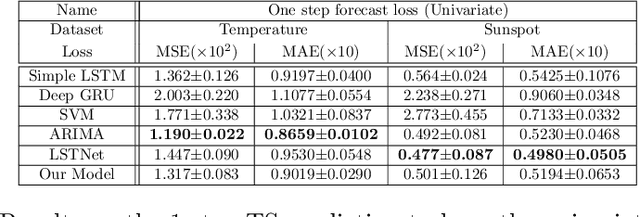
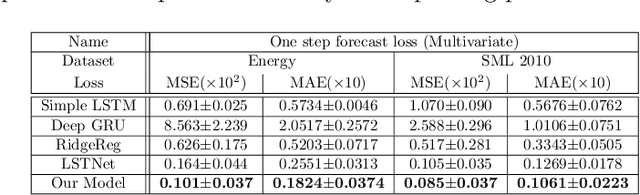
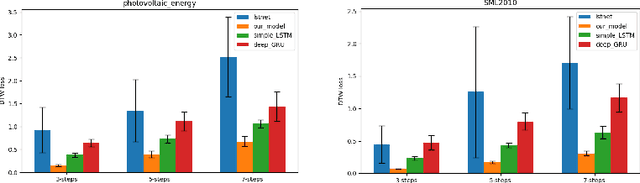
Time Series forecasting (univariate and multivariate) is a problem of high complexity due the different patterns that have to be detected in the input, ranging from high to low frequencies ones. In this paper we propose a new model for timeseries prediction that utilizes convolutional layers for feature extraction, a recurrent encoder and a linear autoregressive component. We motivate the model and we test and compare it against a baseline of widely used existing architectures for univariate and multivariate timeseries. The proposed model appears to outperform the baselines in almost every case of the multivariate timeseries datasets, in some cases even with 50% improvement which shows the strengths of such a hybrid architecture in complex timeseries.
Transient Chaos in BERT
Jun 06, 2021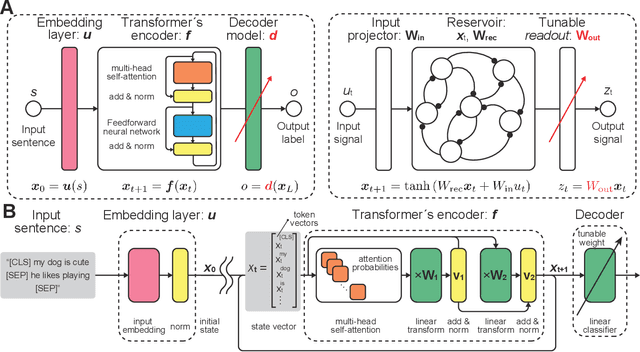
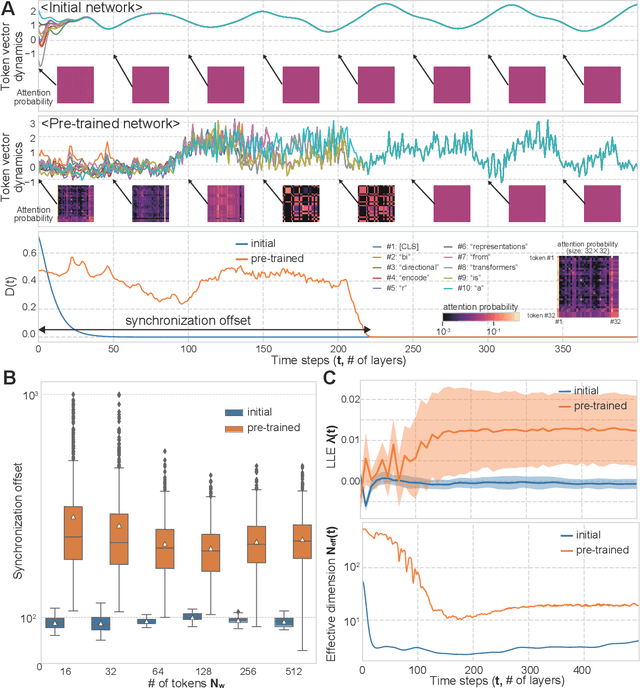
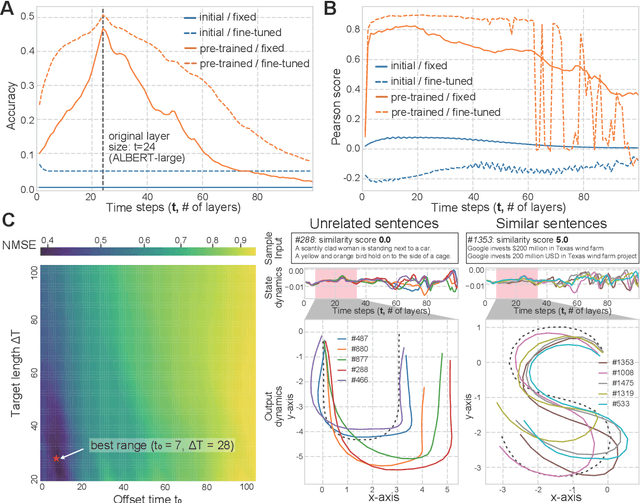
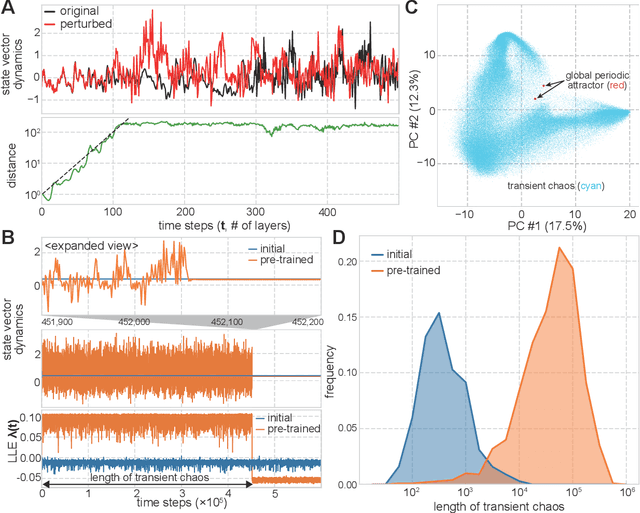
Language is an outcome of our complex and dynamic human-interactions and the technique of natural language processing (NLP) is hence built on human linguistic activities. Bidirectional Encoder Representations from Transformers (BERT) has recently gained its popularity by establishing the state-of-the-art scores in several NLP benchmarks. A Lite BERT (ALBERT) is literally characterized as a lightweight version of BERT, in which the number of BERT parameters is reduced by repeatedly applying the same neural network called Transformer's encoder layer. By pre-training the parameters with a massive amount of natural language data, ALBERT can convert input sentences into versatile high-dimensional vectors potentially capable of solving multiple NLP tasks. In that sense, ALBERT can be regarded as a well-designed high-dimensional dynamical system whose operator is the Transformer's encoder, and essential structures of human language are thus expected to be encapsulated in its dynamics. In this study, we investigated the embedded properties of ALBERT to reveal how NLP tasks are effectively solved by exploiting its dynamics. We thereby aimed to explore the nature of human language from the dynamical expressions of the NLP model. Our short-term analysis clarified that the pre-trained model stably yields trajectories with higher dimensionality, which would enhance the expressive capacity required for NLP tasks. Also, our long-term analysis revealed that ALBERT intrinsically shows transient chaos, a typical nonlinear phenomenon showing chaotic dynamics only in its transient, and the pre-trained ALBERT model tends to produce the chaotic trajectory for a significantly longer time period compared to a randomly-initialized one. Our results imply that local chaoticity would contribute to improving NLP performance, uncovering a novel aspect in the role of chaotic dynamics in human language behaviors.
Optimal Dynamic Regret in Exp-Concave Online Learning
Apr 23, 2021

We consider the problem of the Zinkevich (2003)-style dynamic regret minimization in online learning with exp-concave losses. We show that whenever improper learning is allowed, a Strongly Adaptive online learner achieves the dynamic regret of $\tilde O(d^{3.5}n^{1/3}C_n^{2/3} \vee d\log n)$ where $C_n$ is the total variation (a.k.a. path length) of the an arbitrary sequence of comparators that may not be known to the learner ahead of time. Achieving this rate was highly nontrivial even for squared losses in 1D where the best known upper bound was $O(\sqrt{nC_n} \vee \log n)$ (Yuan and Lamperski, 2019). Our new proof techniques make elegant use of the intricate structures of the primal and dual variables imposed by the KKT conditions and could be of independent interest. Finally, we apply our results to the classical statistical problem of locally adaptive non-parametric regression (Mammen, 1991; Donoho and Johnstone, 1998) and obtain a stronger and more flexible algorithm that do not require any statistical assumptions or any hyperparameter tuning.