 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Structure Discovery via Probabilistic Program Synthesis
May 22, 2017
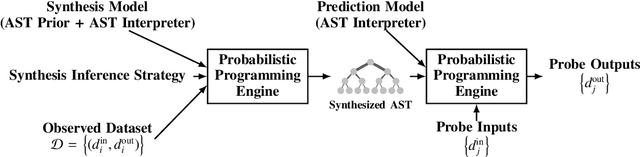


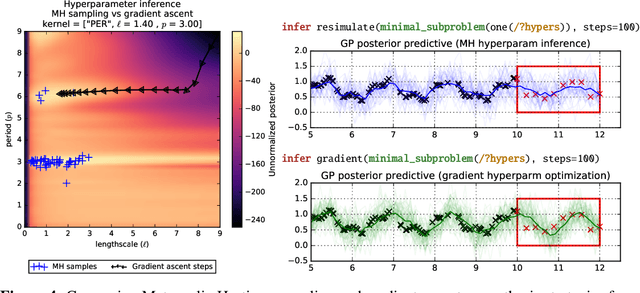
There is a widespread need for techniques that can discover structure from time series data. Recently introduced techniques such as Automatic Bayesian Covariance Discovery (ABCD) provide a way to find structure within a single time series by searching through a space of covariance kernels that is generated using a simple grammar. While ABCD can identify a broad class of temporal patterns, it is difficult to extend and can be brittle in practice. This paper shows how to extend ABCD by formulating it in terms of probabilistic program synthesis. The key technical ideas are to (i) represent models using abstract syntax trees for a domain-specific probabilistic language, and (ii) represent the time series model prior, likelihood, and search strategy using probabilistic programs in a sufficiently expressive language. The final probabilistic program is written in under 70 lines of probabilistic code in Venture. The paper demonstrates an application to time series clustering that involves a non-parametric extension to ABCD, experiments for interpolation and extrapolation on real-world econometric data, and improvements in accuracy over both non-parametric and standard regression baselines.
Learning to Exploit Invariances in Clinical Time-Series Data using Sequence Transformer Networks
Aug 21, 2018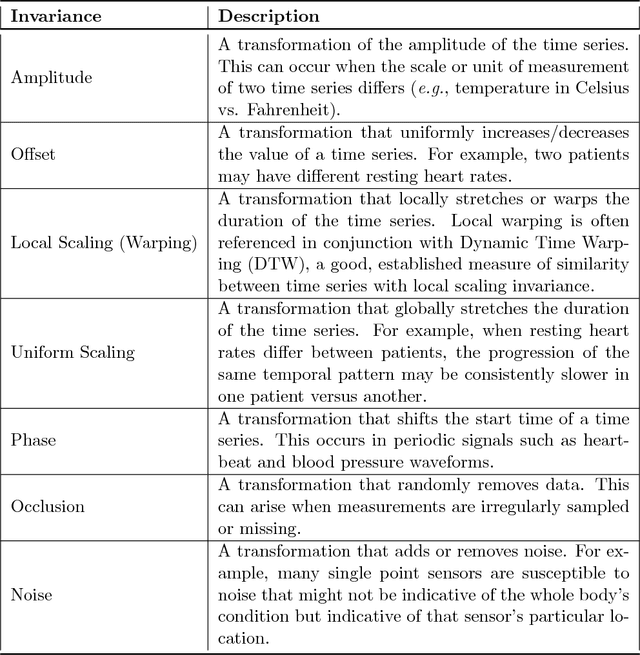
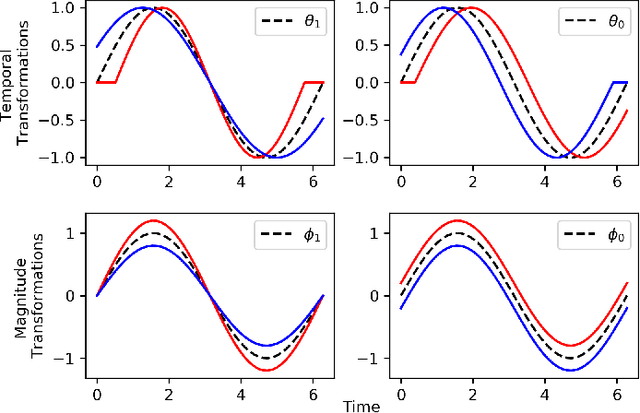
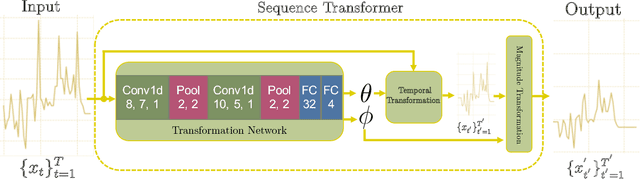
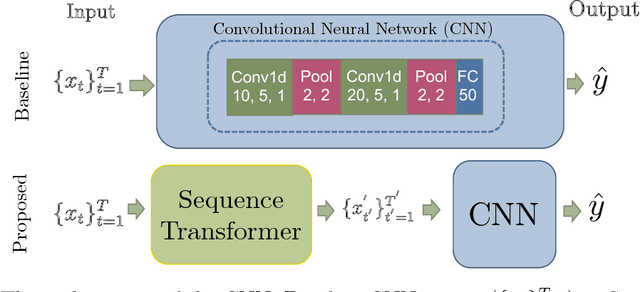
Recently, researchers have started applying convolutional neural networks (CNNs) with one-dimensional convolutions to clinical tasks involving time-series data. This is due, in part, to their computational efficiency, relative to recurrent neural networks and their ability to efficiently exploit certain temporal invariances, (e.g., phase invariance). However, it is well-established that clinical data may exhibit many other types of invariances (e.g., scaling). While preprocessing techniques, (e.g., dynamic time warping) may successfully transform and align inputs, their use often requires one to identify the types of invariances in advance. In contrast, we propose the use of Sequence Transformer Networks, an end-to-end trainable architecture that learns to identify and account for invariances in clinical time-series data. Applied to the task of predicting in-hospital mortality, our proposed approach achieves an improvement in the area under the receiver operating characteristic curve (AUROC) relative to a baseline CNN (AUROC=0.851 vs. AUROC=0.838). Our results suggest that a variety of valuable invariances can be learned directly from the data.
Changing Model Behavior at Test-Time Using Reinforcement Learning
Feb 24, 2017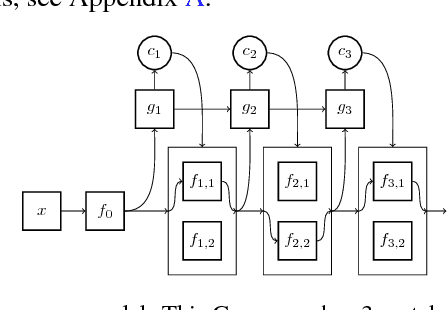
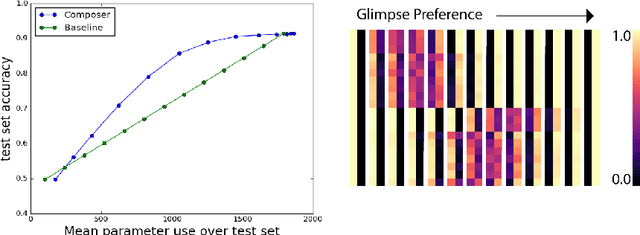

Machine learning models are often used at test-time subject to constraints and trade-offs not present at training-time. For example, a computer vision model operating on an embedded device may need to perform real-time inference, or a translation model operating on a cell phone may wish to bound its average compute time in order to be power-efficient. In this work we describe a mixture-of-experts model and show how to change its test-time resource-usage on a per-input basis using reinforcement learning. We test our method on a small MNIST-based example.
Undistillable: Making A Nasty Teacher That CANNOT teach students
May 16, 2021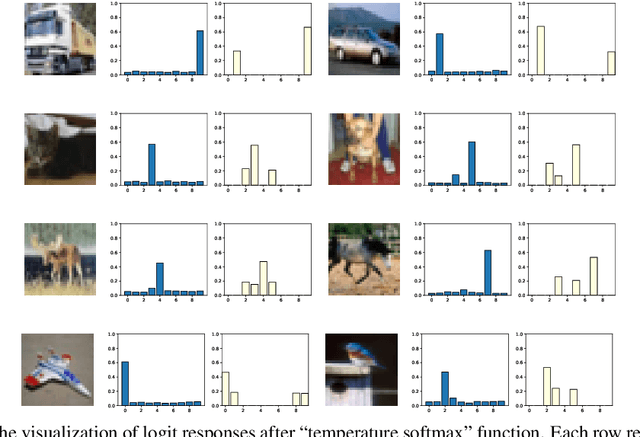
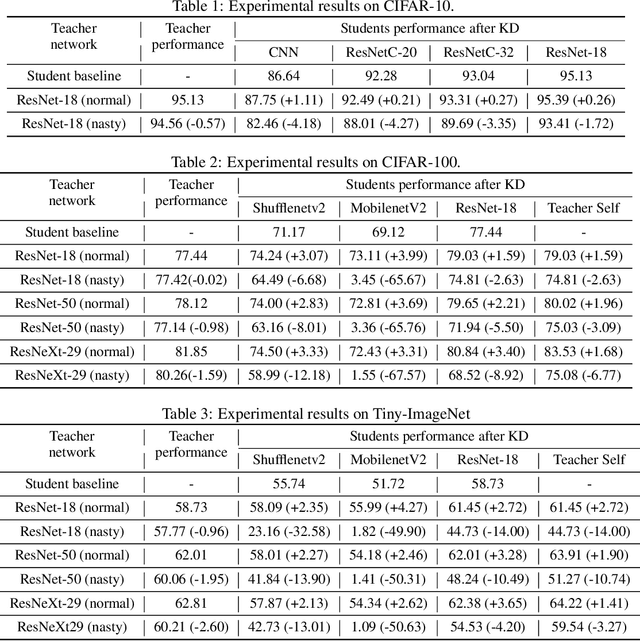
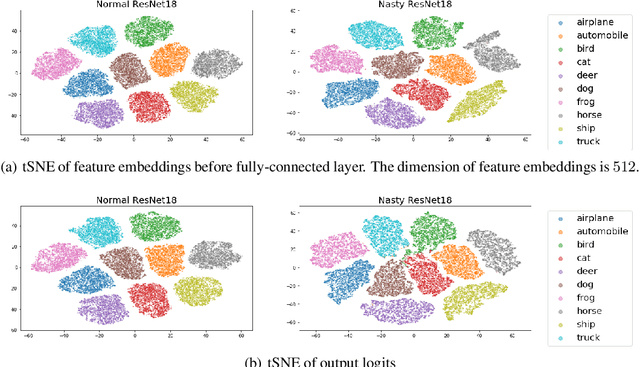
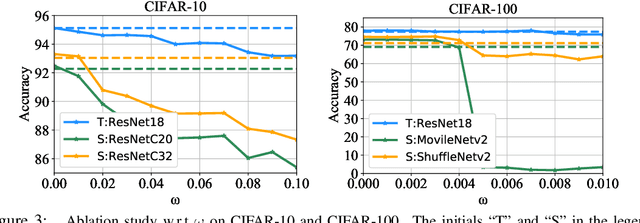
Knowledge Distillation (KD) is a widely used technique to transfer knowledge from pre-trained teacher models to (usually more lightweight) student models. However, in certain situations, this technique is more of a curse than a blessing. For instance, KD poses a potential risk of exposing intellectual properties (IPs): even if a trained machine learning model is released in 'black boxes' (e.g., as executable software or APIs without open-sourcing code), it can still be replicated by KD through imitating input-output behaviors. To prevent this unwanted effect of KD, this paper introduces and investigates a concept called Nasty Teacher: a specially trained teacher network that yields nearly the same performance as a normal one, but would significantly degrade the performance of student models learned by imitating it. We propose a simple yet effective algorithm to build the nasty teacher, called self-undermining knowledge distillation. Specifically, we aim to maximize the difference between the output of the nasty teacher and a normal pre-trained network. Extensive experiments on several datasets demonstrate that our method is effective on both standard KD and data-free KD, providing the desirable KD-immunity to model owners for the first time. We hope our preliminary study can draw more awareness and interest in this new practical problem of both social and legal importance.
* ICLR 2021(Spotlight). Code is available at https://github.com/VITA-Group/Nasty-Teacher
Compressive Neural Representations of Volumetric Scalar Fields
Apr 11, 2021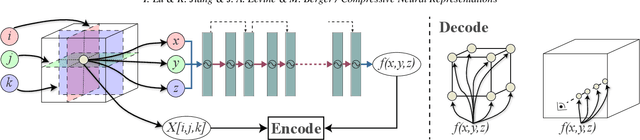
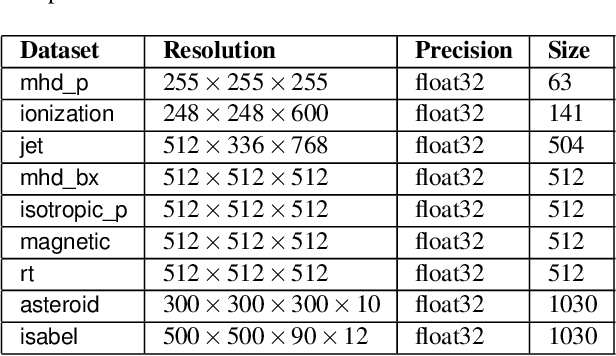
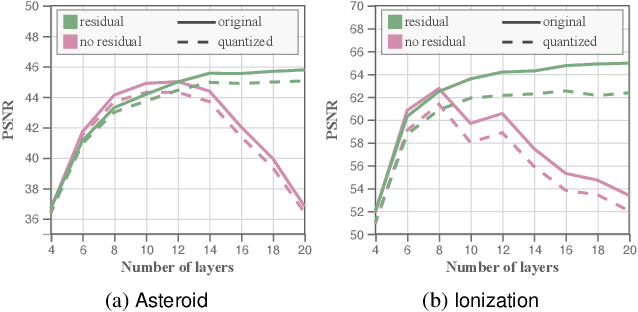
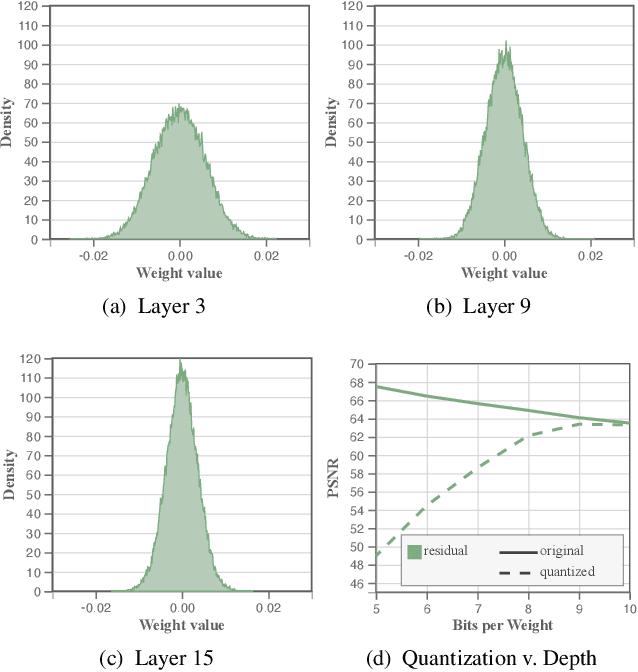
We present an approach for compressing volumetric scalar fields using implicit neural representations. Our approach represents a scalar field as a learned function, wherein a neural network maps a point in the domain to an output scalar value. By setting the number of weights of the neural network to be smaller than the input size, we achieve compressed representations of scalar fields, thus framing compression as a type of function approximation. Combined with carefully quantizing network weights, we show that this approach yields highly compact representations that outperform state-of-the-art volume compression approaches. The conceptual simplicity of our approach enables a number of benefits, such as support for time-varying scalar fields, optimizing to preserve spatial gradients, and random-access field evaluation. We study the impact of network design choices on compression performance, highlighting how simple network architectures are effective for a broad range of volumes.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
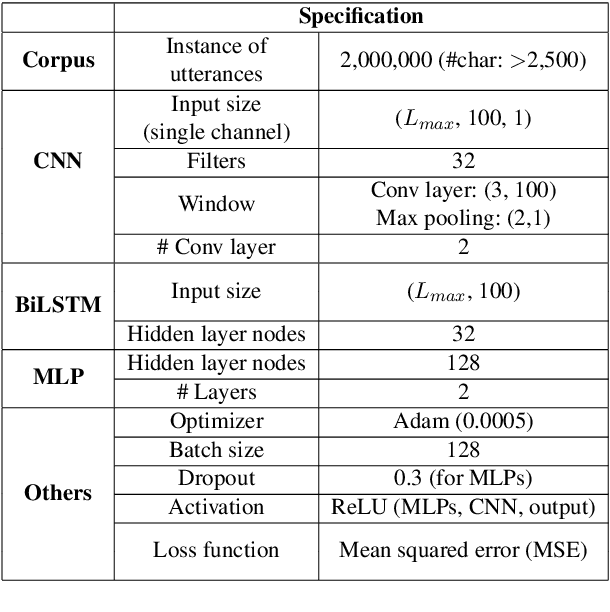
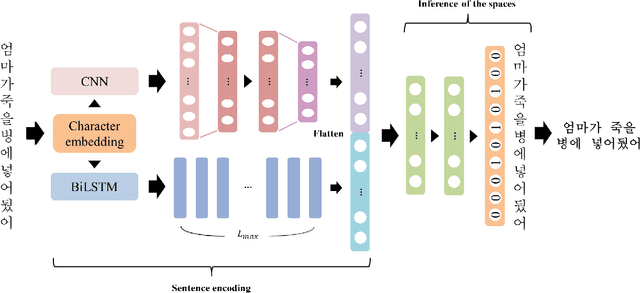
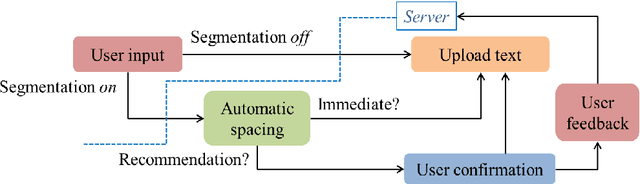
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.
Real-time processing of high resolution video and 3D model-based tracking in remote tower operations
Oct 08, 2019
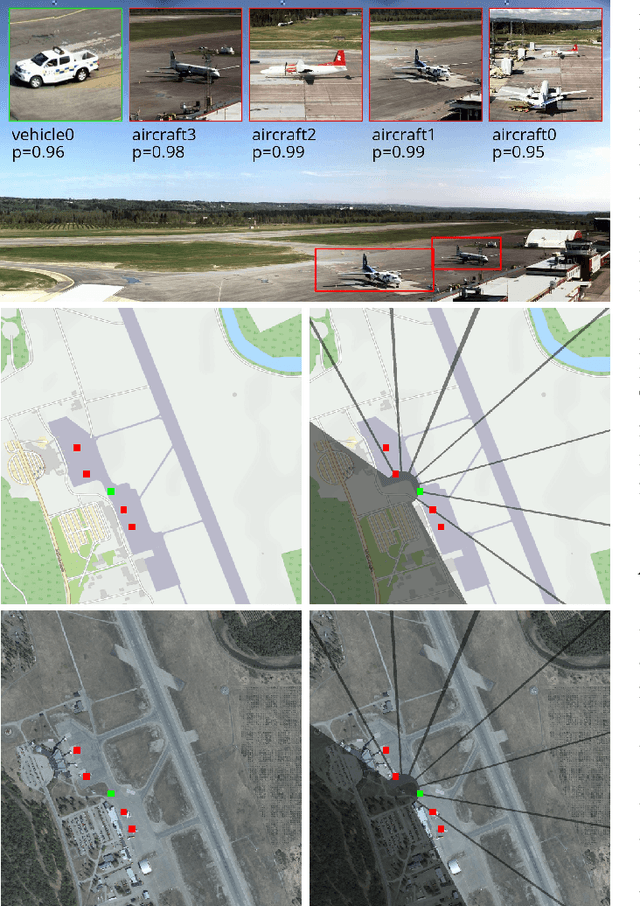

High quality video data is a core component in emerging remote tower operations as it inherently contains a huge amount of information on which an air traffic controller can base decisions. Various digital technologies also have the potential to exploit this data to bring enhancements, including tracking ground movements by relating events in the video view to their positions in 3D space. The total resolution of remote tower setups with multiple cameras often exceeds 25 million RGB pixels and is captured at 30 frames per second or more. It is thus a challenge to efficiently process all the data in such a way as to provide relevant real-time enhancements to the controller. In this paper we discuss how a number of improvements can be implemented efficiently on a single workstation by decoupling processes and utilizing hardware for parallel computing. We also highlight how decoupling the processes in this way increases resilience of the software solution in the sense that failure of a single component does not impair the function of the other components.
Action Segmentation with Mixed Temporal Domain Adaptation
Apr 16, 2021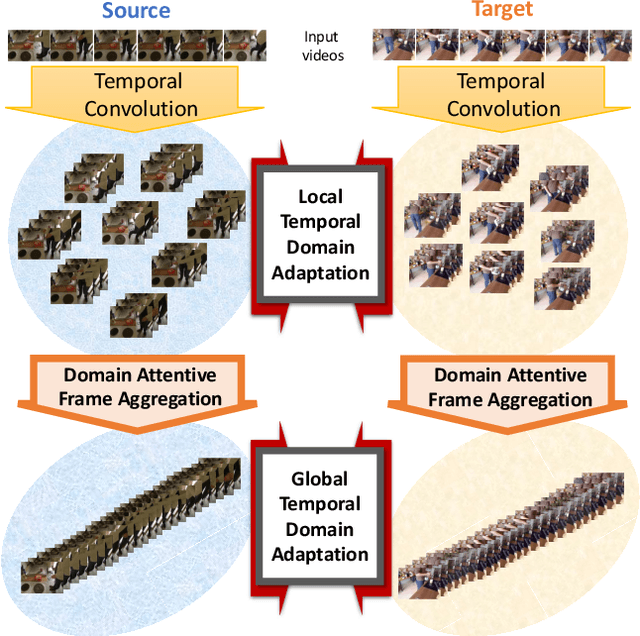
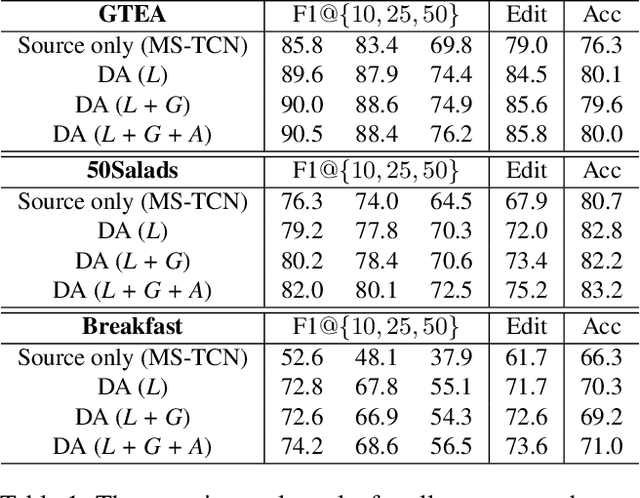
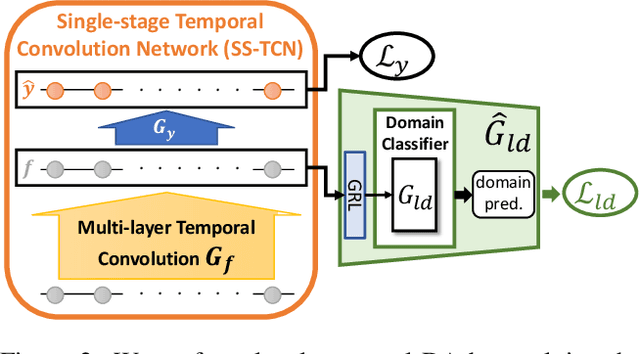
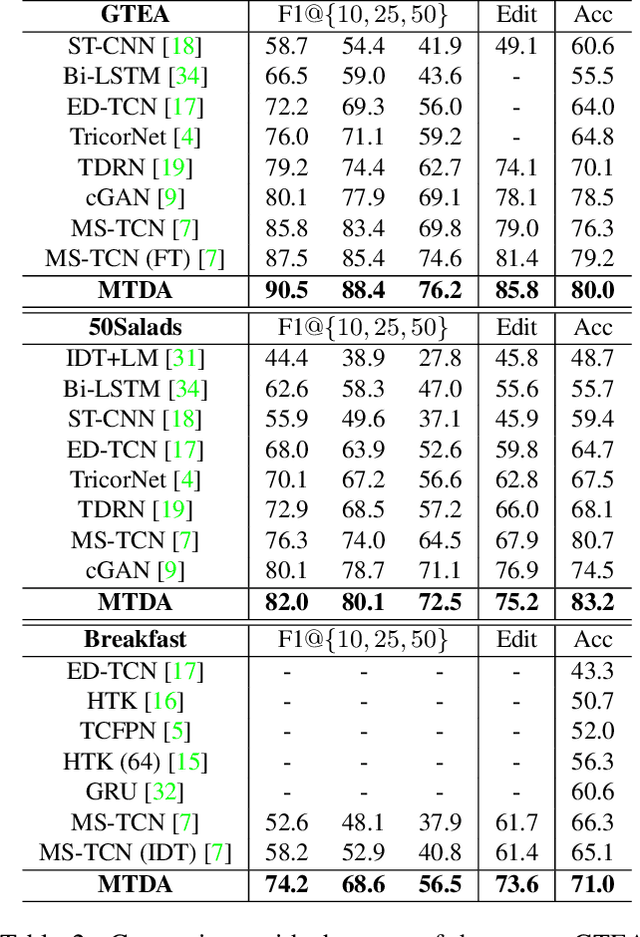
The main progress for action segmentation comes from densely-annotated data for fully-supervised learning. Since manual annotation for frame-level actions is time-consuming and challenging, we propose to exploit auxiliary unlabeled videos, which are much easier to obtain, by shaping this problem as a domain adaptation (DA) problem. Although various DA techniques have been proposed in recent years, most of them have been developed only for the spatial direction. Therefore, we propose Mixed Temporal Domain Adaptation (MTDA) to jointly align frame- and video-level embedded feature spaces across domains, and further integrate with the domain attention mechanism to focus on aligning the frame-level features with higher domain discrepancy, leading to more effective domain adaptation. Finally, we evaluate our proposed methods on three challenging datasets (GTEA, 50Salads, and Breakfast), and validate that MTDA outperforms the current state-of-the-art methods on all three datasets by large margins (e.g. 6.4% gain on F1@50 and 6.8% gain on the edit score for GTEA).
Equivariant neural networks for inverse problems
Feb 23, 2021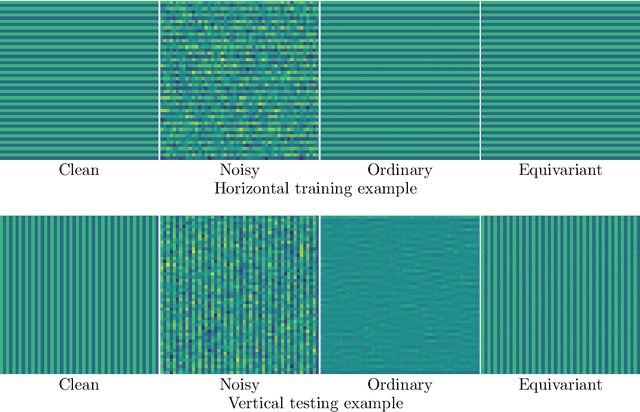

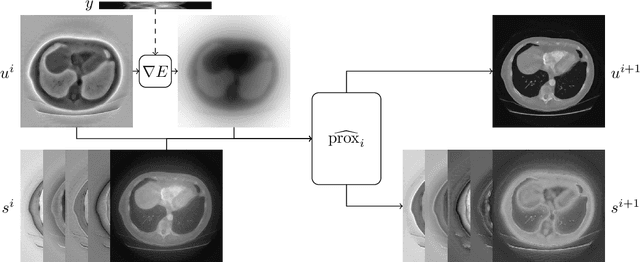
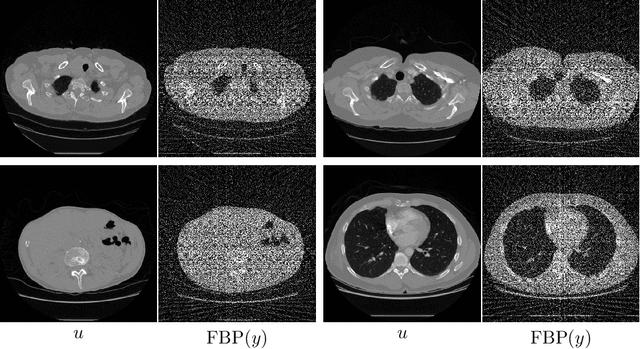
In recent years the use of convolutional layers to encode an inductive bias (translational equivariance) in neural networks has proven to be a very fruitful idea. The successes of this approach have motivated a line of research into incorporating other symmetries into deep learning methods, in the form of group equivariant convolutional neural networks. Much of this work has been focused on roto-translational symmetry of $\mathbf R^d$, but other examples are the scaling symmetry of $\mathbf R^d$ and rotational symmetry of the sphere. In this work, we demonstrate that group equivariant convolutional operations can naturally be incorporated into learned reconstruction methods for inverse problems that are motivated by the variational regularisation approach. Indeed, if the regularisation functional is invariant under a group symmetry, the corresponding proximal operator will satisfy an equivariance property with respect to the same group symmetry. As a result of this observation, we design learned iterative methods in which the proximal operators are modelled as group equivariant convolutional neural networks. We use roto-translationally equivariant operations in the proposed methodology and apply it to the problems of low-dose computerised tomography reconstruction and subsampled magnetic resonance imaging reconstruction. The proposed methodology is demonstrated to improve the reconstruction quality of a learned reconstruction method with a little extra computational cost at training time but without any extra cost at test time.
Time-Dependent Hybrid-State A* and Optimal Control for Autonomous Vehicles in Arbitrary and Dynamic Environment
Nov 08, 2019
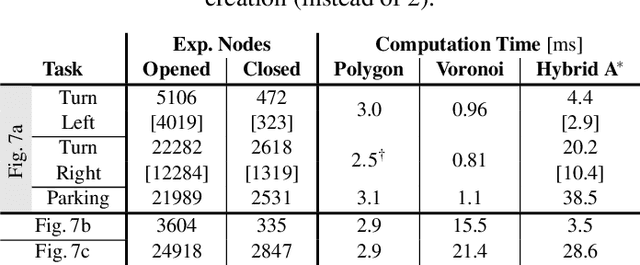
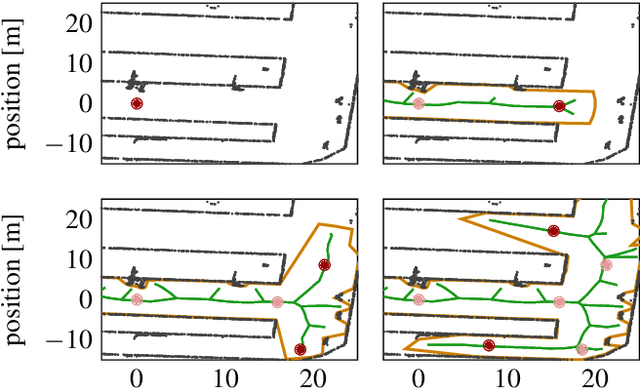
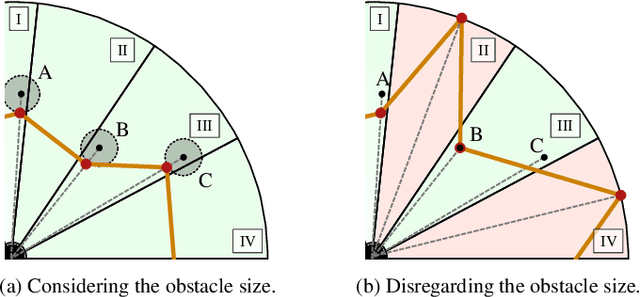
The development of driving functions for autonomous vehicles in urban environments is still a challenging task. In comparison with driving on motorways, a wide variety of moving road users, such as pedestrians or cyclists, but also the strongly varying and sometimes very narrow road layout pose special challenges. The ability to make fast decisions about exact maneuvers and to execute them by applying sophisticated control commands is one of the key requirements for autonomous vehicles in such situations. In this context we present an algorithmic concept of three correlated methods. Its basis is a novel technique for the automated generation of a free-space polygon, providing a generic representation of the currently drivable area. We then develop a time-dependent hybrid-state A* algorithm as a model-based planner for the efficient and precise computation of possible driving maneuvers in arbitrary dynamic environments. While on the one hand its results can be used as a basis for making short-term decisions, we also show their applicability as an initial guess for a subsequent trajectory optimization in order to compute applicable control signals. Finally, we provide numerical results for a variety of simulated situations demonstrating the efficiency and robustness of the proposed methods.