 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse Gaussian process Audio Source Separation Using Spectrum Priors in the Time-Domain
Nov 05, 2018
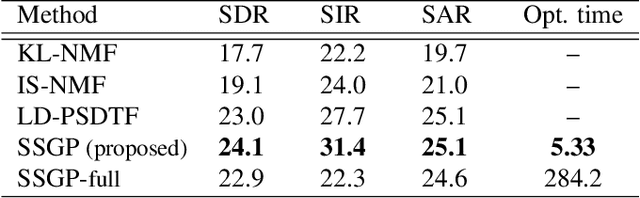
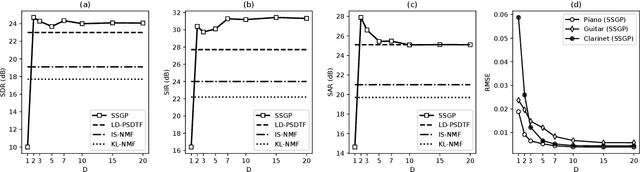
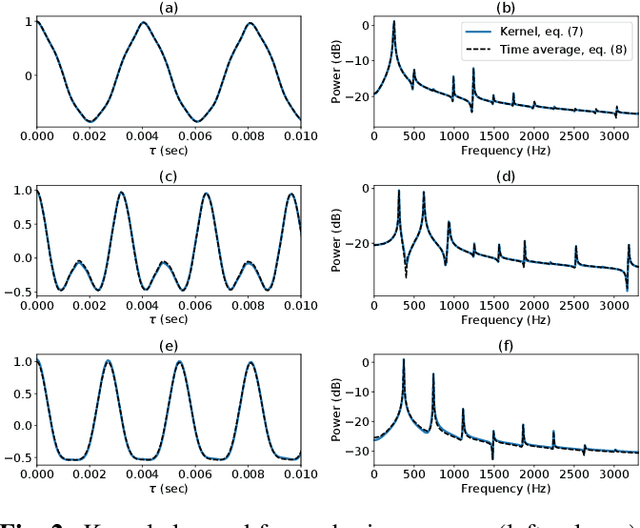
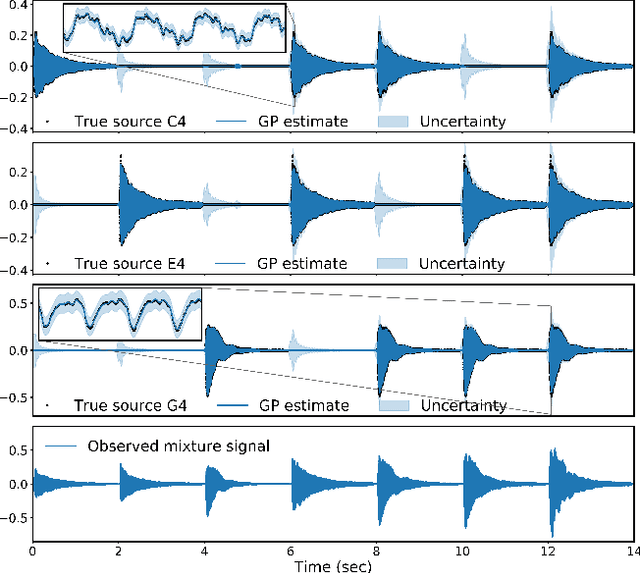
Gaussian process (GP) audio source separation is a time-domain approach that circumvents the inherent phase approximation issue of spectrogram based methods. Furthermore, through its kernel, GPs elegantly incorporate prior knowledge about the sources into the separation model. Despite these compelling advantages, the computational complexity of GP inference scales cubically with the number of audio samples. As a result, source separation GP models have been restricted to the analysis of short audio frames. We introduce an efficient application of GPs to time-domain audio source separation, without compromising performance. For this purpose, we used GP regression, together with spectral mixture kernels, and variational sparse GPs. We compared our method with LD-PSDTF (positive semi-definite tensor factorization), KL-NMF (Kullback-Leibler non-negative matrix factorization), and IS-NMF (Itakura-Saito NMF). Results show that the proposed method outperforms these techniques.
Changing Model Behavior at Test-Time Using Reinforcement Learning
Feb 24, 2017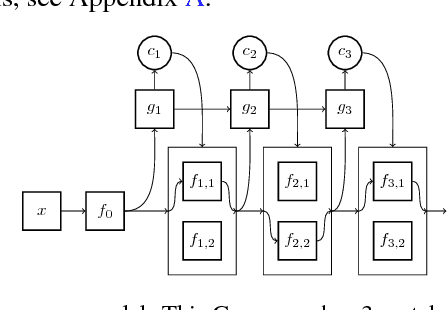
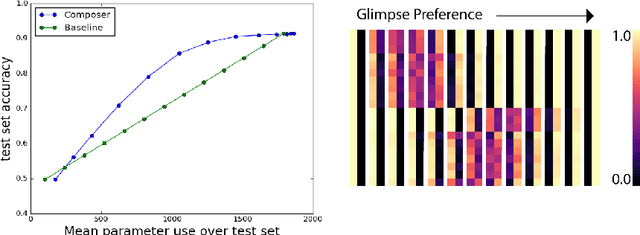

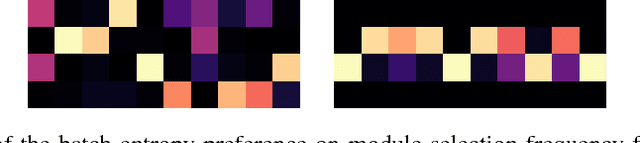
Machine learning models are often used at test-time subject to constraints and trade-offs not present at training-time. For example, a computer vision model operating on an embedded device may need to perform real-time inference, or a translation model operating on a cell phone may wish to bound its average compute time in order to be power-efficient. In this work we describe a mixture-of-experts model and show how to change its test-time resource-usage on a per-input basis using reinforcement learning. We test our method on a small MNIST-based example.
Efficient Transformer based Method for Remote Sensing Image Change Detection
Mar 15, 2021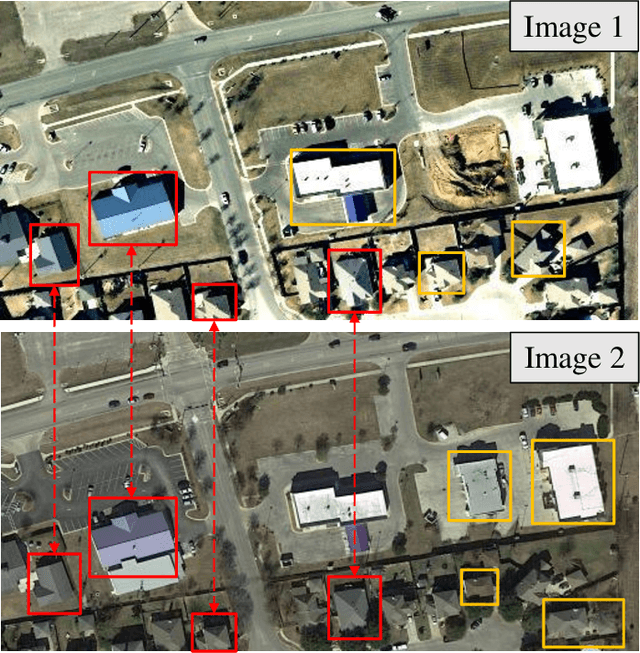
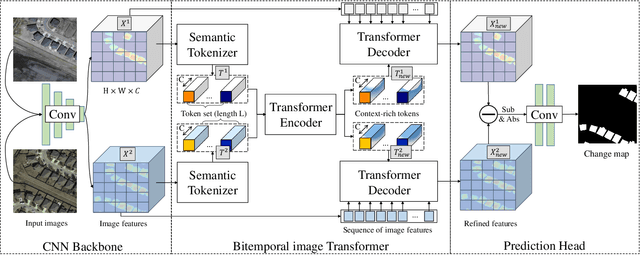
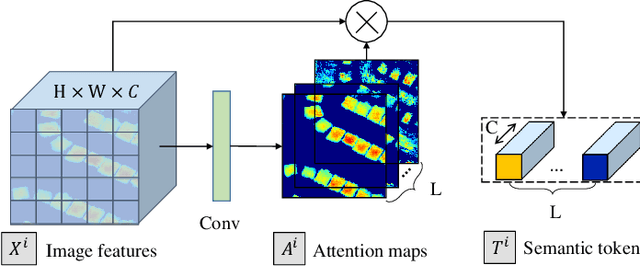
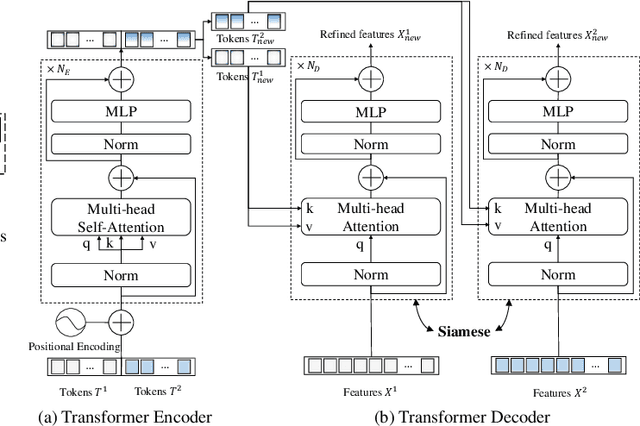
Modern change detection (CD) has achieved remarkable success by the powerful discriminative ability of deep convolutions. However, high-resolution remote sensing CD remains challenging due to the complexity of objects in the scene. Objects with the same semantic concept may show distinct spectral behaviors at different times and different spatial locations. Most recent CD pipelines using pure convolutions are still struggling to relate long-range concepts in space-time. Non-local self-attention approaches show promising performance via modeling dense relations among pixels, yet are computationally inefficient. Here, we propose a bitemporal image transformer (BiT) to efficiently and effectively model contexts within the spatial-temporal domain. Our intuition is that the high-level concepts of the change of interest can be represented by a few visual words, i.e., semantic tokens. To achieve this, we express the bitemporal image into a few tokens, and use a transformer encoder to model contexts in the compact token-based space-time. The learned context-rich tokens are then feedback to the pixel-space for refining the original features via a transformer decoder. We incorporate BiT in a deep feature differencing-based CD framework. Extensive experiments on three CD datasets demonstrate the effectiveness and efficiency of the proposed method. Notably, our BiT-based model significantly outperforms the purely convolutional baseline using only 3 times lower computational costs and model parameters. Based on a naive backbone (ResNet18) without sophisticated structures (e.g., FPN, UNet), our model surpasses several state-of-the-art CD methods, including better than two recent attention-based methods in terms of efficiency and accuracy. Our code will be made public.
Modeling Varying Camera-IMU Time Offset in Optimization-Based Visual-Inertial Odometry
Oct 12, 2018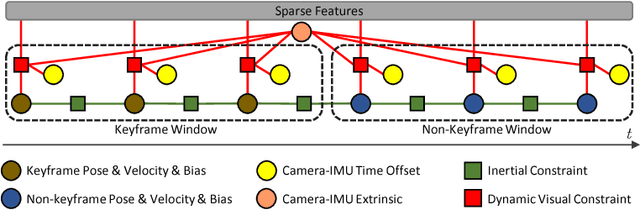
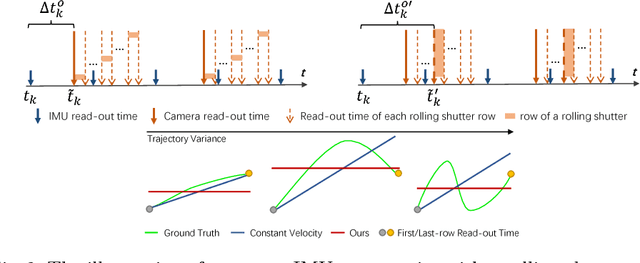
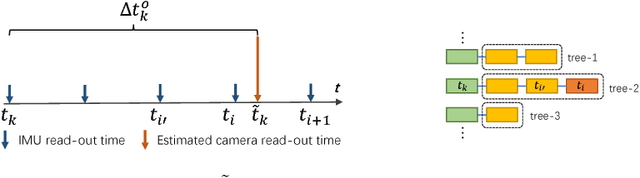
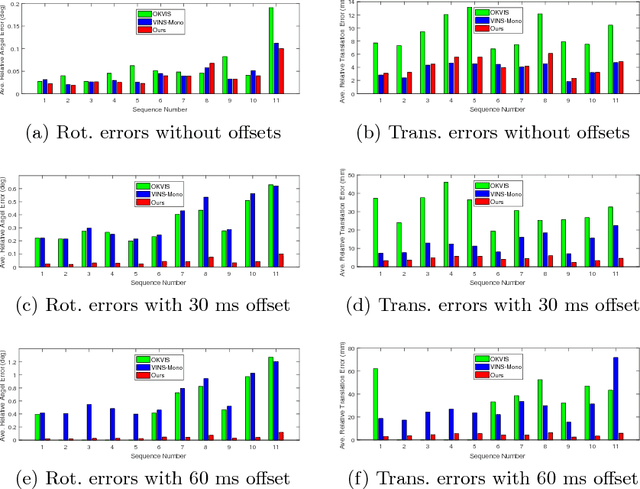
Combining cameras and inertial measurement units (IMUs) has been proven effective in motion tracking, as these two sensing modalities offer complementary characteristics that are suitable for fusion. While most works focus on global-shutter cameras and synchronized sensor measurements, consumer-grade devices are mostly equipped with rolling-shutter cameras and suffer from imperfect sensor synchronization. In this work, we propose a nonlinear optimization-based monocular visual inertial odometry (VIO) with varying camera-IMU time offset modeled as an unknown variable. Our approach is able to handle the rolling-shutter effects and imperfect sensor synchronization in a unified way. Additionally, we introduce an efficient algorithm based on dynamic programming and red-black tree to speed up IMU integration over variable-length time intervals during the optimization. An uncertainty-aware initialization is also presented to launch the VIO robustly. Comparisons with state-of-the-art methods on the Euroc dataset and mobile phone data are shown to validate the effectiveness of our approach.
Speaker Diarization using Two-pass Leave-One-Out Gaussian PLDA Clustering of DNN Embeddings
Apr 07, 2021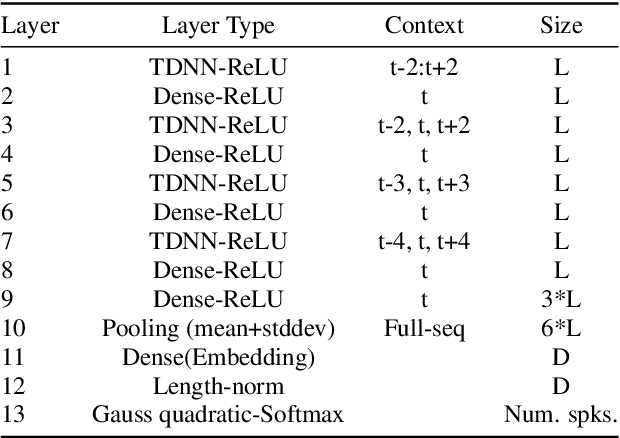
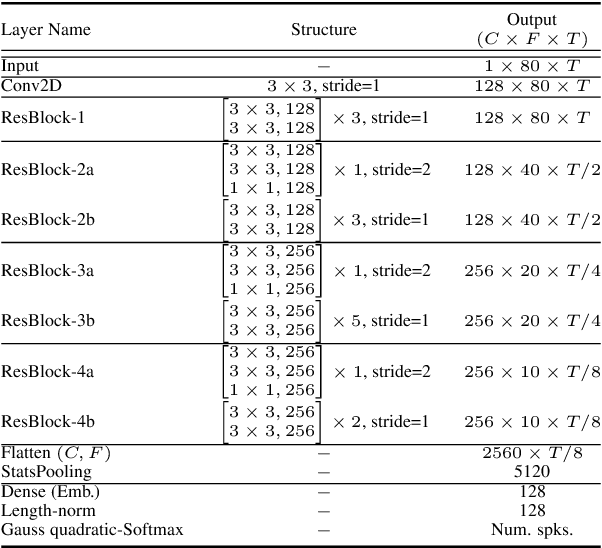
Many modern systems for speaker diarization, such as the recently-developed VBx approach, rely on clustering of DNN speaker embeddings followed by resegmentation. Two problems with this approach are that the DNN is not directly optimized for this task, and the parameters need significant retuning for different applications. We have recently presented progress in this direction with a Leave-One-Out Gaussian PLDA (LGP) clustering algorithm and an approach to training the DNN such that embeddings directly optimize performance of this scoring method. This paper presents a new two-pass version of this system, where the second pass uses finer time resolution to significantly improve overall performance. For the Callhome corpus, we achieve the first published error rate below 4\% without any task-dependent parameter tuning. We also show significant progress towards a robust single solution for multiple diarization tasks.
VIRAL SLAM: Tightly Coupled Camera-IMU-UWB-Lidar SLAM
May 16, 2021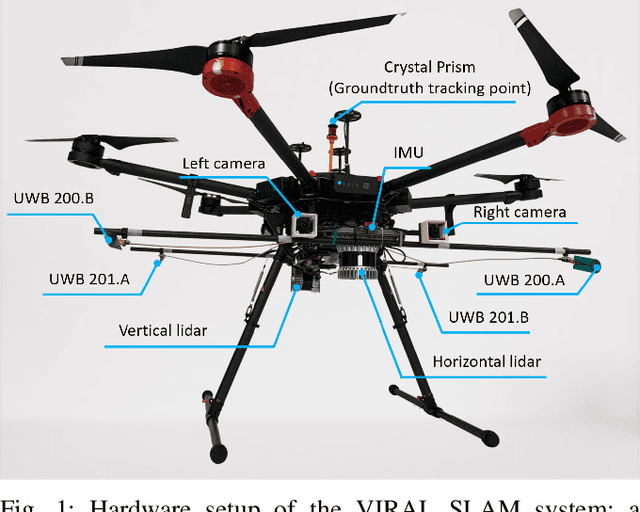
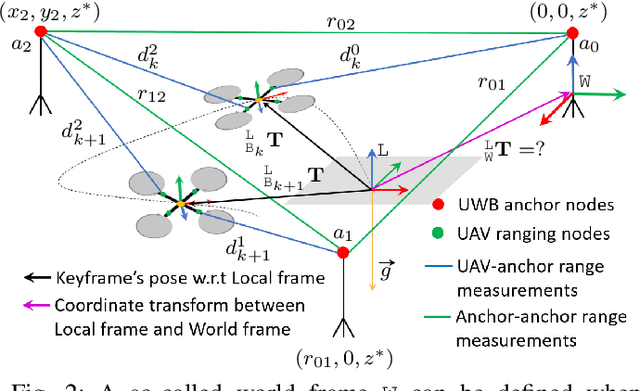
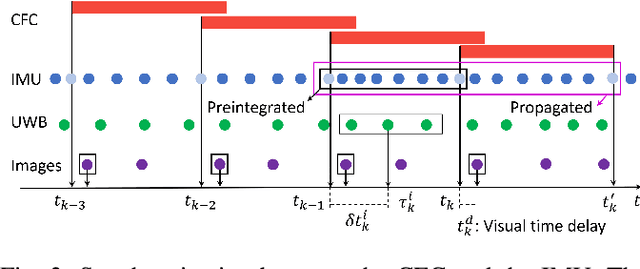
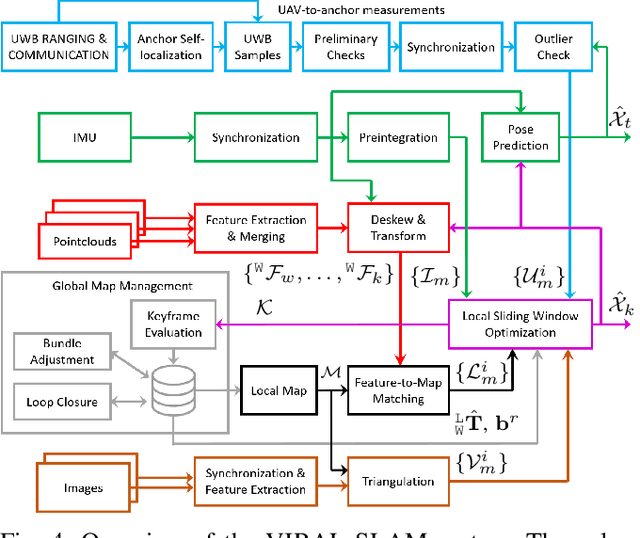
In this paper, we propose a tightly-coupled, multi-modal simultaneous localization and mapping (SLAM) framework, integrating an extensive set of sensors: IMU, cameras, multiple lidars, and Ultra-wideband (UWB) range measurements, hence referred to as VIRAL (visual-inertial-ranging-lidar) SLAM. To achieve such a comprehensive sensor fusion system, one has to tackle several challenges such as data synchronization, multi-threading programming, bundle adjustment (BA), and conflicting coordinate frames between UWB and the onboard sensors, so as to ensure real-time localization and smooth updates in the state estimates. To this end, we propose a two stage approach. In the first stage, lidar, camera, and IMU data on a local sliding window are processed in a core odometry thread. From this local graph, new key frames are evaluated for admission to a global map. Visual feature-based loop closure is also performed to supplement the global factor graph with loop constraints. When the global factor graph satisfies a condition on spatial diversity, the BA process will be triggered, which updates the coordinate transform between UWB and onboard SLAM systems. The system then seamlessly transitions to the second stage where all sensors are tightly integrated in the odometry thread. The capability of our system is demonstrated via several experiments on high-fidelity graphical-physical simulation and public datasets.
A Survey of Machine Learning for Computer Architecture and Systems
Feb 16, 2021
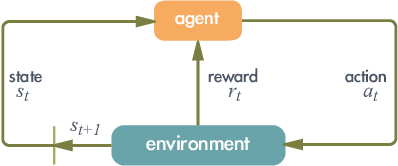
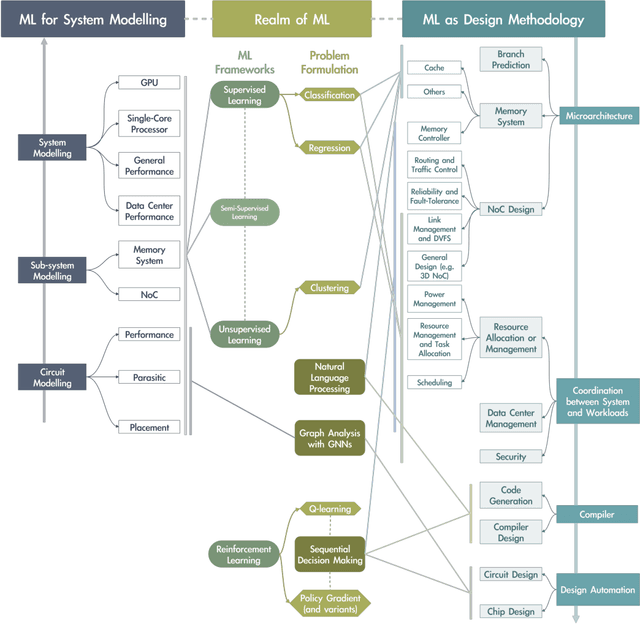
It has been a long time that computer architecture and systems are optimized to enable efficient execution of machine learning (ML) algorithms or models. Now, it is time to reconsider the relationship between ML and systems, and let ML transform the way that computer architecture and systems are designed. This embraces a twofold meaning: the improvement of designers' productivity, and the completion of the virtuous cycle. In this paper, we present a comprehensive review of work that applies ML for system design, which can be grouped into two major categories, ML-based modelling that involves predictions of performance metrics or some other criteria of interest, and ML-based design methodology that directly leverages ML as the design tool. For ML-based modelling, we discuss existing studies based on their target level of system, ranging from the circuit level to the architecture/system level. For ML-based design methodology, we follow a bottom-up path to review current work, with a scope of (micro-)architecture design (memory, branch prediction, NoC), coordination between architecture/system and workload (resource allocation and management, data center management, and security), compiler, and design automation. We further provide a future vision of opportunities and potential directions, and envision that applying ML for computer architecture and systems would thrive in the community.
Time Series Structure Discovery via Probabilistic Program Synthesis
May 22, 2017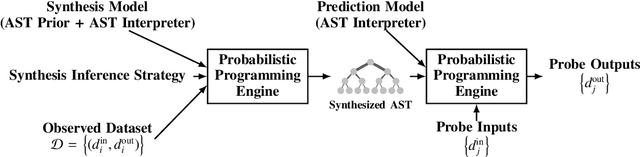


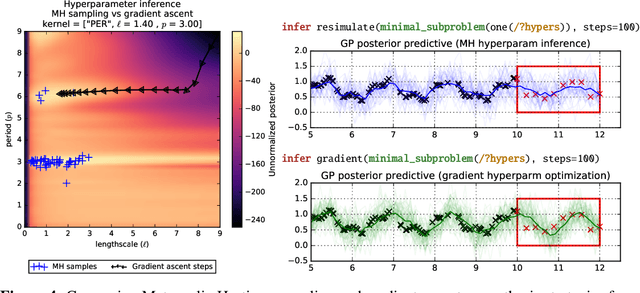
There is a widespread need for techniques that can discover structure from time series data. Recently introduced techniques such as Automatic Bayesian Covariance Discovery (ABCD) provide a way to find structure within a single time series by searching through a space of covariance kernels that is generated using a simple grammar. While ABCD can identify a broad class of temporal patterns, it is difficult to extend and can be brittle in practice. This paper shows how to extend ABCD by formulating it in terms of probabilistic program synthesis. The key technical ideas are to (i) represent models using abstract syntax trees for a domain-specific probabilistic language, and (ii) represent the time series model prior, likelihood, and search strategy using probabilistic programs in a sufficiently expressive language. The final probabilistic program is written in under 70 lines of probabilistic code in Venture. The paper demonstrates an application to time series clustering that involves a non-parametric extension to ABCD, experiments for interpolation and extrapolation on real-world econometric data, and improvements in accuracy over both non-parametric and standard regression baselines.
OmniFlow: Human Omnidirectional Optical Flow
Apr 16, 2021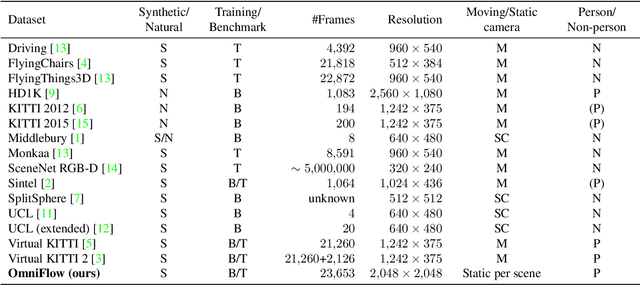
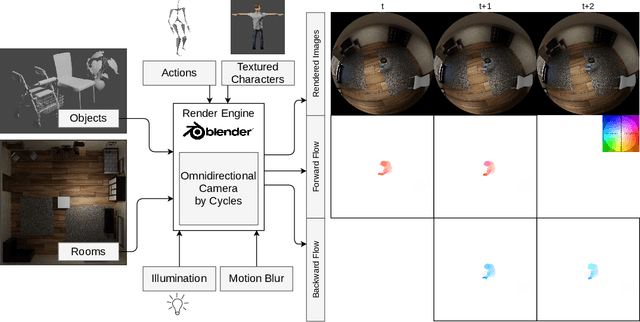
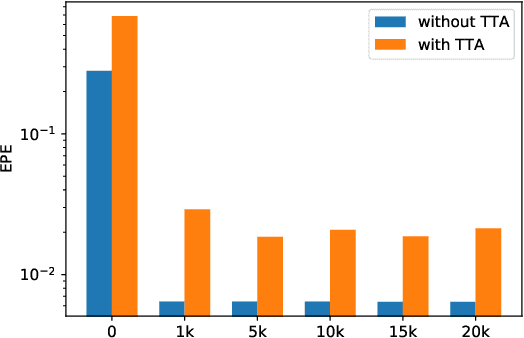
Optical flow is the motion of a pixel between at least two consecutive video frames and can be estimated through an end-to-end trainable convolutional neural network. To this end, large training datasets are required to improve the accuracy of optical flow estimation. Our paper presents OmniFlow: a new synthetic omnidirectional human optical flow dataset. Based on a rendering engine we create a naturalistic 3D indoor environment with textured rooms, characters, actions, objects, illumination and motion blur where all components of the environment are shuffled during the data capturing process. The simulation has as output rendered images of household activities and the corresponding forward and backward optical flow. To verify the data for training volumetric correspondence networks for optical flow estimation we train different subsets of the data and test on OmniFlow with and without Test-Time-Augmentation. As a result we have generated 23,653 image pairs and corresponding forward and backward optical flow. Our dataset can be downloaded from: https://mytuc.org/byfs
KVT: k-NN Attention for Boosting Vision Transformers
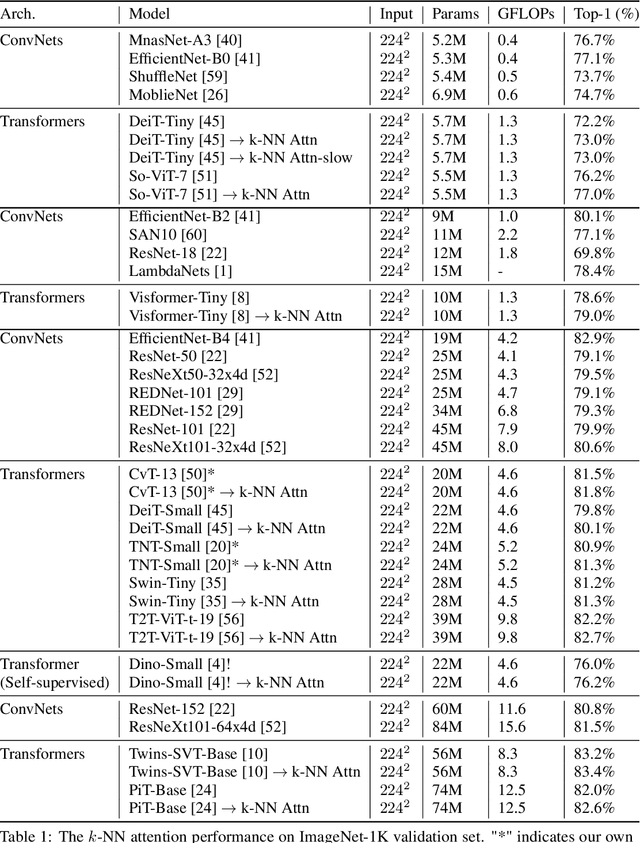
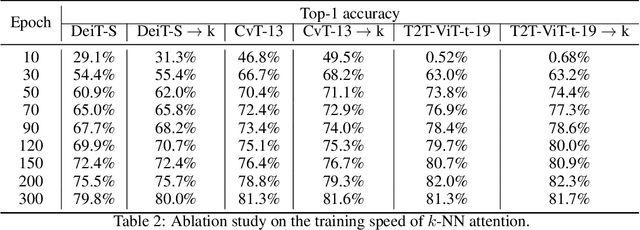
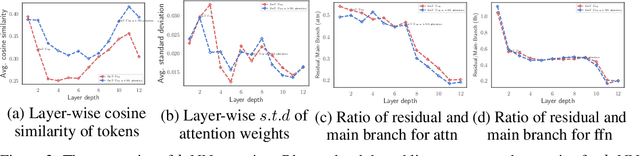
May 28, 2021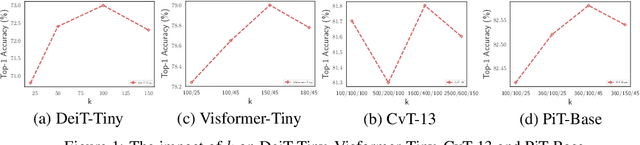
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.