 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing Flight Delay Prediction Under Concept Drift
Apr 05, 2021
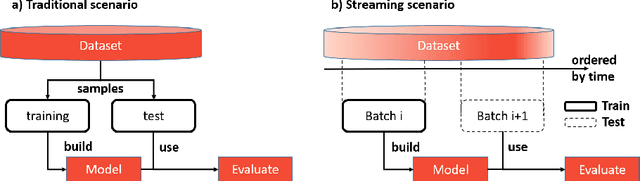

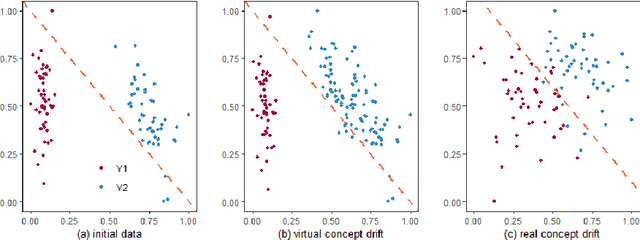

Flight delays impose challenges that impact any flight transportation system. Predicting when they are going to occur is an important way to mitigate this issue. However, the behavior of the flight delay system varies through time. This phenomenon is known in predictive analytics as concept drift. This paper investigates the prediction performance of different drift handling strategies in aviation under different scales (models trained from flights related to a single airport or the entire flight system). Specifically, two research questions were proposed and answered: (i) How do drift handling strategies influence the prediction performance of delays? (ii) Do different scales change the results of drift handling strategies? In our analysis, drift handling strategies are relevant, and their impacts vary according to scale and machine learning models used.
Automatic linear measurements of the fetal brain on MRI with deep neural networks
Jun 15, 2021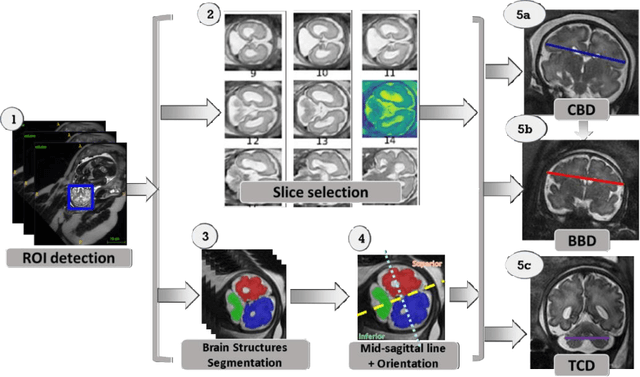
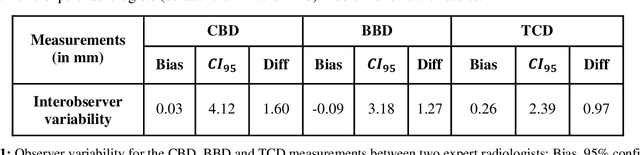
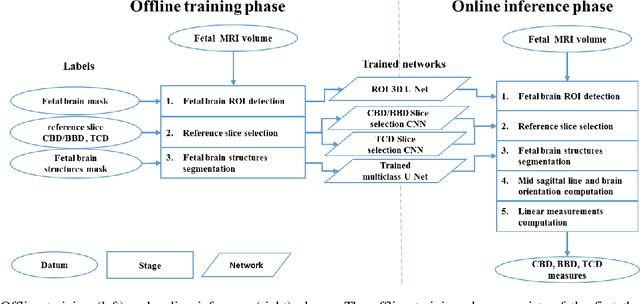
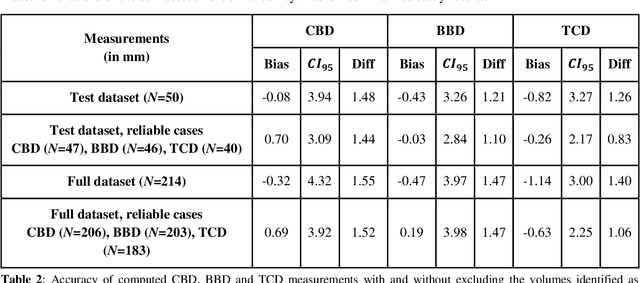
Timely, accurate and reliable assessment of fetal brain development is essential to reduce short and long-term risks to fetus and mother. Fetal MRI is increasingly used for fetal brain assessment. Three key biometric linear measurements important for fetal brain evaluation are Cerebral Biparietal Diameter (CBD), Bone Biparietal Diameter (BBD), and Trans-Cerebellum Diameter (TCD), obtained manually by expert radiologists on reference slices, which is time consuming and prone to human error. The aim of this study was to develop a fully automatic method computing the CBD, BBD and TCD measurements from fetal brain MRI. The input is fetal brain MRI volumes which may include the fetal body and the mother's abdomen. The outputs are the measurement values and reference slices on which the measurements were computed. The method, which follows the manual measurements principle, consists of five stages: 1) computation of a Region Of Interest that includes the fetal brain with an anisotropic 3D U-Net classifier; 2) reference slice selection with a Convolutional Neural Network; 3) slice-wise fetal brain structures segmentation with a multiclass U-Net classifier; 4) computation of the fetal brain midsagittal line and fetal brain orientation, and; 5) computation of the measurements. Experimental results on 214 volumes for CBD, BBD and TCD measurements yielded a mean $L_1$ difference of 1.55mm, 1.45mm and 1.23mm respectively, and a Bland-Altman 95% confidence interval ($CI_{95}$) of 3.92mm, 3.98mm and 2.25mm respectively. These results are similar to the manual inter-observer variability. The proposed automatic method for computing biometric linear measurements of the fetal brain from MR imaging achieves human level performance. It has the potential of being a useful method for the assessment of fetal brain biometry in normal and pathological cases, and of improving routine clinical practice.
Integrating Novelty Detection Capabilities with MSL Mastcam Operations to Enhance Data Analysis
Mar 23, 2021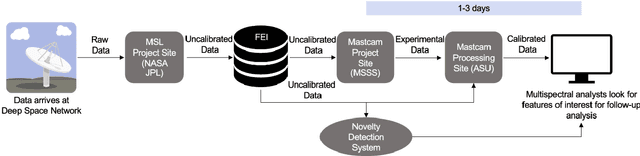



While innovations in scientific instrumentation have pushed the boundaries of Mars rover mission capabilities, the increase in data complexity has pressured Mars Science Laboratory (MSL) and future Mars rover operations staff to quickly analyze complex data sets to meet progressively shorter tactical and strategic planning timelines. MSLWEB is an internal data tracking tool used by operations staff to perform first pass analysis on MSL image sequences, a series of products taken by the Mast camera, Mastcam. Mastcam's multiband multispectral image sequences require more complex analysis compared to standard 3-band RGB images. Typically, these are analyzed using traditional methods to identify unique features within the sequence. Given the short time frame of tactical planning in which downlinked images might need to be analyzed (within 5-10 hours before the next uplink), there exists a need to triage analysis time to focus on the most important sequences and parts of a sequence. We address this need by creating products for MSLWEB that use novelty detection to help operations staff identify unusual data that might be diagnostic of new or atypical compositions or mineralogies detected within an imaging scene. This was achieved in two ways: 1) by creating products for each sequence to identify novel regions in the image, and 2) by assigning multispectral sequences a sortable novelty score. These new products provide colorized heat maps of inferred novelty that operations staff can use to rapidly review downlinked data and focus their efforts on analyzing potentially new kinds of diagnostic multispectral signatures. This approach has the potential to guide scientists to new discoveries by quickly drawing their attention to often subtle variations not detectable with simple color composites.
PEMNET: A Transfer Learning-based Modeling Approach of High-Temperature Polymer Electrolyte Membrane Electrochemical Systems
May 24, 2021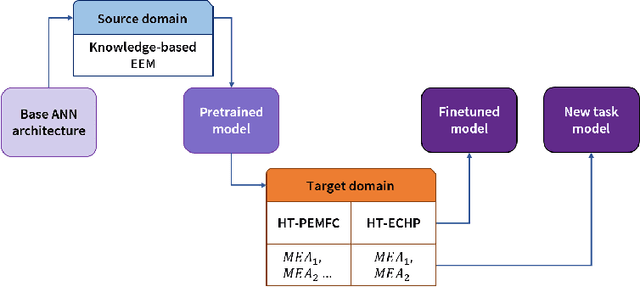
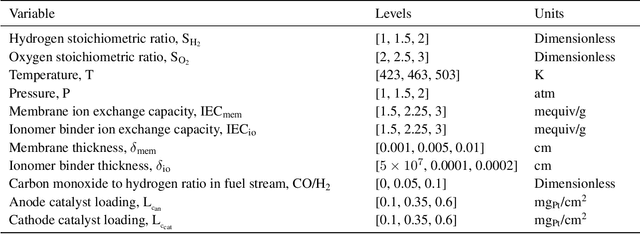
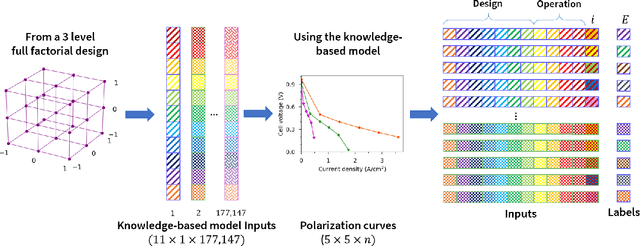
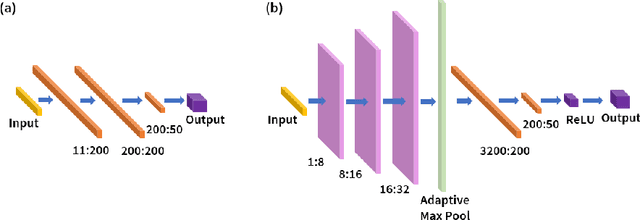
Widespread adoption of high-temperature polymer electrolyte membrane fuel cells (HT-PEMFCs) and HT-PEM electrochemical hydrogen pumps (HT-PEM ECHPs) requires models and computational tools that provide accurate scale-up and optimization. Knowledge-based modeling has limitations as it is time consuming and requires information about the system that is not always available (e.g., material properties and interfacial behavior between different materials). Data-driven modeling on the other hand, is easier to implement, but often necessitates large datasets that could be difficult to obtain. In this contribution, knowledge-based modeling and data-driven modeling are uniquely combined by implementing a Few-Shot Learning (FSL) approach. A knowledge-based model originally developed for a HT-PEMFC was used to generate simulated data (887,735 points) and used to pretrain a neural network source model. Furthermore, the source model developed for HT-PEMFCs was successfully applied to HT-PEM ECHPs - a different electrochemical system that utilizes similar materials to the fuel cell. Experimental datasets from both HT-PEMFCs and HT-PEM ECHPs with different materials and operating conditions (~50 points each) were used to train 8 target models via FSL. Models for the unseen data reached high accuracies in all cases (rRMSE between 1.04 and 3.73% for HT-PEMCs and between 6.38 and 8.46% for HT-PEM ECHPs).
Estimation of Continuous Blood Pressure from PPG via a Federated Learning Approach
Feb 24, 2021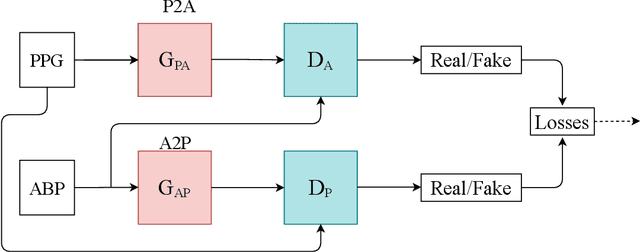

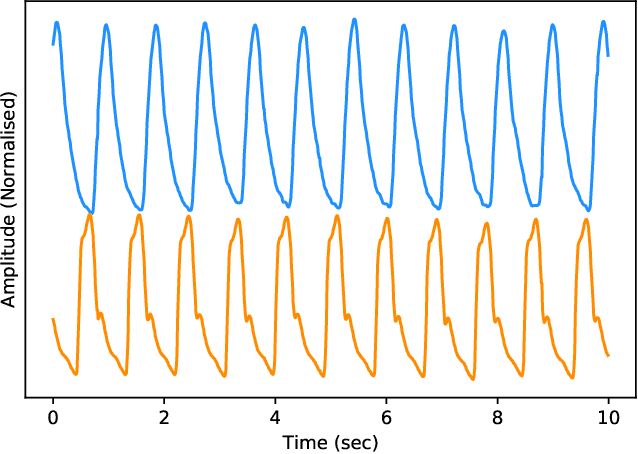
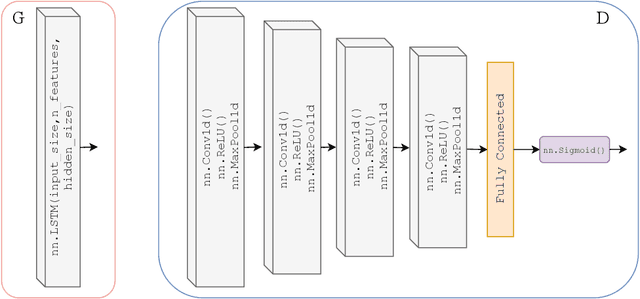
Ischemic heart disease is the highest cause of mortality globally each year. This not only puts a massive strain on the lives of those affected but also on the public healthcare systems. To understand the dynamics of the healthy and unhealthy heart doctors commonly use electrocardiogram (ECG) and blood pressure (BP) readings. These methods are often quite invasive, in particular when continuous arterial blood pressure (ABP) readings are taken and not to mention very costly. Using machine learning methods we seek to develop a framework that is capable of inferring ABP from a single optical photoplethysmogram (PPG) sensor alone. We train our framework across distributed models and data sources to mimic a large-scale distributed collaborative learning experiment that could be implemented across low-cost wearables. Our time series-to-time series generative adversarial network (T2TGAN) is capable of high-quality continuous ABP generation from a PPG signal with a mean error of 2.54 mmHg and a standard deviation of 23.7 mmHg when estimating mean arterial pressure on a previously unseen, noisy, independent dataset. To our knowledge, this framework is the first example of a GAN capable of continuous ABP generation from an input PPG signal that also uses a federated learning methodology.
Uncertainty-Aware Signal Temporal Logic Inference
May 30, 2021



Temporal logic inference is the process of extracting formal descriptions of system behaviors from data in the form of temporal logic formulas. The existing temporal logic inference methods mostly neglect uncertainties in the data, which results in limited applicability of such methods in real-world deployments. In this paper, we first investigate the uncertainties associated with trajectories of a system and represent such uncertainties in the form of interval trajectories. We then propose two uncertainty-aware signal temporal logic (STL) inference approaches to classify the undesired behaviors and desired behaviors of a system. Instead of classifying finitely many trajectories, we classify infinitely many trajectories within the interval trajectories. In the first approach, we incorporate robust semantics of STL formulas with respect to an interval trajectory to quantify the margin at which an STL formula is satisfied or violated by the interval trajectory. The second approach relies on the first learning algorithm and exploits the decision tree to infer STL formulas to classify behaviors of a given system. The proposed approaches also work for non-separable data by optimizing the worst-case robustness in inferring an STL formula. Finally, we evaluate the performance of the proposed algorithms in two case studies, where the proposed algorithms show reductions in the computation time by up to four orders of magnitude in comparison with the sampling-based baseline algorithms (for a dataset with 800 sampled trajectories in total).
PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains
Feb 24, 2021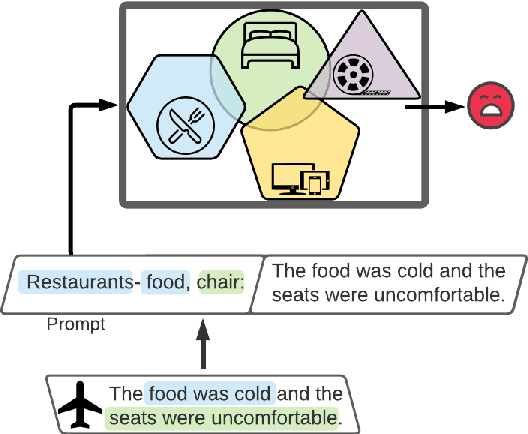
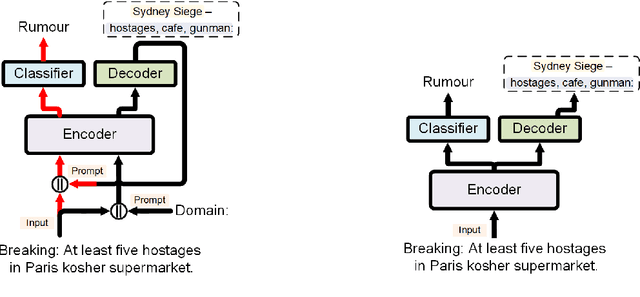
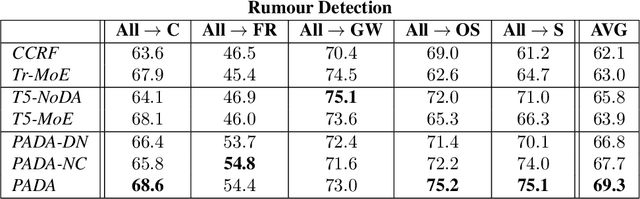
Natural Language Processing algorithms have made incredible progress recently, but they still struggle when applied to out-of-distribution examples. In this paper, we address a very challenging and previously underexplored version of this domain adaptation problem. In our setup an algorithm is trained on several source domains, and then applied to examples from an unseen domain that is unknown at training time. Particularly, no examples, labeled or unlabeled, or any other knowledge about the target domain are available to the algorithm at training time. We present PADA: A Prompt-based Autoregressive Domain Adaptation algorithm, based on the T5 model. Given a test example, PADA first generates a unique prompt and then, conditioned on this prompt, labels the example with respect to the NLP task. The prompt is a sequence of unrestricted length, consisting of pre-defined Domain Related Features (DRFs) that characterize each of the source domains. Intuitively, the prompt is a unique signature that maps the test example to the semantic space spanned by the source domains. In experiments with two tasks: Rumour Detection and Multi-Genre Natural Language Inference (MNLI), for a total of 10 multi-source adaptation scenarios, PADA strongly outperforms state-of-the-art approaches and additional strong baselines.
AI-enabled Automation for Completeness Checking of Privacy Policies
Jun 10, 2021
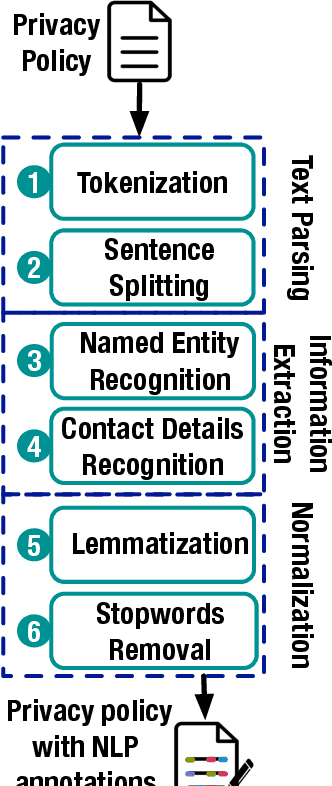
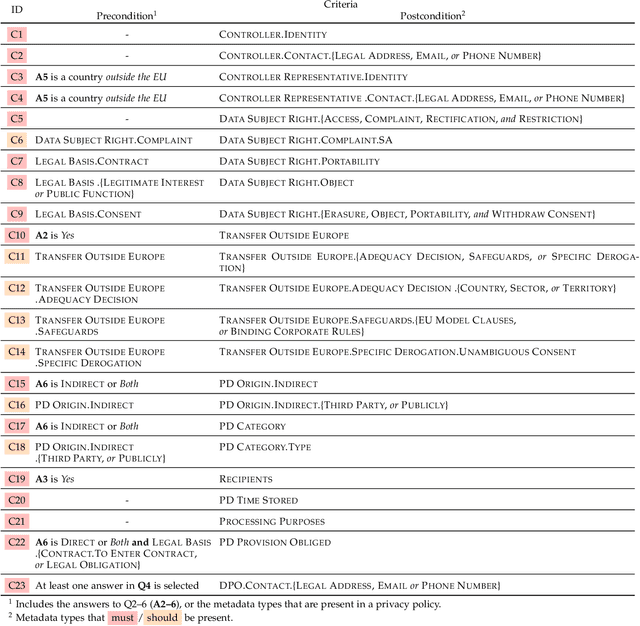
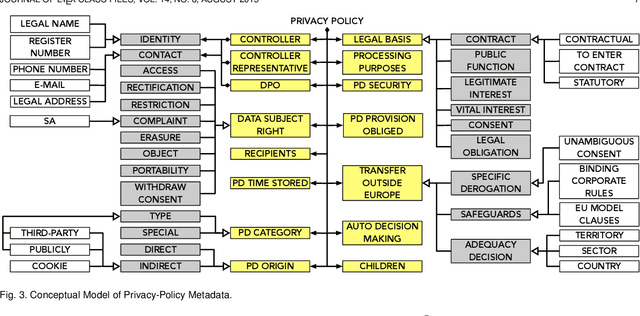
Technological advances in information sharing have raised concerns about data protection. Privacy policies contain privacy-related requirements about how the personal data of individuals will be handled by an organization or a software system (e.g., a web service or an app). In Europe, privacy policies are subject to compliance with the General Data Protection Regulation (GDPR). A prerequisite for GDPR compliance checking is to verify whether the content of a privacy policy is complete according to the provisions of GDPR. Incomplete privacy policies might result in large fines on violating organization as well as incomplete privacy-related software specifications. Manual completeness checking is both time-consuming and error-prone. In this paper, we propose AI-based automation for the completeness checking of privacy policies. Through systematic qualitative methods, we first build two artifacts to characterize the privacy-related provisions of GDPR, namely a conceptual model and a set of completeness criteria. Then, we develop an automated solution on top of these artifacts by leveraging a combination of natural language processing and supervised machine learning. Specifically, we identify the GDPR-relevant information content in privacy policies and subsequently check them against the completeness criteria. To evaluate our approach, we collected 234 real privacy policies from the fund industry. Over a set of 48 unseen privacy policies, our approach detected 300 of the total of 334 violations of some completeness criteria correctly, while producing 23 false positives. The approach thus has a precision of 92.9% and recall of 89.8%. Compared to a baseline that applies keyword search only, our approach results in an improvement of 24.5% in precision and 38% in recall.
Towards Discovery and Attribution of Open-world GAN Generated Images
May 10, 2021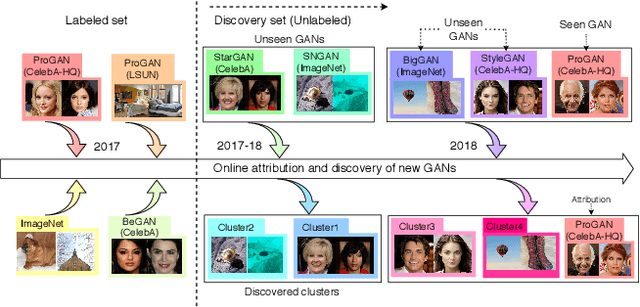

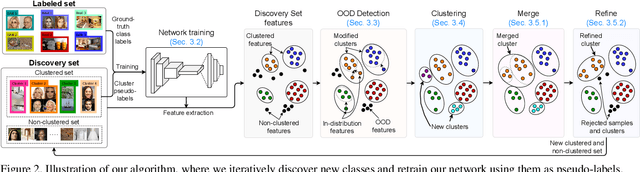
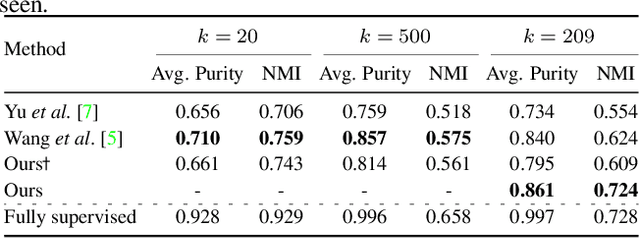
With the recent progress in Generative Adversarial Networks (GANs), it is imperative for media and visual forensics to develop detectors which can identify and attribute images to the model generating them. Existing works have shown to attribute images to their corresponding GAN sources with high accuracy. However, these works are limited to a closed set scenario, failing to generalize to GANs unseen during train time and are therefore, not scalable with a steady influx of new GANs. We present an iterative algorithm for discovering images generated from previously unseen GANs by exploiting the fact that all GANs leave distinct fingerprints on their generated images. Our algorithm consists of multiple components including network training, out-of-distribution detection, clustering, merge and refine steps. Through extensive experiments, we show that our algorithm discovers unseen GANs with high accuracy and also generalizes to GANs trained on unseen real datasets. We additionally apply our algorithm to attribution and discovery of GANs in an online fashion as well as to the more standard task of real/fake detection. Our experiments demonstrate the effectiveness of our approach to discover new GANs and can be used in an open-world setup.
Deep Learning for Fast and Reliable Initial Access in AI-Driven 6G mmWave Networks
Jan 06, 2021
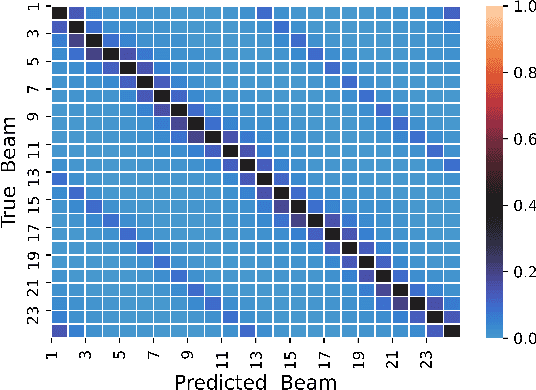
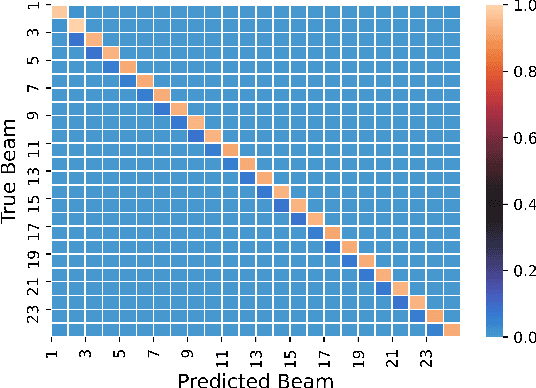
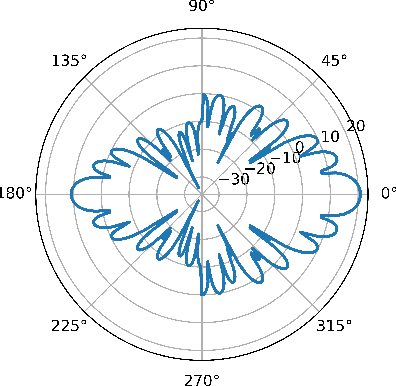
We present DeepIA, a deep neural network (DNN) framework for enabling fast and reliable initial access for AI-driven beyond 5G and 6G millimeter (mmWave) networks. DeepIA reduces the beam sweep time compared to a conventional exhaustive search-based IA process by utilizing only a subset of the available beams. DeepIA maps received signal strengths (RSSs) obtained from a subset of beams to the beam that is best oriented to the receiver. In both line of sight (LoS) and non-line of sight (NLoS) conditions, DeepIA reduces the IA time and outperforms the conventional IA's beam prediction accuracy. We show that the beam prediction accuracy of DeepIA saturates with the number of beams used for IA and depends on the particular selection of the beams. In LoS conditions, the selection of the beams is consequential and improves the accuracy by up to 70%. In NLoS situations, it improves accuracy by up to 35%. We find that, averaging multiple RSS snapshots further reduces the number of beams needed and achieves more than 95% accuracy in both LoS and NLoS conditions. Finally, we evaluate the beam prediction time of DeepIA through embedded hardware implementation and show the improvement over the conventional beam sweeping.