 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robotic Inspection and 3D GPR-based Reconstruction for Underground Utilities
Jun 03, 2021


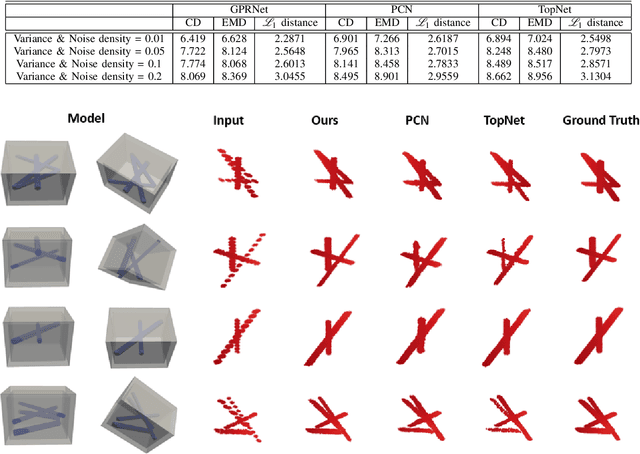
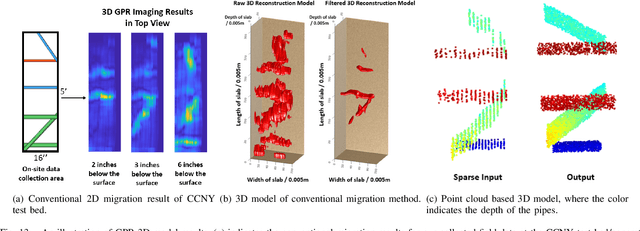
Ground Penetrating Radar (GPR) is an effective non-destructive evaluation (NDE) device for inspecting and surveying subsurface objects (i.e., rebars, utility pipes) in complex environments. However, the current practice for GPR data collection requires a human inspector to move a GPR cart along pre-marked grid lines and record the GPR data in both X and Y directions for post-processing by 3D GPR imaging software. It is time-consuming and tedious work to survey a large area. Furthermore, identifying the subsurface targets depends on the knowledge of an experienced engineer, who has to make manual and subjective interpretation that limits the GPR applications, especially in large-scale scenarios. In addition, the current GPR imaging technology is not intuitive, and not for normal users to understand, and not friendly to visualize. To address the above challenges, this paper presents a novel robotic system to collect GPR data, interpret GPR data, localize the underground utilities, reconstruct and visualize the underground objects' dense point cloud model in a user-friendly manner. This system is composed of three modules: 1) a vision-aided Omni-directional robotic data collection platform, which enables the GPR antenna to scan the target area freely with an arbitrary trajectory while using a visual-inertial-based positioning module tags the GPR measurements with positioning information; 2) a deep neural network (DNN) migration module to interpret the raw GPR B-scan image into a cross-section of object model; 3) a DNN-based 3D reconstruction method, i.e., GPRNet, to generate underground utility model represented as fine 3D point cloud. Comparative studies on synthetic and field GPR raw data with various incompleteness and noise are performed.
Polynomial Time Algorithms for Dual Volume Sampling
Nov 16, 2017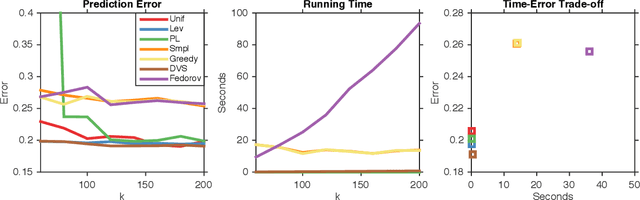
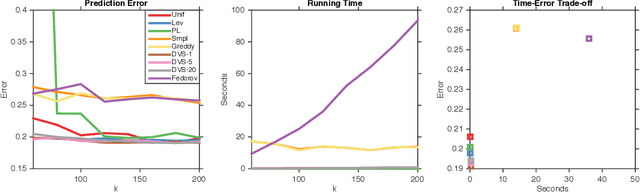
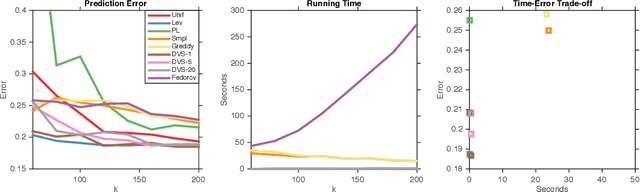
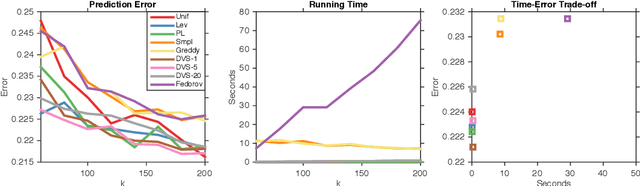
We study dual volume sampling, a method for selecting k columns from an n x m short and wide matrix (n <= k <= m) such that the probability of selection is proportional to the volume spanned by the rows of the induced submatrix. This method was proposed by Avron and Boutsidis (2013), who showed it to be a promising method for column subset selection and its multiple applications. However, its wider adoption has been hampered by the lack of polynomial time sampling algorithms. We remove this hindrance by developing an exact (randomized) polynomial time sampling algorithm as well as its derandomization. Thereafter, we study dual volume sampling via the theory of real stable polynomials and prove that its distribution satisfies the "Strong Rayleigh" property. This result has numerous consequences, including a provably fast-mixing Markov chain sampler that makes dual volume sampling much more attractive to practitioners. This sampler is closely related to classical algorithms for popular experimental design methods that are to date lacking theoretical analysis but are known to empirically work well.
Learning Weakly Convex Sets in Metric Spaces
May 10, 2021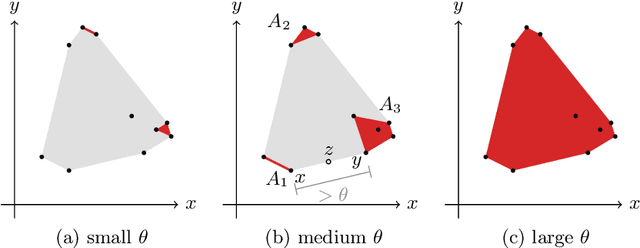
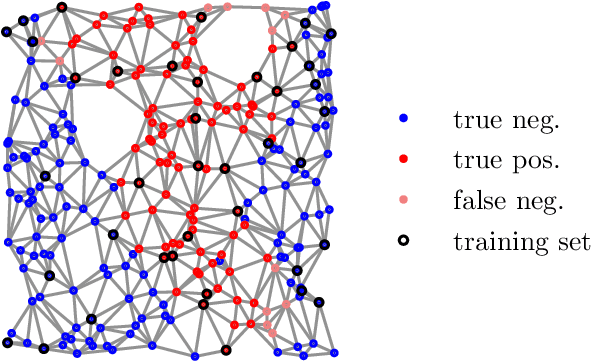
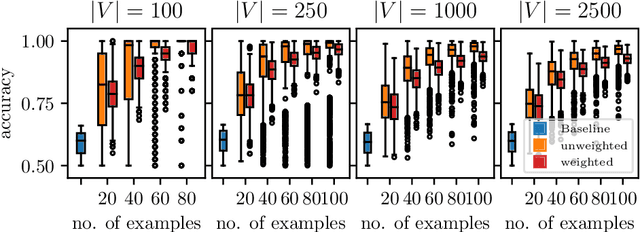
We introduce the notion of weak convexity in metric spaces, a generalization of ordinary convexity commonly used in machine learning. It is shown that weakly convex sets can be characterized by a closure operator and have a unique decomposition into a set of pairwise disjoint connected blocks. We give two generic efficient algorithms, an extensional and an intensional one for learning weakly convex concepts and study their formal properties. Our experimental results concerning vertex classification clearly demonstrate the excellent predictive performance of the extensional algorithm. Two non-trivial applications of the intensional algorithm to polynomial PAC-learnability are presented. The first one deals with learning $k$-convex Boolean functions, which are already known to be efficiently PAC-learnable. It is shown how to derive this positive result in a fairly easy way by the generic intensional algorithm. The second one is concerned with the Euclidean space equipped with the Manhattan distance. For this metric space, weakly convex sets are a union of pairwise disjoint axis-aligned hyperrectangles. We show that a weakly convex set that is consistent with a set of examples and contains a minimum number of hyperrectangles can be found in polynomial time. In contrast, this problem is known to be NP-complete if the hyperrectangles may be overlapping.
Automated Biodesign Engineering by Abductive Meta-Interpretive Learning
May 17, 2021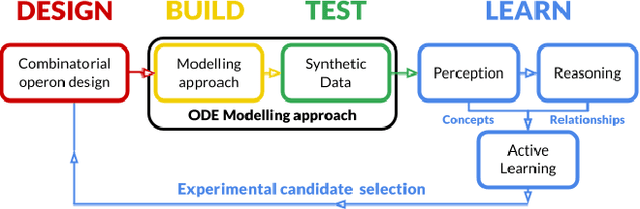
The application of Artificial Intelligence (AI) to synthetic biology will provide the foundation for the creation of a high throughput automated platform for genetic design, in which a learning machine is used to iteratively optimise the system through a design-build-test-learn (DBTL) cycle. However, mainstream machine learning techniques represented by deep learning lacks the capability to represent relational knowledge and requires prodigious amounts of annotated training data. These drawbacks strongly restrict AI's role in synthetic biology in which experimentation is inherently resource and time intensive. In this work, we propose an automated biodesign engineering framework empowered by Abductive Meta-Interpretive Learning ($Meta_{Abd}$), a novel machine learning approach that combines symbolic and sub-symbolic machine learning, to further enhance the DBTL cycle by enabling the learning machine to 1) exploit domain knowledge and learn human-interpretable models that are expressed by formal languages such as first-order logic; 2) simultaneously optimise the structure and parameters of the models to make accurate numerical predictions; 3) reduce the cost of experiments and effort on data annotation by actively generating hypotheses and examples. To verify the effectiveness of $Meta_{Abd}$, we have modelled a synthetic dataset for the production of proteins from a three gene operon in a microbial host, which represents a common synthetic biology problem.
Curious Representation Learning for Embodied Intelligence
May 03, 2021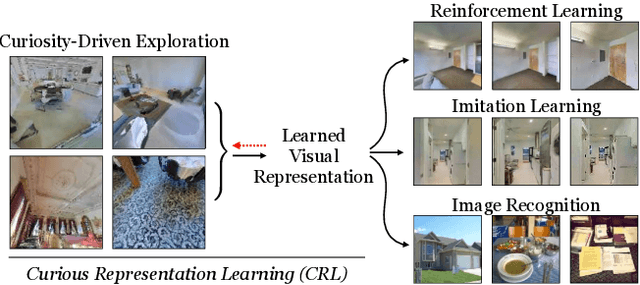
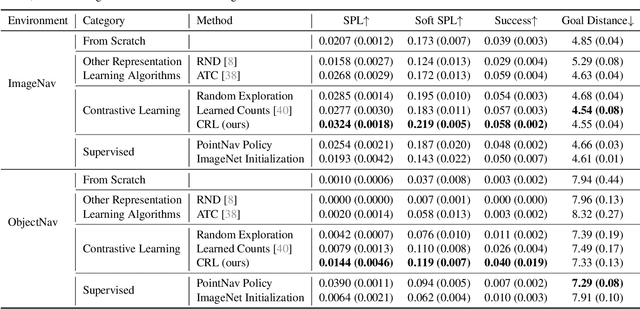
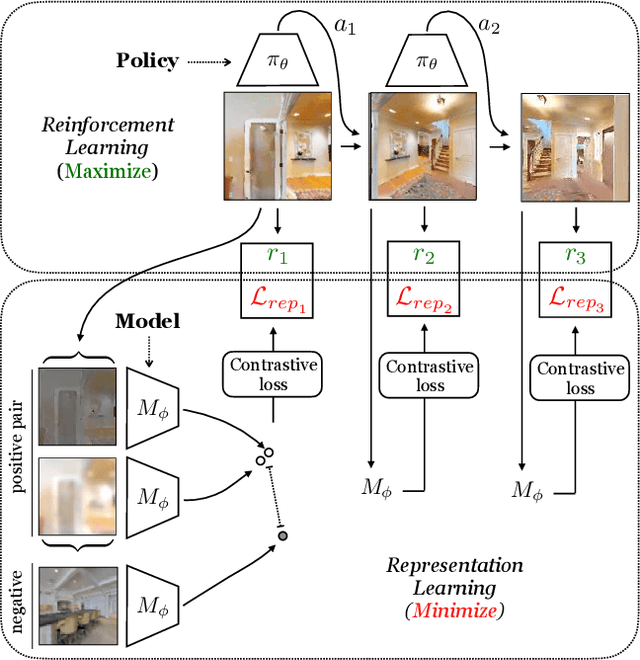

Self-supervised representation learning has achieved remarkable success in recent years. By subverting the need for supervised labels, such approaches are able to utilize the numerous unlabeled images that exist on the Internet and in photographic datasets. Yet to build truly intelligent agents, we must construct representation learning algorithms that can learn not only from datasets but also learn from environments. An agent in a natural environment will not typically be fed curated data. Instead, it must explore its environment to acquire the data it will learn from. We propose a framework, curious representation learning (CRL), which jointly learns a reinforcement learning policy and a visual representation model. The policy is trained to maximize the error of the representation learner, and in doing so is incentivized to explore its environment. At the same time, the learned representation becomes stronger and stronger as the policy feeds it ever harder data to learn from. Our learned representations enable promising transfer to downstream navigation tasks, performing better than or comparably to ImageNet pretraining without using any supervision at all. In addition, despite being trained in simulation, our learned representations can obtain interpretable results on real images.
Linear Time Computation of Moments in Sum-Product Networks
Nov 05, 2017
Bayesian online algorithms for Sum-Product Networks (SPNs) need to update their posterior distribution after seeing one single additional instance. To do so, they must compute moments of the model parameters under this distribution. The best existing method for computing such moments scales quadratically in the size of the SPN, although it scales linearly for trees. This unfortunate scaling makes Bayesian online algorithms prohibitively expensive, except for small or tree-structured SPNs. We propose an optimal linear-time algorithm that works even when the SPN is a general directed acyclic graph (DAG), which significantly broadens the applicability of Bayesian online algorithms for SPNs. There are three key ingredients in the design and analysis of our algorithm: 1). For each edge in the graph, we construct a linear time reduction from the moment computation problem to a joint inference problem in SPNs. 2). Using the property that each SPN computes a multilinear polynomial, we give an efficient procedure for polynomial evaluation by differentiation without expanding the network that may contain exponentially many monomials. 3). We propose a dynamic programming method to further reduce the computation of the moments of all the edges in the graph from quadratic to linear. We demonstrate the usefulness of our linear time algorithm by applying it to develop a linear time assume density filter (ADF) for SPNs.
Generic Itemset Mining Based on Reinforcement Learning
May 17, 2021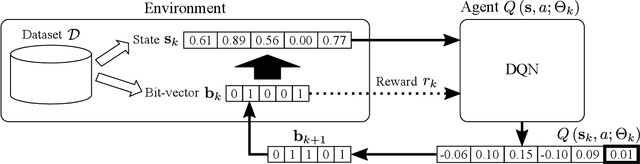

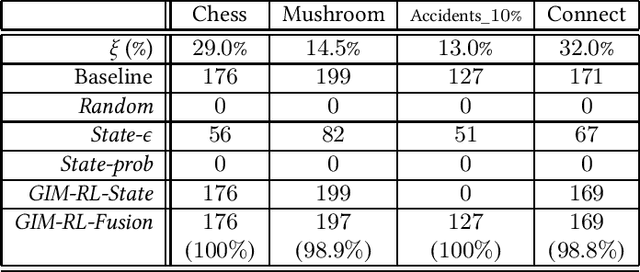
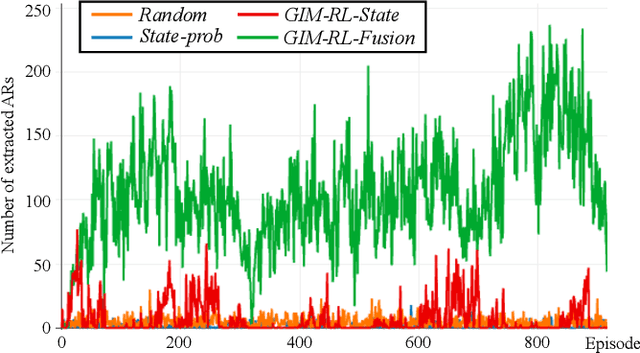
One of the biggest problems in itemset mining is the requirement of developing a data structure or algorithm, every time a user wants to extract a different type of itemsets. To overcome this, we propose a method, called Generic Itemset Mining based on Reinforcement Learning (GIM-RL), that offers a unified framework to train an agent for extracting any type of itemsets. In GIM-RL, the environment formulates iterative steps of extracting a target type of itemsets from a dataset. At each step, an agent performs an action to add or remove an item to or from the current itemset, and then obtains from the environment a reward that represents how relevant the itemset resulting from the action is to the target type. Through numerous trial-and-error steps where various rewards are obtained by diverse actions, the agent is trained to maximise cumulative rewards so that it acquires the optimal action policy for forming as many itemsets of the target type as possible. In this framework, an agent for extracting any type of itemsets can be trained as long as a reward suitable for the type can be defined. The extensive experiments on mining high utility itemsets, frequent itemsets and association rules show the general effectiveness and one remarkable potential (agent transfer) of GIM-RL. We hope that GIM-RL opens a new research direction towards learning-based itemset mining.
Online Adversarial Purification based on Self-Supervision
Jan 23, 2021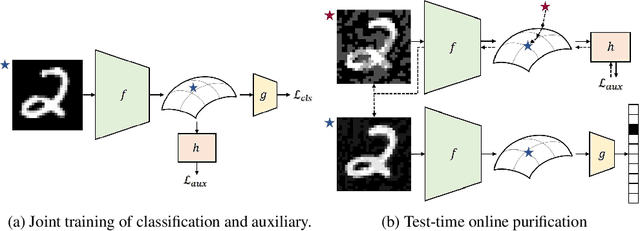
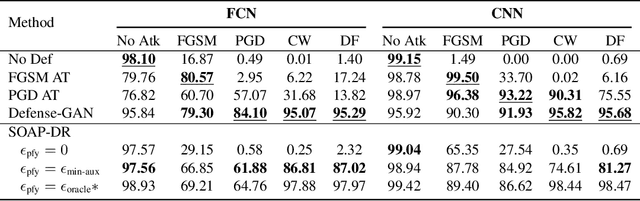

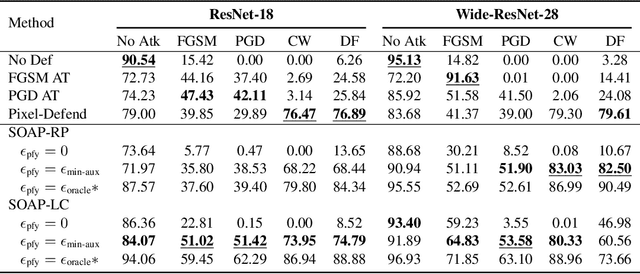
Deep neural networks are known to be vulnerable to adversarial examples, where a perturbation in the input space leads to an amplified shift in the latent network representation. In this paper, we combine canonical supervised learning with self-supervised representation learning, and present Self-supervised Online Adversarial Purification (SOAP), a novel defense strategy that uses a self-supervised loss to purify adversarial examples at test-time. Our approach leverages the label-independent nature of self-supervised signals and counters the adversarial perturbation with respect to the self-supervised tasks. SOAP yields competitive robust accuracy against state-of-the-art adversarial training and purification methods, with considerably less training complexity. In addition, our approach is robust even when adversaries are given knowledge of the purification defense strategy. To the best of our knowledge, our paper is the first that generalizes the idea of using self-supervised signals to perform online test-time purification.
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
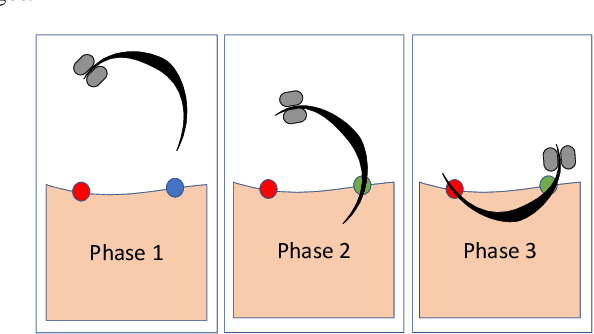
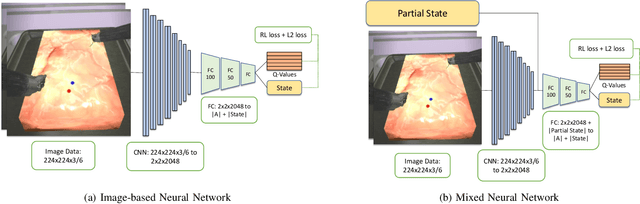
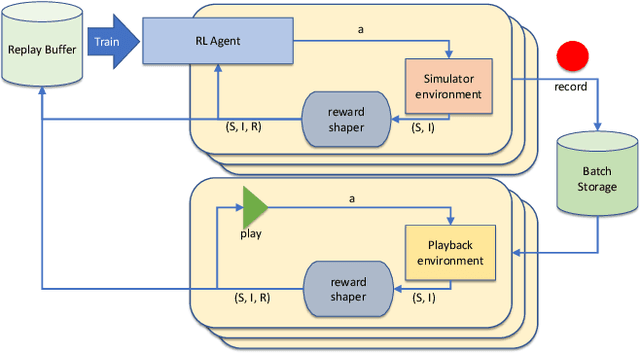
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.
Sparse Gaussian process Audio Source Separation Using Spectrum Priors in the Time-Domain
Nov 05, 2018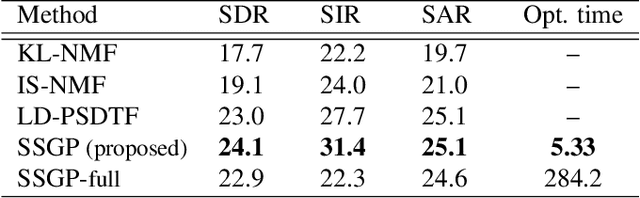
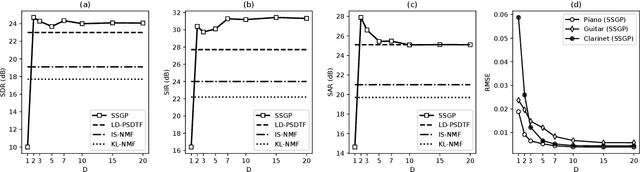
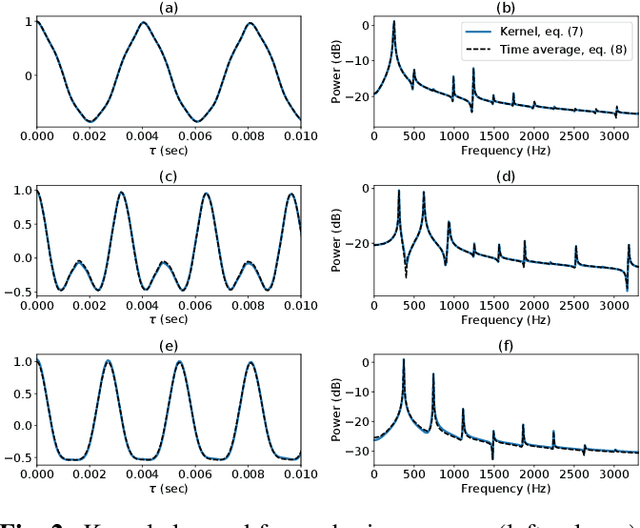
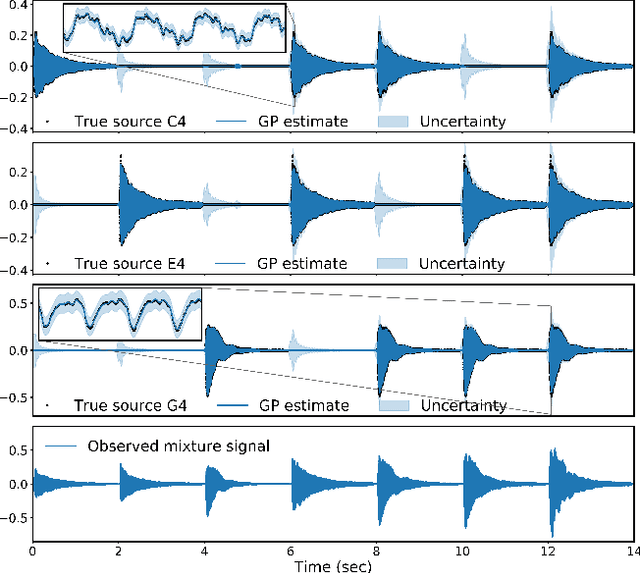
Gaussian process (GP) audio source separation is a time-domain approach that circumvents the inherent phase approximation issue of spectrogram based methods. Furthermore, through its kernel, GPs elegantly incorporate prior knowledge about the sources into the separation model. Despite these compelling advantages, the computational complexity of GP inference scales cubically with the number of audio samples. As a result, source separation GP models have been restricted to the analysis of short audio frames. We introduce an efficient application of GPs to time-domain audio source separation, without compromising performance. For this purpose, we used GP regression, together with spectral mixture kernels, and variational sparse GPs. We compared our method with LD-PSDTF (positive semi-definite tensor factorization), KL-NMF (Kullback-Leibler non-negative matrix factorization), and IS-NMF (Itakura-Saito NMF). Results show that the proposed method outperforms these techniques.