 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
COVID-19 Detection from Chest X-ray Images using Imprinted Weights Approach
May 04, 2021

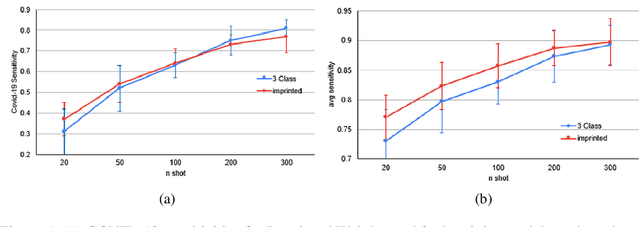
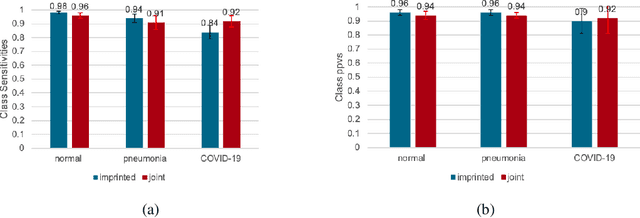
The COVID-19 pandemic has had devastating effects on the well-being of the global population. The pandemic has been so prominent partly due to the high infection rate of the virus and its variants. In response, one of the most effective ways to stop infection is rapid diagnosis. The main-stream screening method, reverse transcription-polymerase chain reaction (RT-PCR), is time-consuming, laborious and in short supply. Chest radiography is an alternative screening method for the COVID-19 and computer-aided diagnosis (CAD) has proven to be a viable solution at low cost and with fast speed; however, one of the challenges in training the CAD models is the limited number of training data, especially at the onset of the pandemic. This becomes outstanding precisely when the quick and cheap type of diagnosis is critically needed for flattening the infection curve. To address this challenge, we propose the use of a low-shot learning approach named imprinted weights, taking advantage of the abundance of samples from known illnesses such as pneumonia to improve the detection performance on COVID-19.
A Formal Framework for Reasoning about Agents' Independence in Self-organizing Multi-agent Systems
May 26, 2021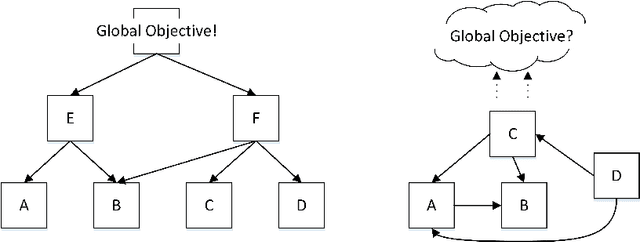
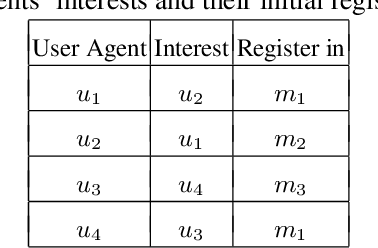
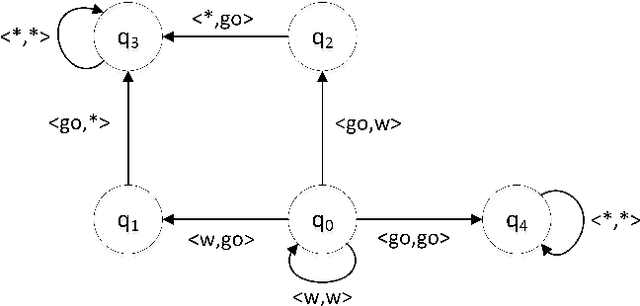
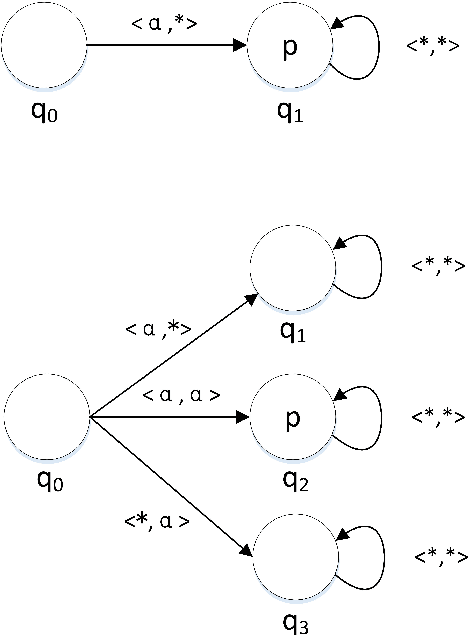
Self-organization is a process where a stable pattern is formed by the cooperative behavior between parts of an initially disordered system without external control or influence. It has been introduced to multi-agent systems as an internal control process or mechanism to solve difficult problems spontaneously. However, because a self-organizing multi-agent system has autonomous agents and local interactions between them, it is difficult to predict the behavior of the system from the behavior of the local agents we design. This paper proposes a logic-based framework of self-organizing multi-agent systems, where agents interact with each other by following their prescribed local rules. The dependence relation between coalitions of agents regarding their contributions to the global behavior of the system is reasoned about from the structural and semantic perspectives. We show that the computational complexity of verifying such a self-organizing multi-agent system is in exponential time. We then combine our framework with graph theory to decompose a system into different coalitions located in different layers, which allows us to verify agents' full contributions more efficiently. The resulting information about agents' full contributions allows us to understand the complex link between local agent behavior and system level behavior in a self-organizing multi-agent system. Finally, we show how we can use our framework to model a constraint satisfaction problem.
On the Power of Preconditioning in Sparse Linear Regression
Jun 17, 2021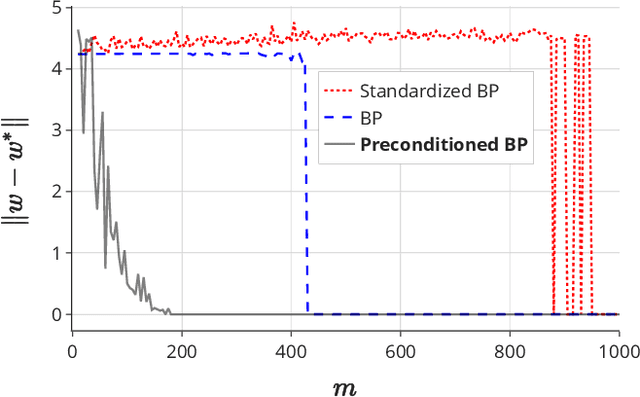
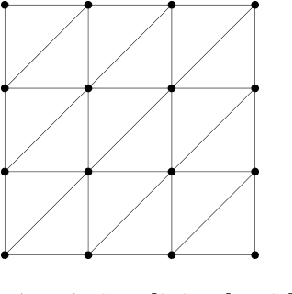
Sparse linear regression is a fundamental problem in high-dimensional statistics, but strikingly little is known about how to efficiently solve it without restrictive conditions on the design matrix. We consider the (correlated) random design setting, where the covariates are independently drawn from a multivariate Gaussian $N(0,\Sigma)$ with $\Sigma : n \times n$, and seek estimators $\hat{w}$ minimizing $(\hat{w}-w^*)^T\Sigma(\hat{w}-w^*)$, where $w^*$ is the $k$-sparse ground truth. Information theoretically, one can achieve strong error bounds with $O(k \log n)$ samples for arbitrary $\Sigma$ and $w^*$; however, no efficient algorithms are known to match these guarantees even with $o(n)$ samples, without further assumptions on $\Sigma$ or $w^*$. As far as hardness, computational lower bounds are only known with worst-case design matrices. Random-design instances are known which are hard for the Lasso, but these instances can generally be solved by Lasso after a simple change-of-basis (i.e. preconditioning). In this work, we give upper and lower bounds clarifying the power of preconditioning in sparse linear regression. First, we show that the preconditioned Lasso can solve a large class of sparse linear regression problems nearly optimally: it succeeds whenever the dependency structure of the covariates, in the sense of the Markov property, has low treewidth -- even if $\Sigma$ is highly ill-conditioned. Second, we construct (for the first time) random-design instances which are provably hard for an optimally preconditioned Lasso. In fact, we complete our treewidth classification by proving that for any treewidth-$t$ graph, there exists a Gaussian Markov Random Field on this graph such that the preconditioned Lasso, with any choice of preconditioner, requires $\Omega(t^{1/20})$ samples to recover $O(\log n)$-sparse signals when covariates are drawn from this model.
FlipReID: Closing the Gap between Training and Inference in Person Re-Identification
May 12, 2021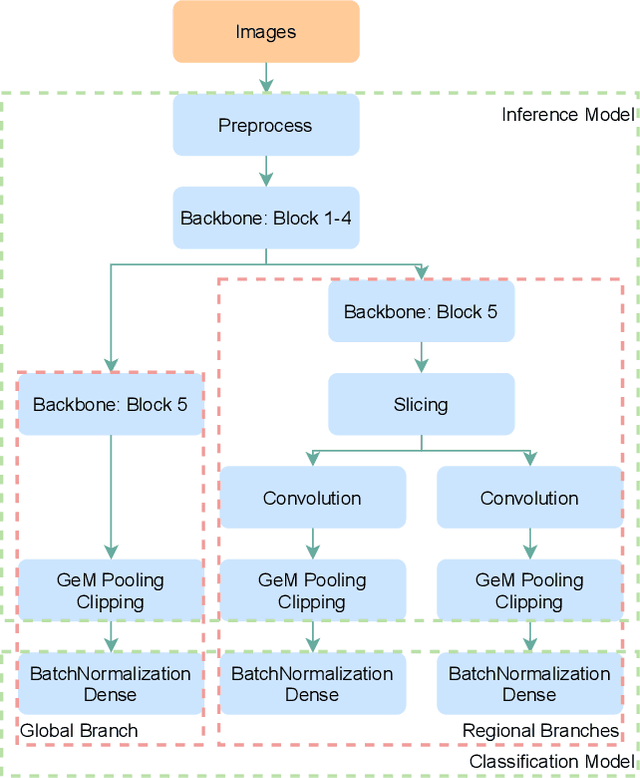
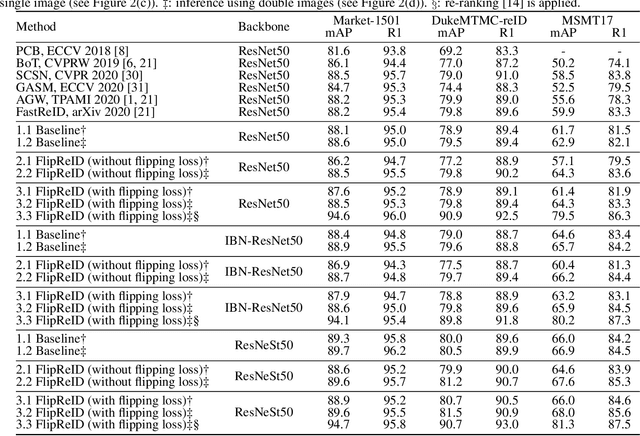
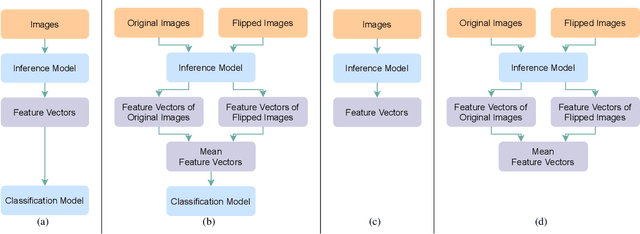
Since neural networks are data-hungry, incorporating data augmentation in training is a widely adopted technique that enlarges datasets and improves generalization. On the other hand, aggregating predictions of multiple augmented samples (i.e., test-time augmentation) could boost performance even further. In the context of person re-identification models, it is common practice to extract embeddings for both the original images and their horizontally flipped variants. The final representation is the mean of the aforementioned feature vectors. However, such scheme results in a gap between training and inference, i.e., the mean feature vectors calculated in inference are not part of the training pipeline. In this study, we devise the FlipReID structure with the flipping loss to address this issue. More specifically, models using the FlipReID structure are trained on the original images and the flipped images simultaneously, and incorporating the flipping loss minimizes the mean squared error between feature vectors of corresponding image pairs. Extensive experiments show that our method brings consistent improvements. In particular, we set a new record for MSMT17 which is the largest person re-identification dataset. The source code is available at https://github.com/nixingyang/FlipReID.
Learning to Localize Using a LiDAR Intensity Map
Dec 20, 2020
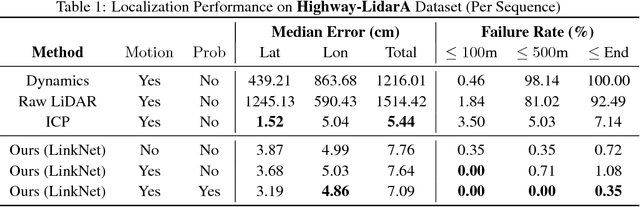
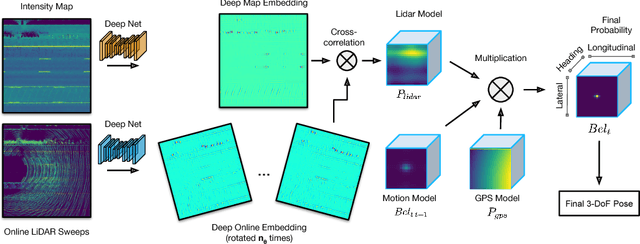

In this paper we propose a real-time, calibration-agnostic and effective localization system for self-driving cars. Our method learns to embed the online LiDAR sweeps and intensity map into a joint deep embedding space. Localization is then conducted through an efficient convolutional matching between the embeddings. Our full system can operate in real-time at 15Hz while achieving centimeter level accuracy across different LiDAR sensors and environments. Our experiments illustrate the performance of the proposed approach over a large-scale dataset consisting of over 4000km of driving.
* 12 pages, 7 figures, 5 tables; Presented at the 2nd Conference on Robot Learning (CoRL), 2018
Poisoning the Unlabeled Dataset of Semi-Supervised Learning
May 04, 2021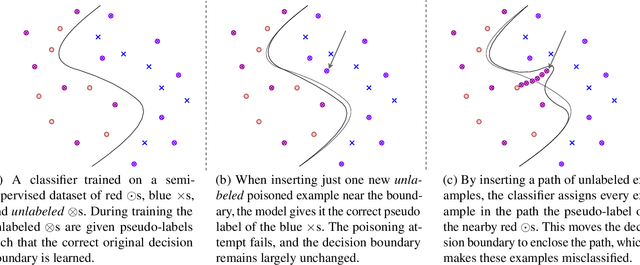

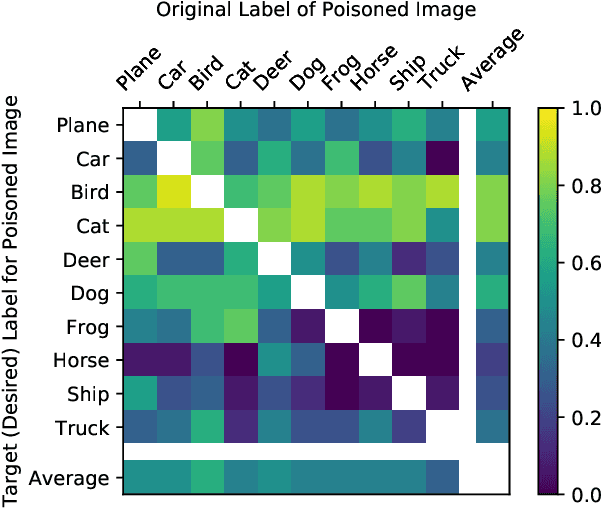
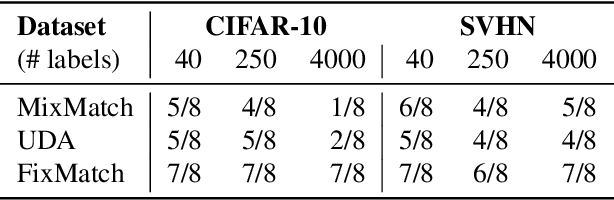
Semi-supervised machine learning models learn from a (small) set of labeled training examples, and a (large) set of unlabeled training examples. State-of-the-art models can reach within a few percentage points of fully-supervised training, while requiring 100x less labeled data. We study a new class of vulnerabilities: poisoning attacks that modify the unlabeled dataset. In order to be useful, unlabeled datasets are given strictly less review than labeled datasets, and adversaries can therefore poison them easily. By inserting maliciously-crafted unlabeled examples totaling just 0.1% of the dataset size, we can manipulate a model trained on this poisoned dataset to misclassify arbitrary examples at test time (as any desired label). Our attacks are highly effective across datasets and semi-supervised learning methods. We find that more accurate methods (thus more likely to be used) are significantly more vulnerable to poisoning attacks, and as such better training methods are unlikely to prevent this attack. To counter this we explore the space of defenses, and propose two methods that mitigate our attack.
Reservoir Stack Machines
May 04, 2021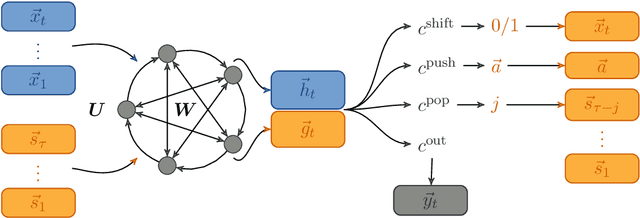

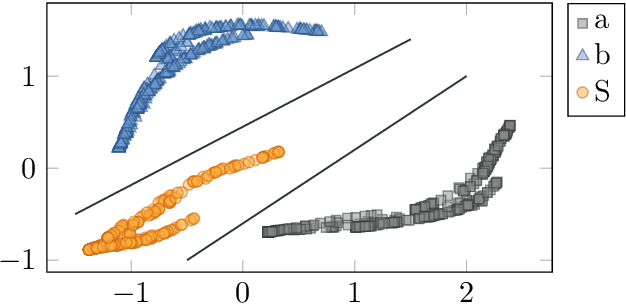
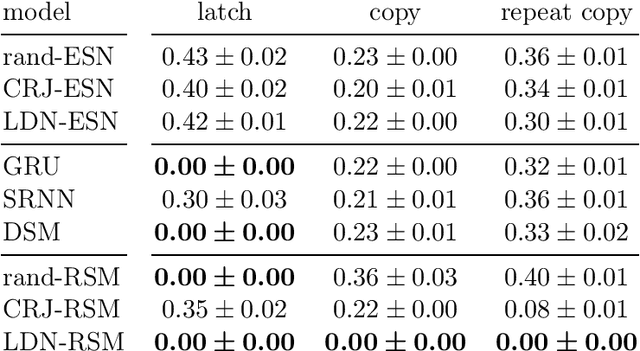
Memory-augmented neural networks equip a recurrent neural network with an explicit memory to support tasks that require information storage without interference over long times. A key motivation for such research is to perform classic computation tasks, such as parsing. However, memory-augmented neural networks are notoriously hard to train, requiring many backpropagation epochs and a lot of data. In this paper, we introduce the reservoir stack machine, a model which can provably recognize all deterministic context-free languages and circumvents the training problem by training only the output layer of a recurrent net and employing auxiliary information during training about the desired interaction with a stack. In our experiments, we validate the reservoir stack machine against deep and shallow networks from the literature on three benchmark tasks for Neural Turing machines and six deterministic context-free languages. Our results show that the reservoir stack machine achieves zero error, even on test sequences longer than the training data, requiring only a few seconds of training time and 100 training sequences.
Low Complexity Joint Impairment Mitigation of I/Q Modulator and PA Using Neural Networks
Apr 06, 2021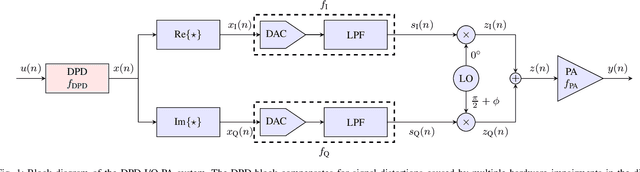
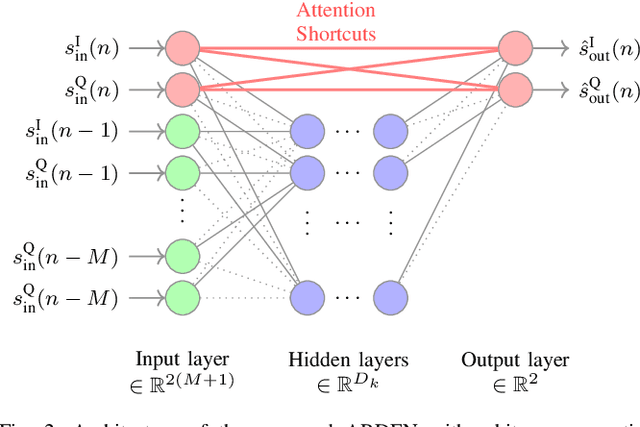
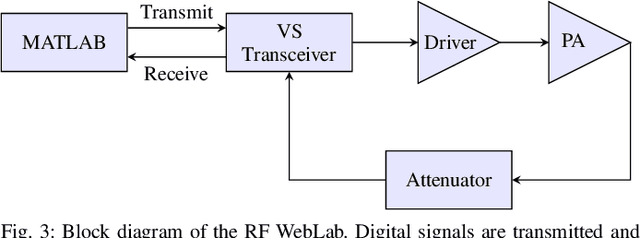
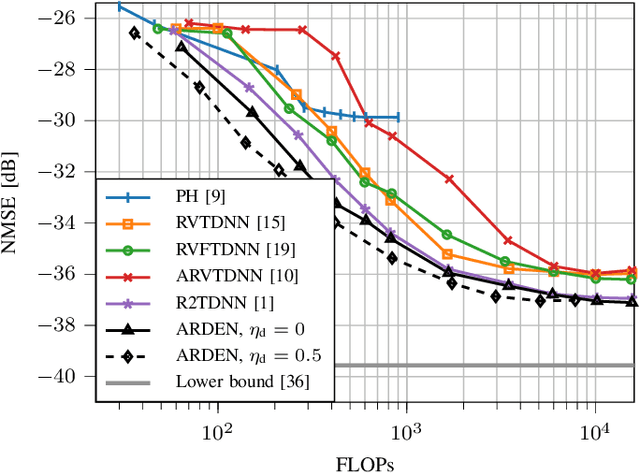
Neural networks (NNs) for multiple hardware impairments mitigation of a realistic direct conversion transmitter are impractical due to high computational complexity. We propose two methods to reduce complexity without significant performance penalty. We first propose a novel attention residual learning NN, referred to as attention residual real-valued time-delay neural network (ARDEN), where trainable neuron-wise shortcut connections between the input and output layers allow to keep the attention always active. Furthermore, we implement a NN pruning algorithm that gradually removes connections corresponding to minimal weight magnitudes in each layer. Simulation and experimental results show that ARDEN with pruning achieves better performance for compensating frequency-dependent quadrature imbalance and power amplifier nonlinearity than other NN-based and Volterra-based models, while requiring less or similar complexity.
A Resilient and Energy-Aware Task Allocation Framework for Heterogeneous Multi-Robot Systems
May 12, 2021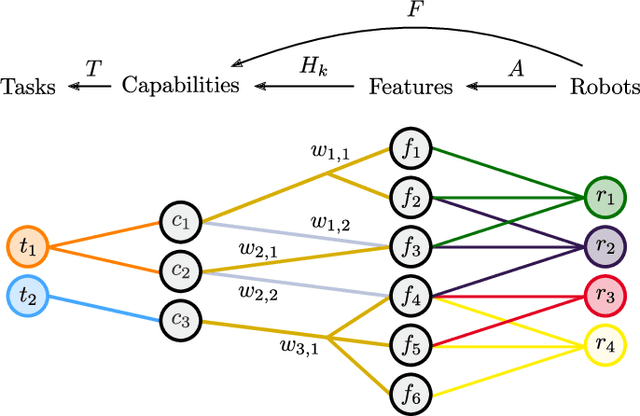
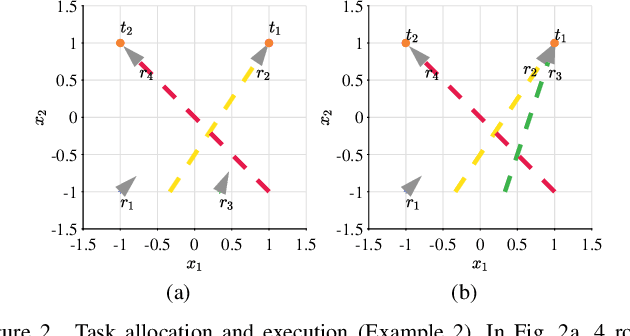
In the context of heterogeneous multi-robot teams deployed for executing multiple tasks, this paper develops an energy-aware framework for allocating tasks to robots in an online fashion. With a primary focus on long-duration autonomy applications, we opt for a survivability-focused approach. Towards this end, the task prioritization and execution -- through which the allocation of tasks to robots is effectively realized -- are encoded as constraints within an optimization problem aimed at minimizing the energy consumed by the robots at each point in time. In this context, an allocation is interpreted as a prioritization of a task over all others by each of the robots. Furthermore, we present a novel framework to represent the heterogeneous capabilities of the robots, by distinguishing between the features available on the robots, and the capabilities enabled by these features. By embedding these descriptions within the optimization problem, we make the framework resilient to situations where environmental conditions make certain features unsuitable to support a capability and when component failures on the robots occur. We demonstrate the efficacy and resilience of the proposed approach in a variety of use-case scenarios, consisting of simulations and real robot experiments.
Improved and efficient inter-vehicle distance estimation using road gradients of both ego and target vehicles
Apr 01, 2021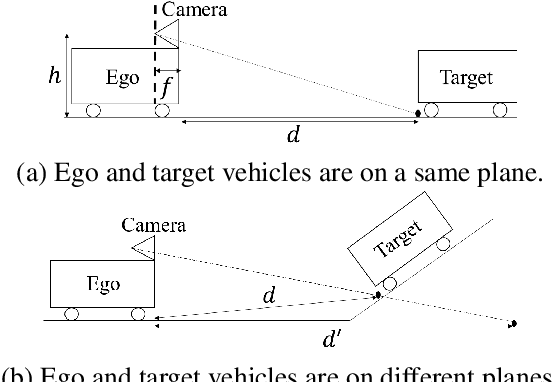
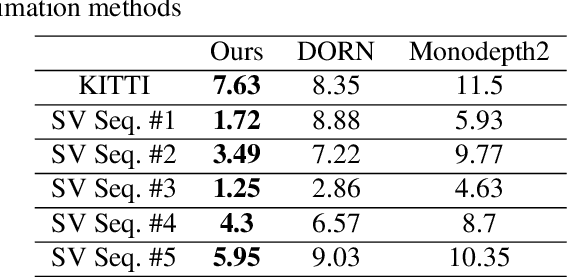
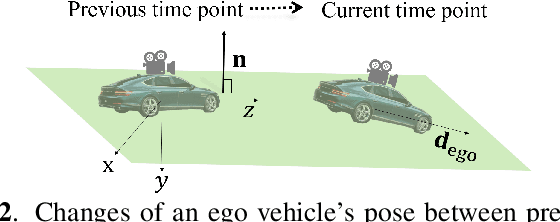

In advanced driver assistant systems and autonomous driving, it is crucial to estimate distances between an ego vehicle and target vehicles. Existing inter-vehicle distance estimation methods assume that the ego and target vehicles drive on a same ground plane. In practical driving environments, however, they may drive on different ground planes. This paper proposes an inter-vehicle distance estimation framework that can consider slope changes of a road forward, by estimating road gradients of \emph{both} ego vehicle and target vehicles and using a 2D object detection deep net. Numerical experiments demonstrate that the proposed method significantly improves the distance estimation accuracy and time complexity, compared to deep learning-based depth estimation methods.