 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accurate and fast matrix factorization for low-rank learning
Apr 21, 2021
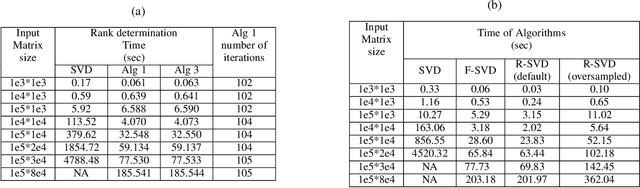
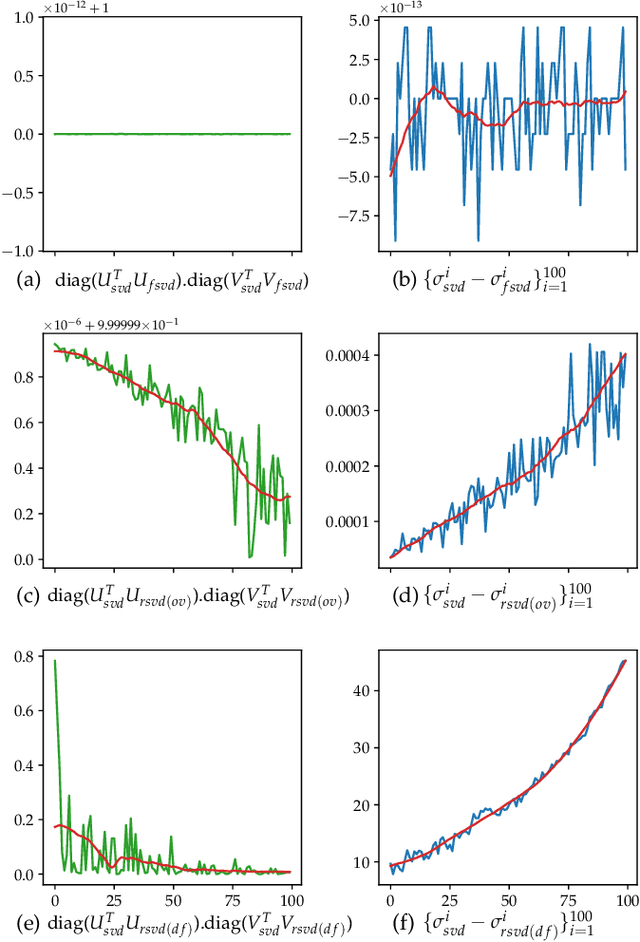
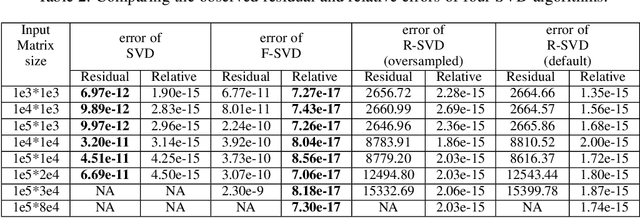
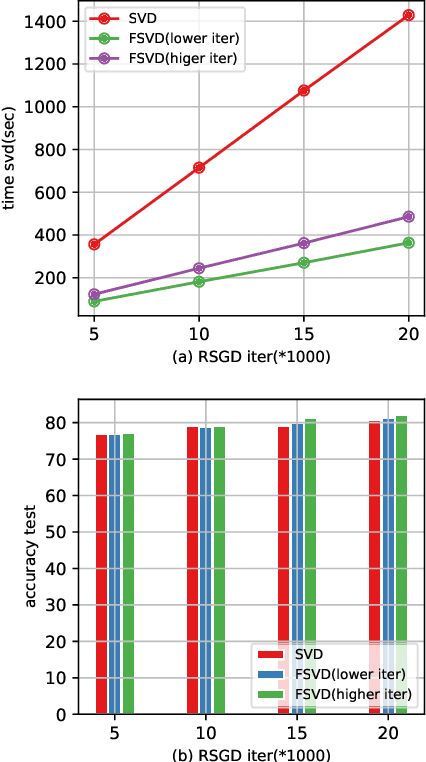
In this paper we tackle two important challenges related to the accurate partial singular value decomposition (SVD) and numerical rank estimation of a huge matrix to use in low-rank learning problems in a fast way. We use the concepts of Krylov subspaces such as the Golub-Kahan bidiagonalization process as well as Ritz vectors to achieve these goals. Our experiments identify various advantages of the proposed methods compared to traditional and randomized SVD (R-SVD) methods with respect to the accuracy of the singular values and corresponding singular vectors computed in a similar execution time. The proposed methods are appropriate for applications involving huge matrices where accuracy in all spectrum of the desired singular values, and also all of corresponding singular vectors is essential. We evaluate our method in the real application of Riemannian similarity learning (RSL) between two various image datasets of MNIST and USPS.
Generative modeling of spatio-temporal weather patterns with extreme event conditioning
Apr 26, 2021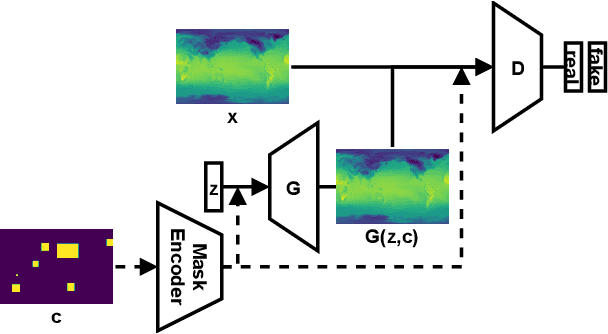
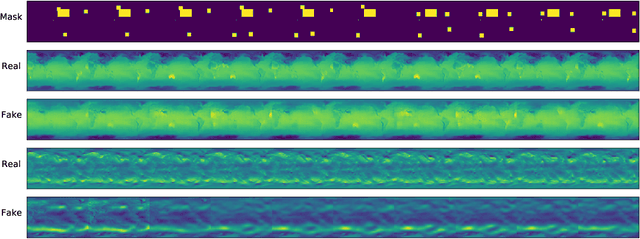
Deep generative models are increasingly used to gain insights in the geospatial data domain, e.g., for climate data. However, most existing approaches work with temporal snapshots or assume 1D time-series; few are able to capture spatio-temporal processes simultaneously. Beyond this, Earth-systems data often exhibit highly irregular and complex patterns, for example caused by extreme weather events. Because of climate change, these phenomena are only increasing in frequency. Here, we proposed a novel GAN-based approach for generating spatio-temporal weather patterns conditioned on detected extreme events. Our approach augments GAN generator and discriminator with an encoded extreme weather event segmentation mask. These segmentation masks can be created from raw input using existing event detection frameworks. As such, our approach is highly modular and can be combined with custom GAN architectures. We highlight the applicability of our proposed approach in experiments with real-world surface radiation and zonal wind data.
MVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
Apr 21, 2021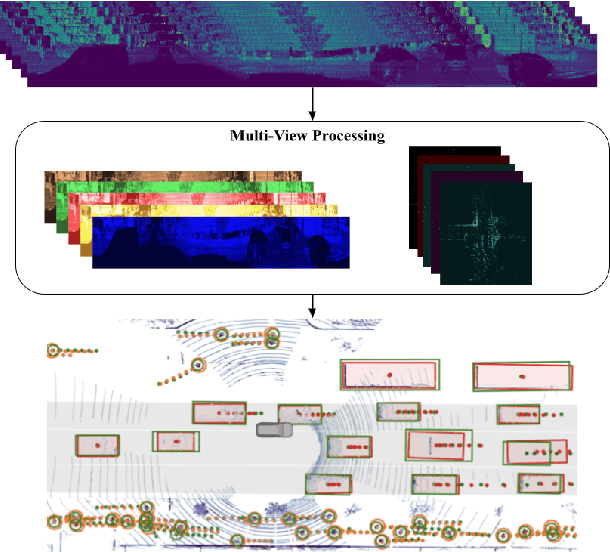
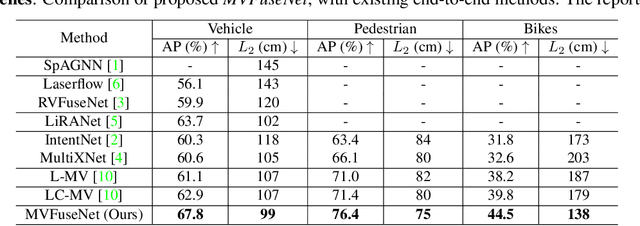
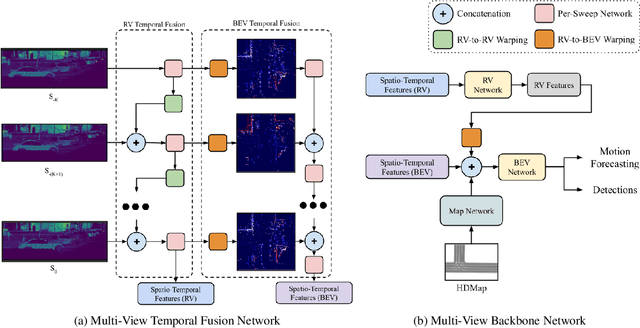
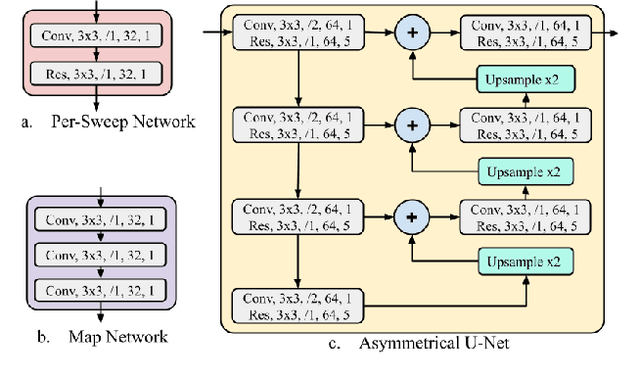
In this work, we propose \textit{MVFuseNet}, a novel end-to-end method for joint object detection and motion forecasting from a temporal sequence of LiDAR data. Most existing methods operate in a single view by projecting data in either range view (RV) or bird's eye view (BEV). In contrast, we propose a method that effectively utilizes both RV and BEV for spatio-temporal feature learning as part of a temporal fusion network as well as for multi-scale feature learning in the backbone network. Further, we propose a novel sequential fusion approach that effectively utilizes multiple views in the temporal fusion network. We show the benefits of our multi-view approach for the tasks of detection and motion forecasting on two large-scale self-driving data sets, achieving state-of-the-art results. Furthermore, we show that MVFusenet scales well to large operating ranges while maintaining real-time performance.
PathBench: A Benchmarking Platform for Classical and Learned Path Planning Algorithms
May 04, 2021



Path planning is a key component in mobile robotics. A wide range of path planning algorithms exist, but few attempts have been made to benchmark the algorithms holistically or unify their interface. Moreover, with the recent advances in deep neural networks, there is an urgent need to facilitate the development and benchmarking of such learning-based planning algorithms. This paper presents PathBench, a platform for developing, visualizing, training, testing, and benchmarking of existing and future, classical and learned 2D and 3D path planning algorithms, while offering support for Robot Oper-ating System (ROS). Many existing path planning algorithms are supported; e.g. A*, wavefront, rapidly-exploring random tree, value iteration networks, gated path planning networks; and integrating new algorithms is easy and clearly specified. We demonstrate the benchmarking capability of PathBench by comparing implemented classical and learned algorithms for metrics, such as path length, success rate, computational time and path deviation. These evaluations are done on built-in PathBench maps and external path planning environments from video games and real world databases. PathBench is open source.
Deep Reinforcement Learning for Haptic Shared Control in Unknown Tasks
Jan 15, 2021
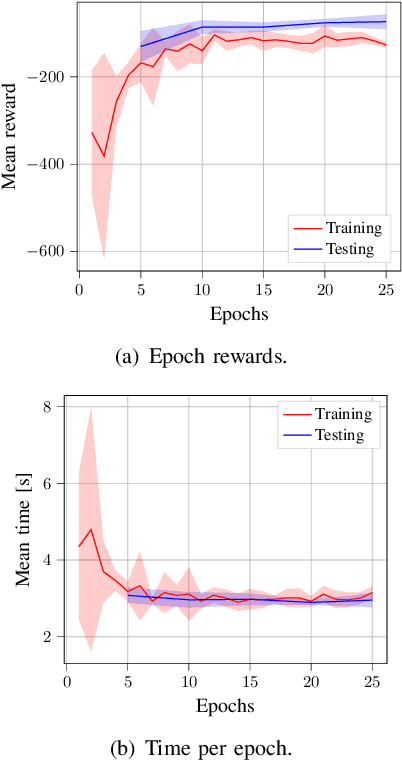
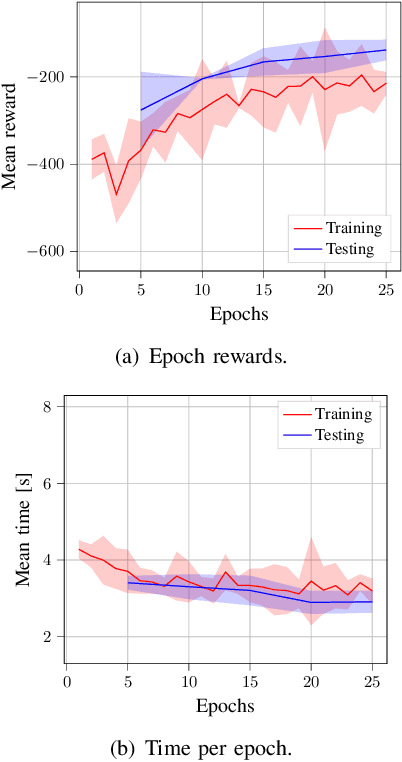
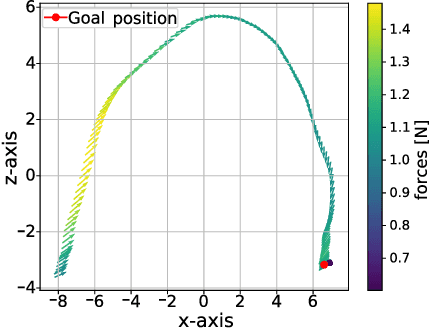
Recent years have shown a growing interest in using haptic shared control (HSC) in teleoperated systems. In HSC, the application of virtual guiding forces decreases the user's control effort and improves execution time in various tasks, presenting a good alternative in comparison with direct teleoperation. HSC, despite demonstrating good performance, opens a new gap: how to design the guiding forces. For this reason, the challenge lies in developing controllers to provide the optimal guiding forces for the tasks that are being performed. This work addresses this challenge by designing a controller based on the deep deterministic policy gradient (DDPG) algorithm to provide the assistance, and a convolutional neural network (CNN) to perform the task detection, called TAHSC (Task Agnostic Haptic Shared Controller). The agent learns to minimize the time it takes the human to execute the desired task, while simultaneously minimizing their resistance to the provided feedback. This resistance thus provides the learning algorithm with information about which direction the human is trying to follow, in this case, the pick-and-place task. Diverse results demonstrate the successful application of the proposed approach by learning custom policies for each user who was asked to test the system. It exhibits stable convergence and aids the user in completing the task with the least amount of time possible.
On the Power of Preconditioning in Sparse Linear Regression
Jun 17, 2021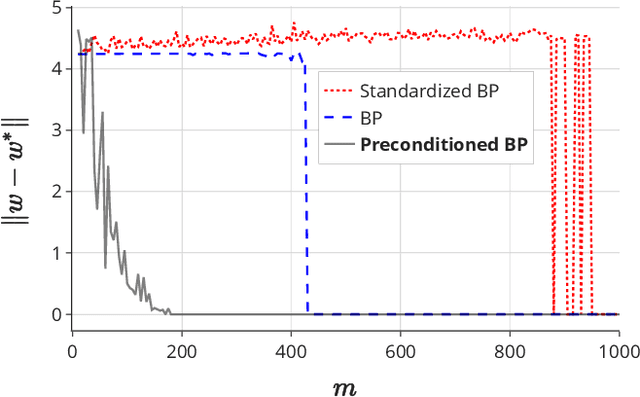
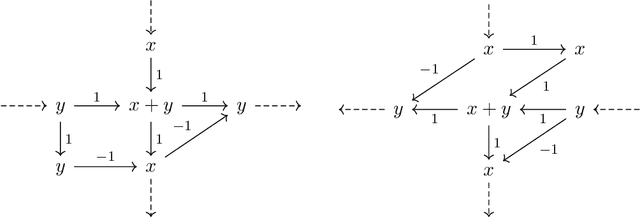
Sparse linear regression is a fundamental problem in high-dimensional statistics, but strikingly little is known about how to efficiently solve it without restrictive conditions on the design matrix. We consider the (correlated) random design setting, where the covariates are independently drawn from a multivariate Gaussian $N(0,\Sigma)$ with $\Sigma : n \times n$, and seek estimators $\hat{w}$ minimizing $(\hat{w}-w^*)^T\Sigma(\hat{w}-w^*)$, where $w^*$ is the $k$-sparse ground truth. Information theoretically, one can achieve strong error bounds with $O(k \log n)$ samples for arbitrary $\Sigma$ and $w^*$; however, no efficient algorithms are known to match these guarantees even with $o(n)$ samples, without further assumptions on $\Sigma$ or $w^*$. As far as hardness, computational lower bounds are only known with worst-case design matrices. Random-design instances are known which are hard for the Lasso, but these instances can generally be solved by Lasso after a simple change-of-basis (i.e. preconditioning). In this work, we give upper and lower bounds clarifying the power of preconditioning in sparse linear regression. First, we show that the preconditioned Lasso can solve a large class of sparse linear regression problems nearly optimally: it succeeds whenever the dependency structure of the covariates, in the sense of the Markov property, has low treewidth -- even if $\Sigma$ is highly ill-conditioned. Second, we construct (for the first time) random-design instances which are provably hard for an optimally preconditioned Lasso. In fact, we complete our treewidth classification by proving that for any treewidth-$t$ graph, there exists a Gaussian Markov Random Field on this graph such that the preconditioned Lasso, with any choice of preconditioner, requires $\Omega(t^{1/20})$ samples to recover $O(\log n)$-sparse signals when covariates are drawn from this model.
Auto-Encoded Reservoir Computing for Turbulence Learning
Dec 20, 2020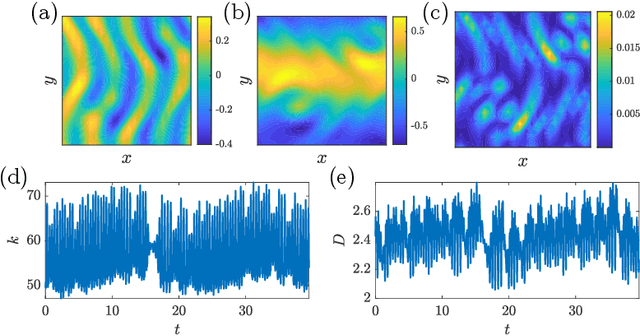
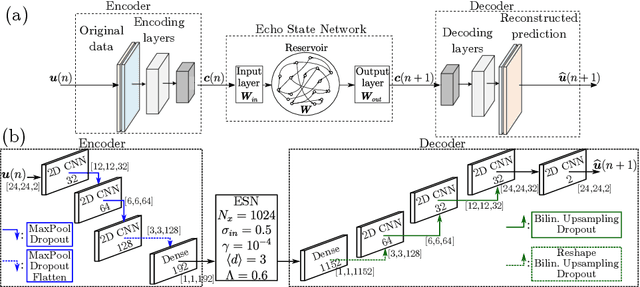
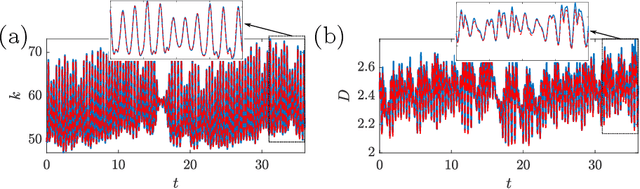
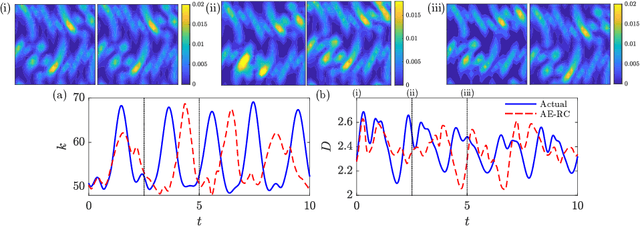
We present an Auto-Encoded Reservoir-Computing (AE-RC) approach to learn the dynamics of a 2D turbulent flow. The AE-RC consists of a Convolutional Autoencoder, which discovers an efficient manifold representation of the flow state, and an Echo State Network, which learns the time evolution of the flow in the manifold. The AE-RC is able to both learn the time-accurate dynamics of the turbulent flow and predict its first-order statistical moments. The AE-RC approach opens up new possibilities for the spatio-temporal prediction of turbulent flows with machine learning.
A Formal Framework for Reasoning about Agents' Independence in Self-organizing Multi-agent Systems
May 26, 2021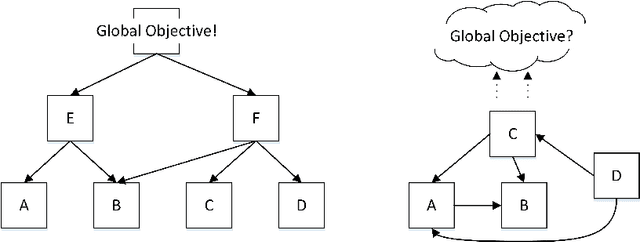
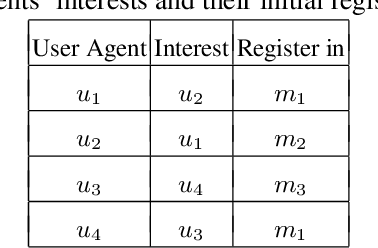
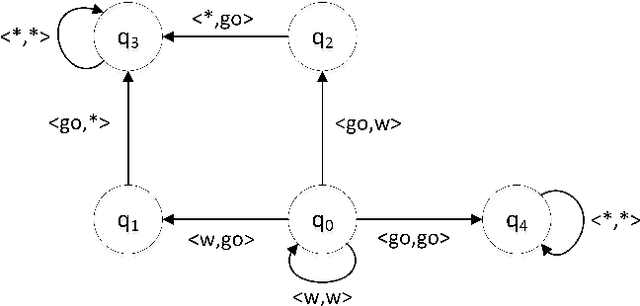
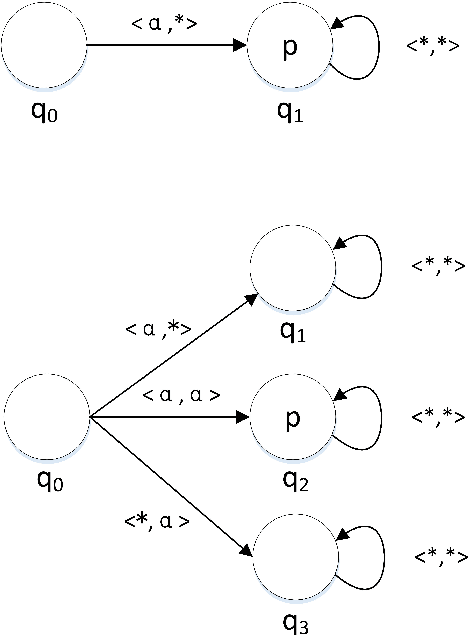
Self-organization is a process where a stable pattern is formed by the cooperative behavior between parts of an initially disordered system without external control or influence. It has been introduced to multi-agent systems as an internal control process or mechanism to solve difficult problems spontaneously. However, because a self-organizing multi-agent system has autonomous agents and local interactions between them, it is difficult to predict the behavior of the system from the behavior of the local agents we design. This paper proposes a logic-based framework of self-organizing multi-agent systems, where agents interact with each other by following their prescribed local rules. The dependence relation between coalitions of agents regarding their contributions to the global behavior of the system is reasoned about from the structural and semantic perspectives. We show that the computational complexity of verifying such a self-organizing multi-agent system is in exponential time. We then combine our framework with graph theory to decompose a system into different coalitions located in different layers, which allows us to verify agents' full contributions more efficiently. The resulting information about agents' full contributions allows us to understand the complex link between local agent behavior and system level behavior in a self-organizing multi-agent system. Finally, we show how we can use our framework to model a constraint satisfaction problem.
COVID-19 Detection from Chest X-ray Images using Imprinted Weights Approach
May 04, 2021
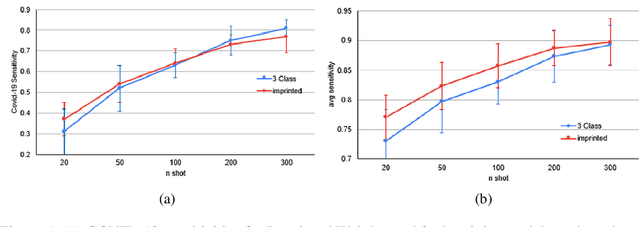
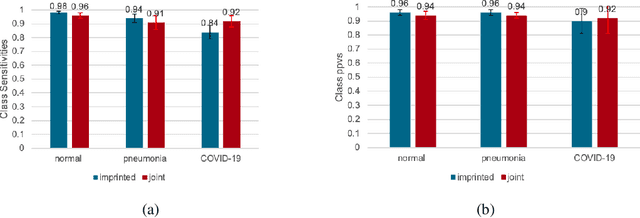
The COVID-19 pandemic has had devastating effects on the well-being of the global population. The pandemic has been so prominent partly due to the high infection rate of the virus and its variants. In response, one of the most effective ways to stop infection is rapid diagnosis. The main-stream screening method, reverse transcription-polymerase chain reaction (RT-PCR), is time-consuming, laborious and in short supply. Chest radiography is an alternative screening method for the COVID-19 and computer-aided diagnosis (CAD) has proven to be a viable solution at low cost and with fast speed; however, one of the challenges in training the CAD models is the limited number of training data, especially at the onset of the pandemic. This becomes outstanding precisely when the quick and cheap type of diagnosis is critically needed for flattening the infection curve. To address this challenge, we propose the use of a low-shot learning approach named imprinted weights, taking advantage of the abundance of samples from known illnesses such as pneumonia to improve the detection performance on COVID-19.
FlipReID: Closing the Gap between Training and Inference in Person Re-Identification
May 12, 2021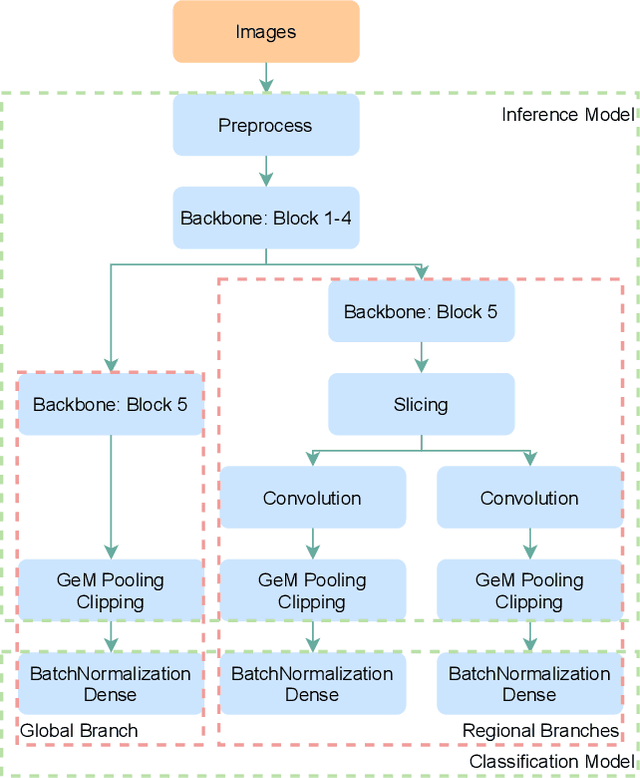
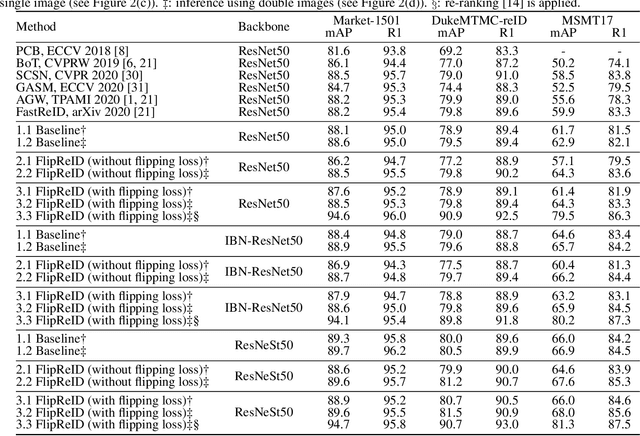
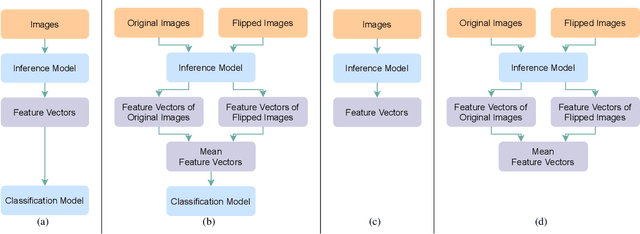
Since neural networks are data-hungry, incorporating data augmentation in training is a widely adopted technique that enlarges datasets and improves generalization. On the other hand, aggregating predictions of multiple augmented samples (i.e., test-time augmentation) could boost performance even further. In the context of person re-identification models, it is common practice to extract embeddings for both the original images and their horizontally flipped variants. The final representation is the mean of the aforementioned feature vectors. However, such scheme results in a gap between training and inference, i.e., the mean feature vectors calculated in inference are not part of the training pipeline. In this study, we devise the FlipReID structure with the flipping loss to address this issue. More specifically, models using the FlipReID structure are trained on the original images and the flipped images simultaneously, and incorporating the flipping loss minimizes the mean squared error between feature vectors of corresponding image pairs. Extensive experiments show that our method brings consistent improvements. In particular, we set a new record for MSMT17 which is the largest person re-identification dataset. The source code is available at https://github.com/nixingyang/FlipReID.