 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smoothness-Aware Quantization Techniques
Jun 07, 2021
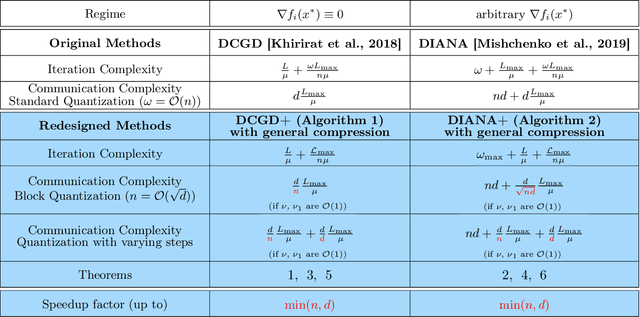
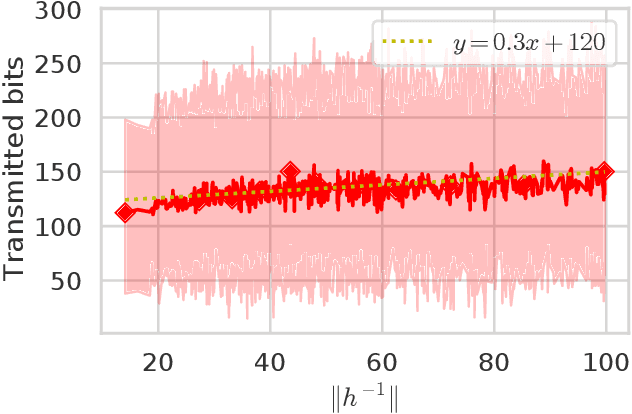
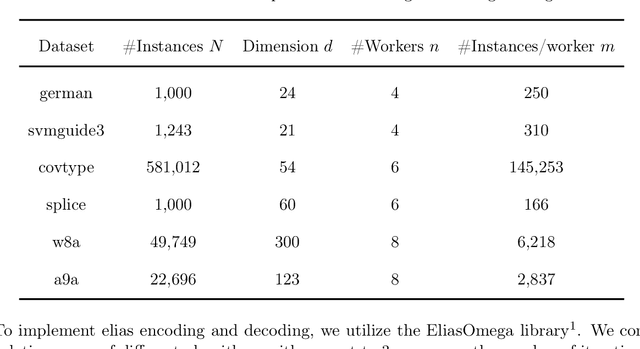
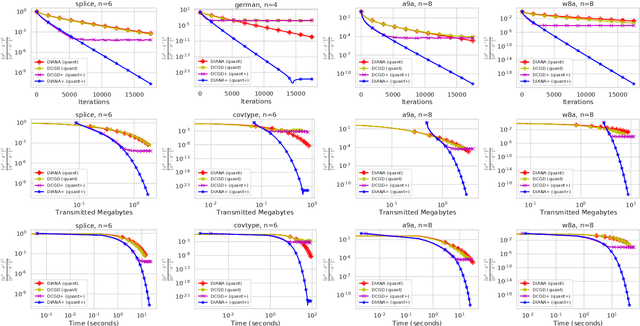
Distributed machine learning has become an indispensable tool for training large supervised machine learning models. To address the high communication costs of distributed training, which is further exacerbated by the fact that modern highly performing models are typically overparameterized, a large body of work has been devoted in recent years to the design of various compression strategies, such as sparsification and quantization, and optimization algorithms capable of using them. Recently, Safaryan et al (2021) pioneered a dramatically different compression design approach: they first use the local training data to form local {\em smoothness matrices}, and then propose to design a compressor capable of exploiting the smoothness information contained therein. While this novel approach leads to substantial savings in communication, it is limited to sparsification as it crucially depends on the linearity of the compression operator. In this work, we resolve this problem by extending their smoothness-aware compression strategy to arbitrary unbiased compression operators, which also includes sparsification. Specializing our results to quantization, we observe significant savings in communication complexity compared to standard quantization. In particular, we show theoretically that block quantization with $n$ blocks outperforms single block quantization, leading to a reduction in communication complexity by an $\mathcal{O}(n)$ factor, where $n$ is the number of nodes in the distributed system. Finally, we provide extensive numerical evidence that our smoothness-aware quantization strategies outperform existing quantization schemes as well the aforementioned smoothness-aware sparsification strategies with respect to all relevant success measures: the number of iterations, the total amount of bits communicated, and wall-clock time.
UAV Localization Using Autoencoded Satellite Images
Feb 10, 2021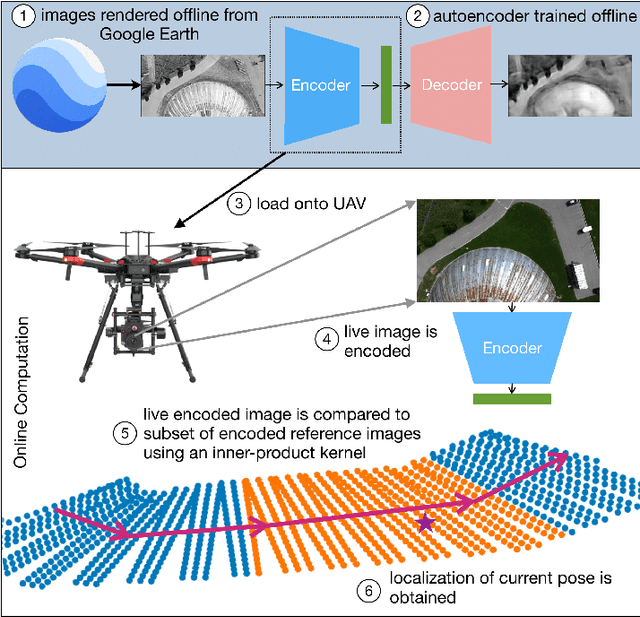


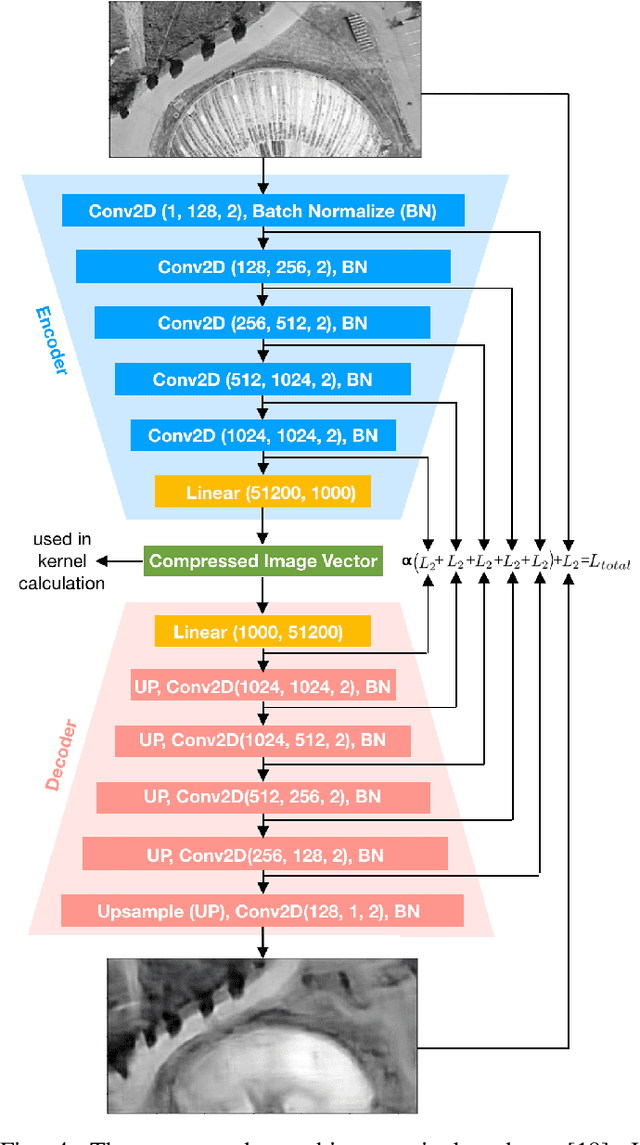
We propose and demonstrate a fast, robust method for using satellite images to localize an Unmanned Aerial Vehicle (UAV). Previous work using satellite images has large storage and computation costs and is unable to run in real time. In this work, we collect Google Earth (GE) images for a desired flight path offline and an autoencoder is trained to compress these images to a low-dimensional vector representation while retaining the key features. This trained autoencoder is used to compress a real UAV image, which is then compared to the precollected, nearby, autoencoded GE images using an inner-product kernel. This results in a distribution of weights over the corresponding GE image poses and is used to generate a single localization and associated covariance to represent uncertainty. Our localization is computed in 1% of the time of the current standard and is able to achieve a comparable RMSE of less than 3m in our experiments, where we robustly matched UAV images from six runs spanning the lighting conditions of a single day to the same map of satellite images.
Task-driven Semantic Coding via Reinforcement Learning
Jun 07, 2021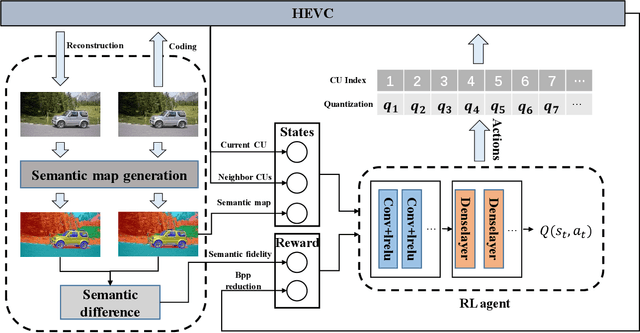
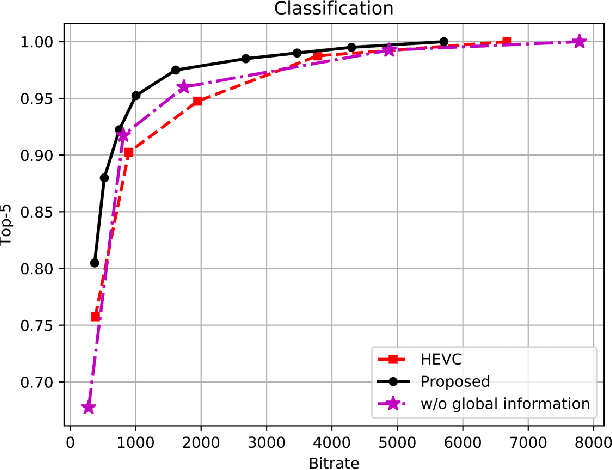
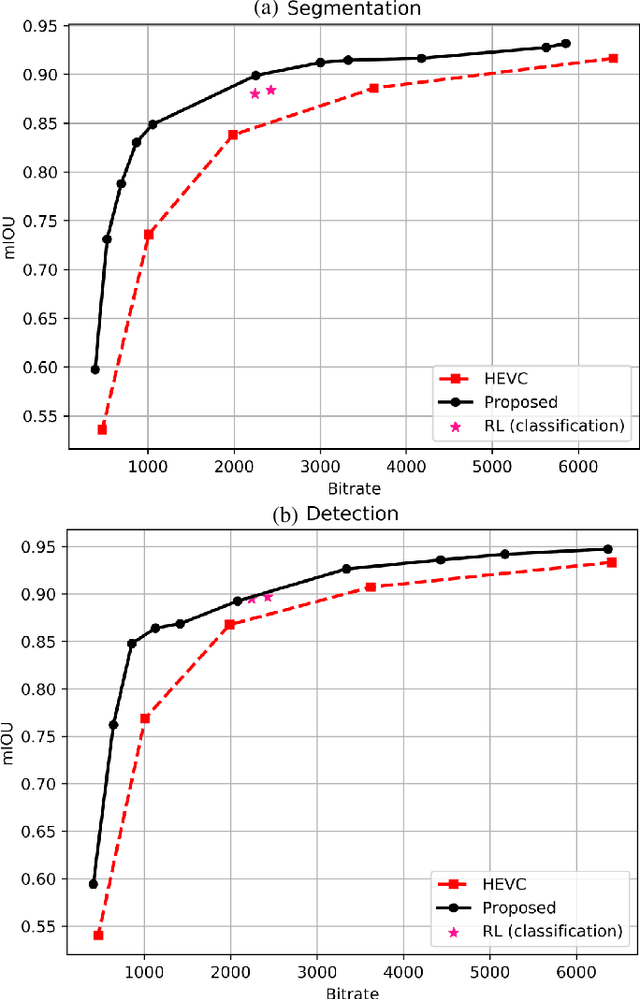
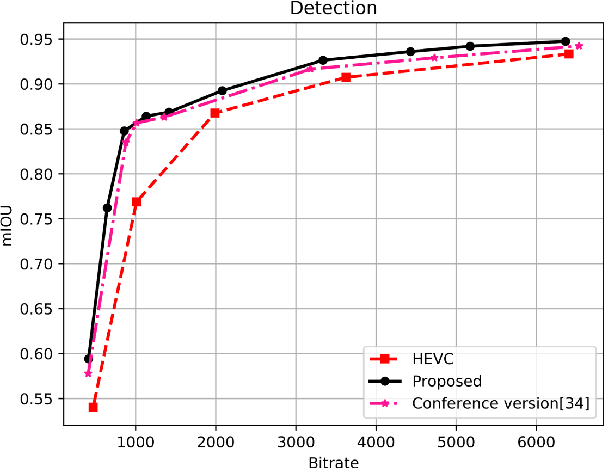
Task-driven semantic video/image coding has drawn considerable attention with the development of intelligent media applications, such as license plate detection, face detection, and medical diagnosis, which focuses on maintaining the semantic information of videos/images. Deep neural network (DNN)-based codecs have been studied for this purpose due to their inherent end-to-end optimization mechanism. However, the traditional hybrid coding framework cannot be optimized in an end-to-end manner, which makes task-driven semantic fidelity metric unable to be automatically integrated into the rate-distortion optimization process. Therefore, it is still attractive and challenging to implement task-driven semantic coding with the traditional hybrid coding framework, which should still be widely used in practical industry for a long time. To solve this challenge, we design semantic maps for different tasks to extract the pixelwise semantic fidelity for videos/images. Instead of directly integrating the semantic fidelity metric into traditional hybrid coding framework, we implement task-driven semantic coding by implementing semantic bit allocation based on reinforcement learning (RL). We formulate the semantic bit allocation problem as a Markov decision process (MDP) and utilize one RL agent to automatically determine the quantization parameters (QPs) for different coding units (CUs) according to the task-driven semantic fidelity metric. Extensive experiments on different tasks, such as classification, detection and segmentation, have demonstrated the superior performance of our approach by achieving an average bitrate saving of 34.39% to 52.62% over the High Efficiency Video Coding (H.265/HEVC) anchor under equivalent task-related semantic fidelity.
Land Cover Mapping in Limited Labels Scenario: A Survey
Mar 03, 2021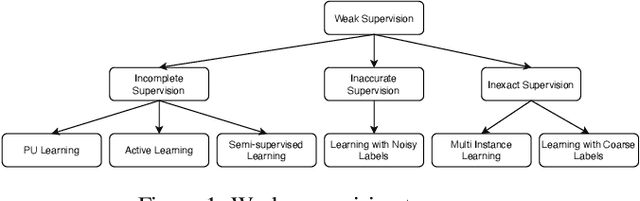
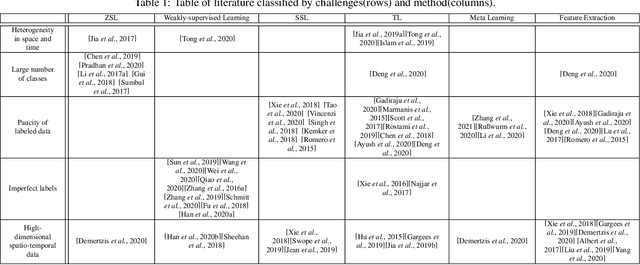
Land cover mapping is essential for monitoring global environmental change and managing natural resources. Unfortunately, traditional classification models are plagued by limited training data available in existing land cover products and data heterogeneity over space and time. In this survey, we provide a structured and comprehensive overview of challenges in land cover mapping and machine learning methods used to address these problems. We also discuss the gaps and opportunities that exist for advancing research in this promising direction.
Networked Federated Multi-Task Learning
May 26, 2021
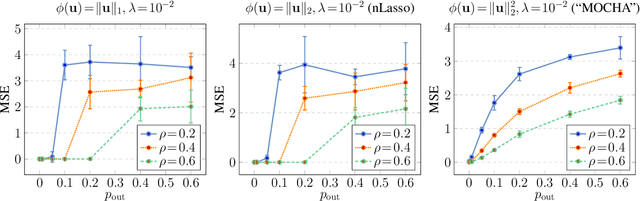
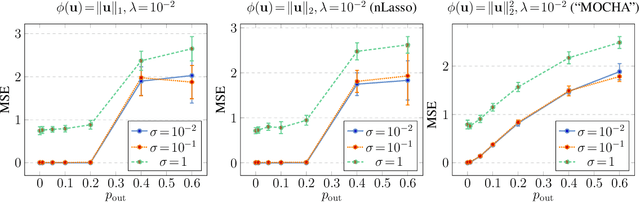
Many important application domains generate distributed collections of heterogeneous local datasets. These local datasets are often related via an intrinsic network structure that arises from domain-specific notions of similarity between local datasets. Different notions of similarity are induced by spatiotemporal proximity, statistical dependencies, or functional relations. We use this network structure to adaptively pool similar local datasets into nearly homogenous training sets for learning tailored models. Our main conceptual contribution is to formulate networked federated learning using the concept of generalized total variation (GTV) minimization as a regularizer. This formulation is highly flexible and can be combined with almost any parametric model including Lasso or deep neural networks. We unify and considerably extend some well-known approaches to federated multi-task learning. Our main algorithmic contribution is a novel federated learning algorithm that is well suited for distributed computing environments such as edge computing over wireless networks. This algorithm is robust against model misspecification and numerical errors arising from limited computational resources including processing time or wireless channel bandwidth. As our main technical contribution, we offer precise conditions on the local models as well on their network structure such that our algorithm learns nearly optimal local models. Our analysis reveals an interesting interplay between the (information-) geometry of local models and the (cluster-) geometry of their network.
Full-Sentence Models Perform Better in Simultaneous Translation Using the Information Enhanced Decoding Strategy
May 05, 2021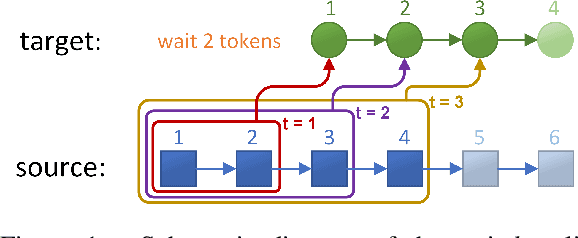
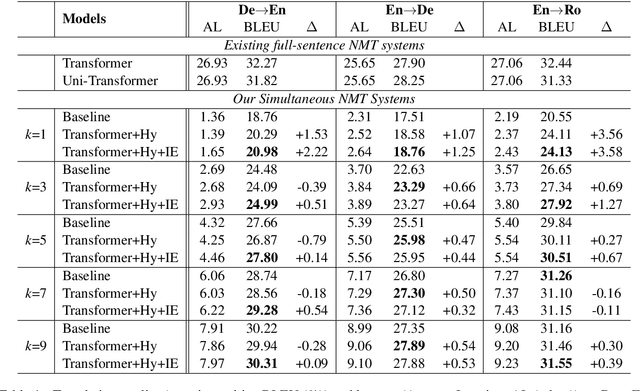
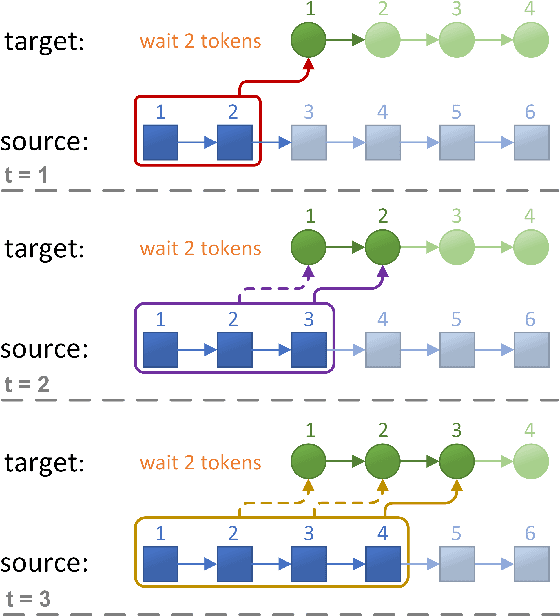
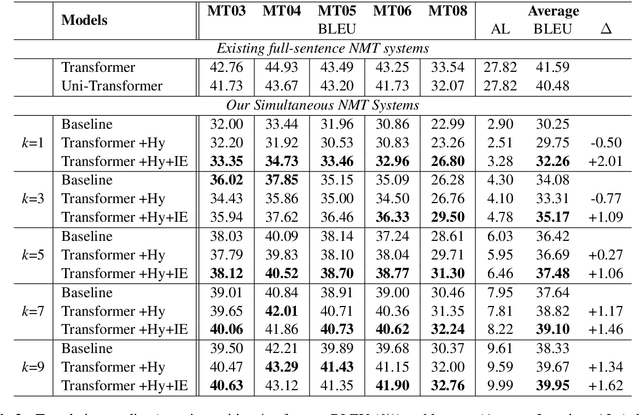
Simultaneous translation, which starts translating each sentence after receiving only a few words in source sentence, has a vital role in many scenarios. Although the previous prefix-to-prefix framework is considered suitable for simultaneous translation and achieves good performance, it still has two inevitable drawbacks: the high computational resource costs caused by the need to train a separate model for each latency $k$ and the insufficient ability to encode information because each target token can only attend to a specific source prefix. We propose a novel framework that adopts a simple but effective decoding strategy which is designed for full-sentence models. Within this framework, training a single full-sentence model can achieve arbitrary given latency and save computational resources. Besides, with the competence of the full-sentence model to encode the whole sentence, our decoding strategy can enhance the information maintained in the decoded states in real time. Experimental results show that our method achieves better translation quality than baselines on 4 directions: Zh$\rightarrow$En, En$\rightarrow$Ro and En$\leftrightarrow$De.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018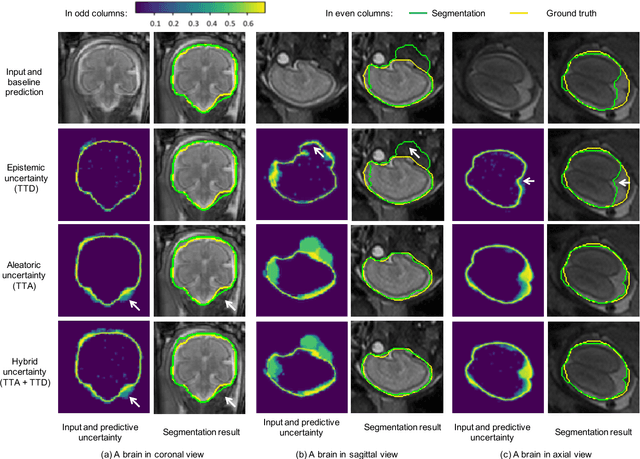
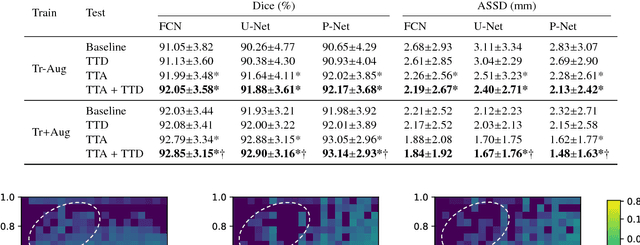
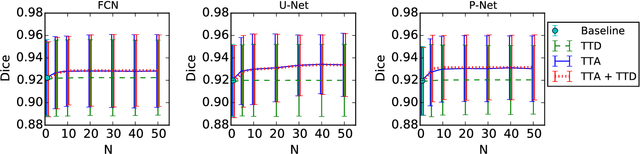
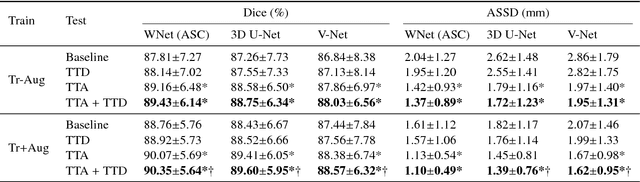
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
Exploring Deep Learning for Joint Audio-Visual Lip Biometrics
Apr 17, 2021
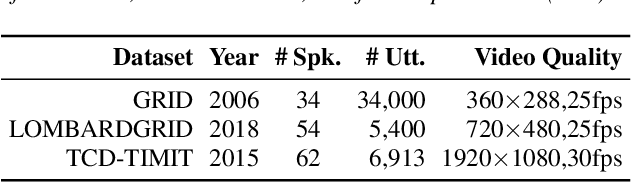
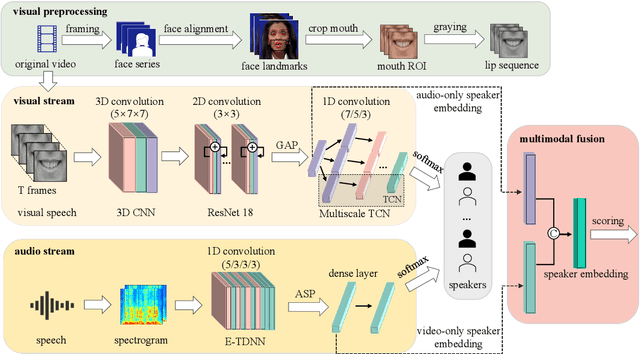

Audio-visual (AV) lip biometrics is a promising authentication technique that leverages the benefits of both the audio and visual modalities in speech communication. Previous works have demonstrated the usefulness of AV lip biometrics. However, the lack of a sizeable AV database hinders the exploration of deep-learning-based audio-visual lip biometrics. To address this problem, we compile a moderate-size database using existing public databases. Meanwhile, we establish the DeepLip AV lip biometrics system realized with a convolutional neural network (CNN) based video module, a time-delay neural network (TDNN) based audio module, and a multimodal fusion module. Our experiments show that DeepLip outperforms traditional speaker recognition models in context modeling and achieves over 50% relative improvements compared with our best single modality baseline, with an equal error rate of 0.75% and 1.11% on the test datasets, respectively.
Change Matters: Medication Change Prediction with Recurrent Residual Networks
May 05, 2021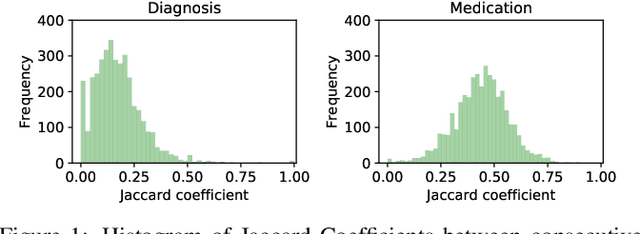
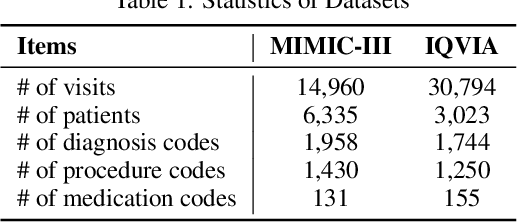
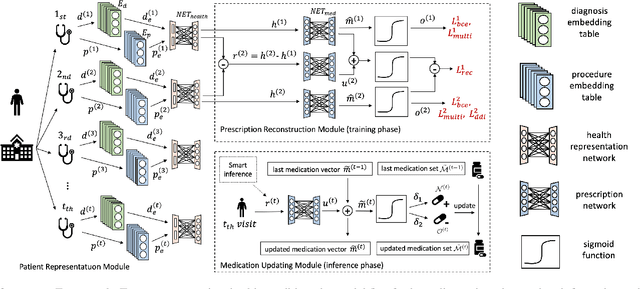
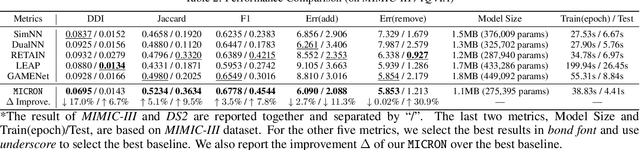
Deep learning is revolutionizing predictive healthcare, including recommending medications to patients with complex health conditions. Existing approaches focus on predicting all medications for the current visit, which often overlaps with medications from previous visits. A more clinically relevant task is to identify medication changes. In this paper, we propose a new recurrent residual network, named MICRON, for medication change prediction. MICRON takes the changes in patient health records as input and learns to update a hidden medication vector and the medication set recurrently with a reconstruction design. The medication vector is like the memory cell that encodes longitudinal information of medications. Unlike traditional methods that require the entire patient history for prediction, MICRON has a residual-based inference that allows for sequential updating based only on new patient features (e.g., new diagnoses in the recent visit) more efficiently. We evaluated MICRON on real inpatient and outpatient datasets. MICRON achieves 3.5% and 7.8% relative improvements over the best baseline in F1 score, respectively. MICRON also requires fewer parameters, which significantly reduces the training time to 38.3s per epoch with 1.5x speed-up.
Efficient Evolutionary Models with Digraphons
Apr 26, 2021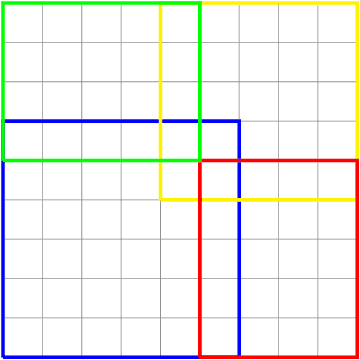
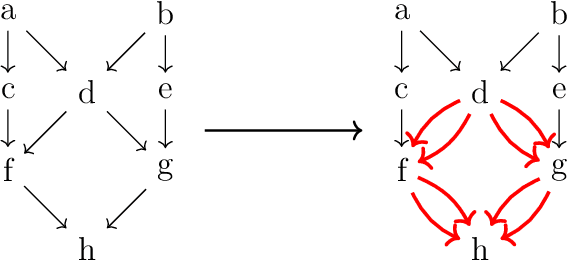
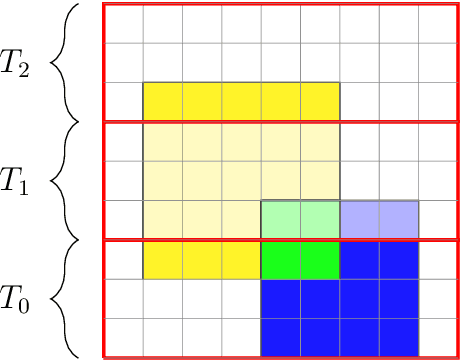
We present two main contributions which help us in leveraging the theory of graphons for modeling evolutionary processes. We show a generative model for digraphons using a finite basis of subgraphs, which is representative of biological networks with evolution by duplication. We show a simple MAP estimate on the Bayesian non parametric model using the Dirichlet Chinese restaurant process representation, with the help of a Gibbs sampling algorithm to infer the prior. Next we show an efficient implementation to do simulations on finite basis segmentations of digraphons. This implementation is used for developing fast evolutionary simulations with the help of an efficient 2-D representation of the digraphon using dynamic segment-trees with the square-root decomposition representation. We further show how this representation is flexible enough to handle changing graph nodes and can be used to also model dynamic digraphons with the help of an amortized update representation to achieve an efficient time complexity of the update at $O(\sqrt{|V|}\log{|V|})$.