 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Formula RL: Deep Reinforcement Learning for Autonomous Racing using Telemetry Data
Apr 22, 2021
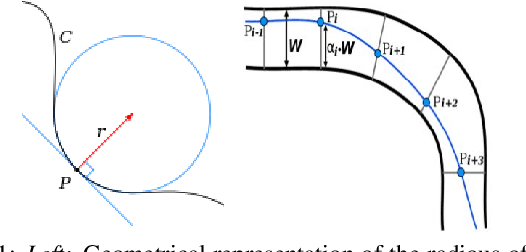

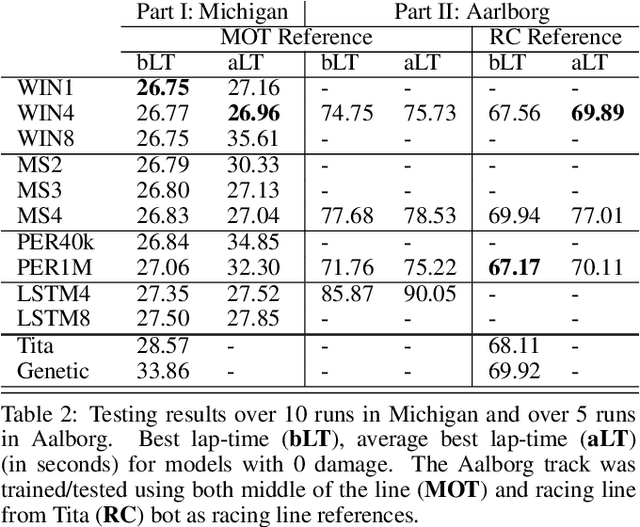
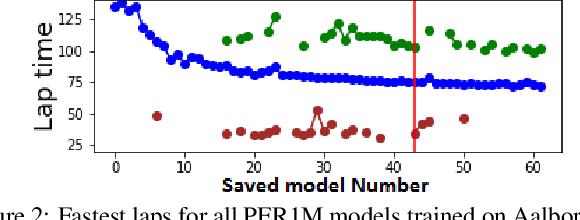
This paper explores the use of reinforcement learning (RL) models for autonomous racing. In contrast to passenger cars, where safety is the top priority, a racing car aims to minimize the lap-time. We frame the problem as a reinforcement learning task with a multidimensional input consisting of the vehicle telemetry, and a continuous action space. To find out which RL methods better solve the problem and whether the obtained models generalize to driving on unknown tracks, we put 10 variants of deep deterministic policy gradient (DDPG) to race in two experiments: i)~studying how RL methods learn to drive a racing car and ii)~studying how the learning scenario influences the capability of the models to generalize. Our studies show that models trained with RL are not only able to drive faster than the baseline open source handcrafted bots but also generalize to unknown tracks.
Deep reinforcement learning with automated label extraction from clinical reports accurately classifies 3D MRI brain volumes
Jun 17, 2021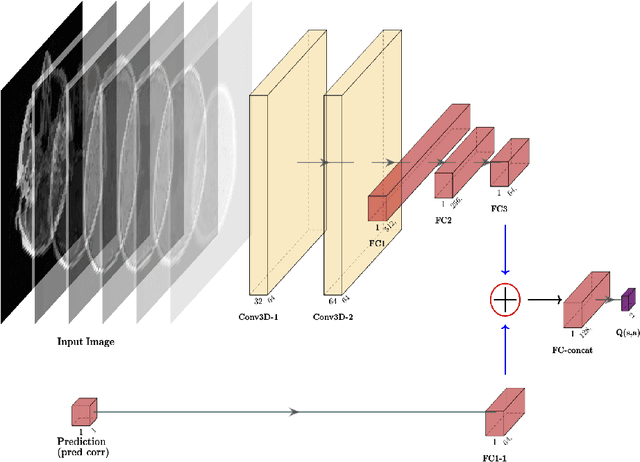
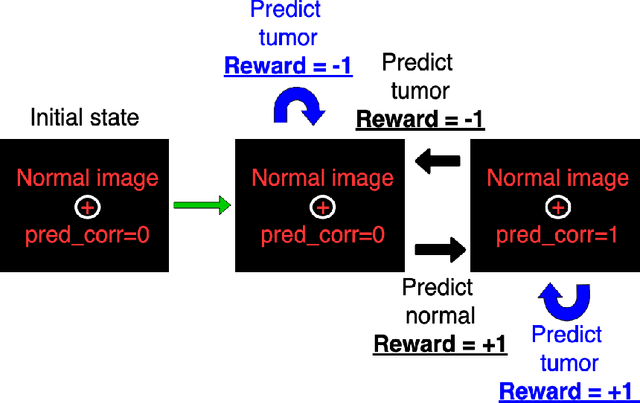
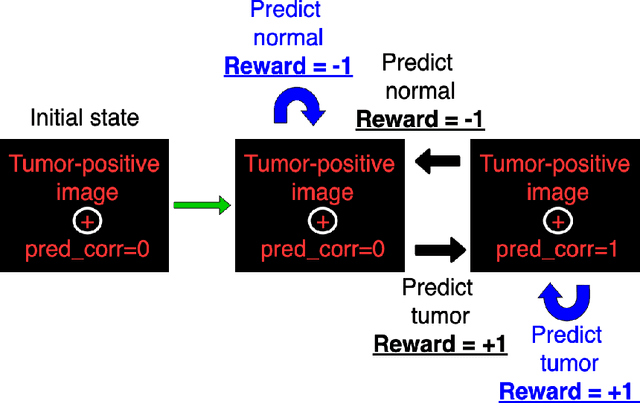
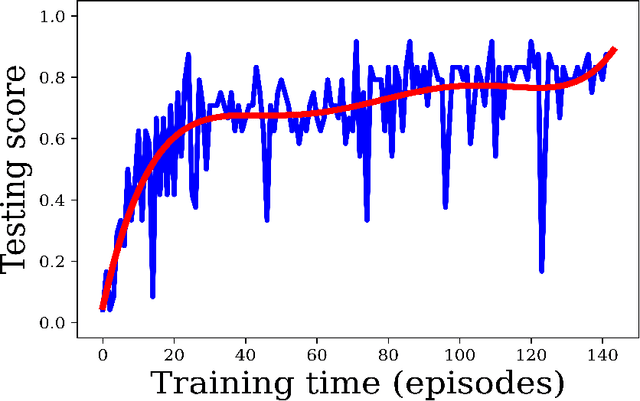
Purpose: Image classification is perhaps the most fundamental task in imaging AI. However, labeling images is time-consuming and tedious. We have recently demonstrated that reinforcement learning (RL) can classify 2D slices of MRI brain images with high accuracy. Here we make two important steps toward speeding image classification: Firstly, we automatically extract class labels from the clinical reports. Secondly, we extend our prior 2D classification work to fully 3D image volumes from our institution. Hence, we proceed as follows: in Part 1, we extract labels from reports automatically using the SBERT natural language processing approach. Then, in Part 2, we use these labels with RL to train a classification Deep-Q Network (DQN) for 3D image volumes. Methods: For Part 1, we trained SBERT with 90 radiology report impressions. We then used the trained SBERT to predict class labels for use in Part 2. In Part 2, we applied multi-step image classification to allow for combined Deep-Q learning using 3D convolutions and TD(0) Q learning. We trained on a set of 90 images. We tested on a separate set of 61 images, again using the classes predicted from patient reports by the trained SBERT in Part 1. For comparison, we also trained and tested a supervised deep learning classification network on the same set of training and testing images using the same labels. Results: Part 1: Upon training with the corpus of radiology reports, the SBERT model had 100% accuracy for both normal and metastasis-containing scans. Part 2: Then, using these labels, whereas the supervised approach quickly overfit the training data and as expected performed poorly on the testing set (66% accuracy, just over random guessing), the reinforcement learning approach achieved an accuracy of 92%. The results were found to be statistically significant, with a p-value of 3.1 x 10^-5.
Remaining Useful Life Estimation Under Uncertainty with Causal GraphNets
Nov 23, 2020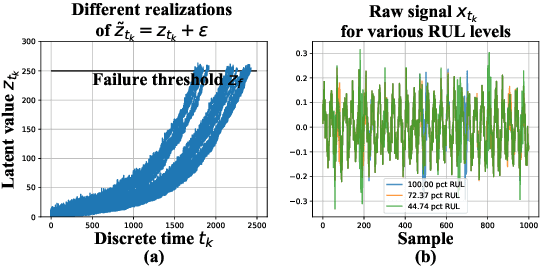
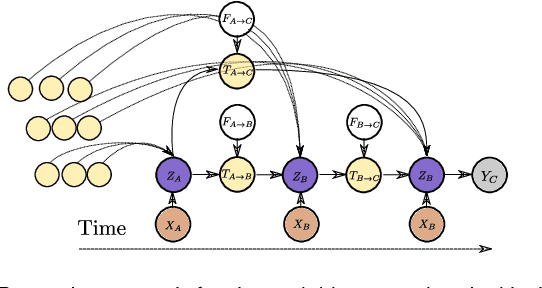
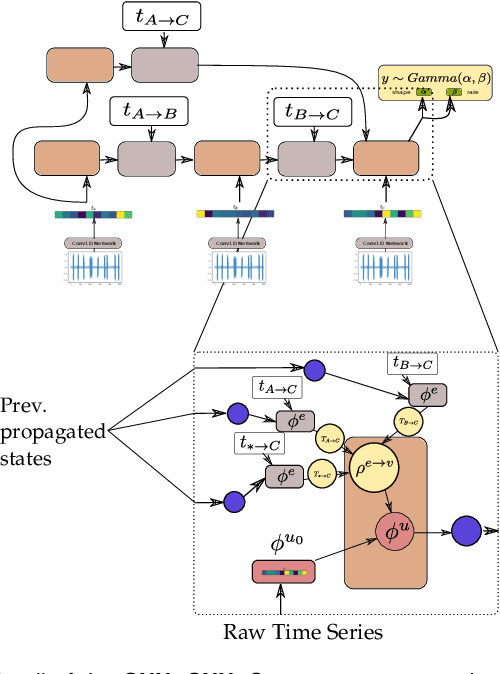
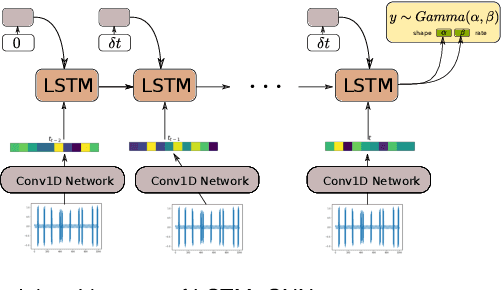
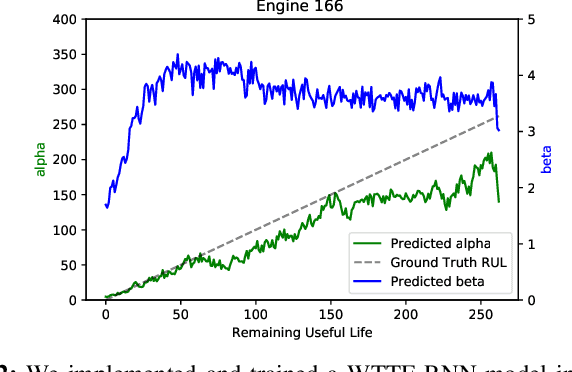
In this work, a novel approach for the construction and training of time series models is presented that deals with the problem of learning on large time series with non-equispaced observations, which at the same time may possess features of interest that span multiple scales. The proposed method is appropriate for constructing predictive models for non-stationary stochastic time series.The efficacy of the method is demonstrated on a simulated stochastic degradation dataset and on a real-world accelerated life testing dataset for ball-bearings. The proposed method, which is based on GraphNets, implicitly learns a model that describes the evolution of the system at the level of a state-vector rather than of a raw observation. The proposed approach is compared to a recurrent network with a temporal convolutional feature extractor head (RNN-tCNN) which forms a known viable alternative for the problem context considered. Finally, by taking advantage of recent advances in the computation of reparametrization gradients for learning probability distributions, a simple yet effective technique for representing prediction uncertainty as a Gamma distribution over remaining useful life predictions is employed.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018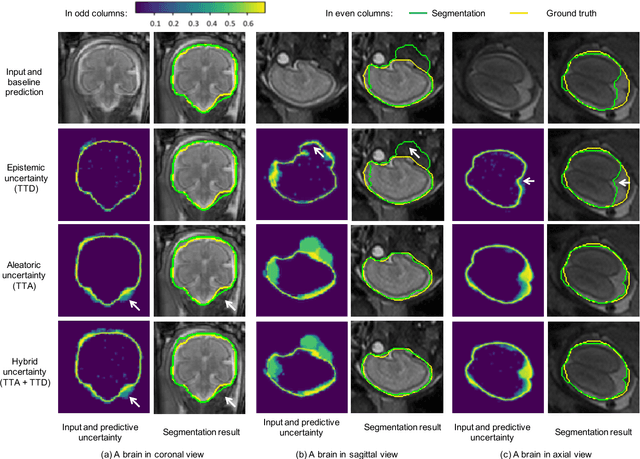
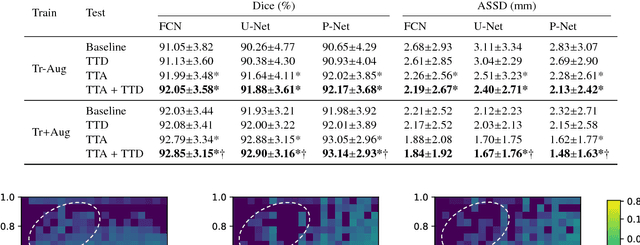
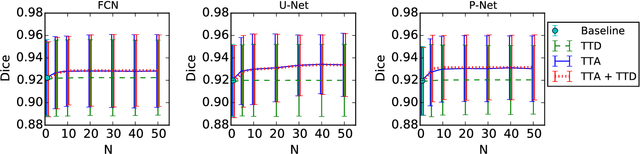
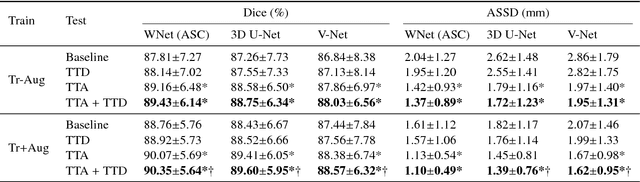
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
Diversity driven Query Rewriting in Search Advertising
Jun 07, 2021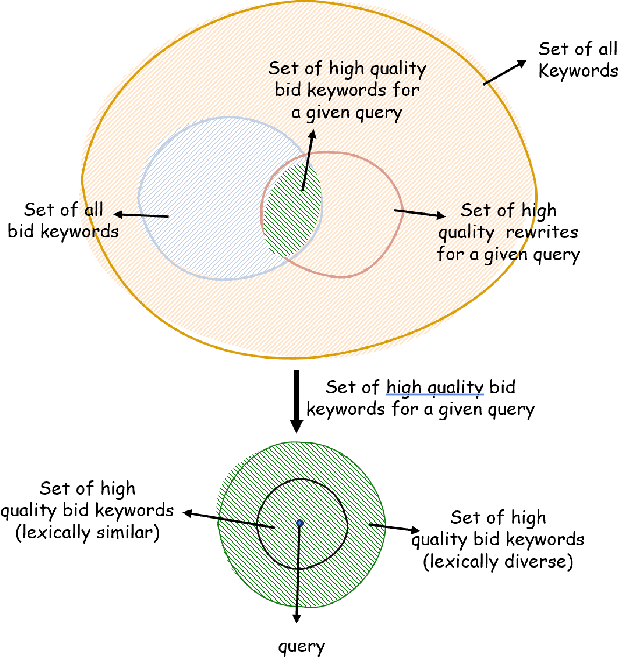

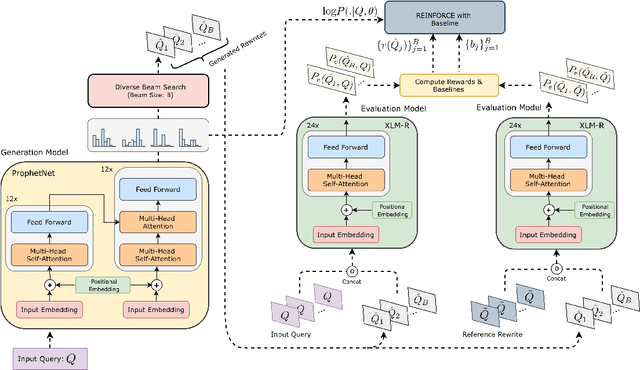
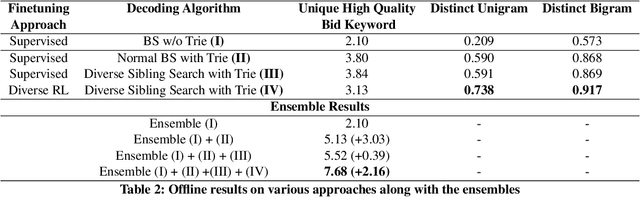
Retrieving keywords (bidwords) with the same intent as query, referred to as close variant keywords, is of prime importance for effective targeted search advertising. For head and torso search queries, sponsored search engines use a huge repository of same intent queries and keywords, mined ahead of time. Online, this repository is used to rewrite the query and then lookup the rewrite in a repository of bid keywords contributing to significant revenue. Recently generative retrieval models have been shown to be effective at the task of generating such query rewrites. We observe two main limitations of such generative models. First, rewrites generated by these models exhibit low lexical diversity, and hence the rewrites fail to retrieve relevant keywords that have diverse linguistic variations. Second, there is a misalignment between the training objective - the likelihood of training data, v/s what we desire - improved quality and coverage of rewrites. In this work, we introduce CLOVER, a framework to generate both high-quality and diverse rewrites by optimizing for human assessment of rewrite quality using our diversity-driven reinforcement learning algorithm. We use an evaluation model, trained to predict human judgments, as the reward function to finetune the generation policy. We empirically show the effectiveness of our proposed approach through offline experiments on search queries across geographies spanning three major languages. We also perform online A/B experiments on Bing, a large commercial search engine, which shows (i) better user engagement with an average increase in clicks by 12.83% accompanied with an average defect reduction by 13.97%, and (ii) improved revenue by 21.29%.
Speaker disentanglement in video-to-speech conversion
May 20, 2021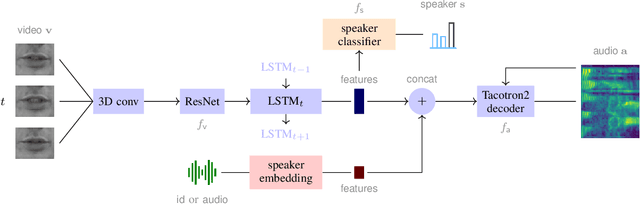
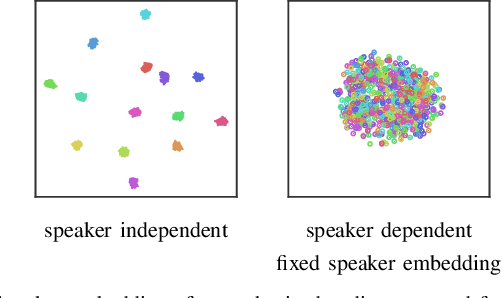
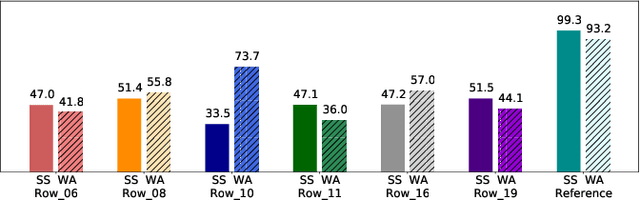
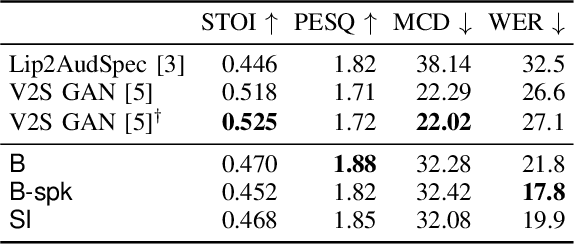
The task of video-to-speech aims to translate silent video of lip movement to its corresponding audio signal. Previous approaches to this task are generally limited to the case of a single speaker, but a method that accounts for multiple speakers is desirable as it allows to i) leverage datasets with multiple speakers or few samples per speaker; and ii) control speaker identity at inference time. In this paper, we introduce a new video-to-speech architecture and explore ways of extending it to the multi-speaker scenario: we augment the network with an additional speaker-related input, through which we feed either a discrete identity or a speaker embedding. Interestingly, we observe that the visual encoder of the network is capable of learning the speaker identity from the lip region of the face alone. To better disentangle the two inputs -- linguistic content and speaker identity -- we add adversarial losses that dispel the identity from the video embeddings. To the best of our knowledge, the proposed method is the first to provide important functionalities such as i) control of the target voice and ii) speech synthesis for unseen identities over the state-of-the-art, while still maintaining the intelligibility of the spoken output.
A One-Class Support Vector Machine Calibration Method for Time Series Change Point Detection
Feb 18, 2019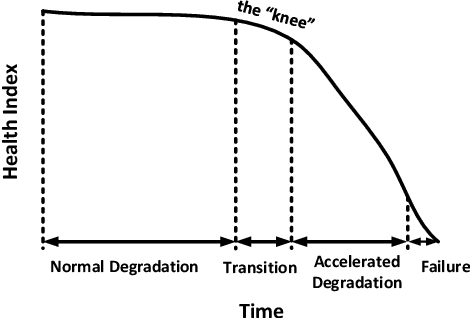
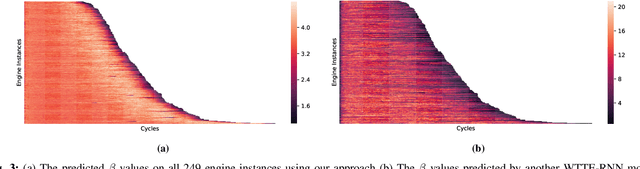
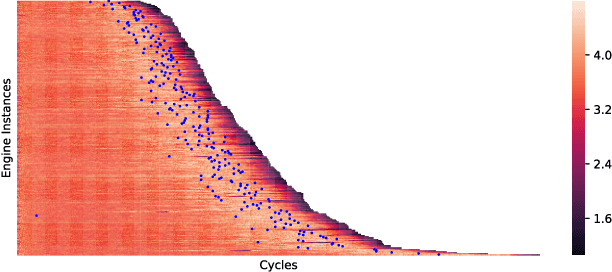
It is important to identify the change point of a system's health status, which usually signifies an incipient fault under development. The One-Class Support Vector Machine (OC-SVM) is a popular machine learning model for anomaly detection and hence could be used for identifying change points; however, it is sometimes difficult to obtain a good OC-SVM model that can be used on sensor measurement time series to identify the change points in system health status. In this paper, we propose a novel approach for calibrating OC-SVM models. The approach uses a heuristic search method to find a good set of input data and hyperparameters that yield a well-performing model. Our results on the C-MAPSS dataset demonstrate that OC-SVM can also achieve satisfactory accuracy in detecting change point in time series with fewer training data, compared to state-of-the-art deep learning approaches. In our case study, the OC-SVM calibrated by the proposed model is shown to be useful especially in scenarios with limited amount of training data.
It$\hat{\text{o}}$TTS and It$\hat{\text{o}}$Wave: Linear Stochastic Differential Equation Is All You Need For Audio Generation
May 20, 2021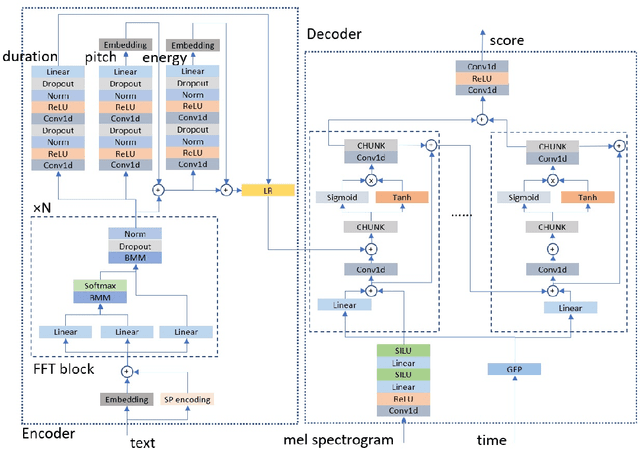
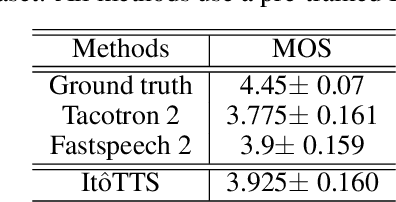
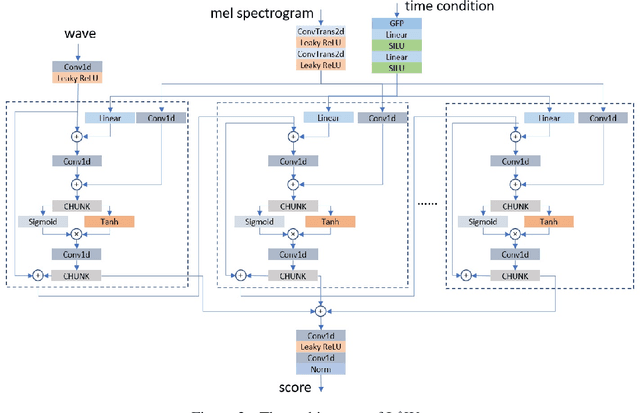
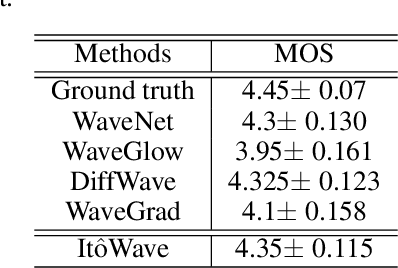
In this paper, we propose to unify the two aspects of voice synthesis, namely text-to-speech (TTS) and vocoder, into one framework based on a pair of forward and reverse-time linear stochastic differential equations (SDE). The solutions of this SDE pair are two stochastic processes, one of which turns the distribution of mel spectrogram (or wave), that we want to generate, into a simple and tractable distribution. The other is the generation procedure that turns this tractable simple signal into the target mel spectrogram (or wave). The model that generates mel spectrogram is called It$\hat{\text{o}}$TTS, and the model that generates wave is called It$\hat{\text{o}}$Wave. It$\hat{\text{o}}$TTS and It$\hat{\text{o}}$Wave use the Wiener process as a driver to gradually subtract the excess signal from the noise signal to generate realistic corresponding meaningful mel spectrogram and audio respectively, under the conditional inputs of original text or mel spectrogram. The results of the experiment show that the mean opinion scores (MOS) of It$\hat{\text{o}}$TTS and It$\hat{\text{o}}$Wave can exceed the current state-of-the-art methods, reached 3.925$\pm$0.160 and 4.35$\pm$0.115 respectively.
Enabling Content-Centric Device-to-Device Communication in the Millimeter-Wave Band
Apr 12, 2021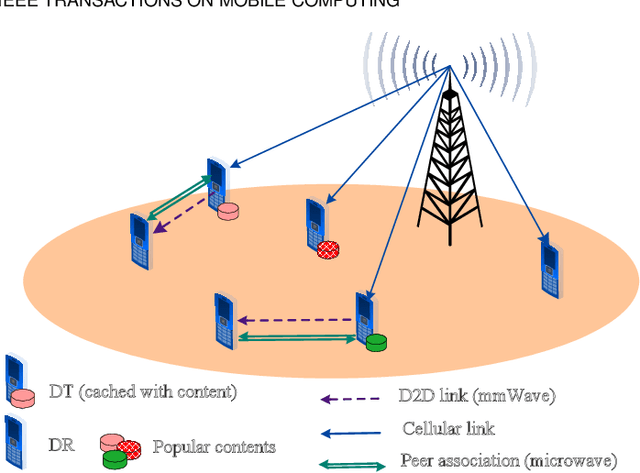

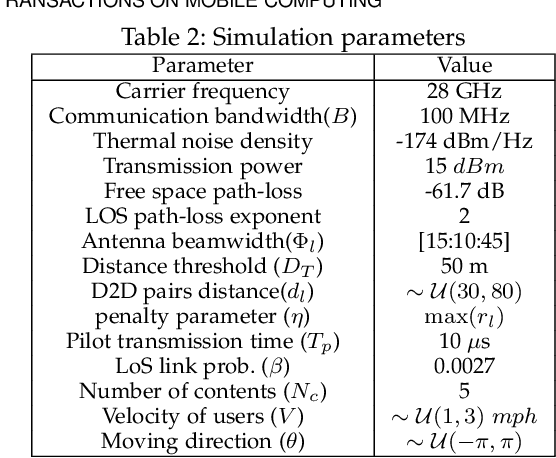
The growth in wireless traffic and mobility of devices have congested the core network significantly. This bottleneck, along with spectrum scarcity, made the conventional cellular networks insufficient for the dissemination of large contents. In this paper, we propose a novel scheme that enables efficient initialization of CCN-based D2D networks in the mmWave band through addressing decentralized D2D peer association and antenna beamwidth selection. The proposed scheme considers mmWave characteristics such as directional communication and blockage susceptibility. We propose a heuristic peer association algorithm to associate D2D users using context information, including link stability time and content availability. The performance of the proposed scheme in terms of data throughput and transmission efficiency is evaluated through extensive simulations. Simulation results show that the proposed scheme improves network performance significantly and outperforms other methods in the literature.
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
Mar 06, 2021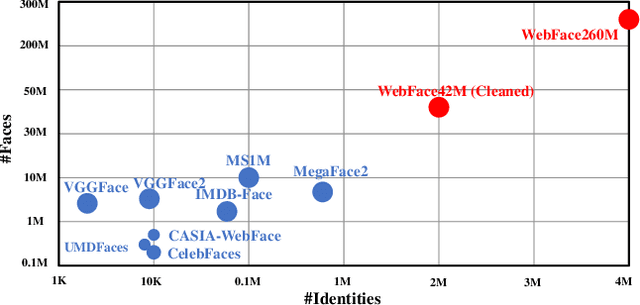
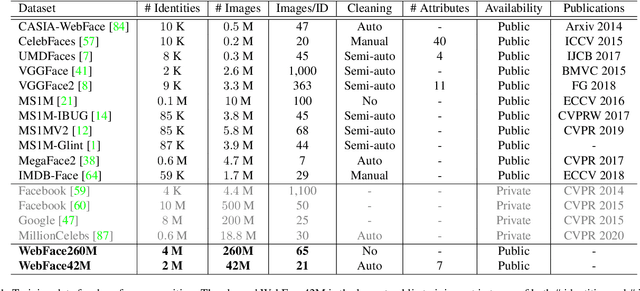
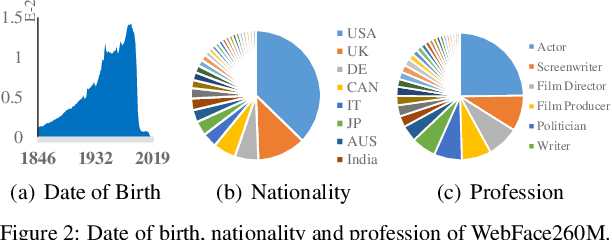
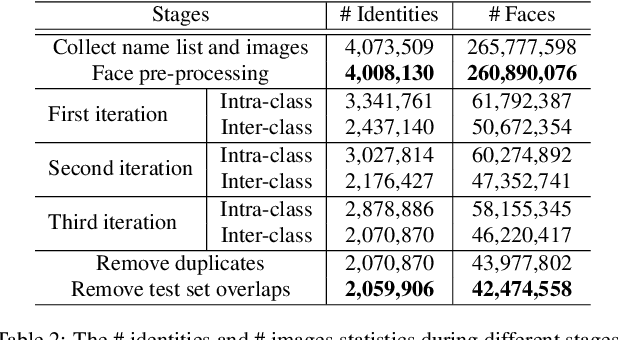
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.