 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Point process simulation of Generalised inverse Gaussian processes and estimation of the Jaeger Integral
May 19, 2021
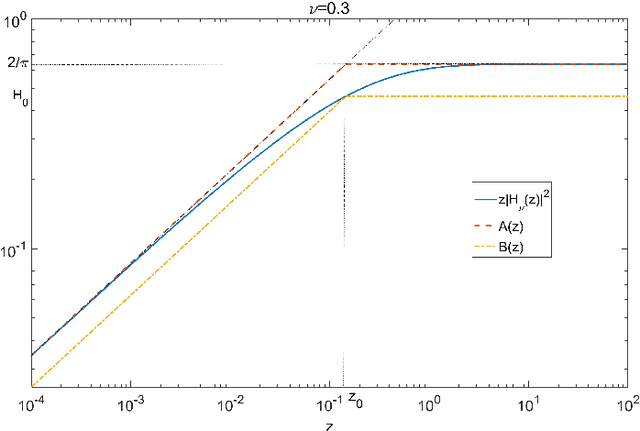
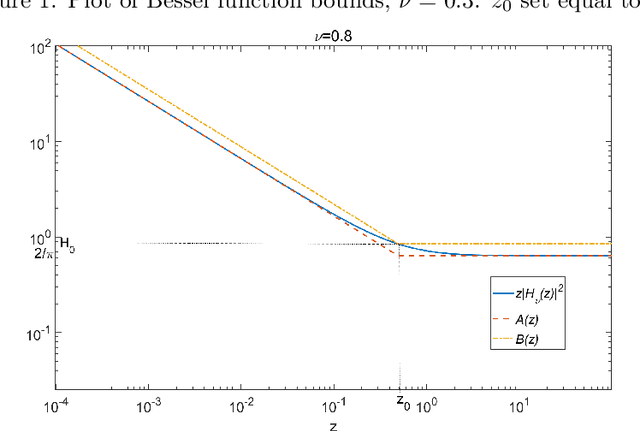
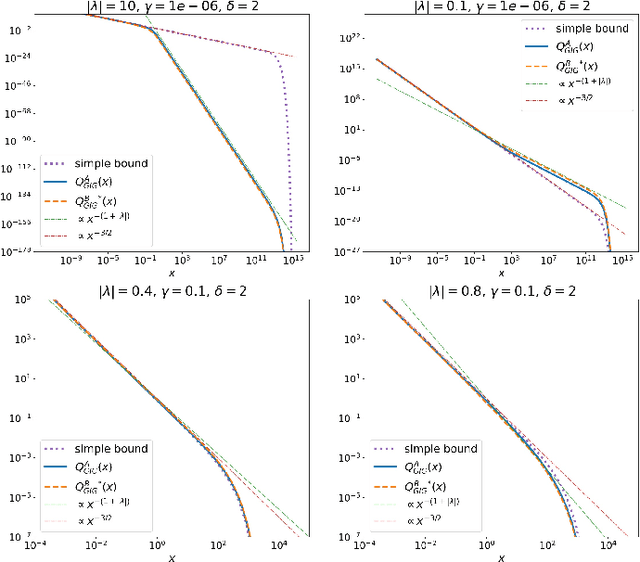
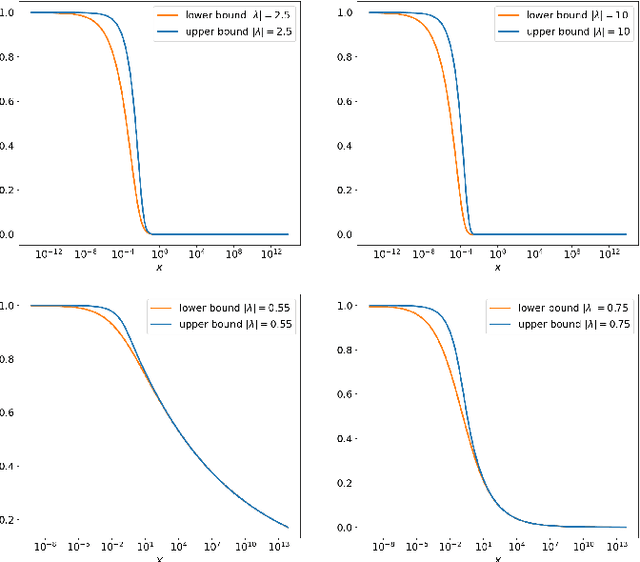
In this paper novel simulation methods are provided for the Generalised inverse Gaussian (GIG) L\'{e}vy process. Such processes are intractable for simulation except in certain special edge cases, since the L\'{e}vy density associated with the GIG process is expressed as an integral involving certain Bessel Functions, known as the Jaeger Integral in diffusive transport applications. We here show for the first time how to solve the problem indirectly, using generalised shot-noise methods to simulate the underlying point processes and constructing an auxiliary variables approach that avoids any direct calculation of the integrals involved. The augmented bivariate process is still intractable and so we propose a novel thinning method based on upper bounds on the intractable integrand. Moreover our approach leads to lower and upper bounds on the Jaeger integral itself, which may be compared with other approximation methods. We note that the GIG process is the required Brownian motion subordinator for the generalised hyperbolic (GH) L\'{e}vy process and so our simulation approach will straightforwardly extend also to the simulation of these intractable proceses. Our new methods will find application in forward simulation of processes of GIG and GH type, in financial and engineering data, for example, as well as inference for states and parameters of stochastic processes driven by GIG and GH L\'{e}vy processes.
SDNet: mutil-branch for single image deraining using swin
May 31, 2021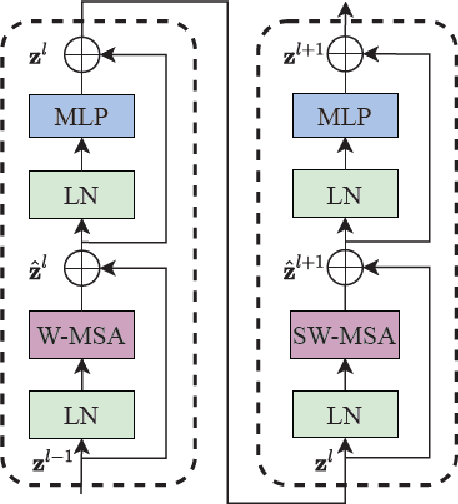
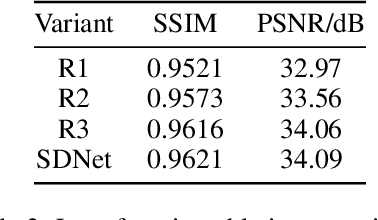
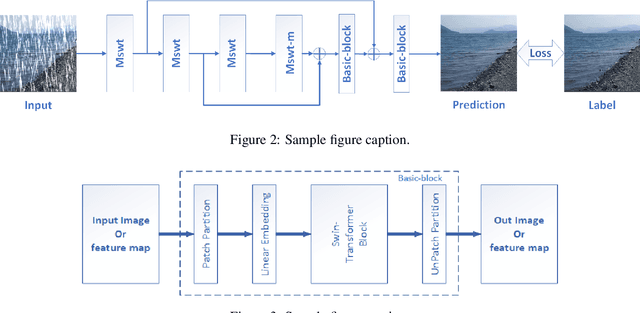
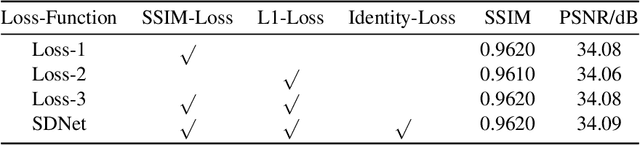
Rain streaks degrade the image quality and seriously affect the performance of subsequent computer vision tasks, such as autonomous driving, social security, etc. Therefore, removing rain streaks from a given rainy images is of great significance. Convolutional neural networks(CNN) have been widely used in image deraining tasks, however, the local computational characteristics of convolutional operations limit the development of image deraining tasks. Recently, the popular transformer has global computational features that can further facilitate the development of image deraining tasks. In this paper, we introduce Swin-transformer into the field of image deraining for the first time to study the performance and potential of Swin-transformer in the field of image deraining. Specifically, we improve the basic module of Swin-transformer and design a three-branch model to implement single-image rain removal. The former implements the basic rain pattern feature extraction, while the latter fuses different features to further extract and process the image features. In addition, we employ a jump connection to fuse deep features and shallow features. In terms of experiments, the existing public dataset suffers from image duplication and relatively homogeneous background. So we propose a new dataset Rain3000 to validate our model. Therefore, we propose a new dataset Rain3000 for validating our model. Experimental results on the publicly available datasets Rain100L, Rain100H and our dataset Rain3000 show that our proposed method has performance and inference speed advantages over the current mainstream single-image rain streaks removal models.The source code will be available at https://github.com/H-tfx/SDNet.
Characterizing the UAV-to-Machine UWB Radio Channel in Smart Factories
Apr 19, 2021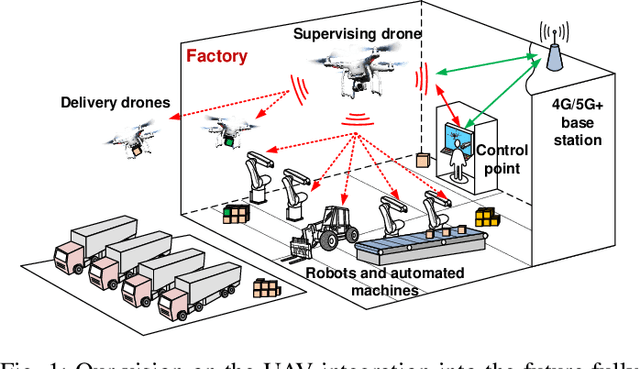

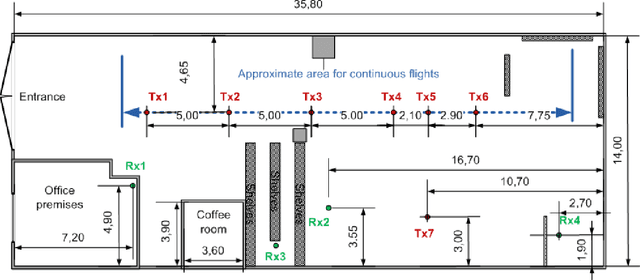
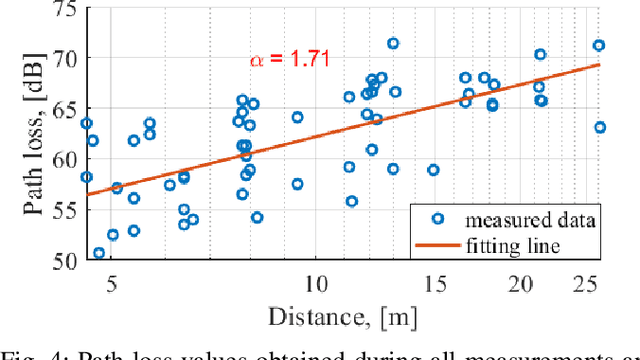
In this work, the results of Ultra-Wideband air-to-ground measurements carried out in a real-world factory environment are presented and discussed. With intelligent in-dustrial deployments in mind, we envision a scenario where the Unmanned Aerial Vehicle can be used as a supplementary tool for factory operation, optimization and control. Measurements address narrow band and wide band characterization of the wireless radio channel, and can be used for link budget calculation, interference studies and time dispersion assessment in real factories, without the usual limitation for both radio terminals to be close to ground. The measurements are performed at different locations and different heights over the 3.1-5.3 GHz band. Some fundamental propagation parameters values are determined vs. distance, height and propagation conditions. The measurements are complemented with, and compared to, conventional ground-to-ground measurements with the same setup. The conducted measurement campaign gives an insight for realizing wireless applications in smart connected factories, including UAV-assisted applications.
Straggler-Resilient Distributed Machine Learning with Dynamic Backup Workers
Feb 11, 2021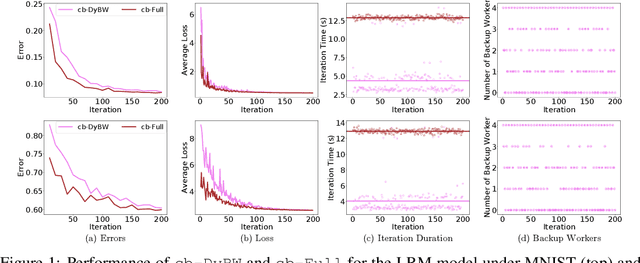

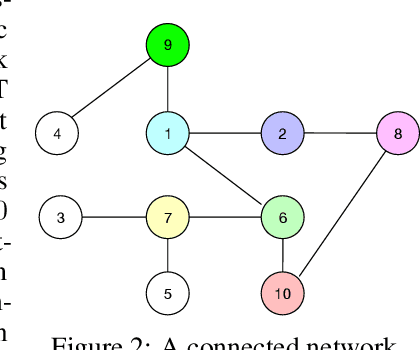
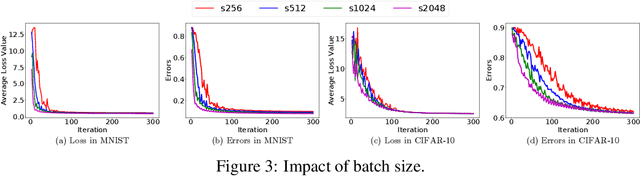
With the increasing demand for large-scale training of machine learning models, consensus-based distributed optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase can be time consuming due to the need to wait for \textit{stragglers}, i.e., slower workers. An efficient way to mitigate this effect is to let each worker wait only for updates from the fastest neighbors before updating its local parameter. The remaining neighbors are called \textit{backup workers.} To minimize the globally training time over the network, we propose a fully distributed algorithm to dynamically determine the number of backup workers for each worker. We show that our algorithm achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). We conduct extensive experiments on MNIST and CIFAR-10 to verify our theoretical results.
Packet-Loss-Tolerant Split Inference for Delay-Sensitive Deep Learning in Lossy Wireless Networks
Apr 28, 2021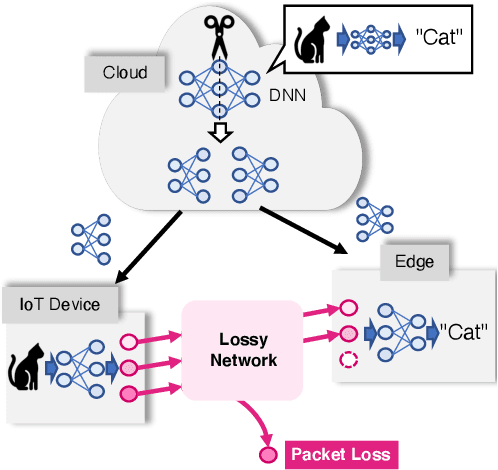
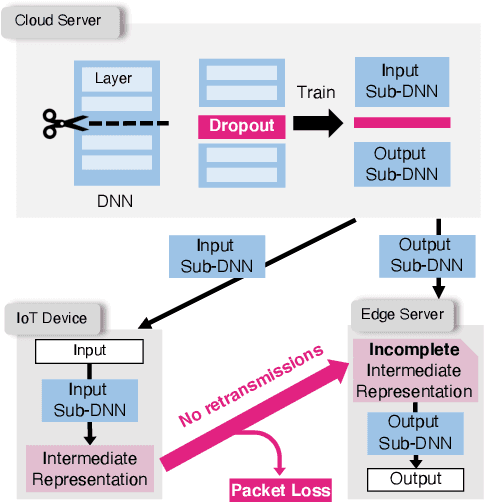
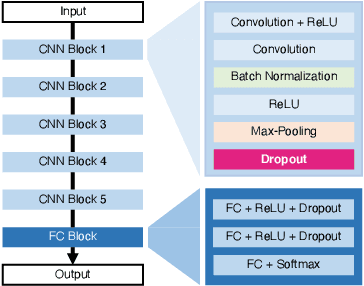
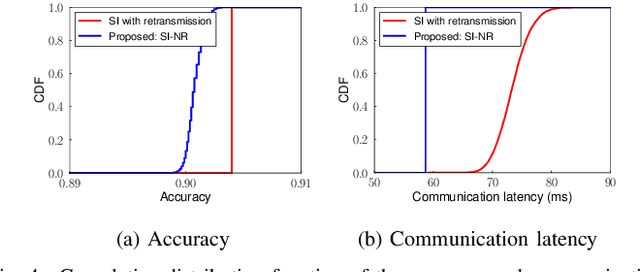
The distributed inference framework is an emerging technology for real-time applications empowered by cutting-edge deep machine learning (ML) on resource-constrained Internet of things (IoT) devices. In distributed inference, computational tasks are offloaded from the IoT device to other devices or the edge server via lossy IoT networks. However, narrow-band and lossy IoT networks cause non-negligible packet losses and retransmissions, resulting in non-negligible communication latency. This study solves the problem of the incremental retransmission latency caused by packet loss in a lossy IoT network. We propose a split inference with no retransmissions (SI-NR) method that achieves high accuracy without any retransmissions, even when packet loss occurs. In SI-NR, the key idea is to train the ML model by emulating the packet loss by a dropout method, which randomly drops the output of hidden units in a DNN layer. This enables the SI-NR system to obtain robustness against packet losses. Our ML experimental evaluation reveals that SI-NR obtains accurate predictions without packet retransmission at a packet loss rate of 60%.
Seglearn: A Python Package for Learning Sequences and Time Series
Oct 18, 2018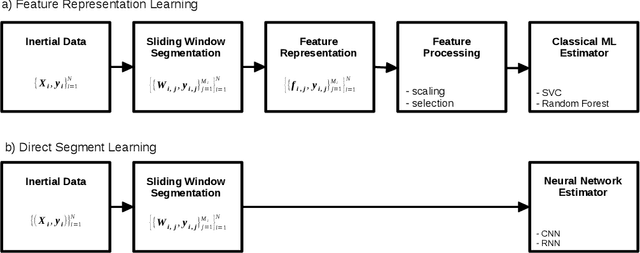
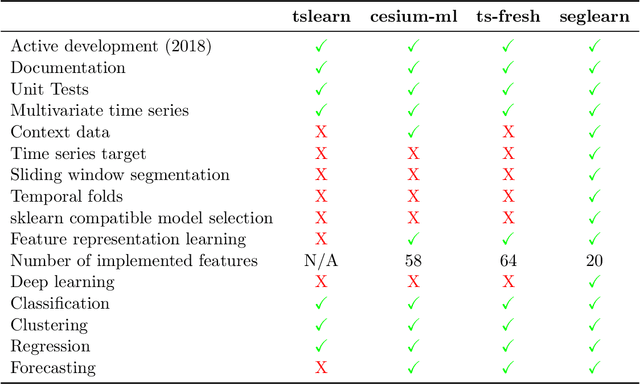

Seglearn is an open-source python package for machine learning time series or sequences using a sliding window segmentation approach. The implementation provides a flexible pipeline for tackling classification, regression, and forecasting problems with multivariate sequence and contextual data. This package is compatible with scikit-learn and is listed under scikit-learn Related Projects. The package depends on numpy, scipy, and scikit-learn. Seglearn is distributed under the BSD 3-Clause License. Documentation includes a detailed API description, user guide, and examples. Unit tests provide a high degree of code coverage.
Deep Reinforcement Learning for Crowdsourced Urban Delivery: System States Characterization, Heuristics-guided Action Choice, and Rule-Interposing Integration
Nov 29, 2020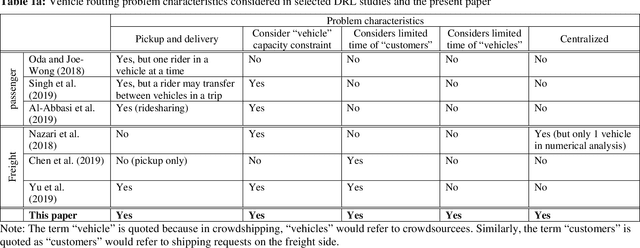
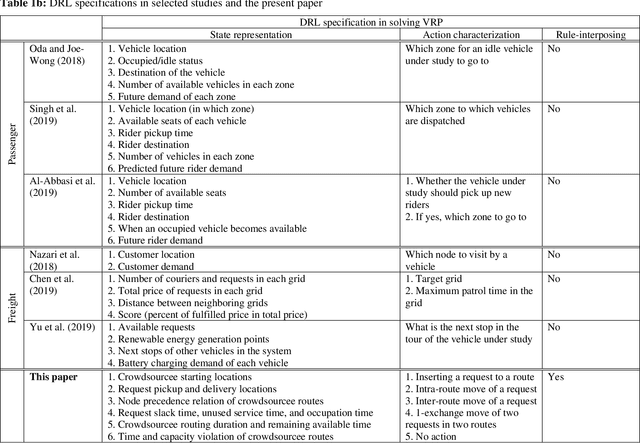
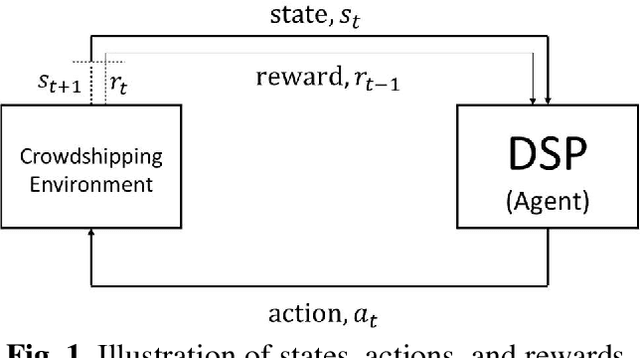

This paper investigates the problem of assigning shipping requests to ad hoc couriers in the context of crowdsourced urban delivery. The shipping requests are spatially distributed each with a limited time window between the earliest time for pickup and latest time for delivery. The ad hoc couriers, termed crowdsourcees, also have limited time availability and carrying capacity. We propose a new deep reinforcement learning (DRL)-based approach to tackling this assignment problem. A deep Q network (DQN) algorithm is trained which entails two salient features of experience replay and target network that enhance the efficiency, convergence, and stability of DRL training. More importantly, this paper makes three methodological contributions: 1) presenting a comprehensive and novel characterization of crowdshipping system states that encompasses spatial-temporal and capacity information of crowdsourcees and requests; 2) embedding heuristics that leverage the information offered by the state representation and are based on intuitive reasoning to guide specific actions to take, to preserve tractability and enhance efficiency of training; and 3) integrating rule-interposing to prevent repeated visiting of the same routes and node sequences during routing improvement, thereby further enhancing the training efficiency by accelerating learning. The effectiveness of the proposed approach is demonstrated through extensive numerical analysis. The results show the benefits brought by the heuristics-guided action choice and rule-interposing in DRL training, and the superiority of the proposed approach over existing heuristics in both solution quality, time, and scalability. Besides the potential to improve the efficiency of crowdshipping operation planning, the proposed approach also provides a new avenue and generic framework for other problems in the vehicle routing context.
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Apr 19, 2021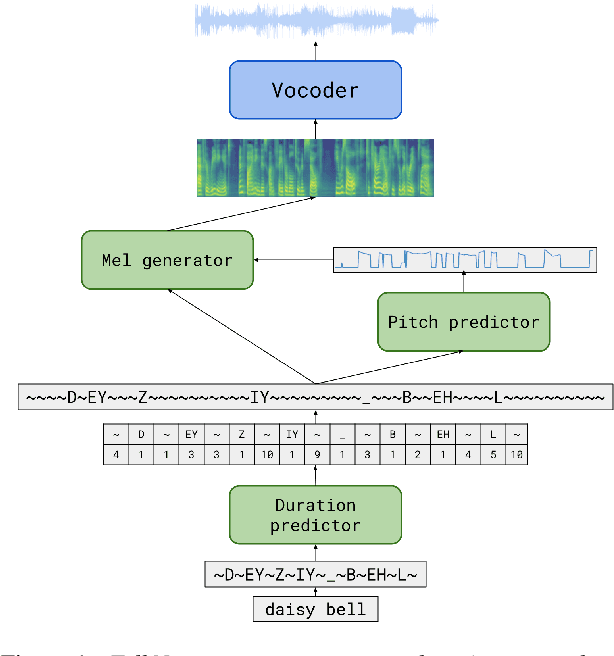
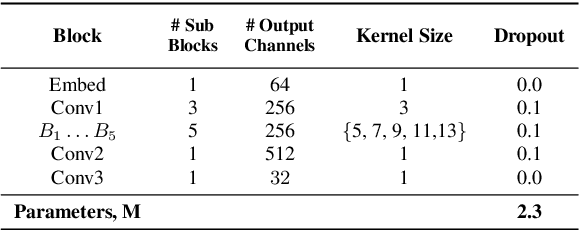
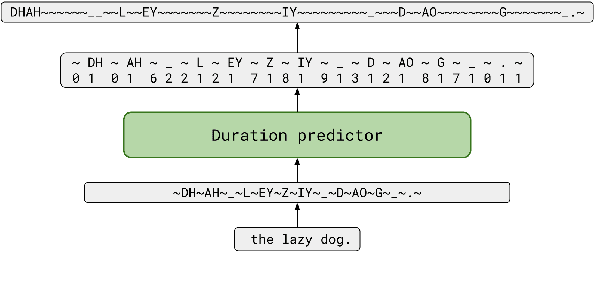
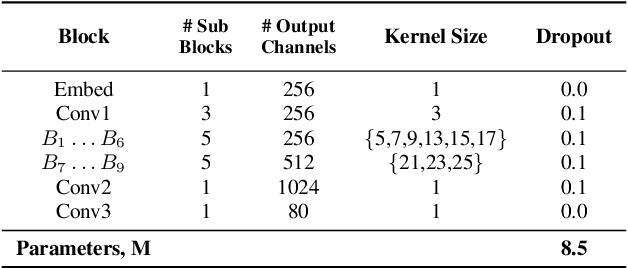
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.
Investigation of Multiple Resource Theory Design Principles on Robot Teleoperation and Workload Management
Mar 31, 2021
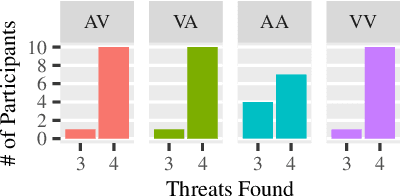
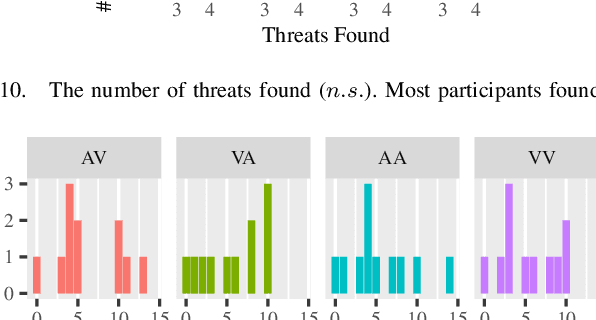
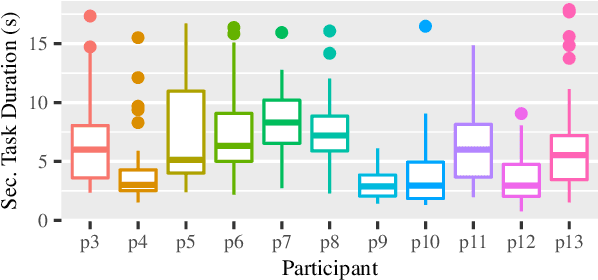
Robot interfaces often only use the visual channel. Inspired by Wickens' Multiple Resource Theory, we investigated if the addition of audio elements would reduce cognitive workload and improve performance. Specifically, we designed a search and threat-defusal task (primary) with a memory test task (secondary). Eleven participants - predominantly first responders - were recruited to control a robot to clear all threats in a combination of four conditions of primary and secondary tasks in visual and auditory channels. We did not find any statistically significant differences in performance or workload across subjects, making it questionable that Multiple Resource Theory could shorten longer-term task completion time and reduce workload. Our results suggest that considering individual differences for splitting interface modalities across multiple channels requires further investigation.
Deep Domain Generalization with Feature-norm Network
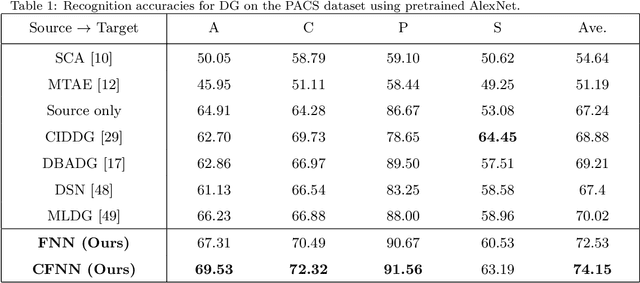
Apr 28, 2021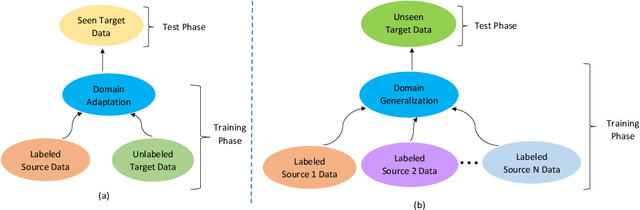

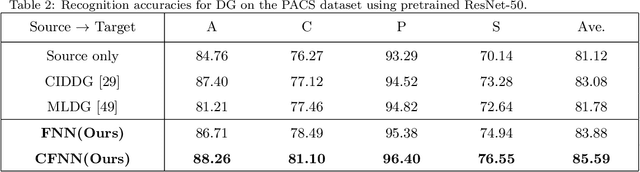
In this paper, we tackle the problem of training with multiple source domains with the aim to generalize to new domains at test time without an adaptation step. This is known as domain generalization (DG). Previous works on DG assume identical categories or label space across the source domains. In the case of category shift among the source domains, previous methods on DG are vulnerable to negative transfer due to the large mismatch among label spaces, decreasing the target classification accuracy. To tackle the aforementioned problem, we introduce an end-to-end feature-norm network (FNN) which is robust to negative transfer as it does not need to match the feature distribution among the source domains. We also introduce a collaborative feature-norm network (CFNN) to further improve the generalization capability of FNN. The CFNN matches the predictions of the next most likely categories for each training sample which increases each network's posterior entropy. We apply the proposed FNN and CFNN networks to the problem of DG for image classification tasks and demonstrate significant improvement over the state-of-the-art.