 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Optimization Kernel: Towards Robust Deep Learning
Jun 11, 2021
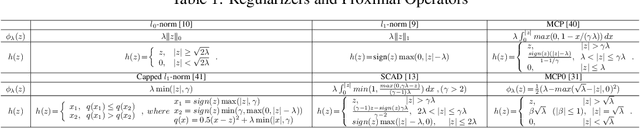
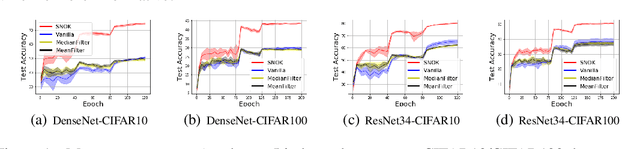
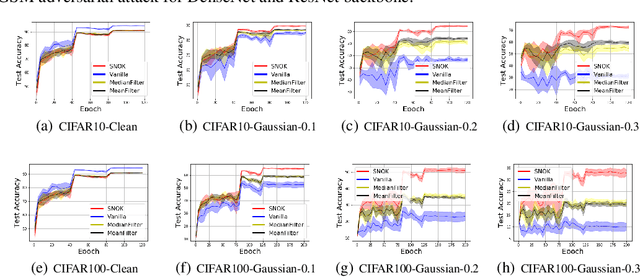
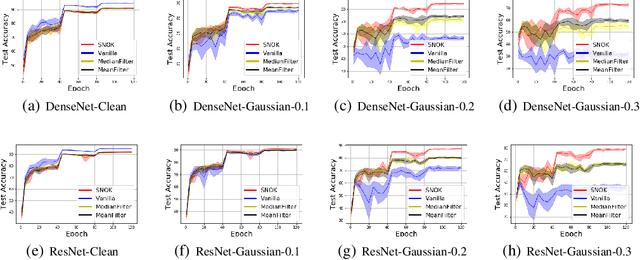
Recent studies show a close connection between neural networks (NN) and kernel methods. However, most of these analyses (e.g., NTK) focus on the influence of (infinite) width instead of the depth of NN models. There remains a gap between theory and practical network designs that benefit from the depth. This paper first proposes a novel kernel family named Neural Optimization Kernel (NOK). Our kernel is defined as the inner product between two $T$-step updated functionals in RKHS w.r.t. a regularized optimization problem. Theoretically, we proved the monotonic descent property of our update rule for both convex and non-convex problems, and a $O(1/T)$ convergence rate of our updates for convex problems. Moreover, we propose a data-dependent structured approximation of our NOK, which builds the connection between training deep NNs and kernel methods associated with NOK. The resultant computational graph is a ResNet-type finite width NN. Our structured approximation preserved the monotonic descent property and $O(1/T)$ convergence rate. Namely, a $T$-layer NN performs $T$-step monotonic descent updates. Notably, we show our $T$-layered structured NN with ReLU maintains a $O(1/T)$ convergence rate w.r.t. a convex regularized problem, which explains the success of ReLU on training deep NN from a NN architecture optimization perspective. For the unsupervised learning and the shared parameter case, we show the equivalence of training structured NN with GD and performing functional gradient descent in RKHS associated with a fixed (data-dependent) NOK at an infinity-width regime. For finite NOKs, we prove generalization bounds. Remarkably, we show that overparameterized deep NN (NOK) can increase the expressive power to reduce empirical risk and reduce the generalization bound at the same time. Extensive experiments verify the robustness of our structured NOK blocks.
Localization and Control of Magnetic Suture Needles in Cluttered Surgical Site with Blood and Tissue
May 20, 2021
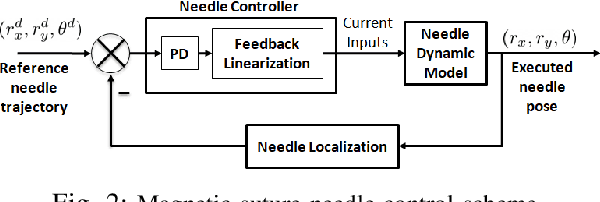
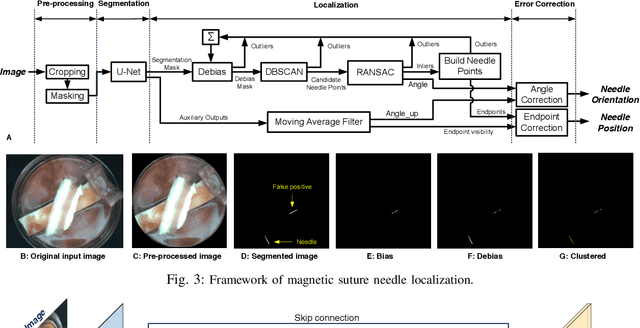
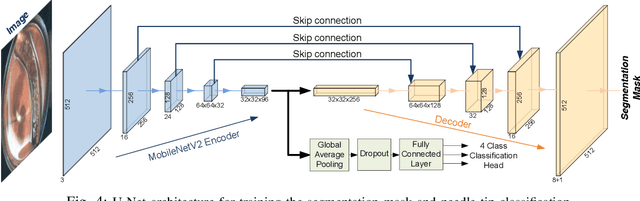
Real-time visual localization of needles is necessary for various surgical applications, including surgical automation and visual feedback. In this study we investigate localization and autonomous robotic control of needles in the context of our magneto-suturing system. Our system holds the potential for surgical manipulation with the benefit of minimal invasiveness and reduced patient side effects. However, the non-linear magnetic fields produce unintuitive forces and demand delicate position-based control that exceeds the capabilities of direct human manipulation. This makes automatic needle localization a necessity. Our localization method combines neural network-based segmentation and classical techniques, and we are able to consistently locate our needle with 0.73 mm RMS error in clean environments and 2.72 mm RMS error in challenging environments with blood and occlusion. The average localization RMS error is 2.16 mm for all environments we used in the experiments. We combine this localization method with our closed-loop feedback control system to demonstrate the further applicability of localization to autonomous control. Our needle is able to follow a running suture path in (1) no blood, no tissue; (2) heavy blood, no tissue; (3) no blood, with tissue; and (4) heavy blood, with tissue environments. The tip position tracking error ranges from 2.6 mm to 3.7 mm RMS, opening the door towards autonomous suturing tasks.
Real-Time Drone Detection and Tracking With Visible, Thermal and Acoustic Sensors
Jul 14, 2020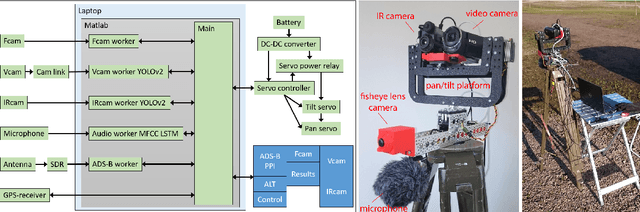
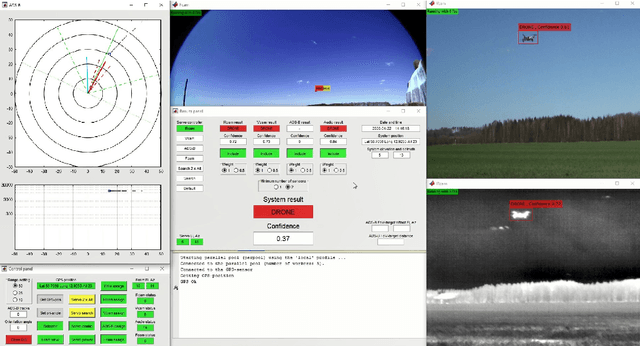


This paper explores the process of designing an automatic multi-sensor drone detection system. Besides the common video and audio sensors, the system also includes a thermal infrared camera, which is shown to be a feasible solution to the drone detection task. Even with slightly lower resolution, the performance is just as good as a camera in visible range. The detector performance as a function of the sensor-to-target distance is also investigated. In addition, using sensor fusion, the system is made more robust than the individual sensors, helping to reduce false detections. To counteract the lack of public datasets, a novel video dataset containing 650 annotated infrared and visible videos of drones, birds, airplanes and helicopters is also presented. The database is complemented with an audio dataset of the classes drones, helicopters and background noise.
Image Segmentation Methods for Non-destructive testing Applications
Mar 13, 2021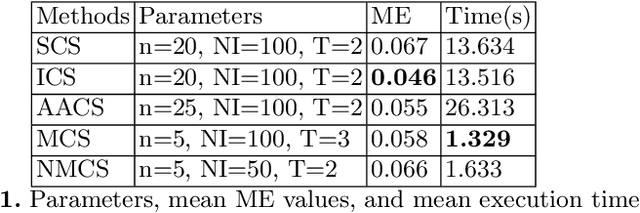
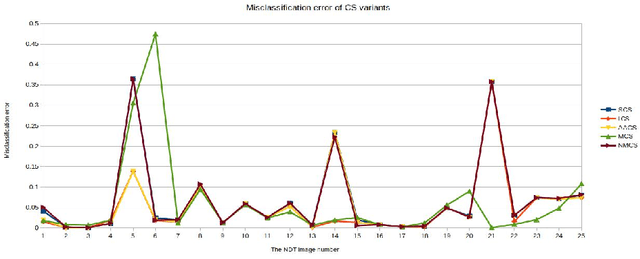
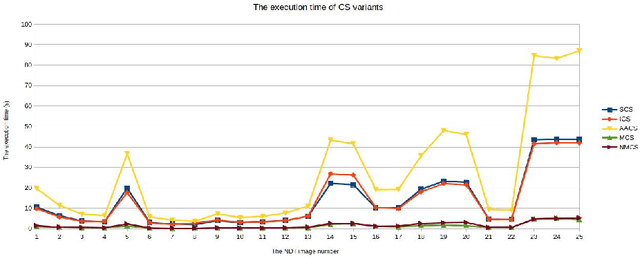

In this paper, we present new image segmentation methods based on hidden Markov random fields (HMRFs) and cuckoo search (CS) variants. HMRFs model the segmentation problem as a minimization of an energy function. CS algorithm is one of the recent powerful optimization techniques. Therefore, five variants of the CS algorithm are used to compute a solution. Through tests, we conduct a study to choose the CS variant with parameters that give good results (execution time and quality of segmentation). CS variants are evaluated and compared with non-destructive testing (NDT) images using a misclassification error (ME) criterion.
Adaptable Deformable Convolutions for Semantic Segmentation of Fisheye Images in Autonomous Driving Systems
Feb 19, 2021



Advanced Driver-Assistance Systems rely heavily on perception tasks such as semantic segmentation where images are captured from large field of view (FoV) cameras. State-of-the-art works have made considerable progress toward applying Convolutional Neural Network (CNN) to standard (rectilinear) images. However, the large FoV cameras used in autonomous vehicles produce fisheye images characterized by strong geometric distortion. This work demonstrates that a CNN trained on standard images can be readily adapted to fisheye images, which is crucial in real-world applications where time-consuming real-time data transformation must be avoided. Our adaptation protocol mainly relies on modifying the support of the convolutions by using their deformable equivalents on top of pre-existing layers. We prove that tuning an optimal support only requires a limited amount of labeled fisheye images, as a small number of training samples is sufficient to significantly improve an existing model's performance on wide-angle images. Furthermore, we show that finetuning the weights of the network is not necessary to achieve high performance once the deformable components are learned. Finally, we provide an in-depth analysis of the effect of the deformable convolutions, bringing elements of discussion on the behavior of CNN models.
CVaR-based Flight Energy Risk Assessment for Multirotor UAVs using a Deep Energy Model
May 31, 2021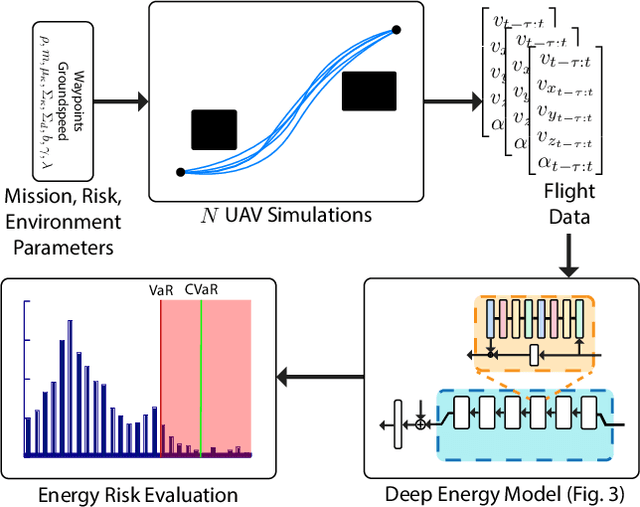
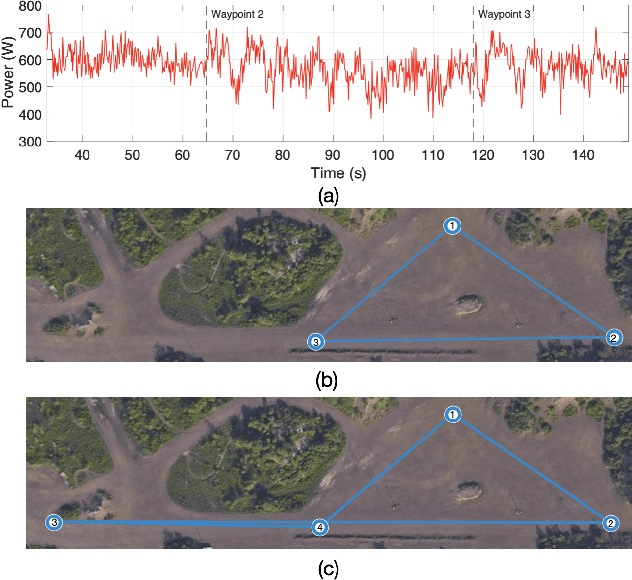
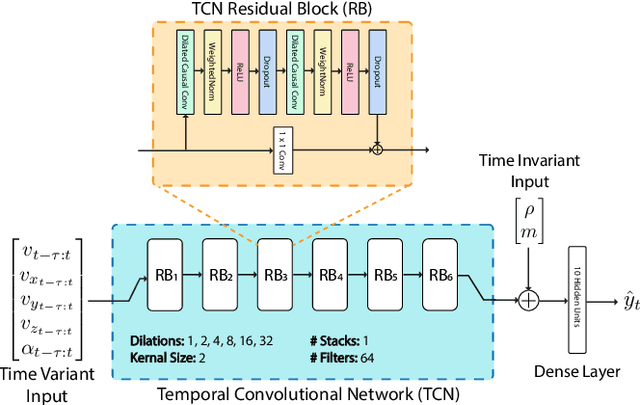
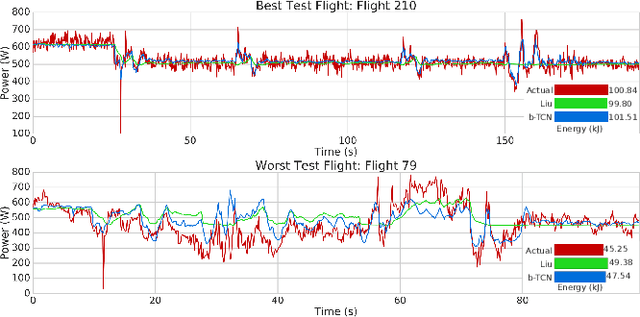
Energy management is a critical aspect of risk assessment for Uncrewed Aerial Vehicle (UAV) flights, as a depleted battery during a flight brings almost guaranteed vehicle damage and a high risk of human injuries or property damage. Predicting the amount of energy a flight will consume is challenging as routing, weather, obstacles, and other factors affect the overall consumption. We develop a deep energy model for a UAV that uses Temporal Convolutional Networks to capture the time varying features while incorporating static contextual information. Our energy model is trained on a real world dataset and does not require segregating flights into regimes. We illustrate an improvement in power predictions by $29\%$ on test flights when compared to a state-of-the-art analytical method. Using the energy model, we can predict the energy usage for a given trajectory and evaluate the risk of running out of battery during flight. We propose using Conditional Value-at-Risk (CVaR) as a metric for quantifying this risk. We show that CVaR captures the risk associated with worst-case energy consumption on a nominal path by transforming the output distribution of Monte Carlo forward simulations into a risk space. Computing the CVaR on the risk-space distribution provides a metric that can evaluate the overall risk of a flight before take-off. Our energy model and risk evaluation method can improve flight safety and evaluate the coverage area from a proposed takeoff location. The video and codebase are available at https://youtu.be/PHXGigqilOA and https://git.io/cvar-risk .
Design of hazard based model and collision avoidance system
Jun 05, 2021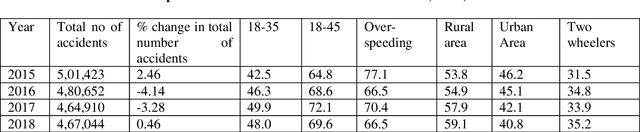
The primary goal of this paper is to examine the motorcyclists' activities during the overtaking period, as well as to develop a model of total overtaking time. For the experimental study, instrumented motorcycles were used to collect data and design an overall overtaking period model. The possibility of death during an attempt to overtake is maximum for people walking on rural roads, mainly identified by a scarcity of pathways and higher speeds of vehicles. It is important to recognize and prototype driver actions during the overtaking moves to set up collision avoidance strategies in order to prevent these collisions, such that device adjustments are acceptable as they occur beyond the comfort zone of the drivers. The purpose of this research is to address both vehicle overtaking movements along urban roads and to develop a collision avoidance system. This research, based on tests performed and instrumented driving information, may lead to the discovery of advanced driver assistance systems, analyzing driver behavior during overtaking. A total of 500 overtaking movements were registered with 50 motorcycles set up with a high-resolution camera and GPS system implemented by 50 professional bikers in India in an undivided one-way road. A technique was developed to collect data explaining the actions of the motorcyclists, based on video and GPS analyses. The overall overtaking period was designed using a risk-based model, which indicates the span of the overtaking based on several coefficients. The proposed model is useful to analyze the behavior during overtaking moves, as well as to develop road and vehicle safety systems to reduce the chances of accidents.
Relation-aware Hierarchical Attention Framework for Video Question Answering
May 13, 2021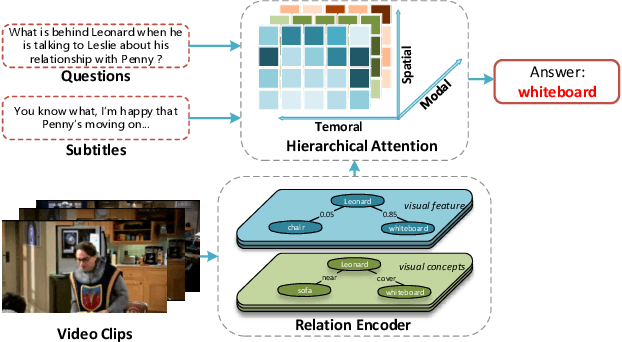
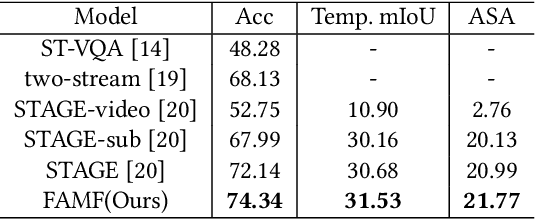
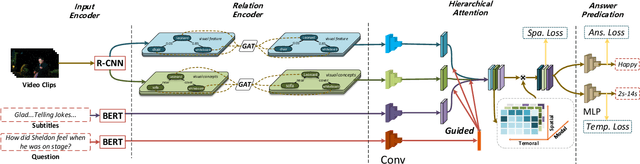
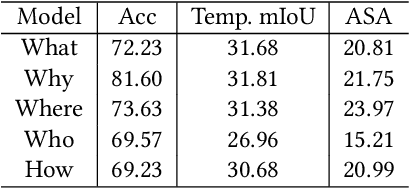
Video Question Answering (VideoQA) is a challenging video understanding task since it requires a deep understanding of both question and video. Previous studies mainly focus on extracting sophisticated visual and language embeddings, fusing them by delicate hand-crafted networks.However, the relevance of different frames, objects, and modalities to the question are varied along with the time, which is ignored in most of existing methods. Lacking understanding of the the dynamic relationships and interactions among objects brings a great challenge to VideoQA task.To address this problem, we propose a novel Relation-aware Hierarchical Attention (RHA) framework to learn both the static and dynamic relations of the objects in videos. In particular, videos and questions are embedded by pre-trained models firstly to obtain the visual and textual features. Then a graph-based relation encoder is utilized to extract the static relationship between visual objects.To capture the dynamic changes of multimodal objects in different video frames, we consider the temporal, spatial, and semantic relations, and fuse the multimodal features by hierarchical attention mechanism to predict the answer. We conduct extensive experiments on a large scale VideoQA dataset, and the experimental results demonstrate that our RHA outperforms the state-of-the-art methods.
Temporal scale selection in time-causal scale space
Jan 09, 2017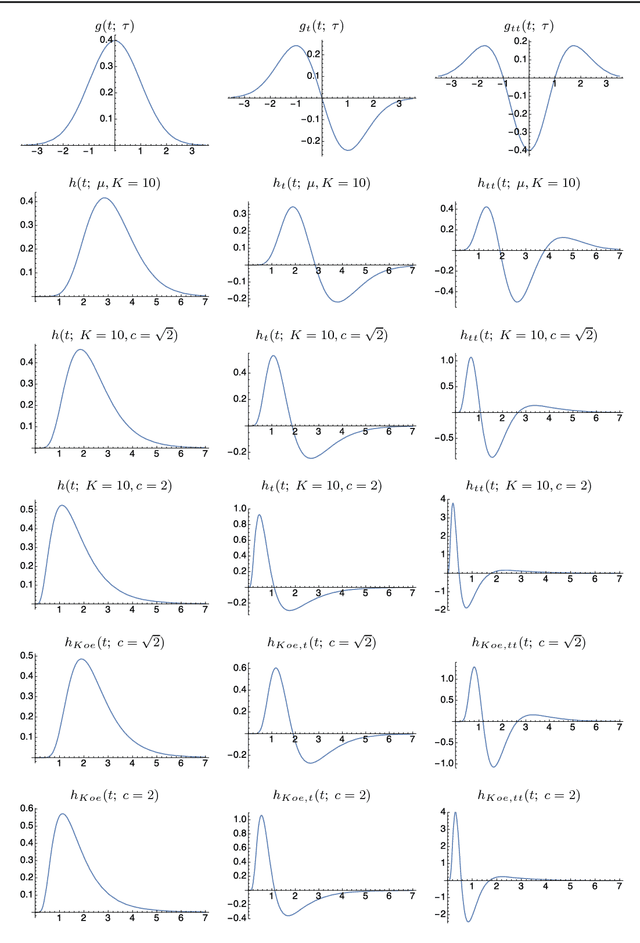

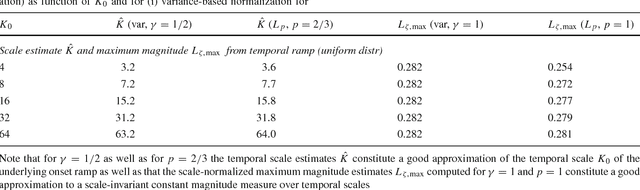
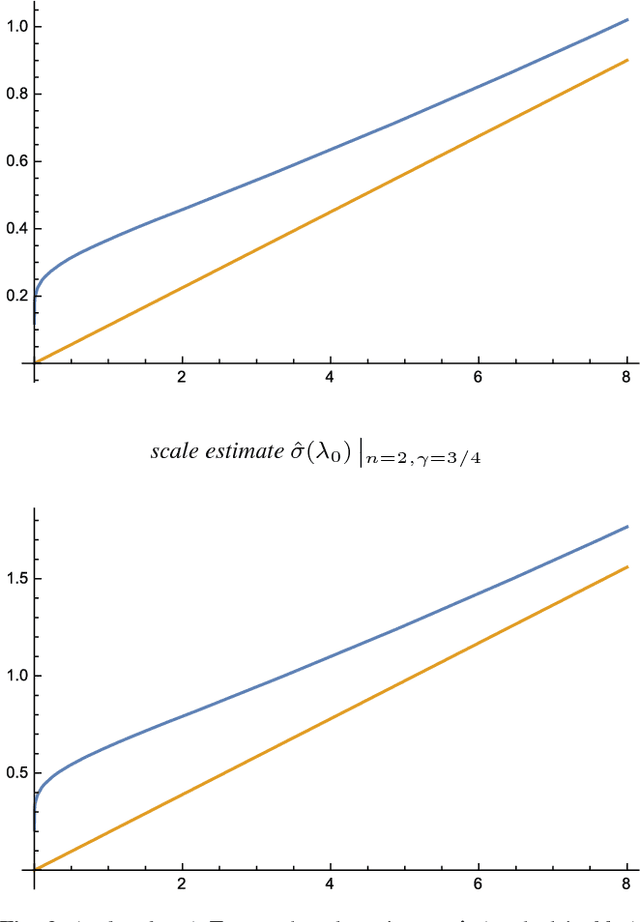
When designing and developing scale selection mechanisms for generating hypotheses about characteristic scales in signals, it is essential that the selected scale levels reflect the extent of the underlying structures in the signal. This paper presents a theory and in-depth theoretical analysis about the scale selection properties of methods for automatically selecting local temporal scales in time-dependent signals based on local extrema over temporal scales of scale-normalized temporal derivative responses. Specifically, this paper develops a novel theoretical framework for performing such temporal scale selection over a time-causal and time-recursive temporal domain as is necessary when processing continuous video or audio streams in real time or when modelling biological perception. For a recently developed time-causal and time-recursive scale-space concept defined by convolution with a scale-invariant limit kernel, we show that it is possible to transfer a large number of the desirable scale selection properties that hold for the Gaussian scale-space concept over a non-causal temporal domain to this temporal scale-space concept over a truly time-causal domain. Specifically, we show that for this temporal scale-space concept, it is possible to achieve true temporal scale invariance although the temporal scale levels have to be discrete, which is a novel theoretical construction.
Boosting Light-Weight Depth Estimation Via Knowledge Distillation
May 13, 2021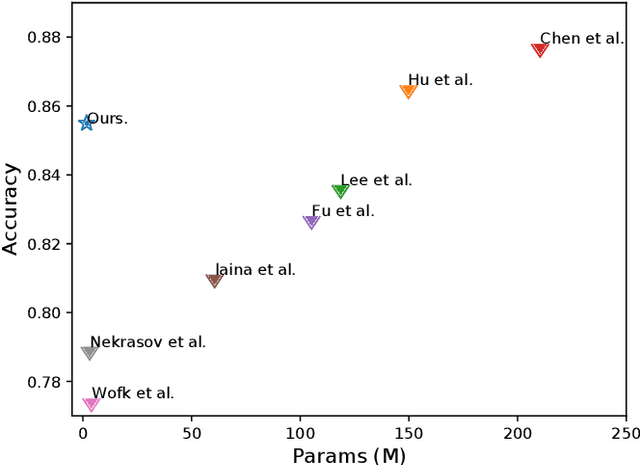

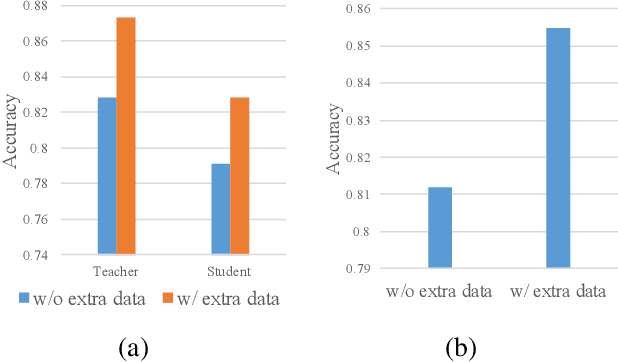
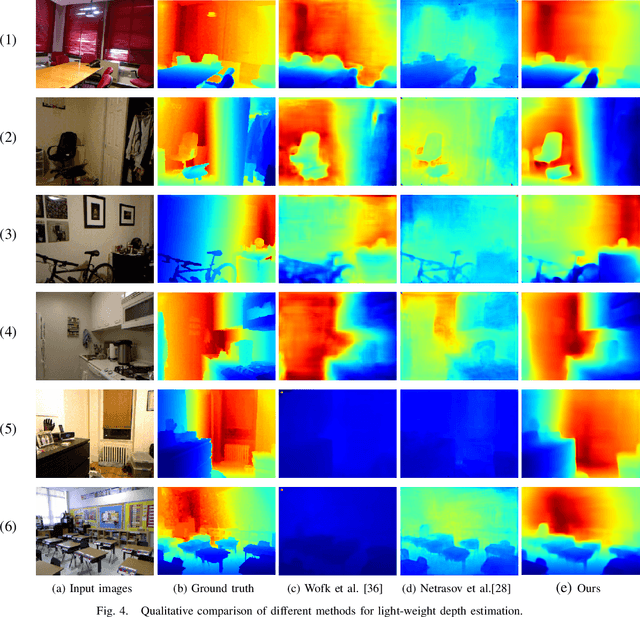
The advanced performance of depth estimation is achieved by the employment of large and complex neural networks. While the performance has still been continuously improved, we argue that the depth estimation has to be accurate and efficient. It's a preliminary requirement for real-world applications. However, fast depth estimation tends to lower the performance as the trade-off between the model's capacity and accuracy. In this paper, we attempt to archive highly accurate depth estimation with a light-weight network. To this end, we first introduce a compact network that can estimate a depth map in real-time. We then technically show two complementary and necessary strategies to improve the performance of the light-weight network. As the number of real-world scenes is infinite, the first is the employment of auxiliary data that increases the diversity of training data. The second is the use of knowledge distillation to further boost the performance. Through extensive and rigorous experiments, we show that our method outperforms previous light-weight methods in terms of inference accuracy, computational efficiency and generalization. We can achieve comparable performance compared to state-of-the-of-art methods with only 1% parameters, on the other hand, our method outperforms other light-weight methods by a significant margin.